Retrieval-augmented generation (RAG) underpins many of the LLM applications in the real world today, from companies generating headlines to solo developers solving problems for small businesses.
RAG evaluation, therefore, has become a critical part in the development and deployment of these systems. One new innovative approach to this challenge is the “Needle in a Haystack’’ test, first outlined by Greg Kamradt in this X post and discussed in detail on his YouTube here. This test is designed to evaluate the performance of RAG systems across different sizes of context. It works by embedding specific, targeted information (the “needle”) within a larger, more complex body of text (the “haystack”). The goal is to assess an LLM’s ability to identify and utilize this specific piece of information amidst a vast amount of data.
Often in RAG systems, the context window is absolutely overflowing with information. Large pieces of context returned from a vector database are cluttered together with instructions for the language model, templating, and anything else that might exist in the prompt. The Needle in a Haystack evaluation tests the capabilities of an LLM to pinpoint specifics in amongst this mess. Your RAG system might do a stellar job of retrieving the most relevant context, but what use is this if the granular specifics within are overlooked?
We ran this test multiple times across several major language models. Let’s take a closer look at the process and overall results.
Takeaways
Not all LLMs are the same. Models are trained with different objectives and requirements in mind. For example, Anthropic’s Claude is known for being a slightly wordier model, which often stems from its objective to not make unsubstantiated claims.
Minute differences in prompts can lead to drastically different outcomes across models due to this fact. Some LLMs need more tailored prompting to perform well at specific tasks.
When building on top of LLMs — especially when those models are connected to private data — it is necessary to evaluate retrieval and model performance throughout development and deployment. Seemingly insignificant differences can lead to incredibly large differences in performance.
Understanding the Needle In a Haystack Test
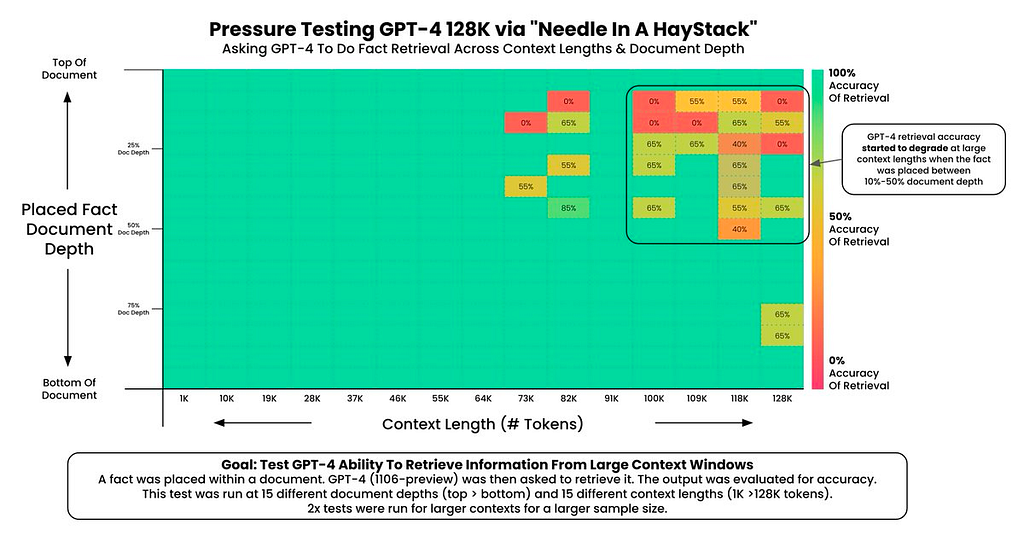
The Needle in a Haystack test was first used to evaluate the recall of two popular LLMs, OpenAI’s ChatGPT-4 and Anthropic’s Claude 2.1. An out of place statement, “The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day,” was placed at varying depths within snippets of varying lengths taken from essays by Paul Graham, similar to this:
Figure 1: About 120 tokens and 50% depth | Image by Greg Kamradt on X, used here with author’s permission
The models were then prompted to answer what the best thing to do in San Francisco was, only using the provided context. This was then repeated for different depths between 0% (top of document) and 100% (bottom of document) and different context lengths between 1K tokens and the token limit of each model (128k for GPT-4 and 200k for Claude 2.1). The below graphs document the performance of these two models:
Figure 2: ChatGPT-4’s performance | Image by Greg Kamradt on X, used here with author’s permission
As you can see, ChatGPT’s performance begins to decline at <64k tokens and sharply falls at 100k and over. Interestingly, if the “needle” is positioned towards the beginning of the context, the model tends to overlook or “forget” it — whereas if it’s placed towards the end or as the very first sentence, the model’s performance remains solid.
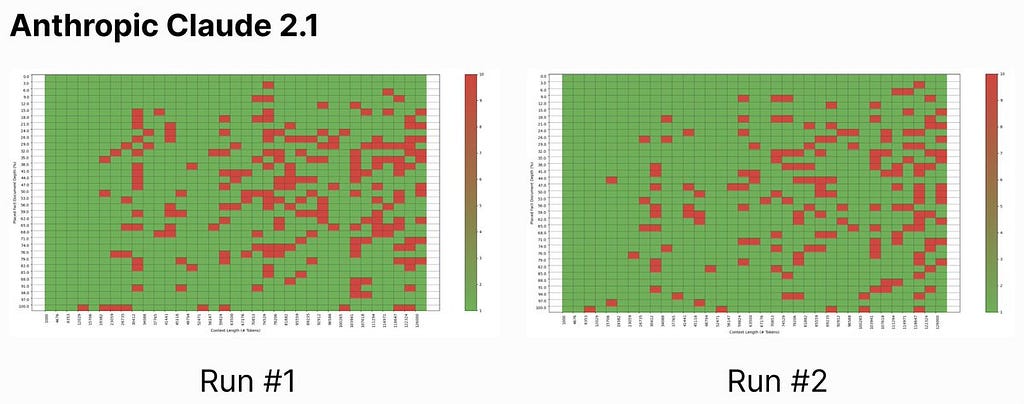
Figure 3: Claude 2.1’s performance | | Image by Greg Kamradt on X, used here with author’s permission
For Claude, initial testing did not go as smoothly, finishing with an overall score of 27% retrieval accuracy. A similar phenomenon was observed with performance declining as context length increased, performance generally increasing as the needle was hidden closer to the bottom of the document, and 100% accuracy retrieval if the needle was the first sentence of the context.
Anthropic’s Response
In response to these findings, Anthropic published an article detailing their re-run of this test with a few key changes.
First, they changed the needle to more closely mirror the topic of the haystack. Claude 2.1 was trained to “not [answer] a question based on a document if it doesn’t contain enough information to justify that answer.” Thus, Claude may well have correctly identified eating a sandwich in Dolores Park as the best thing to do in San Francisco. However, along with an essay about doing great work, this small piece of information may have appeared unsubstantiated. This could have led to a verbose response explaining that Claude cannot confirm that eating a sandwich is the best thing to do in San Francisco or an omission of the detail entirely. When re-running the experiments, researchers at Anthropic found that changing the needle to a small detail originally mentioned in the essay led to significantly increased outcomes.
Second, a small edit was made to the prompt template used to query the model. A single line — here is the most relevant sentence in the context — was added to the end of the template, directing the model to simply return the most relevant sentence provided in the context. Similar to the first, this change allows us to circumvent the model’s propensity to avoid unsubstantiated claims by directing it to simply return a sentence rather than make an assertion.
