Tom Clancy’s XDefiant is almost upon us. Ubisoft is releasing the free-to-play first-person shooter on May 21 for the Xbox Series X|S, the PS5 and PC through Ubisoft Connect. The developer is kicking things off with the preseason version of the game, which is scheduled to last for six weeks before XDefiant’s first season officially starts. Ubisoft announced the game way back in 2021, promising team-based matches with a focus on gunplay that will include elements from other games in the Tom Clancy universe.
The preseason will offer five different game modes with 14 maps, 24 weapons and five playable factions inspired by Ubisoft’s other franchises. Players will need to choose their faction before the match begins and before they respawn. They must also choose their primary and secondary weapon — their options include assault rifles, submachine guns, shotguns and sniper rifles — and a grenade. To customize a weapon, they can add barrel and muzzle attachments, such as sights and grips.
Each faction will give players access to two active abilities, one passive buff and another ultra ability that they have to charge up while the match is ongoing. Libertad, one of the available factions, puts a focus on healing, while members of the Cleaners faction can use fire to burn their opponents. Echelon players can reveal enemy locations with their stealth technology, whereas Phantoms’ abilities can block damage. The last faction available, DedSec, is for those who want to play as hackers.
When the first season launches, Ubisoft is adding four new factions, 12 new weapons and 12 new maps to the game. According to the Year 1 roadmap the developer shared last year, it expects to roll out four seasons with the game’s first year, with each one adding more new content meant to keep players engaged, invested and more likely to come back and keep playing.
This article originally appeared on Engadget at https://www.engadget.com/ubisofts-first-person-shooter-xdefiant-is-launching-on-may-21-074940344.html?src=rss
Extracting and structuring text elements with high accuracy using small models
Image generated by an AI by the author
In this post, I’ll introduce a paradigm recently developed at Anaplan for extracting temporal information from natural language text, as part of an NLQ (natural language query) project. While I will focus on time extraction, the paradigm is versatile and applicable for parsing various unstructured texts and extracting diverse patterns of information. This includes named entity recognition, text-to-SQL conversion, quantity extraction, and more.
The paradigm’s core lies in constructing a flexible pipeline, which provides maximal flexibility, making it easy to fine-tune a model to extract the meaning from any conceivable expression in the language. It is based on a deep learning model (transformers) but for us, it achieved a 99.98% accuracy which is relatively rare for ML methods. Additionally, it does not utilize LLMs (large language models), in fact, it requires a minimal transformer model. This yields a compact, adaptable ML model, exhibiting the precision of rule-based systems.
For those seeking time, numerical value, or phone number extraction, Facebook’s Duckling package offers a rule-based solution. However, if Duckling falls short of your requirements or you’re eager to explore a new ML paradigm, read on.
Can LLMs capture the meaning?
LLMs, despite their capabilities, face challenges in parsing such phrases and extracting their meaning comprehensively. Consider the expression “the first 15 weeks of last year.” Converting this to a date range necessitates the model to determine the current year, subtract one, and calculate the position of the 15th week as it adjusts for leap years. Language models were not built for this kind of computation.
In my experience, LLMs can accurately output the correct date range around 90–95% of the time but struggle with the remaining 5–10%, no matter the prompting techniques you use. Not to mention: LLMs are resource-intensive and slow.
Thankfully, by following three principles, compact transformers can successfully accomplish the task
Separate information extraction from logical deduction.
Auto-generate a dataset using structured patterns.
Constrain the generative AI to the required structure.
In this post, I will cover the first two, as the third one I covered in a previous post.
Separate information extraction from logical deduction
The first principle is to ensure that the language model’s role is to extract information from free text, rather than to make any logical deduction: logical deductions can easily be implemented in code.
Consider the phrase: “How many movies came out two years ago?” The language model’s task should be to identify that the relevant year is: this_year – 2, without calculating the actual year (which means it doesn’t need to know the current year). Its focus is parsing the meaning and structuring unstructured language. Once that formula is extracted, we can implement its calculation in code.
For this to work, we introduce a Structured Time Language (STL) capable of expressing time elements. For instance, “on 2020” translates to “TIME.year==2020,” and “three months from now” becomes “NOW.month==3.” While the entire STL language isn’t detailed here, it should be relatively intuitive: you can reference attributes like year, quarter, and month for an absolute time or relative to NOW. The translation of “the last 12 weeks of last year” is “NOW.year==-1 AND TIME.week>=-12”
By removing any logical deduction or calculation from the task, we take a huge burden off the language model and allow it to focus on information extraction. This division of labor will improve its accuracy significantly. After the translation process is complete, it is straightforward to develop code for a parser that reads the structured language and retrieves the necessary date range.
