Microsoft didn’t disclose the in-the-wild exploits by Kremlin-backed group until now.
Originally appeared here:
Windows vulnerability reported by the NSA exploited to install Russian backdoor

Originally appeared here:
Windows vulnerability reported by the NSA exploited to install Russian backdoor

A while ago, I wrote the article Choosing the right language model for your NLP use case on Medium. It focussed on the nuts and bolts of LLMs — and while rather popular, by now, I realize it doesn’t actually say much about selecting LLMs. I wrote it at the beginning of my LLM journey and somehow figured that the technical details about LLMs — their inner workings and training history — would speak for themselves, allowing AI product builders to confidently select LLMs for specific scenarios.
Since then, I have integrated LLMs into multiple AI products. This allowed me to discover how exactly the technical makeup of an LLM determines the final experience of a product. It also strengthened the belief that product managers and designers need to have a solid understanding of how an LLM works “under the hood.” LLM interfaces are different from traditional graphical interfaces. The latter provide users with a (hopefully clear) mental model by displaying the functionality of a product in a rather implicit way. On the other hand, LLM interfaces use free text as the main interaction format, offering much more flexibility. At the same time, they also “hide” the capabilities and the limitations of the underlying model, leaving it to the user to explore and discover them. Thus, a simple text field or chat window invites an infinite number of intents and inputs and can display as many different outputs.
The responsibility for the success of these interactions is not (only) on the engineering side — rather, a big part of it should be assumed by whoever manages and designs the product. In this article, we will flesh out the relationship between LLMs and user experience, working with two universal ingredients that you can use to improve the experience of your product:
(Note: These two ingredients are part of any LLM application. Beyond these, most applications will also have a range of more individual criteria to be fulfilled, such as latency, privacy, and safety, which will not be addressed here.)
Thus, in Peter Drucker’s words, it’s about “doing the right things” (functionality) and “doing them right” (quality). Now, as we know, LLMs will never be 100% right. As a builder, you can approximate the ideal experience from two directions:
In this article, we will focus on the engineering part. The design of the ideal partnership with human users will be covered in a future article. First, I will briefly introduce the steps in the engineering process — LLM selection, adaptation, and evaluation — which directly determine the final experience. Then, we will look at the two ingredients — functionality and quality — and provide some guidelines to steer your work with LLMs to optimize the product’s performance along these dimensions.
A note on scope: In this article, we will consider the use of stand-alone LLMs. Many of the principles and guidelines also apply to LLMs used in RAG (Retrieval-Augmented Generation) and agent systems. For a more detailed consideration of the user experience in these extended LLM scenarios, please refer to my book The Art of AI Product Development.
In the following, we will focus on the three steps of LLM selection, adaptation, and evaluation. Let’s consider each of these steps:
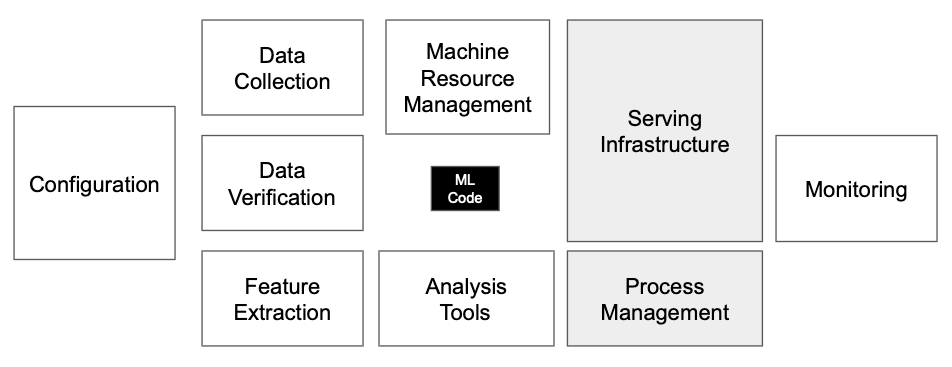
The following figure summarizes the process:
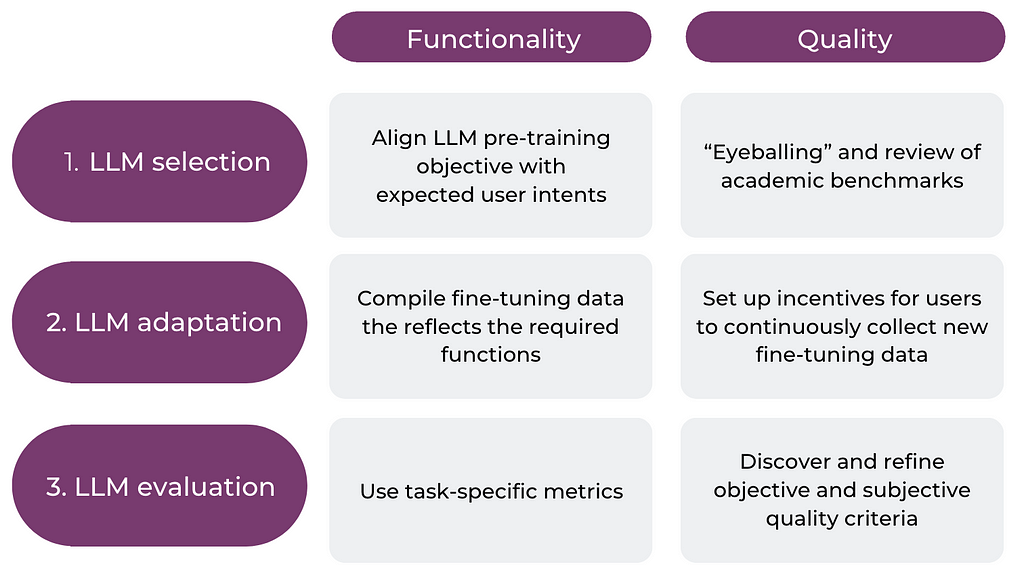
