Apple has scheduled its next product showcase for May 7, a few weeks before the Worldwide Developers Conference gets under way. While the company is, as usual, being a bit coy about what’s on deck, the signs are all there. It had been rumored for months that Apple would refresh its iPad lineup in May. Sure enough, the image on the announcement for this “Let Loose” event includes an illustration of a hand holding an Apple Pencil.
Various reports over recent months have offered some insight as to what Apple has up its sleeves. So, with that in mind, here’s what to expect from the upcoming iPad event:
M3 iPad Pro
Nathan Ingraham / Engadget
It’s been about 18 months since Apple updated any of its iPads, so its tablet lineup is due for a refresh. It won’t exactly come as a surprise to see Apple slot M3 chips into the latest iPad Pro models, since the most recent versions run on M2 chipsets.
Otherwise, the biggest update is expected to come in the form of OLED displays, according to Bloomberg’s Mark Gurman. That should bring richer colors and deeper blacks to the iPad Pro.
Since OLED panels are thinner than LCD panels, that should allow Apple to reduce the thickness of the iPad Pro. According to 9to5 Mac, the 11-inch iPad Pro will be 0.8 mm thinner at 5.1 mm, while the 12.9-inch model will be more noticeably slender, as the thickness is expected to drop by 1.5 mm to 5 mm. A leaker has suggested that the bezels could be up to 15 percent thinner than previous models as well.
Rumors have been swirling for a while that Apple may offer a glass-backed iPad Pro this year to enable MagSafe charging. Meanwhile, there have been hints that Apple will solve one of our biggest iPad bugbears and move the front-facing camera to the landscape edge of the Pro, as it did with the entry-level iPad in late 2022. That means the camera will be more optimally placed for those who use a Magic Keyboard or folks who simply prefer a landscape orientation.
M2 iPad Air
Nathan Ingraham / Engadget
As for the iPad Air, which Apple has left in stasis for over two years, that’s expected to get an upgrade to M2 chips from the M1 that the tablets currently use. There are rumblings that Apple will go with the older chip in the iPad Air to differentiate it from Pro models and ensure that the latter devices clearly remain its highest-end tablets. Reports suggest that the iPad Air’s front-facing camera is also blessedly moving to the landscape edge.
There is one other big change we’re expecting for the iPad Air, and I mean that in the most literal sense. Apple is rumored to be prepping the first 12.9-inch iPad Air. It’s likely to be the least expensive option for a large-screen iPad, even though that would run somewhat against the “Air” part of the name.
Display analyst Ross Young previously suggested that the 12.9-inch iPad Air screen would have a mini-LED display, but that no longer appears to be happening — at least for now. However, Young says that Apple may release an iPad Air with such a display later this year. Meanwhile, the new iPad Air models may have a larger camera bump, perhaps so Apple can add a flash.
New Magic Keyboard and Apple Pencil
Engadget
Gurman reported last year that Apple was working on a revamped Magic Keyboard, but only for the iPad Pro, not the Air lineup. The updated keyboard is said to make the iPad Pro look more like a laptop, with a larger trackpad. It’s said to be made of aluminum to make it sturdier than previous models, though “the exterior shell of the Magic Keyboard will retain the cover material of the current model,” Gurman says.
In addition, Apple is expected to unveil a new Apple Pencil to replace the second-gen model. Dataminers have suggested that an updated peripheral could include a squeeze gesture to carry out certain actions and have Find My support. Some reports have indicated the next Apple Pencil could work with Vision Pro drawing apps too.
What not to expect: A new iPad or iPad mini
Even though the iPad mini in particular is getting very long in the tooth — the most recent model arrived in September 2021 — you probably shouldn’t expect a new model to show up at the Let Loose event. Not are we expecting to see a new base iPad. Reportssuggest an 11th-gen iPad and an updated iPad mini may arrive later this year, but maybe don’t hold your breath for them.
This article originally appeared on Engadget at https://www.engadget.com/apple-is-launching-new-ipads-may-7-heres-what-to-expect-from-the-let-loose-event-210041117.html?src=rss
NVIDIA’s AI can intelligently combine a variety of data from games in DLSS 3.5 and Ray Reconstruction to present more accurate detail at higher resolutions while improving performance.