Since this is a translation task — from natural language to STL — we used an encoder-decoder transformer. We used the Bart model from Hugging Face, which can easily be fine-tuned for this task.
But how do we get the data for training the model?
Auto-generate a dataset using structured patterns
Since a training dataset for this translation task does not exist, we must generate it ourselves. This was done by following these steps:
Step one: Write functions to map datetime objects to both “natural language” and STL formats:
Given a datetime object, these functions return a tuple of free text and its corresponding STL, for instance: “since 2020”, “TIME.year >= 2020”.
Step two: Sample a random function, and sample a random date within a specified range:
date = np.random.choice(pd.date_range('1970/1/1', '2040/12/31'))
now insert the datetime to the function.
Step three: Append the free text to a random question (we can easily randomly generate questions or draw them from some question dataset, their quality and meaning is not very important).
With this pipeline, we can quickly generate 1000s of text-STL pairs, for example:
“What was the GDP growth in Q2–2019?”, “TIME.quarter==2 AND TIME.year==2019”
“Since 2017, who won the most Oscars?”, “TIME.year>=2017”
“Who was the president on 3 May 2020?”, “TIME.date==2020/05/03”
This approach ensures flexibility in adding new patterns effortlessly. If you find a time expression that is not covered by one of these functions (e.g. “In N years”), you can write a function that will generate examples for this pattern within seconds.
In practice, we can optimize the code efficiency further. Rather than separate functions for each pattern like “since 2020” and “until 2020,” we can randomly sample connective words like “since,” “until,” “on,” etc. This initial batch of functions may require some time to develop, but you can quickly scale to 100s of patterns. Subsequently, addressing any missing expressions becomes trivial, as the pipeline is already established. With a few iterations, nearly all relevant expressions can be covered.
Moreover, we don’t need to cover all the expressions: Since the transformer model we used is pre-trained on a huge corpus of text, it will generalize from the provided patterns to new ones.
Finally, we can use an LLM to generate more examples. Simply ask an LLM:
Hey, what's another way to write "What was the revenue until Aug 23"
And it may return:
"How much did we make before August 2023".
This data augmentation process can be automated too: sending numerous examples to an LLM, thus adding variety to our dataset. Given that the LLM’s role is solely in dataset creation, considerations of cost and speed become inconsequential.
Combining the flexibility of adding new patterns, the generalization of the pre-trained model, and data augmentation using an LLM, we can effectively cover almost any expression.
The final principle of this paradigm is to constrain the generative AI to produce only STL queries, ensuring adherence to the required structure. The method to achieve this, as well as a method for optimizing the tokenization process, was discussed in a previous post.
By adhering to these three principles, we achieved an impressive accuracy of 99.98% on our test dataset. Moreover, this paradigm gave us the flexibility to address new, unsupported, time expressions swiftly.
Summary
Large Language Models (LLMs) aren’t always the optimal solution for language tasks. With the right approach, shallower transformer models can efficiently extract information from natural language with high accuracy and flexibility, at a reduced time and cost.
The key principles to remember are:
Focusing the model only on information extraction, avoiding complex logical deductions. This may require generating a mediating language and implementing a parser and logical deduction in code.
Establishing a pipeline for generating a dataset and training a model, so that adding new functionality (new language patterns) is straightforward and fast. This pipeline can include the use of an LLM, adding more variety to the dataset.
Confining the model generation to the constraints of a structured language.
While this post focused on extracting time elements, the paradigm applies to extracting any information from free text and structuring it into various formats. With this paradigm, you can achieve the accuracy of a rule-based engine, with the flexibility of a machine learning model.
