An intro to expert guide on using Gradio to demonstrate product value to expert and non-technical audiences.

We have all experienced at least one demo that has fallen flat. This is particularly a problem in data science, a field where a lot can go wrong on the day. Data scientists often have to balance challenges when presenting to audiences with varying experience levels. It can be challenging to both show the value and explain core concepts of a solution to a wide audience.
This article aims to help overcome the hurdles and help you share your hard work! We always work so hard to improve models, process data, and configure infrastructure. It’s only fair that we also work hard to make sure others see the value in that work. We will explore using the Gradio tool to share AI products. Gradio is an important part of the Hugging Face ecosystem. It’s also used by Google, Amazon and Facebook so you’ll be in great company! Whilst we will use Gradio, a lot of the key concepts can be replicated in common alternatives like StreamLit with Python or Shiny with R.
The importance of stakeholder/customer engagement in data science
The first challenge when pitching is ensuring that you are pitching at the right level. To understand how your AI model solves problems, customers first need to understand what it does, and what the problems are. They may have a PhD in data science, or they may never have heard of a model before. You don’t need to teach them linear algebra nor should you talk through a white paper of your solution. Your goal is to convey the value added by your solution, to all audiences.
This is where a practical demo comes in. Gradio is a lightweight open source package for making practical demos [1]. It is well documented that live demos can feel more personal, and help to drive conversation/generate new leads [2]. Practical demos can be crucial in building trust and understanding with new users. Trust builds from seeing you use the tool, or even better testing with your own inputs. When users can demo the tool they know there is no “Clever Hans” [3] process going on and what they see is what they get. Understanding grows from users seeing the “if-this-then-that” patterns in how your solution operates.
Then comes the flipside … everyone has been to a bad live demo. We have all sat through or made others sit through technical difficulties.
But technical difficulties aren’t the only thing that give us reason to fear live demos. Some other common off-putting factors are:
- Information dumping: Pitching to customers should never feel like a lecture. Adding demos that are inaccessible can give customers too much to learn too quickly.
- Developing a demo: Demos can be slow to build and actually slow down development. Regularly feeding back in “show and tells” is a particular problem for agile teams. Getting content for the show and tell can be an ordeal. Especially if customers grow accustomed to a live demo.
- Broken dependencies: If you are responsible for developing a demo you might rely on some things staying constant. If they change you’ll need to start again.
Introducing Gradio
Now to the technical part. Gradio is a framework for demonstrating machine learning/AI models and it integrates with the rest of the Hugging Face ecosystem. The framework can be implemented using Python or JavaScript SDKs. Here, we will use Python. Before we build a demo an example Gradio app for named entity recognition is below:

You can implement Gradio anywhere you currently work, and this is a key benefit of using the framework. If you are quickly prototyping code in a notebook and want instant feedback from stakeholders/colleagues you can add a Gradio interface. In my experience of using Gradio, I have implemented in Jupyter and Google Colab notebooks. You can also implement Gradio as a standalone site, through a public link hosted on HuggingFace. We will explore deployment options later.
Gradio demos help us solve the problems above, and get us over the fear of the live demo:
- Information dumping: Gradio provides a simple interface that abstracts away a lot of the difficult information. Customers aren’t overloaded with working out how to interact with our tool and what the tool is all at once.
- Developing a demo: Gradio demos have the same benefits as StreamLit and Shiny. The demo code is simple and builds on top of Python code you have already written for your product. This means you can make changes quickly and get instant feedback. You can also see the demo from the customer point of view.
- Broken dependencies: No framework will overcome complete project overhauls. Gradio is built to accomodate new data, data types and even new models. The simplicity and range of allowed inputs/outputs, means that Gradio demos are kept quite constant. Not only that but if you have many tools, many customers and many projects the good news is that most of your demo code won’t change! You can just swap a text output to an image output and you’re all set up to move from LLM to Stable Diffusion!
Step-by-step guide to creating a demo using Gradio
The practical section of this article takes you from complete beginner to demonstration expert in Gradio. That being said, sometimes less can be more, if you are looking for a really simple demo to highlight the impact of your work by all means, stick to the basics!
