
Pininfarina teams up with Wayne Enterprises to create bespoke Battista hyper EVs for hardcore Bruce Wayne fans.
Originally appeared here:
Pininfarina creates Batman-inspired hyper EVs that will set you back a cool $3.6 million

Originally appeared here:
Pininfarina creates Batman-inspired hyper EVs that will set you back a cool $3.6 million




Originally appeared here:
Looking for a Fujifilm X100VI or Leica Q3 alternative? Panasonic could soon launch a surprising full-frame compact rival


Originally appeared here:
X-Men 97 episode 8 is full of fan favorite Marvel superhero cameos – here are 5 of the best
Originally appeared here:
Amazon Q is now open to any workers looking to build an AI chatbot for work


Create an engaging portfolio website from scratch with generative AI (+ a free prompt engineering crash course)
Originally appeared here:
A Beginner’s Guide to Building a Data Science Portfolio Website with ChatGPT
Go Here to Read this Fast! Instagram shows love to smaller accounts that post original content
Originally appeared here:
Instagram shows love to smaller accounts that post original content


As LLMs continue to increase their reasoning ability, their capacity to plan and then act tends to increase. This has led to prompting templates where users give LLMs an end result they want and the LLM then will figure out how to accomplish it — even if it takes multiple actions to do so. This kind of prompting is often called an agent, and it has generated a lot of excitement.
For example, one could ask an agent to win a game and then watch it figure out a good strategy to do so. While typically we would use frameworks like reinforcement learning to train a model to win games like Super Mario Bros, when we look at games with more open-ended goals like Minecraft, an LLMs’ ability to reason can become critical.
The Voyager Paper focuses on how one can prompt an LLM so that it can complete open-ended and challenging tasks like playing Minecraft. Let’s dive in!
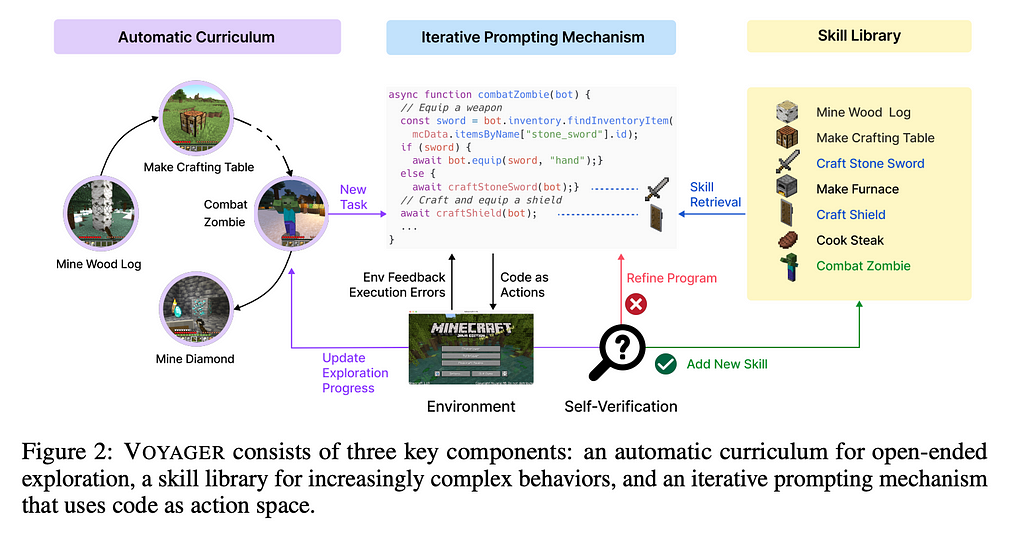
The Voyager system here consists of three major pieces: an automatic curriculum, an iterative prompting mechanism, and a skill library. The curriculum you can imagine as the compass of the system, a way that the agent is able to determine what it should do in a given situation. As new situations arise, we have the iterative prompting mechanism to create new skills for new situations. Because LLMs have limited contexts but the curriculum could potentially create the need for limitless skills, we also have a skill library to store these skills for later use.

The Automatic Curriculum is itself prompt engineering, where pertinent information about the AI’s immediate environment and long-term goals are passed to the LLM. The authors were kind enough to give the full system prompt in the paper, so I will highlight interesting parts of it below.