In real life, the three stages will overlap, and there can be back-and-forth between the stages. In general, model selection is more the “one big decision.” Of course, you can shift from one model to another further down the road and even should do this when new, more suitable models appear on the market. However, these changes are expensive since they affect everything downstream. Past the discovery phase, you will not want to make them on a regular basis. On the other hand, LLM adaptation and evaluation are highly iterative. They should be accompanied by continuous discovery activities where you learn more about the behavior of your model and your users. Finally, all three activities should be embedded into a solid LLMOps pipeline, which will allow you to integrate new insights and data with minimal engineering friction.
Now, let’s move to the second column of the chart, scoping the functionality of an LLM and learning how it can be shaped during the three stages of this process.
You might be wondering why we talk about the “functionality” of LLMs. After all, aren’t LLMs those versatile all-rounders that can magically perform any linguistic task we can think of? In fact, they are, as famously described in the paper Language Models Are Few-Shot Learners. LLMs can learn new capabilities from just a couple of examples. Sometimes, their capabilities will even “emerge” out of the blue during normal training and — hopefully — be discovered by chance. This is because the task of language modeling is just as versatile as it is challenging — as a side effect, it equips an LLM with the ability to perform many other related tasks.
Still, the pre-training objective of LLMs is to generate the next word given the context of past words (OK, that’s a simplification — in auto-encoding, the LLM can work in both directions [3]). This is what a pre-trained LLM, motivated by an imaginary “reward,” will insist on doing once it is prompted. In most cases, there is quite a gap between this objective and a user who comes to your product to chat, get answers to questions, or translate a text from German to Italian. The landmark paper Climbing Towards NLU: On Meaning, Form, and Understanding in the Age of Data by Emily Bender and Alexander Koller even argues that language models are generally unable to recover communicative intents and thus are doomed to work with incomplete meaning representations.
Thus, it is one thing to brag about amazing LLM capabilities in scientific research and demonstrate them on highly controlled benchmarks and test scenarios. Rolling out an LLM to an anonymous crowd of users with different AI skills and intents—some harmful—is a different kind of game. This is especially true once you understand that your product inherits not only the capabilities of the LLM but also its weaknesses and risks, and you (not a third-party provider) hold the responsibility for its behavior.
In practice, we have learned that it is best to identify and isolate discrete islands of functionality when integrating LLMs into a product. These functions can largely correspond to the different intents with which your users come to your product. For example, it could be:
Oftentimes, these can be further decomposed into more granular, potentially even reusable, capabilities. “Engaging in conversation” could be decomposed into:
Taking this more discrete approach to LLM capabilities provides you with the following advantages:
Let’s summarize some practical guidelines to make sure that the LLM does the right thing in your product:

These are just short snapshots of the lessons we learned when integrating LLMs. My upcoming book The Art of AI Product Development contains deep dives into each of the guidelines along with numerous examples. For the technical details behind pre-training objectives and procedures, you can refer to this article.
