

Originally appeared here:
5 Python One-Liners to Kick Off Your Data Exploration
Go Here to Read this Fast! 5 Python One-Liners to Kick Off Your Data Exploration


With Data being constantly glorified as the most valuable asset organizations can own, leaders and decision-makers are always looking for effective ways to put their data insights to use. Every time customers interact with digital products, millions of data points are generated and the opportunity loss of not harnessing these data points to make better products, optimize revenue generation, and improve customer footprint is simply too high to ignore. The role of “Data Translators” began to emerge in analytics and data science job boards in the 2010s to help bridge the knowledge gap between business and Data teams and enable organizations to be better and more data-informed. Over the last decade, this role has evolved and absorbed more and more facets of data-driven decision-making and has been providing much-needed context and translation for business leadership. This role also plays an important role in interfacing with stakeholder groups such as Marketing, Product, and Strategy to help make all decisions data-centric. With the well-accepted importance of this role and the nimble nature of the set of responsibilities assigned to it, it is essential for all data practitioners to build the “data translation” muscle to excel, succeed, and progress in their roles and career paths.
Decision-making has been a cornerstone of successful business stories across all industries. Peter Drucker, the notable Management Theory and Practice expert famously said “Every decision is risky: it is a commitment of present resources to an uncertain and unknown future.” In most Modern organizations, data centricity and data-informed decision-making have been agreed upon as proven ways to have reduced risk and ambiguity and business decisions to have a higher likelihood of successful outcomes. Data and marketing executives are tasked with making a series of decisions each day that have far-reaching impacts on an organization’s day-to-day operations and long-term priorities. While data resources are abundant in the current landscape, the process of utilizing these resources is still a struggle. According to a recent study released by Oracle titled “The Decision Dilemma” (April 2023), 72% of business leaders have expressed that the enormous volume of data available and the lack of trust and inconsistencies in data sources have stopped them from making decisions and 89% believe that the growing number of data sources has limited the success of their organizations, despite understanding that decisions that are not backed by data can less accurate, less successful and more prone to errors.
Data-driven decision-making is certainly not a new concept, in fact, the first set of decision models based on data and statistical principles was proposed in 1953 by Irwin D.J Bross distinguishing between the real and symbolic valid and illustrating the importance of measurements and validation. And organizations have consistently evolved over the past few decades to make data investments and have crafted strategies to make data, the center of their risk mitigation and decision-making efforts. Despite having these resources, organizations currently struggle with the unique problem of balancing the appetite for high-quality actionable insights and the availability of resources. A simple “Seesaw” analogy can be used to describe these business circumstances. An excessive appetite for knowledge and actionable insights combined with inadequate data resources may result in Data leaders relying on past decisions, anecdotal evidence, and gut feelings to make decisions. On the other hand, an abundance of data resources combined with less appetite for knowledge can ultimately result in unnecessary data solutions and too many self-serve dashboards being built with no clear strategy to make these resources useful.
It is becoming increasingly clear that the data knowledge gap is becoming wider despite the availability of abundant data resources. We are increasingly observing a unique situation of a Broken Seesaw, where both Data resources and appetite for knowledge exist, but owing to the lack of efforts to translate the value that the data teams provide to business leaders, both sides of the seesaw get overloaded, eventually leading to broken and inefficient decision making processes in the long run. Valuable data creates impact, everything else sleeps in a dashboard.
Is data literacy the answer?
Yes and No.
Data literacy has quickly become a focal point in the conversation around data insights and delivery, as organizations recognize the importance of equipping employees with the skills to understand and utilize data effectively. The movement gained momentum with research highlighting a significant skills gap among business professionals when it comes to interpreting data. The emphasis on training users to interpret data can sometimes overlook the steep learning curve that is required to build the skill of critically thinking about data evidence and interpreting them in a way that aids in risk mitigation.
Technology barriers are another bottleneck that exists between the data teams and business stakeholders. We can break this bottleneck down into two parts. Firstly, an insufficient analytics tool stack for data analysis can hinder effective data utilization and communication by non-super users of data. Secondly, the lack of training on their use can often lead to misinterpretation and misalignment with other data sources hence hindering the chance to establish a single source of truth. This eventually affects the credibility of the data teams.
A significant drawback of the current emphasis on data literacy is the tendency to place undue blame on users for the shortcomings of data initiatives. When data products fail to deliver value or are met with resistance, the reflexive response is often to assume a lack of user skill or understanding. This perspective overlooks the critical role that business literacy and business context play in effectively communicating the data insights whether it is proving or disproving business hypotheses. Data literacy is a two-way street. Oftentimes, it is the responsibility of the data team members to view the task from the business perspective and understand why they would care about what the data team has to say. Acknowledging and addressing these shortcomings and aligning data initiatives with business goals can lead to more effective and harmonious data-driven cultures.
One solution that the data industry has adopted to address this data and knowledge gap and the shortcomings of data literacy efforts is the introduction of “Data Translator” roles within organizations. The role of a data translator has evolved significantly over the years, reflecting changes in how organizations utilize data analytics. Initially emerging as a bridge between data scientists and business units, the role was designed to ensure that complex data insights were translated into actionable business strategies.
In the early stages, data translators were primarily seen as intermediaries who could communicate technical findings to non-technical stakeholders, helping to prioritize business problems and ensuring that analytics solutions were aligned with business goals. As the demand for data-driven decision-making grew, so did the importance of this role. By 2019, the role had become more prevalent, with about a third of companies having positions fitting the data translator description. The responsibilities expanded to include not only communication but also ensuring that analytics tools were adopted across enterprises and that data democratization was achieved. Recently, there has been a shift towards integrating these roles into broader functions such as Data Product Owners, reflecting an evolution towards more holistic roles that encompass both technical and strategic responsibilities. This evolution highlights the ongoing need for roles that can effectively link data insights with business outcomes.
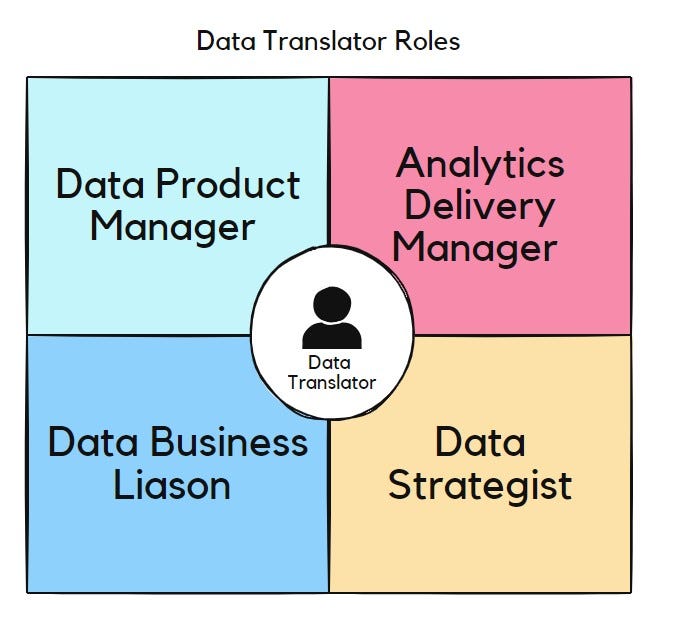
The Data Translator role can take on a multitude of responsibilities depending upon the nature of the organizations they serve. For example, consulting organizations typically assign a dedicated Data Translator who is responsible for translating the provided data solutions to the business audience. Professionals who are hired in-house typically take the form of either dedicated Data Translator resources, Data Product Managers, or Analytics Delivery Managers with the responsibility of ensuring that the Data team’s efforts are utilized appropriately for critical business decisions. Despite having various job titles, Data Translators are tasked with the critical responsibility of proving the value and impact driven by data teams. They accomplish this by focusing on the following key areas:
Data Translators work as liaisons between the business leaders and data teams by consistently quantifying the impact of the projects delivered by the data team and weighing on the thoughtful allocation of data resources. For example, they may do this by keeping a record of monetary impact and decisions driven by the data teams they support. This record is often helpful in estimating resources for new strategic initiatives and serves as a reference for data solutions that can be replicated for similar problems in new contexts.
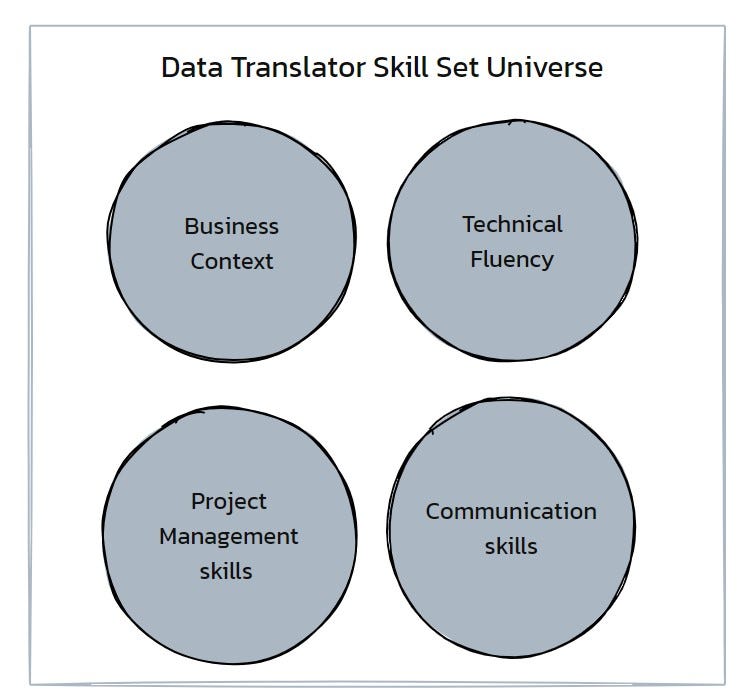
Data translators have a solid grasp of business goals and priorities and work on aligning their team’s efforts with the broader business objectives. This process often involves identifying projects that not only leverage the team’s skills but also have the potential to influence strategic outcomes. A popular approach to prioritization is using a framework that assesses the potential impact and feasibility of projects. By streamlining the data team’s intake systems and focusing on initiatives that promise significant returns or solve critical business problems, data teams can maximize their usefulness and productivity. In an article explaining the traits of data product managers and translators, Harvard Business Review identified business context, broad technical fluency, project management skills, an entrepreneurial spirit, and the ability to explain data needs and strategy to the rest of the organization.
Data Translators work with Governance teams across the organization to establish common data language, definitions, and standards to ensure that all teams are aligned in their understanding and interpretation of data. This ensures that all data efforts are working together cohesively to establish a single source of truth.
Identifying and prioritizing key stakeholders is essential for data teams to ensure their efforts are aligned with the organization’s strategic goals. Data Translators often accomplish this by using a project management technique called the “Interest — Influence Matrix”. This process begins by mapping stakeholders across two dimensions: their level of interest in data initiatives and their influence on decision-making. High-interest and high-influence stakeholders are considered key players and should be prioritized for regular communication and collaboration. Building strong relationships with these individuals is crucial, as they can champion data projects, help secure resources, and remove roadblocks. For less influential stakeholders, maintaining periodic contact ensures they remain informed without overextending team resources. This type of thoughtful engagement enables data teams to focus their efforts where they can have the most significant impact, driving value for the organization as a whole.
In an increasingly data-centric landscape, the role of Data teams has become significant, yet they are often misunderstood. Data Translators often create roadshows, presentations, and educational materials to share out the Data Team’s achievements and value provided in order to build and maintain credibility and trust across the organization.
Observing the history and evolution of the Data Translator role has established that, along with data fluency, it is essential to have domain knowledge, Business context, and a solid understanding of organizational nuances such as goals, expected outcomes, and effective stakeholder partnerships to be successful in this role. The nimble nature of this role cannot go unnoticed. Over the past few decades, professionals across the data ecosystem with various job titles have been absorbed into the “Data Translator” roles and responsibilities in different ways. In order to future proof their data careers and be consistently successful and valuable to their organizations, data professionals must build the “Data Translator” muscle.
Elaborated below, is a non-exhaustive list of practical tips that will help analysts become well-versed in Data Translation.
The curse of knowledge is a cognitive bias that occurs when a person who has specialized knowledge assumes that others share that same knowledge. This bias makes it difficult for knowledgeable individuals to imagine what it’s like to lack their expertise. Assuming everyone shares the same understanding and background knowledge leads to misunderstandings, wrong assumptions and ineffective communication. This is particularly true when interfacing with teams such as Marketing and Product, where the stakeholders are not necessarily data fluent, but data plays a major role in their projects and campaigns being efficient and fruitful. A data translator must have the unique capability to dissect the problem statement and map it into data points available, make the connections, find answers, and explain it to stakeholders in plain English. Here is a Marketing Analytics example:
Statement 1 (Analyst): Looking at the channel attribution charts, it looks like most of your campaign’s ROAS is negative, but it looks like there is less churn and more engagement, it’s not all wasted effort.
Statement 2 (Data translator): After assessing the marketing dollar spend and returns, it looks like your campaign is losing money in the short term. But looking at the big picture, the users acquired by your marketing campaigns are engaging and returning more hence creating long-term value.
The data translated version of the statement clearly explains the findings and illustrates the long-term impact of the campaign without the Data Analytics jargon.
Oftentimes, analysts confine themselves to the bounds of their job responsibilities and purely focus on answering business questions. Sometimes, this phenomenon is also an unexpected side effect of organization-wide Data Literacy efforts. Answering business questions limits the insights to a specific problem while focusing on the overall business outcome gives a chance for both the Data and Business teams to look at data insights at a more holistic level. Data Literacy goes hand in hand with Business literacy. Data Translators are always expected to have a working knowledge of the business outcomes so they can tie insights to the overarching goals.
For example,
Business Question: How is my newly launched brand campaign doing?
Answer (Analyst): We had 6000 impressions in 3 days which is 50% higher compared to the last time we ran a similar campaign same time last year.
Answer (Data Translator): The expected outcome of this campaign is to improve brand awareness. We had 3000 net new users visit our website from this campaign. We also measured brand perception metrics before vs. after using a survey poll for these specific users and their opinions and awareness about the brand’s product offerings have improved.
Learn to Zoom out
Learning to zoom out and look at the big picture, and being able to map out individual tasks into overall priorities help Data translators focus their efforts on impactful initiatives. This skill also enables them to learn to build scalable analytics solutions that can be repurposed, eventually leading to time savings and better speed to insight.
“I didn’t have time to write a short letter, so I wrote a long one instead.”
― Mark Twain
Data storytelling is equal parts science and art. And it is an essential tool in the Data Translator toolkit. It requires a thorough understanding of the problem and solution, constructing a clear, concise, and relatable narrative, and ending with recommendations and insights that can be acted upon. Every data story needs a governing idea that loosely follows an arc. One effective way to arrange the analysis story deck is in the order of Problem, Problem’s Impact, Findings, Recommendations, and Next steps. This ensures that your data story is easy to follow and speaks for itself even when you’re not around to narrate and walk through the whole deck.
The order may look different in repeating tasks such as routine performance updates or retrospective summaries. But for a typical request requiring data insights to aid decision-making, this order is a great starting point. The main thing to ensure in this step is to have accurate and relevant data points that clearly support your story. Apart from that, I have a few tips to help wrap up your Analysis solution neatly. These little details go a long way in presentation delivery and helping the audience remember the key insights.
· Clearly indicate if the key data point being shared is a good sign or a bad sign by using arrows and colors. (Example: A low bounce rate is a good sign, but a low conversion rate is a bad sign.)
· Always add context for any number (data point) shared in the slide by including benchmarking details or trend analyses. (Example: Conversion rate for this month was 12%, this is in line with other SKUs in the same product line and higher compared to the average conversion rate for the same months in the past three years.)
· Tie back the insights to some part of the original business question, goal, and outcome in each slide.
· Including details such as sample size, analysis time frames and important annotations in the footnote will help build trust and credibility.
In essence, a data story can be deemed effective when it leaves the audience informed and inspired to act.
Data Translators perform the critical role of bridging the gap between Data and Business teams. Their skill set is instrumental in proving the worth and impact of data investments, promoting data literacy, prioritizing high-impact initiatives, and protecting Analysts’ time from working on low-value tasks. Organizations and data teams can reap symbiotic benefits by encouraging, incorporating, and nurturing team members with data translator skills.
About the Author :
Nithhyaa Ramamoorthy is a Data Subject matter Expert with over 12 years’ worth of experience in Analytics and Big Data, specifically in the intersection of Healthcare and Consumer behavior. She holds a Master’s Degree in Information Sciences and more recently a CSPO along with several other professional certifications. She is passionate about leveraging her analytics skills to drive business decisions that create inclusive and equitable digital products rooted in empathy.
Bridging the Data Literacy Gap was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Bridging the Data Literacy Gap


