A Guide to Hubert et al.’s Robust PCA Procedure (ROBPCA)
Principal components analysis is a variance decomposition technique that is frequently used for dimensionality reduction. A thorough guide to PCA is available here. In essence, each principal component is computed by finding the linear combination of the original features which has maximal variance, subject to the constraint that it must be orthogonal to the previous principal components. This process tends to be sensitive to outliers as it does not differentiate between meaningful variation and variance due to noise. The top principal components, which represent the directions of maximum variance, are especially susceptible.
In this article, I will discuss ROBPCA, a robust alternative to classical PCA which is less sensitive to extreme values. I will explain the steps of the ROBPCA procedure, discuss how to implement it with the R package ROSPCA, and illustrate its use on the wine quality dataset from the UCI Machine Learning Repository. To conclude, I will consider some limitations of ROBPCA and discuss an alternative robust PCA algorithm which is noteworthy but not well-suited for this particular dataset.
ROBPCA Procedure:
The paper which proposed ROBPCA was published in 2005 by Belgian statistician Mia Hubert and colleagues. It has garnered thousands of citations, including hundreds within the past couple of years, but the procedure is not often covered in data science courses and tutorials. Below, I’ve described the steps of the algorithm:
I) Center the data using the usual estimator of the mean, and perform a singular value decomposition (SVD). This step is particularly helpful when p>n or the covariance matrix is low-rank. The new data matrix is taken to be UD, where U is an orthogonal matrix whose columns are the left singular vectors of the data matrix, and D is the diagonal matrix of singular values.
II) Identify a subset of h_0 ‘least outlying’ data points, drawing on ideas from projection pursuit, and use these core data points to determine how many robust principal components to retain. This can be broken down into three sub-steps:
a) Project each data point in several univariate directions. For each direction, determine how extreme each data point is by standardizing with respect to the maximum covariance determinant (MCD) estimates of the location and scatter. In this case, the MCD estimates are the mean and the standard deviation of the h_0 data points with the smallest variance when projected in the given direction.
b) Retain the subset of h_0 data points which have the smallest maximum standardized score across all of the different directions considered in the previous sub-step.
c) Compute a covariance matrix S_0 from the h_0 data points and use S_0 to select k, the number of robust principal components. Project the full dataset onto the top k eigenvectors of S_0.
III) Robustly calculate the scatter of the final data from step two using an accelerated MCD procedure. This procedure finds a subset of h_1 data points with minimal covariance determinant from the subset of h_0 data points identified previously. The top k eigenvectors of this scatter matrix are taken to be the robust principal components. (In the event that the accelerated MCD procedure leads to a singular matrix, the data is projected onto a lower-dimensional space, ultimately resulting in fewer than k robust principal components.)
Note that classical PCA can be expressed in terms of the same SVD that is used in step one of ROBPCA; however, ROBPCA involves additional steps to limit the influence of extreme values, while classical PCA immediately retains the top k principal components.
ROSPCA Package:
ROBPCA was initially implemented in the rrcov package via the PcaHubert function, but a more efficient implementation is now available in the ROSPCA package. This package contains additional methods for robust sparse PCA, but these are beyond the scope of this article. I will illustrate the use of the robpca function, which depends on two important parameters: alpha and k. Alpha controls how many outlying data points are resisted, taking on values in the range [0.5, 1.0]. The relationship between h_0 and alpha is given by:
The parameter k determines how many robust principal components to retain. If k is not specified, it is chosen as the smallest number such that a) the eigenvalues satisfy:
and b) the retained principal components explain at least 80 percent of the variance among the h_0 least outlying data points. When no value of k satisfies both criteria, then just the ratio of the eigenvalues is used to determine how many principal components will be retained. (Note: the original PcaHubert function states the criterion as 10E-3, but the robpca function uses 1E-3.)
Real Data Example:
For this case study, I have selected the red wine quality dataset from the UCI Machine Learning Repository. The dataset contains n=1,599 observations, each representing a different red wine. The 12 variables include 11 different chemical properties and an expert quality rating. Several of the 11 chemical properties contain potential outliers, making this an ideal dataset to illustrate 1) the impact of extreme values on PCA and 2) how a robust variance structure can be identified through ROBPCA.