Ok, so you have gained an understanding of the intents with which your users come to your product and “motivated” your model to respond to these intents. You might even have put out the LLM into the world in the hope that it will kick off the data flywheel. Now, if you want to keep your good-willed users and acquire new users, you need to quickly ramp up on our second ingredient, namely quality.
In the context of LLMs, quality can be decomposed into an objective and a subjective component. The objective component tells you when and why things go wrong (i.e., the LLM makes explicit mistakes). The subjective component is more subtle and emotional, reflecting the alignment with your specific user crowd.
Using language to communicate comes naturally to humans. Language is ingrained in our minds from the beginning of our lives, and we have a hard time imagining how much effort it takes to learn it from scratch. Even the challenges we experience when learning a foreign language can’t compare to the training of an LLM. The LLM starts from a blank slate, while our learning process builds on an incredibly rich basis of existing knowledge about the world and about how language works in general.
When working with an LLM, we should constantly remain aware of the many ways in which things can go wrong:
These shortcomings can quickly turn into showstoppers for your product — output quality is a central determinant of the user experience of an LLM product. For example, one of the major determinants of the “public” success of ChatGPT was that it was indeed able to generate correct, fluent, and relatively coherent text across a large variety of domains. Earlier generations of LLMs were not able to achieve this objective quality. Most pre-trained LLMs that are used in production today do have the capability to generate language. However, their performance on criteria like coherence, consistency, and world knowledge can be very variable and inconsistent. To achieve the experience you are aiming for, it is important to have these requirements clearly prioritized and select and adapt LLMs accordingly.
Venturing into the more nuanced subjective domain, you want to understand and monitor how users feel around your product. Do they feel good and trustful and get into a state of flow when they use it? Or do they go away with feelings of frustration, inefficiency, and misalignment? A lot of this hinges on individual nuances of culture, values, and style. If you are building a copilot for junior developers, you hardly want it to speak the language of senior executives and vice versa.
For the sake of example, imagine you are a product marketer. You have spent a lot of your time with a fellow engineer to iterate on an LLM that helps you with content generation. At some point, you find yourself chatting with the UX designer on your team and bragging about your new AI assistant. Your colleague doesn’t get the need for so much effort. He is regularly using ChatGPT to assist with the creation and evaluation of UX surveys and is very satisfied with the results. You counter — ChatGPT’s outputs are too generic and monotonous for your storytelling and writing tasks. In fact, you have been using it at the beginning and got quite embarrassed because, at some point, your readersstarted to recognize the characteristic ChatGPT flavor. That was a slippery episode in your career, after which you decided you needed something more sophisticated.
There is no right or wrong in this discussion. ChatGPT is good for straightforward factual tasks where style doesn’t matter that much. By contrast, you as a marketer need an assistant that can assist in crafting high-quality, persuasive communications that speak the language of your customers and reflect the unique DNA of your company.
These subjective nuances can ultimately define the difference between an LLM that is useless because its outputs need to be rewritten anyway and one that is “good enough” so users start using it and feed it with suitable fine-tuning data. The holy grail of LLM mastery is personalization — i.e., using efficient fine-tuning or prompt tuning to adapt the LLM to the individual preferences of any user who has spent a certain amount of time with the model. If you are just starting out on your LLM journey, these details might seem far off — but in the end, they can help you reach a level where your LLM delights users by responding in the exact manner and style that is desired, spurring user satisfaction and large-scale adoption and leaving your competition behind.
Here are our tips for managing the quality of your LLM:
Pre-trained LLMs are highly convenient — they make AI accessible to everyone, offloading the huge engineering, computation, and infrastructure spending needed to train a huge initial model. Once published, they are ready to use, and we can plug their amazing capabilities into our product. However, when using a third-party model in your product, you inherit not only its power but also the many ways in which it can and will fail. When things go wrong, the last thing you want to do to maintain integrity is to blame an external model provider, your engineers, or — worse — your users.
Thus, when building with LLMs, you should not only look for transparency into the model’s origins (training data and process) but also build a causal understanding of how its technical makeup shapes the experience offered by your product. This will allow you to find the sensitive balance between kicking off a robust data flywheel at the beginning of your journey and continuously optimizing and differentiating the LLM as your product matures toward excellence.
[1] Janna Lipenkova (2022). Choosing the right language model for your NLP use case, Medium.