Originally appeared here:
Advancing AI trust with new responsible AI tools, capabilities, and resources


What does a data engineer do differently to a data scientist?
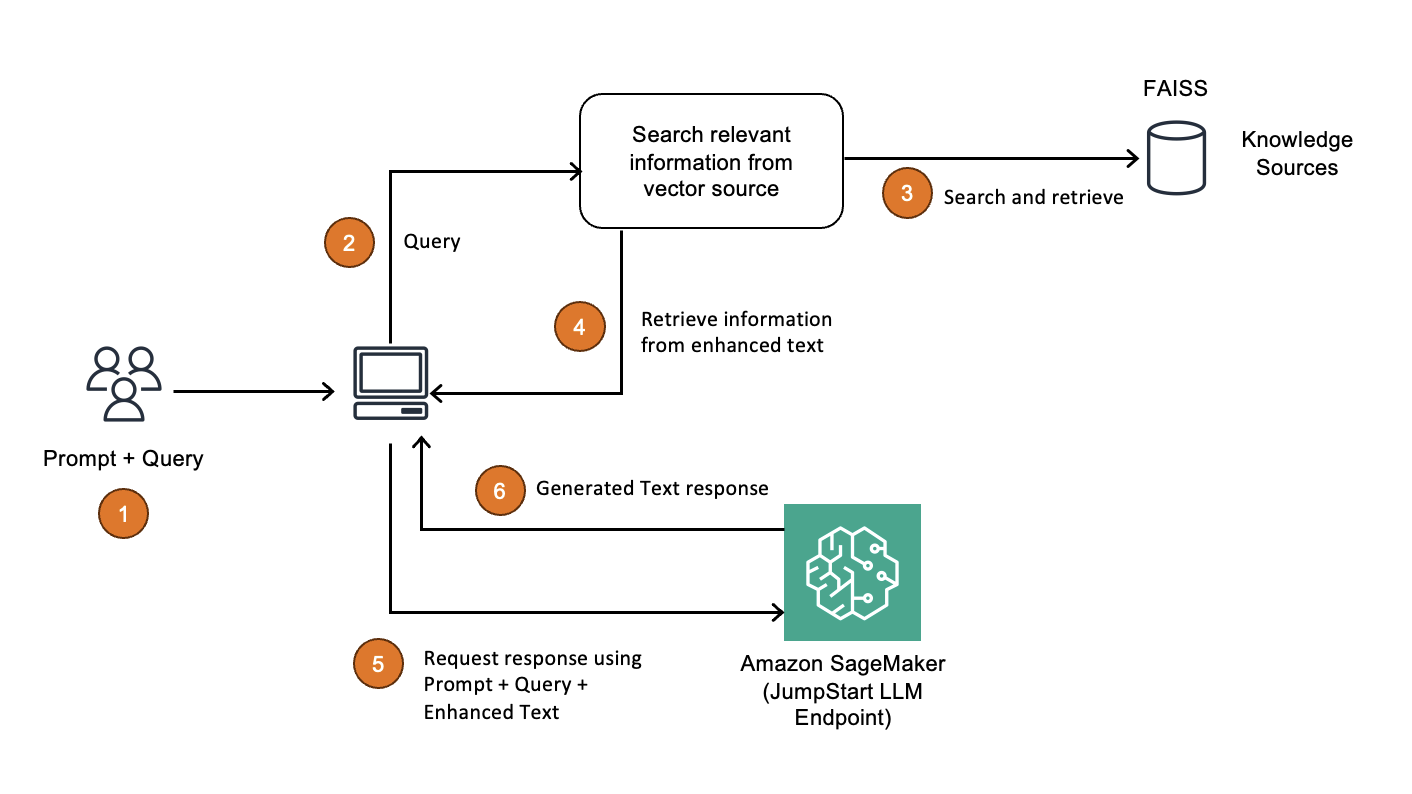

Originally appeared here:
Deploy RAG applications on Amazon SageMaker JumpStart using FAISS
Go Here to Read this Fast! Deploy RAG applications on Amazon SageMaker JumpStart using FAISS