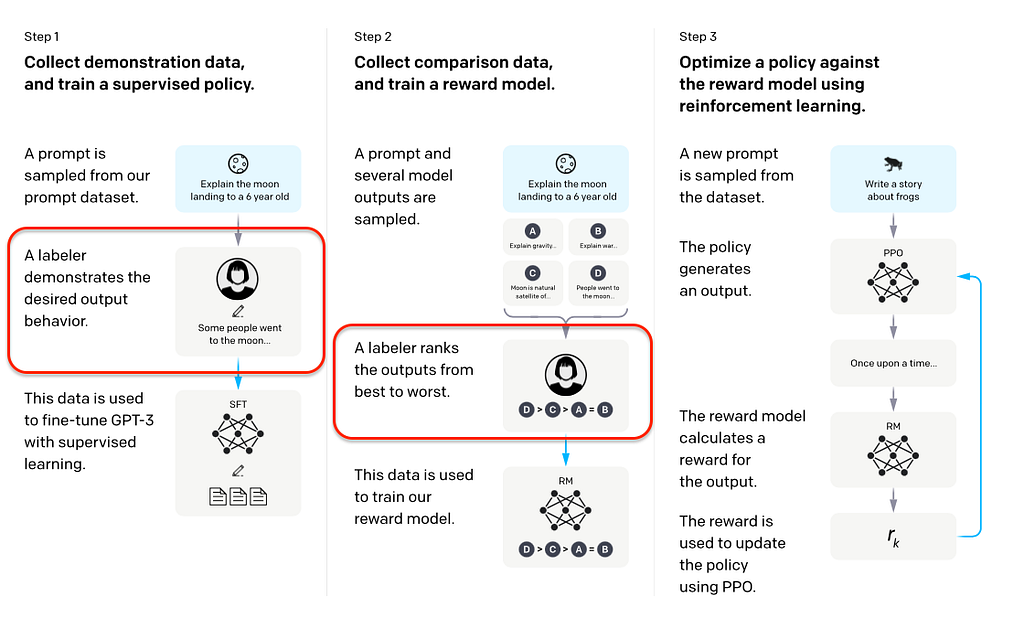
As Large Language Models (LLMs) revolutionize our life, the growth of instruction-tuned LLMs faces significant challenges: the critical need for vast, varied, and high-quality datasets. Traditional methods, such as employing human annotators to generate datasets — a strategy used in InstructGPT (image above)— face high costs, limited diversity, creativity, and allignment challenges. To address these limitations, the Self-Instruct framework² was introduced. Its core idea is simple and powerful: let language models (LM) generate training data, leading to more cost-effective, diverse and creative datasets.
Therefore, in this article, I would like to lead you through the framework step-by-step, demonstrating all the details so that after reading it, you will be able to reproduce the results yourself 🙂
❗ This article provides all steps from code perspective, so please feel free to visit the original GitHub repository .❗
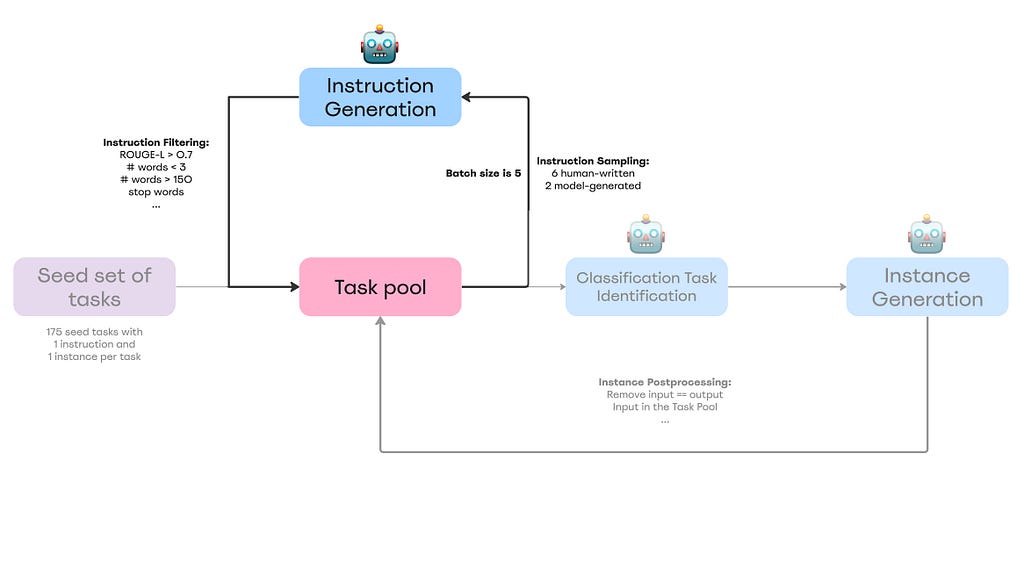
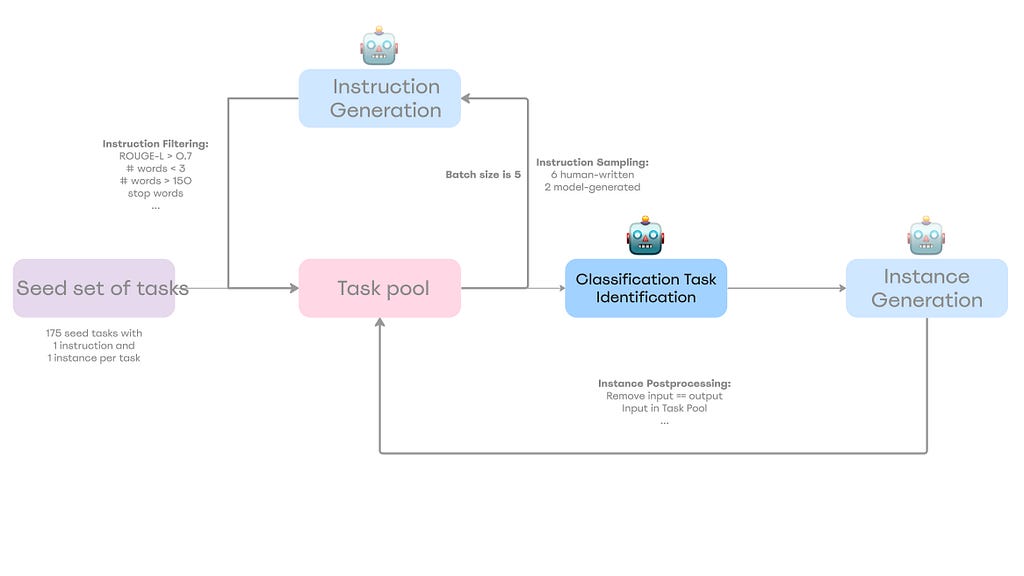
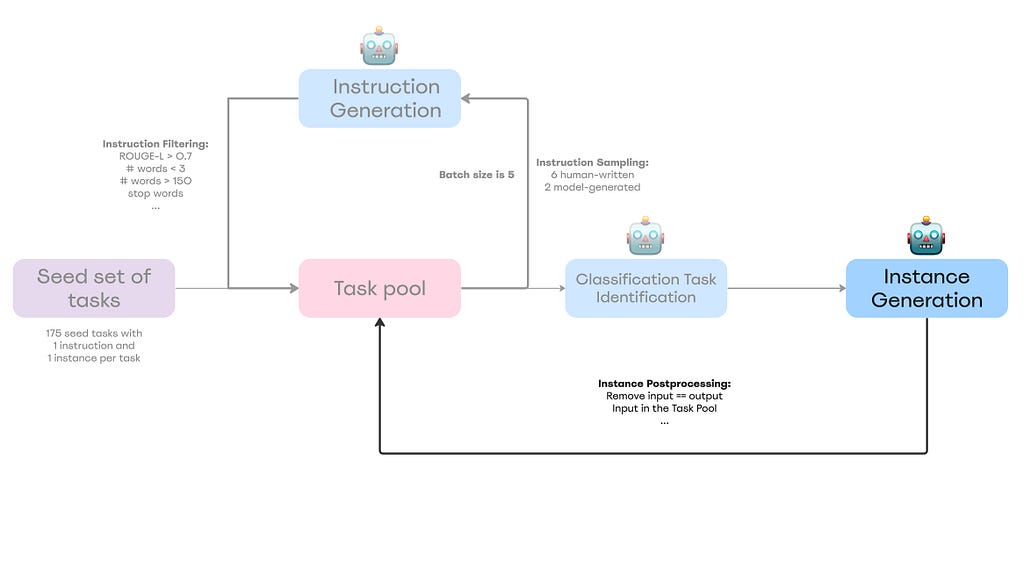
Self-Instruct Framework
A high-level overview of the Self-Instruct framework
The recipe is relatively straightforward:
Step 0 — Define Instruction Data: — Add a seed of high-quality and diverse human-written tasks in different domains as tuples (instruction, instances) to the task pool;
Step 1 — Instruction Generation: — Sample 8 (6 human-written and 2 model-generated) instructions from the task pool; — Insert bootstrapped instructions into the prompt in a few-shot way and ask an LM to come up with more instructions; — Filter generated instructions out based on ROUGE-metric (a method to evaluate the similarity between text outputs and reference texts) and some heuristics (I will cover this later); — Repeat Step 1 until reaching some amount of instructions;
Step 2 — Classification Task Identification: — For every generated instruction in the task pool, we need to identify its type (classification or non-classification) via a few-shot manner;
Step 3 — Instance Generation: — Given the instructions and task types, generate instances (inputs and outputs) and filter them out based on heuristics;
Step 4 — Finetuning the LM to Follow Instructions: — Utilize generated tasks to finetune a pre-trained model.
Voila, that’s how the Self-Instruct works, but the devil is in the details, so let’s dive into every step!
Step 0 — Define Instruction Data
Step 0
Let’s begin by understanding what is inside the initial “Seed of tasks”: it consists of 175 seed tasks (25 classification and 150 non-classifications) with oneinstruction and oneinstance per task in different domains. Each task has an id, name, instruction, instances (input and output), and is_classification binary flag, identifying whether the task has a limited output label space.
There are some examples of classification and non-classification tasks with empty and non-empty input fields:
Example of classification task with non-empty inputExample of non-classification task with empty input
Therefore, we can see in the first example how the input field clarifies and provides context to the more general instruction, while in the second example, we don’t need an input field as long as the instruction is already self-contained. Also, the first example is the classification task — we can answer it by assigning some labels from limited space, while we can’t do the same with the second example.
