In this blog post, I will look at what makes physical AWS DeepRacer racing—a real car on a real track—different to racing in the virtual world—a model in a simulated 3D environment. I will cover the basics, the differences in virtual compared to physical, and what steps I have taken to get a deeper understanding of the challenge.
Concerns about the environmental impacts of Large Language Models (LLMs) are growing. Although detailed information about the actual costs of LLMs can be difficult to find, let’s attempt to gather some facts to understand the scale.
Generated with ChatGPT-4o
Since comprehensive data on ChatGPT-4 is not readily available, we can consider Llama 3.1 405B as an example. This open-source model from Meta is arguably the most “transparent” LLM to date. Based on various benchmarks, Llama 3.1 405B is comparable to ChatGPT-4, providing a reasonable basis for understanding LLMs within this range.
Inference
The hardware requirements to run the 32-bit version of this model range from 1,620 to 1,944 GB of GPU memory, depending on the source (substratus, HuggingFace). For a conservative estimate, let’s use the lower figure of 1,620 GB. To put this into perspective — acknowledging that this is a simplified analogy — 1,620 GB of GPU memory is roughly equivalent to the combined memory of 100 standard MacBook Pros (16GB each). So, when you ask one of these LLMs for a tiramisu recipe in Shakespearean style, it takes the power of 100 MacBook Pros to give you an answer.
Training
I’m attempting to translate these figures into something more tangible… though this doesn’t include the training costs, which are estimated to involve around 16,000 GPUs at an approximate cost of $60 million USD (excluding hardware costs) — a significant investment from Meta — in a process that took around 80 days. In terms of electricity consumption, training required 11 GWh.
The annual electricity consumption per person in a country like France is approximately 2,300 kWh. Thus, 11 GWh corresponds to the yearly electricity usage of about 4,782 people. This consumption resulted in the release of approximately 5,000 tons of CO₂-equivalent greenhouse gases (based on the European average), , although this figure can easily double depending on the country where the model was trained.
For comparison, burning 1 liter of diesel produces 2.54 kg of CO₂. Therefore, training Llama 3.1 405B — in a country like France — is roughly equivalent to the emissions from burning around 2 million liters of diesel. This translates to approximately 28 million kilometers of car travel. I think that provides enough perspective… and I haven’t even mentioned the water required to cool the GPUs!
Sustainability
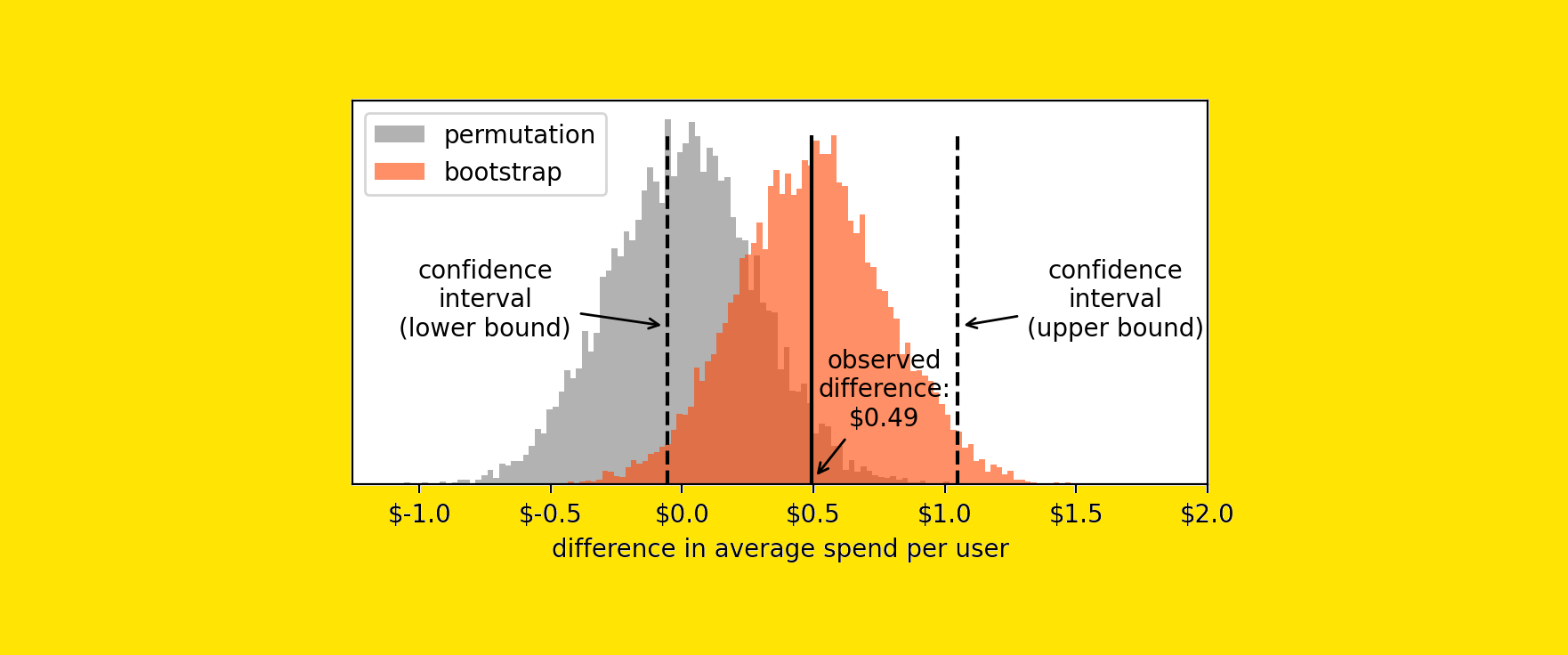
Clearly, AI is still in its infancy, and we can anticipate more optimal and sustainable solutions to emerge over time. However, in this intense race, OpenAI’s financial landscape highlights a significant disparity between its revenues and operational expenses, particularly in relation to inference costs. In 2024, the company is projected to spend approximately $4 billion on processing power provided by Microsoft for inference workloads, while its annual revenue is estimated to range between $3.5 billion and $4.5 billion. This means that inference costs alone nearly match — or even exceed — OpenAI’s total revenue (deeplearning.ai).
