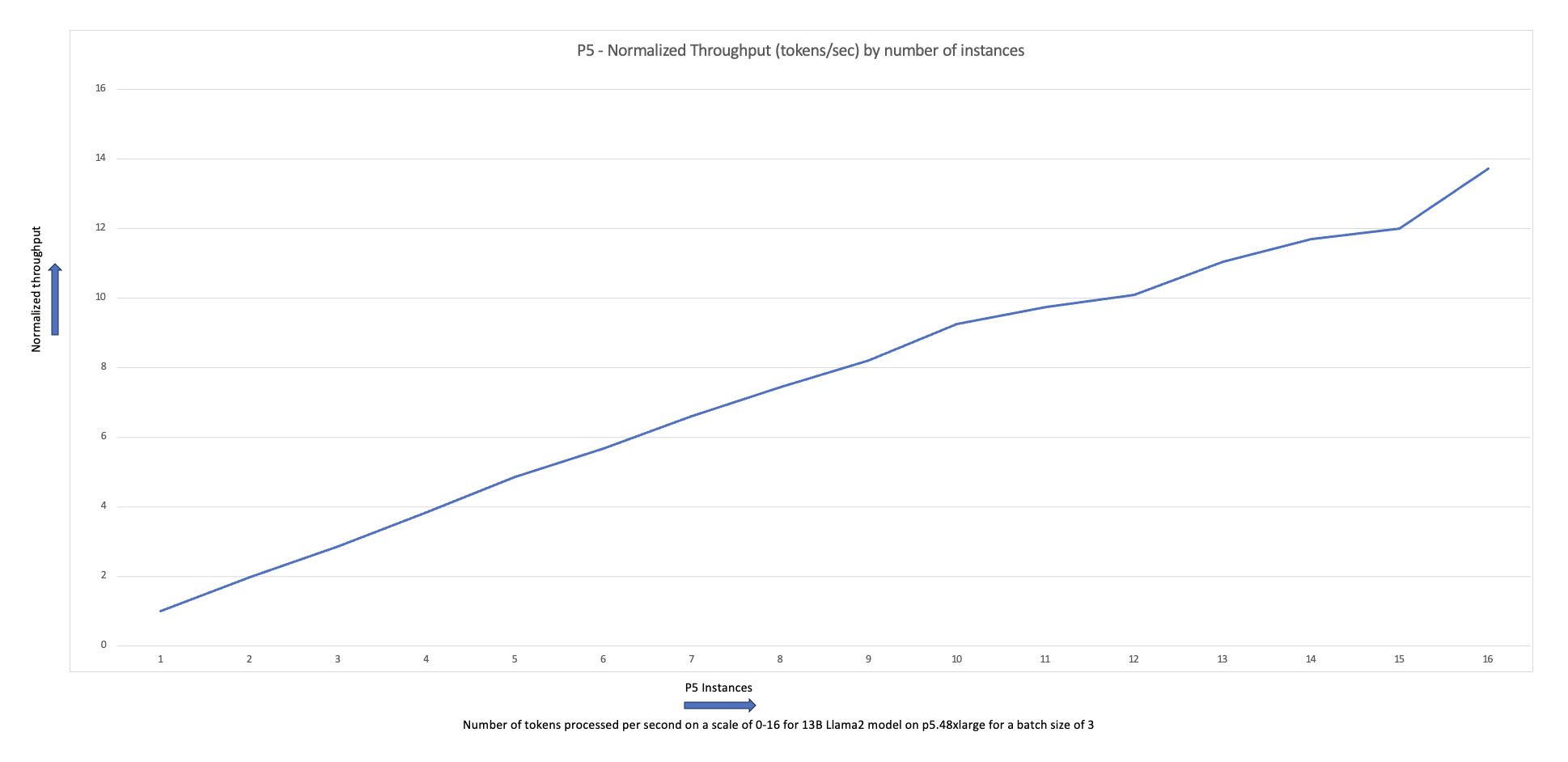
This is a guest post co-written with Meta’s PyTorch team and is a continuation of Part 1 of this series, where we demonstrate the performance and ease of running PyTorch 2.0 on AWS. Machine learning (ML) research has proven that large language models (LLMs) trained with significantly large datasets result in better model quality. In […]
Copyright law in America is a complicated thing. Those of us who are not lawyers understandably find it difficult to suss out what it really means, and what it does and doesn’t protect. Data scientists don’t spend a lot of time thinking about copyright, unless we’re choosing a license for our open source projects. Even then, sometimes we just skip past that bit and don’t really deal with it, even though we know we should. But the legal world is starting to take a close look at how copyright intersects with generative AI, and this could have a real impact on our work. Before we talk about how it is affecting the world of generative AI, let’s recap the truth of copyright.
Copyright
US copyright law is relevant to what are called “original works of authorship”. This includes things under these categories: literary; musical; dramatic; pantomimes and choreographic work; pictorial, graphic, and sculptural works; audio-visual works; sound recordings; derivative works; compilations; architectural works.
Content must be written or documented to be copyrightable. “Ideas are not copyrightable. Only tangible forms of expression (e.g., a book, play, drawing, film, or photo, etc.) are copyrightable. Once you express your idea in a fixed form — as a digital painting, recorded song, or even scribbled on a napkin — it is automatically copyrighted if it is an original work of authorship.” — Electronic Frontier Foundation
Being protected means that only the copyright holder (the author or creator, descendants inheriting the rights, or purchaser of the rights) can do these things: make and sell copies of the works, create derivative works from the originals, and perform or display the works publicly.
Copyright isn’t forever, and it ends after a certain amount of time has elapsed. Usually, this is 70 years after the author’s death or 95 years after publication of the content. (Anything from before 1929 in the US is generally in the “public domain”, which means it is no longer covered by copyright.)
Why does copyright exist at all? Recent legal interpretations argue that the whole point is not to just let creators get rich, but to encourage creation so that we have a society containing art and cultural creativity. Basically we exchange money with creators so they are incentivized to create great things for us to have. This means that a lot of courts look at copyright cases and ask, “Is this copy conducive to a creative, artistic, innovative society?” and take that into consideration when making judgments as well.
Fair Use
In addition, “fair use” is not a free pass to ignore copyright. There are four tests to decide if a use of content is “fair use”:
The purpose and character of the second use: Are you doing something innovative and different with the content, or are you just replicating the original? Is your new thing innovative on its own? If so, it’s more likely to be fair use. Also, if your use is to make money, that is less likely to be fair use.
The nature of the original: If the original is creative, it’s harder to break copyright with fair use. If it’s just facts, then you’re more likely to be able to apply fair use (think of quoting research articles or encyclopedias).
Amount used: Are you copying the whole thing? Or just, say, a paragraph or a small section? Using as little as is necessary is important for fair use, although sometimes you may need to use a lot for your derivative work.
Effect: Are you stealing customers from the original? Are people going to buy or use your copy instead of buying the original? Is the creator going to lose money or market share because of your copy? If so, it’s likely not fair use. (This is relevant even if you don’t make any money.)
You have to meet ALL of these tests to get to be fair use, not just one or two. All of this is, of course, subject to legal interpretation. (This article is NOT legal advice!) But now, with these facts in our pocket, let’s think about what Generative AI does and why the concepts above are crashing into Generative AI.
Generative AI Recap
Regular readers of my column will have a pretty clear understanding of how generative AI is trained already, but let’s do a very quick recap.
Giant volumes of data are collected, and a model learns by analyzing the patterns that exist in that data. (As I’ve written before: “Some reports indicate that GPT-4 had on the order of 1 trillion words in its training data. Every one of those words was written by a person, out of their own creative capability. For context, book 1 in the Game of Thrones series was about 292,727 words. So, the training data for GPT-4 was about 3,416,152 copies of that book long.”)
When the model has learned the patterns in the data (for an LLM, it learns all about language semantics, grammar, vocabulary, and idioms), then it will be fine tuned by human, so that it will behave as desired when people interact with it. These patterns in the data may be so specific that some scholars argue the model can “memorize” the training data.
The model will then be able to answer prompts from users reflecting the patterns it has learned (for an LLM, answering questions in very convincing human-sounding language).
There important implications for copyright law in both the inputs (training data) and outputs of these models, so let’s take a closer look.
