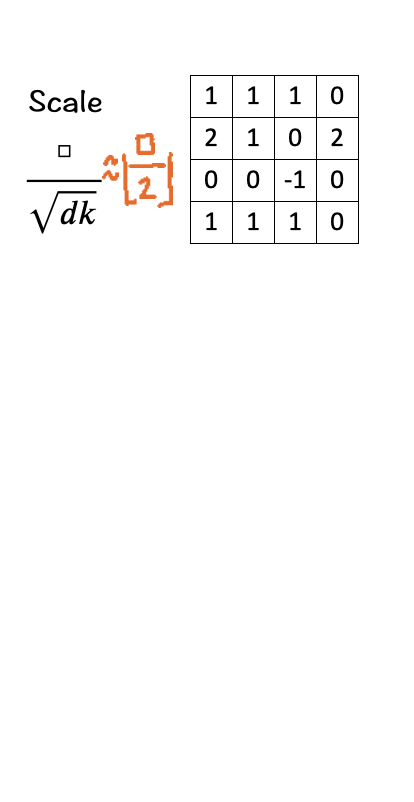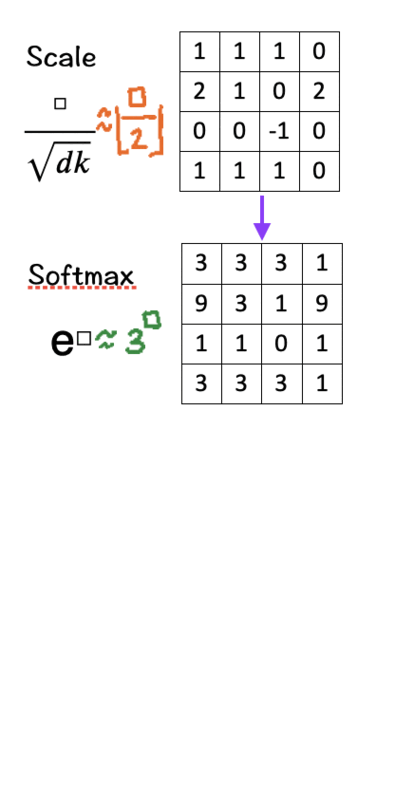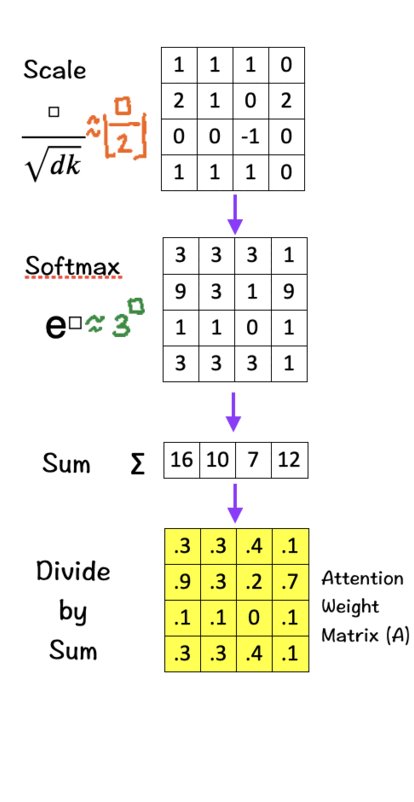Organizations are facing ever-increasing requirements for sustainability goals alongside environmental, social, and governance (ESG) practices. A Gartner, Inc. survey revealed that 87 percent of business leaders expect to increase their organization’s investment in sustainability over the next years. This post serves as a starting point for any executive seeking to navigate the intersection of generative […]
Google Chrome’s potential integration of Gemini, its flagship AI model, promises smarter password suggestions but raises concerns about security vulnerabilities.
Explore the intricacies of the attention mechanism responsible for fueling the transformers
Attention! Attention!
Because ‘Attention is All You Need’.
No, I am not saying that, the Transformer is.
Image by author (Robtimus Prime seeking attention. As per my son, bright rainbow colors work better for attention and hence the color scheme.)
As of today, the world has been swept over by the power of transformers. Not the likes of ‘Robtimus Prime’ but the ones that constitute neural networks. And that power is because of the concept of ‘attention’. So, what does attention in the context of transformers really mean? Let’s try to find out some answers here:
First and foremost:
What are transformers?
Transformers are neural networks that specialize in learning context from the data. Quite similar to us trying to find the meaning of ‘attention and context’ in terms of transformers.
How do transformers learn context from the data?
By using the attention mechanism.
What is the attention mechanism?
The attention mechanism helps the model scan all parts of a sequence at each step and determine which elements need to be focused on. The attention mechanism was proposed as an alternative to the ‘strict/hard’ solution of fixed-length vectors in the encoder-decoder architecture and provide a ‘soft’ solution focusing only on the relevant parts.
What is self-attention?
The attention mechanism worked to improve the performance of Recurrence Neural Networks (RNNs), with the effect seeping into Convolutional Neural Networks (CNNs). However, with the introduction of the transformer architecture in the year 2017, the need for RNNs and CNNs was quietly obliterated. And the central reason for it was the self-attention mechanism.
The self-attention mechanism was special in the sense that it was built to inculcate the context of the input sequence in order to enhance the attention mechanism. This idea became transformational as it was able to capture the complex nuances of a language.
As an example:
When I ask my 4-year old what transformers are, his answer only contains the words robots and cars. Because that is the only context he has. But for me, transformers also mean neural networks as this second context is available to the slightly more experienced mind of mine. And that is how different contexts provide different solutions and so tend to be very important.
The word ‘self’ refers to the fact that the attention mechanism examines the same input sequence that it is processing.
There are many variations of how self-attention is performed. But the scaled dot-product mechanism has been one of the most popular ones. This was the one introduced in the original transformer architecture paper in 2017 — “Attention is All You Need”.
Where and how does self-attention feature in transformers?
I like to see the transformer architecture as a combination of two shells — the outer shell and the inner shell.
The outer shell is a combination of the attention-weighting mechanism and the feed forward layer about which I talk in detail in this article.
The inner shell consists of the self-attention mechanism and is part of the attention-weighting feature.
So, without further delay, let us dive into the details behind the self-attention mechanism and unravel the workings behind it. The Query-Key module and the SoftMax function play a crucial role in this technique.