For more information on alternatives like StreamLit, check out my earlier post:
Building Lightweight Geospatial Data Viewers with StreamLit and PyDeck
The basics
Let’s start with a Hello World style example so that we can learn more about what makes up a Gradio demo. We have three fundamental components:
- Input variables: We provide any number of input variables which users can input using toggles, sliders or other input widgets in our demo.
- Function: The author of the demo makes a function which does the heavy lifting. This is where code changes between demos the most. The function will transform input variables into an output that the user sees. This is where we can call a model, transform data or do anything else we may need.
- Interface: The interface combines the input variables, input widgets, function and output widgets into one demo.
So let’s see how that looks in code form:
This gives us the following demo. Notice how the input and output are both of the text type as we defined above:

Now that we understand the basic components of Gradio, let’s get a bit more technical.
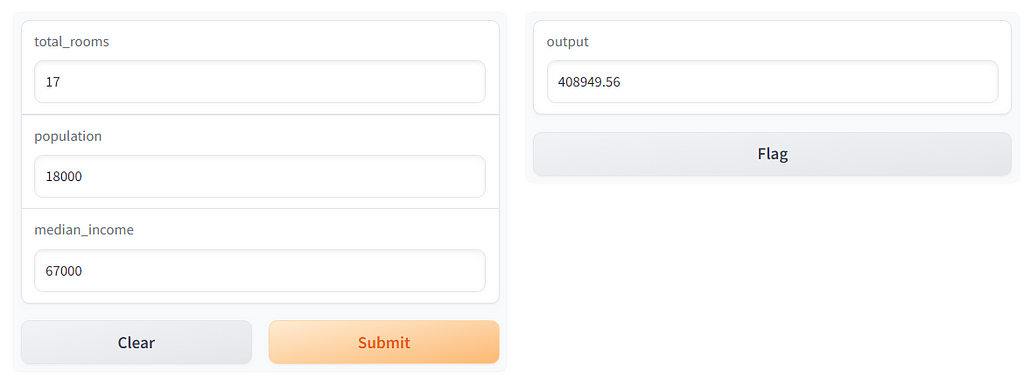
To see how we can apply Gradio to a machine learning problem, we will use the simplest algorithm we can. A linear regression. For the first example. We will build a linear regression using the California House Prices dataset. First, we update the basic code so that the function makes a prediction based on a linear model:
Then we update the interface so that the inputs and outputs match what we need. Note that we also use the Number type here as an input:
Then we hit run and see how it looks:
Why stop now! We can use Blocks in Gradio to make our demos even more complex, insightful and engaging.
Controlling the interface
Blocks are more or less exactly as described. They are the building blocks of Gradio applications. So far, we have only used the higher level Interface wrapper. In the example below we will use blocks which has a slightly different coding pattern. Let’s update the last example to use blocks so that we can understand how they work:
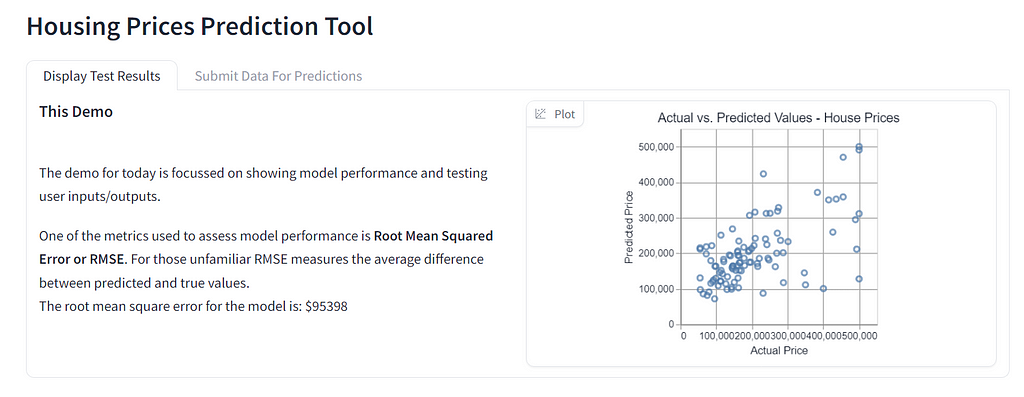
Instead of before when we had inputs, function and interface. We have now rolled everything back to its most basic form in Gradio. We no longer set up an interface and ask for it to add number inputs for us! Now we provide each individual Number input and one Number output. Building like this gives us much more control of the display.
