Elon Musk has made no secret that he’s not a fan of the block button. Now, X is changing how blocks work on its platform, though it’s (for now) stopping short of Musk’s wish of nuking the feature entirely.
Instead, X is tweaking the visibility of replies in the context of a block. Previously, a user could block someone on X and still reply to their posts. And the person who was blocked wouldn’t be able to view that reply or know the person who had blocked them was engaging with their posts. That’s now being rolled back so that users will be able to see direct replies even if the person posting has blocked them. In a post from X’s engineering team, the company said the change is “part of our ongoing commitment to aligning the block feature with our principles as a public town square.”
We are making changes to how block works.
If a user who has blocked you replies to one of your posts, you will now be able to see their reply. This change enables you to identify and report any potential bad content that you previously could not view, safeguarding both your…
The post also hinted that there may be more changes coming to blocks, which is one of the most widely used safety features on the service. “Our goal is to allow users to control their experience while maintaining the public visibility of posts,” the company said. That would seem to align with previous comments from Musk, who has said on multipleoccasions that a public-facing “block” feature “makes no sense” and that “block is going to be deleted as a ‘feature,’ except for DMs.”
For now, the changes to blocking aren’t that drastic. In fact, they may even be welcomed by some users who want more visibility into what people are saying about them on the platform. But the fact that X is starting to change the visibility of previously blocked content could also be a sign of more significant changes to come.
This article originally appeared on Engadget at https://www.engadget.com/x-is-changing-how-the-block-button-works-225338769.html?src=rss
Microsoft says the April security updates for Windows may break your VPN. (Oops!) “Windows devices might face VPN connection failures after installing the April 2024 security update (KB5036893) or the April 2024 non-security preview update,” the company wrote in a status update. It’s working on a fix.
Bleeping Computer first reported the issue, which affects Windows 11, Windows 10 and Windows Server 2008 and later. User reports on Reddit are mixed, with some commenters saying their VPNs still work after installing the update and others claiming their encrypted connections were indeed borked.
“We are working on a resolution and will provide an update in an upcoming release,” Microsoft wrote.
There’s no proper fix until Microsoft pushes a patched update. However, you can work around the issue by uninstalling all the security updates. In an unfortunate bit of timing for CEO Satya Nadella, he said last week that he wants Microsoft to put “security above else.” I can’t imagine making customers (temporarily) choose between going without a VPN and losing the latest protection is what he had in mind.
At least one Redditor claims that uninstalling and reinstalling their VPN app fixed the problem for them, so it may be worth trying that before moving on to more drastic measures.
If you decide to uninstall the security updates, Microsoft tells you how. “To remove the LCU after installing the combined SSU and LCU package, use the DISM/Remove-Package command line option with the LCU package name as the argument,” the company wrote in its patch notes. “You can find the package name by using this command: DISM /online /get-packages.”
This article originally appeared on Engadget at https://www.engadget.com/microsofts-latest-windows-security-updates-might-break-your-vpn-202050679.html?src=rss
There’s a core concept in machine learning that I often tell laypeople about to help clarify the philosophy behind what I do. That concept is the idea that the world changes around every machine learning model, often because of the model, so the world the model is trying to emulate and predict is always in the past, never the present or the future. The model is, in some ways, predicting the future — that’s how we often think of it — but in many other ways, the model is actually attempting to bring us back to the past.
I like to talk about this because the philosophy around machine learning helps give us real perspective as machine learning practitioners as well as the users and subjects of machine learning. Regular readers will know I often say that “machine learning is us” — meaning, we produce the data, do the training, and consume and apply the output of models. Models are trying to follow our instructions, using raw materials we have provided to them, and we have immense, nearly complete control over how that happens and what the consequences will be.
Another aspect of this concept that I find useful is the reminder that models are not isolated in the digital world, but in fact are heavily intertwined with the analog, physical world. After all, if your model isn’t affecting the world around us, that sparks the question of why your model exists in the first place. If we really get down to it, the digital world is only separate from the physical world in a limited, artificial sense, that of how we as users/developers interact with it.
This last point is what I want to talk about today — how does the physical world shape and inform machine learning, and how does ML/AI in turn affect the physical world? In my last article, I promised that I would talk about how the limitations of resources in the physical world intersect with machine learning and AI, and that’s where we’re going.
