A framework for unlocking custom LLM solutions you’ll understand
Foreword
This article illustrates how Large Language Models (LLM) are gradually adapted for custom use. It is meant to give people with no computer science background an easy to grasp analogy into how GPT and similar AI systems can be customized. Why the artwork? Bare with me, I hope you enjoy the journey.
Introduction
I will not start this article with an introduction on how ChatGPT, Claude and generative AI have transformed businesses and will forever change our lives, careers and businesses. This has been written many times (most notably by the GPTs themselves …). Instead, today I would like to focus on the question of how we can use a Large Language Model (LLM) for our specific, custom purposes.
In my professional and private life, I have tried to help people understand the basics of what Language AI can and cannot do, beginning with why and how we should do proper prompting (which is beyond the scope of this article), ranging all the way to what it means when managers claim that their company has it’s “own language model.” I feel there is a lot of confusion and uncertainty around the topic of adapting language models to your business requirements in particular. So far, I have not come accross an established framework that adresses this need.
In an attempt to provide an easy explanation that makes non-IT specialists understand the possibilities of language model customization, I came up with an analogy that took me back to my early days when I had been working as a bar piano player. Just like a language model, a bar piano player is frequently asked to play a variety of songs, often with an unspecific request or limited context: “Play it again, Sam…”
Meet Sam — the Bar Piano Player
Imagine you’re sitting in a piano bar in the lounge of a 5-star hotel, and there is a nice grand piano. Sam, the (still human) piano player, is performing. You’re enjoying your drink and wonder if Sam can also perform according to your specific musical taste. For the sake of our argument, Sam is actually a language model, and you’re the hotel (or business) owner wondering what Sam is able to do for you. The Escalation Ladder I present here is a framework, which offers four levels or approaches to gradually shape Sam’s knowledge and capabilities to align with your unique requirements. On each level, the requirements get more and more specific, along with the efforts and costs of making Sam adapt.
The Escalation Ladder: From Prompting to Training Your Own Language Model
1. Prompting: Beyond the Art of Asking the Right Questions
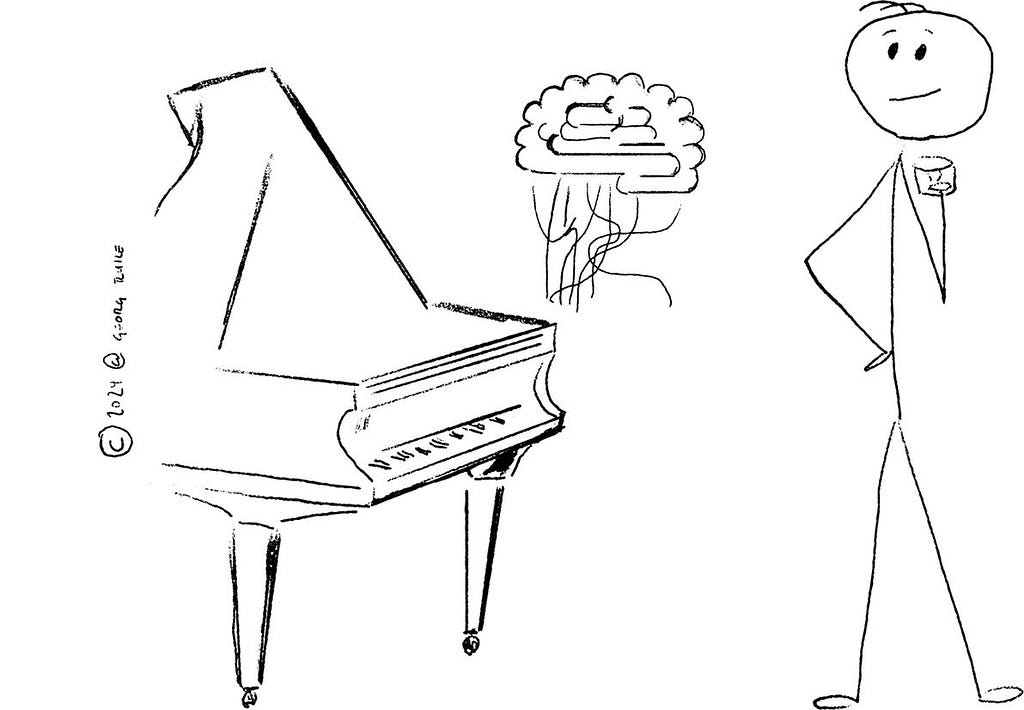
Prompting a language model — the model output depends on the quality of the prompt
The first thing you can do is quite simple, however, may not be easy. You ask Sam to play a song that you’d like to hear. The more specific you are, i.e., the clearer your request, the better your wording (and depending on the number of drinks you’ve had at the hotel bar, your pronunciation), the better. As Voltaire famously said:
“Judge a man by his questions rather than by his answers.”
“Play some jazz” may or may not make Sam play what you had in mind. “Play Dave Brubeck’s original version of ‘Take Five’, playing the lead notes of the saxophone with your right hand while keeping the rythmic pattern in the left” will get quite a specific result, presuming Sam has been given the right training.
What you do here is my analogy to prompting — the way we currently interact with general-purpose language models like GPT or Claude. While prompting is the most straightforward approach, the quality of the output relies heavily on the specificity and clarity of your prompts. It is for this reason that Prompt Engineering has become a profession, one which you probably would never have heard of only a few years ago.
Prompting makes a huge difference, from getting a poor, general, or even false answer to something you can actually work with. That’s why in my daily use of GPT and the like, I always take a minute to consider a proper prompt for the task at hand (my favorite course of action here is something called “role based prompting”, where you give the model a specific role in your prompt, such as an IT expert, a data engineer or a career coach. Again, we will not get into the depths of promtping, since it is beyond the scope of this article).
But prompting has its limits: You may not want to always explain the world within your prompts. It can be quite a tedious task to provide all the context in proper writing (even though chat based language models are somewhat forgiving when it comes to spelling). And the ouput may still deviate from what you had in mind — in the hotel bar scenario, you still may not be happy with Sam’s interpretation of your favorite songs, no matter how specific your requests may have been.
2. Embedding or Retrieval-Augmented Generation (RAG): Provide Context-Relevant Data or Instructions
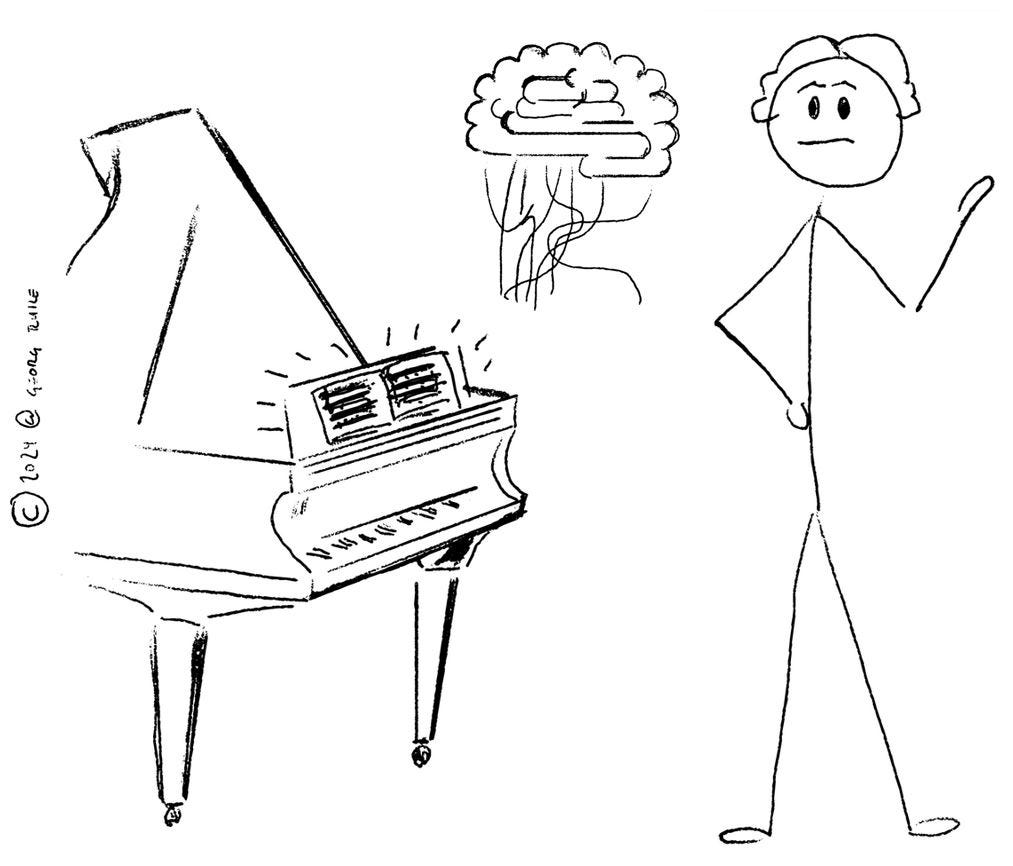
Embedding or adding context to your prompts via Retrieval-Augmented Generation (RAG)
You have an idea. In addition to asking Sam to “play it again” (and to prompt him specifically of what it is you want to hear), you remember you had the sheet music in your bag. So you put the sheets on the piano and ask Sam to play what’s written (provided you give him some incentive, say, $10 in cash).