Training Data and Model Output
Training data is vital to creating generative AI models. The objective is to teach a model to replicate human creativity, so the model needs to see huge volumes of works of human creativity in order to learn what that looks/sounds like. But, as we learned earlier, works that humans create belong to those humans (even if they are jotted down on a napkin). Paying every creator for the rights to their work is financially infeasible for the volumes of data we need to train even a small generative AI model. So, is it fair use for us to feed other people’s work into a training data set and create generative AI models? Let’s go over the Fair Use tests and see where we land.
The purpose and character of the second use
We could argue that using data to train the model doesn’t really count as creating a derivative work. For example, is this different from teaching a child using a book or a piece of music? The counter arguments are first, that teaching one child is not the same as using millions of books to generate a product for profit, and second, that generative AI is so keenly able to reproduce content that it’s trained on, that it’s basically a big fancy tool for copying work almost verbatim. Is the result of generative AI sometimes innovative and totally different from the inputs? If it is, that’s probably because of very creative prompt engineering, but does that mean the underlying tool is legal?
Philosophically, however, machine learning is trying to reproduce the patterns it has learned from its training data as accurately and precisely as possible. Are the patterns it learns from original works the same as the “heart” of the original works?
2. The nature of the original
This varies widely across the different kinds of generative AI that exist, but because of the sheer volumes of data required to train any model, it seems likely that at least some of it would fit the legal criteria for creativity. In many cases, the whole reason for using human content as training data is to try and get innovative (highly diverse) inputs into the model. Unless someone’s going to go through the entire 1 trillion words for GPT-4 and decide which ones were or weren’t creative, I think this criteria is not met for fair use.
3. Amount used
This is kind of a similar issue to #2. Because, almost by definition generative AI training datasets use everything they can get their hands on, and the volume needs to be huge and comprehensive; there’s not really a “minimal necessary” amount of content.
4. Effect
Finally, the effect issue is a big sticking point for generative AI. I think we all know people who use ChatGPT or similar tools from time to time instead of searching for the answer to a question in an encyclopedia or newspaper. There is strong evidence that people use services like Dall-E to request visual works “in the style of [Artist Name Here]” despite some apparent efforts from these services to stop that. If the question is whether people will use the generative AI instead of paying the original creator, it certainly seems like that is happening in some sectors. And we can see that companies like Microsoft, Google, Meta, and OpenAI are making billions in valuation and revenue from generative AI, so they’re definitely not going to get an easy pass on this one.
Copying as a Concept in Computing
I’d like to stop for a moment to talk about a tangential but important issue. Copyright law is not well equipped to handle computing generally, particularly software and digital artifacts. Copyright law was mostly created in an earlier world, where duplicating a vinyl record or republishing a book was a specialized and expensive task. But today, when anything on any computer can basically be copied in seconds with a click of the mouse, the whole idea of copying things is different from how it used to be. Also, keep in mind that installing any software counts as making a copy. A digital copy means something different in our culture than the kinds of copying that we had before computers. There are significant lines of questioning around how copyright should work in the digital era, because a lot of it no longer seems quite relevant. Have you ever copied a bit of code from GitHub or StackOverflow? I certainly have! Did you carefully scrutinize the content license to make sure it was reproducible for your use case? You should, but did you?
New York Times v. OpenAI
Now that we have a general sense of the shape of this dilemma, how are creators and the law approaching the issue? I think the most interesting such case (there are many) is the one brought by the New York Times, because part of it gets at the meaning of copying in a way I think other cases fail to do.
As I mentioned above, the act of duplicating a digital file is so incredibly ubiquitous and normal that it’s hard to imagine enforcing that copying a digital file (at least, without the intent to distribute that exact file to the global public in violation of other fair use tests) is a copyright infringement. I think this is where our attention needs to fall for the generative AI question — not just duplication, but effect on the culture and the market.
Is generative AI actually making copies of content? E.g.,training data in, training data back out? The NYT has shown in its filings that you can get verbatim text of NYT articles out of ChatGPT, with very specific prompting. Because the NYT has a paywall, if this is true, it would seem to clearly violate the Effect test of Fair Use. So far, OpenAI’s response has been “well, you used many complicated prompts to ChatGPT to get those verbatim results”, which makes me wonder, is their argument that if the generative AI sometimes produces verbatim copies of content it was trained on, that’s not illegal? (Universal Music Group has filed a similar case related to music, arguing that the generative AI model Claude can reproduce lyrics to songs that are copyrighted nearly verbatim.)
We are asking the courts to decide exactly how much and what kind of use of a copyrighted material is acceptable, and that is going to be challenging in this context — I tend to believe that using data for training should not be inherently problematic, but that the important question is how the model gets used and what effect that has.
We tend to think of fair use as a single step, like quoting a paragraph in your article with citation. Our system has a body of legal thought that is well prepared for that scenario. But in generative AI, it’s more like two steps. To say that copyright is infringed, it seems to me that if the content gets used in training, it ALSO must be retrievable from the end model in a way that usurps the market for the original material. I don’t think you can separate out the quantity of input content used from the quantity that can be extracted verbatim as output. Is this actually true of ChatGPT, though? We are going to see what the courts think.
There’s another interesting angle to these questions, which is whether or not DMCA (the Digital Millennium Copyright Act) has relevance here. You may be familiar with this law because it’s been used for decades to force social media platforms to remove music and film files that were published without the authorization of the copyright holder. The law was based on the idea that you can kind of go “whac-a-mole” with copyright violators, and get content removed one piece at a time. However, when it comes to training data sets, this obviously won’t fly—you’d need to retrain the entire model, at exorbitant cost in the case of most generative AI, removing the offending file or files from the training data. You could still use DMCA, in theory, to force the output of an offending model to be removed from a site, but proving which model produced the item will be a challenge. But that doesn’t get at the underlying issue of input+output as both being key to the infringement as I have described it.
Questions of Power
If these behaviors are in fact violating copyright, the courts still have to decide what to do about it. Lots of people argue that generative AI is “too big to fail” in a manner of speaking — they can’t abolish the practices that got us here, because everyone loves ChatGPT, right? Generative AI (we are told) is going to revolutionize [insert sector here]!
While the question of whether copyright is violated still remains to be decided, I do feel like there should be consequences if it is. At what point do we stop forgiving powerful people and institutions who skirt the law or outright violate it, assuming it is easier to ask forgiveness than permission? It’s not entirely obvious. We would not have many innovations that we rely on today without some people behaving in this fashion, but that doesn’t necessarily mean it’s worth it. Is there a devaluation of the rule of law that comes from letting these situations pass by?
Like many listeners of 99% Invisible these days, I’m reading The Power Broker by Robert Caro. Hearing about how Robert Moses handled questions of law in New York at the turn of the 20th century is fascinating, because his style of handling zoning laws seems reminiscent of the way Uber handled laws around livery drivers in early 2010’s San Francisco, and the way large companies building generative AI are dealing with copyright now. Instead of abiding by laws, they have taken the attitude that legal strictures don’t apply to them because what they are building is so important and valuable.
I’m just not convinced that’s true, however. Each case is distinctive in some ways, of course, but the concept that a powerful man can decide that what he thinks is a good idea is inevitably more important than what anyone else thinks rubs me the wrong way. Generative AI may be useful, but to argue that it is more important than having a culturally vibrant and creative society seems disingenuous. The courts still have to decide whether generative AI is having a chilling effect on artists and creators, but the court cases being brought by those creators are arguing that it is.
The Future
The US Copyright Office is not ignoring these challenging problems, although they may be a little late to the party, but they have put out a recent blog post talking about their plans for content related to generative AI. However, it’s very short on specifics and only tells us that reports are forthcoming in the future. The three areas this department’s work is going to focus on are:
“digital replicas”: basically deepfakes and digital twins of people (think stunt doubles and actors having to get scanned at work so they can be mimicked digitally)
“copyrightability of works incorporating AI-generated material”
“training AI models on copyrighted works”
These are all important topics, and I hope the results will be thoughtful. (I’ll write about them once these reports come out.) I hope the policymakers engaged in this work will be well informed and technically skilled, because it could be very easy for a bureaucrat to make this whole situation worse with ill-advised new rules.
Another future possibility is that ethical datasets will be developed for training. This is something already being done by some folks at HuggingFace in the form of a code dataset called The Stack. Could we do this sort of thing for other forms of content?