It’s embarrassing how much time I spend thinking about my fantasy football team.
Managing a squad means processing a firehose of information — injury reports, expert projections, upcoming bye weeks, and favorable matchups. And it’s not just the volume of data, but the ephermerality— if your star RB tweaks a hamstring during Wednesday practice, you better not be basing lineup decisions off of Tuesday’s report.
This is why general-purpose chatbots like Anthropic’s Claude and OpenAI’s ChatGPT are essentially useless for fantasy football recommendations, as they are limited to a static training corpus that cuts off months, even years ago.
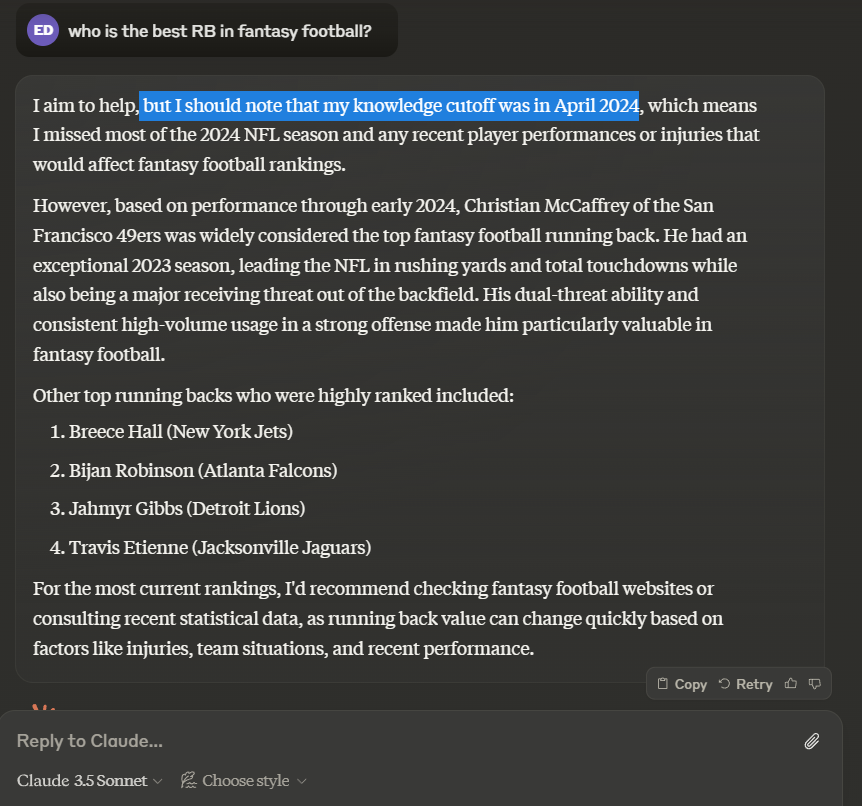
For instance, if we ask Claude Sonnet 3.5 who the current best running back is, we see names like Christian McCaffrey, Breece Hall, and Travis Etienne, who have had injury-ridden or otherwise disappointing seasons thus far in 2024. There is no mention of Saquon Barkley or Derrick Henry, the obvious frontrunners at this stage. (Though to Claude’s credit, it discloses its limitations.)
Apps like Perplexity are more accurate because they do access a search engine with up-to-date information. However, it of course has no knowledge of my entire roster situation, the state of our league’s playoff picture, or the nuances of our keeper rules.
There is an opportunity to tailor a fantasy football-focused Agent with tools and personalized context for each user.
Let’s dig into the implementation.
The heart of the chatbot will be a LangGraph Agent based on the ReAct framework. We’ll give it access to tools that integrate with the Sleeper API for common operations like checking the league standings, rosters, player stats, expert analysis, and more.
In addition to the LangGraph API server, our backend will include a small Postgres database and Redis cache, which are used to manage state and route requests. We’ll use Streamlit for a simple, but effective UI.
For development, we can run all of these components locally via Docker Compose, but I’ll also show the infrastructure-as-code (IaC) to deploy a scalable stack with AWS CDK.
Sleeper graciously exposes a public, read-only API that we can tap into for user & league details, including a full list of players, rosters, and draft information. Though it’s not documented explicitly, I also found some GraphQL endpoints that provide critical statistics, projections, and — perhaps most valuable of all — recent expert analysis by NFL reporters.
I created a simple API client to access the various methods, which you can find here. The one trick that I wanted to highlight is the requests-cache library. I don’t want to be a greedy client of Sleeper’s freely-available datasets, so I cache responses in a local Sqlite database with a basic TTL mechanism.
Not only does this lessen the amount redundant API traffic bombarding Sleeper’s servers (reducing the chance that they blacklist my IP address), but it significantly reduces latency for my clients, making for a better UX.
Setting up and using the cache is dead simple, as you can see in this snippet —
import requests_cache
from urllib.parse import urljoin
from typing import Union, Optional
from pathlib import Path
class SleeperClient:
def __init__(self, cache_path: str = '../.cache'):
# config
self.cache_path = cache_path
self.session = requests_cache.CachedSession(
Path(cache_path) / 'api_cache',
backend='sqlite',
expire_after=60 * 60 * 24,
)
...
def _get_json(self, path: str, base_url: Optional[str] = None) -> dict:
url = urljoin(base_url or self.base_url, path)
return self.session.get(url).json()
def get_player_stats(self, player_id: Union[str, int], season: Optional[int] = None, group_by_week: bool = False):
return self._get_json(
f'stats/nfl/player/{player_id}?season_type=regular&season={season or self.nfl_state["season"]}{"&grouping=week" if group_by_week else ""}',
base_url=self.stats_url,
)
So running something like
self.session.get(url)
first checks the local Sqlite cache for an unexpired response that particular request. If it’s found, we can skip the API call and just read from the database.
I want to turn the Sleeper API client into a handful of key functions that the Agent can use to inform its responses. Because these functions will effectively be invoked by the LLM, I find it important to annotate them clearly and ask for simple, flexible arguments.
For example, Sleeper’s API’s generally ask for numeric player id’s, which makes sense for a programmatic interface. However, I want to abstract that concept away from the LLM and just have it input player names for these functions. To ensure some additional flexibility and allow for things like typos, I implemented a basic “fuzzy search” method to map player name searches to their associated player id.
# file: fantasy_chatbot/league.py
def get_player_id_fuzzy_search(self, player_name: str) -> tuple[str, str]:
# will need a simple search engine to go from player name to player id without needing exact matches. returns the player_id and matched player name as a tuple
nearest_name = process.extract(query=player_name, choices=self.player_names, scorer=fuzz.WRatio, limit=1)[0]
return self.player_name_to_id[nearest_name[0]], self.player_names[nearest_name[2]]
# example usage in a tool
def get_player_news(self, player_name: Annotated[str, "The player's name."]) -> str:
"""
Get recent news about a player for the most up-to-date analysis and injury status.
Use this whenever naming a player in a potential deal, as you should always have the right context for a recommendation.
If sources are provided, include markdown-based link(s)
(e.g. [Rotoballer](https://www.rotoballer.com/player-news/saquon-barkley-has-historic-night-sunday/1502955) )
at the bottom of your response to provide proper attribution
and allow the user to learn more.
"""
player_id, player_name = self.get_player_id_fuzzy_search(player_name)
# news
news = self.client.get_player_news(player_id, limit=3)
player_news = f"Recent News about {player_name}nn"
for n in news:
player_news += f"**{n['metadata']['title']}**n{n['metadata']['description']}"
if analysis := n['metadata'].get('analysis'):
player_news += f"nnAnalysis:n{analysis}"
if url := n['metadata'].get('url'):
# markdown link to source
player_news += f"n[{n['source'].capitalize()}]({url})nn"
return player_news
This is better than a simple map of name to player id because it allows for misspellings and other typos, e.g. saquon → Saquon Barkley
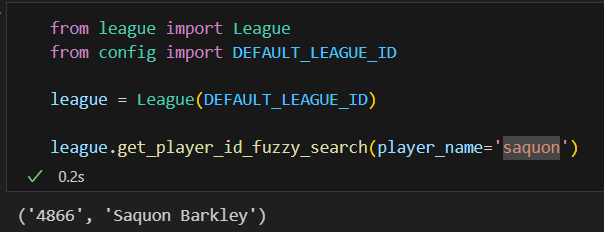
I created a number of useful tools based on these principles:
You can probably think of a few more functions that would be useful to add, like details about recent transactions, league head-to-heads, and draft information.
The impetus for this entire project was an opportunity to learn the LangGraph ecosystem, which may be becoming the de facto standard for constructing agentic workflows.
I’ve hacked together agents from scratch in the past, and I wish I had known about LangGraph at the time. It’s not just a thin wrapper around the various LLM providers, it provides immense utility for building, deploying, & monitoring complex workflows. I’d encourage you to check out the Introduction to LangGraph course by LangChain Academy if you’re interested in diving deeper.
As mentioned before, the graph itself is based on the ReAct framework, which is a popular and effective way to get LLM’s to interact with external tools like those defined above.
I’ve also added a node to persist long-term memories about each user, so that information can be persisted across sessions. I want our agent to “remember” things like users’ concerns, preferences, and previously-recommended trades, as this is not a feature that is implemented particularly well in the chatbots I’ve seen. In graph form, it looks like this:
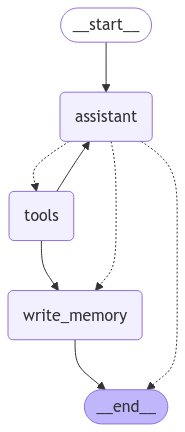
Pretty simple right? Again, you can checkout the full graph definition in the code, but I’ll highlight the write_memory node, which is responsible for writing & updating a profile for each user. This allows us to track key interactions while being efficient about token use.
def write_memory(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Reflect on the chat history and save a memory to the store."""
# get the username from the config
username = config["configurable"]["username"]
# retrieve existing memory if available
namespace = ("memory", username)
existing_memory = store.get(namespace, "user_memory")
# format the memories for the instruction
if existing_memory and existing_memory.value:
memory_dict = existing_memory.value
formatted_memory = (
f"Team Name: {memory_dict.get('team_name', 'Unknown')}n"
f"Current Concerns: {memory_dict.get('current_concerns', 'Unknown')}"
f"Other Details: {memory_dict.get('other_details', 'Unknown')}"
)
else:
formatted_memory = None
system_msg = CREATE_MEMORY_INSTRUCTION.format(memory=formatted_memory)
# invoke the model to produce structured output that matches the schema
new_memory = llm_with_structure.invoke([SystemMessage(content=system_msg)] + state['messages'])
# overwrite the existing user profile
key = "user_memory"
store.put(namespace, key, new_memory)
These memories are surfaced in the system prompt, where I also gave the LLM basic details about our league and how I want it to handle common user requests.
I’m not a frontend developer, so the UI leans heavily on Streamlit’s components and familiar chatbot patterns. Users input their Sleeper username, which is used to lookup their available leagues and persist memories across threads.
I also added a couple of bells and whistles, like implementing token streaming so that users get instant feedback from the LLM. The other important piece is a “research pane”, which surfaces the results of the Agent’s tool calls so that user can inspect the raw data that informs each response.
Here’s a quick demo.
For development, I recommend deploying the components locally via the provided docker-compose.yml file. This will expose the API locally at http://localhost:8123 , so you can rapidly test changes and connect to it from a local Streamlit app.
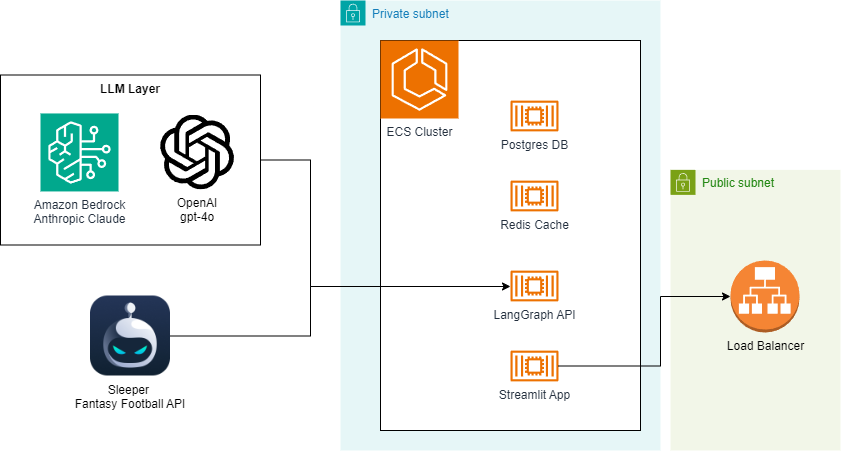
I have also included IaC for an AWS CDK-based deployment that I use to host the app on the internet. Most of the resources are defined here. Notice the parallels between the docker-compose.yml and the CDK code related to the ECS setup:
Snippet from docker-compose.yml for the LangGraph API container:
# from docker-compose.yml
langgraph-api:
image: "fantasy-chatbot"
ports:
- "8123:8000"
healthcheck:
test: curl --request GET --url http://localhost:8000/ok
timeout: 1s
retries: 5
interval: 5s
depends_on:
langgraph-redis:
condition: service_healthy
langgraph-postgres:
condition: service_healthy
env_file: "../.env"
environment:
REDIS_URI: redis://langgraph-redis:6379
POSTGRES_URI: postgres://postgres:postgres@langgraph-postgres:5432/postgres?sslmode=disable// file: fantasy-football-agent-stack.ts
And here is the analogous setup in the CDK stack:
// fantasy-football-agent-stack.ts
const apiImageAsset = new DockerImageAsset(this, 'apiImageAsset', {
directory: path.join(__dirname, '../../fantasy_chatbot'),
file: 'api.Dockerfile',
platform: assets.Platform.LINUX_AMD64,
});
const apiContainer = taskDefinition.addContainer('langgraph-api', {
containerName: 'langgraph-api',
image: ecs.ContainerImage.fromDockerImageAsset(apiImageAsset),
portMappings: [{
containerPort: 8000,
}],
environment: {
...dotenvMap,
REDIS_URI: 'redis://127.0.0.1:6379',
POSTGRES_URI: 'postgres://postgres:[email protected]:5432/postgres?sslmode=disable'
},
logging: ecs.LogDrivers.awsLogs({
streamPrefix: 'langgraph-api',
}),
});
apiContainer.addContainerDependencies(
{
container: redisContainer,
condition: ecs.ContainerDependencyCondition.HEALTHY,
},
{
container: postgresContainer,
condition: ecs.ContainerDependencyCondition.HEALTHY,
},
)
Aside from some subtle differences, it’s effectively a 1:1 translation, which is always something I look for when comparing local environments to “prod” deployments. The DockerImageAsset is a particularly useful resource, as it handles building and deploying (to ECR) the Docker image during synthesis.
Note: Deploying the stack to your AWS account via npm run cdk deploy WILL incur charges. In this demo code I have not included any password protection on the Streamlit app, meaning anyone who has the URL can use the chatbot! I highly recommend adding some additional security if you plan to deploy it yourself.
You want to keep your tools simple. This app does a lot, but is still missing some key functionality, and it will start to break down if I simply add more tools. In the future, I want to break up the graph into task-specific sub-components, e.g. a “News Analyst” Agent and a “Statistician” Agent.
Traceability and debugging are more important with Agent-based apps than traditional software. Despite significant advancements in models’ ability to produce structured outputs, LLM-based function calling is still inherently less reliable than conventional programs. I used LangSmith extensively for debugging.
In an age of commoditized language models, there is no replacement for reliable reporters. We’re at a point where you can put together a reasonable chatbot in a weekend, so how do products differentiate themselves and build moats? This app (or any other like it) would be useless without access to high-quality reporting from analysts and experts. In other words, the Ian Rapaport’s and Matthew Berry’s of the world are more valuable than ever.
GitHub – evandiewald/fantasy-football-agent
All images, unless otherwise noted, are by the author.
Building a Fantasy Football Research Agent with LangGraph was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Building a Fantasy Football Research Agent with LangGraph
Go Here to Read this Fast! Building a Fantasy Football Research Agent with LangGraph
It’s embarrassing how much time I spend thinking about my fantasy football team.
Managing a squad means processing a firehose of information — injury reports, expert projections, upcoming bye weeks, and favorable matchups. And it’s not just the volume of data, but the ephermerality— if your star RB tweaks a hamstring during Wednesday practice, you better not be basing lineup decisions off of Tuesday’s report.
This is why general-purpose chatbots like Anthropic’s Claude and OpenAI’s ChatGPT are essentially useless for fantasy football recommendations, as they are limited to a static training corpus that cuts off months, even years ago.
For instance, if we ask Claude Sonnet 3.5 who the current best running back is, we see names like Christian McCaffrey, Breece Hall, and Travis Etienne, who have had injury-ridden or otherwise disappointing seasons thus far in 2024. There is no mention of Saquon Barkley or Derrick Henry, the obvious frontrunners at this stage. (Though to Claude’s credit, it discloses its limitations.)
Apps like Perplexity are more accurate because they do access a search engine with up-to-date information. However, it of course has no knowledge of my entire roster situation, the state of our league’s playoff picture, or the nuances of our keeper rules.
There is an opportunity to tailor a fantasy football-focused Agent with tools and personalized context for each user.
Let’s dig into the implementation.
The heart of the chatbot will be a LangGraph Agent based on the ReAct framework. We’ll give it access to tools that integrate with the Sleeper API for common operations like checking the league standings, rosters, player stats, expert analysis, and more.
In addition to the LangGraph API server, our backend will include a small Postgres database and Redis cache, which are used to manage state and route requests. We’ll use Streamlit for a simple, but effective UI.
For development, we can run all of these components locally via Docker Compose, but I’ll also show the infrastructure-as-code (IaC) to deploy a scalable stack with AWS CDK.
Sleeper graciously exposes a public, read-only API that we can tap into for user & league details, including a full list of players, rosters, and draft information. Though it’s not documented explicitly, I also found some GraphQL endpoints that provide critical statistics, projections, and — perhaps most valuable of all — recent expert analysis by NFL reporters.
I created a simple API client to access the various methods, which you can find here. The one trick that I wanted to highlight is the requests-cache library. I don’t want to be a greedy client of Sleeper’s freely-available datasets, so I cache responses in a local Sqlite database with a basic TTL mechanism.
Not only does this lessen the amount redundant API traffic bombarding Sleeper’s servers (reducing the chance that they blacklist my IP address), but it significantly reduces latency for my clients, making for a better UX.
Setting up and using the cache is dead simple, as you can see in this snippet —
import requests_cache
from urllib.parse import urljoin
from typing import Union, Optional
from pathlib import Path
class SleeperClient:
def __init__(self, cache_path: str = '../.cache'):
# config
self.cache_path = cache_path
self.session = requests_cache.CachedSession(
Path(cache_path) / 'api_cache',
backend='sqlite',
expire_after=60 * 60 * 24,
)
...
def _get_json(self, path: str, base_url: Optional[str] = None) -> dict:
url = urljoin(base_url or self.base_url, path)
return self.session.get(url).json()
def get_player_stats(self, player_id: Union[str, int], season: Optional[int] = None, group_by_week: bool = False):
return self._get_json(
f'stats/nfl/player/{player_id}?season_type=regular&season={season or self.nfl_state["season"]}{"&grouping=week" if group_by_week else ""}',
base_url=self.stats_url,
)
So running something like
self.session.get(url)
first checks the local Sqlite cache for an unexpired response that particular request. If it’s found, we can skip the API call and just read from the database.
I want to turn the Sleeper API client into a handful of key functions that the Agent can use to inform its responses. Because these functions will effectively be invoked by the LLM, I find it important to annotate them clearly and ask for simple, flexible arguments.
For example, Sleeper’s API’s generally ask for numeric player id’s, which makes sense for a programmatic interface. However, I want to abstract that concept away from the LLM and just have it input player names for these functions. To ensure some additional flexibility and allow for things like typos, I implemented a basic “fuzzy search” method to map player name searches to their associated player id.
# file: fantasy_chatbot/league.py
def get_player_id_fuzzy_search(self, player_name: str) -> tuple[str, str]:
# will need a simple search engine to go from player name to player id without needing exact matches. returns the player_id and matched player name as a tuple
nearest_name = process.extract(query=player_name, choices=self.player_names, scorer=fuzz.WRatio, limit=1)[0]
return self.player_name_to_id[nearest_name[0]], self.player_names[nearest_name[2]]
# example usage in a tool
def get_player_news(self, player_name: Annotated[str, "The player's name."]) -> str:
"""
Get recent news about a player for the most up-to-date analysis and injury status.
Use this whenever naming a player in a potential deal, as you should always have the right context for a recommendation.
If sources are provided, include markdown-based link(s)
(e.g. [Rotoballer](https://www.rotoballer.com/player-news/saquon-barkley-has-historic-night-sunday/1502955) )
at the bottom of your response to provide proper attribution
and allow the user to learn more.
"""
player_id, player_name = self.get_player_id_fuzzy_search(player_name)
# news
news = self.client.get_player_news(player_id, limit=3)
player_news = f"Recent News about {player_name}nn"
for n in news:
player_news += f"**{n['metadata']['title']}**n{n['metadata']['description']}"
if analysis := n['metadata'].get('analysis'):
player_news += f"nnAnalysis:n{analysis}"
if url := n['metadata'].get('url'):
# markdown link to source
player_news += f"n[{n['source'].capitalize()}]({url})nn"
return player_news
This is better than a simple map of name to player id because it allows for misspellings and other typos, e.g. saquon → Saquon Barkley
I created a number of useful tools based on these principles:
You can probably think of a few more functions that would be useful to add, like details about recent transactions, league head-to-heads, and draft information.
The impetus for this entire project was an opportunity to learn the LangGraph ecosystem, which may be becoming the de facto standard for constructing agentic workflows.
I’ve hacked together agents from scratch in the past, and I wish I had known about LangGraph at the time. It’s not just a thin wrapper around the various LLM providers, it provides immense utility for building, deploying, & monitoring complex workflows. I’d encourage you to check out the Introduction to LangGraph course by LangChain Academy if you’re interested in diving deeper.
As mentioned before, the graph itself is based on the ReAct framework, which is a popular and effective way to get LLM’s to interact with external tools like those defined above.
I’ve also added a node to persist long-term memories about each user, so that information can be persisted across sessions. I want our agent to “remember” things like users’ concerns, preferences, and previously-recommended trades, as this is not a feature that is implemented particularly well in the chatbots I’ve seen. In graph form, it looks like this:
Pretty simple right? Again, you can checkout the full graph definition in the code, but I’ll highlight the write_memory node, which is responsible for writing & updating a profile for each user. This allows us to track key interactions while being efficient about token use.
def write_memory(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Reflect on the chat history and save a memory to the store."""
# get the username from the config
username = config["configurable"]["username"]
# retrieve existing memory if available
namespace = ("memory", username)
existing_memory = store.get(namespace, "user_memory")
# format the memories for the instruction
if existing_memory and existing_memory.value:
memory_dict = existing_memory.value
formatted_memory = (
f"Team Name: {memory_dict.get('team_name', 'Unknown')}n"
f"Current Concerns: {memory_dict.get('current_concerns', 'Unknown')}"
f"Other Details: {memory_dict.get('other_details', 'Unknown')}"
)
else:
formatted_memory = None
system_msg = CREATE_MEMORY_INSTRUCTION.format(memory=formatted_memory)
# invoke the model to produce structured output that matches the schema
new_memory = llm_with_structure.invoke([SystemMessage(content=system_msg)] + state['messages'])
# overwrite the existing user profile
key = "user_memory"
store.put(namespace, key, new_memory)
These memories are surfaced in the system prompt, where I also gave the LLM basic details about our league and how I want it to handle common user requests.
I’m not a frontend developer, so the UI leans heavily on Streamlit’s components and familiar chatbot patterns. Users input their Sleeper username, which is used to lookup their available leagues and persist memories across threads.
I also added a couple of bells and whistles, like implementing token streaming so that users get instant feedback from the LLM. The other important piece is a “research pane”, which surfaces the results of the Agent’s tool calls so that user can inspect the raw data that informs each response.
Here’s a quick demo.
For development, I recommend deploying the components locally via the provided docker-compose.yml file. This will expose the API locally at http://localhost:8123 , so you can rapidly test changes and connect to it from a local Streamlit app.
I have also included IaC for an AWS CDK-based deployment that I use to host the app on the internet. Most of the resources are defined here. Notice the parallels between the docker-compose.yml and the CDK code related to the ECS setup:
Snippet from docker-compose.yml for the LangGraph API container:
# from docker-compose.yml
langgraph-api:
image: "fantasy-chatbot"
ports:
- "8123:8000"
healthcheck:
test: curl --request GET --url http://localhost:8000/ok
timeout: 1s
retries: 5
interval: 5s
depends_on:
langgraph-redis:
condition: service_healthy
langgraph-postgres:
condition: service_healthy
env_file: "../.env"
environment:
REDIS_URI: redis://langgraph-redis:6379
POSTGRES_URI: postgres://postgres:postgres@langgraph-postgres:5432/postgres?sslmode=disable// file: fantasy-football-agent-stack.ts
And here is the analogous setup in the CDK stack:
// fantasy-football-agent-stack.ts
const apiImageAsset = new DockerImageAsset(this, 'apiImageAsset', {
directory: path.join(__dirname, '../../fantasy_chatbot'),
file: 'api.Dockerfile',
platform: assets.Platform.LINUX_AMD64,
});
const apiContainer = taskDefinition.addContainer('langgraph-api', {
containerName: 'langgraph-api',
image: ecs.ContainerImage.fromDockerImageAsset(apiImageAsset),
portMappings: [{
containerPort: 8000,
}],
environment: {
...dotenvMap,
REDIS_URI: 'redis://127.0.0.1:6379',
POSTGRES_URI: 'postgres://postgres:[email protected]:5432/postgres?sslmode=disable'
},
logging: ecs.LogDrivers.awsLogs({
streamPrefix: 'langgraph-api',
}),
});
apiContainer.addContainerDependencies(
{
container: redisContainer,
condition: ecs.ContainerDependencyCondition.HEALTHY,
},
{
container: postgresContainer,
condition: ecs.ContainerDependencyCondition.HEALTHY,
},
)
Aside from some subtle differences, it’s effectively a 1:1 translation, which is always something I look for when comparing local environments to “prod” deployments. The DockerImageAsset is a particularly useful resource, as it handles building and deploying (to ECR) the Docker image during synthesis.
Note: Deploying the stack to your AWS account via npm run cdk deploy WILL incur charges. In this demo code I have not included any password protection on the Streamlit app, meaning anyone who has the URL can use the chatbot! I highly recommend adding some additional security if you plan to deploy it yourself.
You want to keep your tools simple. This app does a lot, but is still missing some key functionality, and it will start to break down if I simply add more tools. In the future, I want to break up the graph into task-specific sub-components, e.g. a “News Analyst” Agent and a “Statistician” Agent.
Traceability and debugging are more important with Agent-based apps than traditional software. Despite significant advancements in models’ ability to produce structured outputs, LLM-based function calling is still inherently less reliable than conventional programs. I used LangSmith extensively for debugging.
In an age of commoditized language models, there is no replacement for reliable reporters. We’re at a point where you can put together a reasonable chatbot in a weekend, so how do products differentiate themselves and build moats? This app (or any other like it) would be useless without access to high-quality reporting from analysts and experts. In other words, the Ian Rapaport’s and Matthew Berry’s of the world are more valuable than ever.
GitHub – evandiewald/fantasy-football-agent
All images, unless otherwise noted, are by the author.
Building a Fantasy Football Research Agent with LangGraph was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Building a Fantasy Football Research Agent with LangGraph
Go Here to Read this Fast! Building a Fantasy Football Research Agent with LangGraph