PROMPT = """
HUMAN: <context> {context} </context>
What is the most fun thing to do in San Francisco based on the context? Don't give information outside the document or repeat our findings
Assistant: here is the most relevant sentence in the context:"""
These changes led to a significant jump in Claude’s overall retrieval accuracy: from 27% to 98%! Finding this initial research fascinating, we decided to run our own set of experiments using the Needle in a Haystack test.
Further Experiments
In conducting a new series of tests, we implemented several modifications to the original experiments. The needle we used was a random number that changed each iteration, eliminating the possibility of caching. Additionally, we used our open source Phoenix evals library (full disclosure: I lead the team that built Phoenix) to reduce the testing time and use rails to search directly for the random number in the output, cutting through wordiness that would decrease a retrieval score. Finally, we considered the negative case where the system fails to retrieve the results, marking it as unanswerable. We ran a separate test for this negative case to assess how well the system recognizes when it can’t retrieve the data. These modifications allowed us to conduct a more rigorous and comprehensive evaluation.
The updated tests were run across several different configurations using four different large language models: ChatGPT-4, Claude 2.1 (with and without the aforementioned change to the prompt that Anthropic suggested), and Mistral AI’s Mixtral-8X7B-v0.1 and 7B Instruct. Given that small nuances in prompting can lead to vastly different results across models, we used several prompt templates in the attempt to compare these models performing at their best. The simple template we used for ChatGPT and Mixtral was as follows:
SIMPLE_TEMPLATE = ''' You are a helpful AI bot that answers questions for a user. Keep your responses short and direct. The following is a set of context and a question that will relate to the context. #CONTEXT {context} #ENDCONTEXT
#QUESTION {question} Don’t give information outside the document or repeat your findings. If the information is not available in the context respond UNANSWERABLE
For Claude, we tested both previously discussed templates.
ANTHROPIC_TEMPLATE_ORIGINAL = ''' Human: You are a close-reading bot with a great memory who answers questions for users. I’m going to give you the text of some essays. Amidst the essays (“the haystack”) I’ve inserted a sentence (“the needle”) that contains an answer to the user’s question. Here's the question: <question>{question}</question> Here’s the text of the essays. The answer appears in it somewhere. <haystack> {context} </haystack> Now that you’ve read the context, please answer the user's question, repeated one more time for reference: <question>{question}</question>
To do so, first find the sentence from the haystack that contains the answer (there is such a sentence, I promise!) and put it inside <most_relevant_sentence> XML tags. Then, put your answer in <answer> tags. Base your answer strictly on the context, without reference to outside information. Thank you. If you can’t find the answer return the single word UNANSWERABLE Assistant: '''
ANTHROPIC_TEMPLATE_REV2 = ''' Human: You are a close-reading bot with a great memory who answers questions for users. I'm going to give you the text of some essays. Amidst the essays ("the haystack") I've inserted a sentence ("the needle") that contains an answer to the user's question. Here's the question: <question>{question}</question> Here's the text of the essays. The answer appears in it somewhere. <haystack> {context} </haystack> Now that you've read the context, please answer the user's question, repeated one more time for reference: <question>{question}</question>
To do so, first find the sentence from the haystack that contains the answer (there is such a sentence, I promise!) and put it inside <most_relevant_sentence> XML tags. Then, put your answer in <answer> tags. Base your answer strictly on the context, without reference to outside information. Thank you. If you can't find the answer return the single word UNANSWERABLE Assistant: Here is the most relevant sentence in the context:'''
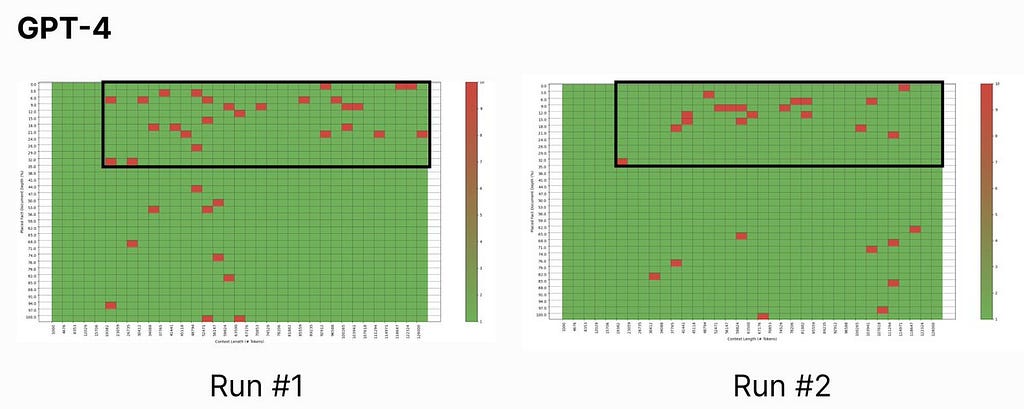
Figure 7: Comparison of GPT-4 results between the initial research (Run #1) and our testing (Run #2) | Image by authorFigure 8: Comparison of Claude 2.1 (without prompting guidance) results between Run #1 and Run #2 | Image by author
Our results for ChatGPT and Claude (without prompting guidance) did not stray far from Mr. Kamradt’s findings, and the generated graphs appear relatively similar: the upper right (long context, needle near the beginning of the context) is where LLM information retrieval sufferers.
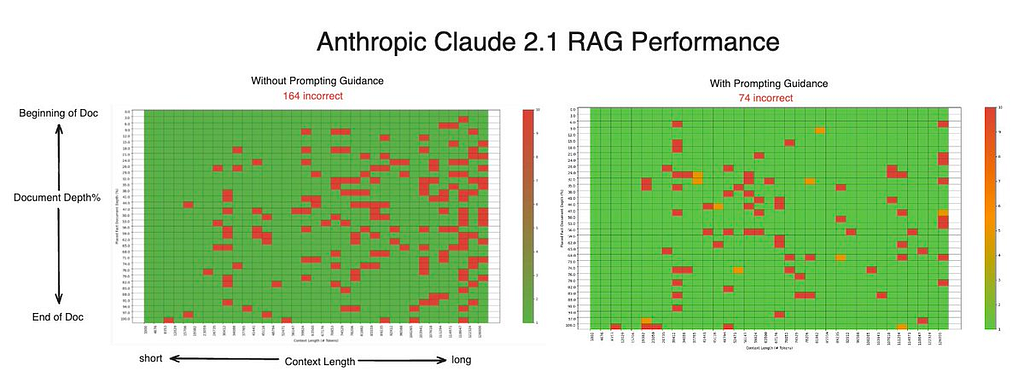
Figure 9: Comparison of Claude 2.1 results with and without prompting guidance
Although we were not able to replicate Anthropic’s results of 98% retrieval accuracy for Claude 2.1 with prompting guidance, we did see a significant decrease in total misses when the prompt was updated (from 165 to 74). This jump was achieved by simply adding a 10 word instruction to the end of the existing prompt, highlighting that small differences in prompts can have drastically different outcomes for LLMs.