Advertorial Disclosure: Advertiser Content From NVIDIA
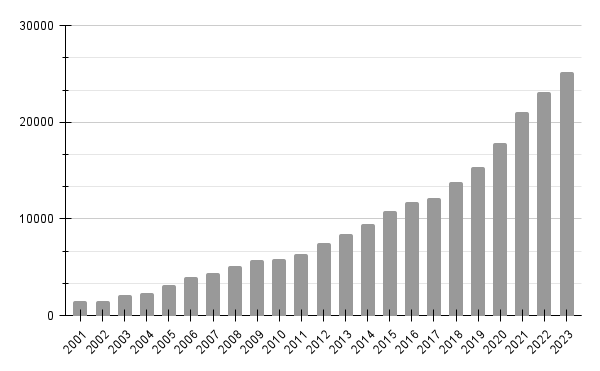
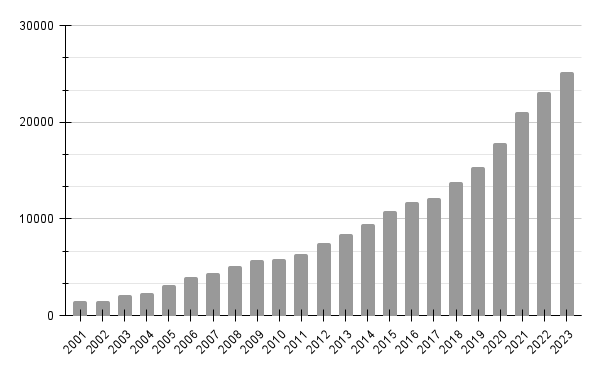
Choosing between frequentist and Bayesian approaches is the great debate of the last century, with a recent surge in Bayesian adoption in the sciences.
Number of articles referring Bayesian statistics in sciencedirect.com (April 2024) — Graph by the author
What’s the difference?
The philosophical difference is actually quite subtle, where some propose that the great bayesian critic, Fisher, was himself a bayesian in some regard. While there are countless articles that delve into formulaic differences, what are the practical benefits? What does Bayesian analysis offer to the lay data scientist that the vast plethora of highly-adopted frequentist methods do not already? This article aims to give a practical introduction to the motivation, formulation, and application of Bayesian methods. Let’s dive in.
Prior Beliefs
While frequentists deal with describing the exact distributions of any data, the bayesian viewpoint is more subjective. Subjectivity and statistics?! Yes, it’s actually compatible.
Let’s start with something simple, like a coin flip. Suppose you flip a coin 10 times, and get heads 7 times. What is the probability of heads?
P(heads) = 7/10 (0.7)?
Obviously, here we are riddled with low sample size. In a Bayesian POV however, we are allowed to encode our beliefs directly, asserting that if the coin is fair, the chance of heads or tails must be equal i.e. 1/2. While in this example the choice seems pretty obvious, the debate is more nuanced when we get to more complex, less obvious phenomenon.
Yet, this simple example is a powerful starting point, highlighting both the greatest benefit and shortcoming of Bayesian analysis:
Benefit: Dealing with a lack of data. Suppose you are modeling spread of an infection in a country where data collection is scarce. Will you use the low amount of data to derive all your insights? Or would you want to factor-in commonly seen patterns from similar countries into your model i.e. informed prior beliefs. Although the choice is clear, it leads directly to the shortcoming.
Shortcoming: the prior belief is hard to formulate. For example, if the coin is not actually fair, it would be wrong to assume that P (heads) = 0.5, and there is almost no way to find true P (heads) without a long run experiment. In this case, assuming P (heads) = 0.5 would actually be detrimental to finding the truth. Yet every statistical model (frequentist or Bayesian) must make assumptions at some level, and the ‘statistical inferences’ in the human mind are actually a lot like bayesian inference i.e. constructing prior belief systems that factor into our decisions in every new situation. Additionally, formulating wrong prior beliefs is often not a death sentence from a modeling perspective either, if we can learn from enough data (more on this in later articles).
Bayes’ Rule
So what does all this look like mathematically? Bayes’ rule lays the groundwork. Let’s suppose we have a parameter θ that defines some model which could describe our data (eg. θ could represent the mean, variance, slope w.r.t covariate, etc.). Bayes’ rule states that
P (θ = t|data) represents the conditional probability that θ is equal to t, given our data (a.k.a the posterior).