PCA is not scale-invariant, so it’s important to decide intentionally on what, if any, standardization will be used. Failing to standardize would give undue weight to variables measured on larger scales, so I center each of the 11 features and divide by its standard deviation. An alternative approach would be to use a robust measure of center and scale such as the median and MAD; however, I find that robust estimates of the scale completely distort the classical principal components since the extreme values are even farther from the data’s center. ROBPCA is less sensitive to the initial scaling (a considerable advantage in itself), but I use the standard deviation for consistency and to ensure the results are comparable.
To select k for ROBPCA, I allow the function to determine the optimal k value, resulting in k=5 robust principal components. I accept the default of alpha=0.75 since I find that the variable loadings are not very sensitive to the choice of alpha, with alpha values between 0.6 and 0.9 producing very similar loadings. For classical PCA, I let k=5 to facilitate comparisons between the two methods. This is a reasonable choice for classical PCA, irrespective of ROBPCA, as the top five principal components explain just under 80 percent of the total variance.
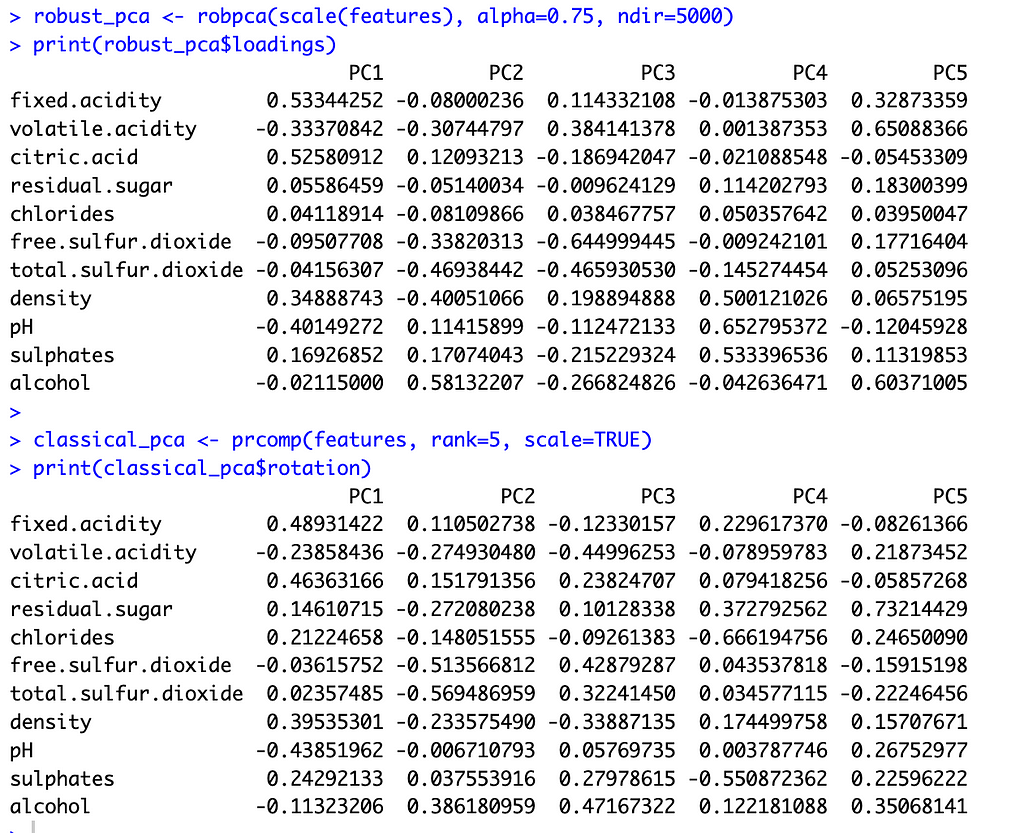
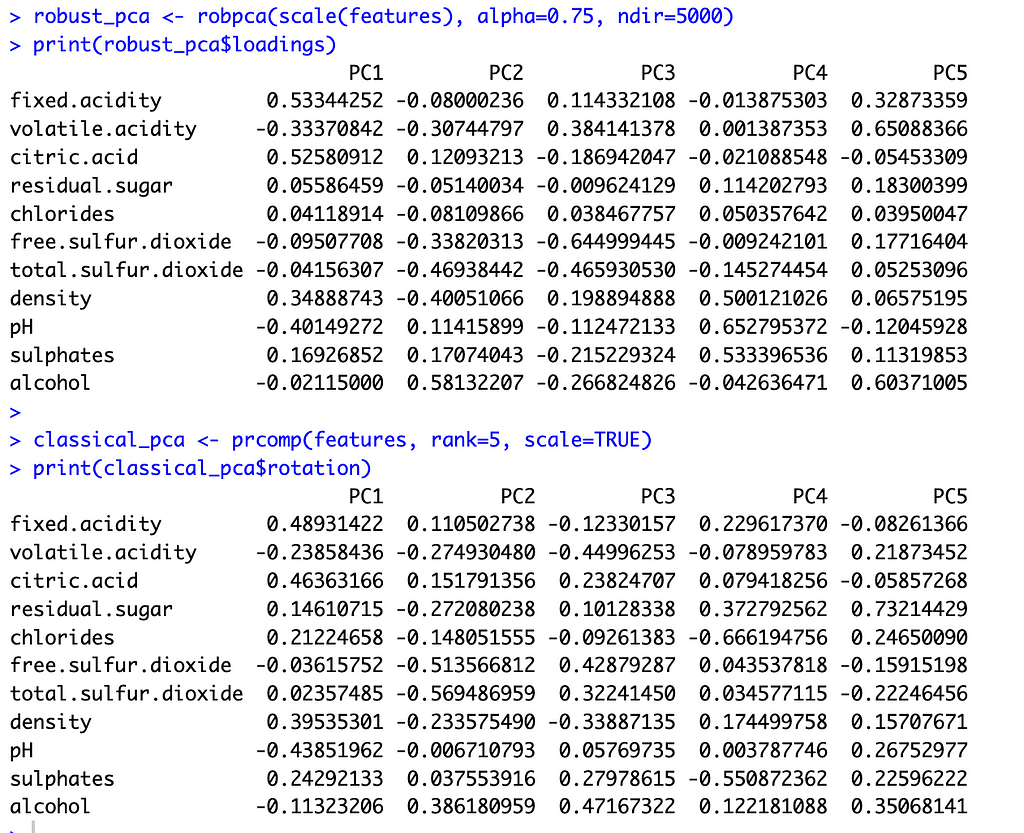
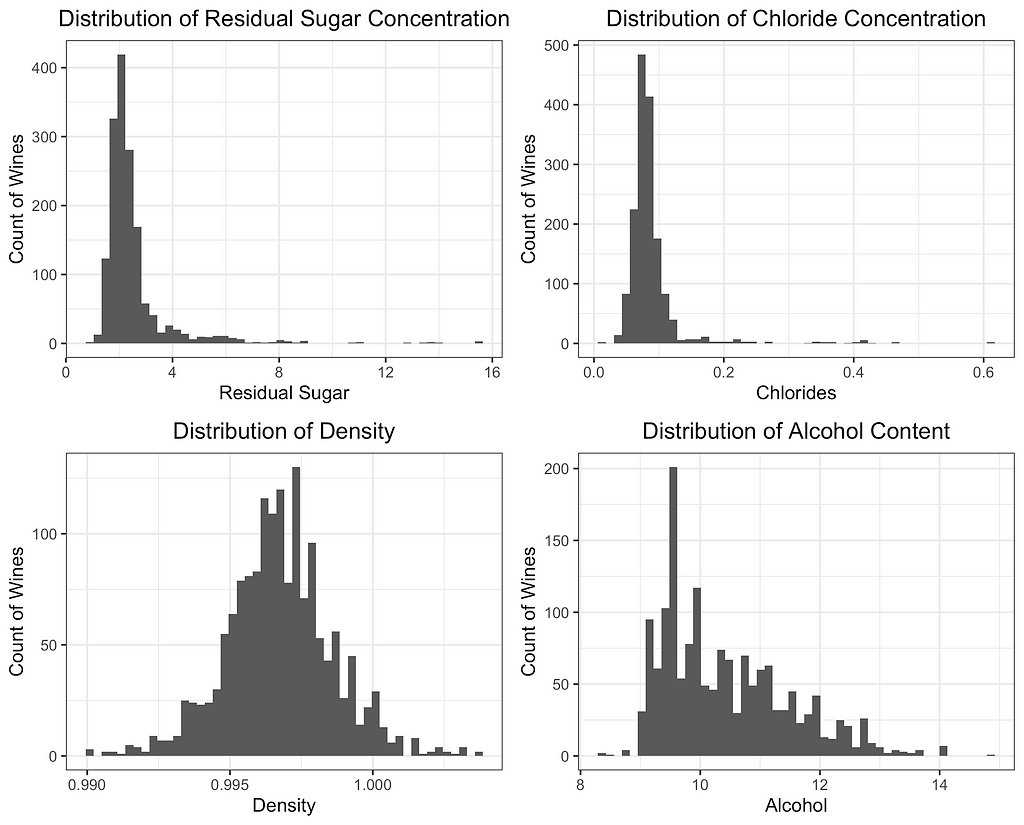
With these preliminaries out of the way, let’s compare the two methods. The image below shows the principal component loadings for both methods. Across all five components, the loadings on the variables ‘residual sugar’ and ‘chlorides’ are much smaller (in absolute value) for ROBPCA than for classical PCA. Both of these variables contain a large number of outliers, which ROBPCA tends to resist.