With this new control over the demo we can even add new tabs. Tabs enable us to control the user flows and experience. We can first explain a concept, like how our predictions are distributed. Then on the next tab, we have a whole new area to let users prompt the model for predictions of their own. We can also use tabs to overcome technical difficulties. The first tab gives users a lot of information about model performance. This is all done through functions that were implemented earlier. If the model code doesn’t run on the day we still have something insightful to share. It’s not perfect, but it’s a lot better than a blank screen!
Note: This doesn’t mean we can hide technical difficulties behind tabs! We can just use tabs to give audiences something to go on if all else fails. Then reshare the demo when we resolve the technical issues.
Ramping up the complexity shows how useful Gradio can be to show all kinds of information! So far though we have kept to a pretty simple model. Let’s now explore how we would use Gradio for something a bit more complex.
Gradio for AI Models and Images
The next application will look at using Gradio to demonstrate Generative AI. Once again, we will use Blocks to build the interface. This time the demo will have two core components:
- An intro tab explaining the limitations, in and out of scope uses of the model.
- An inspiration tab showing some images generated earlier.
- An interactive tab where users can submit prompts to generate images.
In this blog we will just demo a pre-trained model. To learn more about Stable Diffusion models, including key concepts and fine-tuning, check out my earlier blog:
Stable Diffusion: How AI converts text to images
As this is a demo, we will start from the most difficult component. This ensures we will have the most time to deliver the hardest piece of work. The interactive tab is likely to be the most challenging, so we will start there. So that we have an idea of what we are aiming for our demo page will end up looking something like this:

To achieve this the demo code will combine the two examples above. We will use blocks, functions, inputs and buttons. Buttons enable us to work in a similar way to before where we have inputs, outputs and functions. We use buttons as event listeners. Event listeners help to control our logic flow.
Let’s imagine we are trying to start our demo. At runtime (as soon as the demo starts), we have no inputs. As we have no input, the model the demo uses has no prompt. With no prompt, the model cannot generate an image. This will cause an error. To overcome the error we use an event listener. The button listens for an event, in this case, a click of the button. Once it “hears” the event, or gets clicked, it then triggers an action. In this case, the action will be submitting a completed prompt to the model.
Let’s review some new code that uses buttons and compare it to the previous interface examples:
The button code looks like the interface code, but there are some big conceptual changes:
- The button code uses blocks. This is because whilst we are using the button in a similar way to interface, we still need something to determine what the demo looks like.
- Input and output widgets are used as objects instead of strings. If you go back to the first example, our input was “text” of type string but here it is prompt of type gr.Text().
- We use button.click() instead of Interface.launch(). This is because the interface was our whole demo before. This time the event is the button click.
This is how the demo ends up looking:

Can you see how important an event listener is! It has saved us lots of work in trying to make sure things happen in the right order. The beauty of Gradio means we also get some feedback on how long we will have to wait for images. The progress bar and time information on the left are great for user feedback and engagement.
The next part of the demo is sharing images we generated beforehand. This will serve as inspiration to customers. They will be able to see what is possible from the tool. For this we will implement another new output widget, a Gallery. The gallery displays the images we just generated:
An important note: We actually make use of our generate_images() function from before. As we said above, all of these lightweight app libraries enable us to simply build on top of our existing code.
The demo now looks like this, users are able to switch between two core functionalities:

Finally we will tie everything together with a landing page for the demo. In a live or recorded demo the landing page will give us something to talk through. It’s useful but not essential. The main reason we include a landing page, is for any users that will test the tool without us being present. This helps to build accessibility of the tool and trust and understanding in users. If you need to be there every time customers use your product, it’s not going to deliver value.
This time we won’t be using anything new. Instead we will show the power of the Markdown() component. You may have noticed we have used some Markdown already. For those familiar, Markdown can help express all kinds of information in text. The code below has some ideas, but for your demos, get creative and see how far you can take Markdown in Gradio:

The finished demo is below. Let me know what you think in the comments!



Sharing with customers
Whether you’re a seasoned pro, or pitching beginner sharing the demo can be daunting. Building demonstrations and pitching are two very different skillsets. This article so far has helped to build your demo. There are great resources online to help pitching [5]. Let’s now focus on the intersection of the two, how you can share the demo you built, effectively.