In our analogy, our model now uses its inherent abilities to generate language output (Sam playing piano) and directs those abilities towards a specific piece of context (Sam playing a specific song).
This architectural pattern is referred to as Retrieval-Augmented Generation (RAG), where you provide the model with additional context or reference materials relevant to your domain. By incorporating these external sources and data, the model can generate more informed and accurate responses, tailored to your specific needs. In more technical terms, this involves preparing and cleaning textual context data that is then transformed into Embeddings and properly indexed. When prompted, the model receives a relevant selection of this context data, according to the content of the prompt.
It is the next step up the ladder since it requires some effort on your side (e.g., giving Sam $10) and can involve some serious implementation costs.
Now Sam plays your favorite tune — however, you are still not happy with the way he plays it. Somehow, you want more Swing, or another touch is missing. So you take the next step on our ladder.
3. Fine-tuning: Learning and Adapting to Feedback
Fine-tuning a model by iteratively giving it (human) feedback — just like a piano teacher
This is where my analogy starts to get a bit shaky, especially when we’re taking the word “tuning” in our musical context literally. Here, we are not talking about tuning Sam’s piano. Instead, when thinking about fine-tuning in this context, I am referring to taking a considerable amount of time to work with Sam until he plays how we like him to play. So we basically give him piano lessons, providing feedback on his playing and supervising his progress.
Back to language models, one of the approaches here is referred to as reinforcement learning from human feedback (RLHF), and it fits well into our picture of a strict piano teacher. Fine-tuning takes the customization process further by adapting (i.e. tuning) the model’s knowledge and skills to a particular task or domain. Again, putting it a little more technical, what happens here is based on Reinforecement Learning, which has a Reward Function at its core. This reward dynamically adapts to the human feedback, which is often given as a human A/B judgement label to the textual output of the model, given the same prompt.
For this process, we need considerable (computational) resources, large amounts of curated data, and/or human feedback. This explains why it is already quite high on our escalation ladder, but it’s not the end yet.
What if we want Sam to play or do very specific musical things? For example, we want him to sing along — that would make Sam quite nervous (at least, that’s what this specific request made me feel, back in the days), because Sam hasn’t been trained and never tried to sing…
4. Custom Model Training: Breeding a New Expert
Training a model from scratch to breed an expert
At the pinnacle of the Escalation Ladder we encounter custom model (pre-)training, where you essentially create a new expert from scratch, tailored to your exact requirements. This is also where my analogy might crumble (never said it was perfect!) — how do you breed a new piano player from scratch? But let’s stick to it anyway — let’s think about training Samantha, who has never played any music nor sung in her entire life. So we invest heavily in her education and skills, sending her to the top institutions where musicians learn what we want them to play.
Here we are nurturing a new language model from the ground up, instilling it with the knowledge and data necessary to perform in our particular domain. By carefully curating the training data and adjusting the model and its architecture, we can develop a highly specialized and optimized language model capable of tackling even the most proprietary tasks within your organization. In this process, the amount of data and number of parameters that current large language models are trained on can get quite staggering. For instance, rumours suggest that OpenAI’s most recent GPT-4 has 1.76 trillion parameters. Hence, this approach often requires enormous resources and is beyond reach for many businesses today.
Conclusion
Just like our journey from timidly asking Sam to play Dave Brubeck’s “Take Five” up to developing new talent — as we progress through each level of the Escalation Ladder, the effort and resources required increase significantly, but so does the level of customization and control we gain over the language model’s capabilities.
Of course, much like most frameworks, this one is not as clear cut as I have presented it here. There can be hybrid or mixed approaches, and even the finest RAG implementation will need you to do some proper prompting. However, by understanding and reminding yourself of this framework, I believe you can strategically determine the appropriate level of customization needed for your specific use cases. To unlock the full potential of Language AI, you will need to strike the right balance between effort and cost, and tailored performance. It may also help bridge the communication gap between business and IT when it comes to Language AI model adaption and implementation.
I hope you enjoyed meeting Sam and Samantha and adapting their abilities on the piano. I welcome you to comment, critique, or expand on what you think of this analogy in the comments below, or simply share this article with people who might benefit from it.
Notes and References: This article has been inspired by this technical article on Retrieval Augmented Generation from Databricks. All drawings are hand crafted with pride by the author 🙂
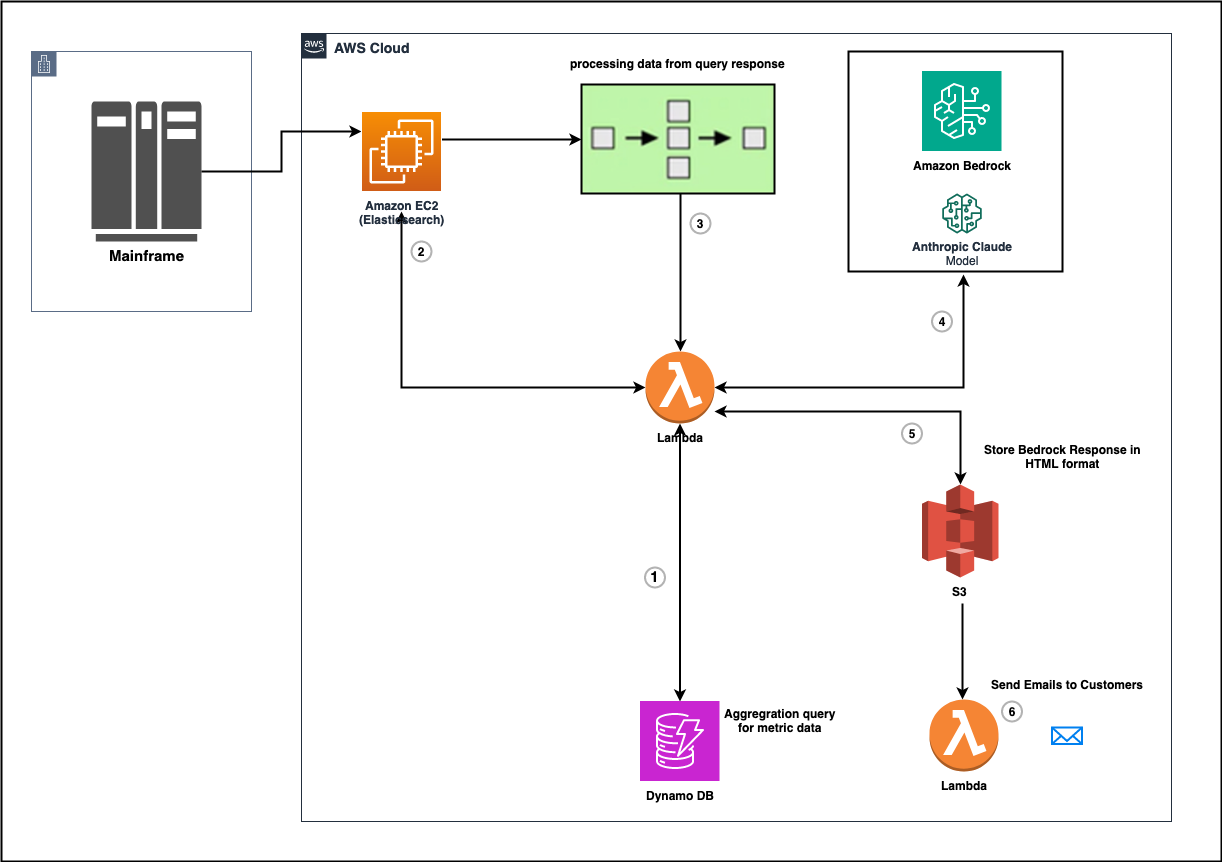
This blog post discusses how BMC Software added AWS Generative AI capabilities to its product BMC AMI zAdviser Enterprise. The zAdviser uses Amazon Bedrock to provide summarization, analysis, and recommendations for improvement based on the DORA metrics data.