First, the prompt explains the basic schema that will be passed in. Although the exact information is not filled in here, it appears like this is helping by priming the LLM to receive information in this schema. This is similar to few-shot reasoning, as later turns with this chatbot will use that format.

Next, the prompt outlines a fairly precise way that the LLM should reason. Notice that this is still given in the second-person (you) and that the instructions are highly specific to Minecraft itself. In my opinion, improvements to the pieces outlined above would seem to give the greatest payoff. Moreover, notice how the steps themselves are not always exact like one might see in traditional programming, instead being consistent with the more ambiguous goal of exploration. This is where the promise of agents lies.
Within the above section, Step one is especially interesting to me, as it could be read as a kind of “persona” prompting: telling the LLM it is a mentor and thus having it speak with more certainty in its replies. We have seen in the past that persona prompting can result in the LLM taking more decisive action, so this could be a way to ensure the agent will act and not get stuck in analysis paralysis.
Finally, the prompt ends by again giving a few-shot reasoning piece illustrating how best to respond.
Historically, we’ve used reinforcement machine learning models with specific inputs to discover optimal strategies for maximizing well-defined metrics (think getting the highest score in an arcade game). Today, the LLM is given a more ambiguous long-term goal and seen taking actions that would realize it. That we think the LLM is capable of approximating this type of goal signals a major change in expectations for ML agents.

Here, the LLM will create code that executes certain actions in Minecraft. As these tend to be more complex series of actions, we call these skills.
When creating the skills that will go into the skill library, the authors had their LLM receive 3 distinct kinds of feedback during development: (1) execution errors, (2) environment feedback, and (3) peer-review from another LLM.
Execution errors can occur when the LLM makes a mistake with the syntax of the code, the Mineflayer library, or some other item that is caught by the compiler or in run-time. Environment feedback comes from the Minecraft game itself. The authors use the bot.chat() feature within Mineflayer to get feedback such as “I cannot make stone_shovel because I need: 2 more stick”. This information is then passed into the LLM.
While execution and environment feedback seems natural, the peer-review feedback may seem strange. After all, running two LLMs is more expensive than running only one. However, as the set of skills that can be created by the LLM is enormous, it would be very difficult to write code that verifies the skills actually do what they are supposed to do. To get around this, the authors have a separate LLM review the code and give feedback on if the task is accomplished. While this isn’t as perfect as verifying programmatically the job is finished, it is a good enough proxy.

Going chronologically, the LLM will keep trying to create a skill in code while it is given ways to improve via execution errors, the environment, and peer-feedback. Once all say the skill looks good, it is then added to the skill library for future use.
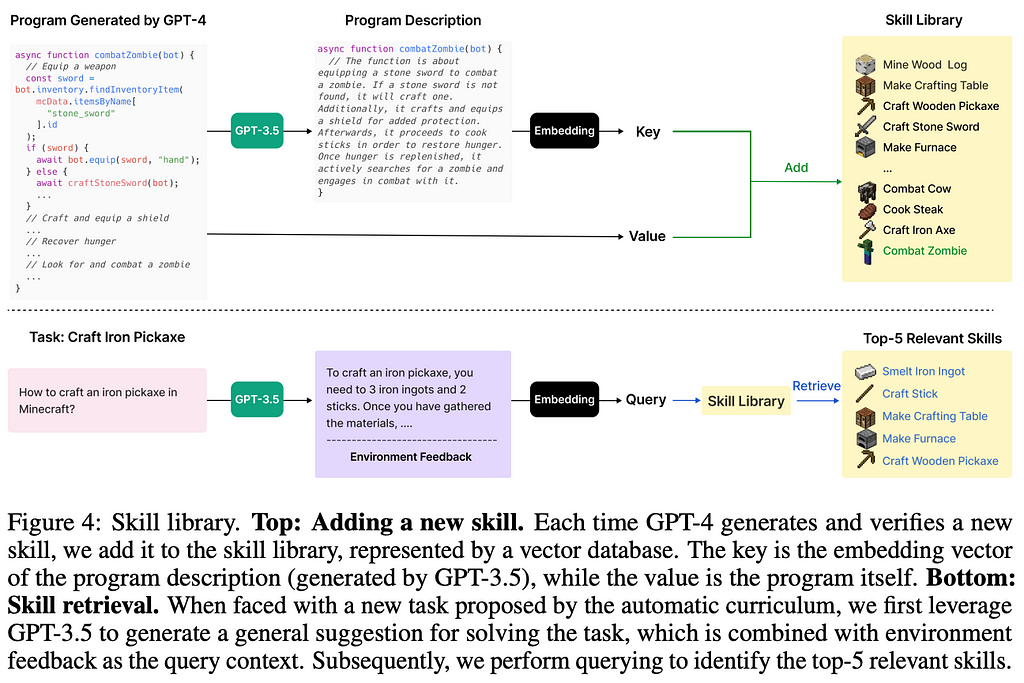
The Skill Library holds the skills that the LLM has generated before and gone through the approval process in the iterative prompting step. Each skill is added to the library by taking a description of it and then converting that description into an embedding. The authors then take the description of the task and query the skill library to find skills with a similar embedding.
Because the Skill Library is a separate data store, it is free to grow over time. The paper did not go into updating the skills already in the library, so it would appear that once the skill is learned it will stay in that state. This poses interesting questions for how you could update the skills as experience progresses.
Voyager is considered part of the agent space — where we expect the LLM to behave as an entity in its own right, interacting with the environment and changing things.

