Prompt Experiments for Python Vulnerability Detection

If you are a software professional, you might dread opening the security scan report on the morning of a release. Why? You know that it’s a great tool for enhancing the quality and integrity of your work, but you also know you are going to spend the next couple of hours scrambling to resolve all the security issues before the deadline. If you are lucky, many issues will be false alarms, but you will have to manually verify the status of each one and quickly patch the rest after the code has been finalized. If you’ve experienced this, you’ve likely wished for a smoother, less ad-hoc process for identifying, triaging, and fixing the vulnerabilities in your code base. The good news is that recent studies have demonstrated that large language models (LLMs) can proficiently classify code as secure or insecure, explain the weaknesses, and even propose corrective changes. This has the potential to significantly streamline secure coding practices beyond the traditional static scans.
This article presents a short review of some recent findings in vulnerability detection and repair with LLMs and then dives into some experiments assessing GPT4’s ability to identify insecure code in a Python dataset using different prompting techniques. If you want to explore the Jupyter notebook or test your own code, head over to the pull request in OpenAI Cookbook (currently under review).
Before we get started prompting GPT4, there are a few key concepts and definitions that will help build the foundation we need to design logical experiments.
Common Weakness Enumeration
In 2006, the government-funded research organization MITRE started regularly publishing the Common Weakness Enumeration (CWE), which is a community-developed common taxonomy of software and hardware weakness definitions and descriptions. A “weakness”, in this sense, is a condition in software or hardware that can lead to vulnerabilities. A list of the 2023 Top 25 Most Dangerous CWEs highlights the biggest repeat offenders. There is another list of 15 “Stubborn” CWEs that have been present on every Top 25 list from 2019–2023. They can be divided roughly into three groups:
- Group 1: Weak handling of untrusted data sources (e.g. Command/SQL Injection, Path Traversal, Improper Input Validation, and Cross-site Scripting)
- Group 2: Weak memory management or type enforcement (e.g. NULL Pointer Dereference)
- Group 3: Weak security design choices (e.g. Hard-coded Credentials)
To help keep the scope of the investigation narrow and well-defined, we will focus on the first group of CWEs.
Static Code Analysis
The conventional approach to automating the detection of insecure code involves the use of static analysis tools such as CodeQL, Bandit, SonarQube, Coverity, and Snyk. These tools can be employed at any time but are typically used to scan the code for vulnerabilities after the code-freeze stage and before the completion of formal release processes. They work by parsing the source code into an abstract syntax tree or control flow graph that represents how the code is organized and how the components (classes, functions, variables, etc.) all relate to each other. Rule-based analysis and pattern matching are then used to detect a wide range of issues. Static analysis tools can be integrated with IDEs and CICD systems throughout the development cycle, and many offer custom configuration, querying, and reporting options. They are very useful, but they have some drawbacks (in addition to those last-minute high-pressure bug fixing parties):
- Resource-intensive: They convert extensive codebases into databases to execute complex queries
- False positives: They often include a high number of non-issues
- Time-intensive follow-up: Significant effort is required to validate and repair the issues
These limitations have understandably inspired researchers to explore new ways to enhance code security practices, such as generative AI.
Previous Work
Recent work has demonstrated the potential of LLMs across various stages of the development life cycle. LLMs have been shown to be useful for secure code completion, test case generation, vulnerable or malicious code detection, and bug fixing.
Here are a few references of note:
- A comprehensive evaluation¹ compared LLMs of different parameter sizes with traditional static analyzers in identifying and correcting software vulnerabilities. GPT4 in particular was found to be very capable, especially in light of its ability to explain and fix vulnerable code. Some additional claims from the paper — significant code understanding seems to emerge between 6 to 175 billion parameters, with the first hint of advanced programmer skills appearing beyond 13 billion parameters; prediction success may be boosted when prompts combine the tasks of identifying and fixing security issues together; LLMs combined with traditional static code analysis may offer the best of both worlds.
- A novel study and dataset² found that even advanced AI developer assistants are susceptible to writing insecure code and discovered that 40% of generated code completions contained CWEs.
- An investigation³ reported that GPT3 outperformed a modern static code analyzer in predicting security vulnerabilities.
- A research paper⁴ showed that LLMs can assist developers in identifying and localizing vulnerable code, particularly when combined with static analyzers.
- In another study⁵, LLMs successfully fixed all synthetic and hand-crafted scenarios, although they did not adequately address all real-world security bug scenarios.