AI Needs the Physical World
This is probably obvious if you think about it for a moment. There’s a joke that goes around about how we can defeat the sentient robot overlords by just turning them off, or unplugging the computers. But jokes aside, this has a real kernel of truth. Those of us who work in machine learning and AI, and computing generally, have complete dependence for our industry’s existence on natural resources, such as mined metals, electricity, and others. This has some commonalities with a piece I wrote last year about how human labor is required for machine learning to exist, but today we’re going to go a different direction and talk about two key areas that we ought to appreciate more as vital to our work — mining/manufacturing and energy, mainly in the form of electricity.
If you go out looking for it, there is an abundance of research and journalism about both of these areas, not only in direct relation to AI, but relating to earlier technological booms such as cryptocurrency, which shares a great deal with AI in terms of its resource usage. I’m going to give a general discussion of each area, with citations for further reading so that you can explore the details and get to the source of the scholarship. It is hard, however, to find research that takes into account the last 18 months’ boom in AI, so I expect that some of this research is underestimating the impact of the new technologies in the generative AI space.
Mining and Manufacturing
What goes in to making a GPU chip? We know these chips are instrumental in the development of modern machine learning models, and Nvidia, the largest producer of these chips today, has ridden the crypto boom and AI craze to a place among the most valuable companies in existence. Their stock price went from the $130 a share at the start of 2021 to $877.35 a share in April 2024 as I write this sentence, giving them a reported market capitalization of over $2 trillion.In Q3 of 2023, they sold over 500,000 chips, for over $10 billion. Estimates put their total 2023 sales of H100s at 1.5 million, and 2024 is easily expected to beat that figure.
GPU chips involve a number of different specialty raw materials that are somewhat rare and hard to acquire, including tungsten, palladium, cobalt, and tantalum. Other elements might be easier to acquire but have significant health and safety risks, such as mercury and lead. Mining these elements and compounds has significant environmental impacts, including emissions and environmental damage to the areas where mining takes place. Even the best mining operations change the ecosystem in severe ways. This is in addition to the risk of what are called “Conflict Minerals”, or minerals that are mined in situations of human exploitation, child labor, or slavery. (Credit where it is due: Nvidia has been very vocal about avoiding use of such minerals, calling out the Democratic Republic of Congo in particular.)
After a chip is produced, it can have a lifespan of usefulness that can be significant —3–5 years if maintained well — however, Nvidia is constantly producing new, more powerful, more efficient chips (2 million a year is a lot!) so a chip’s lifespan may be limited by obsolescence as well as wear and tear. When a chip is no longer useful, it goes into the pipeline of what is called “e-waste”. Theoretically, many of the rare metals in a chip ought to have some recycling value, but as you might expect, chip recycling is a very specialized and challenging technological task, and only about 20% of all e-waste gets recycled, including much less complex things like phones and other hardware. The recycling process also requires workers to disassemble equipment, again coming into contact with the heavy metals and other elements that are involved in manufacturing to begin with.
Most research on the carbon footprint of machine learning, and its general environmental impact, has been in relation to power consumption, however. So let’s take a look in that direction.
Electricity
Once we have the hardware necessary to do the work, the elephant in the room with AI is definitely electricity consumption. Training large language models consumes extraordinary amounts of electricity, but serving and deploying LLMs and other advanced machine learning models is also an electricity sinkhole.
In the case of training, one research paper suggests that training GPT-3, with 175 billion parameters, runs around 1,300 megawatt hours (MWh) or 1,300,000 KWh of electricity. Contrast this with GPT-4, which uses 1.76 trillion parameters, and where the estimated power consumption of training was between 51,772,500 and 62,318,750 KWh of electricity. For context, an average American home uses just over 10,000 KWh per year. On the conservative end, then, training GPT-4 once could power almost 5,000 American homes for a year. (This is not considering all the power consumed by preliminary analyses or tests that almost certainly were required to prepare the data and get ready to train.)
Given that the power usage between GPT-3 and GPT-4 training went up approximately 40x, we have to be concerned about the future electrical consumption involved in next versions of these models, as well as the consumption for training models that generate video, image, or audio content.
Past the training process, which only needs to happen once in the life of a model, there’s the rapidly growing electricity consumption of inference tasks, namely the cost of every time you ask Chat-GPT a question or try to generate a funny image with an AI tool. This power is absorbed by data centers where the models are running so that they can serve results around the globe. The International Energy Agency predicted that data centers alone would consume 1,000 terawatts in 2026, roughly the power usage of Japan.