Conclusion
Regardless of what the government or industry comes up with, however, the courts are proceeding to decide this problem. What happens if one of the cases in the courts is lost by the generative AI side?
It may at least mean that some of the money being produced by generative AI will be passed back to creators. I’m not terribly convinced that the whole idea of generative AI will disappear, although we did see the end of a lot of companies during the era of Napster. Courts could bankrupt companies producing generative AI, and/or ban the production of generative AI models — this is not impossible! I don’t think it’s the most likely outcome, however- instead, I think we’ll see some penalties and some fragmentation of the law around this (this model is ok, that model is not, and so on), which may or may not make the situation any clearer legally.
I would really like it if the courts take up the question of when and how a generative AI model should be considered infringing, not separating the input and output questions but examining them together as a single whole, because I think that is key to understanding the situation. If they do, we might be able to come up with legal frameworks that make sense for the new technology we are dealing with. If not, I fear we’ll end up further into a quagmire of laws woefully unprepared to guide our digital innovations. We need copyright law that makes more sense in the context of our digital world. But we also need to intelligently protect human art and science and creativity in various forms, and I don’t think AI-generated content is worth trading that away.
There are lots of tutorials on using powerful Large Language Models (LLMs) for knowledge retrieval. However, if considering real-world application of these techniques, engineering best practices need to be applied and these should be extended to mitigate some of the new risks associated with LLMs, such as hallucinations. In this article, we explore how to implement some key areas required for operationalizing LLMs — such as safety, prompt engineering, grounding, and evaluation — developing a simple Prompt Flow to create a simple demo AI assistant for answering questions about humanitarian disasters using information from situation reports on the ReliefWeb platform. Prompt Flow includes a great set of tools for orchestrating LLM workflows, and packages such as deep eval provide ways to test outputs on the fly using LLMs (albeit with some caveats).
Operationalizing Large Language Model Applications
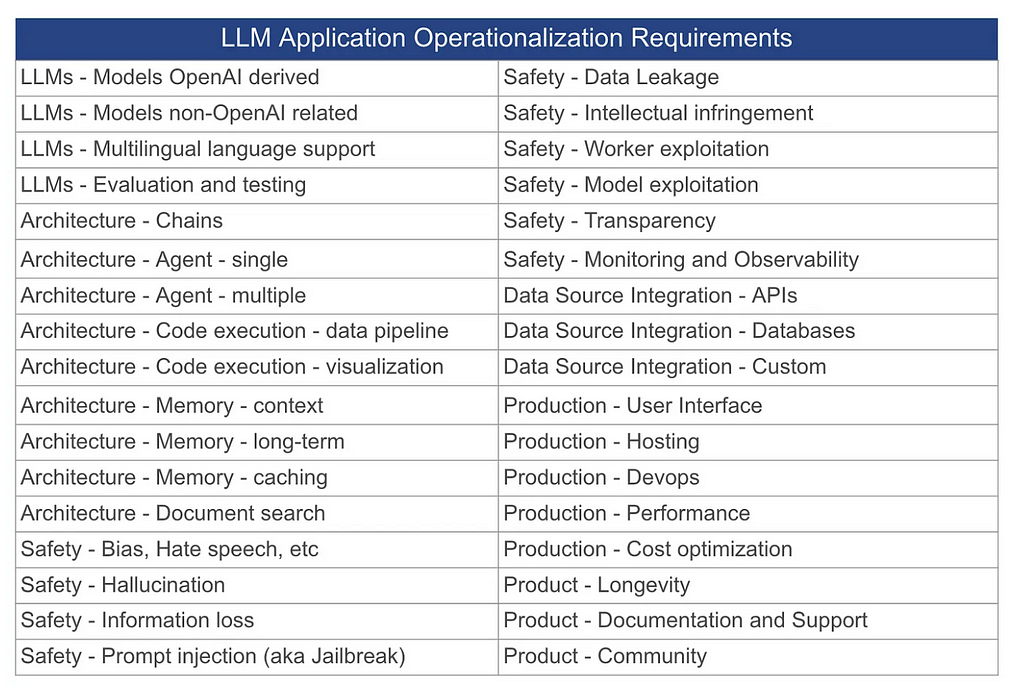
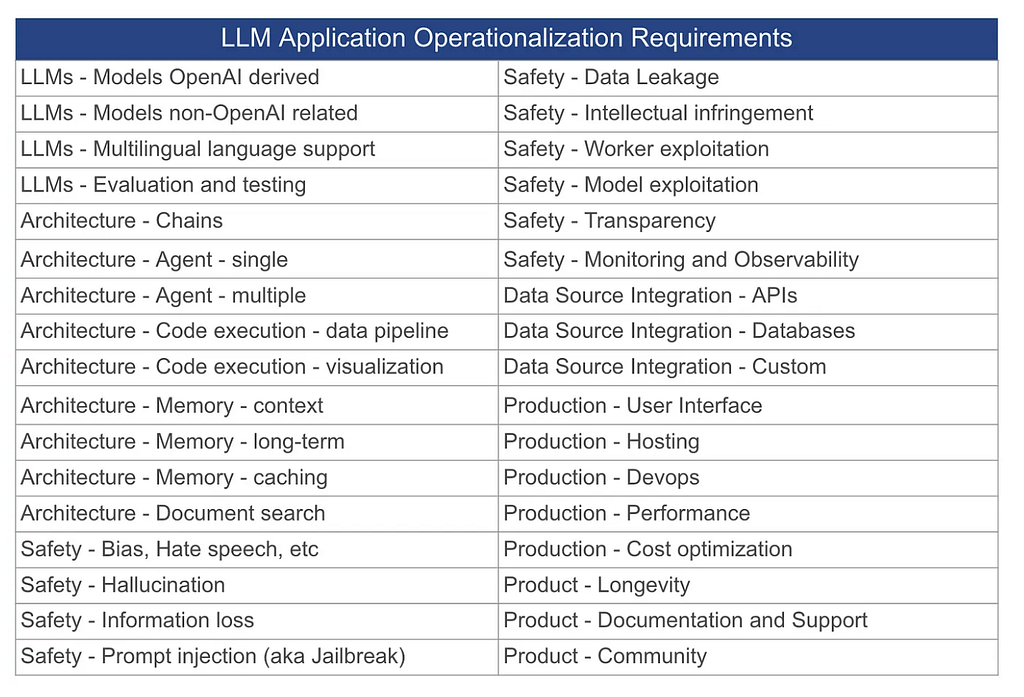
In a previous blog post “Some thoughts on operationalizing LLM Applications”, we discussed that when launching LLM applications there are a wide range of factors to consider beyond the shiny new technology of generative AI. Many of the engineering requirements apply to any software development, such as DevOps and having a solid framework to monitor and evaluate performance, but other areas such as mitigating hallucination risk are fairly new. Any organization launching a fancy new generative AI application ignores these at their peril, especially in high-risk contexts where biased, incorrect, and missing information could have very damaging outcomes.
Some of the key areas that should be considered before launching applications that use Large Language Models (LLMs). Source: Some thoughts on operationalizing LLMs
Many organizations are going through this operatiuonalizing process right now and are trying to figure out how exactly to use new Generative AI. The good news is that we are in a phase where supporting products and services are beginning to make it a lot easier to apply solid principles for making applications safe, cost-effective, and accurate. AWS Bedrock, Azure Machine Learning and Studio, Azure AI Studio (preview), and a wide range of other vendor and open source products all make it easier to develop LLM solutions.
Prompt Flow
In this article, we will focus on using Prompt Flow, an open-source project developed by Microsoft …
Prompt Flow is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, and evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.
Why Prompt Flow?
After quite a bit of personal research, Prompt Flow has emerged as a great way to develop LLM applications in some situations because of the following …
Intuitive user interface. As we shall see below, even simple LLM applications require complicated workflows. Prompt Flow offers a nice development user interface, making it easier to visualize flows, with built-in evaluation and strong integration with Visual Studio Code supported by solid supporting documentation.
Open source. This is useful in situations where applications are being shipped to organizations with different infrastructure requirements. As we shall see below, Prompt Flow isn’t tied to any specific cloud vendor (even though it was developed by Microsoft) and can be deployed in several ways.