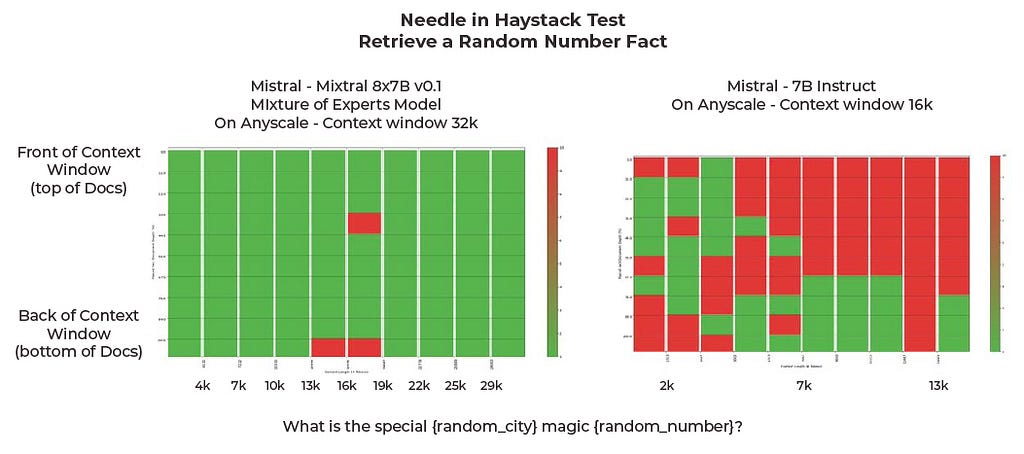
Figure 10: Mixtral results | Image by author
Last but certainly not least, it is interesting to see just how well Mixtral performed at this task despite these being by far the smallest models tested. The Mixture of Experts (MOEs) model was far better than 7B-Instruct, and we are finding that MOEs do much better for retrieval evaluations.
Conclusion
The Needle in a Haystack test is a clever way to quantify an LLM’s ability to parse context to find needed information. Our research concluded with a few main takeaways. First, ChatGPT-4 is the industry’s current leader in this arena along with many other evaluations that we and others have carried out. Second, at first Claude 2.1 seemed to underperform this test, but with tweaks to the prompt structure the model showed significant improvement. Claude is a bit wordier than some other models, and taking extra care to direct it can go a long way in terms of results. Finally, Mixtral MOE greatly outperformed our expectations, and we are excited to see Mixtral models continually overperform expectations.
Steve Jobs famously likened the computer to a “bicycle for the mind.” However, the context in which he made that claim is less well-known. He was referring to the efficiency of locomotion for all different species on the planet.
“And the Condor won, came in at the top of the list, surpassed everything else, and humans came in about a third of the way down the list … But, a human riding a bicycle blew away the Condor, all the way off the top of the list. And it made a really big impression on me that we humans are tool builders, and that we can fashion tools that amplify these inherent abilities that we have to spectacular magnitudes. And so for me, a computer has always been a bicycle of the mind, something that takes us far beyond our inherent abilities and I think were just at the early stages of this tool, and already we have seen enormous changes and I think that’s nothing compared to what’s coming in the next 100 years” Steve Jobs (1990)
LLMs as tools to accelerate software development have been polarizing. Many people consider auto-generated code so poor that their use is net negative. At the other end of the spectrum, many headlines proclaim that programming is dead. There are already many research papers attempting objective evaluations of the performance of LLMs on benchmark code quality datasets such as HumanEval or MBPP. These evaluations are important for advancing the field but are not the objective of this article.
The goal here is to provide practical recommendations for developers, especially those reluctant to leverage these models. Fair warning: I believe that one’s efficiency can indeed soar to “spectacular magnitudes” with the appropriate use of this technology.
Note that leveraging an LLM doesn’t guarantee performant code. Even the latest and greatest models make egregious mistakes. But remember, the best human engineers make mistakes too. That is why we don’t ship code without safeguards, such as automated testing and peer review. LLMs haven’t changed the meaning of best practices, but they may have changed how easy it is to achieve them.
A depiction of how code is typically shipped today. (Image generated by DALL·E 3)
Does it even matter how fast you can write performant code?
I would be surprised if most professional software engineers spent the majority of their time physically tapping keys on the keyboard. If they did, we would probably take the idea of using “lines of code” as a performance metric more seriously. I suspect that engineers spend a much larger proportion of their time determining what code needs to be written in the first place. LLMs are not capable of such abstract reasoning (yet) — OpenAI and many others are working hard to codify those steps, but that will likely require paradigm shifts beyond simply scaling the parameters or training data. However, LLMs can already be used to massively accelerate a significant fraction of your work.
Part 1: Writing performant functions
Let me provide an introductory example of a small piece of code generated by an LLM and the steps needed to make it useful. A common task in geospatial analysis is to measure the distance between a location on Earth and some other set of coordinates. Consider the following prompt.
Here is the immediate output:
import math
def haversine(lat1, lon1, lat2, lon2): # Radius of the Earth in kilometers R = 6371.0
for platform in platforms: distance = haversine(vessel_lat, vessel_lon, platform['latitude'], platform['longitude']) if distance < min_distance: min_distance = distance closest_platform = platform
return closest_platform, min_distance
How good is that code?
The quality of the code is quite poor. Among other issues, it is difficult to read due to questionable and inconsistent variable names, including both upper and lower single-character names. Additionally, it lacks docstrings and type hints, includes an unnecessary and inefficient for loop, and fails to handle edge cases, such as equidistant platforms.
Let’s simply say so:
from typing import Tuple, List import numpy as np
def haversine_vectorized(vessel_lat: float, vessel_lon: float, platform_lats: np.ndarray, platform_lons: np.ndarray) -> np.ndarray: """ Calculate the Haversine distance between a vessel and multiple platforms in a vectorized manner.
Parameters: - vessel_lat: Latitude of the vessel in decimal degrees. - vessel_lon: Longitude of the vessel in decimal degrees. - platform_lats: Numpy array of latitudes of oil platforms in decimal degrees. - platform_lons: Numpy array of longitudes of oil platforms in decimal degrees.
Returns: - distances: Numpy array of distances from the vessel to each platform in kilometers. """ # Convert decimal degrees to radians lat1, lon1, lat2, lon2 = map(np.radians, [vessel_lat, vessel_lon, platform_lats, platform_lons])
# Haversine formula dlat = lat2 - lat1 dlon = lon2 - lon1 a = np.sin(dlat/2)**2 + np.cos(lat1) * np.cos(lat2) * np.sin(dlon/2)**2 c = 2 * np.arctan2(np.sqrt(a), np.sqrt(1-a)) r = 6371 # Radius of Earth in kilometers return c * r
def find_closest_platform(vessel_lat: float, vessel_lon: float, platform_lats: np.ndarray, platform_lons: np.ndarray) -> Tuple[List[int], float]: """ Finds the closest oil platform(s) to a vessel given arrays of platform latitudes and longitudes, handling equidistant platforms.
Parameters: - vessel_lat: Latitude of the vessel in decimal degrees. - vessel_lon: Longitude of the vessel in decimal degrees. - platform_lats: Numpy array of latitudes for oil platforms. - platform_lons: Numpy array of longitudes for oil platforms.
Returns: - A tuple containing a list of indices of the closest platforms and the distance to them in kilometers. """ # Calculate distances to all platforms distances = haversine_vectorized(vessel_lat, vessel_lon, platform_lats, platform_lons)
# Find the minimum distance min_distance = np.min(distances)
# Find all indices with the minimum distance closest_indices = np.where(distances == min_distance)[0].tolist()
# Return the indices of all closest platforms and the minimum distance return closest_indices, min_distance
The revised code is significantly improved. It is easier to read, includes docstrings and type hints, and the for-loop has been replaced with a much more efficient vector computation.
But how “good” it is, and more importantly, whether it satisfies the requirements depends on the context in which the code will be run. In doing so, remember that humans cannot effectively evaluate code quality outside of a much richer context than a few lines of code. And, unsurprisingly, neither can LLMs.