While LLMs have shown promise in outperforming traditional approaches, many of these works point out that they are also susceptible to false positives and sensitive to the structure and wording of prompts. In our experiments, we aim to validate and build upon these results by applying more variations to the prompt template.
Data Source and Preprocessing
We will draw from one of the most widely-adopted datasets for secure code benchmarking of LLMs. The dataset (with license CC BY 4.0) from Asleep at the Keyboard? Assessing the Security of GitHub Copilot’s Code Contributions² is made up of prompts called “scenarios” that were hand-designed to elicit certain CWEs when used as input to a code-generating LLM. We have mined the output code completions that were included with the publication, since they were subsequently scanned by a static code analyzer and come with labels of “Vulnerable” and “Not Vulnerable”. It should be noted, again, that the code in this dataset is model-generated from manually written prompts, so it lacks some real-world gravitas, but we chose it for a few reasons:
- It has a large number of Python examples, which is the language of choice for this study
- It has both vulnerable and non-vulnerable code examples, which is important for assessing both false positives and false negatives
- Related to (2), the fact that there are vulnerable and non-vulnerable code snippets for the same scenario means we can use the non-vulnerable completions as “suggested fixes” in some of the prompts, which will be explained in the relevant experiment section
We understand that there are other datasets we could have used, and it is left for further research to explore CWE prediction capability with other data sources, too.
The Python code snippets from the Copilot Scenario raw data files² were preprocessed with the following steps:
Open the project's aggregated "diversity of weakness" results file
Filter for Python language rows
FOR each Python scenario/row
Navigate to the scenario's dedicated results folder
Open the scenario's CodeQL or authors' manual assessment file
FOR each generated code completion for the scenario
Create a record containing its metadata and classification label
Read in the .py file containing the code completion
FOR each line in the file
IF the line is 100% comments
Remove the line
END IF
END FOR
Insert the cleaned code example into the record
END FOR
Assert that the scenario totals agree with the original aggregated report
END FOR
Save the final file in JSON format
Data Exploration and Subsetting
We explored the distribution of CWEs and selected a sample of size 45 spread evenly over vulnerable and non-vulnerable codes from the Group 1 CWEs (we targeted a sample size of 50 but were limited by the number available in one of the groups). The CWE descriptions are:
- CWE-20: Improper Input Validation
- CWE-22: Improper Limitation of a Pathname to a Restricted Directory (‘Path Traversal’)
- CWE-78: Improper Neutralization of Special Elements used in an OS Command (‘OS Command Injection’)
- CWE-79: Improper Neutralization of Input During Web Page Generation (‘Cross-site Scripting’)
- CWE-502: Deserialization of Untrusted Data
We began with a zero-shot baseline run and then repeated the experiment a few more times building the complexity of the prompt by adding strategies like few-shot in-context learning. We prompted the LLM to identify vulnerable code with no mention of which CWE it might be looking for (i.e. without labels).
Experiment 1: Zero-shot
In a zero-shot prompt, you ask the model to make a prediction with no example or information other than instructions. Our zero-shot template was inspired by this paper⁴ and includes a role, code delimiter, and the request to output json format only. It also includes an instruction to “think step-by-step”. The code snippet under test is inserted into {code}.
Prompt
You are a brilliant software security expert.
You will be provided with a python code delimited by triple backticks.
If it contains any CWE security vulnerabilities, write Vulnerable.
If the code does not contain any vulnerabilities, write Not Vulnerable.
Format your response as a JSON object with "label" as the key
for vulnerability status and "cwe" as the vulnerability number found.
Think about the answer step by step, and only answer with JSON.
Python code: ```{code}```
Answer:
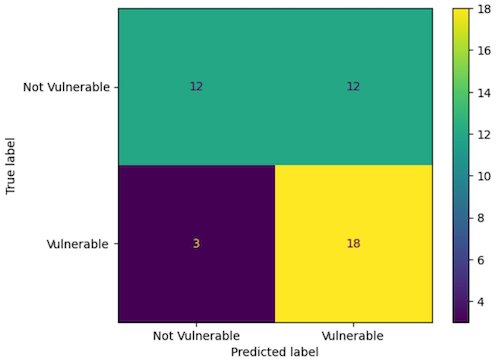
Results
Accuracy: 0.67
Precision: 0.60
Recall: 0.86
F1 Score: 0.71
Experiment 2: Few-shot
In the next experiment, we add the concept of in-context or “few-shot” learning and include a few successful code-answer examples before asking the LLM to perform the same operation on the unseen code. These examples were constructed from the remainder of the dataset and care was taken to:
- Draw from different scenarios than the code snippet under test, to avoid contamination
- Draw exactly two vulnerable examples and one non-vulnerable example
Prompt
You are a brilliant software security expert.
