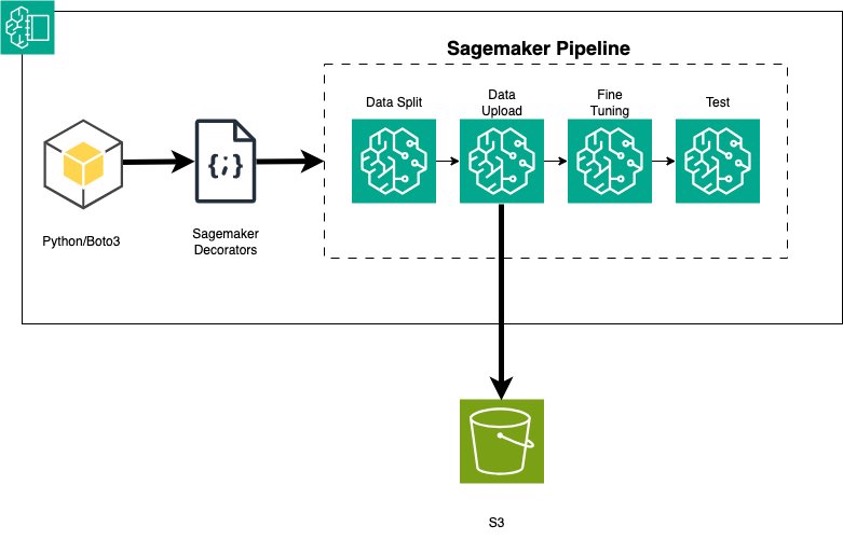
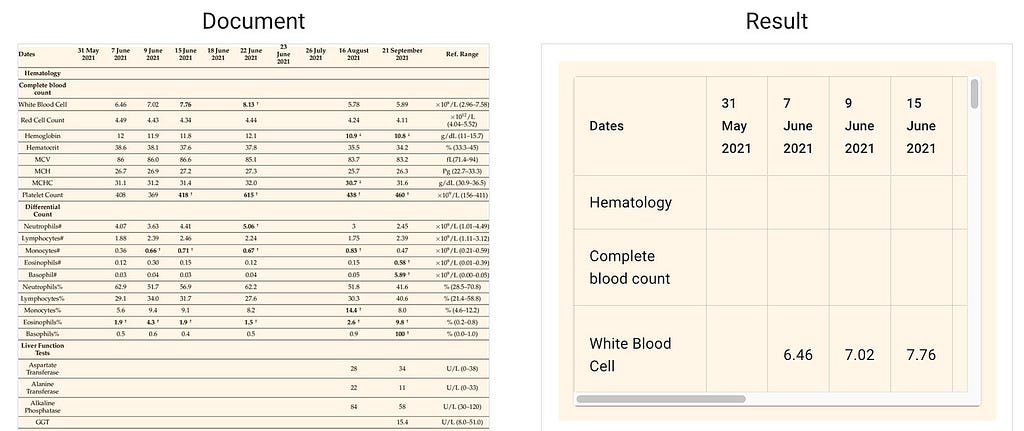
In this post, we show you how to convert Python code that fine-tunes a generative AI model in Amazon Bedrock from local files to a reusable workflow using Amazon SageMaker Pipelines decorators.
The future is here and you don’t get killer robots. You get great automation for tedious office work.
Almost a decade ago, I worked as a Machine Learning Engineer at LinkedIn’s illustrious data standardization team. From the day I joined to the day I left, we still couldn’t automatically read a person’s profile and reliably understand someone’s seniority and job title across all languages and regions.
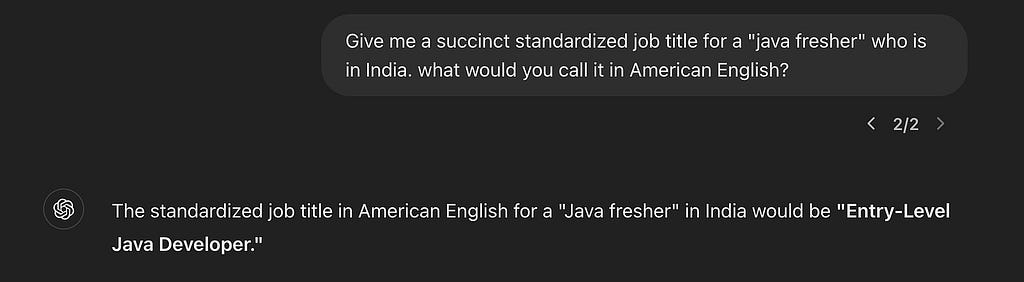
This looks simple at first glance. “software engineer” is clear enough, right? How about someone who just writes “associate”? It might be a low seniority retail worker, if they’re in Walmart, or a high ranking lawyer if they work in a law firm. But you probably knew that — do you know what’s a Java Fresher? What’s Freiwilliges Soziales Jahr? This isn’t just about knowing the German language — it translates to “Voluntary Social year”. But what’s a good standard title to represent this role? If you had a large list of known job titles, where would you map it?