Baring in mind your preferred style, live demo is guaranteed to liven up your pitch (pun intended!). To a technical audience we can set off our demo right in our notebook. This is useful to those who want to get into the code. I recommend sharing this way with new colleagues, senior developers and anyone looking to collaborate or expand your work. If you are using an alternative to Gradio, I’d still recommend sharing your code at a high level with this audience. It can help bring new developers onboard, or explain your latest changes to senior developers.
An alternative is to present the live demo using just a “front-end”. This can be done using the link provided when you run the demo. When you share this way customers don’t have to get bogged down in code to see your demo. This is how the screenshots so far have been taken. I’d recommend this for live non-technical audiences, new customers and for agile feedback/show and tell sessions. We can get to this using a link provided if you built your demo in Gradio.
The link we can use to share also allows us to share the demo with others. By setting a share parameter when we launch the demo:
demo.launch(debug=True, share=True)
This works well for users who can’t make the live session, or want more time to experiment with the product. This link is available for 72 hours. There is a need for caution at this point as demos are hosted publicly from your machine. It is advised that you consider the security aspects of your system before sharing this way. One thing we can do to make this a bit more secure is to share our demo with password protection:
demo.launch(debug=True, auth=('trusted_user', 'trusted123'))
This adds a password pop-up to the demo.
You can take this further by using authorisation techniques. Examples include using Hugging Face directly or Google for OAuth identity providers [6]. Further protections can be put in place for blocked files and file paths on the host machine [6].
This does not solve security concerns with sharing this way completely. If you are looking to share privately, containerisation through a cloud provider may be a better option [7].
For wider engagement, you may want to share your demo publicly to an online audience. This can be brilliant for finding prospective customers, building word of mouth or getting some feedback on your latest AI project. I have been sharing work publicly for feedback for years on Medium, Kaggle and GitHub. The feedback I have had has definitely improved my work over time.
If you are using Gradio demos can be publicly shared through Hugging Face. Hugging Face provides Spaces which are used for sharing Gradio apps. Spaces provide a free platform to share your demo. There are costs attached to GPU instances (ranging from $0.40 to $5 per hour). To share to spaces, the following documentation is available [6]. The docs explain how you can:
- Share to spaces
- Implement CI/CD of spaces with GitHub actions
