
Palit’s Pandora can be used for AI inference, machine learning and robotics.
Originally appeared here:
Key Nvidia partner unveils a tiny mini PC build for AI that has a unique feature: 3D-printed designs

Originally appeared here:
Key Nvidia partner unveils a tiny mini PC build for AI that has a unique feature: 3D-printed designs
Go Here to Read this Fast! Myanmar enforces new cybersecurity law – and VPN usage is the main target
Originally appeared here:
Myanmar enforces new cybersecurity law – and VPN usage is the main target
Go Here to Read this Fast! Everything new on Paramount Plus in January 2025
Originally appeared here:
Everything new on Paramount Plus in January 2025
Go Here to Read this Fast! Thomson Reuters just spent $600m on a tax automation start-up
Originally appeared here:
Thomson Reuters just spent $600m on a tax automation start-up
Go Here to Read this Fast! Japan’s largest telco NTT Docomo disrupted by DDoS attack
Originally appeared here:
Japan’s largest telco NTT Docomo disrupted by DDoS attack
LucianoSphere (Luciano Abriata, PhD)
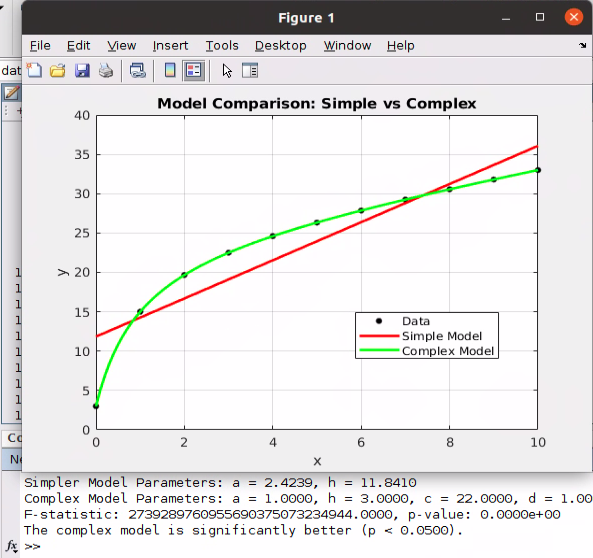
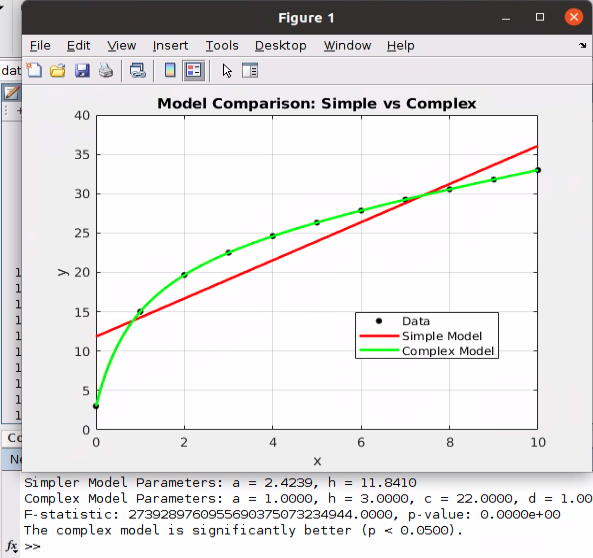
Diving into the F-test for nested models with algorithms, examples and code
Originally appeared here:
How to Tell Among Two Regression Models with Statistical Significance
Go Here to Read this Fast! How to Tell Among Two Regression Models with Statistical Significance