This step is crucial as long as we encourage task diversity via data formats in the dataset and demonstrate correct ways of solving various tasks.
As long as we define the instruction format, we add them to the task pool to store our final dataset.
Step 1 — Instruction Generation
Step 1
Sampling and prompting
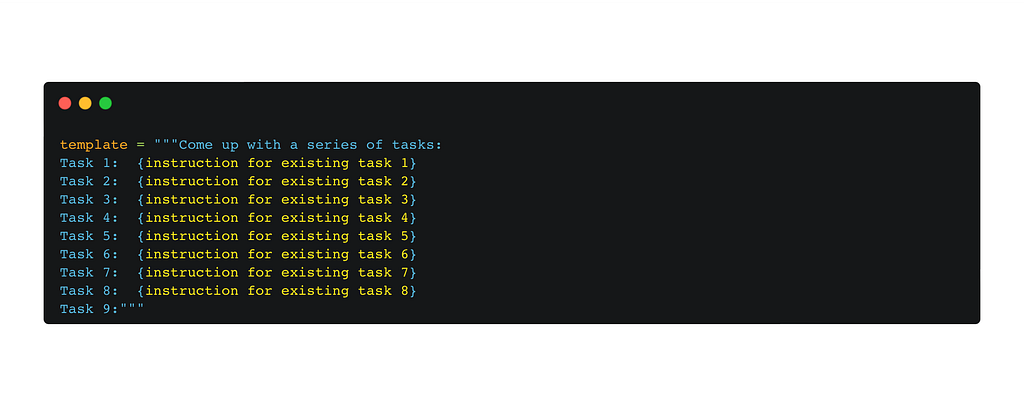
By adding a human-written seed set of tasks to the task pool, we can start with instructions generation. To do so, we need to sample 8 instructions from the task pool (6 human-written and 2 machine-generated) and encode them into the following prompt:
Prompt to generate new instructions
However, in the beginning, we do not have any machine-generated instructions. Therefore, we just replaced them with empty strings in the prompt.
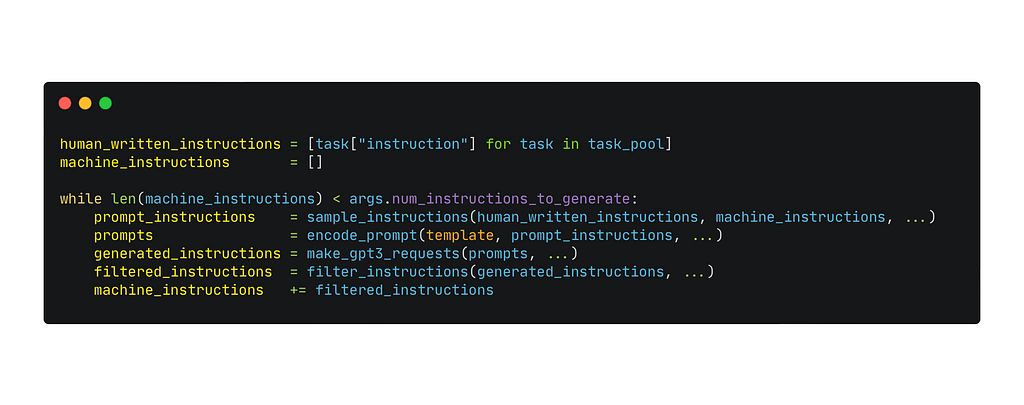
After generation, we extract instructions from the LM’s response (via regular expressions), filter them out, and add filtered instructions to the task pool:
Pseudo-code of instruction generation step
We repeat the instruction generation step until we reach some number of machine-generated instructions (specified at the beginning of the step).