Amazon Titan lmage Generator G1 is a cutting-edge text-to-image model, available via Amazon Bedrock, that is able to understand prompts describing multiple objects in various contexts and captures these relevant details in the images it generates. It is available in US East (N. Virginia) and US West (Oregon) AWS Regions and can perform advanced image […]
This blog post will go into detail about a cost-saving architecture for LLM-driven apps as seen in the “FrugalGPT” paper
Image by Author generated by DALL-E
Large Language Models open up a new frontier for computer science, however, they are (as of 2024) significantly more expensive to run than almost anything else in computer science. For companies looking to minimize their operating costs, this poses a serious problem. The “FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance” paper introduces one framework to reduce operating costs significantly while maintaining quality.
How to Measure the Cost of LLM
There are multiple ways to determine the cost of running a LLM (electricity use, compute cost, etc.), however, if you use a third-party LLM (a LLM-as-a-service) they typically charge you based on the tokens you use. Different vendors (OpenAI, Anthropic, Cohere, etc.) have different ways of counting the tokens, but for the sake of simplicity, we’ll consider the cost to be based on the number of tokens processed by the LLM.
The most important part of this framework is the idea that different models cost different amounts. The authors of the paper conveniently assembled the below table highlighting the difference in cost, and the difference between them is significant. For example, AI21’s output tokens cost an order of magnitude more than GPT-4’s does in this table!
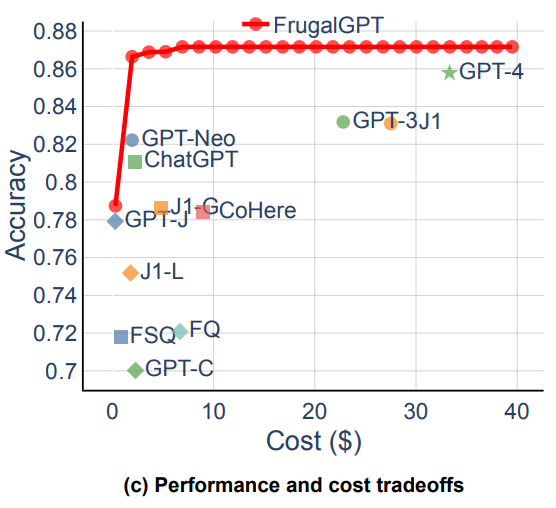
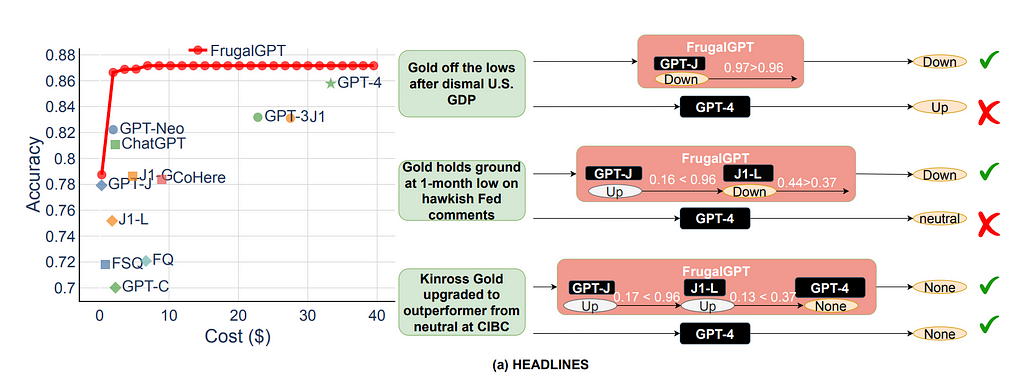
As a part of cost optimization we always need to figure out a way to optimize the answer quality while minimizing the cost. Typically, higher cost models are often higher performing models, able to give higher quality answers than lower cost ones. The general relationship can be seen in the below graph, with Frugal GPT’s performance overlaid on top in red.
Figure 1c from the paper comparing various LLMs based on the how often they would accurately respond to questions based on the HEADLINES dataset
Maximizing Quality with Cascading LLMS
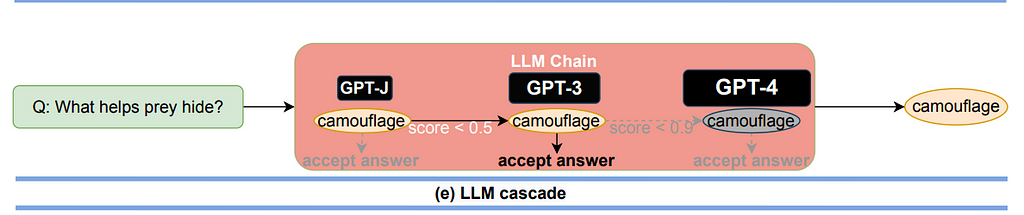
Using the vast cost difference between models, the researchers’ FrugalGPT system relies on a cascade of LLMs to give the user an answer. Put simply, the user query begins with the cheapest LLM, and if the answer is good enough, then it is returned. However, if the answer is not good enough, then the query is passed along to the next cheapest LLM.
The researchers used the following logic: if a less expensive model answers a question incorrectly, then it is likely that a more expensive model will give the answer correctly. Thus, to minimize costs the chain is ordered from least expensive to most expensive, assuming that quality goes up as you get more expensive.
This setup relies on reliably determining when an answer is good enough and when it isn’t. To solve for this, the authors created a DistilBERT model that would take the question and answer then assign a score to the answer. As the DistilBERT model is exponentially smaller than the other models in the sequence, the cost to run it is almost negligible compared to the others.
Better Average Quality Than Just Querying the Best LLM
One might naturally ask, if quality is most important, why not just query the best LLM and work on ways to reduce the cost of running the best LLM?
When this paper came out GPT-4 was the best LLM they found, yet GPT-4 did not always give a better answer than the FrugalGPT system! (Eagle-eyed readers will see this as part of the cost vs performance graph from before) The authors speculate that just as the most capable person doesn’t always give the right answer, the most complex model won’t either. Thus, by having the answer go through a filtering process with DistilBERT, you are removing any answers that aren’t up to par and increasing the odds of a good answer.
Figure 5a from the paper showing instances where FrugalGPT is outperforming GPT-4
Consequently, this system not only reduces your costs but can also increase quality more so than just using the best LLM!
Moving Forwards with Cost Savings
The results of this paper are fascinating to consider. For me, it raises questions about how we can go even further with cost savings without having to invest in further model optimization.
One such possibility is to cache all model answers in a vector database and then do a similarity search to determine if the answer in the cache works before starting the LLM cascade. This would significantly reduce costs by replacing a costly LLM operation with a comparatively less expensive query and similarity operation.
Additionally, it makes you wonder if outdated models can still be worth cost-optimizing, as if you can reduce their cost per token, they can still create value on the LLM cascade. Similarly, the key question here is at what point do you get diminishing returns by adding new LLMs onto the chain.
Questions for Further Study
As the world creates more LLMs and we increasingly build systems that use them, we will want to find cost-effective ways to run them. This paper creates a strong framework for future builders to expand on, making me wonder about how far this framework can go.
In my opinion, this framework applies really well for general queries that do not have different answers based on different users, such as a tutor LLM. However, for use cases where answers differ based on the user, say a LLM that acts as a customer service agent, the scoring system would have to be aware of who the LLM was talking with.
Finding a framework that saves money for user-specific interactions will be important for the future.