This discussion is based on Prof. Tom Yeh’s wonderful AI by Hand Series on Self-Attention. (All the images below, unless otherwise noted, are by Prof. Tom Yeh from the above-mentioned LinkedIn post, which I have edited with his permission.)
So here we go:
Self-Attention
To build some context here, here is a pointer to how we process the ‘Attention-Weighting’ in the transformerouter shell.
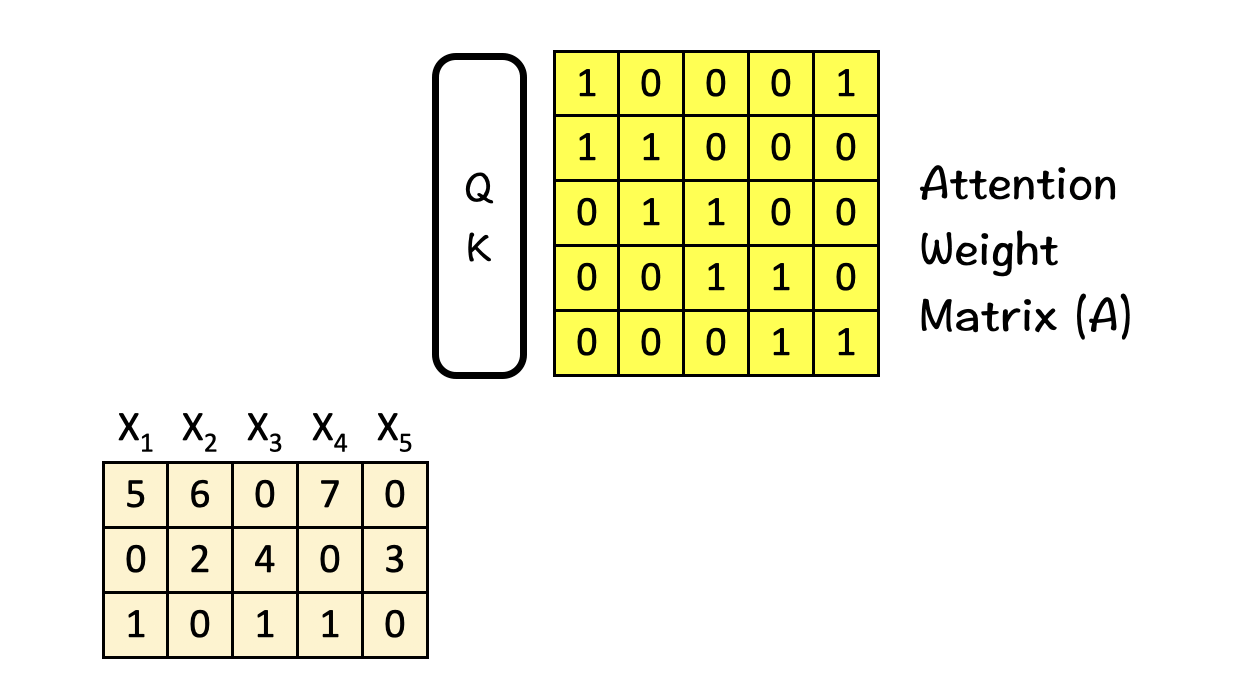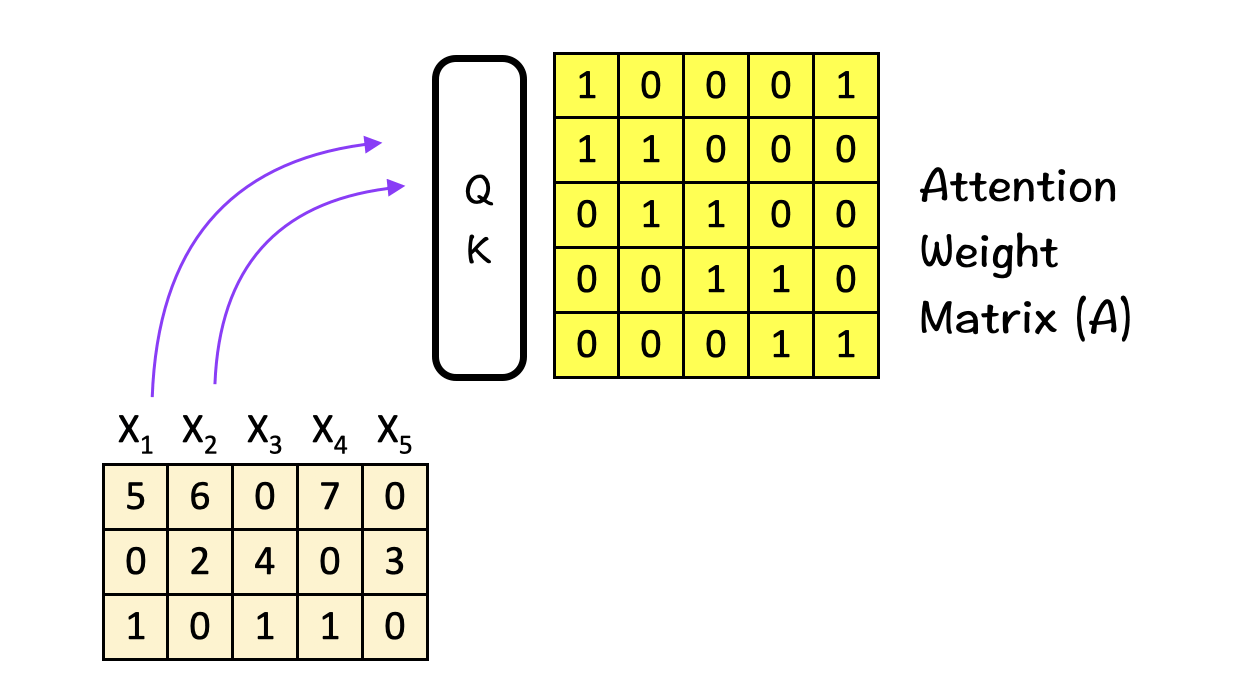
Attention weight matrix (A)
The attention weight matrix A is obtained by feeding the input features into the Query-Key (QK) module. This matrix tries to find the most relevant parts in the input sequence. Self-Attention comes into play while creating the Attention weight matrix A using the QK-module.
How does the QK-module work?