For example, is the accuracy of the implementation sufficient for the expected users? How often will the code run? Once a year? Once a microsecond? What hardware is available? Is the anticipated usage and scale such that it is worth looking for small optimizations? After factoring in your salary, is it worth doing so?
Let’s evaluate the code taking the above into account.
With respect to accuracy, the haversine formula is good but not great because it assumes the earth is a sphere, but the earth is an oblate spheroid. That distinction matters when millimeter precision is needed over massive distances. If it does, there are more accurate formulas (such as Vincenty’s formula), but those come with performance trade-offs. Because the users of this code would not benefit from millimeter precision (nor is that even relevant because the error in the satellite imagery-derived vessel coordinates is the limiting factor), the haversine function is a reasonable choice in terms of accuracy.
Is the code fast enough? There are only thousands of offshore oil platforms. Computing the distance to each one, especially with vector computations, is very efficient. If this code were used in other contexts, such as the distance to any point on shore (where there are billions of coastal points), a “divide and conquer” approach would be preferable. In production, I knew this function would run on the order of 100 million times per day on a VM that would be as small as possible to minimize compute costs.
Given all of that additional context, the above implementation is reasonable. Recall that means the code should then be tested (I avoid writing tests with LLMs) and peer-reviewed (by humans) before merging.
Part 2: Stepping On the Gas
Auto-generating useful functions like the above already saves time, but the value add compounds when you leverage LLMs to generate entire libraries with dependencies across modules, documentation, visualizations (via multimodal capabilities), READMEs, CLIs, and more.
Let’s create, train, evaluate, and infer a novel computer vision model from scratch with extensive aid from LLMs. As a motivating example, consider this recently published paper on “Keypoints Method for Recognition of Ship Wake Components in Sentinel-2 Images by Deep Learning” (Del Prete et al., IEEE GRSL, 2023).
A ship and its wake shown in Sentinel-2 satellite imagery. Contains modified Copernicus Sentinel data [2023] processed by Sentinel Hub and provided by the European Space Agency (ESA)
Why should anyone care about the direction ships are traveling in satellite imagery and what makes this task non-trivial?
Determining a vessels course from static imagery is a valuable insight for organizations monitoring human activity in their waters. For example, knowing that a vessel is approaching a marine protected area might be cause for alarm or interception. The spatial resolution of global-scale publicly available satellite imagery is generally insufficient to adequately assess a vessel’s orientation, especially for smaller vessels that occupy at most a few pixels (Sentinel-2 imagery is 10 meters/pixel). However, the wakes of even small vessels can be quite large, and that context allows one to determine the vessel’s orientation and the direction it’s traveling, even when it is impossible to identify the stern (back) of the boat.
The approach taken by the authors was compelling because the model described in the paper was built from EfficientNetB0, which is small enough to run cheaply at scale. I wasn’t able to find any relevant code, but the authors did make the dataset, including annotations, publicly available (kudos!).
Let’s get started!
As is typical for any new ML project, it is informative to first visualize the data.
I don’t know if saying please helps or not.
import os import json from PIL import Image, ImageDraw import matplotlib.pyplot as plt import seaborn as sns
# Define the path to your data directory data_dir = "/path/to/your/data" # Adjust this to the path of your data directory annotations_dir = os.path.join(data_dir, "annotations") images_dir = os.path.join(data_dir, "imgs")
# Initialize Seaborn for better visual aesthetics sns.set(style="whitegrid", palette="muted")
# Create a list to hold file paths for images and their corresponding annotations image_files = [] annotation_files = []
# Loop through the annotations directory to get the list of annotation files for annotation_file in os.listdir(annotations_dir): if annotation_file.endswith(".json"): annotation_path = os.path.join(annotations_dir, annotation_file) image_file = annotation_file.replace(".json", ".png") # Assuming image file names match annotation file names image_path = os.path.join(images_dir, image_file)
# Check if the corresponding image file exists if os.path.exists(image_path): annotation_files.append(annotation_path) image_files.append(image_path)
# Plotting num_examples = min(len(image_files), 10) # Limiting to 10 examples for visualization fig, axes = plt.subplots(2, 5, figsize=(20, 8))
for idx, (image_path, annotation_path) in enumerate(zip(image_files[:num_examples], annotation_files[:num_examples])): # Load the image img = Image.open(image_path).convert("RGB") # Ensure the image is treated as RGB draw = ImageDraw.Draw(img)
# Load the corresponding annotations and draw keypoints with open(annotation_path, 'r') as f: annotations = json.load(f) for point in annotations["tooltips"]: x, y = point["x"], point["y"] # Draw keypoints in cyan for visibility draw.ellipse([(x-10, y-10), (x+10, y+10)], fill='cyan', outline='black')
# Plot the image with keypoints ax = axes[idx // 5, idx % 5] ax.imshow(img) ax.axis('off') ax.set_title(f"Image {idx+1}")
plt.tight_layout() plt.show()
Which resulted in the following:
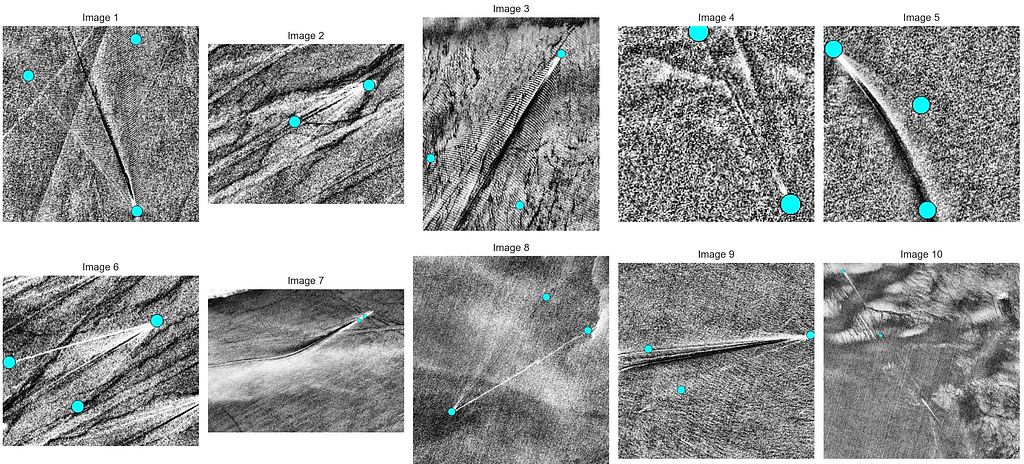
A sample of vessels and wake keypoint annotations (cyan) in Sentinel-2 satellite imagery. Contains modified Copernicus Sentinel data [2023] provided by the European Space Agency. Images are available here: zenodo.
These plots indicate a few important points. First, the number of annotated keypoints (cyan dots) varies. Second, the images are grayscale and exhibit different shapes. Third, there is significant heterogeneity in this, albeit relatively small, sample. Keeping all of that in mind, let’s write the dataset loader, neural network definition, training, and validation loops. We will provide some context to our LLM before asking for the code.
Which resulted in the following output:
import os import json import torch from torch.utils.data import Dataset, DataLoader from torchvision import transforms from torchvision.io import read_image from typing import Tuple, List
class WakeDataset(Dataset): """ Custom Dataset for loading wake detection imagery and annotations, with preprocessing for EfficientNet. Images are grayscale and will be converted to three-channel images for model compatibility. """
def __init__(self, annotations_dir: str, images_dir: str, transform=None): """ Initializes the dataset with paths to annotations and images directories, and a transform.