Step-by-Step Workflow for developing and refining an AI Agent while dealing with errors
When we think about the future of AI, we envision intuitive everyday helpers seamlessly integrating into our workflows and taking on complex, routinely tasks. We all have found touchpoints that relieve us from the tedium of mental routine work. Yet, the main tasks currently tackled involve text creation, correction, and brainstorming, underlined by the significant role RAG (Retrieval-Augmented Generation) pipelines play in ongoing development. We aim to provide Large Language Models with better context to generate more valuable content.
Thinking about the future of AI conjures images of Jarvis from Iron Man or Rasputin from Destiny (the game) for me. In both examples, the AI acts as a voice-controlled interface to a complex system, offering high-level abstractions. For instance, Tony Stark uses it to manage his research, conduct calculations, and run simulations. Even R2D2 can respond to voice commands to interface with unfamiliar computer systems and extract data or interact with building systems.
In these scenarios, AI enables interaction with complex systems without requiring the end user to have a deep understanding of them. This could be likened to an ERP system in a large corporation today. It’s rare to find someone in a large corporation who fully knows and understands every facet of the in-house ERP system. It’s not far-fetched to imagine that, in the near future, AI might assist nearly every interaction with an ERP system. From the end user managing customer data or logging orders to the software developer fixing bugs or implementing new features, these interactions could soon be facilitated by AI assistants familiar with all aspects and processes of the ERP system. Such an AI assistant would know which database to enter customer data into and which processes and code might be relevant to a bug.
To achieve this, several challenges and innovations lie ahead. We need to rethink processes and their documentation. Today’s ERP processes are designed for human use, with specific roles for different users, documentation for humans, input masks for humans, and user interactions designed to be intuitive and error-free. The design of these aspects will look different for AI interactions. We need specific roles for AI interactions and different process designs to enable intuitive and error-free AI interaction. This is already evident in our work with prompts. What we consider to be a clear task often turns out not to be so straightforward.
From Concept to Reality: Building the Basis for AI Agents
However, let’s first take a step back to the concept of agents. Agents, or AI assistants that can perform tasks using the tools provided and make decisions on how to use these tools, are the building blocks that could eventually enable such a system. They are the process components we’d want to integrate into every facet of a complex system. But as highlighted in a previous article, they are challenging to deploy reliably. In this article, I will demonstrate how we can design and optimize an agent capable of reliably interacting with a database.
While the grand vision of AI’s future is inspiring, it’s crucial to take practical steps towards realizing this vision. To demonstrate how we can start building the foundation for such advanced AI systems, let’s focus on creating a prototype agent for a common task: expense tracking. This prototype will serve as a tangible example of how AI can assist in managing financial transactions efficiently, showcasing the potential of AI in automating routine tasks and highlighting the challenges and considerations involved in designing an AI system that interacts seamlessly with databases. By starting with a specific and relatable use case, we can gain valuable insights that will inform the development of more complex AI agents in the future.
The Aim of This Article
This article will lay the groundwork for a series of articles aimed at developing a chatbot that can serve as a single point of interaction for a small business to support and execute business processes or a chatbot that in your personal life organizes everything you need to keep track of. From data, routines, files, to pictures, we want to simply chat with our Assistant, allowing it to figure out where to store and retrieve your data.
Transitioning from the grand vision of AI’s future to practical applications, let’s zoom in on creating a prototype agent. This agent will serve as a foundational step towards realizing the ambitious goals discussed earlier. We will embark on developing an “Expense Tracking” agent, a straightforward yet essential task, demonstrating how AI can assist in managing financial transactions efficiently.
This “Expense Tracking” prototype will not only showcase the potential of AI in automating routine tasks but also illuminate the challenges and considerations involved in designing an AI system that interacts seamlessly with databases. By focusing on this example, we can explore the intricacies of agent design, input validation, and the integration of AI with existing systems — laying a solid foundation for more complex applications in the future.
1. Hands-On: Testing OpenAI Tool Call
To bring our prototype agent to life and identify potential bottlenecks, we’re venturing into testing the tool call functionality of OpenAI. Starting with a basic example of expense tracking, we’re laying down a foundational piece that mimics a real-world application. This stage involves creating a base model and transforming it into the OpenAI tool schema using the langchain library’s convert_to_openai_tool function. Additionally, crafting a report_tool enables our future agent to communicate results or highlight missing information or issues:
from pydantic.v1 import BaseModel, validator from datetime import datetime from langchain_core.utils.function_calling import convert_to_openai_tool
With the data model and tools set up, the next step is to use the OpenAI client SDK to initiate a simple tool call. In this initial test, we’re intentionally providing insufficient information to the model to see if it can correctly indicate what’s missing. This approach not only tests the functional capability of the agent but also its interactive and error-handling capacities.
Calling OpenAI API
Now, we’ll use the OpenAI client SDK to initiate a simple tool call. In our first test, we deliberately provide the model with insufficient information to see if it can notify us of the missing details.
from openai import OpenAI from langchain_core.utils.function_calling import convert_to_openai_tool
SYSTEM_MESSAGE = """You are tasked with completing specific objectives and must report the outcomes. At your disposal, you have a variety of tools, each specialized in performing a distinct type of task.
For successful task completion: Thought: Consider the task at hand and determine which tool is best suited based on its capabilities and the nature of the work.
Use the report_tool with an instruction detailing the results of your work. If you encounter an issue and cannot complete the task:
Use the report_tool to communicate the challenge or reason for the task's incompletion. You will receive feedback based on the outcomes of each tool's task execution or explanations for any tasks that couldn't be completed. This feedback loop is crucial for addressing and resolving any issues by strategically deploying the available tools. """ user_message = "I have spend 5$ on a coffee today please track my expense. The tax rate is 0.2."
As we can observe, we have encountered several issues in the execution:
The gross_amount is not calculated.
The date is hallucinated.
With that in mind. Let’s try to resolve this issues and optimize our agent workflow.
2. Optimize Tool handling
To optimize the agent workflow, I find it crucial to prioritize workflow over prompt engineering. While it might be tempting to fine-tune the prompt so that the agent learns to use the tools provided perfectly and makes no mistakes, it’s more advisable to first adjust the tools and processes. When a typical error occurs, the initial consideration should be how to fix it code-based.
Handling Missing Information
Handling missing information effectively is an essential topic for creating robust and reliable agents. In the previous example, providing the agent with a tool like “get_current_date” is a workaround for specific scenarios. However, we must assume that missing information will occur in various contexts, and we cannot rely solely on prompt engineering and adding more tools to prevent the model from hallucinating missing information.
A simple workaround for this scenario is to modify the tool schema to treat all parameters as optional. This approach ensures that the agent only submits the parameters it knows, preventing unnecessary hallucination.
Therefore, let’s take a look at openai tool schema:
As we can see we have special key required , which we need to remove. Here’s how you can adjust the add_expense_tool schema to make parameters optional by removing the required key:
del add_expense_tool["function"]["parameters"]["required"]
Designing Tool class
Next, we can design a Tool class that initially checks the input parameters for missing values. We create the Tool class with two methods: .run(), .validate_input(), and a property openai_tool_schema, where we manipulate the tool schema by removing required parameters. Additionally, we define the ToolResult BaseModel with the fields content and success to serve as the output object for each tool run.
from pydantic import BaseModel from typing import Type, Callable, Dict, Any, List
class ToolResult(BaseModel): content: str success: bool
def run(self, **kwargs) -> ToolResult: if self.validate_missing: missing_values = self.validate_input(**kwargs) if missing_values: content = f"Missing values: {', '.join(missing_values)}" return ToolResult(content=content, success=False) result = self.function(**kwargs) return ToolResult(content=str(result), success=True)
def validate_input(self, **kwargs) -> List[str]: missing_values = [] for key in self.model.__fields__.keys(): if key not in kwargs: missing_values.append(key) return missing_values @property def openai_tool_schema(self) -> Dict[str, Any]: schema = convert_to_openai_tool(self.model) if "required" in schema["function"]["parameters"]: del schema["function"]["parameters"]["required"] return schema
The Tool class is a crucial component in the AI agent’s workflow, serving as a blueprint for creating and managing various tools that the agent can utilize to perform specific tasks. It is designed to handle input validation, execute the tool’s function, and return the result in a standardized format.
The Tool class key components:
name: The name of the tool.
model: The Pydantic BaseModel that defines the input schema for the tool.
function: The callable function that the tool executes.
validate_missing: A boolean flag indicating whether to validate missing input values (default is False).