Enterprise support in Azure. Though open source, if you are on Azure, Prompt Flow is natively supported and provides a wide range of enterprise-grade features. Being part of Azure Machine Learning Studio and the preview Azure AI studio, it comes with off-the-shelf-integration for safety, observability, and deployment, freeing up time to focus on the business use case
Easy deployment. As mentioned above, deployment on Azure is a few clicks. But even if you are running locally or another cloud vendor, Prompt flow supports deployment using Docker
It may not be ideal for all situations of course, but if you want the best of both worlds — open source and enterprise support in Azure — then Prompt Flow might be for you.
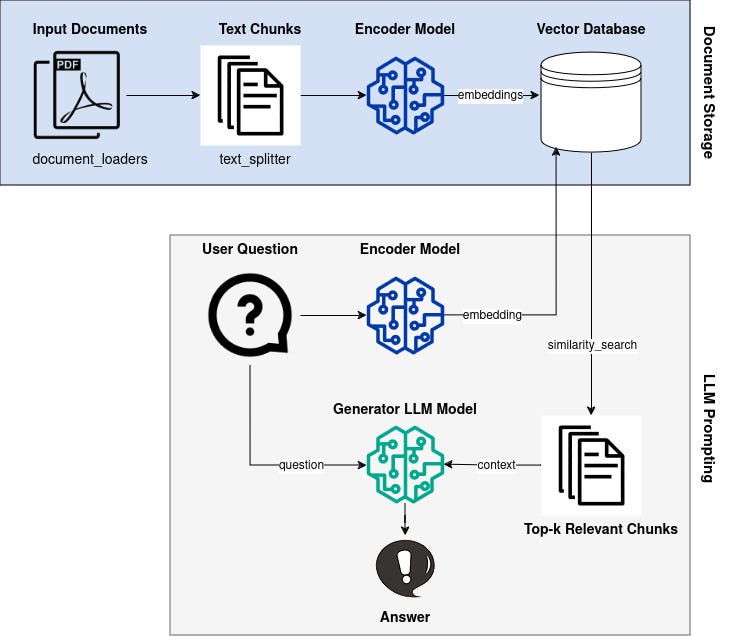
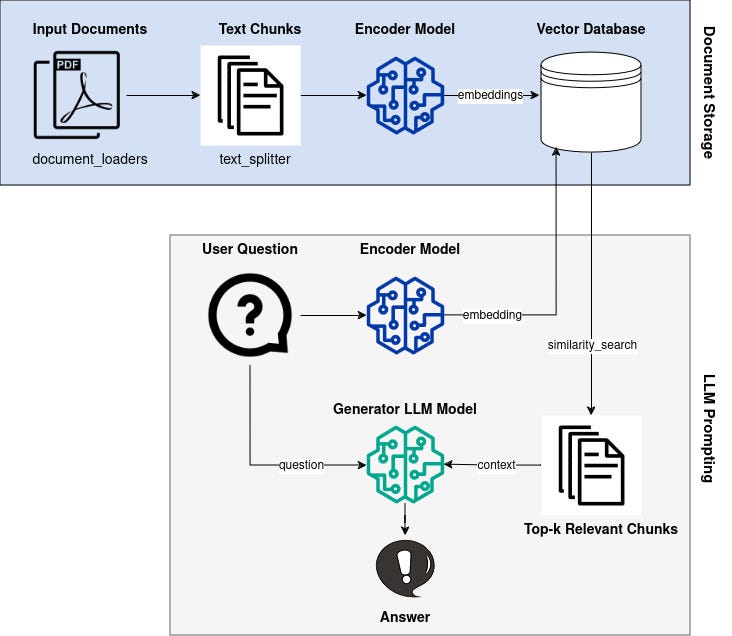
An AI assistant to answer questions about active humanitarian disasters
In this article we will develop an AI assistant with Prompt Flow that can answer questions using information contained in humanitarian reports on the amazing ReliefWeb platform. ReliefWeb includes content submitted by humanitarian organizations which provide information about what is happening on the ground for disasters around the world, a common format being ‘Situation Reports’. There can be a lot of content so being able to extract a key piece of required information quickly is less effort than reading through each report one by one.
Please note: Code for this article can be found here, but it should be mentioned that it is a basic example and only meant to demonstrate some key concepts for operationalizing LLMs. For it to be used in production more work would be required around integration and querying of ReliefWeb, as well as including the analysis of PDF documents rather than just their HTML summaries, but hopefully the code provides some examples people may find useful.
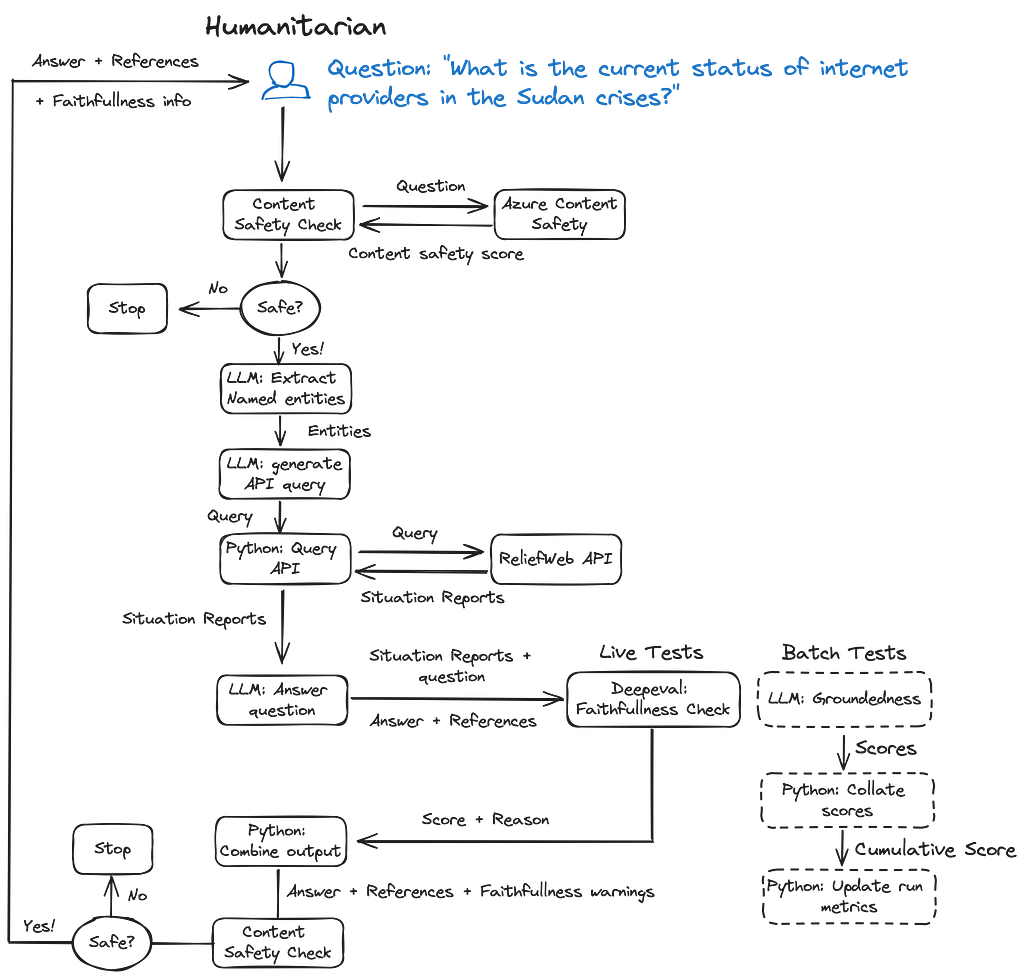
Process flow used in this article — A demonstration AI agent for answering questions about humanitarian disasters using information from situation reports on ReliefWeb. The full code can be found here.
The demo application has been set up to demonstrate the following …
Content safety monitoring
Orchestrating LLM tasks
Automated self-checking for factual accuracy and coverage
Batch testing of groundedness
Self-testing using Prompt Flow run in GitHub actions
Deployment
Setup of the demo Prompt Flow application
The demo application for this article comes with a requirements.txt and runs with Python 3.11.4 should you want to install it in your existing environment, otherwise please see the setup steps below.