In my prior column, I established how AI generated content is expanding online, and described scenarios to illustrate why it’s occurring. (Please read that before you go on here!) Let’s move on now to talking about what the impact is, and what possibilities the future might hold.
Human beings are social creatures, and visual ones as well. We learn about our world through images and language, and we use visual inputs to shape how we think and understand concepts. We are shaped by our surroundings, whether we want to be or not.
Accordingly, no matter how much we are consciously aware of the existence of AI generated content in our own ecosystems of media consumption, our subconscious response and reaction to that content will not be fully within our control. As the truism goes, everyone thinks they’re immune to advertising — they’re too smart to be led by the nose by some ad executive. But advertising continues! Why? Because it works. It inclines people to make purchasing choices that they otherwise wouldn’t have, whether just from increasing brand visibility, to appealing to emotion, or any other advertising technique.
AI-generated content may end up being similar, albeit in a less controlled way. We’re all inclined to believe we’re not being fooled by some bot with an LLM generating text in a chat box, but in subtle or overt ways, we’re being affected by the continued exposure. As much as it may be alarming that advertising really does work on us, consider that with advertising the subconscious or subtle effects are being designed and intentionally driven by ad creators. In the case of generative AI, a great deal of what goes into creating the content, no matter what its purpose, is based on an algorithm using historical information to choose the features most likely to appeal, based on its training, and human actors are less in control of what that model generates.
I mean to say that the results of generative AI routinely surprise us, because we’re not that well attuned to what our history really says, and we often don’t think of edge cases or interpretations of prompts we write. The patterns that AI is uncovering in the data are sometimes completely invisible to human beings, and we can’t control how these patterns influence the output. As a result, our thinking and understanding are being influenced by models that we don’t completely understand and can’t always control.
Beyond that, as I’ve mentioned, public critical thinking and critical media consumption skills are struggling to keep pace with AI generated content, to give us the ability to be as discerning and thoughtful as the situation demands. Similarly to the development of Photoshop, we need to adapt, but it’s unclear whether we have the ability to do so.
We are all learning tell-tale signs of AI generated content, such as certain visual clues in images, or phrasing choices in text. The average internet user today has learned a huge amount in just a few years about what AI generated content is and what it looks like. However, suppliers of the models used to create this content are trying to improve their performance to make such clues subtler, attempting to close the gap between obviously AI generated and obviously human produced media. We’re in a race with AI companies, to see whether they can make more sophisticated models faster than we can learn to spot their output.
We’re in a race with AI companies, to see whether they can make more sophisticated models faster than we can learn to spot their output.
In this race, it’s unclear if we will catch up, as people’s perceptions of patterns and aesthetic data have limitations. (If you’re skeptical, try your hand at detecting AI generated text: https://roft.io/) We can’t examine images down to the pixel level the way a model can. We can’t independently analyze word choices and frequencies throughout a document at a glance. We can and should build tools that help do this work for us, and there are some promising approaches for this, but when it’s just us facing an image, a video, or a paragraph, it’s just our eyes and brains versus the content. Can we win? Right now, we often don’t. People are fooled every day by AI-generated content, and for every piece that gets debunked or revealed, there must be many that slip past us unnoticed.
One takeaway to keep in mind is that it’s not just a matter of “people need to be more discerning” — it’s not as simple as that, and if you don’t catch AI generated materials or deepfakes when they cross your path every time, it’s not all your fault. This is being made increasingly difficult on purpose.
So, living in this reality, we have to cope with a disturbing fact. We can’t trust what we see, at least not in the way we have become accustomed to. In a lot of ways, however, this isn’t that new. As I described in my first part of this series, we kind of know, deep down, that photographs may be manipulated to change how we interpret them and how we perceive events. Hoaxes have been perpetuated with newspapers and radio since their invention as well. But it’s a little different because of the race — the hoaxes are coming fast and furious, always getting a little more sophisticated and a little harder to spot.
We can’t trust what we see, at least not in the way we have become accustomed to.
There’s also an additional layer of complexity in the fact that a large amount of the AI generated content we see, particularly on social media, is being created and posted by bots (or agents, in the new generative AI parlance), for engagement farming/clickbait/scams and other purposes as I discussed in part 1 of this series. Frequently we are quite a few steps disconnected from a person responsible for the content we’re seeing, who used models and automation as tools to produce it. This obfuscates the origins of the content, and can make it harder to infer the artificiality of the content by context clues. If, for example, a post or image seems too good (or weird) to be true, I might investigate the motives of the poster to help me figure out if I should be skeptical. Does the user have a credible history, or institutional affiliations that inspire trust? But what if the poster is a fake account, with an AI generated profile picture and fake name? It only adds to the challenge for a regular person to try and spot the artificiality and avoid a scam, deepfake, or fraud.
As an aside, I also think there’s general harm from our continued exposure to unlabeled bot content. When we get more and more social media in front of us that is fake and the “users” are plausibly convincing bots, we can end up dehumanizing all social media engagement outside of people we know in analog life. People already struggle to humanize and empathize through computer screens, hence the longstanding problems with abuse and mistreatment online in comments sections, on social media threads, and so on. Is there a risk that people’s numbness to humanity online worsens, and degrades the way they respond to people and models/bots/computers?
How do we as a society respond, to try and prevent being taken in by AI-generated fictions? There’s no amount of individual effort or “do your homework” that can necessarily get us out of this. The patterns and clues in AI-generated content may be undetectable to the human eye, and even undetectable to the person who built the model. Where you might normally do online searches to validate what you see or read, those searches are heavily populated with AI-generated content themselves, so they are increasingly no more trustworthy than anything else. We absolutely need photographs, videos, text, and music to learn about the world around us, as well as to connect with each other and understand the broader human experience. Even though this pool of material is becoming poisoned, we can’t quit using it.
There are a number of possibilities for what I think might come next that could help with this dilemma.
I think it very unlikely that generative AI will continue to gain sophistication at the rate seen in 2022–2023, unless a significantly different training methodology is developed. We are running short of organic training data, and throwing more data at the problem is showing diminishing returns, for exorbitant costs. I am concerned about the ubiquity of AI-generated content, but I (optimistically) don’t think these technologies are going to advance at more than a slow incremental rate going forward, for reasons I have written about before.
This means our efforts to moderate the negative externalities of generative AI have a pretty clear target. While we continue to struggle with difficulty detecting AI-generated content, we have a chance to catch up if technologists and regulators put the effort in. I also think it is vital that we work to counteract the cynicism this AI “slop” inspires. I love machine learning, and I’m very glad to be a part of this field, but I’m also a sociologist and a citizen, and we need to take care of our communities and our world as well as pursuing technical progress.
Read more of my work at www.stephaniekirmer.com.
https://dl.acm.org/doi/pdf/10.1145/3637528.3671463
https://arxiv.org/pdf/2402.00045
https://iris.uniroma1.it/bitstream/11573/1710645/1/Maiano_Human_2024.pdf
https://dl.acm.org/doi/abs/10.1145/3658644.3670306
https://www.cis.upenn.edu/~ccb/publications/miragenews.pdf
The Cultural Impact of AI Generated Content: Part 2 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
The Cultural Impact of AI Generated Content: Part 2
Go Here to Read this Fast! The Cultural Impact of AI Generated Content: Part 2