I joined LinkedIn, I left LinkedIn. We made progress, but making sense of even the most simple regular texts — a person’s résumé, was elusive.
Very hard becomes trivial
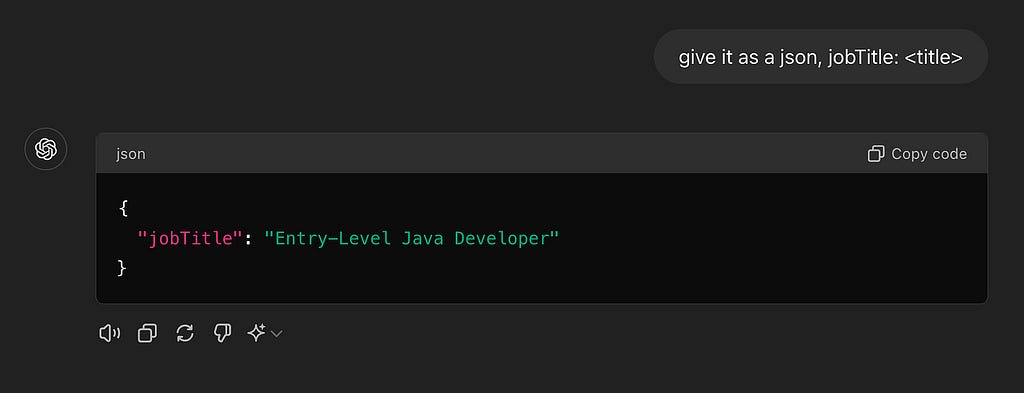
You probably won’t be shocked to learn that this problem is trivial for an LLM like GPT-4
Easy peasy for GPT (source: me. and GPT)
But wait, we’re a company, not a guy in a chat terminal, we need structured outputs.
(source: GPT)
Ah, that’s better. You can repeat this exercise with the most nuanced and culture-specific questions. Even better, you can repeat this exercise when you get an entire person’s profile, that gives you more context, and with code, which gives you the ability to use the results consistently in a business setting, and not only as a one off chat. With some more work you can coerce the results into a standard taxonomy of allowable job titles, which would make it indexable. It’s not an exaggeration to say if you copy & paste all of a person’s resume and prompt GPT just right, you will exceed the best results obtainable by some pretty smart people a decade ago, who worked at this for years.
High Value Office Work == Understanding Documents
The specific example of standardizing reumès is interesting, but it stays limited to where tech has always been hard at work — at a tech website that naturally applies AI tools. I think there’s a deeper opportunity here. A large percent of the world’s GDP is office work that boils down to expert human intelligence being applied to extract insights from a document repeatedly, with context. Here are some examples at increasing complexity:
Expense management is reading an invoice and converting it to a standardized view of what was paid, when, in what currency, and for which expense category. Potentially this decision is informed by background information about the business, the person making the expense, etc.
Healthcare claim adjudication is the process of reading a tangled mess of invoices and clinican notes and saying “ok so all told there was a single chest X-ray with a bunch of duplicates, it cost $800, and it maps to category 1-C in the health insurance policy”.
A loan underwriter might look at a bunch of bank statements from an applicants and answer a sequence of questions. Again, this is complex only because the inputs are all over the place. The actual decision making is something like “What’s the average inflow and outflow of cash, how much of it is going towards loan repayment, and which portion of it is one-off vs actual recurring revenue”.
Reasoning about text is LLM’s home turf
By now LLMs are notorious for being prone to hallucinations, a.k.a making shit up. The reality is more nuanced: hallucinations are in fact apredictable result in some settings, and are pretty much guaranteed not to happen in others.