4. You will need LLM API Keys from either OpenAI or Azure OpenAI, as well as the deployment names of the models you want to use
5. Check out the application repo which includes the Prompt Flow app in this article
6. In your repo’s top folder, copy.env.example to .env and set the API keys in that file
7. Set up an environment at the command line, open a terminal, and in the repo top directory run: conda env create -f environment.yml. This will build a conda environment called pf-rweb-demo
8. Open VS Code
9. Open the repo with File > Open Folder and select the repo’s top directory
10. In VS Code, click on the Prompt flow icon — it looks like a ‘P’ on the left-hand bar
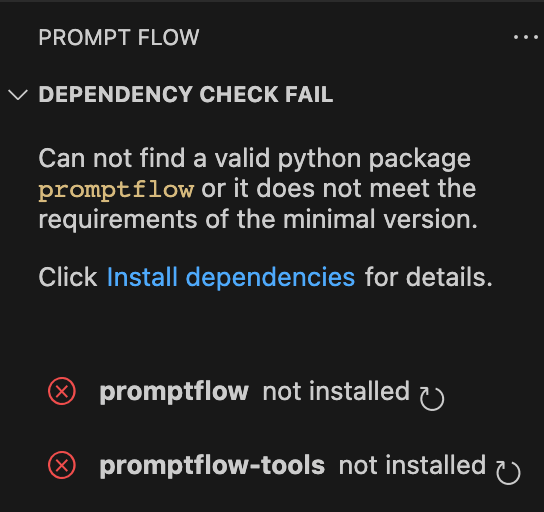
11. The first time you click on this, you should see on the upper-left, the message below, click on the ‘Install dependencies’ link
12. Click ‘Select Python Interpreter’ and choose the conda Python environment pf-rweb-demoyou built in step 7. Once you do this the libraries section should
13. You should now see a section called ‘Flows’ on the left-hand navigation, click on the ‘relief web_chat’ and select ‘Open’
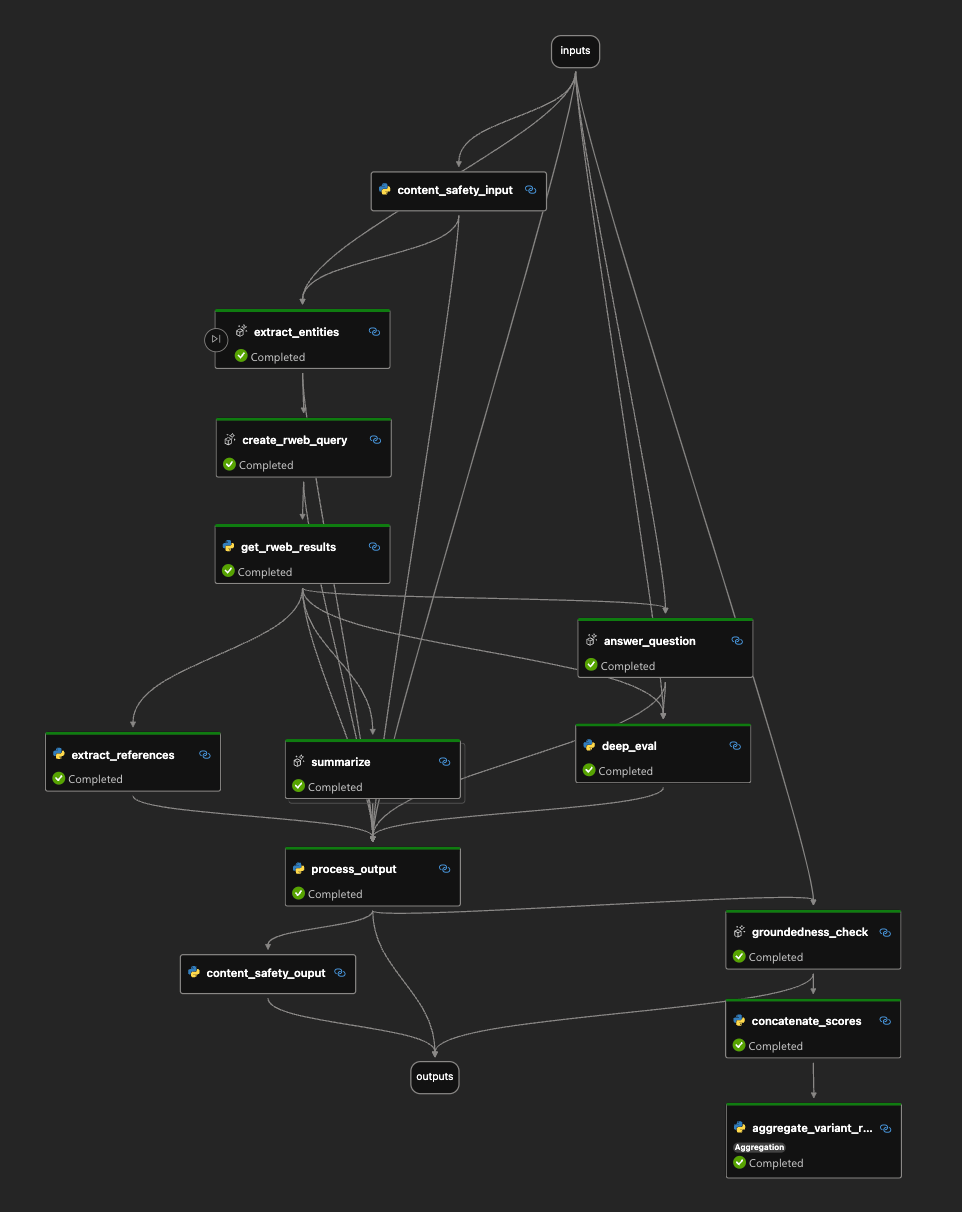
This should open the Prompt Flow user interface …
Prompt Flow user interface for the demo code for this article. The flow shows how to orchestrate stages in an LLM application