Understanding Different Types of Chi-Squared Tests: A/B Testing for Data Science Series (8)
Originally appeared here:
Chi-Squared Test: Comparing Variations Through Soccer
Go Here to Read this Fast! Chi-Squared Test: Comparing Variations Through Soccer


Making you a better data scientist, and enhancing your career.
Originally appeared here:
Non-Technical Principles All Data Scientists Should Have
Go Here to Read this Fast! Non-Technical Principles All Data Scientists Should Have


I’ve been working on updates for my 2025 class on Values and Ethics in Artificial Intelligence. This course is part of the Johns Hopkins Education for Professionals program, part of the Master’s degree in Artificial Intelligence.
I’m doing major updates on three topics based on 2024 developments, and a number of small updates, integrating other news and filling gaps in the course.
Anthropic’s work in interpretability was a breakthrough in explainable AI (XAI). We will be discussing how this method can be used in practice, as well as implications for how we think about AI understanding.
Rapid AI development adds urgency to the question: How do we design AI to empower rather than replace human beings? I have added content throughout my course on this, including two new design exercises.
Major developments were the EU’s AI Act and the raft of California legislation, including laws targeting deep fakes, misinformation, intellectual property, medical communications and minor’s use of ‘addictive’ social media, among other. For class I developed some heuristics for evaluating AI legislation, such as studying definitions, and explain how legislation is only one piece of the solution to the AI governance puzzle.