All of this is happening in a context where experts are announcing a performance plateau for AI models (scaling paradigm). Increasing model size and GPUs are yielding significantly diminished returns compared to previous leaps, such as the advancements GPT-4 achieved over GPT-3. “The pursuit of AGI has always been unrealistic, and the ‘bigger is better’ approach to AI was bound to hit a limit eventually — and I think this is what we’re seeing here” said Sasha Luccioni, researcher and AI lead at startup Hugging Face.
And now?
But don’t get me wrong — I’m not putting AI on trial, because I love it! This research phase is absolutely a normal stage in the development of AI. However, I believe we need to exercise common sense in how we use AI: we can’t use a bazooka to kill a mosquito every time. AI must be made sustainable — not only to protect our environment but also to address social divides. Indeed, the risk of leaving the Global South behind in the AI race due to high costs and resource demands would represent a significant failure in this new intelligence revolution..
So, do you really need the full power of ChatGPT to handle the simplest tasks in your RAG pipeline? Are you looking to control your operational costs? Do you want complete end-to-end control over your pipeline? Are you concerned about your private data circulating on the web? Or perhaps you’re simply mindful of AI’s impact and committed to its conscious use?
SLM can be a smarter choice!
Small language models (SLMs) offer an excellent alternative worth exploring. They can run on your local infrastructure and, when combined with human intelligence, deliver substantial value. Although there is no universally agreed definition of an SLM — in 2019, for instance, GPT-2 with its 1.5 billion parameters was considered an LLM, which is no longer the case — I am referring to models such as Mistral 7B, Llama-3.2 3B, or Phi3.5, to name a few. These models can operate on a “good” computer, resulting in a much smaller carbon footprint while ensuring the confidentiality of your data when installed on-premise. Although they are less versatile, when used wisely for specific tasks, they can still provide significant value — while being more environmentally virtuous.
Smaller is smarter was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Real-world examples on how actively using special methods can simplify coding and improve readability.
Dunder methods, though possibly a basic topic in Python, are something I have often noticed being understood only superficially, even by people who have been coding for quite some time.
Disclaimer: This is a forgivable gap, as in most cases, actively using dunder methods “simply” speeds up and standardize tasks that can be done differently. Even when their use is essential, programmers are often unaware that they are writing special methods that belong to the broader category of dunder methods.
Anyway, if you code in Python and are not familiar with this topic, or if you happen to be a code geek intrigued by the more native aspects of a programming language like I am, this article might just be what you’re looking for.
Appearances can deceive… even in Python!
If there is one thing I learned in my life is that not everything is what it seems like at a first look, and Python is no exception.
This is the “emptiest” custom class we can define in Python, as we did not define attributes or methods. It is so empty you would think you can do nothing with it.