Meanwhile, the variables ‘density’ and ‘alcohol’ seem to contribute more significantly to the robust principal components. The second robust component, for instance, has much larger loadings on these variables than does the second classical component. The fourth and fifth robust components also have much larger loadings on either ‘density’ or ‘alcohol,’ respectively, than their classical counterparts. There are few outliers in terms of density and alcohol content, with almost all red wines distributed along a continuum of values. ROBPCA seems to better capture these common sources of variation.
Variable loadings for the robust principal components (top) and the classical principal components (bottom). Image by the author.Histograms showing the distribution of four features: residual sugar, chlorides, density, and alcohol. ROBPCA had smaller loadings on residual sugar and chlorides, which contain a number of outliers, and larger loadings on density and alcohol. Image by the author.
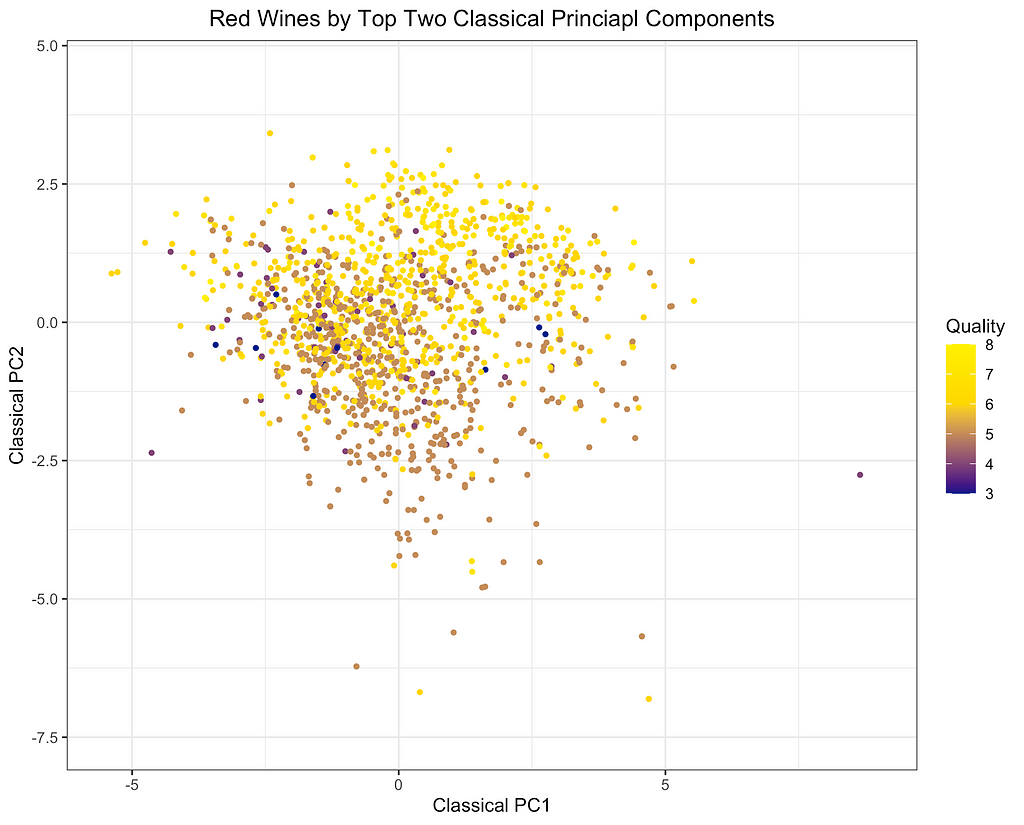
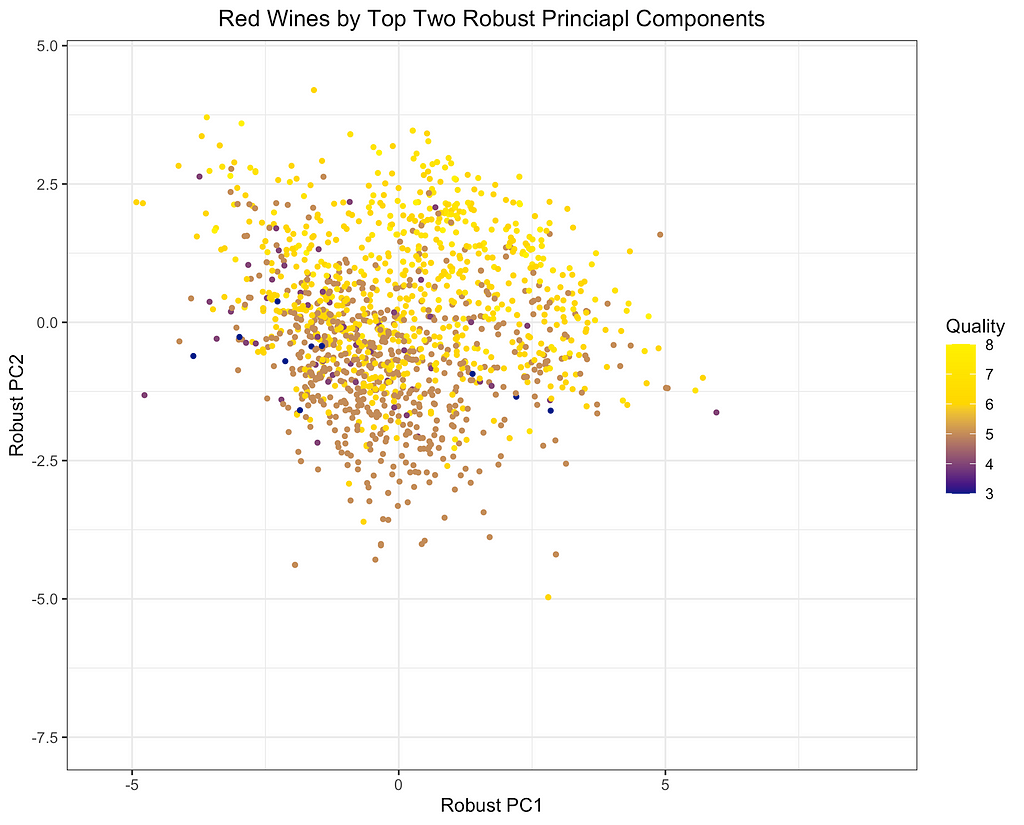
Finally, I will depict the differences between ROBPCA and classical PCA by plotting the scores for the top two principal components against each other, a common technique used for visualizing datasets in a low-dimensional space. As can be seen from the first plot below, there are a number of outliers in terms of the classical principal components, most of which have a large negative loading on PC1 and/or a large positive loading on PC2. There are a few potential outliers in terms of the robust principal components, but they do not deviate as much from the main cluster of data points. The differences between the two plots, particularly in the upper left corner, indicate that the classical principal components may be skewed downward in the direction of the outliers. Moreover, it appears that the robust principal components can better separate the wines by quality, which was not used in the principal components decomposition, providing some indication that ROBPCA recovers more meaningful variation in the data.