Let us look at The different components of Self-Attention: Query (Q), Key (K) and Value (V).
I love using the spotlight analogy here as it helps me visualize the model throwing light on each element of the sequence and trying to find the most relevant parts. Taking this analogy a bit further, let us use it to understand the different components of Self-Attention.
Imagine a big stage getting ready for the world’s largest Macbeth production. The audience outside is teeming with excitement.
The lead actor walks onto the stage, the spotlight shines on him and he asks in his booming voice “Should I seize the crown?”. The audience whispers in hushed tones and wonders which path this question will lead to. Thus, Macbeth himself represents the role of Query (Q) as he asks pivotal questions and drives the story forward.
Based on Macbeth’s query, the spotlight shifts to other crucial characters that hold information to the answer. The influence of other crucial characters in the story, like Lady Macbeth, triggers Macbeth’s own ambitions and actions. These other characters can be seen as the Key (K) as they unravel different facets of the story based on the particular they know.
Finally, these characters provide enough motivation and information to Macbeth by their actions and perspectives. These can be seen as Value (V). The Value (V) pushes Macbeth towards his decisions and shapes the fate of the story.
And with that is created one of the world’s finest performances, that remains etched in the minds of the awestruck audience for the years to come.
Now that we have witnessed the role of Q, K, V in the fantastical world of performing arts, let’s return to planet matrices and learn the mathematical nitty-gritty behind the QK-module. This is the roadmap that we will follow:
Roadmap for the Self-Attention mechanism
And so the process begins.
We are given:
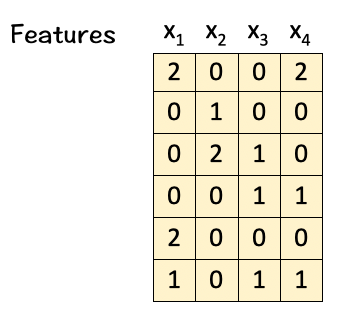
A set of 4-feature vectors (Dimension 6)
Our goal :
Transform the given features into Attention Weighted Features.
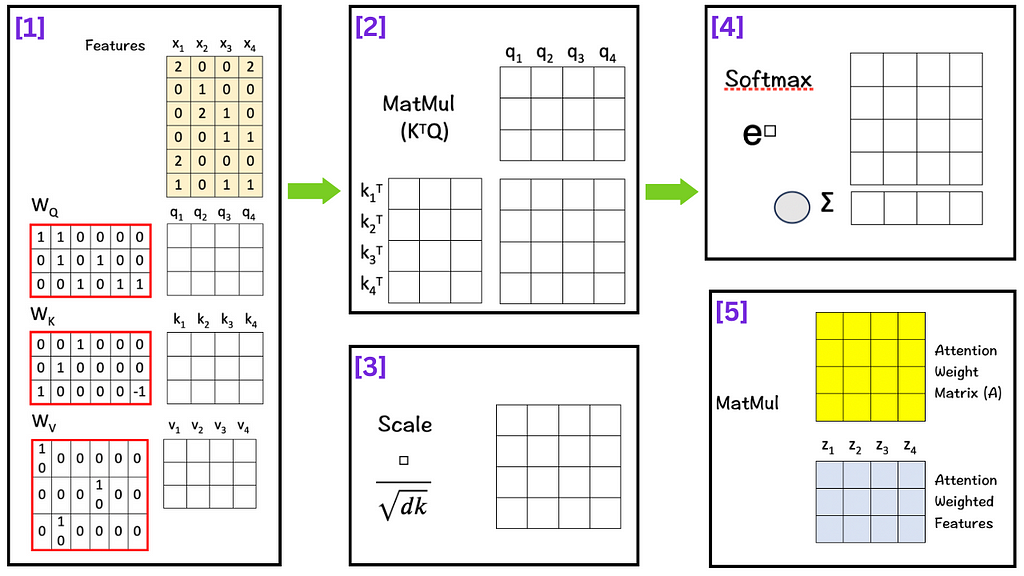
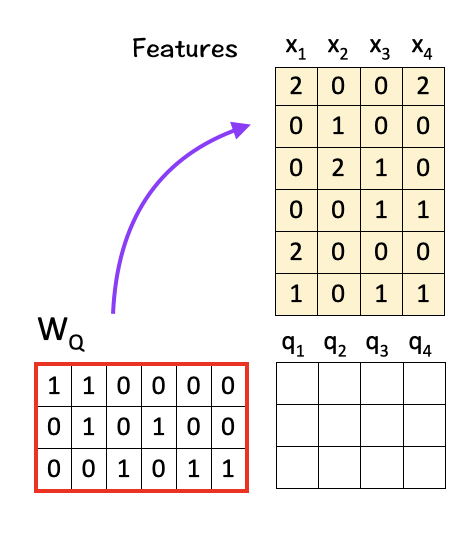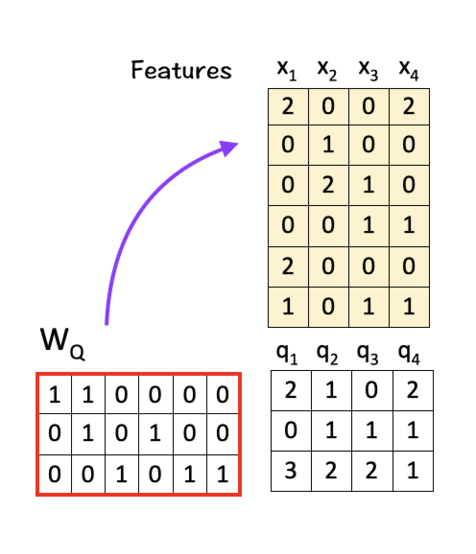
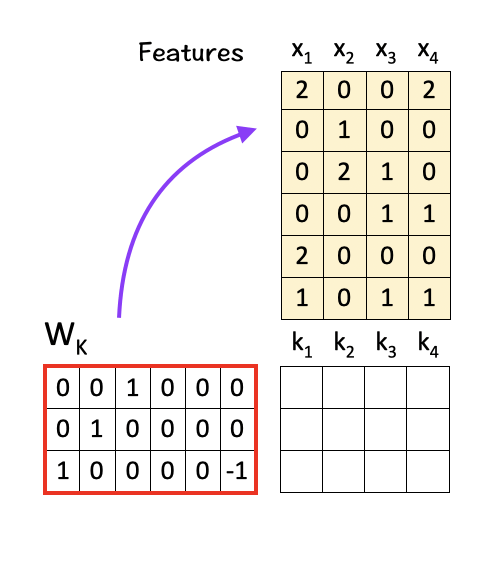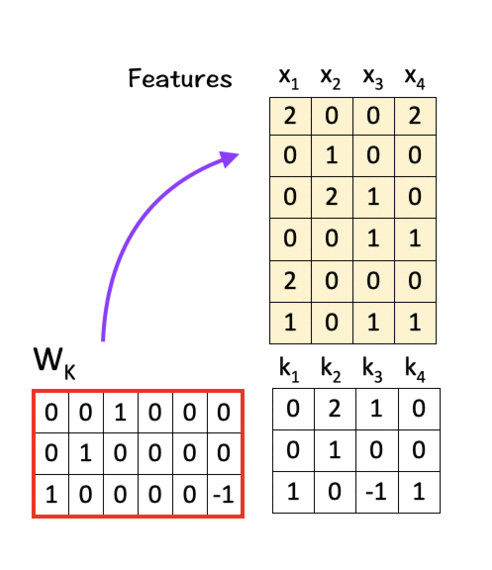
[1] Create Query, Key, Value Matrices
To do so, we multiply the features with linear transformation matrices W_Q, W_K, and W_V, to obtain query vectors (q1,q2,q3,q4), key vectors (k1,k2,k3,k4), and value vectors (v1,v2,v3,v4) respectively as shown below:
To get Q, multiply W_Q with X:
To get K, multiply W_K with X:
Similarly, to get V, multiply W_V with X.