However, this is not the case. For example, Python will not complain if you try to create an instance of this class or even compare two instances for equality:
Of course, this is not magic. Simply, leveraging a standard object interface, any object in Python inherits some default attributes and methods that allow the user to always have a minimal set of possible interactions with it.
While these methods may seem hidden, they are not invisible. To access the available methods, including the ones assigned by Python itself, just use the dir() built-in function. For our empty class, we get:
It is these methods that can explain the behaviour we observed earlier. For example, since the class actually has an __init__ method we should not be surprised that we can instantiate an object of the class.
Meet the Dunder Methods
All the methods shown in the last output belongs to the special group of — guess what — dunder methods. The term “dunder” is short for double underscore, referring to the double underscores at the beginning and end of these method names.
They are special for several reasons:
They are built into every object: every Python object is equipped with a specific set of dunder methods determined by its type.
They are invoked implicitly: many dunder methods are triggered automatically through interactions with Python’s native operators or built-in functions. For example, comparing two objects with == is equivalent to calling their __eq__ method.
They are customizable: you can override existing dunder methods or define new ones for your classes to give them custom behavior while preserving their implicit invocation.
For most Python developers, the first dunder they encounter is __init__, the constructor method. This method is automatically called when you create an instance of a class, using the familiar syntax MyClass(*args, **kwargs) as a shortcut for explicitly calling MyClass.__init__(*args, **kwargs).
Despite being the most commonly used, __init__ is also one of the most specialized dunder methods. It does not fully showcase the flexibility and power of dunder methods, which can allow you to redefine how your objects interact with native Python features.
Make an object pretty
Let us define a class representing an item for sale in a shop and create an instance of it by specifying the name and price.
class Item: def __init__(self, name: str, price: float) -> None: self.name = name self.price = price
item = Item(name="Milk (1L)", price=0.99)
What happens if we try to display the content of the item variable? Right now, the best Python can do is tell us what type of object it is and where it is allocated in memory:
>>> item <__main__.Item at 0x00000226C614E870>
Let’s try to get a more informative and pretty output!
To do that, we can override the __repr__ dunder, which output will be exactly what gets printed when typing a class instance in the interactive Python console but also — as soon as the other dunder method __str__ is not override — when attempting a print() call.
Note: it is a common practice to have __repr__ provide the necessary syntax to recreate the printed instance. So in that latter case we expect the output to be Item(name=”Milk (1L)”, price=0.99).
class Item: def __init__(self, name: str, price: float) -> None: self.name = name self.price = price
>>> item # In this example it is equivalent also to the command: print(item) Item('Milk (1L)', 0.99)
Nothing special, right? And you would be right: we could have implemented the same method and named it my_custom_repr without getting indo dunder methods. However, while anyone immediately understands what we mean with print(item) or just item, can we say the same for something like item.my_custom_repr()?
Define interaction between an object and Python’s native operators
Imagine we want to create a new class, Grocery, that allows us to build a collection of Item along with their quantities.
In this case, we can use dunder methods for allowing some standard operations like:
Adding a specific quantity of Item to the Grocery using the + operator
Iterating directly over the Grocery class using a for loop
Accessing a specific Item from the Grocery class using the bracket [] notation
To achieve this, we will define (we already see thata generic class do not have these methods by default) the dunder methods __add__, __iter__ and __getitem__ respectively.
from typing import Optional, Iterator from typing_extensions import Self
The __iter__ method allows us to loop through a Grocery object following the logic implemented in the method (i.e., implicitly the loop will iterate over the elements contained in the iterable attribute items).
>>> print([item for item in grocery]) [Item('Milk (1L)', 0.99), Item('Soy Sauce (0.375L)', 1.99)]
Similarly, accessing elements is handled by defining the __getitem__ dunder:
>>> grocery[new_item] 1
fake_item = Item("Creamy Cheese (500g)", 2.99) >>> grocery[fake_item] KeyError: "Item Item('Creamy Cheese (500g)', 2.99) not in the grocery"
In essence, we assigned some standard dictionary-like behaviours to our Grocery class while also allowing some operations that would not be natively available for this data type.
Enhance functionality: make classes callable for simplicity and power.
Let us wrap up this deep-dive on dunder methods with a final eample showcasing how they can be a powerful tool in our arsenal.
Imagine we have implemented a function that performs deterministic and slow calculations based on a certain input. To keep things simple, as an example we will use an identity function with a built-in time.sleep of some seconds.