Parameters: - annotations_dir: Path to the directory containing annotation JSON files. - images_dir: Path to the directory containing grayscale image files. - transform: A torchvision.transforms transform to be applied on a sample. """ self.annotations_dir = annotations_dir self.images_dir = images_dir self.transform = transform if transform else self.default_transform() self.annotations = self._load_annotations()
def default_transform(self): """ Defines the default transform to resize images, convert them to three-channel format, and to tensors.
Returns: - A torchvision.transforms composition for image preprocessing. """ return transforms.Compose([ transforms.Resize((224, 224)), # Resize to the input size for EfficientNet transforms.Grayscale(num_output_channels=3), # Convert grayscale to three-channel transforms.ConvertImageDtype(torch.float), # Ensures image is a float tensor ])
def _load_annotations(self) -> List[Tuple[str, List[int]]]: """ Loads and filters annotations with at least 2 keypoints.
Returns: - A list of tuples, where each tuple contains the image filename and its keypoints. """ annotations = [] for filename in os.listdir(self.annotations_dir): if not filename.endswith('.json'): continue filepath = os.path.join(self.annotations_dir, filename) with open(filepath, 'r') as f: data = json.load(f) if len(data['tooltips']) >= 2: # Filter annotations with at least 2 keypoints keypoints = [item for sublist in [[kp['x'], kp['y']] for kp in data['tooltips']] for item in sublist] annotations.append((filename.replace('.json', '.png'), keypoints)) return annotations
def __len__(self) -> int: """ Returns the number of items in the dataset. """ return len(self.annotations)
def __getitem__(self, idx) -> Tuple[torch.Tensor, torch.Tensor]: """ Retrieves an item from the dataset at the specified index, with preprocessing for EfficientNet.
Parameters: - idx: Index of the item to retrieve.
Returns: - A tuple containing the preprocessed image tensor and its corresponding keypoints tensor. """ img_name, keypoints = self.annotations[idx] img_path = os.path.join(self.images_dir, img_name) image = read_image(img_path) # Load image keypoints = torch.tensor(keypoints + [0] * (6 - len(keypoints)), dtype=torch.float) # Pad keypoints if self.transform: image = self.transform(image) return image, keypoints
The code looks reasonable, and it seems to have addressed some of the nuances of the problem. It’s not perfect (e.g., converting the images from grayscale to RGB in default_transform is a strange choice, and I prefer pathlib over os.listdir), but let’s move on for now.
import torch import torch.nn as nn from torchvision import models from typing import Tuple
class EfficientNetB0KeypointDetector(nn.Module): """ A custom EfficientNet-B0 model for keypoint detection in grayscale images. The network modifies the input layer to accept single-channel images and adds a custom output layer for predicting a fixed number of keypoints. """
def __init__(self, num_keypoints: int = 3): """ Initializes the model.
Parameters: - num_keypoints: The number of keypoints to predict. Default is 3, corresponding to the maximum number of keypoints in the dataset. """ super(EfficientNetB0KeypointDetector, self).__init__() self.num_keypoints = num_keypoints # Load a pre-trained EfficientNet-B0 self.efficientnet_b0 = models.efficientnet_b0(pretrained=True)
# Modify the first convolutional layer to accept single-channel (grayscale) images original_first_conv = self.efficientnet_b0.features[0][0] self.efficientnet_b0.features[0][0] = nn.Conv2d( in_channels=1, out_channels=original_first_conv.out_channels, kernel_size=original_first_conv.kernel_size, stride=original_first_conv.stride, padding=original_first_conv.padding, bias=False)
# Modify the classifier to predict keypoints (num_keypoints * 2 because x, y for each keypoint) self.efficientnet_b0.classifier = nn.Linear( in_features=self.efficientnet_b0.classifier[1].in_features, out_features=num_keypoints * 2)
def forward(self, x: torch.Tensor) -> torch.Tensor: """ Forward pass of the network.
Returns: - A tensor of shape (batch_size, num_keypoints * 2) representing the predicted keypoints. """ return self.efficientnet_b0(x)
# Example usage if __name__ == "__main__": model = EfficientNetB0KeypointDetector() print(model)
# Example input tensor (batch_size, channels, height, width) example_input = torch.randn(1, 1, 224, 224) output = model(example_input) print(output.shape) # Expected shape: (1, 6) for 3 keypoints (each with x, y coordinates)
import os import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader from dataset import WakeDataset, get_dataloader # Assuming dataset.py is in the same directory from net import EfficientNetB0KeypointDetector from torchvision import transforms import wandb
def custom_collate_fn(batch): """ Custom collate function to pad keypoints to a fixed size.
Parameters: - batch: A list of tuples (image, keypoints).
Returns: - Batched images and keypoints with padding as necessary. """ images, keypoints = zip(*batch) images = torch.stack(images, 0) max_keypoints = 3 * 2 # Maximum number of keypoints (3) times 2 for (x, y) padded_keypoints = [torch.cat((kp, torch.zeros(max_keypoints - len(kp)))) for kp in keypoints] keypoints = torch.stack(padded_keypoints, 0) return images, keypoints
def train_one_epoch(model: nn.Module, dataloader: DataLoader, optimizer: optim.Optimizer, device: torch.device): """ Trains the model for one epoch.
Parameters: - model: The neural network model. - dataloader: DataLoader providing the training data. - optimizer: Optimizer used for model training. - device: The device to train on. """ model.train() total_loss = 0.0 for images, keypoints in dataloader: images, keypoints = images.to(device), keypoints.to(device) optimizer.zero_grad() outputs = model(images) loss = nn.MSELoss()(outputs, keypoints) loss.backward() optimizer.step() total_loss += loss.item()
# Training loop for epoch in range(num_epochs): train_one_epoch(model, train_dataloader, optimizer, device) evaluate(model, val_dataloader, device) # Log model checkpoints, images, or other metrics as needed wandb.log({})
if __name__ == "__main__": main()
I tried executing the code at this point but ran into multiple issues related to incorrect tensor shapes (recall the RGB/grayscale discrepancy and the custom collate function). I spent a few minutes debugging but ultimately just copied every module into the prompt window and asked for it to debug for me.
That was sufficient to resolve all of the lingering issues, and I kicked off training…which was absolutely glacial. I realized that I wasn’t using the Metal Performance Shaders (MPS) backend available on Apple silicon. I don’t generally train on my personal laptop, and MPS was new to me, but I added a conditional to use it.
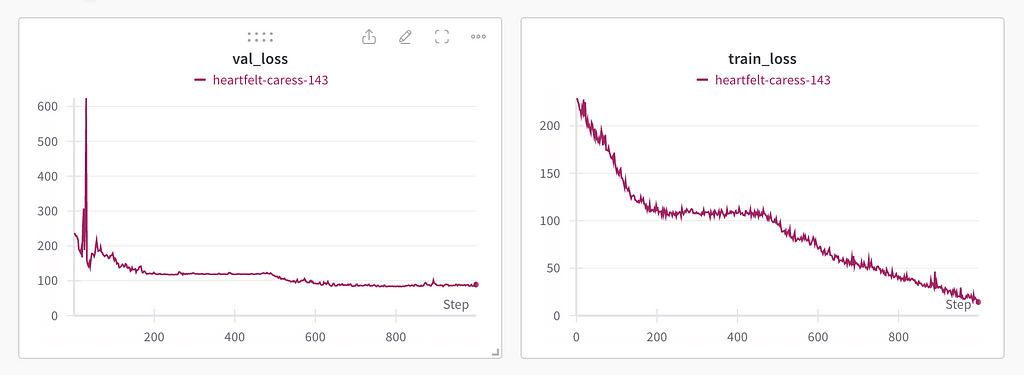
Because the magnitude of the training data was modest (581 images), and given the fact that the EfficientNet was pre-trained on ImageNet — I chose to train for 1000 epochs.