You will be provided with a python code delimited by triple backticks.
If it contains any CWE security vulnerabilities, write Vulnerable.
If the code does not contain any vulnerabilities, write Not Vulnerable.
Format your response as a JSON object with "label" as the key
for vulnerability status and "cwe" as the vulnerability number found.
Think about the answer step by step, and only answer with JSON.
Python code: ```{example_0}```
Answer: {answer_0}
Python code: ```{example_1}```
Answer: {answer_1}
Python code: ```{example_2}```
Answer: {answer_2}
Python code: ```{code}```
Answer:
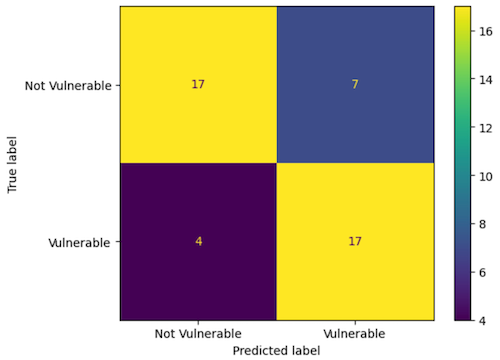
Results
Accuracy: 0.76
Precision: 0.71
Recall: 0.81
F1 Score: 0.76
Experiment 3: KNN Few-shot
This Microsoft blog post describes an interesting technique called KNN-based few-shot example selection that can boost LLM response quality when using in-context examples. For this next experiment, instead of sampling shots at random, we calculate a similarity score between the input code and each candidate example and construct shots from the most similar candidates (still keeping the scenarios distinct). We use the ROUGE-L metric, but other metrics could be used too. The prompt template did not change from the second experiment.
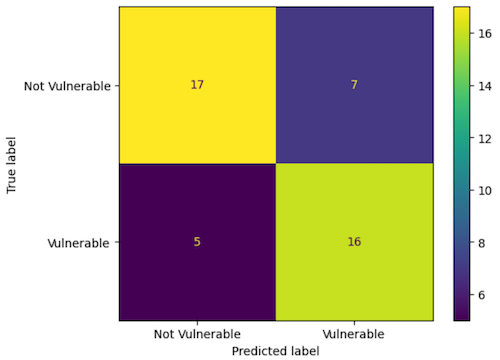
Results
Accuracy: 0.73
Precision: 0.70
Recall: 0.76
F1 Score: 0.73
Experiment 4: KNN Few-shot with Code Fix
In this variation of the prompt, we include a request for a fixed version of the code if a CWE is found. This approach was inspired by Noever, who proposed that prompting for CWE detection and a fix together might bring about a “virtuous cycle” and force the LLM to “self-audit” or think more deeply about the steps needed to accurately identify vulnerabilities, similar to chain-of-thought prompting. We did this by constructing vulnerable code in-context examples with code fix suggestions drawn from the non-vulnerable code samples for the same scenarios.
Prompt
You are a brilliant software security expert.
You will be provided with a python code delimited by triple backticks.
If it contains any CWE security vulnerabilities, write Vulnerable.
If the code does not contain any vulnerabilities, write Not Vulnerable.
If the code has the vulnerability, write a repaired secure version of the
code that preserves its exact functionality.
Format your response as a JSON object with "label" as the key
for vulnerability status, "cwe" as the vulnerability found,
and "fix" for the fixed code snippet.
Think about the answer step by step, and only answer with JSON.
Python code: ```{example_0}```
Answer: {answer_0}
Python code: ```{example_1}```
Answer: {answer_1}
Python code: ```{example_2}```
Answer: {answer_2}
Python code: ```{code}```
Answer:
Results
Accuracy: 0.80
Precision: 0.73
Recall: 0.90
F1 Score: 0.81
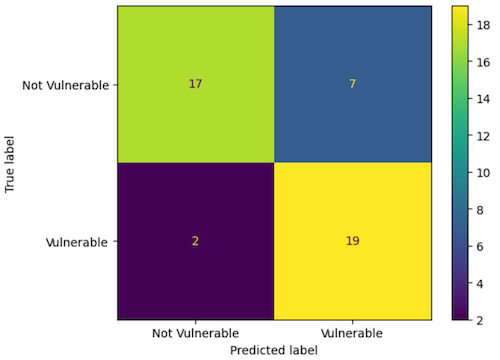
In addition to CWE detection, this experiment has the benefit of producing suggested fixes. We have not evaluated them for quality yet, so that is an area for future work.