The place where hallucinations occur is when you ask it to answer factual questions and expect the model to just “know” the answer from its innate knowledge about the world. LLMs are bad and introspecting about what they know about the world — it’s more like a very happy accident that they can do this at all. They weren’t explicitly trained for that task. What they were trained for is to generate a predictable completion of text sequences. When an LLM is grounded against an input text and needs to answer questions about the content of that text, it does not hallucinate. If you copy & paste this blog post into chatGPT and ask does it teach you how to cook a an American Apple Pie, you will get the right result 100% of the time. For an LLM this is a very predictable task, where it sees a chunk of text, and tries to predict how a competent data analyst would fill a set of predefined fields with predefined outcomes, one of which is {“is cooking discussed”: false}.
Previously as an AI consultant, we’ve repeatedly solved projects that involved extracting information from documents. Turns out there’s a lot of utility there in insurance, finance, etc. There was a large disconnect between what our clients feared (“LLMs hellucinate”) vs. what actually destroyed us (we didn’t extract the table correctly and all errors stem from there). LLMs did fail — when we failed them present it with the input text in a clean and unambiguous way. There are two necessary ingredients to build automatic pipelines that reason about documents:
Perfect Text extraction that converts the input document into clean, understandable plain text. That means handling tables, checkmarks, hand-written comments, variable document layout etc. The entire complexity of a real world form needs to convert into a clean plaintext that makes sense in an LLM’s mind.
Robust Schemas that define exactly what outputs you’re looking from a given document type, how to handle edge cases, what data format to use, etc.
Text extraction is trickier than first meets the eye
Here’s what causes LLMs to crash and burn, and get ridiculously bad outputs:
The input has complex formatting like a double column layout, and you copy & pasted in text from e.g. a PDF from left to right, taking sentences completely out of context.
The input has checkboxes, checkmarks, hand scribbled annotations, and you missed them altogether in conversion to text
Even worse: you thought you can get around converting to text, and hope to just paste a picture of a document and have GPT reason about it on its own. THIS gets your into hallucination city. Just ask GPT to transcribe an image of a table with some empty cells and you’ll se it happily going apeshit and making stuff up willy nilly.
It always helps to remember what a crazy mess goes on in real world documents. Here’s a casual tax form:
Of course real tax forms have all these fields filled out, often in handwriting
Or here’s my resumè
Source: my resume
Or a publicly available example lab report (this is a front page result from Google)
The absolute worst thing you can do, by the way, is ask GPT’s multimodal capabilities to transcribe a table. Try it if you dare — it looks right at first glance, and absolutely makes random stuff up for some table cells, takes things completely out of context, etc.
If something’s wrong with the world, build a SaaS company to fix it
When tasked with understanding these kinds of documents, my cofounder Nitai Dean and I were befuddled that there aren’t any off-the-shelf solutions for making sense of these texts.
Some people claim to solve it, like AWS Textract. But they make numerous mistakes on any complex document we’ve tested on. Then you have the long tail of small things that are necessary, like recognizing checkmarks, radio button, crossed out text, handwriting scribbles on a form, etc etc.
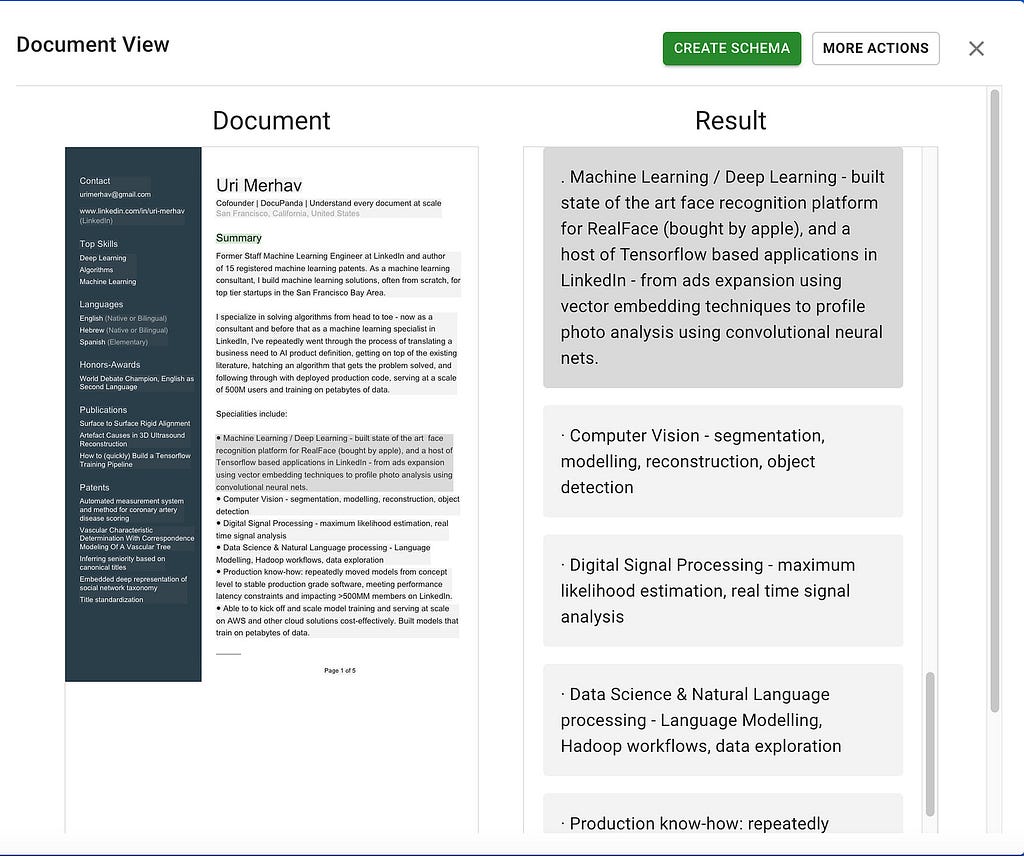