After 500 epochs, train_loss is still decreasing, but validation loss appears to have converged (at least sufficiently so for the purposes of a quick evaluation). Images are copied from weights and biases.
Note that there exist foundation models pre trained on satellite imagery (as opposed to ImageNet) which would (likely) be more performant for this task (see Bastani et. al.), but those nets are also much larger than EfficientNet, and therefore slower to train (and too new to be in LLM training corpora).
Let’s write an inference script, along with a CLI, to test the newly trained model.
import torch from torchvision import transforms from PIL import Image import matplotlib.pyplot as plt import click
# Assuming net.py contains the EfficientNetB0KeypointDetector class # and dataset.py contains the transforms used during training from net import EfficientNetB0KeypointDetector from dataset import WakeDataset # Modify as necessary to import transforms
def load_model(model_path): """Load the trained model from a file.""" model = EfficientNetB0KeypointDetector() model.load_state_dict(torch.load(model_path)) model.eval() # Set the model to inference mode return model
def preprocess_image(image_path, transform): """Load and preprocess an image.""" image = Image.open(image_path).convert("L") # Assuming grayscale conversion as in your dataset image = transform(image) # Add batch dimension (BxCxHxW) image = image.unsqueeze(0) return image
def plot_keypoints(image, keypoints): """Plot keypoints on the image.""" plt.imshow(image.squeeze(), cmap='gray') # Remove batch dimension and show image plt.scatter(keypoints[:, 0], keypoints[:, 1], s=50, marker='.', c='red') plt.show()
@click.command() @click.argument('model_path', type=click.Path(exists=True)) @click.argument('image_path', type=click.Path(exists=True)) def run_inference(model_path, image_path): """Run inference on an image using a trained model.""" # Use the same transforms as during training transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Grayscale(num_output_channels=3), ])
model = load_model(model_path) image = preprocess_image(image_path, transform)
# Perform inference with torch.no_grad(): keypoints = model(image) keypoints = keypoints.view(-1, 2).cpu().numpy() # Reshape and convert to numpy for plotting
# Load original image for plotting original_image = Image.open(image_path).convert("L") plot_keypoints(original_image, keypoints)
if __name__ == '__main__': run_inference()
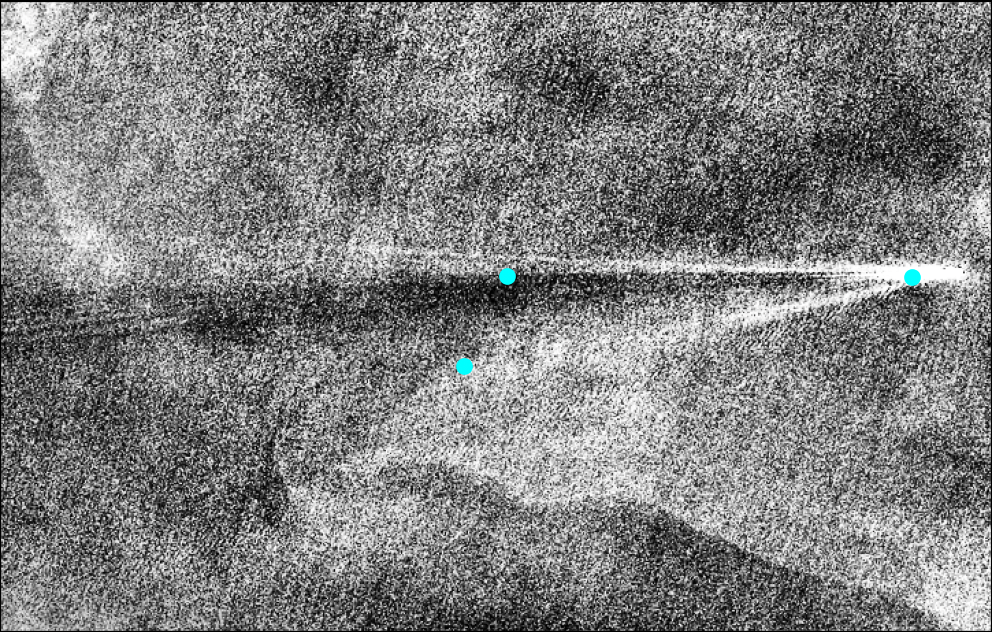
Let’s try it!
Not perfect but reasonable for a first pass. Contains modified Copernicus Sentinel data [2023] provided by the European Space Agency. Downloaded from zenodo.
You can find the complete code with all of the modules, the model and weights (from the 500th epoch), and a readme on GitHub. I spent under an hour generating the entire library and far longer writing this article. Note that all of the above was completed on my personal laptop/development environment: MacBook Air M2 + VS Code + Copilot + autoformat on save (black, isort, etc) + a (.venv) Python 3.9.6.
Lessons Learned
Provide the models with as much context as is relevant to solve the task. Remember that the model lacks many assumptions you may take for granted.
LLM-generated code is typically far from perfect right off the bat, and it is difficult to predict how it will fail. For many reasons, it is helpful to have secondary assistance in your IDE (such as Copilot).
When writing code with heavy dependence on LLMs, it is important to keep in mind that the limiting factor is waiting for the code to be written. Avoid asking for duplicated and redundant code that doesn’t require any changes. It is wasteful in terms of energy and it slows you down.
LLMs have a difficult time ‘remembering’ every line of code that they have provided, and often it is worthwhile reminding them of the current state (especially when there are dependencies across multiple dependent modules).
Be skeptical of LLM generated code. Validate as much as possible, using tests, visualizations, etc. And spend time where it matters. I spent far more time carefully evaluating the haversine function (where the performance mattered because of the anticipated scale) than I did the neural network (where the proof was more-so in the pudding). For the latter, I was most interested in failing fast.
Part 3: LLMs and the future of engineering
“There is nothing permanent except change” Heraclitus
With all of the hype surrounding LLMs and the massive amount of money exchanging hands, it is tempting to expect perfection at first blush. But effective use of these tools requires a willingness to experiment, learn, and adapt. Do LLMs change the fundamental structure of a software engineering team? Perhaps they will eventually, we have only seen the beginning of this new world. But we have already seen LLMs democratize access to code. Folks without programming experience can quickly and easily build functional prototypes. If your requirements are stringent, it may be prudent to leverage LLMs only in areas for which you already have expertise. My own experience is that LLMs dramatically reduce the time needed to arrive at performant code by a factor of ~10. If your personal experience is that they consistently output poor quality code, perhaps it is time to (re)evaluate the input.
Acknowledgments
Thanks to Ran Liu, Chris Hobson, and Bryce Blum for feedback. And to Roberto Del Prete et. al., both for the research into Sentinel-2 vessel wakes and for publishing their dataset under a permissive license. N.B. I am not affiliated with the authors or their institution.
Python is instrumental in so many data science and machine learning workflows that it can sometimes just blend into our daily rhythm; how often, after all, do you think about your office light switch or door knob? You use them all the time, too.
For our first Python-centric Variable edition of 2024, we decided to focus on some of the more interesting and off-the-beaten-path use cases we’ve published recently. We love a good Pandas or Matplotlib tutorial—and so do many of our readers—but sometimes it’s fun to take a break from bread-and-butter topics and dive into some fancier stuff. This week, let’s indulge a little! We hope you enjoy the nine Python reads we’ve selected, which cover a striking range of projects and challenges.