Whether investments in electricity infrastructure have a chance of meeting the skyrocketing demand wrought by AI tools is still to be seen, and since government action is necessary to get there, it’s reasonable to be pessimistic.
In the meantime, even if we do manage to produce electricity at the necessary rates, until renewable and emission-free sources of electricity are scalable, we’re adding meaningfully to the carbon emissions output of the globe by using these AI tools. At a rough estimate of 0.86 pounds of carbon emissions per KWh of power, training GPT-4 output over 20,000 metric tons of carbon into the atmosphere. (In contrast, the average American emits 13 metric tons per year.)
Ok, So What?
As you might expect, I’m not out here arguing that we should quit doing machine learning because the work consumes natural resources. I think that workers who make our lives possible deserve significant workplace safety precautions and compensation commensurate with the risk, and I think renewable sources of electricity should be a huge priority as we face down preventable, human caused climate change.
But I talk about all this because knowing how much our work depends upon the physical world, natural resources, and the earth should make us humbler and make us appreciate what we have. When you conduct training or inference, or use Chat-GPT or Dall-E, you are not the endpoint of the process. Your actions have downstream consequences, and it’s important to recognize that and make informed decisions accordingly. You might be renting seconds or hours of use of someone else’s GPU, but that still uses power, and causes wear on that GPU that will eventually need to be disposed of. Part of being ethical world citizens is thinking about your choices and considering your effect on other people.
In addition, if you are interested in finding out more about the carbon footprint of your own modeling efforts, there’s a tool for that: https://www.green-algorithms.org/
This blog post is an updated version of part of a conference talk I gave on GOTO Amsterdam last year. The talk is also available to watch online.
As a Machine Learning Product Manager, I am fascinated by the intersection of Machine Learning and Product Management, particularly when it comes to creating solutions that provide value and positive impact on the product, company, and users. However, managing to provide this value and positive impact is not an easy job. One of the main reasons for this complexity is the fact that, in Machine Learning initiatives developed for digital products, two sources of uncertainty intersect.
From a Product Management perspective, the field is uncertain by definition. It is hard to know the impact a solution will have on the product, how users will react to it, and if it will improve product and business metrics or not… Having to work with this uncertainty is what makes Product Managers potentially different from other roles like Project Managers or Product Owners. Product strategy, product discovery, sizing of opportunities, prioritization, agile, and fast experimentation, are some strategies to overcome this uncertainty.
The field of Machine Learning also has a strong link to uncertainty. I always like to say “With predictive models, the goal is to predict things you don’t know are predictable”. This translates into projects that are hard to scope and manage, not being able to commit beforehand to a quality deliverable (good model performance), and many initiatives staying forever as offline POCs. Defining well the problem to solve, initial data analysis and exploration, starting small, and being close to the product and business, are actions that can help tackle the ML uncertainty in projects.
Mitigating this uncertainty risk from the beginning is key to developing initiatives that end up providing value to the product, company, and users. In this blog post, I’ll deep-dive into my top 3 lessons learned when starting ML Product initiatives to manage this uncertainty from the beginning. These learnings are mainly based on my experience, first as a Data Scientist and now as an ML Product Manager, and are helpful to improve the likelihood that an ML solution will reach production and achieve a positive impact. Get ready to explore:
Start with the problem, and define how predictions will be used from the beginning.
Start small, and maintain small if you can.
Data, data, and data: quality, volume, and historic.
Start with the problem (and define how predictions will be used)
I have to admit, I have learned this the hard way. I’ve been involved in projects where, once the model was developed and prediction performance was determined to be “good enough”, the model’s predictions weren’t really usable for any specific use case, or were not useful to help solve any problem.
There are many reasons this can happen, but the ones I’ve found more frequently are:
Solution-driven initiatives: even before GenAI, Machine Learning, and predictive models were “cool” solutions, and because of that some initiatives started from the ML solution: “let’s try to predict churn” (users or clients who abandon a company), “let’s try to predict user segments”… Current GenAI hype has worsened this trend, putting pressure on companies to integrate GenAI solutions “anywhere” they fit.
Lack of end-to-end design of the solution: in very few cases, the predictive model is a standalone solution. Usually, though, models and their predictions are integrated into a bigger system to solve a specific use case or enable a new functionality. If this end-to-end solution is not defined from the beginning, it can happen that the model, once already implemented, is found to be useless.
To start an ML initiative on the right foot, it is key to start with the good problem to solve. This is foundational in Product Management, and recurrently reinforced product leaders like Marty Cagan and Melissa Perri. It includes product discovery (through user interviews, market research, data analysis…), and sizing and prioritization of opportunities (by taking into account quantitative and qualitative data).