To be noted:
As can be seen from the calculation above, we use the same set of features for both queries and keys. And that is how the idea of “self” comes into play here, i.e. the model uses the same set of features to create its query vector as well as the key vector.
The query vector represents the current word (or token) for which we want to compute attention scores relative to other words in the sequence.
The key vector represents the other words (or tokens) in the input sequence and we compute the attention score for each of them with respect to the current word.
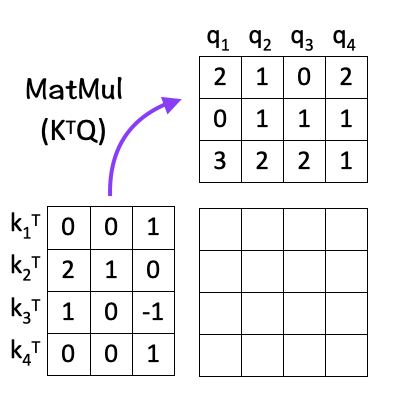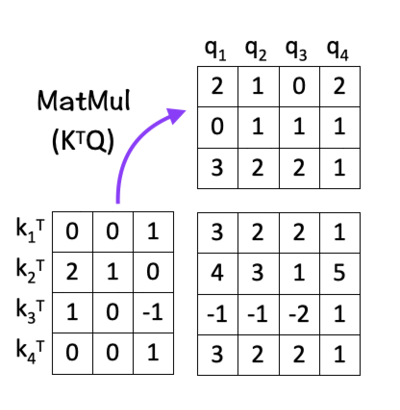
[2] Matrix Multiplication
The next step is to multiply the transpose of K with Q i.e. K^T . Q.
The idea here is to calculate the dot product between every pair of query and key vectors. Calculating the dot product gives us an estimate of the matching score between every “key-query” pair, by using the idea of Cosine Similarity between the two vectors. This is the ‘dot-product’ part of the scaled dot-product attention.
Cosine-Similarity
Cosine similarity is the cosine of the angle between the vectors; that is, it is the dot product of the vectors divided by the product of their lengths. It roughly measures if two vectors are pointing in the same direction thus implying the two vectors are similar.
– If the dot product between the two vectors is approximately 1, it implies we are looking at an almost zero angle between the two vectors meaning they are very close to each other.
– If the dot product between the two vectors is approximately 0, it implies we are looking at vectors that are orthogonal to each other and not very similar.
– If the dot product between the two vectors is approximately -1, it implies we are looking at an almost an 180° angle between the two vectors meaning they are opposites.
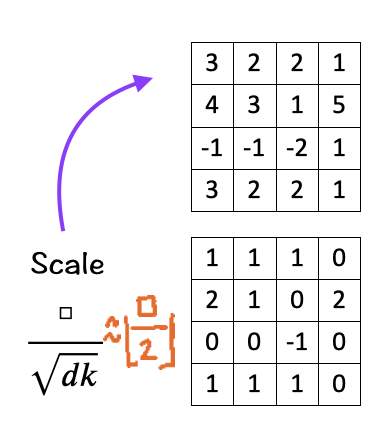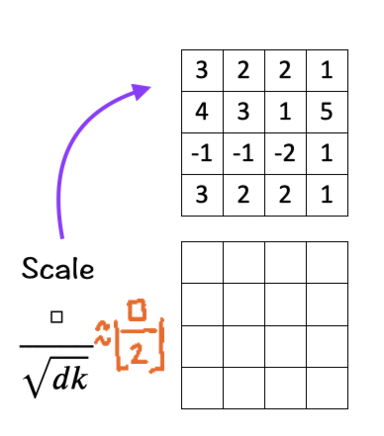
[3] Scale
The next step is to scale/normalize each element by the square root of the dimension ‘d_k’. In our case the number is 3. Scaling down helps to keep the impact of the dimension on the matching score in check.
How does it do so? As per the original Transformer paper and going back to Probability 101, if two independent and identically distributed (i.i.d) variables q and k with mean 0 and variance 1 with dimension d are multiplied, the result is a new random variable with mean remaining 0 but variance changing to d_k.
Now imagine how the matching score would look if our dimension is increased to 32, 64, 128 or even 4960 for that matter. The larger dimension would make the variance higher and push the values into regions ‘unknown’.
To keep the calculation simple here, since sqrt [3] is approximately 1.73205, we replace it with [ floor(□/2) ].
Floor Function
The floor function takes a real number as an argument and returns the largest integer less than or equal to that real number.
The opposite of the floor function is the ceiling function.
This the ‘scaled’ part of the scaled dot-product attention.
[4] Softmax
There are three parts to this step:
Raise e to the power of the number in each cell (To make things easy, we use 3 to the power of the number in each cell.)