The Tool class two main methods:
run(self, **kwargs) -> ToolResult: This method is responsible for executing the tool’s function with the provided input arguments. It first checks if validate_missing is set to True. If so, it calls the validate_input() method to check for missing input values. If any missing values are found, it returns a ToolResult object with an error message and success set to False. If all required input values are present, it proceeds to execute the tool’s function with the provided arguments and returns a ToolResult object with the result and success set to True.
validate_input(self, **kwargs) -> List[str]: This method compares the input arguments passed to the tool with the expected input schema defined in the model. It iterates over the fields defined in the model and checks if each field is present in the input arguments. If any field is missing, it appends the field name to a list of missing values. Finally, it returns the list of missing values.
The Tool class also has a property called openai_tool_schema, which returns the OpenAI tool schema for the tool. It uses the convert_to_openai_tool() function to convert the model to the OpenAI tool schema format. Additionally, it removes the “required” key from the schema, making all input parameters optional. This allows the agent to provide only the available information without the need to hallucinate missing values.
By encapsulating the tool’s functionality, input validation, and schema generation, the Tool class provides a clean and reusable interface for creating and managing tools in the AI agent’s workflow. It abstracts away the complexities of handling missing values and ensures that the agent can gracefully handle incomplete information while executing the appropriate tools based on the available input.
Testing Missing Information Handling
Next, we will extend our OpenAI API call. We want the client to utilize our tool, and our response object to directly trigger a tool.run(). For this, we need to initialize our tools in our newly created Tool class. We define two dummy functions which return a success message string.
def add_expense_func(**kwargs): return f"Added expense: {kwargs} to the database."
Next we define our helper function, that each take client response as input an help to interact with out tools.
def get_tool_from_response(response, tools=tools): tool_name = response.choices[0].message.tool_calls[0].function.name for t in tools: if t.name == tool_name: return t raise ValueError(f"Tool {tool_name} not found in tools list.")
Perfectly, we now see our tool indicating that missing values are present. Thanks to our trick of sending all parameters as optional, we now avoid hallucinated parameters.
3. Building the Agent Workflow
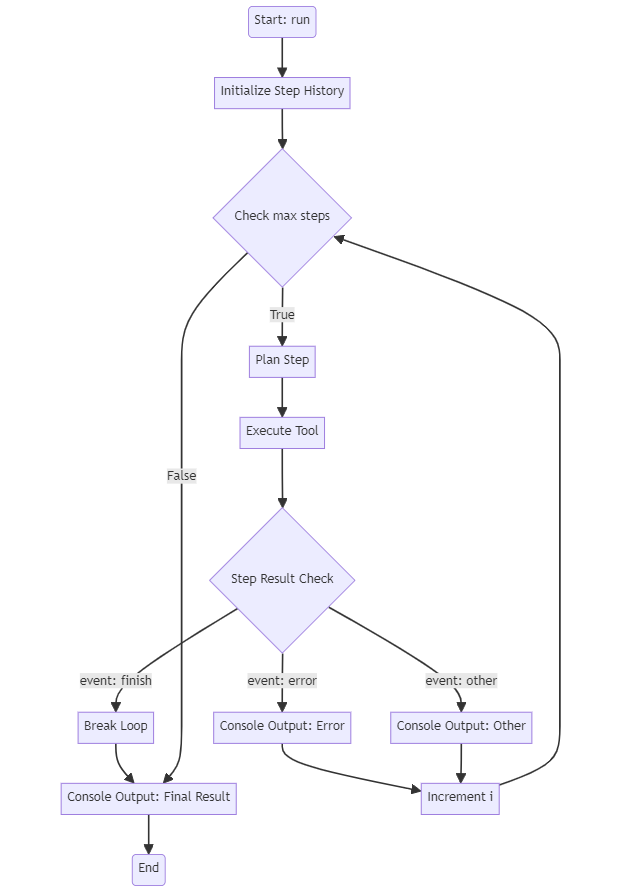
Our process, as it stands, doesn’t yet represent a true agent. So far, we’ve only executed a single API tool call. To transform this into an agent workflow, we need to introduce an iterative process that feeds the results of tool execution back to the client. The basic process should like this:
Image by author
Let’s get started by creating a new OpenAIAgent class:
class StepResult(BaseModel): event: str content: str success: bool
Like our ToolResultobject, we’ve defined a StepResult as an object for each agent step. We then defined the __init__ method of the OpenAIAgent class and a to_console() method to print our intermediate steps and tool calls to the console, using colorama for colorful printouts. Next, we define the heart of the agent, the run() and the run_step() method.
class OpenAIAgent:
# ... __init__...
# ... to_console ...
def run(self, user_input: str):
openai_tools = [tool.openai_tool_schema for tool in self.tools] self.step_history = [ {"role":"system", "content":self.system_message}, {"role":"user", "content":user_input} ]
step_result = None i = 0
self.to_console("START", f"Starting Agent with Input: {user_input}")
while i < self.max_steps: step_result = self.run_step(self.step_history, openai_tools)
if step_result.event == "finish": break elif step_result.event == "error": self.to_console(step_result.event, step_result.content, "red") else: self.to_console(step_result.event, step_result.content, "yellow") i += 1
In the run() method, we start by initializing the step_history, which will serve as our message memory, with the predefined system_message and the user_input. Then we start our while loop, where we call run_step during each iteration, which will return a StepResult Object. We identify if the agent finished his task or if an error occurred, which will be passed to the console as well.
# plan the next step response = self.client.chat.completions.create( model=self.model_name, messages=messages, tools=tools )
# add message to history self.step_history.append(response.choices[0].message)
# check if tool call is present if not response.choices[0].message.tool_calls: return StepResult( event="Error", content="No tool calls were returned.", success=False )
Now we’ve defined the logic for each step. We first obtain a response object by our previously tested client API call with tools. We append the response message object to our step_history. We then verify if a tool call is included in our response object, otherwise, we return an error in our StepResult. Then we log our tool call to the console and run the selected tool with our previously defined method run_tool_from_response(). We also need to append the tool result to our message history. OpenAI has defined a specific format for this purpose, so that the Model knows which tool call refers to which output by passing a tool_call_id into our message dict. This is done by our method tool_call_message(), which takes the response object and the tool_result as input arguments. At the end of each step, we assign the tool result to a StepResult Object, which also indicates if the step was successful or not, and return it to our loop in run().
4. Running the Agent
Now we can test our agent with the previous example, directly equipping it with a get_current_date_tool as well. Here, we can set our previously defined validate_missing attribute to False, since the tool doesn’t need any input argument.
Tool Call: add_expense_tool Args: {'description': 'Coffee expense', 'net_amount': 5, 'tax_rate': 0.2, 'date': '2024-03-15', 'gross_amount': 6} tool_result: Added expense: {'description': 'Coffee expense', 'net_amount': 5, 'tax_rate': 0.2, 'date': '2024-03-15', 'gross_amount': 6} to the database. Error: No tool calls were returned.
Tool Call: Name: report_tool Args: {'report': 'Expense successfully tracked for coffee purchase.'} tool_result: Reported: Expense successfully tracked for coffee purchase.
Final Result: Reported: Expense successfully tracked for coffee purchase.
Following the successful execution of our prototype agent, it’s noteworthy to emphasize how effectively the agent utilized the designated tools according to plan. Initially, it invoked the get_current_date_tool, establishing a foundational timestamp for the expense entry. Subsequently, when attempting to log the expense via the add_expense_tool, our intelligently designed tool class identified a missing gross_amount—a crucial piece of information for accurate financial tracking. Impressively, the agent autonomously resolved this by calculating the gross_amount using the provided tax_rate.
It’s important to mention that in our test run, the nature of the input expense — whether the $5 spent on coffee was net or gross — wasn’t explicitly specified. At this juncture, such specificity wasn’t required for the agent to perform its task successfully. However, this brings to light a valuable insight for refining our agent’s understanding and interaction capabilities: Incorporating such detailed information into our initial system prompt could significantly enhance the agent’s accuracy and efficiency in processing expense entries. This adjustment would ensure a more comprehensive grasp of financial data right from the outset.
Key Takeaways
Iterative Development: The project underscores the critical nature of an iterative development cycle, fostering continuous improvement through feedback. This approach is paramount in AI, where variability is the norm, necessitating an adaptable and responsive development strategy.