Red wine data projected onto the top two classical principal components. Image by the author.Red wine data projected onto the top two robust principal components identified through ROBPCA. Image by the author.
This example demonstrates how ROBPCA can resist extreme values and identify sources of variation that better represent the majority of the data points. However, the choice between robust PCA and classical PCA will ultimately depend on the dataset and the objective of the analysis. Robust PCA has the greatest advantage when there are extreme values due to measurement errors or other sources of noise that are not meaningfully related to the phenomenon of interest. Classical PCA is often preferred when the extreme values represent valid measurements, but this will depend on the objective of the analysis. Regardless of the validity of the outliers, I’ve found that robust PCA can have a large advantage when the objective of the analysis is to cluster the data points and/or visualize their distribution using only the top two or three components. The top components are especially susceptible to outliers, and they may not be very useful for segmenting the majority of data points when extreme values are present.
Potential Limitations of ROBPCA Procedure:
While ROBPCA is a powerful tool, there are some limitations of which the reader should be aware:
The projection procedure in step two can be time consuming. If n>500, the ROSPCA package recommends setting the maximum number of directions to 5,000. Even fixing ndir=5,000, the projection step still has time complexity O(np + nlog(n)), where the nlog(n) term is the time complexity for finding the MCD estimates of location and scale. This might be unsuitable for very large n and/or p.
The robust principal components are not an orthogonal basis for the full dataset, which includes the outlying data points that were resisted in the identification of the robust components. If uncorrelated predictors are desired, then ROBPCA might not be the best approach.
An Alternative Robust PCA Algorithm:
There are various alternative approaches to robust PCA, including a method proposed by Candes et al. (2011), which seeks to decompose the data matrix into a low-dimensional component and a sparse component. This approach is implemented in the rpca R package. I applied this method on the red wine dataset, but over 80 percent of the entries in the sparse matrix were non-zero. This low sparsity level indicates that the assumptions of the method were not well met. While this alternative approach is not very suitable for the red wine data, it could be a very useful algorithm for other datasets where the assumed decomposition is more appropriate.
References:
M. Hubert, P. J. Rousseeuw, K. Vanden Branden, ROBPCA: a new approach to robust principal components analysis (2005), Technometrics.
E. Candes, X. Li, Y. Ma, J. Wright, Robust Principal Components Analysis? (2011), Journal of the ACM (JACM).
T. Reynkens, V. Todorov, M. Hubert, E. Schmitt, T. Verdonck, rospca: Robust Sparse PCA using the ROSPCA Algorithm (2024), Comprehensive R Archive Network (CRAN).
V. Todorov, rrcov: Scalable Robust Estimators with High Breakdown Point (2024), Comprehensive R Archive Network (CRAN).
M. Sykulski, rpca: RobustPCA: Decompose a Matrix into Low-Rank and Sparse Components (2015), Comprehensive R Archive Network (CRAN).
P. Cortez, A. Cerdeira, F. Almeida, T. Matos, J. Reis, Wine Quality (2009), UC Irvine Machine Learning Repository. (CC BY 4.0)
A Data Scientist’s Guide to Longitudinal Experiments for Personalization Programs
Unlocking rapid “test-and-learn” and capturing full-scaled personalization value from longitudinal experimentation
A/B testing vs. longitudinal experiment
Experimentation does not always need to be complex; simple A/B test framework could be just excellent in situations with manageable marketing levers. The design and implementation of experimentation should always go hand in hand with marketing learning agenda, marketing technology (MarTech) maturity, and creative design capability.
Let’s take grocery shopping as an example. To understand impacts of one-time promotions and offerings on online grocery shoppers, a simple A/B test framework of control and test variants will do. It matters less if these shoppers are assigned to consistent control and test groups throughout their customer life journey, nor if a few of them dropped out midway.
Longitudinal experiments, also known as panel studies, provide a framework of studying causal relationships over time. Unlike one-time experiments, they allow for the examination of evolving patterns and trends within a population or sample group. Traditionally prominent in fields like medical sciences and economics, longitudinal experiments have found increasing use cases in sectors including tech, retail, banking, and insurance.
Longitudinal experiments offer distinct advantages in complex personalization scenarios. They enable a deeper understanding of the cumulative impact of personalized marketing strategies and help determine when to scale these efforts.