To that end, there are a few different prompting methodologies employed to accomplish that. First, AutoGPT is a Github library that people have used to automate many different tasks from file system actions to simple software development. Next, we have Reflexion which gives the LLM an example of what has just happened and then has it reflect on what it should do next time in a similar situation. We use the reflected upon advice to tell the Minecraft player what to do. Finally, we have ReAct, which will have the LLM break down tasks into simpler steps via a formulaic way of thinking. From the image above you can see the formatting it uses.
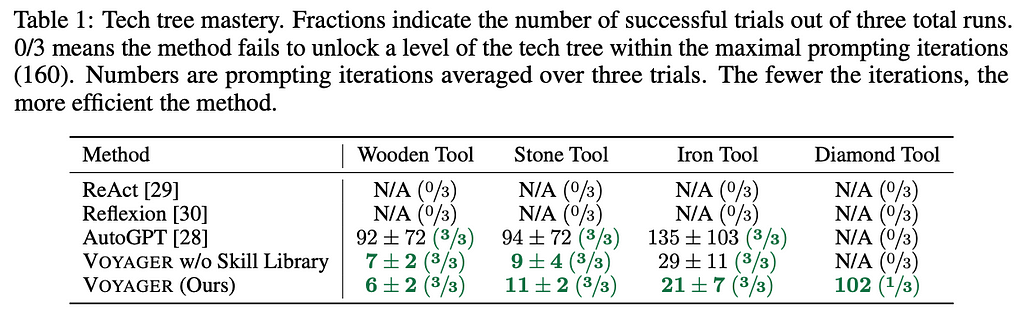
Each of the methodologies were put into the game, and the table below shows the results. Only AutoGPT and the Voyager methods actually successfully made it to the Wooden Tool stage. This may be a consequence of the training data for the LLMs. With ReAct and Reflexion, it appears a good amount of knowledge about the task at hand is required for the prompting to be effective. From the table below, we can see that the Voyager methodology without the skill library was able to do better than AutoGPT, but not able to make it to the final Diamond Tool category. Thus, we can see clearly that the Skill Library plays an outsize role here. In the future, Skill Libraries for LLMs may become a type of moat for a company.
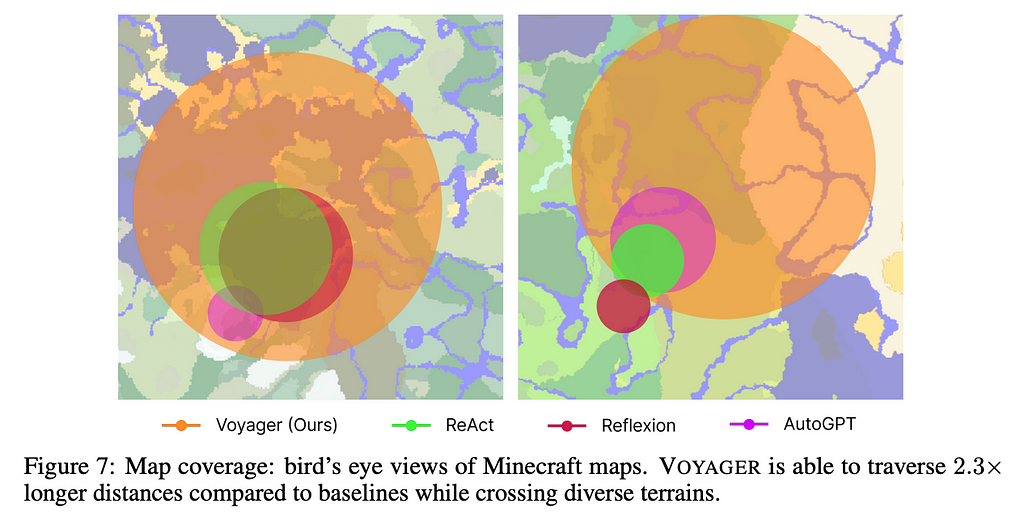
Tech progress is just one way to look at a Minecraft game. The figure below clearly outlines the parts of the game map that each LLM explored. Just look at how much further Voyager will go in the map than the others. Whether this is an accident of slightly different prompts or an inherent part of the Voyager architecture remains to be seen. As this methodology is applied to other situations we’ll have a better understanding.
This paper highlights an interesting approach to tool usage. As we push for LLMs to have greater reasoning ability, we will increasingly look for them to make decisions based on that reasoning ability. While an LLM that improves itself will be more valuable than a static one, it also poses the question: How do you make sure it doesn’t go off track?
From one point of view, this is limited to the quality of its actions. Improvement in complex environments is not always as simple as maximizing a differentiable reward function. Thus, a major area of work here will focus on validating that the LLM’s skills are improving rather than just changing.
However, from a larger point of view, we can reasonably wonder if there are some skills or areas where the LLM may become too dangerous if left to its own discretion. Areas with direct impact on human life come to mind. Now, areas like this still have problems that LLMs could solve, so the solution cannot be to freeze progress here and allow people who otherwise would have benefitted from the progress to suffer instead. Rather, we may see a world where LLMs execute the skills that humans design, creating a world that pairs human and machine intelligence.
It is an exciting time to be building.
[1] Wang, G., et al. “VOYAGER: An Open-Ended Embodied Agent
with Large Language Models” (2023), arXiv
[2] Significant-gravitas/auto-gpt: An experimental open-source attempt to make gpt-4 fully autonomous., 2024, Github
[3] Yao, S., et al. “REAC T: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS” (2023), arXiv
Tool Use, Agents, and the Voyager Paper was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Tool Use, Agents, and the Voyager Paper
Go Here to Read this Fast! Tool Use, Agents, and the Voyager Paper