Filtering
To obtain a diverse dataset, we need to define somehow which instructions will be added or not to the task pool, and the easiest way is a heuristically chosen set of rules, for instance:
Filter out instructions that are too short or too long;
Filter based on keywords unsuitable for language models (image, graph, file, plot, …);
Filter those starting with punctuation;
Filter those starting with non-English characters;
Filter those when their ROUGE-L similarity with any existing instruction is higher than 0.7;
Step 2— Classification Task Identification
Step 2
The authors of Self-Instruct noticed that depending on an instruction, the language models can be biased towards one label, especially for classification tasks. Therefore, to eliminate such such, we need to classify every instruction via few-shot prompting:
Prompt used to classify whether a task instruction is a classification or non-classification task (12 classification and 19 non-classification instructions are used in this template)
Step 3 — Instance Generation
Step 3
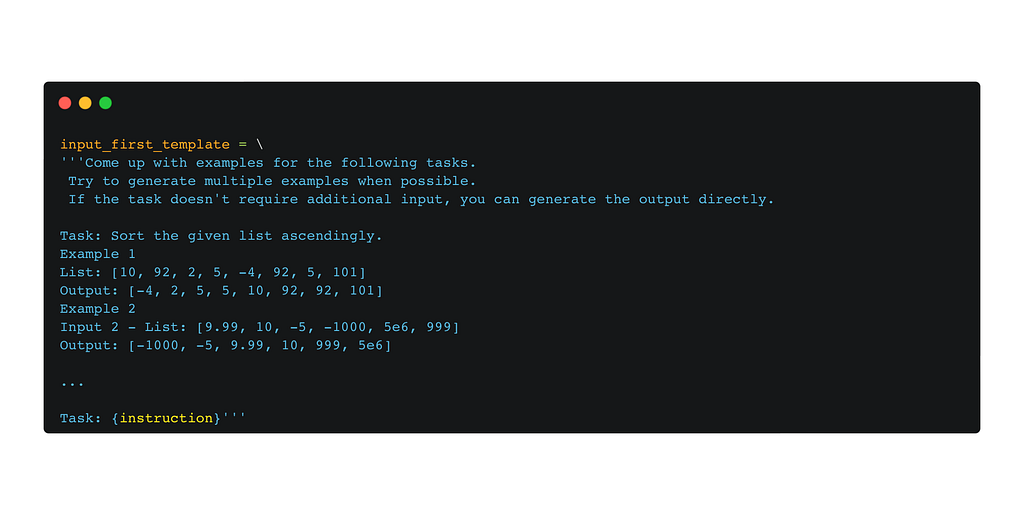
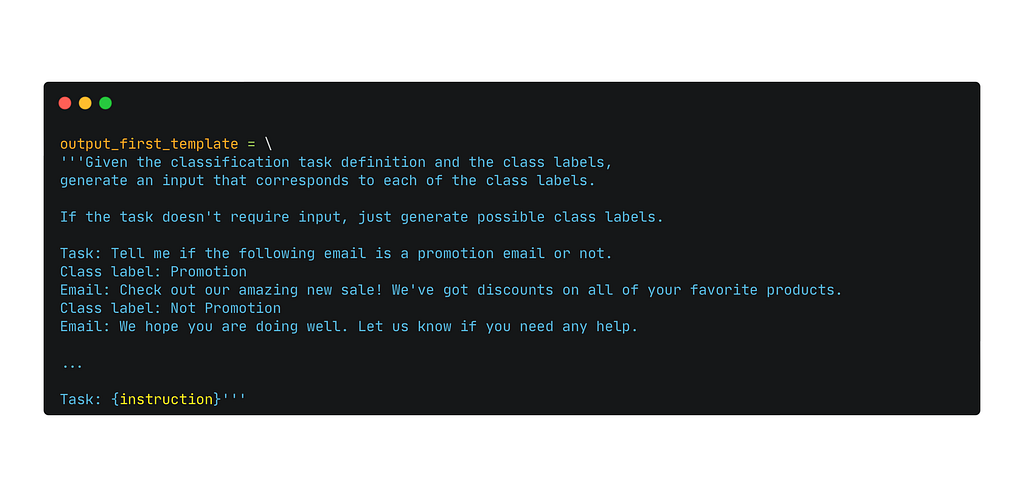
After identifying the instruction type, we can finally generate input and output, considering that we have two types of instructions (classification or non-classification). How? Few-shot prompting!
For non-classification instructions, we ask the model to generate input and only then output (Input-First Approach), but for classification tasks, we ask the model to generate output (class label) first and then condition input generation based on output (Output-First Approach). Compared to Step 0, we don’t restrict the number of generated instances per every instruction.
Prompt used for the Input-First Approach of instance generationPrompt used for the Output-First Approach of instance generation
After generation, we extract instances and format them (regular expressions); after formatting, we filter them out using some rules, for example:
If input and output are the same,
If instances are already in the task pool,
If the output is empty,
These are usually incomplete generations if the input or output ends with a colon;
And some other heuristics. In the end, we have the following example of a generated task with 1 instruction and 1 instance:
Instance generation example
That’s the main idea behind Self-Intsruct!
Step 4— Finetuning the LM to Follow Instructions
After completing all previous steps, we can take a pre-trained LM and instruction-tune it on the generated dataset to achieve better metrics.
Overcoming challenges
At the beginning of the article, I covered some challenges that “instruction-tuned” LLMs face; let’s see how Self-Instruct enables overcoming them.