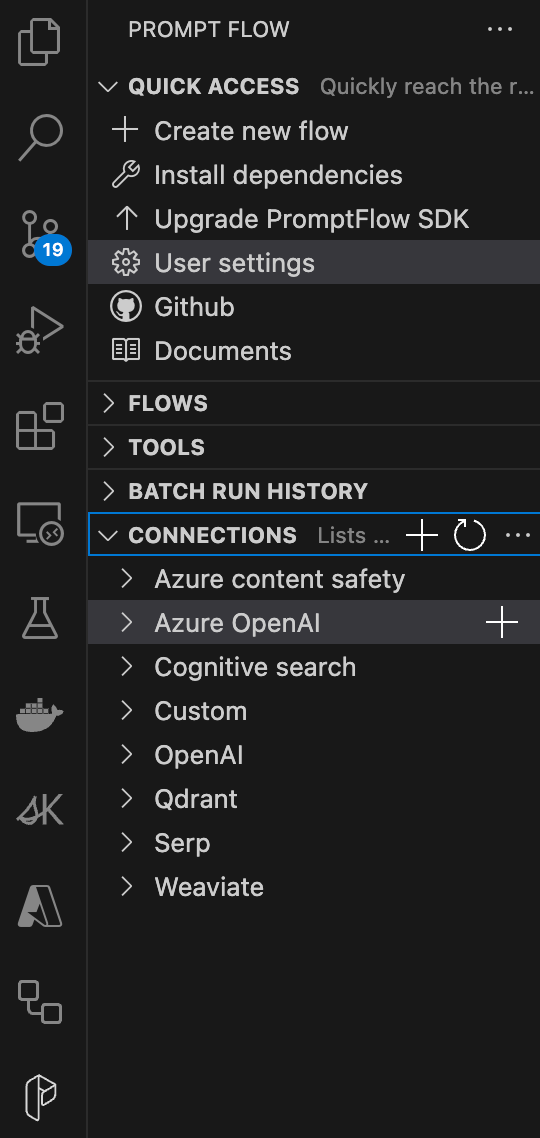
12. Click on the ‘P’ (Prompt Flow) in the left-hand vertical bar, you should see a section for connections
13. Click on the ‘+’ for either Azure OpenAI or OpenAI depending on which service you are using.
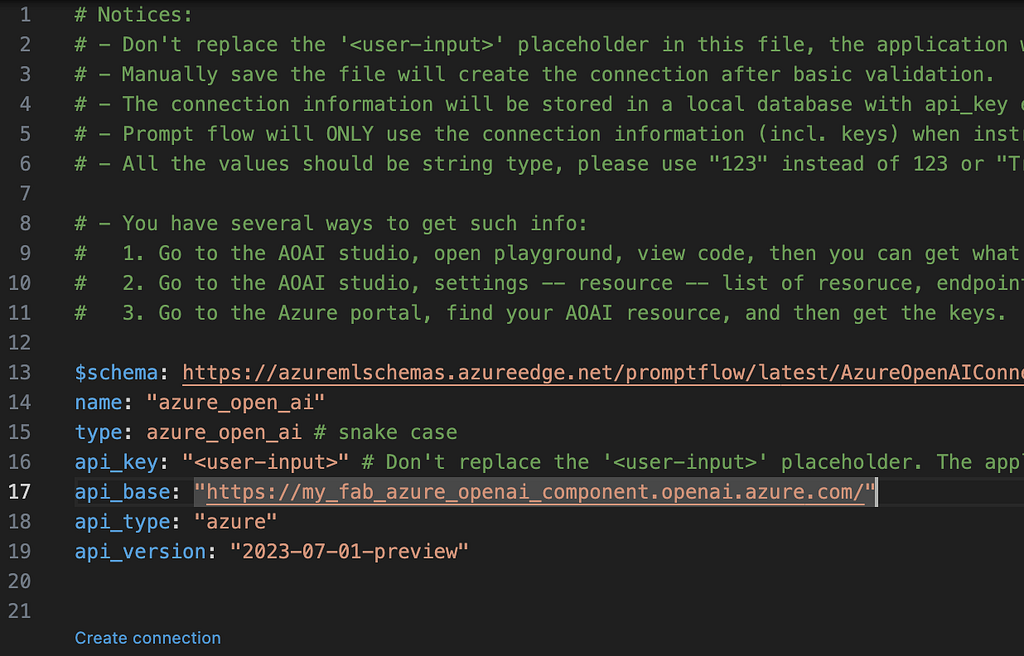
14. In the connection edit window, set the name to something reasonable, and if using Azure the fieldapi_base to your base URL. Don’t populate the api_key as you will get prompted for this.
15. Click the little ‘create connection’ and when prompted enter your API Key, your connection has now been created
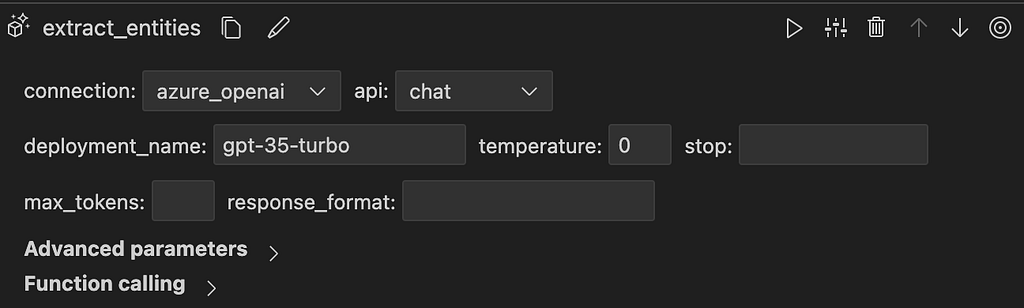
16. If you are using Azure and called your connection azure_openai and have model deployments ‘gpt-4-turbo’ and ‘got-35-turbo-16k’, you should be configured, otherwise, click on any LLM Nodes in the Prompt Flow user interface and set the connection and deployment name appropriately. See below for the settings used for ‘extract_entities’ LLM node
Running the demo Prompt Flow application
Now that you’re all set up, anytime you want to run the flow …
Open the flow as described in steps 9–11 above
Click on the little double-play icon at the top of the flow
This should run the full flow. To see the outputs you can click on any node and view inputs/outputs and even run individual nodes as part of debugging.
Now, let’s go through some of the main components of the application …
Content Safety
Any chat application using LLMs should have some tests to ensure user inputs and LLM outputs are safe. Safety checks should cover areas such as:
Bias
Hate speech / Toxicity
Self-harm
Violence
Prompt injection (hacking to get different prompt through to the LLM)
Intellectual property infringement
This list is not exhaustive and not all will be applicable, depending on the application context, but a review should always be carried out and appropriate safety tests identified.
Prompt Flow comes with integration to Azure content safety which covers some of the above and is very easy to implement by selecting ‘Content Safety’ when creating a new node in the flow. I originally configured the demo application to use this, but realized not everybody will have Azure so instead the flow includes two Python placeholder nodes content_safety_in and content_safety_out to illustrate where content safety checks could be applied. These do not implement actual safety validation in the demo application, but libraries such as Guardrails AI and deep eval offer a range of tests that could be used in these scripts.
The content_safety_innode controls the downstream flow, and will not call those tasks if the content is considered unsafe.
Given the LLM output is heavily grounded in provided data and evaluated on the fly, it’s probably overkill to include a safety check on the output for this application, but it illustrates that there are two points safety could be enforced in an LLM application.
It should also be noted that Azure also provides safety filters at the LLM level if using Azure Model Library. This can be a convenient way to implement content safety without having to develop code or specify nodes in your flow, clicking a button and paying a little extra for a safety service can sometimes be the better option.
Entity Extraction
In order to query the ReliefWeb API it is useful to extract entities from the user’s question and search with those rather than the raw input. Depending on the remote API this can yield more appropriate situation reports for finding answers.
An example in the demo application is as follows …
User input: “How many children are affected by the Sudan crises?”
This is a very basic entity extraction as we are only interested in a simple search query that will return results in the ReliefWeb API. The API supports more complex filtering and entity extraction could be extended accordingly. Other Named Entity Recognition techniques like GLiNER may improve performance.
Getting data from the ReliefWeb API
Once a query string is generated, a call to the ReliefWeb API can be made. For the demo application we restrict the results to the top 5 most recent situation reports, where Python code creates the following API request …
One thing to note about calling APIs is that they can incur costs if API results are processed directly by the LLM. I’ve written a little about this here, but for small amounts of data, the above approach should suffice.
Summarization
Though the focus of the demo application is on answering a specific question, a summary node has been included in the flow to illustrate the possibility of having the LLM perform more than one task. This is where Prompt Flow works well, in orchestrating complex multi-task processes.
LLM summarization is an active research field and poses some interesting challenges. Any summarization will lose information from the original document, this is expected. However, controlling which information is excluded is important and will be specific to requirements. When summarizing a ReliefWeb situation report, it may be important in one scenario to ensure all metrics associated with refugee migration are accurately represented. Other scenarios might require that information related to infrastructure is the focus. The point being that a summarization prompt may need to be tailored to the audience’s requirements. If this is not the case, there are some useful general summarization prompts such as Chain of Density (CoD) which aim to capture pertinent information.
The demo app has two summarization prompts, a very basic one …
system:
You are a humanitarian researcher who needs produces accurate and consise summaries of latest news
========= TEXT BEGIN =========
{{text}}
========= TEXT END =========
Using the output from reliefweb above, write a summary of the article. Be sure to capture any numerical data, and the main points of the article. Be sure to capture any organizations or people mentioned in the article.
You are an expert in writing rich and dense summaries in broad domains.
You will generate increasingly concise, entity-dense summaries of the above JSON list of data extracted.
Repeat the following 2 steps 5 times.
- Step 1: Identify 1-3 informative Entities from the Article which are missing from the previously generated summary and are the most relevant.
- Step 2: Write a new, denser summary of identical length which covers every entity and detail from the previous summary plus the missing entities
A Missing Entity is:
- Relevant: to the main story - Specific: descriptive yet concise (5 words or fewer) - Novel: not in the previous summary - Faithful: present in the Article - Anywhere: located anywhere in the Article
Guidelines: - The first summary should be long (5 paragraphs) yet highly non-specific, containing little information beyond the entities marked as missing.
- Use overly verbose language and fillers (e.g. "this article discusses") to reach approx.
- Make every word count: re-write the previous summary to improve flow and make space for additional entities.
- Make space with fusion, compression, and removal of uninformative phrases like "the article discusses"
- The summaries should become highly dense and concise yet self-contained, e.g., easily understood without the Article.
- Missing entities can appear anywhere in the new summary.
- Never drop entities from the previous summary. If space cannot be made, add fewer new entities.
> Remember to use the exact same number of words for each summary. Answer in JSON.
> The JSON in `summaries_per_step` should be a list (length 5) of dictionaries whose keys are "missing_entities" and "denser_summary".