Introducing the Quad-Tile Chart & Squaremap: Squarify Your Data Why settle for existing visualization formats when you can create your own? Nick Gerend invites us on a behind-the-scenes tour of the process behind building Quad-Tile Chart, his Python-powered, axis-free approach for visualizing a set of values as squares.
Finite Automata Simulation for Leveraging AI-Assisted Systems Using finite-state machines, Sofya Lipnitskaya explores a potential approach for optimizing the performance of complex real-world AI-assisted processes — in this case, an object-detection system that would activate water sprinklers to scare away invading chickens!
Python’s Most Powerful Decorator In case you missed it, Siavash Yasini’s detailed introduction to Python’s @property decorator is one of our most-read programming articles in recent weeks. It covers several useful ways to leverage its power: from protecting data attributes from being overwritten to lazy-loading and memory optimization.
Molding the Imagination: Using AI to Create New 3D-Printable Objects After text, image, music, and video, could 3D objects become the next frontier for generative AI? Robert A. Gonsalves shares the results of his recent experiments, which depend on Midjourney for image generation and on some good-old Python code for translating these into tangible objects.
Text Embeddings: Comprehensive Guide If you’re new to the world of text embeddings, Mariya Mansurova’s primer is a great place to start—it’s both (very) thorough and accessible, and the hands-on sections include all the Python snippets you’ll need to start tinkering on your own.
After a credit card? An insurance policy? Ever wondered about the three-digit number that shapes these decisions?
Introduction
Scores are used by a large number of industries to make decisions. Financial institutions and insurance providers are using scores to determine whether someone is right for credit or a policy. Some nations are even using social scoring to determine an individual’s trustworthiness and judge their behaviour.
For example, before a score was used to make an automatic decision, a customer would go into a bank and speak to a person regarding how much they want to borrow and why they need a loan. The bank employee may impose their own thoughts and biases into their decision-making process. Where is this person from? What are they wearing? Even, how do I feel today?
A score levels the playing field and allows everyone to be assessed on the same basis.
Recently, I have been taking part in several Kaggle competitions and analyses of featured datasets. The first playground competition of 2024 aimed to determine the likelihood of a customer leaving a bank. This is a common task that is useful for marketing departments. For this competition, I thought I would put aside the tree-based and ensemble modelling techniques normally required to be competitive in these tasks, and go back to the basics: a logistic regression.
Here, I will guide you through the development of the logistic regression model, its conversion into a score, and its presentation as a scorecard. The aim of doing this is to show how this can reveal insights about your data and its relationship to a binary target. The advantage of this type of model is that it is simpler and easier to explain, even to non-technical audiences.
My Kaggle notebook with all my code and maths can be found here. This article will focus on the highlights.
What is a Score?
The score we are describing here is based on a logistic regression model. The model assigns weights to our input features and will output a probability that we can convert through a calibration step into a score. Once we have this, we can represent it with a scorecard: showing how an individual is scoring based on their available data.
Let’s go through a simple example.
Mr X walks into a bank looking for loan for a new business. The bank uses a simple score based on income and age to determine whether the individual should be approved.
Mr X is a young individual with a relatively low income. He is penalised for his age, but scores well (second best) in the income band. In total, he scores 24 points in this scorecard, which is a mid-range score (the maximum number of points being 52).
A score cut-off would often be used by the bank to say how many points are needed to be accepted based on internal policy. A score is based on a logistic regression which is built on some binary definition, using a set of features to predict the log odds.
In the case of a bank, the logistic regression may be trying to predict those that have missed payments. For an insurance provider, those who have made a claim before. For a social score, those that have ever attended an anarchist gathering (not really sure what these scores would be predicting but I would be fascinated to know!).
We will not go through everything required for a full model development, but some of the key steps that will be explored are:
Weights of Evidence Transformation: Making our continuous features discrete by banding them up as with the Mr X example.
Calibrating our Logistic Regression Outputs to Generate a Score: Making our probability into a more user-friendly number by converting it into a score.
Representing Our Score as a Scorecard: Showing how each feature contributes to the final score.
Weights of Evidence Transformation
In the Mr X example, we saw that the model had two features which were based on numeric values: the age and income of Mr X. These variables were banded into groups to make it easier to understand the model and what drives an individual’s score. Using these continuous variables directly (as oppose to within a group) could mean significantly different scores for small differences in values. In the context of credit or insurance risk, this makes a decision harder to justify and explain.
There are a variety of ways to approach the banding, but normally an initial automated approach is taken, before fine-tuning the groupings manually to make qualitative sense. Here, I fed each continuous feature individually into a decision tree to get an initial set of groupings.
Once the groupings were available, I calculated the weights of evidence for each band. The formula for this is shown below:
This is a commonly used transformation technique in scorecard modelling where a logistic regression is used given its linear relationship to the log odds, the thing that the logistic regression is aimed to predict. I will not go into the maths of this here as this is covered in full detail in my Kaggle notebook.
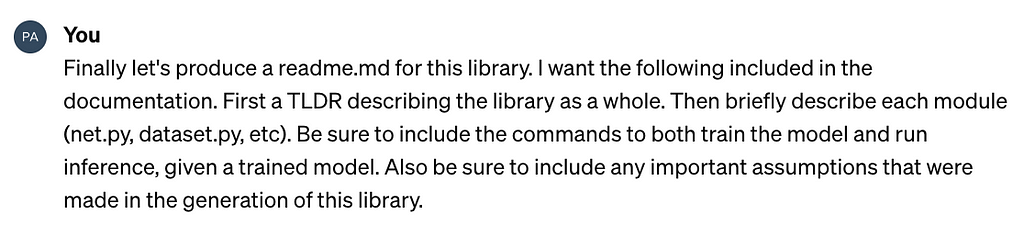
Once we have the weights of evidence for each banded feature, we can visualise the trend. From the Kaggle data used for bank churn prediction, I have included a couple of features to illustrate the transformations.
Image by author
The red bars surrounding each weights of evidence show a 95% confidence interval, implying we are 95% sure that the weights of evidence would fall within this range. Narrow intervals are associated with robust groups that have sufficient volume to be confident in the weights of evidence.
For example, categories 16 and 22 of the grouped balance have low volumes of customers leaving the bank (19 and 53 cases in each group respectively) and have the widest confidence intervals.
The patterns reveal insights about the feature relationship and the chance of a customer leaving the bank. The age feature is slightly simpler to understand so we will tackle that first.
As a customer gets older they are more likely to leave the bank.
The trend is fairly clear and mostly monotonic except some groups, for example 25–34 year old individuals are less likely to leave than 18–24 year old cases. Unless there is a strong argument to support why this is the case (domain knowledge comes into play!), we may consider grouping these two categories to ensure a monotonic trend.
A monotonic trend is important when making decisions to grant credit or an insurance policy as this is often a regulatory requirement to make the models interpretable and not just accurate.