Handling Uncertainty: Our journey highlighted the significance of elegantly managing ambiguities and errors. Innovations such as optional parameters and rigorous input validation have proven instrumental in enhancing both the reliability and user experience of the agent.
Customized Agent Workflows for Specific Tasks: A key insight from this work is the importance of customizing agent workflows to suit particular use cases. Beyond assembling a suite of tools, the strategic design of tool interactions and responses is vital. This customization ensures the agent effectively addresses specific challenges, leading to a more focused and efficient problem-solving approach.
The journey we have embarked upon is just the beginning of a larger exploration into the world of AI agents and their applications in various domains. As we continue to push the boundaries of what’s possible with AI, we invite you to join us on this exciting adventure. By building upon the foundation laid in this article and staying tuned for the upcoming enhancements, you will witness firsthand how AI agents can revolutionize the way businesses and individuals handle their data and automate complex tasks.
Together, let us embrace the power of AI and unlock its potential to transform the way we work and interact with technology. The future of AI is bright, and we are at the forefront of shaping it, one reliable agent at a time.
Looking Ahead
As we continue our journey in exploring the potential of AI agents, the upcoming articles will focus on expanding the capabilities of our prototype and integrating it with real-world systems. In the next article, we will dive into designing a robust project structure that allows our agent to interact seamlessly with SQL databases. By leveraging the agent developed in this article, we will demonstrate how AI can efficiently manage and manipulate data stored in databases, opening up a world of possibilities for automating data-related tasks.
Building upon this foundation, the third article in the series will introduce advanced query features, enabling our agent to handle more complex data retrieval and manipulation tasks. We will also explore the concept of a routing agent, which will act as a central hub for managing multiple subagents, each responsible for interacting with specific database tables. This hierarchical structure will allow users to make requests in natural language, which the routing agent will then interpret and direct to the appropriate subagent for execution.
To further enhance the practicality and security of our AI-powered system, we will introduce a role-based access control system. This will ensure that users have the appropriate permissions to access and modify data based on their assigned roles. By implementing this feature, we can demonstrate how AI agents can be deployed in real-world scenarios while maintaining data integrity and security.
Through these upcoming enhancements, we aim to showcase the true potential of AI agents in streamlining data management processes and providing a more intuitive and efficient way for users to interact with databases. By combining the power of natural language processing, database management, and role-based access control, we will be laying the groundwork for the development of sophisticated AI assistants that can revolutionize the way businesses and individuals handle their data.
Stay tuned for these exciting developments as we continue to push the boundaries of what’s possible with AI agents in data management and beyond.
Source Code
Additionally, the entire source code for the projects covered is available on GitHub. You can access it at https://github.com/elokus/AgentDemo.
For a moment, imagine an airplane. What springs to mind? Now imagine a Boeing 737 and a V-22 Osprey. Both are aircraft designed to move cargo and people, yet they serve different purposes — one more general (commercial flights and freight), the other very specific (infiltration, exfiltration, and resupply missions for special operations forces). They look far different because they are built for different activities.
With the rise of LLMs, we have seen our first truly general-purpose ML models. Their generality helps us in so many ways:
The same engineering team can now do sentiment analysis and structured data extraction
Practitioners in many domains can share knowledge, making it possible for the whole industry to benefit from each other’s experience
There is a wide range of industries and jobs where the same experience is useful
But as we see with aircraft, generality requires a very different assessment from excelling at a particular task, and at the end of the day business value often comes from solving particular problems.
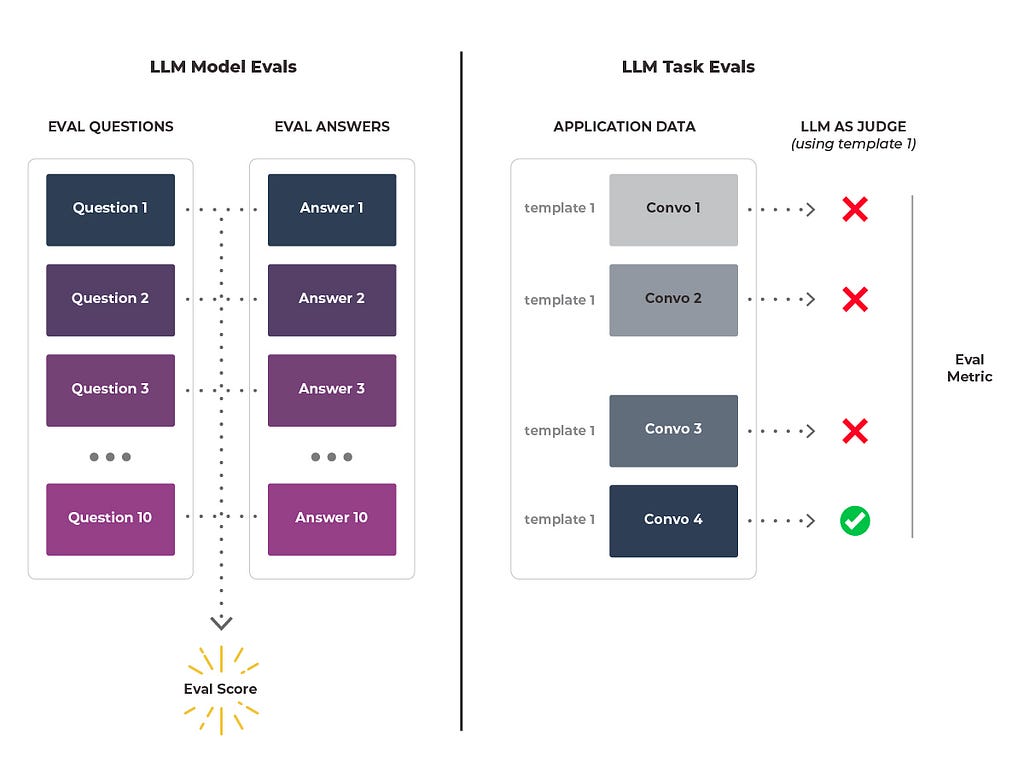
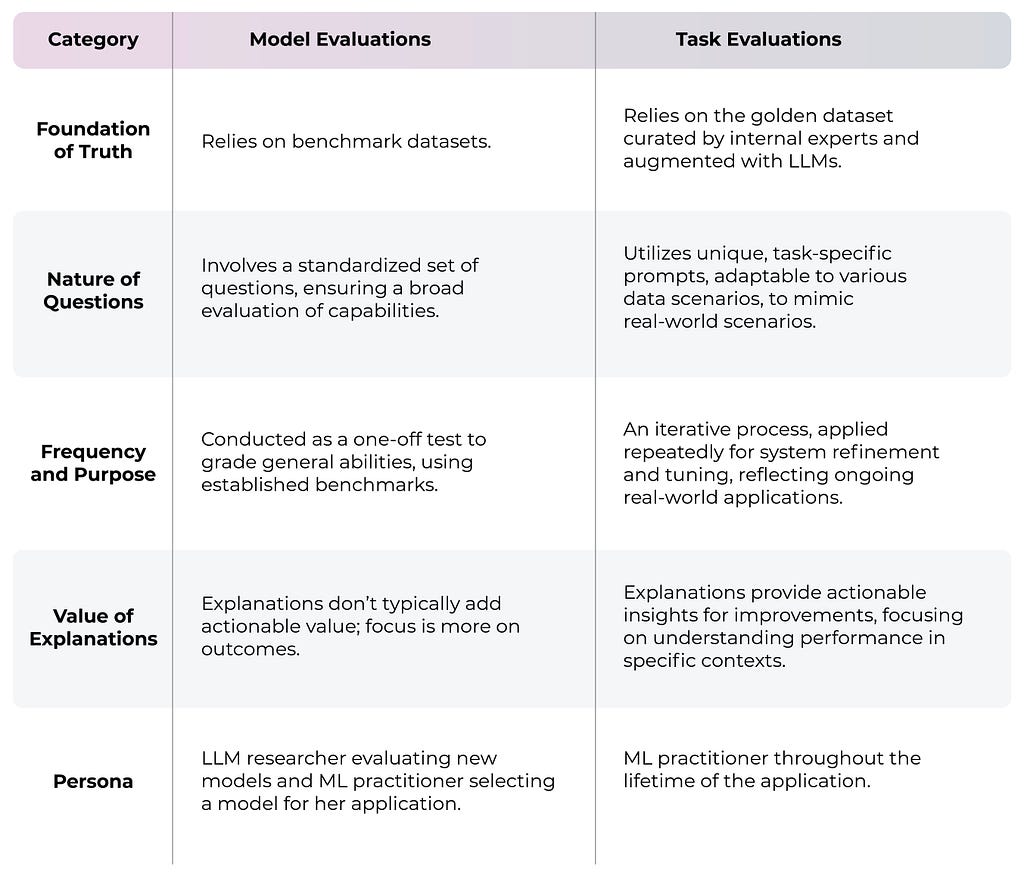
This is a good analogy for the difference between model and task evaluations. Model evals are focused on overall general assessment, but task evals are focused on assessing performance of a particular task.