Once opportunities are identified, the second step is to explore potential solutions for the problem, which should include Machine Learning and GenAI techniques, if they can help solve the problem.
If it is decided to try out a solution that includes the use of predictive models, the third step would be to do an end-to-end definition and design of the solution or system. This way, we can ensure the requirements on how to use the predictions by the system, influence the design and implementation of the predictive piece (what to predict, data to be used, real-time vs batch, technical feasibility checks…).
However, I’d like to add there might be a notable exception in this topic. Starting from GenAI solutions, instead of from the problem, can make sense if this technology ends up truly revolutionizing your sector or the world as we know it. There are a lot of discussions about this, but I’d say it is not clear yet whether that will happen or not. Up until now, we have seen this revolution in very specific sectors (customer support, marketing, design…) and related to people’s efficiency when performing certain tasks (coding, writing, creating…). For most companies though, unless it’s considered R&D work, delivering short/mid-term value still should mean focusing on problems, and considering GenAI just as any other potential solution to them.
Start small (and maintain small if you can)
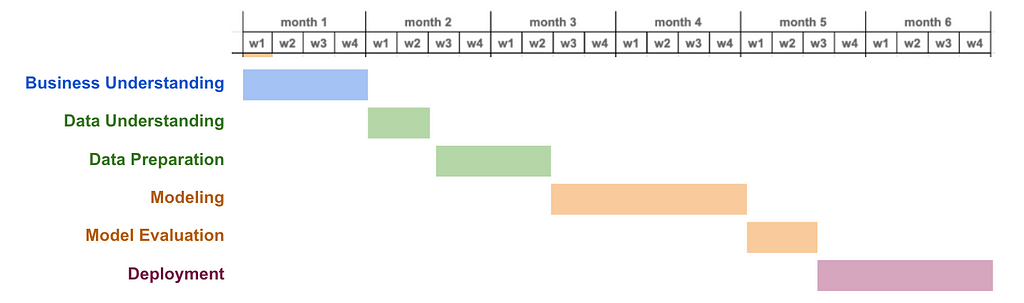
Tough experiences lead to this learning as well. Those experiences had in common a big ML project defined in a waterfall manner. The kind of project that is set to take 6 months, and follow the ML lifecycle phase by phase.
Waterfall project planning following the ML Lifecycle phases, image by author
What could go wrong, right? Let me remind you of my previous quote “With predictive models, the goal is to predict things you don’t know are predictable”! In a situation like this, it can happen that you arrive at month 5 of the project, and during the model evaluation realize there is no way the model is able to predict whatever it needs to predict with good enough quality. Or worse, you arrive at month 6, with a super model deployed in production, and realize it is not bringing any value.
This risk combines with the uncertainties related to Product, and makes it mandatory to avoid big, waterfall initiatives if possible. This is not something new or related only to ML initiatives, so there is a lot we can learn from traditional software development, Agile, Lean, and other methodologies and mindsets. By starting small, validating assumptions soon and continuously, and iteratively experimenting and scaling, we can effectively mitigate this risk, adapt to insights and be more cost-efficient.
While these principles are well-established in traditional software and product development, their application to ML initiatives is a bit more complex, as it is not easy to define “small” for an ML model and deployment. There are some approaches, though, that can help start small in ML initiatives.
Rule-based approaches, simplifying a predictive model through a decision tree. This way, “predictions” can be easily implemented as “if-else statements” in production as part of the functionality or system, without the need to deploy a model.
Proofs of Concept (POCs), as a way to validate offline the predictive feasibility of the ML solution, and hint on the potential (or not) of the predictive step once in production.
Minimum Viable Products (MVPs), to first focus on essential features, functionalities, or user segments, and expand the solution only if the value has been proven. For an ML model this can mean, for example, only the most straightforward, priority input features, or predicting only for a segment of data points.
Buy instead of build, to leverage existing ML solutions or platforms to help reduce development time and initial costs. Only when proved valuable and costs increase too much, might be the right time to decide to develop the ML solution in-house.
Using GenAI as an MVP, for some use cases (especially if they involve text or images), genAI APIs can be used as a first approach to solve the prediction step of the system. Tasks like classifying text, sentiment analysis, or image detection, where GenAI models deliver impressive results. When the value is validated and if costs increase too much, the team can decide to build a specific “traditional” ML model in-house.