[2] Tom B. Brown et al. (2020). Language Models are Few-Shot Learners.
[3] Jacob Devlin et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
[4] Emily M. Bender and Alexander Koller (2020). Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data.
[5] Janna Lipenkova (upcoming). The Art of AI Product Development, Manning Publications.
Note: All images are by the author, except when noted otherwise.
Designing the relationship between LLMs and user experience was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Designing the relationship between LLMs and user experience
Go Here to Read this Fast! Designing the relationship between LLMs and user experience
Disease prediction from speech can be the next revolution in healthcare
Originally appeared here:
AI’s Emerging Role in Disease Detection from Human Speech
Go Here to Read this Fast! AI’s Emerging Role in Disease Detection from Human Speech
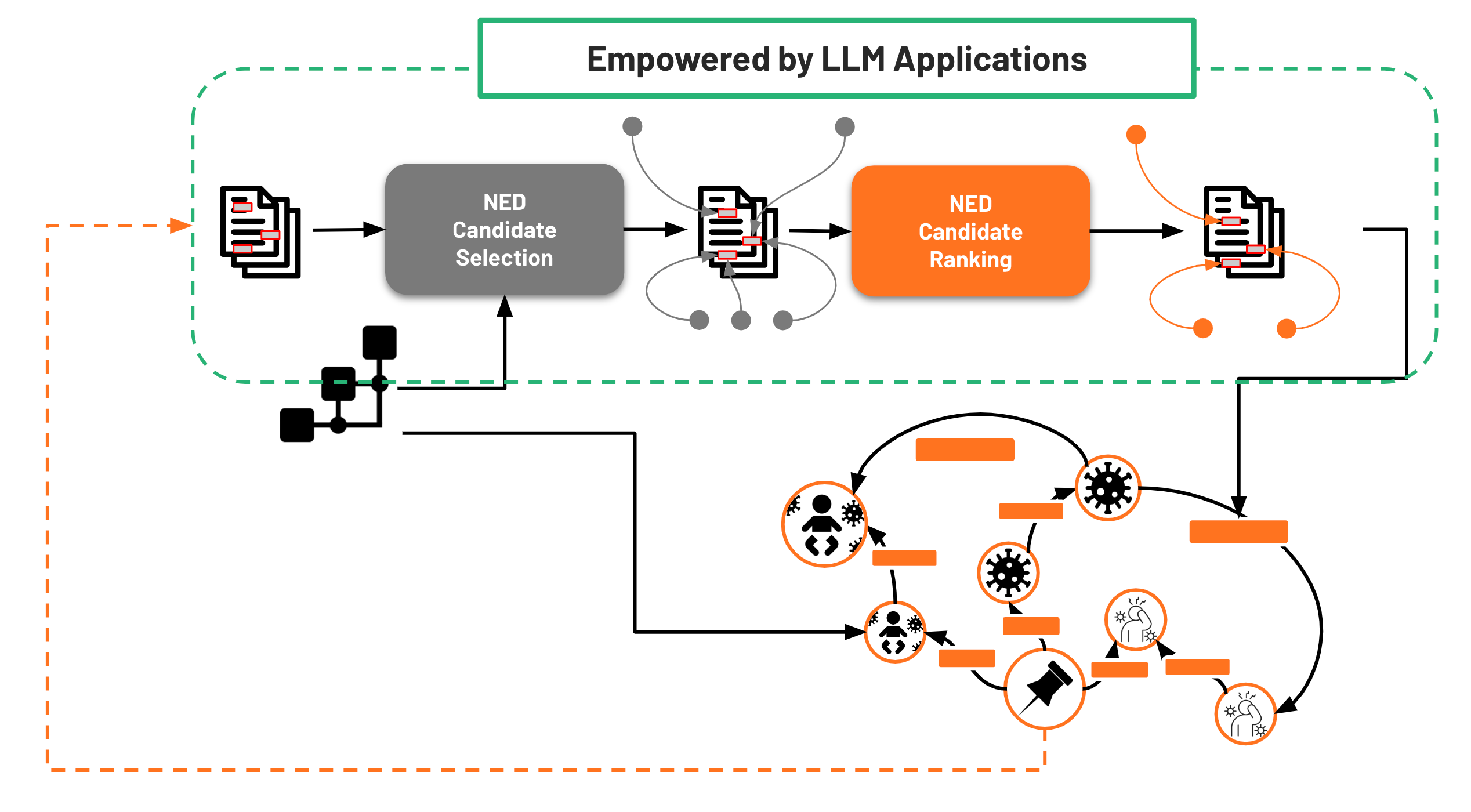
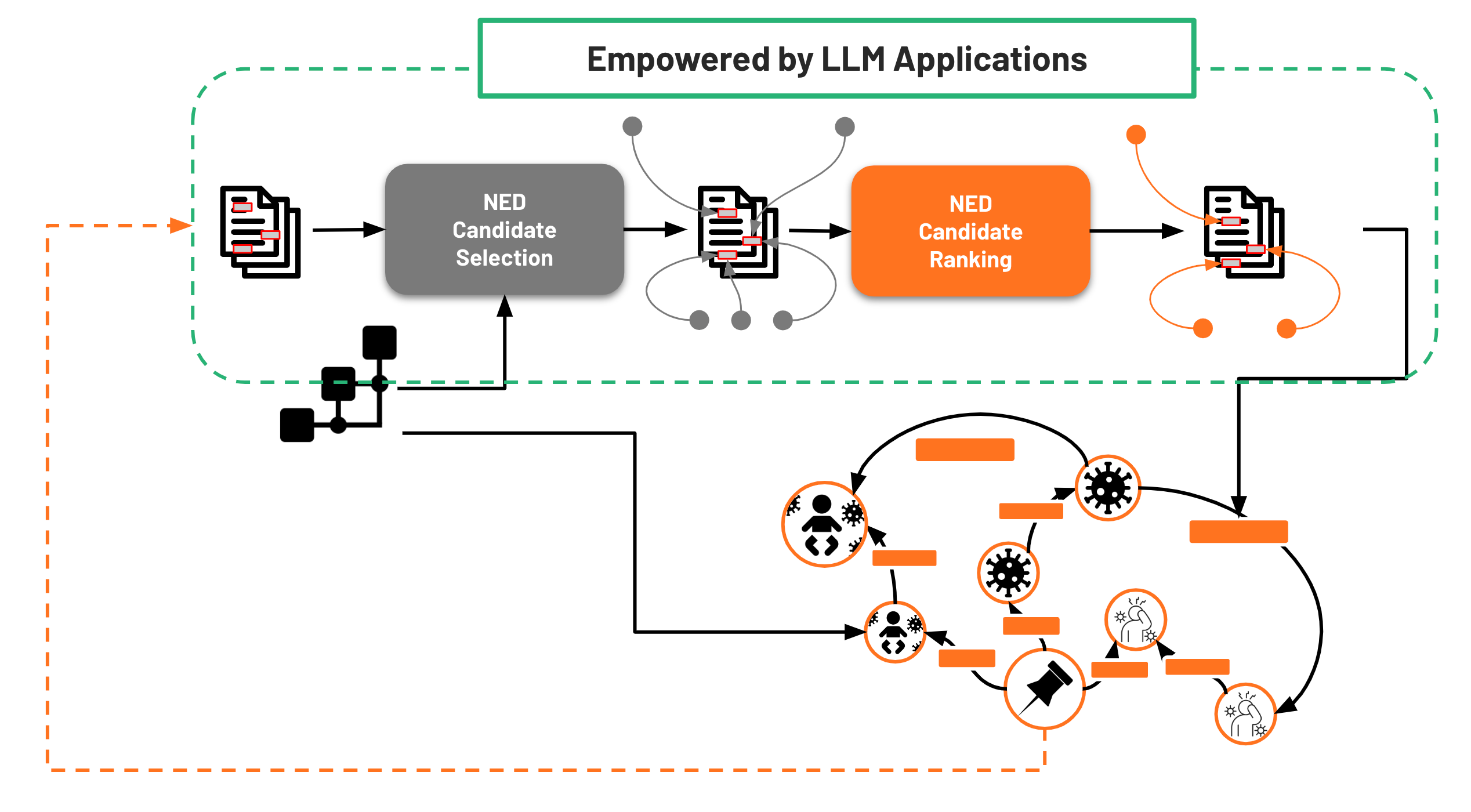
A perspective for combining LLMs, Ontologies, and Knowledge Graphs in the Biomedical Domain
Originally appeared here:
Leveraging AI Synergies for Named Entity Disambiguation
Go Here to Read this Fast! Leveraging AI Synergies for Named Entity Disambiguation


Discover how Test-Driven Development (TDD) transforms ML project outcomes. This article unveils why TDD is beneficial and easy to…
Originally appeared here:
Making the Case for Test-Driven Development in Machine Learning
Go Here to Read this Fast! Making the Case for Test-Driven Development in Machine Learning


Originally appeared here:
Integrate HyperPod clusters with Active Directory for seamless multi-user login

Originally appeared here:
OpenAI’s new Sora video is an FPV drone ride through the strangest TED Talk you’ve ever seen – and I need to lie down


Do you have customers coming to you first with a data incident? Are your customers building their own data solutions due to un-trusted data? Does your data team spend unnecessarily long hours remediating undetected data quality issues instead of prioritising strategic work?