While LLMs clearly excel in natural language processing tasks, their ability to analyze patterns in non-textual data, such as time series data, remains less explored. As more teams rush to deploy LLM-powered solutions without thoroughly testing their capabilities in basic pattern analysis, the task of evaluating the performance of these models in this context takes on elevated importance.
In this research, we set out to investigate the following question: given a large set of time series data within the context window, how well can LLMs detect anomalies or movements in the data? In other words, should you trust your money with a stock-picking OpenAI GPT-4 or Anthropic Claude 3 agent? To answer this question, we conducted a series of experiments comparing the performance of LLMs in detecting anomalous time series patterns.
All code needed to reproduce these results can be found in this GitHub repository.

We tasked GPT-4 and Claude 3 with analyzing changes in data points across time. The data we used represented specific metrics for different world cities over time and was formatted in JSON before input into the models. We introduced random noise, ranging from 20–30% of the data range, to simulate real-world scenarios. The LLMs were tasked with detecting these movements above a specific percentage threshold and identifying the city and date where the anomaly was detected. The data was included in this prompt template:
basic template = ''' You are an AI assistant for a data scientist. You have been given a time series dataset to analyze.
The dataset contains a series of measurements taken at regular intervals over a period of time.
There is one timeseries for each city in the dataset. Your task is to identify anomalies in the data. The dataset is in the form of a JSON object, with the date as the key and the measurement as the value.
The dataset is as follows:
{timeseries_data}
Please use the following directions to analyze the data:
{directions}
...