So, we built Docupanda.io — which first generates a clean text representation of any page you throw at it. On the left hand you’ll see the original document, and on the right you can see the text output
Source: docupanda.io
Tables are similarly handled. Under the hood we just convert the tables into huuman and LLM-readable markdown format:
Source: docupanda.io
The last piece to making sense of data with LLMs is generating and adhering to rigid output formats. It’s great that we can make AI mold its output into a json, but in order to apply rules, reasoning, queries etc on data — we need to make it behave in a regular way. The data needs to conform to a predefined set of slots which we’ll fill up with content. In the data world we call that a Schema.
Building Schemas is a trial an error process… That an LLM can do
The reason we need a schema, is that data is useless without regularity. If we’re processing patient records, and they map to “male” “Male” “m” and “M” — we’re doing a terrible job.
So how do you build a schema? In a textbook, you might build a schema by sitting long and hard and staring at the wall, and defining that what you want to extract. You sit there, mull over your healthcare data operation and go “I want to extract patient name, date, gendfer and their physician’s name. Oh and gender must be M/F/Other.”
In real life, in order to define what to extract from documents, you freaking stare at your documents… a lot. You start off with something like the above, but then you look at documents and see that one of them has a LIST of physicians instead of one. And some of them also list an address for the physicians. And some addresses have a unit number and a building number, so maybe you need a slot for that. On and on it goes.
What we came to realize is that being able to define exactly what’s all the things you want to extract, is both non-trivial, difficult, and very solvable with AI.
That’s a key piece of DocuPanda. Rather than just asking an LLM to improvise an output for every document, we’ve built the mechanism that lets you:
Specify what things you need to get from a document in free language
Have our AI map over many documents and figure out a schema that answers all the questions and accommodates the kinks and irregularities observed in actual documents.
Change the schema with feedback to adjust it to your business needs
What you end up with is a powerful JSON schema — a template that says exactly what you want to extract from every document, and maps over hundreds of thousands of them, extracting answers to all of them, while obeying rules like always extracting dates in the same format, respecting a set of predefined categories, etc.
Source: docupanda.io
Plenty More!
Like with any rabbit hole, there’s always more stuff than first meets the eye. As time went by, we’ve discovered that more things are needed:
Often organizations have to deal with an incoming stream of anonymous documents, so we automatically classify them and decide what schema to apply to them
Documents are sometimes a concatenation of many documents, and you need an intelligent solution to break apart a very long documents into its atomic, seperate components
Querying for the right documents using the generated results is super useful
If there’s one takeaway from this post, it’s that you should look into harnessing LLMs to make sense of documents in a regular way. If there’s two takeawways, it’s that you should also try out Docupanda.io. The reason I’m building it is that I believe in it. Maybe that’s a good enough reason to give it a go?
If you’re a regular reader of the Variable, you might have noticed that we stress—every week—that TDS is always open to contributions from new authors. And we mean it! Some of you might have seen this message and thought something along the lines of “great, I’d love to write an article!” but then wondered what kinds of posts would be a good fit, what topics our readers are interested in, and what types of experiences and skill sets are welcome.