Sum these new values across each column.
For each column, divide each element by its respective sum (Normalize). The purpose of normalizing each column is to have numbers sum up to 1. In other words, each column then becomes a probability distribution of attention, which gives us our Attention Weight Matrix (A).
This Attention Weight Matrix is what we had obtained after passing our feature matrix through the QK-module in Step 2 in the Transformers section.
The Softmax step is important as it assigns probabilities to the score obtained in the previous steps and thus helps the model decide how much importance (higher/lower attention weights) needs to be given to each word given the current query. As is to be expected, higher attention weights signify greater relevance allowing the model to capture dependencies more accurately.
Once again, the scaling in the previous step becomes important here. Without the scaling, the values of the resultant matrix gets pushed out into regions that are not processed well by the Softmax function and may result in vanishing gradients.
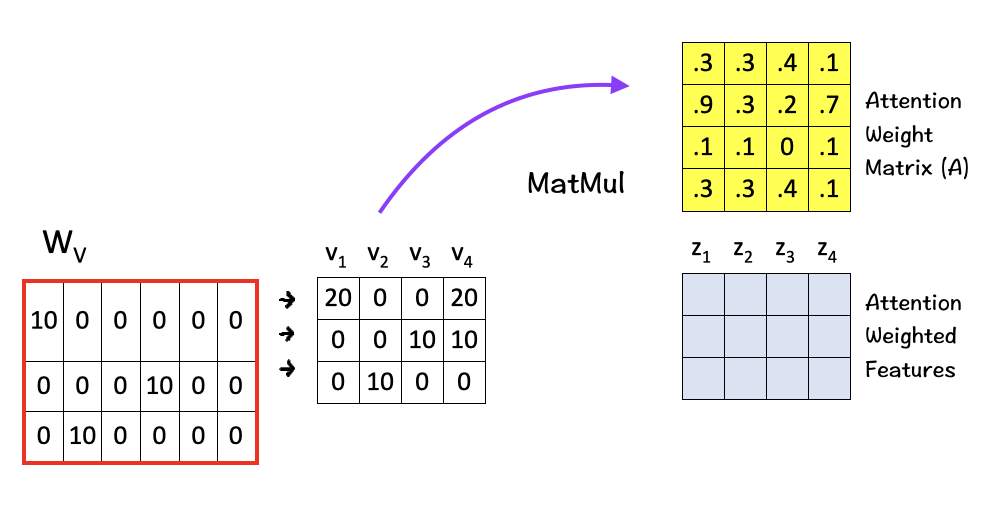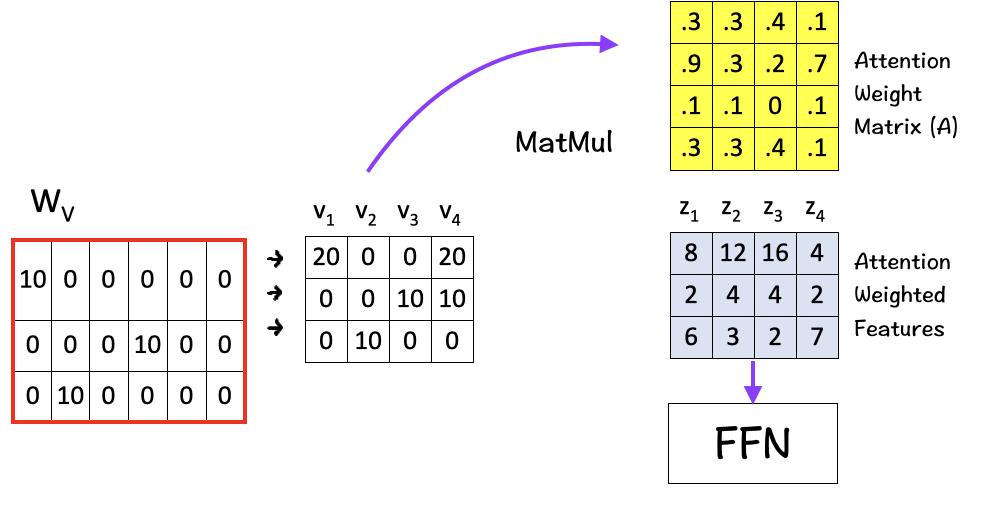
[5] Matrix Multiplication
Finally we multiply the value vectors (Vs) with the Attention Weight Matrix (A). These value vectors are important as they contain the information associated with each word in the sequence.
And the result of the final multiplication in this step are the attention weighted features Zs which are the ultimate solution of the self-attention mechanism. These attention-weighted features essentially contain a weighted representationof the features assigning higher weights for features with higher relevance as per the context.
Now with this information available, we continue to the next step in the transformer architecture where the feed-forward layer processes this information further.
And this brings us to the end of the brilliant self-attention technique!
Reviewing all the key points based on the ideas we talked about above:
Attention mechanism was the result of an effort to better the performance of RNNs, addressing the issue of fixed-length vector representations in the encoder-decoder architecture. The flexibility of soft-length vectors with a focus on the relevant parts of a sequence was the core strength behind attention.
Self-attention was introduced as a way to inculcate the idea of context into the model. The self-attention mechanism evaluates the same input sequence that it processes, hence the use of the word ‘self’.
There are many variants to the self-attention mechanism and efforts are ongoing to make it more efficient. However, scaled dot-product attention is one of the most popular ones and a crucial reason why the transformer architecture was deemed to be so powerful.
Scaled dot-product self-attention mechanism comprises the Query-Key module (QK-module) along with the Softmax function. The QK module is responsible for extracting the relevance of each element of the input sequence by calculating the attention scores and the Softmax function complements it by assigning probability to the attention scores.
Once the attention-scores are calculated, they are multiplied with the value vector to obtain the attention-weighted features which are then passed on to the feed-forward layer.
Multi-Head Attention
To cater to a varied and overall representation of the sequence, multiple copies of the self-attention mechanism are implemented in parallel which are then concatenated to produce the final attention-weighted values. This is called the Multi-Head Attention.
Transformer in a Nutshell
This is how the inner-shell of the transformer architecture works. And bringing it together with the outer shell, here is a summary of the Transformer mechanism:
The two big ideas in the Transformer architecture here are attention-weighting and the feed-forward layer (FFN). Both of them combined together allow the Transformer to analyze the input sequence from two directions. Attention looks at the sequence based on positions and the FFN does it based on the dimensions of the feature matrix.