A case study — longitudinal experiment at a bike part supplier
Consider a hypothetical scenario with AvidBikers, a leading supplier of premium bike parts for mountain cyclists to customize and upgrade their bikes. They recently launched a personalization program to send weekly best offerings and promotions to their loyal cyclist customer base.
Contrary to one-time grocery trips, typical shopper journeys at AvidBikers consists of a series of online shopping trips to get all parts needed to DIY bikes and upgrade biking equipments.
As personalization program is rolling out, AvidBikers’ marketing data science team would like to understand both the individual campaign effectiveness and the overall program-level incrementality from combined personalized marketing strategies.
Program vs. campaign experiment
AvidBikers implements a dual-layered longitudinal experimentation framework to track the overall personalization program-wide impacts as well as impacts from individual campaigns. Here program-wide effects refer to the impacts from running the personalization program, sometime consists of up to thousands of individual campaigns, whereas campaign-level impacts refer to that of sending personalized weekly best offerings vs. promotions to most relevant customers.
To implement the framework, test and control groups are created on both global level and campaign level. Global test group is the customer base who receives personalized offerings and promos when eligible, whereas global control is carved out as “hold-out” group. Within the global test group, we further carve out campaign-level test and control groups to measure impacts of different personalization strategies.
Addressing dynamic customer in-and-out
Challenges arise, however, from new and departing customers as they could disrupt test-control group balance. For one, customer attrition likely has an uneven impact on test and control groups, creating uncontrolled differences that could not be attributed to the personalization treatment / interventions.
To address such bias, new customers are assigned into program-level and campaign level test and control groups, followed by a statistical test to validate groups are balanced. In addition, a longitudinal quality check will be run to ensure audience assignment is consistent week over week.
Measure, iterate, and repeat
Measurement is often (mistakenly) used interchangeably with experimentation. The difference, in simple terms, is that experimentations are frameworks to test hypotheses and identify causal relationship whereas measurement is the collection and quantification of observed data points.
Measurement is key to capturing learnings and financial impacts of company endeavors. Similarly to experimentation, AvidBikers prepared program and campaign-level measurement files to run statistical tests to understand program and campaign-level performance and impacts. Program-level measurement results indicate the overall success of AvidBikers personalization program. On the other hand, campaign-level measurement tells us which specific personalization tactic (personalized offering or promo) is the winning strategy for which subset of the customer base.
With measurement results, AvidBiker data scientists could work closely with their marketing and pricing teams to find the best personalization tactics through numerous fast “test-and-learn” cycles.
Implementing longitudinal experiment at scale
Implementing longitudinal experiments at scale demands a balance of technological infrastructure and methodological rigor. Tools like Airflow and Databricks streamline workflow management and data processing, facilitating the orchestration of complex experiments. Nevertheless, the cornerstone of success remains the meticulous design and execution of the experimentation framework tailored to the specific business context.
In my personal experience, complexities such as cold-start, customer dropouts, and overlapping strategies could arise, which require case-by-case evaluation and customization in experiment design and implementation. However, as customer needs continue to evolve, strategic implementation of longitudinal experiments stands as a pivotal foundation in the evolution of customer-centric personalization.
Thanks for reading and stay tuned for more data science and AI topics in the future 🙂
Connections is the new puzzle game from the New York Times, and it can be quite difficult. If you need a hand with solving today’s puzzle, we’re here to help.
Even with AirDrop’s convenience for Mac users, transferring large files or navigating software incompatibilities often requires a more robust solution. Here are some options for using a cable.
How to transfer files between two Macs using a cable
Apple equips you with several intuitive methods for transferring files between Macs. These include Ethernet for straightforward wired connections, Target Disk Mode for transforming one Mac into an external hard drive accessible by another, and Thunderbolt networking for high-speed data transfer.
Using a cable to transfer files between Macs often proves much faster and more reliable than wireless alternatives like AirDrop, particularly for large or numerous files. This method shines in scenarios where speed is critical, and data volume is substantial, offering a streamlined solution that enhances your workflow.
This digital calendar is the perfect gift for busy moms on Mother’s Day
Originally appeared here:
This digital calendar is the perfect gift for busy moms on Mother’s Day
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.