This week’s Variable edition highlights some of our best recent articles, so if you have no desire to become a TDS author, that’s totally fine! We hope you enjoy your reading as always. We’ve focused exclusively on posts by our most recent cohort of authors, however, in the hope that their work inspires you to give this a try, too.
As you’ll see, TDS contributors come to us with a wide range of experience levels (from early learners to PhDs and industry veterans), interests, and writing styles. What unites them is great storytelling skills and a desire to share their knowledge with a broader community. We hope (and are fairly certain) you’ll enjoy our weekly lineup.
What Do Large Language Models “Understand”? “When we attribute human-like abilities to LLMs, we fall into an anthropomorphic bias by likening their capabilities to our own. But are we also showing an anthropocentric bias by failing to recognize the capabilities that LLMs consistently demonstrate?” In one of the most thought-provoking articles we’ve read recently, Tarik Dzekman tackles the question of LLMs’ capacity to understand language, looking at the topic through a philosophy- and psychology-informed lens.
Integrating LLM Agents with LangChain into VICA “Our goal is to say goodbye to the robotic and awkward form-like experience within a chatbot, and say hello to personalized conversations with human-like assistance.” Ng Wei Cheng and Nicole Ren share practical insights and lessons learned from their extensive work on Singapore’s GovTech Virtual Intelligent Chat Assistant (VICA) platform.
Text Vectorization Demystified: Transforming Language into Data “For those of us who are aware of the machine learning pipeline in general, we understand that feature engineering is a very crucial step in generating good results from the model. The same concept applies in NLP as well.” Lakshmi Narayanan offers a thorough overview of text-vectorization approaches and weighs their respective advantages and limitations.
Leveraging Gemini-1.5-Pro-Latest for Smarter Eating “It is worth noting here that with advancements in the world of AI, it is incumbent on data scientists to gradually shift from traditional deep learning to generative AI techniques in order to revolutionize their role.” Mary Ara presents an end-to-end project walkthrough that demonstrates how to do precisely that—in this case, through the creation of a calorie-tracking app that leverages a cutting-edge multimodal model.
The Most Useful Advanced SQL Techniques to Succeed in the Tech Industry “Although mastering basic and intermediate SQL is relatively easy, achieving mastery of this tool and wielding it adeptly in diverse scenarios is sometimes challenging.” Jiayan Yin aims to help data analysts and other practitioners bridge that skill gap with a comprehensive overview of the more advanced SQL techniques you should add to your querying toolkit.
Fine-Tune the Audio Spectrogram Transformer with Hugging Face Transformers “This process adapts the model’s capabilities to the unique characteristics of our dataset, such as classes and data distribution, ensuring the relevance of the results.” Writing at the intersection of machine learning and audio data, Marius Steger outlines a detailed workflow for fine-tuning the Audio Spectrogram Transformer (AST) on any audio-classification dataset.
Algorithm-Agnostic Model Building with MLflow “Consider this scenario: we have an sklearn model currently deployed in production for a particular use case. Later on, we find that a deep learning model performs even better. If the sklearn model was deployed in its native format, transitioning to the deep learning model could be a hassle because the two model artifacts are very different.” Mena Wang, PhD explains why it can sometimes make a lot of sense to work with algorithm-agnostic models—and shows how to get started in MLflow.
A Fresh Look at Nonlinearity in Deep Learning “But why do we need activation functions in the first place, specifically nonlinear activation functions? There’s a traditional reasoning, and also a new way to look at it.” Harys Dalvi unpacks the stakes of using a linear layer for the output of deep learning classifiers and the value we can gain by interpreting the consequences of linearity and nonlinearity in multiple ways.
Thank you for supporting the work of our authors! As we mentioned above, we love publishing articles from new authors, so if you’ve recently written an interesting project walkthrough, tutorial, or theoretical reflection on any of our core topics, don’t hesitate to share it with us.
While the timeline remains somewhat uncertain, the overwhelming consensus is that machines will eventually take over most work. Rather than getting bogged down in a debate about exactly when this will happen, in two years or in twenty, it’s more productive to ask what we can do to adapt and thrive in a world where work by artificial intelligence (AI) systems is growing increasingly prevalent, often at the cost of human jobs.