Conversely, P (data|θ) represents the probability of observing our data, if θ = t (a.k.a the ‘likelihood’).
Finally, P (θ=t) is simply the probability that θ takes the value t (the infamous ‘prior’).
So what’s this mysterious t? It can take many possible values, depending on what θ means. In fact, you want to try a lot of values, and check the likelihood of your data for each. This is a key step, and you really really hope that you checked the best possible values for θ i.e. those which cover the maximum likelihood area of seeing your data (global minima, for those who care).
And that’s the crux of everything Bayesian inference does!
Form a prior belief for possible values of θ,
Scale it with the likelihood at each θ value, given the observed data, and
Return the computed result i.e. the posterior, which tells you the probability of each tested θ value.
Graphically, this looks something like:
Prior (left) scaled with the likelihood (middle) forms the posterior (right) (figures adapted from Andrew Gelmans Book). Here, θ encodes the east-west location coordinate of a plane. The prior belief is that the plane is more towards the east than west. The data challenges the prior and the posterior thus lies somehwere in the middle. [image using data generated by author]
Which highlights the next big advantages of Bayesian stats-
We have an idea of the entire shape of θ’s distribution (eg, how wide is the peak, how heavy are the tails, etc.) which can enable more robust inferences. Why? Simply because we can not only better understand but also quantify the uncertainty (as compared to a traditional point estimate with standard deviation).
Since the process is iterative, we can constantly update our beliefs (estimates) as more data flows into our model, making it much easier to build fully online models.
Easy enough! But not quite…
This process involves a lot of computations, where you have to calculate the likelihood for each possible value of θ. Okay, maybe this is easy if suppose θ lies in a small range like [0,1]. We can just use the brute-force grid method, testing values at discrete intervals (10, 0.1 intervals or 100, 0.01 intervals, or more… you get the idea) to map the entire space with the desired resolution.
But what if the space is huge, and god forbid additional parameters are involved, like in any real-life modeling scenario?
Now we have to test not only the possible parameter values but also all their possible combinations i.e. the solution space expands exponentially, rendering a grid search computationally infeasible. Luckily, physicists have worked on the problem of efficient sampling, and advanced algorithms exist today (eg. Metropolis-Hastings MCMC, Variational Inference) that are able to quickly explore high dimensional spaces of parameters and find convex points. You don’t have to code these complex algorithms yourself either, probabilistic computing languages like PyMC or STAN make the process highly streamlined and intuitive.
STAN
STAN is my favorite as it allows interfacing with more common data science languages like Python, R, Julia, MATLAB etc. aiding adoption. STAN relies on state-of-the-art Hamiltonian Monte Carlo sampling techniques that virtually guarantee reasonably-timed convergence for well specified models. In my next article, I will cover how to get started with STAN for simple as well as not-no-simple regression models, with a full python code walkthrough. I will also cover the full Bayesian modeling workflow, which involves model specification, fitting, visualization, comparison, and interpretation.
Amidst generative AI copyright chaos, Apple looks like it’s leading with ethical training methods, navigating legal hurdles to forge a path of compliance and innovation.
The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey
Image by Author
My team and I (Sandi Besen, Tula Masterman, Mason Sawtell, and Alex Chao) recently published a survey research paper that offers a comprehensive look at the current state of AI agent architectures. As co-authors of this work, we set out to uncover the key design elements that enable these autonomous systems to effectively execute complex goals.
This paper serves as a resource for researchers, developers, and anyone interested in staying updated on the cutting-edge progress in the field of AI agent technologies.
Since the launch of ChatGPT, the initial wave of generative AI applications has largely revolved around chatbots that utilize the Retrieval Augmented Generation (RAG) pattern to respond to user prompts. While there is ongoing work to enhance the robustness of these RAG-based systems, the research community is now exploring the next generation of AI applications — a common theme being the development of autonomous AI agents.
Agentic systems incorporate advanced capabilities like planning, iteration, and reflection, which leverage the model’s inherent reasoning abilities to accomplish tasks end-to-end. Paired with the ability to use tools, plugins, and function calls — agents are empowered to tackle a wider range of general-purpose work.