Data teams need to be able to paint a complete picture of their data systems health in order to gain trust with their stakeholders and have better conversations with the business as a whole.
We can combine data quality dimensions with Google’s Site Reliability Engineering principles to measure the health of our Data Systems. To do this, assess a few Data Quality Dimensions that makes sense for your data pipelines and come up with service level objectives (SLOs).
The service level terminology we will use in this article are service level indicators and service level objectives. The two are borrowed principles from Google’s SRE book.
service level indicator — a carefully defined quantitative measure of some aspect of the level of service that is provided.
The indicators we’re familiar with in the software world are throughput, latency and up time (availability). These are used to measure the reliability of an application or website.

The indicators are then turned into objectives bounded by a threshold. The health of the software application is now “measurable” in a sense that we can now communicate the state of our application with our customers.
service level objective: a target value or range of values for a service level that is measured by an SLI.
We have an intuitive understanding of the necessity of these quantitative measures and indicators in a typical user applications to reduce friction and establish trust with our customers. We need to start adopting a similar mindset when building out data pipelines in the data world.
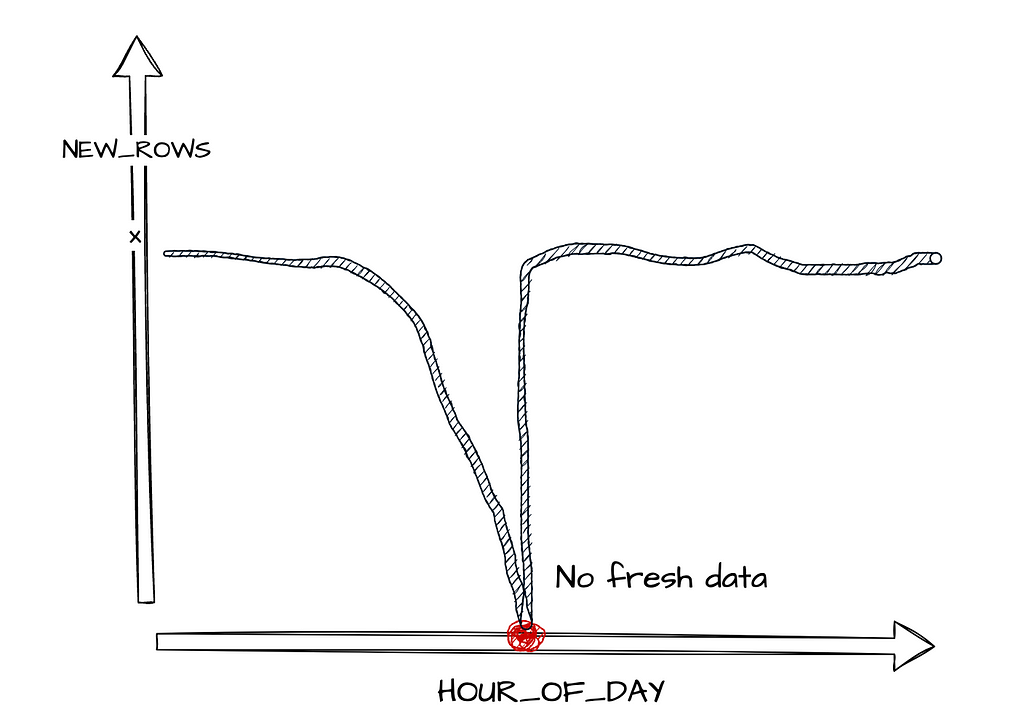
Lets say the user interacts with our application and generates X amounts of data every hour into our data warehouse, if the number of rows entering the warehouse suddenly decreases drastically, we can flag it as an issue. Then trace our timestamps from our pipelines to diagnose and treat the problem.