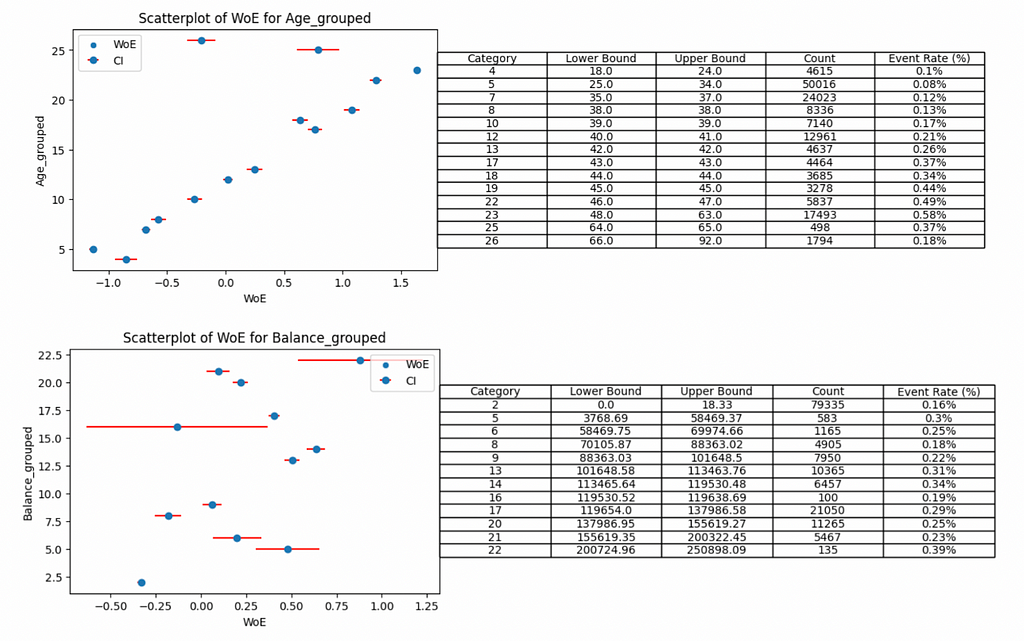
This brings us on to the balance feature. The pattern is not clear and we don’t have a real argument to make here. It does seem that customers with lower balances have less chance to leave the bank but you would need to band several of the groups to make this trend make any sense.
By grouping categories 2–9, 13–21 and leaving 22 on its own (into bins 1, 2 and 3 respectively) we can start to see the trend. However, the down side of this is losing granularity in our features and likely impacting downstream model performance.
Image by author
For the Kaggle competition, my model did not need to be explainable, so I did not regroup any of the features and just focused on producing the most predictive score based on the automatic groupings I applied. In an industry setting, I may think twice about doing this.
It is worth noting that our insights are limited to the features we have available and there may be other underlying causes for the observed behaviour. For example, the age trend may have been driven by policy changes over time such as the move to online banking, but there is no feasible way to capture this in the model without additional data being available.
If you want to perform auto groupings to numeric features, apply this transformation and make these associated graphs for yourselves, they can be created for any binary classification task using the Python repository I put together here.
Once these features are available, we can fit a logistic regression. The fitted logistic regression will have an intercept and each feature in the model will have a coefficient assigned to it. From this, we can output the probability that someone is going to leave the bank. I won’t spend time here discussing how I fit the regression, but as before, all the details are available in my Kaggle notebook.
Calibrating our Logistic Regression Outputs to Generate a Score
The fitted logistic regression can output a probability, however this is not particularly useful for non-technical users of the score. As such, we need to calibrate these probabilities and transform them into something neater and more interpretable.
Remember that the logistic regression is aimed at predicting the log odds. We can create the score by performing a linear transformation to these odds in the following way:
In credit risk, the points to double the odds and 1:1 odds are typically set to 20 and 500 respectively, however this is not always the case and the values may differ. For the purposes of my analysis, I stuck to these values.
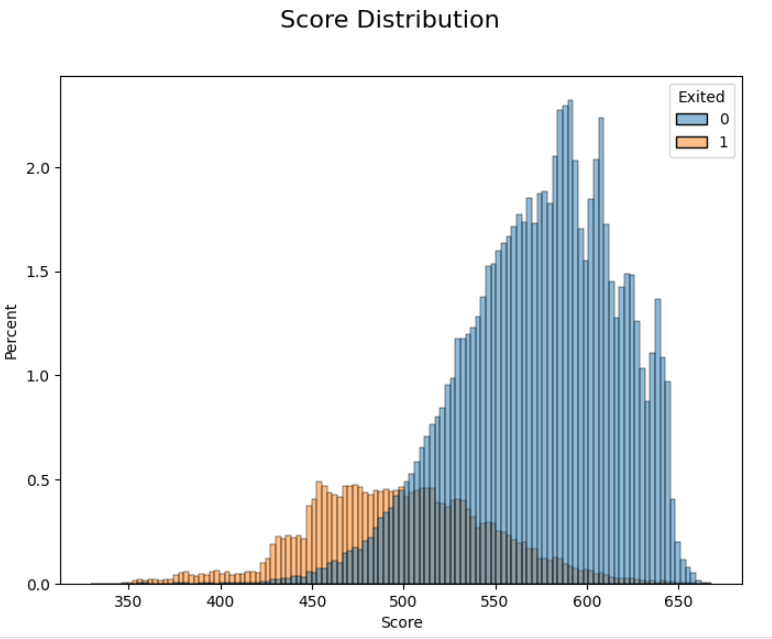
We can visualise the calibrated score by plotting its distribution.
Image by author
I split the distribution by the target variable (whether a customer leaves the bank), this provides a useful validation that all the previous steps have been done correctly. Those more likely to leave the bank score lower and those who stay score higher. There is an overlap, but a score is rarely perfect!
Based on this score, a marketing department may set a score cut-off to determine which customers should be targeted with a particular marketing campaign. This cut-off can be set by looking at this distribution and converting a score back to a probability.
Translating a score of 500 would give a probability of 50% (remember that our 1:1 odds are equal to 500 for the calibration step). This would imply that half of our customers below a score of 500 would leave the bank. If we want to target more of these customers, we would just need to raise the score cut-off.
Representing Our Score as a Scorecard
We already know that the logistic regression is made up of an intercept and a set of weights for each of the used features. We also know that the weights of evidence have a direct linear relationship with the log odds. Knowing this, we can convert the weights of evidence for each feature to understand its contribution to the overall score.
I have displayed this for all features in the model in my Kaggle notebook, but below are examples we have already seen when transforming the variables into their weights of evidence form.
Age
Balance
The advantage of this representation, as opposed to the weights of evidence form, is it should make sense to anyone without needing to understand the underlying maths. I can tell a marketing colleague that customers age 48 to 63 years old are scoring lower than other customers. A customer with no balance in their account is more likely to leave than someone with a high balance.
You may have noticed that in the scorecard the balance trend is the opposite to what was observed at the weights of evidence stage. Now, low balances are scoring lower. This is due to the coefficient attached to this feature in the model. It is negative and so is flipping the initial trend. This can happen as there are various interactions happening between the features during the fitting of the model. A decision must be made whether these sorts of interactions are acceptable or whether you would want to drop the feature if the trend becomes unintuitive.
Supporting documentation can explain the full detail of any score and how it is developed (or at least should!), but with just the scorecard, anyone should be able to get immediate insights!
Conclusion
We have explored some of the key steps in developing a score based on a logistic regression and the insights that it can bring. The simplicity of the final output is why this type of score is still used to this day in the face of more advanced classification techniques.
The score I developed for this competition had an area under the curve of 87.4%, while the top solutions based on ensemble techniques were around 90%. This shows that the simple model is still competitive, although not perfect if you are just looking for accuracy. However, if for your next classification task you are looking for something simple and easily explainable, what about considering a scorecard to gain insights into your data?
With the use of cloud computing, big data and machine learning (ML) tools like Amazon Athena or Amazon SageMaker have become available and useable by anyone without much effort in creation and maintenance. Industrial companies increasingly look at data analytics and data-driven decision-making to increase resource efficiency across their entire portfolio, from operations to performing […]
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.