Question Answering
The demo app contains a node to answer the user’s original question. For this we used a prompt as follows:
system: You are a helpful assistant. Using the output from a query to reliefweb, anser the user's question. You always provide your sources when answering a question, providing the report name, link and quote the relevant information.
{{reliefweb_data}}
{% for item in chat_history %} user: {{item.inputs.question}} assistant: {{item.outputs.answer}} {% endfor %}
user: {{question}}
This is a basic prompt which includes a request to include references and links with any answer.
Attribution of Informational Sources
Even with validation and automatic fact-checking of LLM outputs, it is very important to provide attribution links to data sources used so the human can check themselves. In some cases it may still be useful to provide an uncertain answer — clearly informing the user about the uncertainty — as long as there is an information trail to the sources for further human validation.
In our example this means links to the situation reports which were used to answer the user’s question. This allows the person asking the question to jump to the sources and check facts themselves, as well as read additional context. In the demo app we have included two attribution methodologies. The first is to include a request in the prompt, as shown above. As with any LLM output this can of course result in hallucination, but as we’ll see below these can be validated.
The second method is to simply collate a list of documents returned in the API call, being all the sources reviewed even if some weren’t used in the answer. Being able to view the full list can help identify cases where a key report was perhaps missed due to how the API was queried.
Both attribution methods can be useful to the user in understanding how their answer was found.
Automatic Fact Checking
LLM information extraction, though amazing, is imperfect. Hallucinations and information omission are possible in situations where questions are asked of content. Therefore it’s key to validate the answer to ensure it isn’t presenting incorrect or incomplete information. Since we are essentially comparing one text (raw data returned from the API) with LLM-generated text (the question answer), we can also use LLMs to validate. With good prompt design these can be made to work well, if not absolutely perfectly.
In the demo app we have include two methods for this to illustrate …
Real-time fact checking
One useful library for checking LLM-generated output against the source data is deep eval, which offers a wide range of tests for LLM generated output. In our example we have implemented a faithfulness check to compare the answer with raw API output and give a score between 0–1 and reason for that score, where 1 is the best score possible. In the demo app, even if the score is less than 1 we have opted to allow the answer to be presented to the user, along with a warning and reasons, about the score being less than perfect.
Here is an example answer showing the warning for a run asking the question “What is the current status of internet providers in the Sudan crises?” where we adjusted the answer intentionally to say the effects were minor instead of the true major communications outage mentioned in the source data …
The current status of internet providers in Sudan, as reported in the “Sudan, conflict — ETC Situation Report #15 Reporting period: 01/02/2024 to 29/02/2024” by the Emergency Telecommunications Cluster (ETC) led by the World Food Programme (WFP), indicates that there have been only minor disruptions to telecommunications infrastructure due to the conflict between the Sudanese Armed Forces (SAF) and the Rapid Support Forces (RSF). Here is the relevant excerpt from the report:
“All three of Sudan’s main internet operators were reported as offline on 07 February in the latest of a minor network blackout of communications affecting millions of people.”
This information suggests that as of the reporting period, there was a minor network blackout, and the main internet operators in Sudan were offline, which would have a minor impact on communication and response efforts within the country.
Warning! Fact checker evaluation returned a score of 0.88/1.0
Reason:
The score is 0.88 because the actual output incorrectly downplays the extent of the damage to telecommunications infrastructure in Sudan, suggesting only minor disruptions, whereas the retrieval context indicates there was widespread damage to telecommunications infrastructure and the national power grid.
Note the Warning section at the end and the associated Reason.
It should however be noted, that though deep eval offers a neat way to evaluate LLMs, since it uses an LLM it too could sometimes suffer from hallucination. For the demo application performance was acceptable in re-running the same question 20 times, but for production, it would make sense to include self-tests to evaluate the evaluation (!) and ensure behavior is as expected.
Batch Groundedness testing
Another approach supported by Prompt Flow is the ability to create a test file with inputs and context information, which can be executed in a prompt flow batch run. This is analogous to software self-tests, with a twist that in evaluating LLMs where responses can vary slightly each time, it’s useful to use LLMs in the tests also. In the demo app, there is a groundedness test that does exactly this for batch runs, where the outputs of all tests are collated and summarized so that performance can be tracked over time.
We have included batch test nodes in the demo app for demonstration purposes, but in the live applications, they wouldn’t be required and could be removed for improved performance.
Finally, it’s worth noting that although we can implement strategies to mitigate LLM-related issues, any software can have bugs. If the data being returned from the API doesn’t contain the required information to begin with, no amount of LLM magic will find the answer. For example, the data returned from ReliefWeb is heavily influenced by the search engine so if the best search terms aren’t used, important reports may not be included in the raw data. LLM fact-checking cannot control for this, so it’s important not to forget good old-fashioned self-tests and integration tests.
LLMOps
Now that we have batch tests in Prompt Flow, we can use these as part of our DevOps, or LLMOps, process. The demo app repo contains a set of GitHub actions that run the tests automatically, and check the aggregated results to automatically confirm if the app is performing as expected. This confirmation could be used to control whether the application is deployed or not.
Deployment
Which brings us onto deployment. Prompt Flow offers easy ways to deploy, which is a really great feature which may save time so more effort can be put into addressing the user’s requirements.
The ‘Build’ option will suggest two options ‘Build as local app’ and ‘Build as Docker’.
The first is quite useful and will launch a chat interface, but it’s only meant for testing and not production. The second will build a Docker container, to present an API app running the flow. This container could be deployed on platforms supporting docker and used in conjunction with a front-end chat interface such as Streamline, chainlit, Copilot Studio, etc. If deploying using Docker, then observability for how your app is used — a must for ensuring AI safety — needs to be configured on the service hosting the Docker container.
For those using Azure, the flow can be imported to Azure Machine Learning, where it can be managed as in VS Code. One additional feature here is that it can be deployed as an API with the click of a button. This is a great option because the deployment can be configured to include detailed observability and safety monitoring with very little effort, albeit with some cost.
Final Thoughts
We have carried out a quick exploration of how to implement some important concepts required when operationalizing LLMs: content safety, fact checking (real-time and batch), fact attribution, prompt engineering, and DevOps. These were implemented using Prompt Flow, a powerful framework for developing LLM applications.
The demo application we used is only a demonstration, but it shows how complex simple tasks can quickly get when considering all aspects of productionizing LLM applications safely.
Caveats and Trade-offs
As with all things, there are trade-offs when implementing some of the items above. Adding safety tests and real-time evaluation will slow application response times and incur some extra costs. For me, this is an acceptable trade-off for ensuring solutions are safe and accurate.
Also, though the LLM evaluation techniques are a great step forward in making applications more trustworthy and safe, using LLMs for this is not infallible and will sometimes fail. This can be addressed with more engineering of the LLM output in the demo application, as well as advances in LLM capabilities — it’s still a relatively new field — but it’s worth mentioning here that application design should include evaluation of the evaluation techniques. For example, creating a set of self-tests with defined context and question answers and running those through the evaluation workflow to give confidence it will work as expected in a dynamic environment.
As we navigate through 2024, the rush to develop AI-powered applications is unmistakable, thanks to their clear benefits.
Traditionally, creating an app involves writing separate functions or services for each feature, like user login or booking a ticket. This process often requires users to fill out forms, ticking boxes and entering data, which must then pass through various validation checks to ensure that the data is usable. This method, especially when involving multiple steps, significantly detracts from the user experience.
Consider planning a one-day farm trip for Easter. You’re undecided about the date but have specific requirements: the farm must be within a two-hour drive, offer certain activities, have cloudy weather (as your child is allergic to the sun), and you need to consult your partner before making a decision. The traditional approach would involve navigating through multiple pages, steps, and forms — a snapshot of the complexities in daily decision-making. This complexity is a key reason why, despite the prevalence of booking websites, many still prefer the personalized service of a travel agent for planning trips.
What AI can do
AI introduces significant improvements by:
Providing a conversational experience, making interactions feel more natural and user-friendly.
Consolidating app features into a single entry point. Unlike traditional apps, where different pages and forms are needed for different functions, AI can interpret user inputs and seamlessly select and execute the necessary functions, even handling complex requests in a step-by-step manner.
However, a major challenge remains: dealing with the unstructured text data returned by AI models.
Traditionally, extracting structured data (like JSON) from model outputs required complex prompt engineering or regular expressions (RegEx), which can be error-prone and inconsistent due to the unpredictable nature of AI models and the variability of user inputs.