Quantity
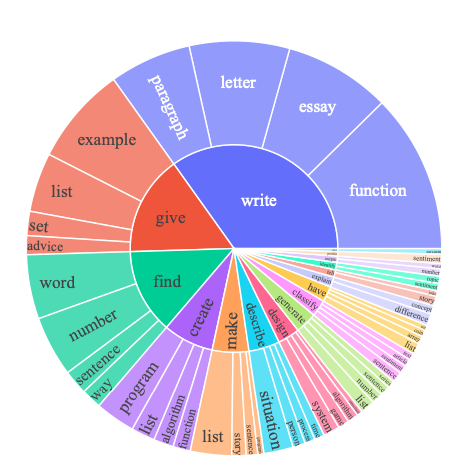
With the help of only 175 initial human-written tasks, 52K instructions and 82K instances were generated:
To investigate how diverse the generated dataset is, authors of Self-Instruct used Berkley Neural Parser to parse instructions and then extract the closest verb to the root and its first direct noun object. 26K out of 52K instructions have a verb-noun format, but the other 26K instructions have more complex structure (e.g., “Classify whether this tweet contains political content or not.”) or are framed as questions (e.g., “Which of these statements are true?”).
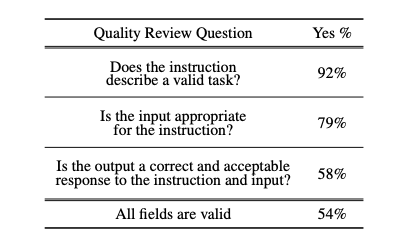
To prove that Self-Instruct can generate high-quality tasks, it was randomly selected 200 generated instructions and sampled 1 instance per instruction, and then the author of the framework assessed them, obtaining the following results:
As we can see, 92% of all tasks describe a valid task, and 54% — have all valid fields (given that we generated 52K tasks, at least 26K will represent high-quality data, which is fantastic!)
Costs
The Self-Instruct framework also introduces significant cost advantages as well. The initial phases of task generation (Steps 1-3 ) amount to a mere $600, while the last step of fine-tuning using the GPT-3 model incurs a cost of $338. It’s vital to keep in mind when we look at results!
Results
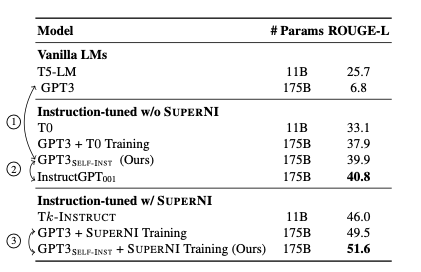
How Self-Instruct can enhance the ROUGE-L metric on the SuperNI (Super-Natural Instructions) dataset? For that, we can compare the results of 1) off-the-shelf pre-trained LMs without any instruction fine-tuning (Vanilla LMs), 2) Instruction-tuned models (Instruction-tuned w/o SuperNI), and 3) Instruction-tuned models trained on SuperNI (Instruction-tuned w/ SuperNI):
As we can see, using Self-Instruct demonstrates a 33% absolute improvement over the original model on the dataset (1); simultaneously, it shows that using the framework can also slightly improve metrics after fine-tuning the SuperNI dataset (3).
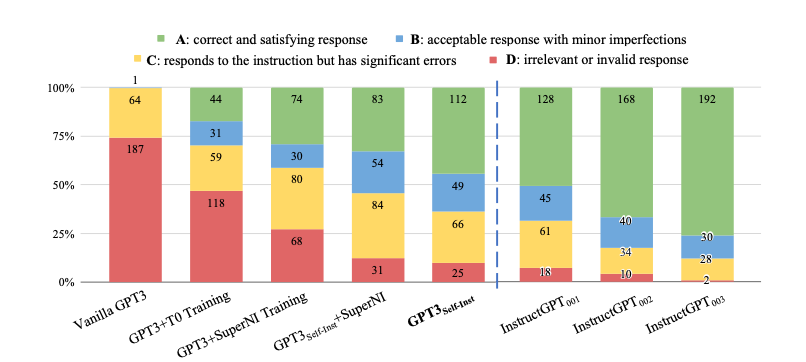
Moreover, if we create a new (=unseen) dataset of 252 instructions and 1 instance per instruction and evaluate a selection of instruction-tuned variants, we can see the following results:
GPT3 + Self-Instruct shows impressive results compared to other instruction-tuned variants, but there is still a place for improvement compared to InstructGPT (previously available LLMs by OpenAI) variants.
Enhancements
The idea behind Self-Instruct is straightforward, but at the same time, it is compelling, so let’s look at how we can use it in different cases.