Working on scientific papers often involves translating algorithms into scientific formulas, typically formatted in LaTeX. This process can be tedious and time-consuming, especially in large projects, as it requires constant back-and-forth between the code repository and the LaTeX document.
While working on a large repository of algorithms, I began exploring ways to streamline this workflow. My motivation arose from the inefficiency of manually converting complex algorithms into LaTeX-compatible formulas. A particular challenge was ensuring consistency across multiple documents, especially in projects where formulas required frequent updates. This led me to explore how automation could streamline repetitive tasks while improving accuracy.
For the remainder of this document, I will use both the term “algorithm” and “scientific code.” All images in this article, except for the cover image, were created by the author.
My goal was to transition from scientific code to a comprehensive document that introduces the purpose of the code, defines variables, presents scientific formulas, includes a generated example plot, and demonstrates the calculations for a specific example. The document would follow a predefined framework, combining static and dynamic elements to ensure both consistency and adaptability.
The framework I designed included the following structure:
This structure was designed to dynamically adapt based on the number of algorithms being documented, ensuring a consistent and professional presentation regardless of the document’s size or complexity.
To achieve this goal, a well-organized repository was essential for enabling a scalable and efficient solution. The algorithm calculations were grouped into a dedicated folder, with files named using a consistent snake_case convention that matched the algorithm names.
To ensure clarity and support reuse, initial values for examples and the generated plots were stored in separate folders. These folders followed the same naming convention as the algorithms but with distinct suffixes to differentiate their purpose. This structure ensured that all components were easy to find and consistent with the overall framework of the project.
At the core of this project is the use of GPT models to automate the conversion of algorithms into LaTeX. GPT’s strength lies in its ability to interpret the structure of generic, variable-rich code and transform it into human-readable explanations and precisely formatted scientific formulas. This automation significantly reduces the manual effort required, ensuring both accuracy and consistency across documents.
For this project, I will leverage OpenAI’s ChatGPT-4o model, renowned for its advanced ability to comprehend and generate structured content. To interact with OpenAI’s API, you must have an OPENAI_KEY set in your environment. Below is a simple Python function I use to fetch responses from the GPT model:
import os
from openai import OpenAI
from dotenv import load_dotenv
def ask_chat_gpt(prompt):
load_dotenv()
api_key = os.getenv("OPENAI_KEY") or exit("API key missing")
client = OpenAI(api_key=api_key)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
Overview of What the Code Does
This code automates the generation of structured LaTeX documentation for Python algorithms, complete with examples, plots, and Python code listings. Here’s an overview:
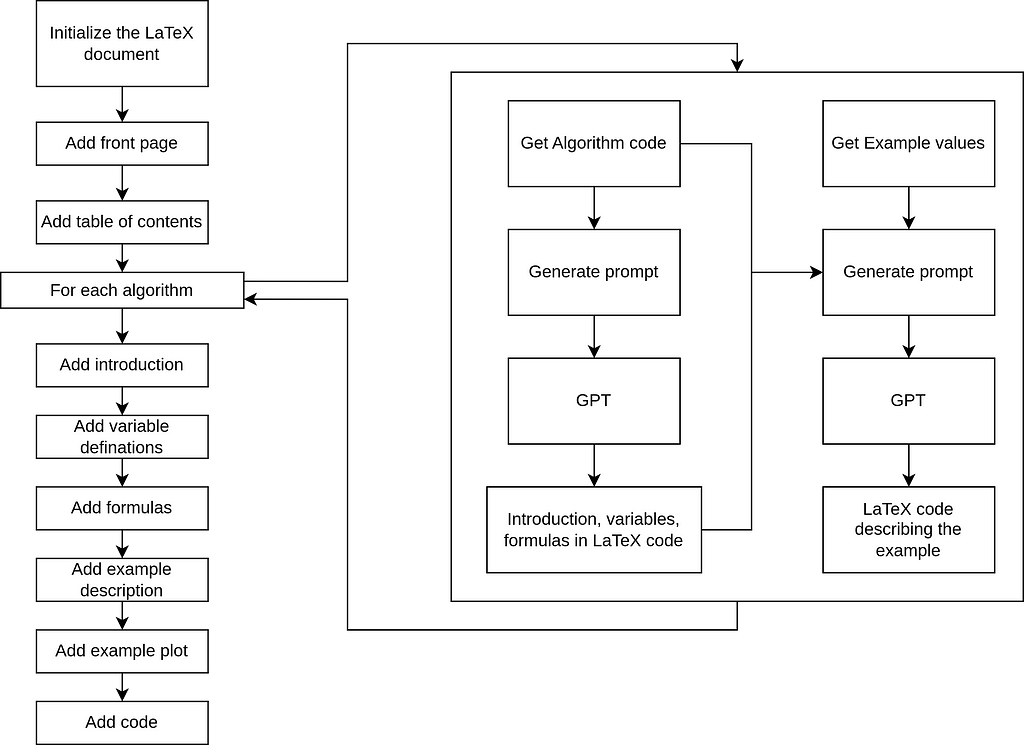
Prompt Creation for GPT
This section describes custom functions designed to generate detailed prompts for GPT, enabling the automated creation of LaTeX documentation:
Document Generation
These functions are responsible for processing the GPT-generated content and saving it as LaTeX files:
LaTeX Assembly
# Create and structure the LaTeX document programmatically
doc = Document(documentclass="report")
# Include preamble and metadata
doc.preamble.append(NoEscape(r'input{algo_docs/init.tex}')) # Custom preamble
doc.append(NoEscape(r'input{algo_docs/title_page.tex}')) # Title page
doc.append(NoEscape(r'tableofcontents')) # Table of contents
# Add Introduction Chapter
with doc.create(Chapter('Introduction')):
doc.append(
'This document provides an overview of various algorithms, exploring their design, analysis, and application in computational problem-solving. '
'The aim is to facilitate understanding of their mechanisms and significance across different domains.'
)
# Add Algorithms Chapter
with doc.create(Chapter('Algorithms')):
doc.append(
'This chapter presents detailed analyses of various algorithms, highlighting their theoretical foundations, use cases, and practical insights. '
'Each algorithm is accompanied by examples and visualizations to illustrate its functionality and potential limitations.'
)
# Process each Python file in the 'python_code' directory
python_code_dir = "python_code/"
output_folder = "algo_docs/"
plot_folder = "plots/"
for filename in os.listdir(python_code_dir):
if filename.endswith(".py"): # Process only Python files
algorithm_name = filename.replace(".py", "")
formatted_name = algorithm_name.replace("_", " ").title()
# Define paths for documentation files and plots
document_path = os.path.join(output_folder, f"{algorithm_name}_doc.tex")
example_path = os.path.join(output_folder, f"{algorithm_name}_example.tex")
plot_path = os.path.join(plot_folder, f"{algorithm_name}_plot.png")
python_code_path = os.path.join(python_code_dir, filename)
print(f"Processing: {filename}")
# Start a new page for each algorithm
doc.append(NoEscape(r'newpage'))
# Generate documentation and example files with GPT
make_algo_doc(algorithm_name)
make_algo_example(algorithm_name)
# Insert generated LaTeX sections
doc.append(NoEscape(rf'input{{{document_path}}}'))
doc.append(NoEscape(rf'input{{{example_path}}}'))
# Insert plot directly after example subsection
if os.path.exists(plot_path):
with doc.create(Figure(position='H')) as figure:
figure.add_image(plot_path, width=NoEscape(r'textwidth'))
figure.add_caption(f'Example plot for {formatted_name}.')
# Add a subsection for the Python code listing
with doc.create(Subsection('Code Listing')):
doc.append(NoEscape(rf'lstinputlisting[language=Python]{{{python_code_path}}}'))
# Add a page break for clarity
doc.append(NoEscape(r'clearpage'))
# Generate the LaTeX file
tex_file = "programmatic_report"
doc.generate_tex(tex_file)
# Compile the LaTeX file to a PDF
subprocess.run(["pdflatex", f"{tex_file}.tex"])
PDF Compilation