- Embedding Gradio demos in your own website from spaces!
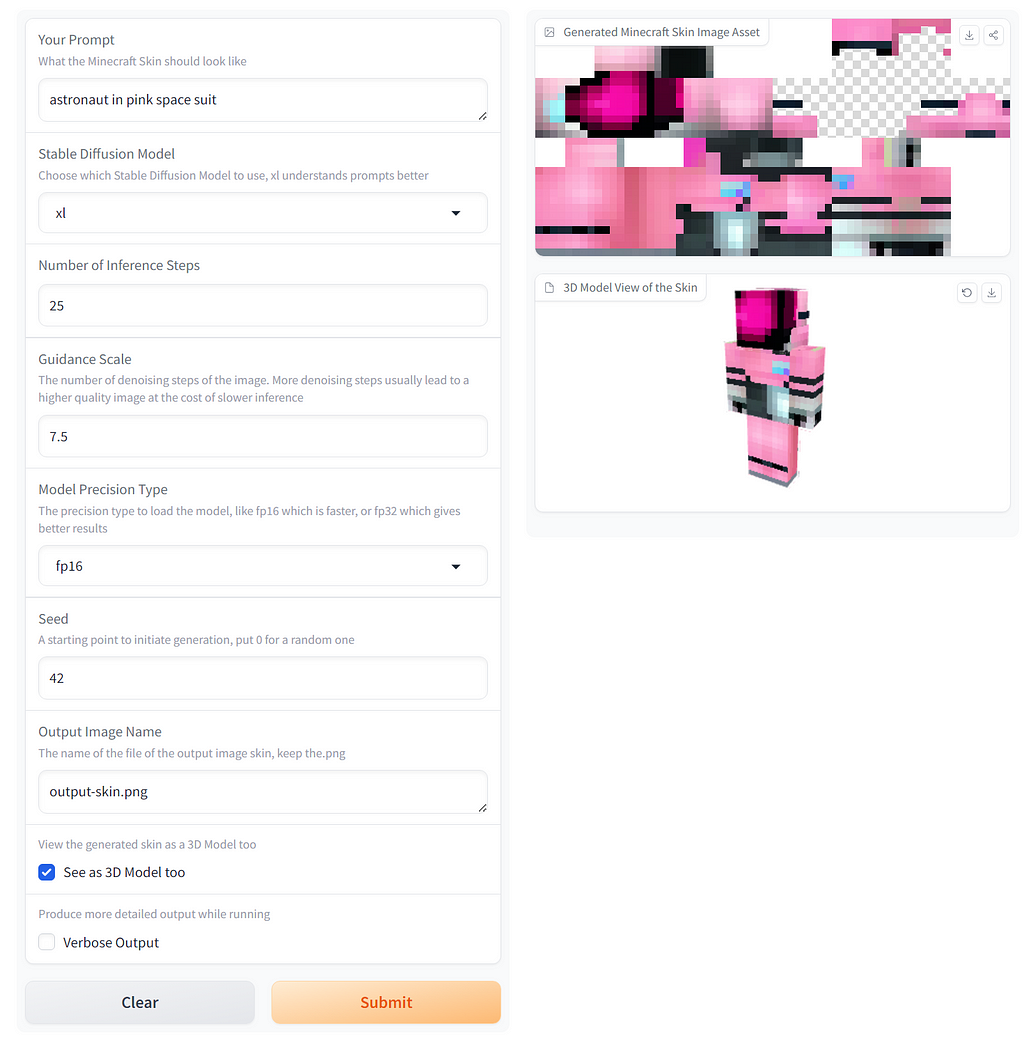
Spaces are helpful for reaching a wider audience, without worrying about resources. It is also a permanent link for prospective customers. It does make it more important to include as much guidance as possible. Again, this is a public sharing platform on compute you do not own. For more secure requirements, containerisation and dedicated hosting may be preferred. A particularly great example is this Minecraft skin generator [8].
Additional considerations
The elephant in the room in the whole AI community right now is of course LLMs. Gradio has plenty of components built with LLM in mind. This includes using agentic workflows and models as a service [9].
It is also worth mentioning custom components. Custom components have been developed by other data scientists and developers. They are extensions on top of the Gradio framework. Some great examples are:
- Image annotation component: gradio_image_annotation V0.0.6 — a Hugging Face Space by edgargg
- Question answering with an uploaded PDF: gradio_pdf V0.0.6 — a Hugging Face Space by awacke1
Extensions are not unique to Gradio. If you choose to use StreamLit or Shiny to build your demo there are great extensions to those frameworks as well:
- StreamLit Extras, an extension of the StreamLit UI components: https://extras.streamlit.app/
- Awesome R Shiny, additional reactive/UI/theming components for Shiny: https://github.com/nanxstats/awesome-shiny-extensions
A final word on sharing work, in an agile context. When sharing regularly through show and tells or feedback sessions lightweight demos are a game changer. The ability to easily layer on from MVP to final product really helps customers see their journey with your product.
In summary, Gradio is a lightweight, open source tool for sharing AI products. Some important security steps may need consideration depending on your requirements. I really hope you are feeling more prepared with your demos!
If you enjoyed this article please consider giving me a follow, sharing this article or leaving a comment. I write a range of content across the data science field, so please checkout more on my profile.
References
[1] Gradio Documentation. https://www.gradio.app/
[2] User Pilot Product Demos. https://userpilot.com/blog/product-demos/
[3] Clever Hans Wikipedia. https://en.wikipedia.org/wiki/Clever_Hans
[4] Gradio Named Entity Recognition App. Named Entity Recognition (gradio.app)
[5] Harvard Business Review. What makes a great pitch. What Makes a Great Pitch (hbr.org)
[6] Gradio Deploying to Spaces. Sharing Your App (gradio.app).
[7] Deploying Gradio to Docker. Deploying Gradio With Docker
[8] Amazing Minecraft Skin Generator Example. Stable Diffusion Finetuned Minecraft Skin Generator — a Hugging Face Space by Nick088
[9] Gradio for LLM. Gradio And Llm Agents
Demo AI Products Like a Pro was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Demo AI Products Like a Pro