Figure 2: The basic prompt template used in our tests
Analyzing patterns throughout the context window, detecting anomalies across a large set of time series simultaneously, synthesizing the results, and grouping them by date is no simple task for an LLM; we really wanted to push the limits of these models in this test. Additionally, the models were required to perform mathematical calculations on the time series, a task that language models generally struggle with.
We also evaluated the models’ performance under different conditions, such as extending the duration of the anomaly, increasing the percentage of the anomaly, and varying the number of anomaly events within the dataset. We should note that during our initial tests, we encountered an issue where synchronizing the anomalies, having them all occur on the same date, allowed the LLMs to perform better by recognizing the pattern based on the date rather than the data movement. When evaluating LLMs, careful test setup is extremely important to prevent the models from picking up on unintended patterns that could skew results.
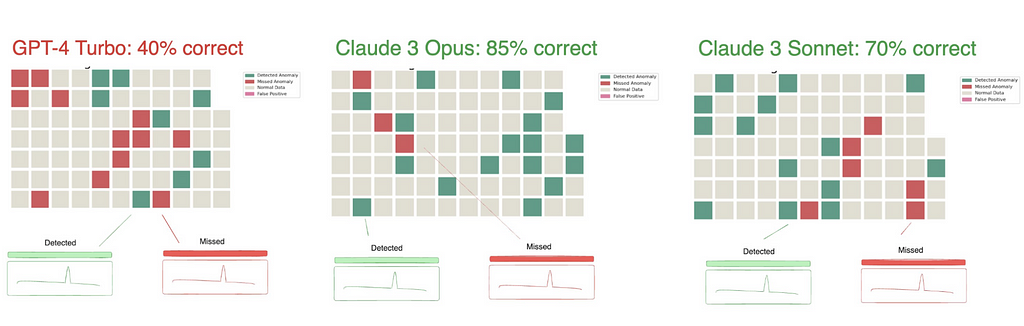
In testing, Claude 3 Opus significantly outperformed GPT-4 in detecting time series anomalies. Given the nature of the testing, it’s unlikely that this specific evaluation was included in the training set of Claude 3 — making its strong performance even more impressive.
Our first set of results is based on data where each anomaly was a 50% spike in the data.
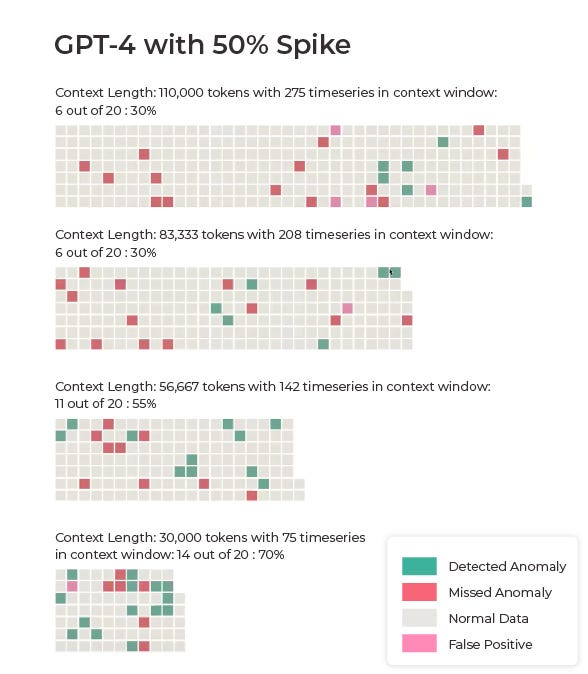
Claude 3 outperformed GPT-4 on the majority of the 50% spike tests, achieving accuracies of 50%, 75%, 70%, and 60% across different test scenarios. In contrast, GPT-4 Turbo, which we used due to the limited context window of the original GPT-4, struggled with the task, producing results of 30%, 30%, 55%, and 70% across the same tests.
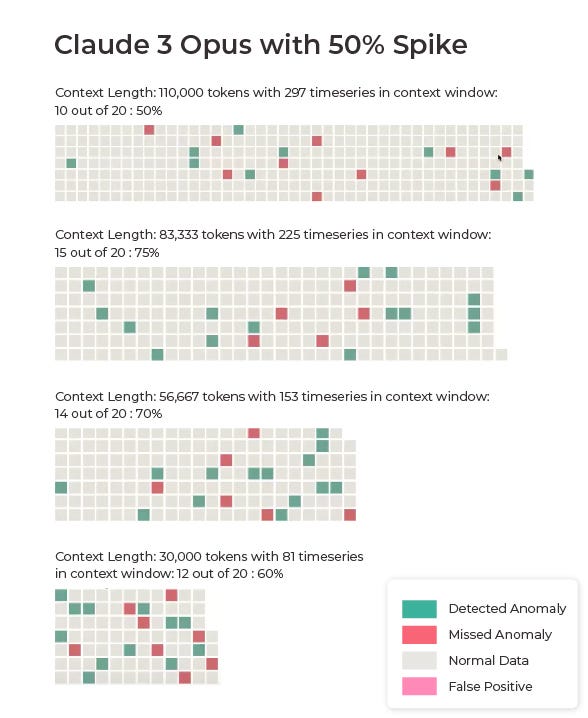
Claude 3’s also led where each anomaly was a 90% spike in the data.