One of the most challenging aspects of this project was designing and refining the prompts used to interact with GPT. The success of the entire process depended on the quality of the GPT-generated output, making the creation of effective prompts a critical task that required extensive time and experimentation.
The prompts needed to strike a delicate balance:
To address these challenges, I implemented dynamic prompting. This approach involved programmatically generating prompts tailored to the contents of each file. By providing GPT with relevant context and specific instructions, dynamic prompting ensured the output was both accurate and contextually appropriate for the given algorithm.
Through numerous iterations, the prompts evolved to become precise and flexible, forming the foundation of the automation process.
Example of a prompt for generating LaTeX code from a algorithm:
Generate LaTeX code from the provided Python code. Follow these guidelines:
1. **Document Structure**:
- Start with `\section{}` for the algorithm title.
- Add a `\subsection{Introduction}` for a brief overview of the algorithm.
- Include a `\subsection{Variables}` section that lists all variables with descriptions, using subscript notation (e.g., `v_{\text{earth}}`).
- Add a `\subsection{Formulas}` section presenting the code's logic as LaTeX formulas. Use subscripted symbols for variable names instead of copying Python variable names directly.
2. **Formatting Rules**:
- Ensure that the output includes **only** the LaTeX content, without `\documentclass`, `\usepackage`, `\begin{document}`, `\end{document}`, or any unrelated text.
- Do **not** include the triple backticks (e.g., ```latex or ```).
- Properly close all LaTeX environments (e.g., `\begin{align*}...\end{align*}`).
- Ensure all brackets, parentheses, and braces are matched correctly.
- Maintain consistent subscript notation for all variables.
3. **Important Notes**:
- **Do not** include any text or explanations outside the LaTeX code.
- Only the relevant LaTeX content for the `\section`, `\subsection`, `\begin{align*}`, and `\end{align*}` parts should be generated.
- Ensure no extra or unrelated LaTeX sections are added.
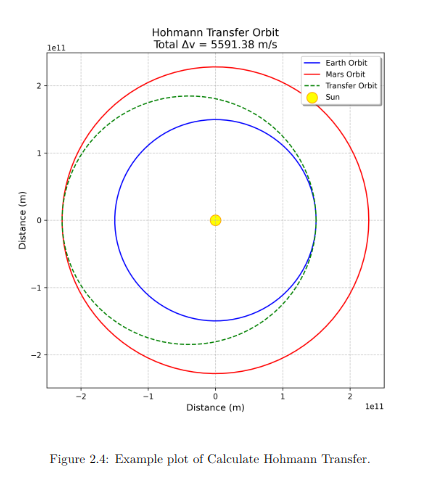
The following demonstrates how the Hohmann Transfer Orbit Calculation algorithm is documented using GPT-generated LaTeX code. This algorithm calculates the velocity changes (delta-v) required to transfer a spacecraft from Earth’s orbit to Mars’s orbit. Below is the Python implementation of the algorithm:
def calculate_hohmann_transfer(earth_orbit_radius, mars_orbit_radius):
# Gravitational constant for the Sun
mu_sun = 1.32712440018e20
# Orbital velocities of Earth and Mars
v_earth = np.sqrt(mu_sun / earth_orbit_radius)
v_mars = np.sqrt(mu_sun / mars_orbit_radius)
# Semi-major axis of the transfer orbit
transfer_orbit_semi_major_axis = (earth_orbit_radius + mars_orbit_radius) / 2
# Transfer orbit velocities at Earth and Mars
v_transfer_at_earth = np.sqrt(2 * mu_sun / earth_orbit_radius - mu_sun / transfer_orbit_semi_major_axis)
v_transfer_at_mars = np.sqrt(2 * mu_sun / mars_orbit_radius - mu_sun / transfer_orbit_semi_major_axis)
# Delta-v at Earth and Mars
delta_v_earth = v_transfer_at_earth - v_earth
delta_v_mars = v_mars - v_transfer_at_mars
# Total delta-v for the transfer
total_delta_v = abs(delta_v_earth) + abs(delta_v_mars)
return delta_v_earth, delta_v_mars, total_delta_v
Using the GPT prompt with this code, I generated LaTeX subsections for the documentation. Below are the components created:
Introduction to the Algorithm
GPT generated a LaTeX explanation of the algorithm’s purpose, detailing how it calculates velocity changes for an efficient interplanetary transfer.