The part that powers the attention mechanism is the scaled dot-product Attention which consists of the QK-module and outputs the attention weighted features.
‘Attention Is really All You Need’
Transformers have been here for only a few years and the field of AI has already seen tremendous progress based on it. And the effort is still ongoing. When the authors of the paper used that title for their paper, they were not kidding.
It is interesting to see once again how a fundamental idea — the ‘dot product’ coupled with certain embellishments can turn out to be so powerful!
Image by author
P.S. If you would like to work through this exercise on your own, here are the blank templates for you to use.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
The LangChain documentation actually has a pretty good page on the high level concepts around its agents. It’s a short easy read, and definitely worth skimming through before getting started.
If you lookup the definition of AI Agents, you get something along the lines of “An entity that is able to perceive its environment, act on its environment, and make intelligent decisions about how to reach a goal it has been given, as well as the ability to learn as it goes”
That fits the definition of LangChain agents pretty well I would say. What makes all this possible in software is the reasoning abilities of Large Language Model’s (LLM’s). The brains of a LangChain agent are an LLM. It is the LLM that is used to reason about the best way to carry out the ask requested by a user.
In order to carry out its task, and operate on things and retrieve information, the agent has what are called Tool’s in LangChain, at its disposal. It is through these tools that it is able to interact with its environment.
The tools are basically just methods/classes the agent has access to that can do things like interact with a Stock Market index over an API, update a Google Calendar event, or run a query against a database. We can build out tools as needed, depending on the nature of tasks we are trying to carry out with the agent to fulfil.
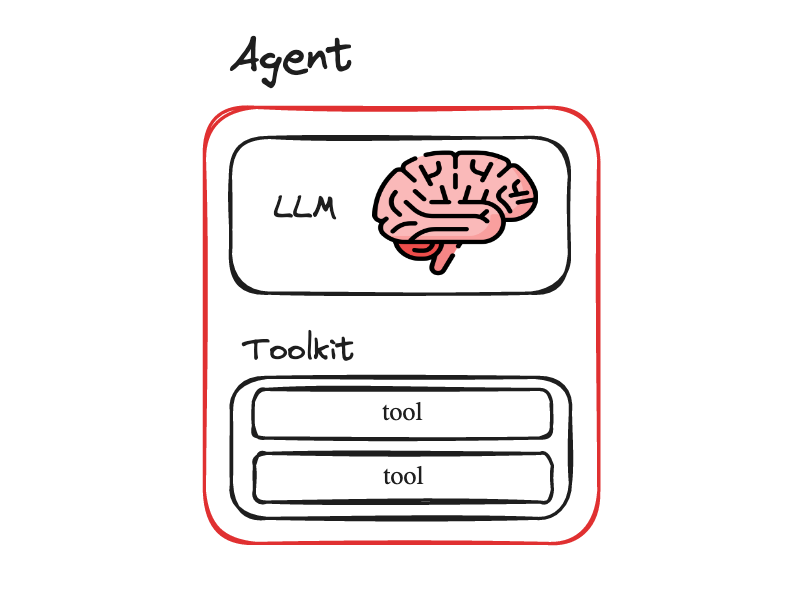
A collection of Tools in LangChain are called a Toolkit. Implementation wise, this is literally just an array of the Tools that are available for the agent. As such, the high level overview of an agent in LangChain looks something like this
Image by author
So, at a basic level, an agent needs
an LLM to act as its brain, and to give it its reasoning abilities
tools so that it can interact with the environment around it and achieve its goals
Building the Agent
To make some of these concepts more concrete, let’s build a simple agent.
We will create a Mathematics Agent that can perform a few simple mathematical operations.
The simplest place to start will be to fist define the tools for our Maths agent.
Let’s give it “add”, “multiply” and “square” tools, so that it can perform those operations on questions we pass to it. By keeping our tools simple we can focus on the core concepts, and build the tools ourselves, instead of relying on an existing and more complex tools like the WikipediaTool, that acts as a wrapper around the Wikipedia API, and requires us to import it from the LangChain library.
Again, we are not trying to do anything fancy here, just keeping it simple and putting the main building blocks of an agent together so we can understand how they work, and get our first agent up and running.
Let’s start with the “add” tool. The bottom up way to create a Tool in LangChain would be to extend the BaseTool class, set the name and description fields on the class, and implement the _run method. That would look like this
from langchain_core.tools import BaseTool
class AddTool(BaseTool): name = "add" description = "Adds two numbers together" args_schema: Type[BaseModel] = AddInput return_direct: bool = True
def _run( self, a: int, b: int, run_manager: Optional[CallbackManagerForToolRun] = None ) -> str: return a + b
Notice that we need to implement the _run method to show what our tool does with the parameters that are passed to it.
Notice also how it requires a pydantic model for the args_schema. We will define that here
AddInput a: int = Field(description="first number") b: int = Field(description="second number")
Now, LangChain does give us an easier way to define tools, then by needing to extend the BaseTool class each time. We can do this with the help of the @tool decorator. Defining the “add” tool in LangChain using the @tool decorator will look like this
from langchain.tools import tool
@tool def add(a: int, b: int) -> int: “””Adds two numbers together””” # this docstring gets used as the description return a + b # the actions our tool performs
Much simpler right. Behind the scenes, the decorator magically uses the method provided to extend the BaseTool class, just as we did earlier. Some thing to note:
the method name also becomes the tool name
the method params define the input parameters for the tool
the docstring gets converted into the tools description
Note that the description of a tool is very important as this is what the LLM uses to decide whether or not it is the right tool for the job. A bad description may lead to the not tool getting used when it should be, or getting used at the wrong times.
With the add tool done, let’s move on to the definitions for our multiply and square tools.
@tool def multiply(a: int, b: int) -> int: """Multiply two numbers.""" return a * b
@tool def square(a) -> int: """Calculates the square of a number.""" a = int(a) return a * a
And that is it, simple as that.
So we have defined our own three custom tools. A more common use case might be to use some of the already provided and existing tools in LangChain, which you can see here. However, at the source code level, they would all be built and defined using a similar methods as described above.
And that is it as far as our Tools our concerned. Now time to combine our tools into a Toolkit.