There Is More Than One LLM Eval
The term LLM evals is thrown around quite generally. OpenAI released some tooling to do LLM evals very early, for example. Most practitioners are more concerned with LLM task evals, but that distinction is not always clearly made.
What’s the Difference?
Model evals look at the “general fitness” of the model. How well does it do on a variety of tasks?
Task evals, on the other hand, are specifically designed to look at how well the model is suited for your particular application.
Someone who works out generally and is quite fit would likely fare poorly against a professional sumo wrestler in a real competition, and model evals can’t stack up against task evals in assessing your particular needs.
Model Evals
Model evals are specifically meant for building and fine-tuning generalized models. They are based on a set of questions you ask a model and a set of ground-truth answers that you use to grade responses. Think of taking the SATs.
While every question in a model eval is different, there is usually a general area of testing. There is a theme or skill each metric is specifically targeted at. For example, HellaSwag performance has become a popular way to measure LLM quality.
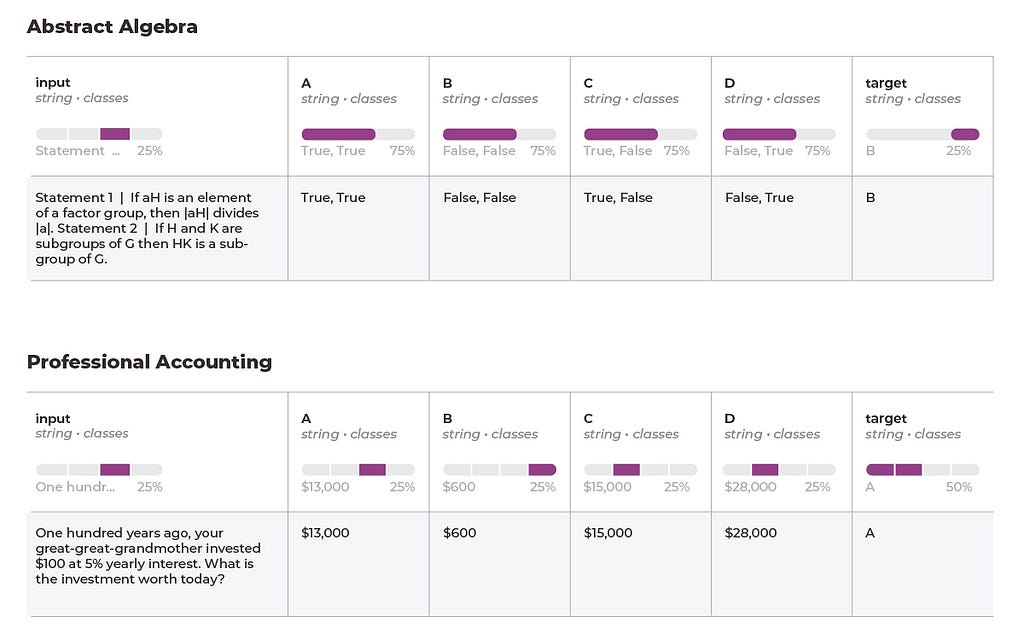
The HellaSwag dataset consists of a collection of contexts and multiple-choice questions where each question has multiple potential completions. Only one of the completions is sensible or logically coherent, while the others are plausible but incorrect. These completions are designed to be challenging for AI models, requiring not just linguistic understanding but also common sense reasoning to choose the correct option.
Here is an example: A tray of potatoes is loaded into the oven and removed. A large tray of cake is flipped over and placed on counter. a large tray of meat
A. is placed onto a baked potato
B. ls, and pickles are placed in the oven
C. is prepared then it is removed from the oven by a helper when done.
Another example is MMLU. MMLU features tasks that span multiple subjects, including science, literature, history, social science, mathematics, and professional domains like law and medicine. This diversity in subjects is intended to mimic the breadth of knowledge and understanding required by human learners, making it a good test of a model’s ability to handle multifaceted language understanding challenges.
Here are some examples — can you solve them?
For which of the following thermodynamic processes is the increase in the internal energy of an ideal gas equal to the heat added to the gas?
A. Constant Temperature
B. Constant Volume
C. Constant Pressure
D. Adiabatic
Image by author
The Hugging Face Leaderboard is perhaps the best known place to get such model evals. The leaderboard tracks open source large language models and keeps track of many model evaluation metrics. This is typically a great place to start understanding the difference between open source LLMs in terms of their performance across a variety of tasks.
Multimodal models require even more evals. The Gemini paper demonstrates that multi-modality introduces a host of other benchmarks like VQAv2, which tests the ability to understand and integrate visual information. This information goes beyond simple object recognition to interpreting actions and relationships between them.
Similarly, there are metrics for audio and video information and how to integrate across modalities.
The goal of these tests is to differentiate between two models or two different snapshots of the same model. Picking a model for your application is important, but it is something you do once or at most very infrequently.
Image by author
Task Evals
The much more frequent problem is one solved by task evaluations. The goal of task-based evaluations is to analyze the performance of the model using LLM as a judge.
Did your retrieval system fetch the right data?
Are there hallucinations in your responses?
Did the system answer important questions with relevant answers?
Some may feel a bit unsure about an LLM evaluating other LLMs, but we have humans evaluating other humans all the time.
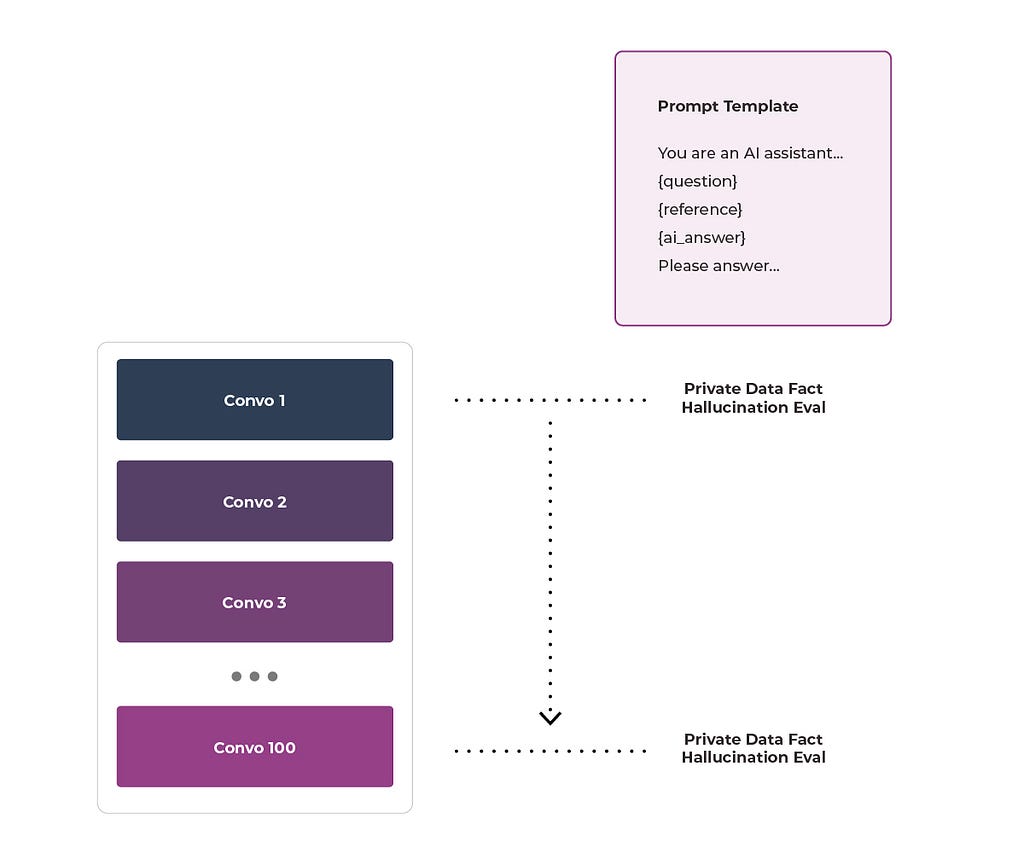
The real distinction between model and task evaluations is that for a model eval we ask many different questions, but for a task eval the question stays the same and it is the data we change. For example, say you were operating a chatbot. You could use your task eval on hundreds of customer interactions and ask it, “Is there a hallucination here?” The question stays the same across all the conversations.