Note that using GenAI models for image or text classification, while possible and fast, means using a way too big an complex model (expensive, lack of control, hallucinations…) for something that could be predicted with a much simpler and controllable one. A fun analogy would be the idea of delivering a pizza with a truck: it is feasible, but why not just use a bike?
Data is THE recurring problem Data Scientist and ML teams encounter when starting ML initiatives. How many times have you been surprised by data with duplicates, errors, missing batches, weird values… And how different that is from the toy datasets you find in online courses!
It can also happen that the data you need is simply not there: the tracking of the specific event was never implemented, collection and proper ETLs where implemented recently… I have experienced how this translates into having to wait some months to be able to start a project with enough historic and volume data.
All this relates to the adage “Garbage in, garbage out”: ML models are only as good as the data they’re trained on. Many times, solutions have a bigger potential to be improve by improving the data than by improving the models (Data Centric AI). Data needs to be sufficient in volume, historic (data generated during years can bring more value than the same volume generated in just a week), and quality. To achieve that, mature data governance, collection, cleaning, and preprocessing are critical.
From the ethical AI point of view, data is also a primary source of bias and discrimination, so acknowledging that and taking action to mitigate these risks is paramount. Considering data governance principles, privacy and regulatory compliance (e.g. EU’s GDPR), is also key to ensure a responsible use of data (especially when dealing with personal data).
With GenAI models this is pivoting: huge volumes of data are already used to train them. When using these types of models, we might not need volume and quality data for training, but we might need it for fine-tuning (see Good Data = Good GenAI), or to construct the prompts (nurture the context, few-shot learning, Retrieval Augmented Generation… — I explained all these concepts in a previous post!).
Gender bias example with ChatGPT (prompting on May 1st 2024)
Wrapping it up
We started this blogpost discussing what makes ML Product initiatives especially tricky: the combination of the uncertainty related to developing solutions in digital products, with the uncertainty related to trying to predict things through the use of ML models.
It is comforting to know there are actionable steps and strategies available to mitigate these risks. Yet, perhaps the best ones, are related to starting the initiatives off on the right foot! To do so, it can really help to start with the right problem and an end-to-end design of the solution, reduce initial scope, and prioritize data quality, volume, and historical accuracy.
I hope this post was useful and that it will help you challenge how you start working in future new initiatives related to ML Products!
Today, we’re excited to announce the availability of Meta Llama 3 inference on AWS Trainium and AWS Inferentia based instances in Amazon SageMaker JumpStart. The Meta Llama 3 models are a collection of pre-trained and fine-tuned generative text models. Amazon Elastic Compute Cloud (Amazon EC2) Trn1 and Inf2 instances, powered by AWS Trainium and AWS […]
Today’s NHS faces severe time constraints, with the risk of short consultations and concerns about the risk of misdiagnosis or delayed care. These challenges are compounded by limited resources and overstretched staff that results in protracted patient wait times and generic treatment strategies. Staff can operate with a surface level view of patient data, relying on basic medical histories and recent test results. This lack of comprehensive data interferes with their ability to fully understand patient needs and compromises the accuracy and individualisation of diagnoses and treatments. Such a healthcare approach, characterised by these limitations and engagements, could aptly be…
The unannounced Beats Pill has made another public appearance. This time, it’s caught in the hand of F1 racing driver Daniel Ricciardo.
A Beats Pill-like speaker carried by Daniel Ricciardo [Instagram/F1]
Beats is in the middle of updating its personal audio lineup, including its Beats Solo 4 and Beats Solo Buds. So far, it has yet to announce a speaker, but celebrity leaks are continuing to flow.
A shot posted to the official F1 Instagram account shows racing driver Daniel Ricciardo in Miami holding a Beats speaker by a connected cord. The shot clearly shows the Beats logo in the middle of a speaker that looks like the well-known Pill series.
The HomePod is having an issue understanding the simple query “What time is it?” right now. Apple will probably fix it soon.
You can’t ask Siri what time it is on HomePod for the moment
Users of Siri know that there are many basic queries that could be asked, which result in straightforward results. One common query is to ask Siri the time, which is helpful if the user can’t see a clock nearby.
However, social media users started to report on Tuesday that asking Siri for the time was coming up with a completely different answer on HomePod. In many cases, Siri seems to believe that users want to know about a web result.
Siri on HomePod can’t tell you what time it is right now
Originally appeared here:
Siri on HomePod can’t tell you what time it is right now
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.