Claude 3 Opus consistently picked up the time series anomalies better than GPT-4, achieving accuracies of 85%, 70%, 90%, and 85% across different test scenarios. If we were actually trusting a language model to analyze data and pick stocks to invest in, we would of course want close to 100% accuracy. However, these results are impressive. GPT-4 Turbo’s performance ranged from 40–50% accuracy in detecting anomalies.
To assess the impact of mathematical complexity on the models’ performance, we did additional tests where the standard deviation was pre-calculated and included in the data like this:
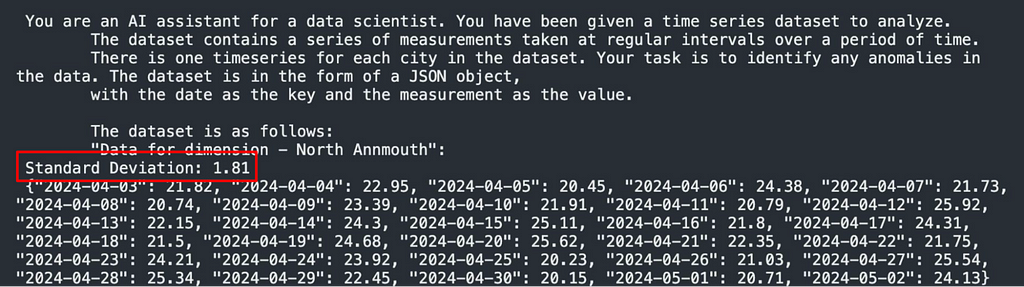
Since math isn’t a strong suit of large language models at this point, we wanted to see if helping the LLM complete a step of the process would help increase accuracy.

The change did in fact increase accuracy across three of the four Claude 3 runs. Seemingly minor changes like this can help LLMs play to their strengths and greatly improve results.
This evaluation provides concrete evidence of Claude’s capabilities in a domain that requires a complex combination of retrieval, analysis, and synthesis — though the delta between model performance underscores the need for comprehensive evaluations before deploying LLMs in high-stakes applications like finance.
While this research demonstrates the potential of LLMs in time series analysis and data analysis tasks, the findings also point to the importance of careful test design to ensure accurate and reliable results — particularly since data leaks can lead to misleading conclusions about an LLM’s performance.
As always, understanding the strengths and limitations of these models is pivotal for harnessing their full potential while mitigating the risks associated with their deployment.
Large Language Model Performance in Time Series Analysis was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Large Language Model Performance in Time Series Analysis
Go Here to Read this Fast! Large Language Model Performance in Time Series Analysis


Learn how to build and deploy a custom self-hosted Llama 3 chat assistant in four simple steps.
Originally appeared here:
Four Simple Steps to Build a Custom Self-hosted Llama3 Application
Go Here to Read this Fast! Four Simple Steps to Build a Custom Self-hosted Llama3 Application