Variable Definitions
GPT provided a clear explanation of all variables used in the algorithm.

Formulas
The key formulas used in the algorithm were formatted into LaTeX by GPT.

Example Section
Using example values, GPT generated LaTeX code for a worked example.

Plot Generation
A plot of the transfer orbit was generated using the example values and included in the LaTeX document.
Code Listing
The algorithm’s source code was appended to the document for completeness at the end.

Initial experiments with this system have been promising. Using Python and GPT-4, I successfully automated the conversion of several algorithms into LaTeX documents. The results of this proof of concept (POC) can be explored in my GitHub repository, where all aspects of the project are available for review.
The repository includes the complete Python codebase, showcasing the custom functions used to generate LaTeX documentation and create GPT prompts. It also contains the detailed prompts themselves, illustrating how the system guides GPT in producing structured and accurate LaTeX content. Additionally, the repository features the final outputs, including both the LaTeX source files and the compiled PDF documents.
While the initial results have been promising, the process has not been without its challenges and valuable insights along the way::
Despite its imperfections, the workflow has drastically reduced the time spent on documentation by automating much of the process. While minor reviews and adjustments are still needed, they represent only a fraction of the effort previously required. This proof of concept demonstrates the potential to generate polished documents without writing LaTeX manually, though further refinement is needed to enhance consistency, scalability, and adaptability. The results so far highlight the significant promise of this approach.
This project has proven the potential of GPT models to automate the creation of structured LaTeX documentation, significantly reducing the manual effort involved. It successfully generated professional-quality outputs, including formulas, plots, and structured examples. However, challenges such as inconsistent results, formatting issues, and variability in GPT’s output highlighted the need for refinement. Strategies like dynamic prompting, better code commenting, and iterative validation have helped address these issues, but some manual oversight remains necessary.
Despite these challenges, the workflow has shown clear benefits, streamlining the documentation process and saving considerable time. While the solution is not yet perfect, it represents a significant step toward automating complex documentation tasks, paving the way for future improvements in accuracy.
From Code to Paper: Using GPT Models and Python to Generate Scientific LaTeX Documents was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
From Code to Paper: Using GPT Models and Python to Generate Scientific LaTeX Documents