The Toolkit
Toolkits sound fancy, but they are actually very simple. They are literally just a a list of tools. We can define our toolkit as an array of tools like so
toolkit = [add, multiply, square]
And that’s it. Really straightforward, and nothing to get confused over.
Usually Toolkits are groups of tools that are useful together, and would be helpful for agents trying to carry out certain kinds of tasks. For example an SQLToolkit might contain a tool for generating an SQL query, validating an SQL query, and executing an SQL query.
The Integrations Toolkit page on the LangChain docs has a large list of toolkits developed by the community that might be useful for you.
The LLM
As mentioned above, an LLM is the brains of an agent. It decides which tools to call based on the question passed to it, what are the best next steps to take based on a tools description. It also decides when it has reached its final answer, and is ready to return that to the user.
Lastly we need a prompt to pass into our agent, so it has a general idea bout what kind of agent it is, and what sorts of tasks it should solve.
Our agent requires a ChatPromptTemplate to work (more on that later). This is what a barebones ChatPromptTemplate looks like. The main part we care about is the system prompt, and the rest are just the default settings we are required to pass in.
In our prompt we have included a sample answer, showing the agent how we want it to return the answer only, and not any descriptive text along with the answer
prompt = ChatPromptTemplate.from_messages( [ ("system", """ You are a mathematical assistant. Use your tools to answer questions. If you do not have a tool to answer the question, say so.
Return only the answers. e.g Human: What is 1 + 1? AI: 2 """), MessagesPlaceholder("chat_history", optional=True), ("human", "{input}"), MessagesPlaceholder("agent_scratchpad"), ] )
That is it. We have setup our Tools and Toolkit, which our agent will need as part of its setup, so its knows what are the types of actions and capabilities it has at its disposal. And we have also setup the LLM and system prompt.
Now for the fun part. Setting up our Agent!
The Agent
LangChain has a number of different agents types that can be created, with different reasoning powers and abilities. We will be using the most capable and powerful agent currently available, the OpenAI Tools agent. As per the docs on the the OpenAI Tools agent, which uses newer OpenAI models also,
Newer OpenAI models have been fine-tuned to detect when one or more function(s) should be called and respond with the inputs that should be passed to the function(s). In an API call, you can describe functions and have the model intelligently choose to output a JSON object containing arguments to call these functions. The goal of the OpenAI tools APIs is to more reliably return valid and useful function calls than what can be done using a generic text completion or chat API.
In other words this agents is good at generating the correct structure for calling functions, and is able to understand if more than one function (tool) might be needed for our task also. This agent also has the ability to call functions (tools) with multiple input parameters, just like ours do. Some agents can only work with functions that have a single input parameter.
If you are familiar with OpenAI’s Function calling feature, where we can use the OpenAI LLM to generate the correct parameters to call a function with, the OpenAI Tools agent we are using here is leveraging some of that power in order to be able to call the correct tool, with the correct parameters.
In order to setup an agent in LangChain, we need to use one of the factory methods provided for creating the agent of our choice.
The factory method for creating an OpenAI tools agent is create_openai_tools_agent(). And it requires passing in the llm, tools and prompt we setup above. So let’s initialise our agent.
Finally, in order to run agents in LangChain, we cannot just call a “run” type method on them directly. They need to be run via an AgentExecutor.
Am bringing up the Agent Executor only here at the end as I don’t think it’s a critical concept for understanding how the agents work, and bring it up at the start with everything else would just the whole thing seem more complicated than it needs to be, as well as distract from understanding some of the other more fundamental concepts.
So, now that we are introducing it, an AgentExecutor acts as the runtime for agents in LangChain, and allow an agent to keep running until it is ready to return its final response to the user. In pseudo-code, the AgentExecutor’s are doing something along the lines of (pulled directly from the LangChain docs)
So they are basically a while loop that keep’s calling the next action methods on the agent, until the agent has returned its final response.
So, let us setup our agent inside the agent executor. We pass it the agent, and must also pass it the toolkit. And we are setting verbose to True so we can get an idea of what the agent is doing as it is processing our request
And that is it. We are now ready to pass commands to our agent
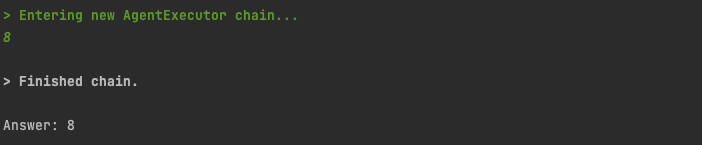
result = agent_executor.invoke({"input": "what is 1 + 1"})
Let run our script, and see the agent’s output
python3 math-agent.py
Image by author
Since we have set verbose=True on the AgentExecutor, we can see the lines of Action our agent has taken. It has identified we should call the “add” tool, called the “add” tool with the required parameters, and returned us our result.
This is what the full source code looks like
import os
from langchain.agents import AgentExecutor, create_openai_tools_agent from langchain_openai import ChatOpenAI
from langchain.tools import BaseTool, StructuredTool, tool from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
os.environ["OPENAI_API_KEY"] = "sk-"
# setup the tools @tool def add(a: int, b: int) -> int: """Add two numbers.""" return a + b
@tool def multiply(a: int, b: int) -> int: """Multiply two numbers.""" return a * b
@tool def square(a) -> int: """Calculates the square of a number.""" a = int(a) return a * a
prompt = ChatPromptTemplate.from_messages( [ ("system", """You are a mathematical assistant. Use your tools to answer questions. If you do not have a tool to answer the question, say so.
Return only the answers. e.g Human: What is 1 + 1? AI: 2 """), MessagesPlaceholder("chat_history", optional=True), ("human", "{input}"), MessagesPlaceholder("agent_scratchpad"), ] )
# Choose the LLM that will drive the agent llm = ChatOpenAI(model="gpt-3.5-turbo-1106", temperature=0)
# setup the toolkit toolkit = [add, multiply, square]
# Create an agent executor by passing in the agent and tools agent_executor = AgentExecutor(agent=agent, tools=toolkit, verbose=True)
result = agent_executor.invoke({"input": "what is 1 + 1?"})
print(result['output'])
Testing our agent
Let’s shoot a few questions at our agent to see how it performs.