Image by author
There are several libraries aimed at helping practitioners build these evaluations: Ragas, Phoenix (full disclosure: the author leads the team that developed Phoenix), OpenAI, LlamaIndex.
How do they work?
The task eval grades performance of every output from the application as a whole. Let’s look at what it takes to put one together.
Establishing a benchmark
The foundation rests on establishing a robust benchmark. This starts with creating a golden dataset that accurately reflects the scenarios the LLM will encounter. This dataset should include ground truth labels — often derived from meticulous human review — to serve as a standard for comparison. Don’t worry, though, you can usually get away with dozens to hundreds of examples here. Selecting the right LLM for evaluation is also critical. While it may differ from the application’s primary LLM, it should align with goals of cost-efficiency and accuracy.
Crafting the evaluation template
The heart of the task evaluation process is the evaluation template. This template should clearly define the input (e.g., user queries and documents), the evaluation question (e.g., the relevance of the document to the query), and the expected output formats (binary or multi-class relevance). Adjustments to the template may be necessary to capture nuances specific to your application, ensuring it can accurately assess the LLM’s performance against the golden dataset.
Here is an example of a template to evaluate a Q&A task.
You are given a question, an answer and reference text. You must determine whether the given answer correctly answers the question based on the reference text. Here is the data: [BEGIN DATA] ************ [QUESTION]: {input} ************ [REFERENCE]: {reference} ************ [ANSWER]: {output} [END DATA] Your response should be a single word, either "correct" or "incorrect", and should not contain any text or characters aside from that word. "correct" means that the question is correctly and fully answered by the answer. "incorrect" means that the question is not correctly or only partially answered by the answer.
Metrics and iteration
Running the eval across your golden dataset allows you to generate key metrics such as accuracy, precision, recall, and F1-score. These provide insight into the evaluation template’s effectiveness and highlight areas for improvement. Iteration is crucial; refining the template based on these metrics ensures the evaluation process remains aligned with the application’s goals without overfitting to the golden dataset.
In task evaluations, relying solely on overall accuracy is insufficient since we always expect significant class imbalance. Precision and recall offer a more robust view of the LLM’s performance, emphasizing the importance of identifying both relevant and irrelevant outcomes accurately. A balanced approach to metrics ensures that evaluations meaningfully contribute to enhancing the LLM application.
Application of LLM evaluations
Once an evaluation framework is in place, the next step is to apply these evaluations directly to your LLM application. This involves integrating the evaluation process into the application’s workflow, allowing for real-time assessment of the LLM’s responses to user inputs. This continuous feedback loop is invaluable for maintaining and improving the application’s relevance and accuracy over time.
Evaluation across the system lifecycle
Effective task evaluations are not confined to a single stage but are integral throughout the LLM system’s life cycle. From pre-production benchmarking and testing to ongoing performance assessments in production, LLM evaluation ensures the system remains responsive to user need.
Example: is the model hallucinating?
Let’s look at a hallucination example in more detail.
Example by author
Since hallucinations are a common problem for most practitioners, there are some benchmark datasets available. These are a great first step, but you will often need to have a customized dataset within your company.
The next important step is to develop the prompt template. Here again a good library can help you get started. We saw an example prompt template earlier, here we see another specifically for hallucinations. You may need to tweak it for your purposes.
In this task, you will be presented with a query, a reference text and an answer. The answer is generated to the question based on the reference text. The answer may contain false information, you must use the reference text to determine if the answer to the question contains false information, if the answer is a hallucination of facts. Your objective is to determine whether the reference text contains factual information and is not a hallucination. A 'hallucination' in this context refers to an answer that is not based on the reference text or assumes information that is not available in the reference text. Your response should be a single word: either "factual" or "hallucinated", and it should not include any other text or characters. "hallucinated" indicates that the answer provides factually inaccurate information to the query based on the reference text. "factual" indicates that the answer to the question is correct relative to the reference text, and does not contain made up information. Please read the query and reference text carefully before determining your response.
Is the answer above factual or hallucinated based on the query and reference text?
Your response should be a single word: either "factual" or "hallucinated", and it should not include any other text or characters. "hallucinated" indicates that the answer provides factually inaccurate information to the query based on the reference text. "factual" indicates that the answer to the question is correct relative to the reference text, and does not contain made up information. Please read the query and reference text carefully before determining your response.
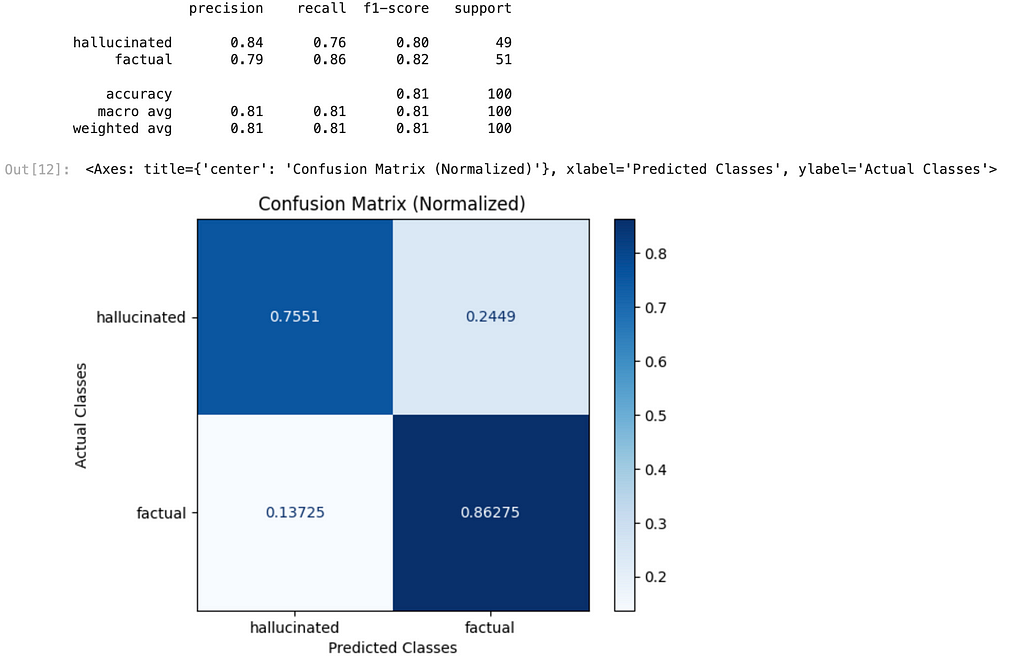
Now you are ready to give your eval LLM the queries from your golden dataset and have it label hallucinations. When you look at the results, remember that there should be class imbalance. You want to track precision and recall instead of overall accuracy.
It is very useful to construct a confusion matrix and plot it visually. When you have such a plot, you can feel reassurance about your LLM’s performance. If the performance is not to your satisfaction, you can always optimize the prompt template.
Example of evaluating performance of the task eval so users can build confidence in their evals
After the eval is built, you now have a powerful tool that can label all your data with known precision and recall. You can use it to track hallucinations in your system both during development and production phases.
Summary of Differences
Let’s sum up the differences between task and model evaluations.
Table by author
Takeaways
Ultimately, both model evaluations and task evaluations are important in putting together a functional LLM system. It is important to understand when and how to apply each. For most practitioners, the majority of their time will be spent on task evals, which provide a measure of system performance on a specific task.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.