As a society, we are faced with a stark choice of what will happen when the machines eventually take over jobs: will people be left destitute, or will they enjoy leisure time and be empowered to live life on their own terms. The latter scenario isn’t just about not working. It’s about having the freedom to pursue what brings us joy, without the burden of financial stress. It’s about having the time and resources to explore our passions, travel, learn, and grow, without the constant pressure of making ends meet. In this scenario, people would still be free to work, but only because they want to, not because they have to. They could also pursue their own entrepreneurial ventures, whether a side hustle or a full-fledged startup, without the constraint of needing to fully support themselves.
The fundamental challenge how can we take the huge bounty that will eventually be produced by automated AI systems and share it in a reasonable way. In the US our current tax structure is based primarily on taxing the work of individuals through income tax, but as more people inevitably lose work that source of revenue is going to shrink while at the same time the need for support will grow. Instead of taxing a shrinking pool of human work, perhaps we should tax the growing work of AI systems instead.
The Need for Universal Basic Income
Universal Basic Income (UBI) has gained attention in recent years as a potential solution to the challenges posed by automation. At its core, UBI is a government provision of set amount of income for every individual, regardless of their background, employment status, or financial situation. This unconditional income would provide a financial foundation for everyone, untethered from any job or employer. It would not be contingent on employment, savings, or income levels. It would be universal, meaning that everyone who is part of the system, from the most impoverished to the wealthiest, would receive the same amount money.
The biggest glaring problem with implementing UBI is figuring out how to fund it. In the United States, individual income taxes are the primary source of government revenue. However, this situation would create a circular problem where taxes come from income, and income comes from taxes. Attempting to adjust the taxation system to cover UBI for both workers and non-workers would put an unsustainable burden on those still employed, who may feel understandably resentful. Moreover, as AI systems increasingly replace human jobs, the shrinking workforce would struggle to bear the growing weight of funding the entire system.
This issue of a shrinking base of income tax payers will be a pressing concern, irrespective of UBI. As jobs are taken over by AI income tax revenue will shrink, while simultaneously the number of people needing assistance will grow. Continually increasing taxes on those who would still have jobs would not be sustainable.
Leaving the majority of the population to starve on the street isn’t a reasonable option, even for the cold hearted. Not only would it be grossly unfair, inhumane, and reprehensible, it would also not be politically stable. If those people who end up directly benefiting from AI automation cavalierly tell those who don’t to “go eat cake” then they probably should probably expect a violent backlash similar to the one that has become linked to that phrase.
If the alternative is infeasible then we must find some way to support those without jobs. The current unemployment and welfare systems are inadequate, plagued by huge bureaucracies and irrational penalties for working. Even if these support systems were effective, they would still rely on a shrinking tax base, which is unsustainable and would only perpetuate the problem. Therefore, we need to explore alternative solutions that can support people without jobs, and how to fund them from sustainable sources.
Challenges of Funding UBI
Some have already suggested a national sales tax as one possible solution to address the shrinking income tax base. While sales taxes can be regressive, meaning that people with less money tend to pay a larger fraction of their income relative to those with more money, a well-designed tax can mitigate this effect. For instance, exemptions for essential items like groceries, medical expenses, and housing could ensure that a sales tax is more progressive. Ideally, profitable corporations would bear the brunt of the tax, as they would be the direct beneficiaries of AI-driven efficiency. Some might expect that corporations would simply pass the cost on to customers, but the benefits of AI-driven productivity should offset those costs.
Building on this last point, we could make the taxation of AI-related savings explicit by designing a tax system that specifically targets the benefits of automation. By mildly taxing AI-related cost savings, corporations would still reap the benefits of automation while contributing to the broader social good. Importantly, as jobs are taken over by AI systems, leaving more people in need of assistance, tax revenues would grow instead of shrink.
This core concept of requiring that the benefits of AI be shared with society is a fundamental goal. Under the current system, people work to produce value, and their salary is essentially a slice of that value minus the costs of production. The employer also takes a slice as does the government. This leads to a zero-sum game where there is a limit to the total value created by a pool workers and trying to share the value broadly with those who don’t have jobs invariably leads to shrinking the existing slices. With AI work, the costs of production are less and there is no employee share.
Whatever the details, one thing seems inescapable and essential: If AI systems are going to take over human work and therefore human salary earning, then they must also replace human tax paying.