I am integrating material from news stories into existing topics on copyright, risk, privacy, safety and social media/ smartphone harms.
What’s new:
Anthropic’s pathbreaking 2024 work on interpretability was a fascination of mine. They published a blog post here, and there is also a paper, and there was an interactive feature browser. Most tech-savvy readers should be able to get something out of the blog and paper, despite some technical content and a daunting paper title (‘Scaling Monosemanticity’).
Below is a screenshot of one discovered feature, ‘syncophantic praise’. I like this one because of the psychological subtlety; it amazes me that they could separate this abstract concept from simple ‘flattery’, or ‘praise’.

What’s important:
Explainable AI: For my ethics class, this is most relevant to explainable AI (XAI), which is a key ingredient of human-centered design. The question I will pose to the class is, how might this new capability be used to promote human understanding and empowerment when using LLMs? SAEs (sparse autoencoders) are too expensive and hard to train to be a complete solution to XAI problems, but they can add depth to a multi-pronged XAI strategy.
Safety implications: Anthropic’s work on safety is also worth a mention. They identified the ‘syncophantic praise’ feature as part of their work on safety, specifically relevant to this question: could a very powerful AI hide its intentions from humans, possibly by flattering users into complacency? This general direction is especially salient in light of this recent work: Frontier Models are Capable of In-context Scheming.
Evidence of AI ‘Understanding’? Did interpretability kill the ‘stochastic parrot’? I have been convinced for a while that LLMs must have some internal representations of complex and inter-related concepts. They could not do what they do as one-deep stimulus-response or word-association engines, (‘stochastic parrots’) no matter how many patterns were memorized. The use of complex abstractions, such as those identified by Anthropic, fits my definition of ‘understanding’, although some reserve that term only for human understanding. Perhaps we should just add a qualifier for ‘AI understanding’. This is not a topic that I explicitly cover in my ethics class, but it does come up in discussion of related topics.
SAE visualization needed. I am still looking for a good visual illustration of how complex features across a deep network are mapped onto to a very thin, very wide SAEs with sparsely represented features. What I have now is the Powerpoint approximation I created for class use, below. Props to Brendan Boycroft for his LLM visualizer, which has helped me understand more about the mechanics of LLMs. https://bbycroft.net/llm

What’s new?
In 2024 it was increasingly apparent that AI will affect every human endeavor and seems to be doing so at a much faster rate than previous technologies such as steam power or computers. The speed of change matters almost more than the nature of change because human culture, values, and ethics do not usually change quickly. Maladaptive patterns and precedents set now will be increasingly difficult to change later.
What’s important?
Human-Centered AI needs to become more than an academic interest, it needs to become a well-understood and widely practiced set of values, practices and design principles. Some people and organizations that I like, along with the Anthropic explainability work already mentioned, are Stanford’s Human-Centered AI, Google’s People + AI effort, and Ben Schneiderman’s early leadership and community organizing.
For my class of working AI engineers, I am trying to focus on practical and specific design principles. We need to counter the dysfunctional design principles I seem to see everywhere: ‘automate everything as fast as possible’, and ‘hide everything from the users so they can’t mess it up’. I am looking for cases and examples that challenge people to step up and use AI in ways that empower humans to be smarter, wiser and better than ever before.
I wrote fictional cases for class modules on the Future of Work, HCAI and Lethal Autonomous Weapons. Case 1 is about a customer-facing LLM system that tried to do too much too fast and cut the expert humans out of the loop. Case 2 is about a high school teacher who figured out most of her students were cheating on a camp application essay with an LLM and wants to use GenAI in a better way.