Working on scientific papers often involves translating algorithms into scientific formulas, typically formatted in LaTeX. This process can be tedious and time-consuming, especially in large projects, as it requires constant back-and-forth between the code repository and the LaTeX document.
While working on a large repository of algorithms, I began exploring ways to streamline this workflow. My motivation arose from the inefficiency of manually converting complex algorithms into LaTeX-compatible formulas. A particular challenge was ensuring consistency across multiple documents, especially in projects where formulas required frequent updates. This led me to explore how automation could streamline repetitive tasks while improving accuracy.
For the remainder of this document, I will use both the term “algorithm” and “scientific code.” All images in this article, except for the cover image, were created by the author.
My goal was to transition from scientific code to a comprehensive document that introduces the purpose of the code, defines variables, presents scientific formulas, includes a generated example plot, and demonstrates the calculations for a specific example. The document would follow a predefined framework, combining static and dynamic elements to ensure both consistency and adaptability.
The framework I designed included the following structure:
This structure was designed to dynamically adapt based on the number of algorithms being documented, ensuring a consistent and professional presentation regardless of the document’s size or complexity.
To achieve this goal, a well-organized repository was essential for enabling a scalable and efficient solution. The algorithm calculations were grouped into a dedicated folder, with files named using a consistent snake_case convention that matched the algorithm names.
To ensure clarity and support reuse, initial values for examples and the generated plots were stored in separate folders. These folders followed the same naming convention as the algorithms but with distinct suffixes to differentiate their purpose. This structure ensured that all components were easy to find and consistent with the overall framework of the project.
At the core of this project is the use of GPT models to automate the conversion of algorithms into LaTeX. GPT’s strength lies in its ability to interpret the structure of generic, variable-rich code and transform it into human-readable explanations and precisely formatted scientific formulas. This automation significantly reduces the manual effort required, ensuring both accuracy and consistency across documents.
For this project, I will leverage OpenAI’s ChatGPT-4o model, renowned for its advanced ability to comprehend and generate structured content. To interact with OpenAI’s API, you must have an OPENAI_KEY set in your environment. Below is a simple Python function I use to fetch responses from the GPT model:
import os
from openai import OpenAI
from dotenv import load_dotenv
def ask_chat_gpt(prompt):
load_dotenv()
api_key = os.getenv("OPENAI_KEY") or exit("API key missing")
client = OpenAI(api_key=api_key)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
Overview of What the Code Does
This code automates the generation of structured LaTeX documentation for Python algorithms, complete with examples, plots, and Python code listings. Here’s an overview:
Prompt Creation for GPT
This section describes custom functions designed to generate detailed prompts for GPT, enabling the automated creation of LaTeX documentation:
Document Generation
These functions are responsible for processing the GPT-generated content and saving it as LaTeX files:
LaTeX Assembly
# Create and structure the LaTeX document programmatically
doc = Document(documentclass="report")
# Include preamble and metadata
doc.preamble.append(NoEscape(r'input{algo_docs/init.tex}')) # Custom preamble
doc.append(NoEscape(r'input{algo_docs/title_page.tex}')) # Title page
doc.append(NoEscape(r'tableofcontents')) # Table of contents
# Add Introduction Chapter
with doc.create(Chapter('Introduction')):
doc.append(
'This document provides an overview of various algorithms, exploring their design, analysis, and application in computational problem-solving. '
'The aim is to facilitate understanding of their mechanisms and significance across different domains.'
)
# Add Algorithms Chapter
with doc.create(Chapter('Algorithms')):
doc.append(
'This chapter presents detailed analyses of various algorithms, highlighting their theoretical foundations, use cases, and practical insights. '
'Each algorithm is accompanied by examples and visualizations to illustrate its functionality and potential limitations.'
)
# Process each Python file in the 'python_code' directory
python_code_dir = "python_code/"
output_folder = "algo_docs/"
plot_folder = "plots/"
for filename in os.listdir(python_code_dir):
if filename.endswith(".py"): # Process only Python files
algorithm_name = filename.replace(".py", "")
formatted_name = algorithm_name.replace("_", " ").title()
# Define paths for documentation files and plots
document_path = os.path.join(output_folder, f"{algorithm_name}_doc.tex")
example_path = os.path.join(output_folder, f"{algorithm_name}_example.tex")
plot_path = os.path.join(plot_folder, f"{algorithm_name}_plot.png")
python_code_path = os.path.join(python_code_dir, filename)
print(f"Processing: {filename}")
# Start a new page for each algorithm
doc.append(NoEscape(r'newpage'))
# Generate documentation and example files with GPT
make_algo_doc(algorithm_name)
make_algo_example(algorithm_name)
# Insert generated LaTeX sections
doc.append(NoEscape(rf'input{{{document_path}}}'))
doc.append(NoEscape(rf'input{{{example_path}}}'))
# Insert plot directly after example subsection
if os.path.exists(plot_path):
with doc.create(Figure(position='H')) as figure:
figure.add_image(plot_path, width=NoEscape(r'textwidth'))
figure.add_caption(f'Example plot for {formatted_name}.')
# Add a subsection for the Python code listing
with doc.create(Subsection('Code Listing')):
doc.append(NoEscape(rf'lstinputlisting[language=Python]{{{python_code_path}}}'))
# Add a page break for clarity
doc.append(NoEscape(r'clearpage'))
# Generate the LaTeX file
tex_file = "programmatic_report"
doc.generate_tex(tex_file)
# Compile the LaTeX file to a PDF
subprocess.run(["pdflatex", f"{tex_file}.tex"])
PDF Compilation
One of the most challenging aspects of this project was designing and refining the prompts used to interact with GPT. The success of the entire process depended on the quality of the GPT-generated output, making the creation of effective prompts a critical task that required extensive time and experimentation.
The prompts needed to strike a delicate balance:
To address these challenges, I implemented dynamic prompting. This approach involved programmatically generating prompts tailored to the contents of each file. By providing GPT with relevant context and specific instructions, dynamic prompting ensured the output was both accurate and contextually appropriate for the given algorithm.
Through numerous iterations, the prompts evolved to become precise and flexible, forming the foundation of the automation process.
Example of a prompt for generating LaTeX code from a algorithm:
Generate LaTeX code from the provided Python code. Follow these guidelines:
1. **Document Structure**:
- Start with `\section{}` for the algorithm title.
- Add a `\subsection{Introduction}` for a brief overview of the algorithm.
- Include a `\subsection{Variables}` section that lists all variables with descriptions, using subscript notation (e.g., `v_{\text{earth}}`).
- Add a `\subsection{Formulas}` section presenting the code's logic as LaTeX formulas. Use subscripted symbols for variable names instead of copying Python variable names directly.
2. **Formatting Rules**:
- Ensure that the output includes **only** the LaTeX content, without `\documentclass`, `\usepackage`, `\begin{document}`, `\end{document}`, or any unrelated text.
- Do **not** include the triple backticks (e.g., ```latex or ```).
- Properly close all LaTeX environments (e.g., `\begin{align*}...\end{align*}`).
- Ensure all brackets, parentheses, and braces are matched correctly.
- Maintain consistent subscript notation for all variables.
3. **Important Notes**:
- **Do not** include any text or explanations outside the LaTeX code.
- Only the relevant LaTeX content for the `\section`, `\subsection`, `\begin{align*}`, and `\end{align*}` parts should be generated.
- Ensure no extra or unrelated LaTeX sections are added.
The following demonstrates how the Hohmann Transfer Orbit Calculation algorithm is documented using GPT-generated LaTeX code. This algorithm calculates the velocity changes (delta-v) required to transfer a spacecraft from Earth’s orbit to Mars’s orbit. Below is the Python implementation of the algorithm:
def calculate_hohmann_transfer(earth_orbit_radius, mars_orbit_radius):
# Gravitational constant for the Sun
mu_sun = 1.32712440018e20
# Orbital velocities of Earth and Mars
v_earth = np.sqrt(mu_sun / earth_orbit_radius)
v_mars = np.sqrt(mu_sun / mars_orbit_radius)
# Semi-major axis of the transfer orbit
transfer_orbit_semi_major_axis = (earth_orbit_radius + mars_orbit_radius) / 2
# Transfer orbit velocities at Earth and Mars
v_transfer_at_earth = np.sqrt(2 * mu_sun / earth_orbit_radius - mu_sun / transfer_orbit_semi_major_axis)
v_transfer_at_mars = np.sqrt(2 * mu_sun / mars_orbit_radius - mu_sun / transfer_orbit_semi_major_axis)
# Delta-v at Earth and Mars
delta_v_earth = v_transfer_at_earth - v_earth
delta_v_mars = v_mars - v_transfer_at_mars
# Total delta-v for the transfer
total_delta_v = abs(delta_v_earth) + abs(delta_v_mars)
return delta_v_earth, delta_v_mars, total_delta_v
Using the GPT prompt with this code, I generated LaTeX subsections for the documentation. Below are the components created:
Introduction to the Algorithm
GPT generated a LaTeX explanation of the algorithm’s purpose, detailing how it calculates velocity changes for an efficient interplanetary transfer.
Variable Definitions
GPT provided a clear explanation of all variables used in the algorithm.
Formulas
The key formulas used in the algorithm were formatted into LaTeX by GPT.
Example Section
Using example values, GPT generated LaTeX code for a worked example.
Plot Generation
A plot of the transfer orbit was generated using the example values and included in the LaTeX document.
Code Listing
The algorithm’s source code was appended to the document for completeness at the end.
Initial experiments with this system have been promising. Using Python and GPT-4, I successfully automated the conversion of several algorithms into LaTeX documents. The results of this proof of concept (POC) can be explored in my GitHub repository, where all aspects of the project are available for review.
The repository includes the complete Python codebase, showcasing the custom functions used to generate LaTeX documentation and create GPT prompts. It also contains the detailed prompts themselves, illustrating how the system guides GPT in producing structured and accurate LaTeX content. Additionally, the repository features the final outputs, including both the LaTeX source files and the compiled PDF documents.
While the initial results have been promising, the process has not been without its challenges and valuable insights along the way::
Despite its imperfections, the workflow has drastically reduced the time spent on documentation by automating much of the process. While minor reviews and adjustments are still needed, they represent only a fraction of the effort previously required. This proof of concept demonstrates the potential to generate polished documents without writing LaTeX manually, though further refinement is needed to enhance consistency, scalability, and adaptability. The results so far highlight the significant promise of this approach.
This project has proven the potential of GPT models to automate the creation of structured LaTeX documentation, significantly reducing the manual effort involved. It successfully generated professional-quality outputs, including formulas, plots, and structured examples. However, challenges such as inconsistent results, formatting issues, and variability in GPT’s output highlighted the need for refinement. Strategies like dynamic prompting, better code commenting, and iterative validation have helped address these issues, but some manual oversight remains necessary.
Despite these challenges, the workflow has shown clear benefits, streamlining the documentation process and saving considerable time. While the solution is not yet perfect, it represents a significant step toward automating complex documentation tasks, paving the way for future improvements in accuracy.
From Code to Paper: Using GPT Models and Python to Generate Scientific LaTeX Documents was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
From Code to Paper: Using GPT Models and Python to Generate Scientific LaTeX Documents