The Importance of Reasoning, Planning, and Effective Tool Calling for Agents
Reasoning is a foundational building block of the human mind. Without reasoning one would not be able to make decisions, solve problems, or refine plans when new information is learned — essentially misunderstanding the world around us. If agents don’t have strong reasoning skills then they might misunderstand their task, generate nonsensical answers, or fail to consider multi-step implications.
We find that most agent implementations contain a planning phase which invokes one of the following techniques to create a plan: task decomposition, multi-plan selection, external module-aided planning, reflection and refinement and memory-augmented planning [1].
Another benefit of utilizing an agent implementation over just a base language model is the agent’s ability to solve complex problems by calling tools. Tools can enable an agent to execute actions such as interacting with APIs, writing to third party applications, and more. Reasoning and tool calling are closely intertwined and effective tool calling has a dependency on adequate reasoning. Put simply, you can’t expect an agent with poor reasoning abilities to understand when is the appropriate time to call its tools.
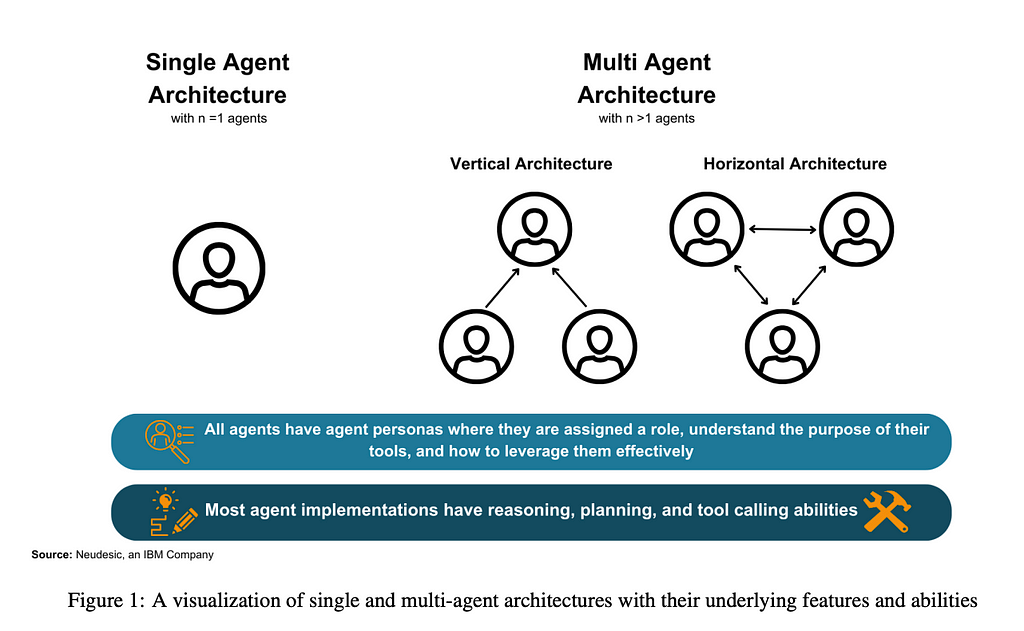
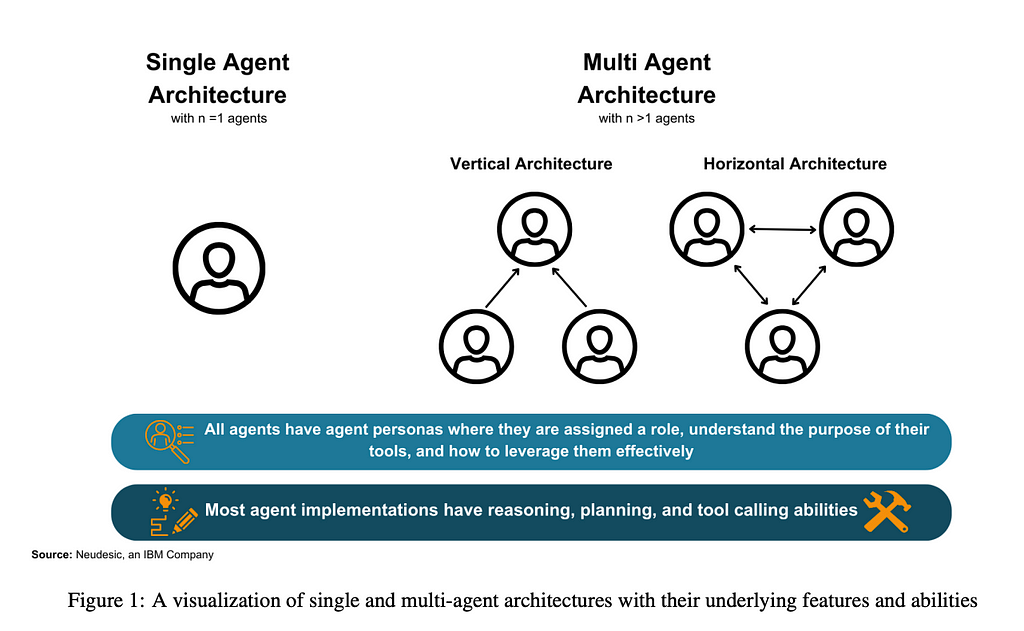
Single vs Multi Agent Architecture
Our findings emphasize that both single-agent and multi-agent architectures can be used to solve challenging tasks by employing reasoning and tool calling steps.
For single agent implementations, we find that successful goal execution is contingent upon proper planning and self-correction [1, 2, 3, 4]. Without the ability to self-evaluate and create effective plans, single agents may get stuck in an endless execution loop and never accomplish a given task or return a result that does not meet user expectations [2]. We find that single agent architectures are especially useful when the task requires straightforward function calling and does not need feedback from another agent.
However, we note that single agent patterns often struggle to complete a long sequence of sub tasks or tool calls [5, 6]. Multi-agent patterns can address the issues of parallel tasks and robustness since multiple agents within the architecture can work on individual subproblems. Many multi-agent patterns start by taking a complex problem and breaking it down into several smaller tasks. Then, each agent works independently on solving each task using their own independent set of tools.