We want to capture enough information about the data coming into our systems so that we can detect when anomalies occur. Most data teams tend to start with Data Timeliness. Is the expected amount of data arriving at the right time?
This can be decomposed into the indicators:

Once the system is stable it is important to maintain a good relationship with your customers in order to set the right objectives that are valuable to your stakeholders.
How do we actually figure out how much data to expect and when? What is the right amount of data for all our different datasets? This is when we need to focus on the threshold concept as it does get tricky.
Assume we have an application where users mainly login to the system during the working hours. We expect around 2,000 USER_LOGIN events per hour between 9am to 5pm, and 100 events outside of those hours. If we use a single threshold value for the whole day, it would lead to the wrong conclusion. Receiving 120 events at 8pm is perfectly reasonable, but it would be concerning and should be investigated further if we only received 120 events at 2pm.
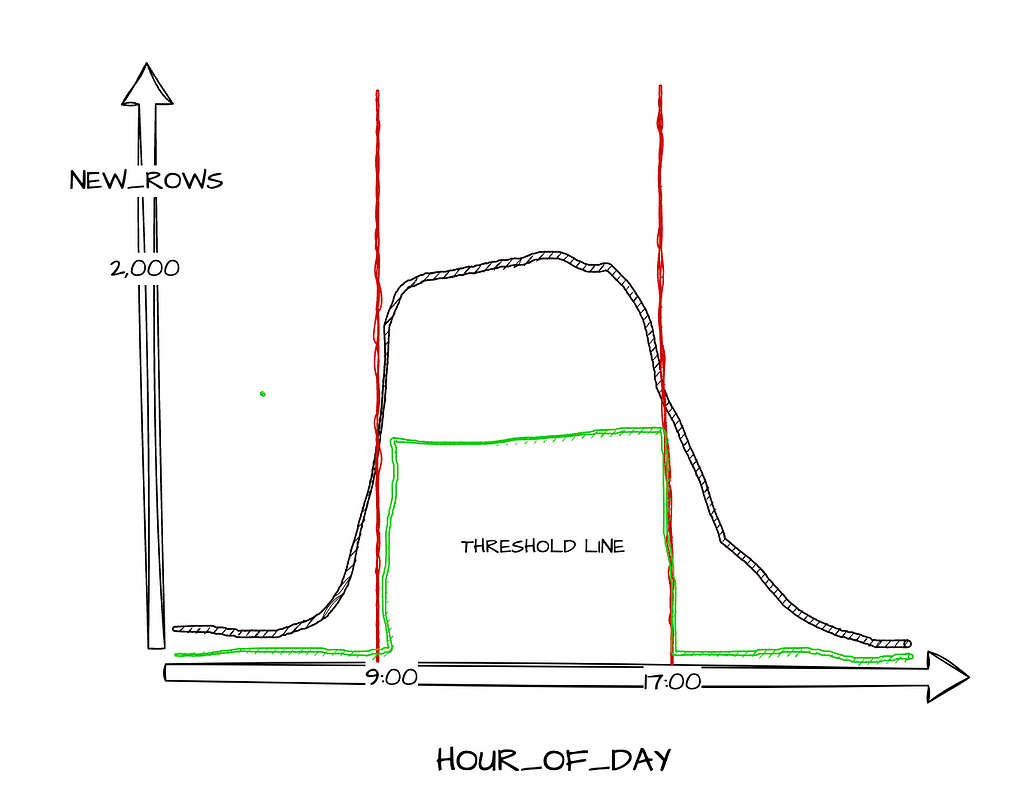
Because of this, we need to calculate a different expected value for each hour of the day for each different dataset — this is the threshold value. A metadata table would need to be defined that dynamically fetches the number of rows arrived each hour in order to get a resulting threshold that makes sense for each data source.
There are some thresholds which can be extracted using timestamps as a proxy as explained above. This can be done using statistical measures such as averages, standard deviations or percentiles to iterate over your metadata table.
Depending on how creative you want to be, you can even introduce machine learning in this part of the process to help you set the threshold. Other thresholds or expectations would need to be discussed with your stakeholders as it would stem from having specific knowledge of the business to know what to expect.
The very first step to getting started is picking a few business critical dataset to build on top of before implementing a data-ops solution at scale. This is the easiest way to gather momentum and feel the impact of your data observability efforts.