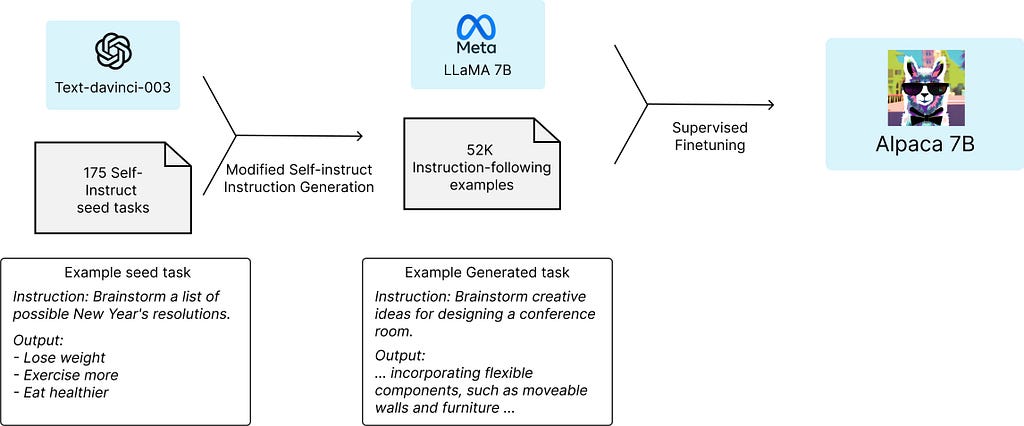
Stanford Alpaca³
In 2023, Alpaca LLM from Stanford gained colossal interest due to affordability, accessibility, and the fact that it was developed for less than $600, and at the same time, it combined LLaMA and Self-Instruct ideas.
Alpaca’s version of Self-Instruct were slightly modified:
Step 1 (instruction generation): more aggressive batch decoding was applied, i.e., generating 20 instructions at once
Step 2 (classification task): this step was wholly excluded
Step 3 (instance generation): only one instance is generated per instruction
In the end, researchers from Stanford could achieve significant improvements in comparison to the initial set-up in Self-Instruct and based on performed a blind pairwise comparison between text-davinci-003 (InstructGPT-003) and Alpaca 7B: Alpaca wins 90 versus 89 comparisons against text-davinci-003.
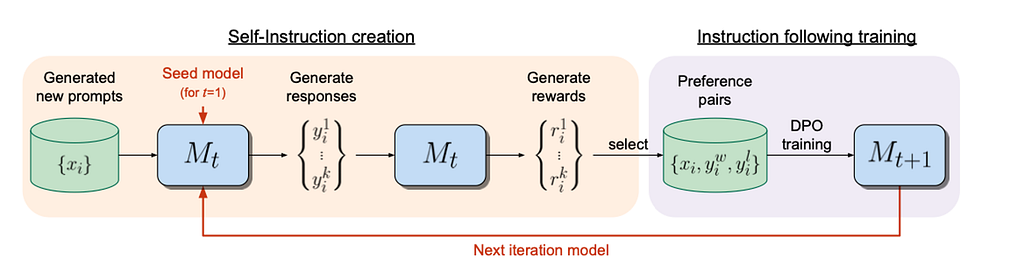
In 2024, Self-Instruct is a practical framework used in more complex set-ups like in Self-Rewarding Language Models by Meta. As in Self-Instruct, initially, we have a seed set of human-written tasks; we then generate new instructions {xᵢ} and prompt model Mₜ to generate outputs {yᵢ¹, …, yᵢᵏ} and later generate rewards {rᵢ¹, …, rᵢᵏ } — that’s how we could ““eliminate”” human-annotators in InstructGPT by self-instruction process. The last block of Self-Rewarding models is instruction following training — on this step, we compose preference pairs and via DPO train Mₜ₊₁ — next iteration model. Therefore, we can repeat this procedure repeatedly to enrich the dataset and improve the initial pre-trained model.
Exploring Limitations
Although Self-Instruct offers an innovative approach to autonomous dataset generation, its reliance on large pre-trained models introduces potential limitations.
Data quality
Despite the impressive capability to generate synthetic data, the quality — marked by a 54% validity in the Overcoming Challenges section — remains a concern. It underscores a critical issue: the biases inherent in pre-trained models could replicate, or even amplify, within the generated datasets.
Tail phenomena
Instructions vary in frequency: some instructions are frequently requested, while others are rare. Nonetheless, it’s crucial to effectively manage these infrequent requests, as they highlight the brittleness of LLMs in processing uncommon and creative tasks.
Conclusion
In conclusion, the Self-Instruct framework represents an advancement in developing instruction-tuned LMs, offering an innovative solution to the challenges of dataset generation. Enabling LLMs to autonomously produce diverse and high-quality data significantly reduces dependency on human annotators, therefore driving down costs.
Unless otherwise noted, all images are by the author, inspired by Self-Instruct 🙂
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.