Architectures involving multiple agents present an opportunity for intelligent labor division based on capabilities as well as valuable feedback from diverse agent personas. Numerous multi-agent architectures operate in stages where teams of agents are dynamically formed and reorganized for each planning, execution, and evaluation phase [7, 8, 9]. This reorganization yields superior outcomes because specialized agents are utilized for specific tasks and removed when no longer required. By matching agent roles and skills to the task at hand, agent teams can achieve greater accuracy and reduce the time needed to accomplish the goal. Crucial features of effective multi-agent architectures include clear leadership within agent teams, dynamic team construction, and efficient information sharing among team members to prevent important information from getting lost amidst superfluous communication.
Our research highlights notable single agent methods such as ReAct, RAISE, Reflexion, AutoGPT + P, LATS, and multi agent implementations such as DyLAN, AgentVerse, and MetaGPT, which are explained more in depth in the full text.
Our Key Findings
Single Agent Patterns:
Single agent patterns are generally best suited for tasks with a narrowly defined list of tools and where processes are well-defined. They don’t face poor feedback from other agents or distracting and unrelated chatter from other team members. However, single agents may get stuck in an execution loop and fail to make progress towards their goal if their reasoning and refinement capabilities aren’t robust.
Multi Agent Patterns:
Multi agent patterns are well-suited for tasks where feedback from multiple personas is beneficial in accomplishing the task. They are useful when parallelization across distinct tasks or workflows is required, allowing individual agents to proceed with their next steps without being hindered by the state of tasks handled by others.
Feedback and Human in the Loop
Language models tend to commit to an answer earlier in their response, which can cause a ‘snowball effect’ of increasing diversion from their goal state [10]. By implementing feedback, agents are much more likely to correct their course and reach their goal. Human oversight improves the immediate outcome by aligning the agent’s responses more closely with human expectations, yielding more reliable and trustworthy results [11, 8]. Agents can be susceptible to feedback from other agents, even if the feedback is not sound. This can lead the agent team to generate a faulty plan which diverts them from their objective [12].