What happens if we run the function twice on the same input? Well, right now calculation would be executed twice, meaning that we twice get the same output waiting two time for the whole execution time (i.e., a total of 10 seconds).
start_time = time.time()
>>> print(expensive_function(2)) >>> print(expensive_function(2)) >>> print(f"Time for computation: {round(time.time()-start_time, 1)} seconds") 2 2 Time for computation: 10.0 seconds
Does this make sense? Why should we do the same calculation (which leads to the same output) for the same input, especially if it’s a slow process?
One possible solution is to “wrap” the execution of this function inside the __call__ dunder method of a class.
This makes instances of the class callable just like functions — meaning we can use the straightforward syntax my_class_instance(*args, **kwargs) — while also allowing us to use attributes as a cache to cut computation time.
With this approach we also have the flexibility to create multiple process (i.e., class instances), each with its own local cache.
class CachedExpensiveFunction:
def __init__(self) -> None: self.cache = dict()
def __call__(self, input): if input not in self.cache: output = expensive_function(input=input) self.cache[input] = output return output else: return self.cache.get(input)
>>> print(cached_exp_func(3)) >>> print(another_cached_exp_func (3)) >>> print(f"Time for computation: {round(time.time()-start_time, 1)} seconds") 3 3 Time for computation: 10.0 seconds
Here we are! A simple yet powerful optimization trick made possible by dunder methods that not only reduces redundant calculations but also offers flexibility by allowing local, instance-specific caching.
My final considerations
Dunder methods are a broad and ever-evolving topic, and this writing does not aim to be an exhaustive resource on the subject (for this purpose, you can refer to the 3. Data model — Python 3.12.3 documentation).
My goal here was rather to explain clearly what they are and how they can be used effectively to handle some common use cases.
While they may not be mandatory for all programmers all the time, once I got a good grasp of how they work they have made a ton of difference for me and hopefully they may work for you as well.
Dunder methods indeed are a way to avoid reinventing the wheel. They also align closely with Python’s philosophy, leading to a more concise, readable and convention-friendly code. And that never hurts, right?
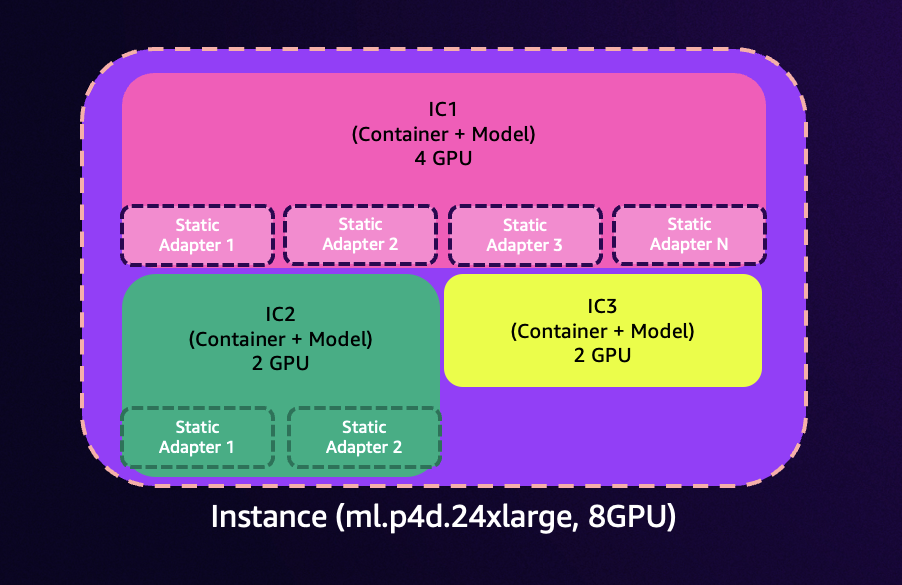
The new efficient multi-adapter inference feature of Amazon SageMaker unlocks exciting possibilities for customers using fine-tuned models. This capability integrates with SageMaker inference components to allow you to deploy and manage hundreds of fine-tuned Low-Rank Adaptation (LoRA) adapters through SageMaker APIs. In this post, we show how to use the new efficient multi-adapter inference feature in SageMaker.
Today, we are excited to announce the availability of Prompt Optimization on Amazon Bedrock. With this capability, you can now optimize your prompts for several use cases with a single API call or a click of a button on the Amazon Bedrock console. In this post, we discuss how you can get started with this new feature using an example use case in addition to discussing some performance benchmarks.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.