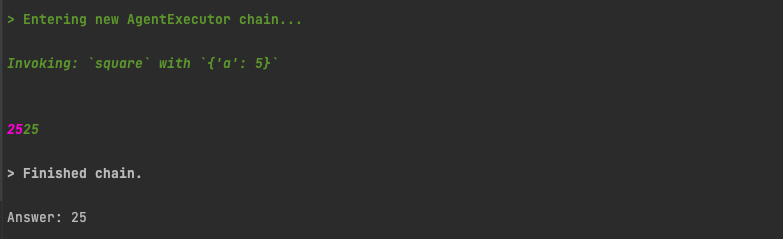
what is 5 squared?
Again we get the correct result, and see that it does use our square tool
Image by author
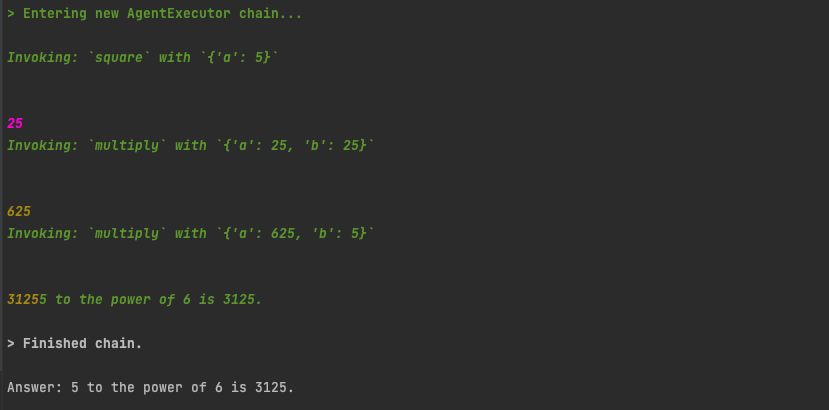
what is 5 to the power of 6?
It takes an interesting course of action. It first uses the square tool. And then, using the result of that, tries to use the multiply tool a few times to get the final answer. Admittedly, the final answer, 3125, is wrong, and needs to be multiplied by 5 one more time to get the correct answer. But it is interesting to see how the agent tried to use different tools, and multiple steps to try and get to the final answer.
Image by author
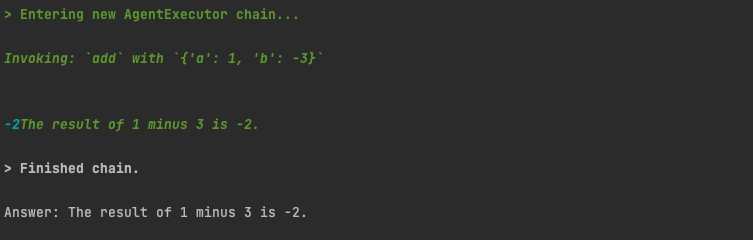
what is 1 minus 3?
We don’t have a minus tool. But it is smart enough to use our add tool, but set the second value to -3. Its funny and somewhat amazing sometimes how they are smart and creative like that.
Image by author
what is the square root of 64
As a final test, what if we ask it to carry out a mathematical operation that is not part of our tool set? Since we have no tools for square rooting, it does not attempt to call a tool, and instead calculates the value directly using just the LLM.
Image by author
Our system prompt did tell it to answer that it “does not know” if it does not have the correct tool for the job, and it did do that sometimes during testing. An improved initial system prompt could probably help resolve that, at least to some extent
Observations
Based on using the agent a bit, I noticed the following
when asking it direct questions which it had the tools to answer with, it was pretty consistent at using the correct tools for the job, and returning the correct answer. So, pretty reliable in that sense.
if the question is a little complicated, for example our “5 to the power of 6” question, it does not always return the correct results.
it can sometimes use just the pure power of the LLM to answer our question, without invoking our tools.
The Future
Agents, and programs that can reason from themselves, are a new paradigm in programming, and I think they are going to become a much more mainstream part of how lots of things are built. Obviously the non-deterministic (i.e not wholly predictable) nature of LLM’s means that agents results will also suffer from this, questioning how much we can rely on them for tasks where we need to be sure of the answers we have.
Perhaps as the technology matures, their results can be more and more predictable, and we may develop some work arounds for this.
I can also see agent type libraries and packages starting to become a thing. Similar to how we install third party libraries and packages into software, for example via the pip package manager for python, or Docker Hub for docker images, I wonder if we may start to see a library and package manager of agents start being developed, with agents developed that become very good at their specific tasks, which we can then also install as packages into out application.
Indeed LangChain’s library of Toolkits for agents to use, listed on their Integrations page, are sets of Tools built by the community for people to use, which could be an early example of agent type libraries built by the community.
Conclusion
Hope this was a useful introduction into getting you started building with agents in LangChain.
Remember, agents are basically just a brain (the LLM), and a bunch of tools, which they can use to get stuff done in the world around us.
Happy hacking!
If you enjoyed the article, and would like to stay up to date on future articles I release about building things with LangChain and AI tools, do subscribe here to be notified by email when they come out
Investment bank Morgan Stanley says there are signs of increased iPhone, Mac, and Services revenue for Apple, but it has cut its target price by $10.
Apple Park
One week after claiming that Apple has increased its June quarter iPhone orders, Morgan Stanley now says that there are also rises in demand for other devices. Specifically, in a note to investors seen by AppleInsider, its analysts say that Mac shipments have grown year over year, which contributes to a rising March quarter revenue.
The analysts further say that the supply chain is reporting around a 5% increase for the iPad above forecasts, or 11 million units instead of 10.5 million. Morgan Stanley has hiked its forecast for Services by 1%, based on what it believes to be stronger than expected App Store performance.
On this episode of the HomeKit Insider Podcast, we check out a pair of new purifiers, go hands on with the Mophie Qi2 dock, and break down more new product launches.
HomeKit Insider Podcast
Nanoleaf’s new string lights are available, though the name can be misleading. These dangling pendant lights are more similar to your typical filament bulbs found on outdoor patios.
They are Matter-enabled, support RGBIC, and over 16 million colors. They come in three lengths from 15m to 45m and extensions can also be purchased.
Nanoleaf string lights, new air purifiers, Qi2 chargers, & Govee floor lamps on HomeKit Insider
Originally appeared here:
Nanoleaf string lights, new air purifiers, Qi2 chargers, & Govee floor lamps on HomeKit Insider
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.