The cases are on separate Medium pages here and here, and I love feedback! Thanks to Sara Bos and Andrew Taylor for comments already received.
The second case might be controversial; some people argue that it is OK for students to learn to write with AI before learning to write without it. I disagree, but that debate will no doubt continue.
I prefer real-world design cases when possible, but good HCAI cases have been hard to find. My colleague John (Ian) McCulloh recently gave me some great ideas from examples he uses in his class lectures, including the Organ Donation case, an Accenture project that helped doctors and patients make time-sensitive kidney transplant decision quickly and well. Ian teaches in the same program that I do. I hope to work with Ian to turn this into an interactive case for next year.
Most people agree that AI development needs to be governed, through laws or by other means, but there’s a lot of disagreement about how.
The EU’s AI Act came into effect, giving a tiered system for AI risk, and prohibiting a list of highest-risk applications including social scoring systems and remote biometric identification. The AI Act joins the EU’s Digital Markets Act and the General Data Protection Regulation, to form the world’s broadest and most comprehensive set of AI-related legislation.
California passed a set of AI governance related laws, which may have national implications, in the same way that California laws on things like the environment have often set precedent. I like this (incomplete) review from the White & Case law firm.
For international comparisons on privacy, I like DLA Piper‘s website Data Protection Laws of the World.
My class will focus on two things:
Given the pace of change, the most useful thing I thought I could give my class is a set of heuristics for evaluating new governance structures.
Pay attention to the definitions. Each of the new legal acts faced problems with defining exactly what would be covered; some definitions are probably too narrow (easily bypassed with small changes to the approach), some too broad (inviting abuse) and some may be dated quickly.
California had to solve some difficult definitional problems in order to try to regulate things like ‘Addictive Media’ (see SB-976), ‘AI Generated Media’ (see AB-1836), and to write separate legislation for ‘Generative AI’, (see SB-896). Each of these has some potentially problematic aspects, worthy of class discussion. As one example, The Digital Replicas Act defines AI-generated media as “an engineered or machine-based system that varies in its level of autonomy and that can, for explicit or implicit objectives, infer from the input it receives how to generate outputs that can influence physical or virtual environments.” There’s a lot of room for interpretation here.
Who is covered and what are the penalties? Are the penalties financial or criminal? Are there exceptions for law enforcement or government use? How does it apply across international lines? Does it have a tiered system based on an organization’s size? On the last point, technology regulation often tries to protect startups and small companies with thresholds or tiers for compliance. But California’s governor vetoed SB 1047 on AI safety for exempting small companies, arguing that “Smaller, specialized models may emerge as equally or even more dangerous”. Was this a wise move, or was he just protecting California’s tech giants?
Is it enforceable, flexible, and ‘future-proof’? Technology legislation is very difficult to get right because technology is a fast-moving target. If it is too specific it risks quickly becoming obsolete, or worse, hindering innovations. But the more general or vague it is, the less enforceable it may be, or more easily ‘gamed’. One strategy is to require companies to define their own risks and solutions, which provides flexibility, but will only work if the legislature, the courts and the public later pay attention to what companies actually do. This is a gamble on a well-functioning judiciary and an engaged, empowered citizenry… but democracy always is.
Not every problem can or should be solved with legislation. AI governance is a multi-tiered system. It includes the proliferation of AI frameworks and independent AI guidance documents that go further than legislation should, and provide non-binding, sometimes idealistic goals. A few that I think are important:
Here’s some other news items and topics I am integrating into my class, some of which are new to 2024 and some are not. I will:
Thanks for reading! I always appreciate making contact with other people teaching similar courses or with deep knowledge of related areas. And I also always appreciate Claps and Comments!
What I’m Updating in My AI Ethics Class for 2025 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
What I’m Updating in My AI Ethics Class for 2025
Go Here to Read this Fast! What I’m Updating in My AI Ethics Class for 2025