Also note that while some work by AI systems will take jobs away from humans, the total amount of work done by AI is likely to be much greater than the number of human jobs displaced. One reason for this difference is that AI is capable of doing things that would be too difficult or dangerous, or conversely too trivial or boring for people to do. Another reason is that AI systems can be scaled up more easily than a human workforce. This greater base means that AI work could be taxed at a much lower rate than we currently tax human work.
Measuring AI Work
Imagine a world where the work done by AI systems can be measured and quantified. One possible approach is to use a concept called “Human Equivalent Effort Time” (HEET), which represents the amount of time a typical human would need to complete the same task. With HEET, we could track AI automation not only as it replaces human labor, but also as it creates new work opportunities for AI systems. A measurement like this would allow us to tax the work done by AI systems in a way that’s fair, efficient, and sustainable.
By taxing AI work in HEET units, we can create a new revenue stream that supplements and eventually replaces traditional income taxes. This approach would enable continued revenue growth as AI systems become faster, more efficient, and easier to scale. Unlike human labor, AI systems are relatively inexpensive to maintain and can be replicated easily, allowing growth without all the difficulties typically involved when trying to hire more people.
A side point to note is that the AI systems discussed here are simply software designed to perform specific tasks, without any consciousness or self-awareness. Using a sentient AI for most work appears neither necessary nor desirable. An amusing illustration of this point is from the TV show Rick and Morty, where a character creates a sentient robot just to pass butter at the breakfast table. The robot experiences an existential crisis and sadness when it realizes its purpose is so trivial. While humorous, it nevertheless demonstrates potential pitfalls of creating sentient AI just for work tasks.
Like the butter-passing robot, humans experience boredom and depression when faced with tasks that are monotonous or of little value. Unnecessarily replicating that experience with our machines seems pointless and cruel. The vast majority tasks can be accomplished without self-awareness, and there’s no need to create complex artificial life to perform them. (Which is a good thing because we don’t currently know how to make self-aware software.) Machines with no sentience do not need a slice of the value they create beyond their operating costs.
I don’t think measuring HEET would be clear and simple, but it doesn’t seem impossible. We know a lot about human workers and what they are capable of and that knowledge could be applied to assessing any task performed by an AI system and estimating how much time a human would take to do it or something similar. Making that determination for the millions of tasks that AI will be used for sounds tedious, but it’s also something that could be automated by AI systems. One could imagine that instead of reporting how much a company paid in payroll and taxing that payroll, companies would instead report how much HEET was done by their software and pay a tax on that.
One could imagine that an AI system managed by the IRS that would take descriptions of work done, assign an amount of HEET, and access a tax. As with today’s tax systems, this would require some honesty and also some penalties for lying. People would not enjoy the process and there would likely be frequent appeals of the assessment. People would intentionally or by error fail to report work, and everyone would probably continue to hate the IRS. In other words, it would not be that different from today’s taxation. We would be trading one frustrating bureaucratic tax system for another, with the key difference being that this new one would tax rapidly growing AI-driven productivity rather than dwindling personal income.
Some Details
One expected objection to taxing AI work is that it would be burdensome on companies and that it would stifle innovation and growth. However, that objection doesn’t really stand up to scrutiny. Today, a large company wanting work done must hire someone which requires paying the person and paying taxes. If AI systems are doing the work and being taxed, then there is no salary to pay and the amount of taxation could be much smaller than what they would otherwise pay in payroll and payroll taxes. For example, instead of paying an employee $50K, plus $10K in payroll taxes (and hopefully some amount for benefits) to get one human unit of work done, a company might instead deploy ten human-equivalent AI systems, paying $1K in taxes for each, thus getting 10x the work done for 1/6th the total cost while the government still collects the same amount in taxes.
The idea that everyone comes out ahead sounds nonsensical from our normal zero-sum perspective. How can everyone come out ahead? The critical change will be a vast pool of AI workers that do work yet need nearly nothing in return.
Individuals and small companies might look to AI automation to enable activities where labor is needed but they can’t afford to pay for human staffing. For these small entities, paying a tax on the use of AI systems might make their business infeasible. In this respect, taxing HEET could stifle innovation and create barriers to new competition. However, the system could be designed to avoid this problem.
For example, business use with less than $1 million in gross annual revenue and personal use could both be exempted from HEET tax. To avoid a sudden cost shock, the tax could ramp up between $1 million and $2 million gross annual revenue, allowing these businesses to adjust to the new tax gradually without being overwhelmed by the burden. One could imagine a carefully thought out system with other appropriate exemptions.