Many analytical warehouses already have inbuilt functionalities around this. For example, Snowflake has recently pushed out Data Metric Functions in preview for Enterprise accounts to help data teams get started quickly.
Data Metrics Functions is a wrapper around some of the queries we might write to get insights into our data systems. We can start with the system DMFs.

We first need to sort out a few privileges…
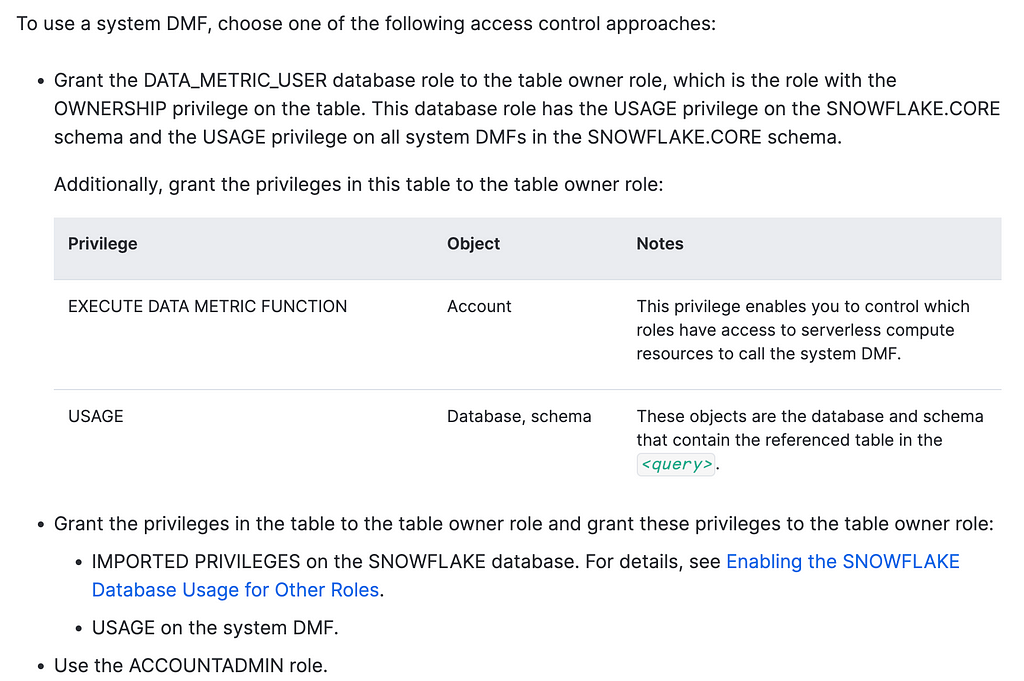
USE ROLE ACCOUNTADMIN;
GRANT database role DATA_METRIC_USER TO role jess_zhang;
GRANT EXECUTE data metric FUNCTION ON account TO role jess_zhang;
## Useful queries once the above succeeds
SHOW DATA METRIC FUNCTIONS IN ACCOUNT;
DESC FUNCTION snowflake.core.NULL_COUNT(TABLE(VARCHAR));
DATA_METRIC_USER is a database role which may catch a few people out. It’s important to revisit the docs if you’re running into issues. The most likely reason is probably due to permissions.
Then, simply choose a DMF …
-- Uniqueness
SELECT SNOWFLAKE.CORE.NULL_COUNT(
SELECT customer_id
FROM jzhang_test.product.fct_subscriptions
);
-- Freshness
SELECT SNOWFLAKE.CORE.FRESHNESS(
SELECT
_loaded_at_utc
FROM jzhang_test.product.fct_subscriptions
) < 60;
-- replace 60 with your calculated threshold value
You can schedule your DMFs to run using Data Metric Schedule — an object parameter or your usual orchestration tool. The hard-work would still need to be done to determine your own thresholds in order to set the right SLOs for your pipelines.
Data teams need to engage with stakeholders to set better expectations about the data by using service level indicators and objectives. Introducing these metrics will help data teams move from reactively firefighting to a more proactive approach in preventing data incidents. This would allow energy to be refocused towards delivering business value as well as building a trusted data platform.
Unless otherwise noted, all images are by the author.
Monitor Data Pipelines Using Snowflake’s Data Metric Functions was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Monitor Data Pipelines Using Snowflake’s Data Metric Functions
Go Here to Read this Fast! Monitor Data Pipelines Using Snowflake’s Data Metric Functions