Information Sharing and Communication
Multi-agent patterns have a greater tendency to get caught up in niceties and ask one another things like “how are you”, while single agent patterns tend to stay focused on the task at hand since there is no team dynamic to manage. This can be mitigated by robust prompting. In vertical architectures, agents can fail to send critical information to their supporting agents not realizing the other agents aren’t privy to necessary information to complete their task. This failure can lead to confusion in the team or hallucination in the results. One approach to address this issue is to explicitly include information about access rights in the system prompt so that the agents have contextually appropriate interactions.
Impact of Role Definition and Dynamic Teams
Clear role definition is critical for both single and multi-agent architectures. Role definition ensures that the agents understands their assigned role, stay focused on the provided task, execute the proper tools, and minimizes hallucination of other capabilities. Establishing a clear group leader improves the overall performance of multi-agent teams by streamlining task assignment. Dynamic teams where agents are brought in and out of the system based on need have also been shown to be effective. This ensures that all agents participating in the tasks are strong contributors.
Summary of Key Insights
The key insights discussed suggest that the best agent architecture varies based on use case. Regardless of the architecture selected, the best performing agent systems tend to incorporate at least one of the following approaches: well defined system prompts, clear leadership and task division, dedicated reasoning / planning- execution — evaluation phases, dynamic team structures, human or agentic feedback, and intelligent message filtering. Architectures that leverage these techniques are more effective across a variety of benchmarks and problem types.
Conclusion
Our meta-analysis aims to provide a holistic understanding of the current AI agent landscape and offer insight for those building with existing agent architectures or developing custom agent architectures. There are notable limitations and areas for future improvement in the design and development of autonomous AI agents such as a lack of comprehensive agent benchmarks, real world applicability, and the mitigation of harmful language model biases. These areas will need to be addressed in the near-term to enable reliable agents.
Note: The opinions expressed both in this article and paper are solely those of the authors and do not necessarily reflect the views or policies of their respective employers.
If you still have questions or think that something needs to be further clarified? Drop me a DM on Linkedin! I‘m always eager to engage in food for thought and iterate on my work.
References
[1] Timo Birr et al. AutoGPT+P: Affordance-based Task Planning with Large Language Models. arXiv:2402.10778 [cs] version: 1. Feb. 2024. URL: http://arxiv.org/abs/2402.10778.
[2] Shunyu Yao et al. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629 [cs]. Mar. 2023. URL: http://arxiv.org/abs/2210.03629.
[3] Na Liu et al. From LLM to Conversational Agent: A Memory Enhanced Architecture with Fine-Tuning of Large Language Models. arXiv:2401.02777 [cs]. Jan. 2024. URL: http://arxiv.org/abs/2401.02777.
[4] Noah Shinn et al. Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv:2303.11366 [cs]. Oct. 2023. URL: http://arxiv.org/abs/2303.11366.
[5]Zhengliang Shi et al. Learning to Use Tools via Cooperative and Interactive Agents. arXiv:2403.03031 [cs]. Mar. 2024. URL: http://arxiv.org/abs/2403.03031.
[6] Silin Gao et al. Efficient Tool Use with Chain-of-Abstraction Reasoning. arXiv:2401.17464 [cs]. Feb. 2024. URL: http://arxiv.org/abs/2401.17464
[7] Weize Chen et al. AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors. arXiv:2308.10848 [cs]. Oct. 2023. URL: http://arxiv.org/abs/2308.10848.
[8] Xudong Guo et al. Embodied LLM Agents Learn to Cooperate in Organized Teams. 2024. arXiv: 2403.12482 [cs.AI].
[9] Zijun Liu et al. Dynamic LLM-Agent Network: An LLM-agent Collaboration Framework with Agent Team Optimization. 2023. arXiv: 2310.02170 [cs.CL].
[10] Muru Zhang et al. How Language Model Hallucinations Can Snowball. arXiv:2305.13534 [cs]. May 2023. URL: http://arxiv.org/abs/2305.13534.
[11] Xueyang Feng et al. Large Language Model-based Human-Agent Collaboration for Complex Task Solving. 2024. arXiv: 2402.12914 [cs.CL].
[12] Weize Chen et al. AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors. arXiv:2308.10848 [cs]. Oct. 2023. URL: http://arxiv.org/abs/2308.10848.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.





{kind=link}