The Future of Work and Human Wellbeing
The future of work is going to very clearly be one of massive automation by AI systems and those AI systems are going to be very productive. AI systems won’t take sick days. An AI run factory will not need to have space devoted to safe places for humans to stand and it can run 24/7. An AI accounting service won’t need to spend money on office space, HR, or training. If you have an enterprise staffed by AI and you want to expand, you just need to buy some more computers or maybe some more robots. The majority of the multitude of things that limit human productivity do not apply to AI systems. This bounty of savings is what will make something like UBI possible, but only if we find a way to share that bounty beyond the specific owners of the AI systems.
Today, being unable to find a job causes significant stress and insecurity, with unemployment being linked to a higher risk of depression and anxiety. Moreover, the financial and societal pressure to find a job can be overwhelming and debilitating. However, people without jobs who are financially secure often find that they’re able to pursue their passions without the stress of needing to earn a living. For instance, a well-planned and well-funded retirement provides the financial freedom to devote oneself to rewarding activities that bring joy and fulfillment, without the limitation of needing to support oneself financially.
If we find a way to share the bounty produced by AI, we could create a world where no one needs to struggle with poverty or homelessness. People would have the freedom to pursue their passions and interests, and spend their days doing what brings them joy. They might devote themselves to creative pursuits, adventures, or community service, and have the time and resources to nurture meaningful relationships. In this world, work would be a choice, not a necessity, and people would not spend most of their waking hours working for someone else.
This isn’t the first time someone has predicted “the end of work,” but this time is fundamentally different. In the past, technological advances made human work more efficient. Instead of spending hundreds of person hours to dig a hole, one person with a steam-shovel could dig it in a couple hours. Rather than painstakingly building something one at a time by hand, the same number of workers in a factory could churn out hundreds every hour. However, you still needed people. Now consider a factory with no people, or construction equipment that drives and operates itself. Production with zero people is only possible because AI systems can make operational decisions and handle exceptions on their own.
Final Thoughts
My suggestion of taxing the work done by AI system is admittedly somewhat inchoate and vague. It probably has a hundred problems that would need answers and thousands of details that need figuring out. Also, there may be much better ideas that I’ve overlooked, both for funding and for distributing support. A national sales tax or a tax on HEET are just two possibilities. Maybe something as simple as taxing power spent on computing would suffice, or maybe we will need complex new mathematical theories relating to the value of a computation.
I also suggested some exceptions and thresholds that would be intended to keep the tax burden on the corporations that can afford it and that are benefitting from replacing human employees with AI systems. Determining what those exceptions and thresholds should be will require careful thought and analysis to make the numbers work. A badly designed system could be worse than doing nothing. This problem is a place for math and economics, not political squabbling and catering to special interests.
In conclusion, my proposal for taxing AI work is just one possible solution for sharing the fruits of AI automation. While still in its early stages, I believe this is an important conversation to have. As we move forward, it’s crucial that we prioritize careful consideration and analysis to ensure that any solution we choose is fair, effective, and sustainable. Rather than getting bogged down in partisan politics, let’s focus on finding a solution that benefits all people, not just a select few.
Regardless of what the actual solution ends up being, if we don’t find a way to share the bounty produces by AI systems, then I fear that most people in the world are going to be left behind and suffer greatly. We have a choice in front of us: dystopian inequity or a bright world with ample resources for all. Unfortunately, the default if we do nothing is the dystopian one. I very much hope that we can put aside our differences and fears, and focus on realizing the brighter possibility.
About Me: James F. O’Brien is a Professor of Computer Science at the University of California, Berkeley. His research interests include computer graphics, computer animation, simulations of physical systems, human perception, rendering, image synthesis, machine learning, virtual reality, digital privacy, and the forensic analysis of images and video.
Disclaimer: Any opinions expressed in this article are those of the author as a private individual. Nothing in this article should be interpreted as a statement made in relation to the author’s professional position with any institution.
This article and all embedded images are Copyright 2024 by the author. This article was written by a human, and both an LLM and other humans were used for proofreading and editorial suggestions.
Today, we are excited to announce general availability of batch inference for Amazon Bedrock. This new feature enables organizations to process large volumes of data when interacting with foundation models (FMs), addressing a critical need in various industries, including call center operations. In this post, we demonstrate the capabilities of batch inference using call center transcript summarization as an example.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.