In this article, I explore the fundamental concepts explained in the research paper titled “DRAGIN : Dynamic Retrieval Augmented Generation based on the Information Needs of Large Language Models” by Weihang Su, Yichen Tang, Qingyao Ai, Zhijing Wu, and Yiqun Liu. This paper can be accessed here.
Introduction — Lets look at a short story!
Imagine you’re working on a problem. At the very beginning, you get only one chance to ask your professor for guidance. This means it’s important to understand the entire scope of the problem upfront. If it’s a simple problem, that might be fine — you ask your question, get clarity, and move forward.
Now, imagine that the problem is much more complex. The more you dive into it, the more questions you have! Unfortunately, you can’t go back to your professor because all your questions had to be asked at the start. This makes solving the problem much harder.
But what if, instead, you were allowed to go back to your professor every time you discovered a new question that expanded the scope of the problem? This approach lets you navigate the complexity iteratively, asking for guidance whenever the problem evolves. That is the essence of DRAGIN (Dynamic RAG) over Traditional RAG.
And given how complex and multi-dimensional our tasks, problems, and worlds have become, the need for this dynamic approach is greater than ever!
Large Language models have changed the way we all access information. We are at that point where the way we search has forever changed. Now, instead of finding multiple links and processing the information to answer our questions, we can directly ask the LLM!
However, there are still a number of issues :
To overcome the above issues, Retrieval Augmented Generation (RAG) emerged as a promising solution. The way it works, is by accessing and incorporating the relevant external information needed for the LLM to generate accurate responses.
However with traditional RAG methods, they rely on single-round retrieval, which would mean retrieving external information once, at the start of the information generation. This works well for straightforward tasks, however our needs and requirements from LLMs are getting more complex, multi-step and requiring longer responses.
In these cases, a single-round of retrieval will not work well and mutiple rounds of retrieval need to be conducted. Now when, we talk about retrieving information more than once, the two next questions are :
When to retrieve and What to retrieve? To solve these, a number of RAG methods have been devised :
IRCoT (Fixed Sentence RAG) [1] : Retrieval is conducted for each generated query and the latest sentence is used as a query.
RETRO [2] and IC-RALM [3] (Fixed Length RAG) : A sliding window is defined and the retrieval module is triggered every n tokens.
But aren’t we retrieving too often and hence retrieving information that may be unnecessary ? This would introduce noise and could jeopardize the quality of the LLM’s outputs, which defeats the original purpose of improving accuracy. These rules are still static and we need to think of dynamic ways of retrieval.
FLARE [4] (Low Confidence RAG) : Retrieval is conducted dynamically, when the LLM’s confidence (the generation probability) on the next token is lower than certain thresholds. So FLARE, is triggering retrieval based on uncertainty.
For determining what to retrieve, the LLMs often restrict themselves to queries based on the last few generated tokens or sentences. These methods of query formulation for retrieval may not work, when the tasks get more complex and the LLM’s information needs span over the entire context!
Finally, moving on to the star of the show : DRAGIN!
This method is specifically designed to make decisions about when and what to retrieve to cater to the LLM’s information needs. So, it optimizes the process of information retrieval using two frameworks. As the authors explain in their paper, DRAGIN has two key frameworks :
I. RIND (Real-time Information Needs Detection) : When to retrieve ?
It considers the LLM’s uncertainty about its own content, the influence of each token and the semantics of each token.
II. QFS (Query Formulation based on Self-Attention) : What to retrieve?
Query formulation leverages the LLM’s self-attention across the entire context, rather than not just the last few tokens or sentences.
To illustrate the above frameworks, the paper uses an example query about the ‘brief introduction to Einstein’.
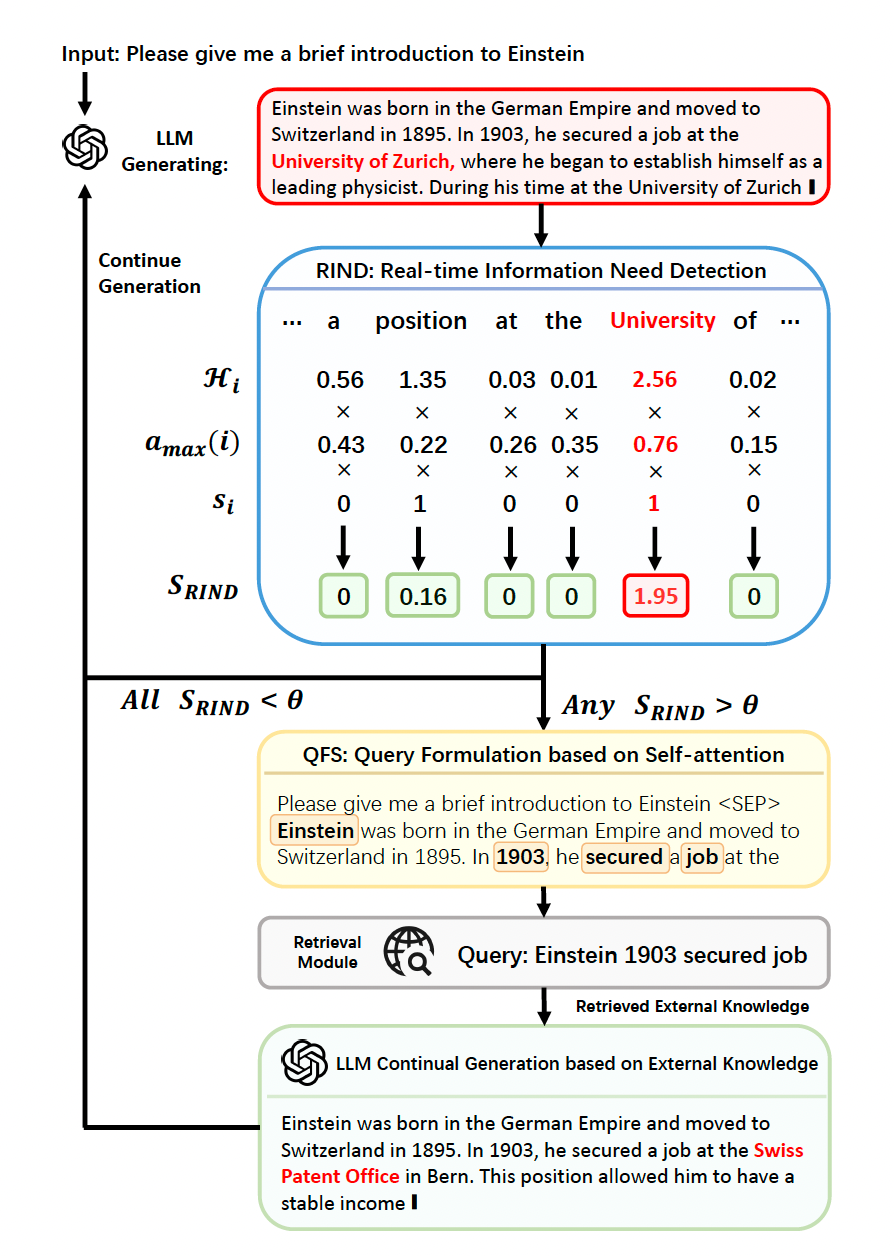
Explanation :
Input is Provided: The system is queried to provide some introduction about Einstein.
Processing Starts: The system begins generating a response based on what it knows. It uses the RIND module to decide if it has enough information or if it needs to look things up.
Checking for Required Information (RIND): The system breaks down the query into smaller parts (tokens), like “position,” “at,” “University,” etc. It checks which parts (tokens) need more information. For example, “university” might need additional data because it’s not specific enough.
Triggering Retrieval: If a token like “university” is considered to be important and unclear, the system triggers retrieval to gather external information about it. In this case, it looks up relevant data about Einstein and universities.
Formulating the Query (QFS): The system uses its self attention mechanism to determine which words are most relevant for forming a precise query. For example, it might pick “Einstein,” “1903,” and “secured a job” as the key parts.
These keywords are used to craft a query, such as “Einstein 1903 secured a job,” which is sent to an external source for information.
Retrieving and Adding Information: The external source provides the required details. For example, it might return, “In 1903, Einstein secured a job at the Swiss Patent Office.” The system incorporates this new information into the response.
Continuing Generation: With the new details, the system continues generating a more complete and accurate response.For example, it might now say, “In 1903, Einstein secured a job at the Swiss Patent Office. This allowed him to have a stable income.”
Repeating the Process: If more requirements are identified, the process repeats: checking, retrieving, and integrating information until the response is complete and accurate. This process ensures that the system can dynamically fill in gaps in its knowledge and provide detailed, accurate answers by combining what it knows with retrieved external information.
The frameworks mentioned in the paper are:
A. Real-time Information Needs Detection (RIND) : Retrieval is triggered based on uncertainty of tokens, influence on other tokens and semantic significance of each token.
i. The uncertainty of each token generated by the LLM, is quantified. This is done by calculating the entropy of the token’s probability distribution across the vocabulary. Consider an output sequence T = {t1,t2,…tn}, with each ti representing an individual token at the position i. For any token ti, the entropy is calculated as follows :
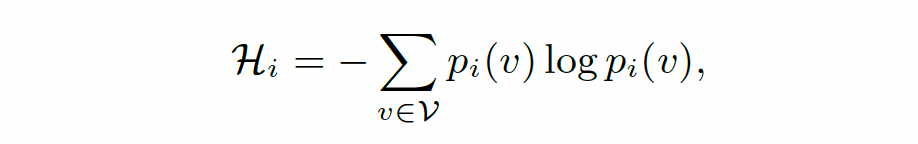
where pi(v) denotes the probability of generating the token v over all the tokens in the vocabulary.
ii. The influence of each token on subsequent tokens, is done by leveraging the self-attention scores. For a token t, the max attention value is identified
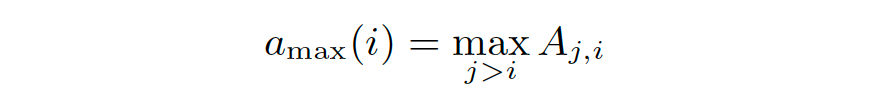
iii. The semantic contribution of each token ti, a binary indicator is employed. This filters out stop words.
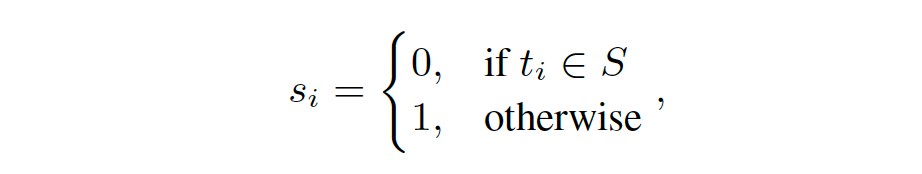
Combining the uncertainty, significance and semantics, RIND computes a score and if this is greater than a pre-defined threshold then retrieval is triggered.
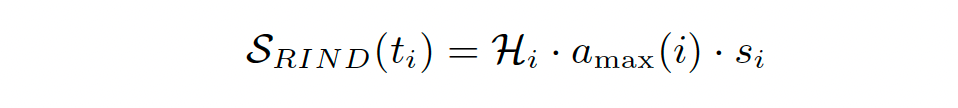
B. Query Formulation based on Self-Attention (QFS)
Once retrieval is triggered, the next step is to formulate an efficient query from external databases for the continued generation of LLMs. In the existing dynamic RAG frameworks, queries are formulated using the last sentence or last tokens generated by the LLM. This narrow scope doesn’t capture the need for real-time information needs. It examines the full context.
Suppose RIND identifies the token ti at position i, requires external knowledge and triggers retrieval.
Since the token ti was generated based on based on the knowledge of all the preceding tokens, it only makes sense to look at the entire content generated, until now, to formulate a query. It uses the following steps:
Step 1: Extracts the attention scores of the last transformer layer for each token ti.
Step 2: Sorts the attention scores in descending order, to identify the top n scores. (This is basically, identifying the most important tokens).
Step 3: Finds the words corresponding to these tokens from the vocabulary and arranges them in their original order. (This brings back the structure of the language form the attention scores and tokens).
Step 4 : Construct the query Qi using the words associated with these top n tokens.
C. Continue Generation after Retrieval
Once RIND has identified the position i, at which external knowledge is needed and QFS creates the query, Qi to extract the information using an off-the-shelf retrieval model (e.g. BM25).
It finds the relevant information in documents Di1, Di2 and Di3. It integrates the relevant information at position i, by truncating the LLM’s output. This retrieved knowledge is integrated using the following designed prompt template.

As the paper states, the primary limitations of this paper is the reliance on the self-attention mechanisms for both the Real-time Information Needs Detection (RIND) and Query Formulation based on Self-Attention (QFS). While self-attention scores are available for all source LLMs, it is not applicable for certain APIs that do not provide access to self-attention scores.
A point worth considering is the impact on inference time latency and cost: in the paper, the authors point out that these are only marginally more since an imperfect token sub-sequence is rapidly detected, and further generation is interrupted until remediation.
The DRAGIN framework allows us to look to move a few steps ahead of the traditional RAG framework. It allows us to perform multiple retrievals, based on the information needs of generation. It is an optimized framework for multiple retrievals!
Our needs and requirements from LLMs are becoming larger and more complex, and in such cases where we want to retrieve information accurately, with just the right number of retrievals.
To conclude, DRAGIN :
Strikes the perfect balance for the number of retrievals.
Produces highly context-aware queries for retrievals.
Generates content from the LLMs with better accuracy!
Thank you so much for reading and for a more detailed explanation of the research paper, please watch my video!
References :
[1] Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. arXiv preprint arXiv:2212.10509.
[2] Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. 2022.
[3] Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2023. In-context retrieval-augmented language models. arXiv preprint arXiv:2302.00083.
[4] Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. arXiv preprint arXiv:2305.06983.
DRAGIN: Dynamic Retrieval Augmented Generation based on the Information Needs of Large Language… was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
DRAGIN: Dynamic Retrieval Augmented Generation based on the Information Needs of Large Language…