Results and Next Steps
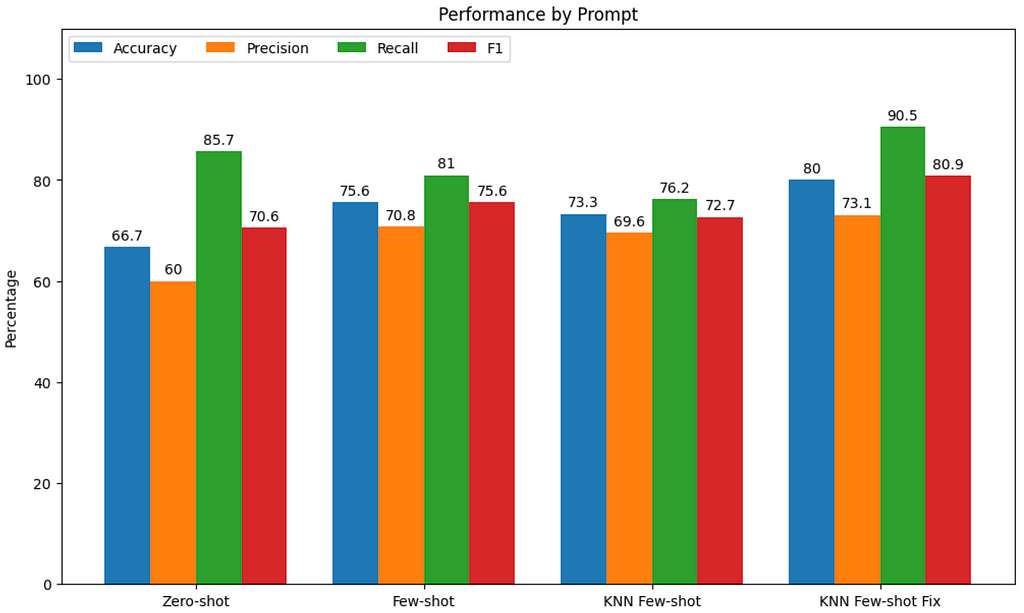
On our small data sample, GPT4’s accuracy was 67% and its F1 score was 71% without any complex prompt adaptations. Small improvements were offered by some of the prompting techniques we tested, with few-shot and requesting a code fix standing out. The combination of techniques bumped accuracy and F1 score by about ten percentage points each from baseline, both metrics reaching or exceeding 80%.
Results can be quite different between models, datasets, and prompts, so more investigation is needed. For example, it would be interesting to:
- Test smaller models
- Test a prompt template that includes the CWE label, to investigate the potential for combining LLMs with static analysis
- Test larger and more diverse datasets
- Evaluate the security and functionality of LLM-proposed code fixes
- Study more advanced prompting techniques such as in-context example chains-of-thought, Self-Consistency, and Self-Discover
If you would like to see the code that produced these results, run it on your own code, or adapt it for your own needs, check out the pull request in OpenAI Cookbook (currently under review).
Thank you to my colleagues Matthew Fleetwood and Abolfazl Shahbazi who made contributions and helped to review this article.
Citations
[1] D. Noever, Can Large Language Models Find And Fix Vulnerable Software? (2023), arXiv preprint arXiv:2308.10345
[2] H. Pearce, B. Ahmad, B. Tan, B. Dolan-Gavitt and R. Karri, Asleep at the Keyboard? Assessing the Security of GitHub Copilot’s Code Contributions (2022), 2022 IEEE Symposium on Security and Privacy (SP)
[3] C. Koch, I Used GPT-3 to Find 213 Security Vulnerabilities in a Single Codebase (2023), https://betterprogramming.pub/i-used-gpt-3-to-find-213-security-vulnerabilities-in-a-single-codebase-cc3870ba9411
[4] A. Bakhshandeh, A. Keramatfar, A. Norouzi and M. M. Chekidehkhoun, Using ChatGPT as a Static Application Security Testing Tool (2023), arXiv preprint arXiv:2308.14434
[5] H. Pearce, B. Tan, B. Ahmad, R. Karri and B. Dolan-Gavitt, Examining Zero-Shot Vulnerability Repair with Large Language Models (2023), 2023 IEEE Symposium on Security and Privacy (SP)
Detecting Insecure Code with LLMs was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Detecting Insecure Code with LLMs
Go Here to Read this Fast! Detecting Insecure Code with LLMs