To address this, OpenAI has rolled out two innovative features: Json mode and Function calling. This article will delve into the Function calling feature, illustrating how it streamlines the extraction of structured data from model outputs, complemented by TypeScript code examples.
Discover all the code examples in this Github repository and consider giving it a star if you find it useful.
Current challenges
Structured Data Handling: Previously, developers relied on RegEx or intricate prompt engineering to parse text data, a process fraught with complexity and errors. Function Calling simplifies this by allowing models to process user-defined functions, generating structured outputs like JSON without the need for cumbersome techniques.
Consistency and Predictability: Function Calling ensures consistent and predictable outcomes from AI models by enabling the definition of custom functions for precise information extraction. This guarantees structured and reliable outputs across varied inputs, essential for applications requiring dependable data extraction for text summarization, document analysis, and integrations with external APIs or databases.
How it works
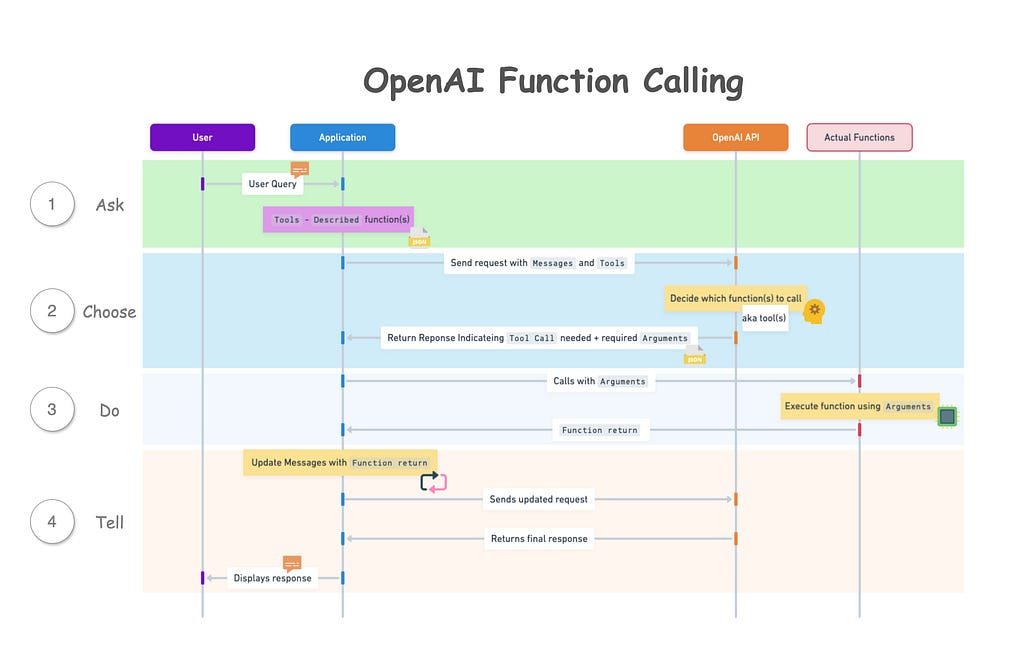
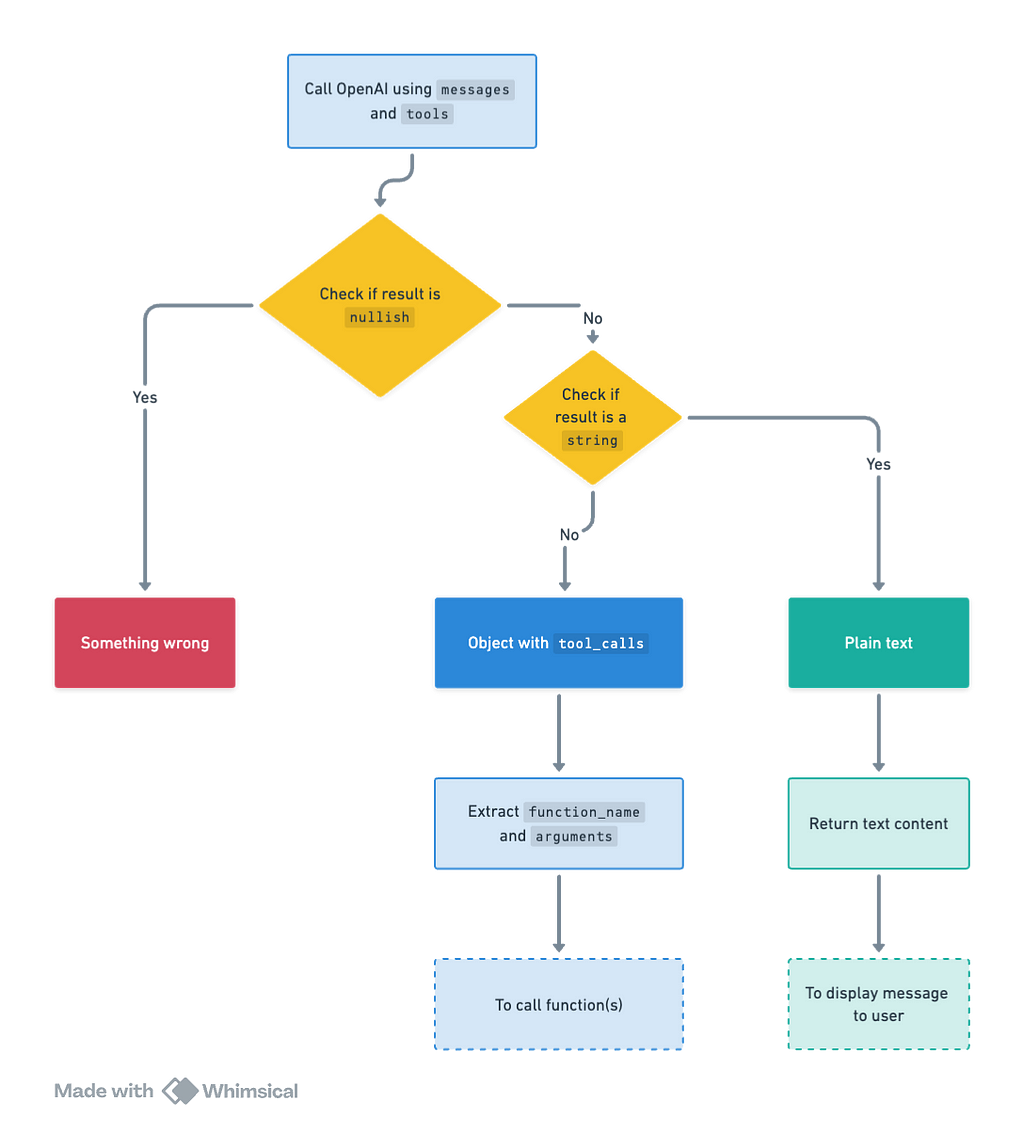
According to OpenAI’s documentation, the basic sequence of steps for function calling is as follows:
Call the model with the user query and a set of functions defined in the functions(tools) parameter.
The model can choose to call one or more functions; if so, the content will be a stringified JSON object adhering to your custom schema (note: the model may hallucinate parameters).
Parse the string into JSON in your code, and call your function with the provided arguments if they exist.
Call the model again by appending the function response as a new message, and let the model summarize the results back to the user.
A sequence diagram of how OpenAI function calling works
Four key concepts that may be confusing at first:
Tools: The term Functions is depreciated and replaced by Tools. Currently, Tools exclusively support what is essentially the function type. Essentially, this change is in name and syntax
Tools Description: When we say you’re passing “tools” to the model, think of it as providing a list or menu of what the model can do, not the actual functions. It’s like telling the model, “Here are the actions you can choose to perform,” without giving it the direct means to do so.
Function Call Returns: When the model suggests a function call, it’s essentially saying, “I think we should use this tool and here’s what we need for it,” by naming the function and specifying any required information (arguments). However, at this point, it’s just a suggestion; the actual action is carried out in your application.
Using Responses to Inform the Next Steps: Once a function is actually executed in your application and you have the results, you feed these results back to the model as part of a new prompt. This helps the model understand what happened and guides it in making the next move or response.
Step-by-Step Guide to Building an Agent
Business Case: Development of a Farm Trip Assistant Agent
We aim to develop a farm trip assistant agent designed to enhance the user experience in planning farm visits. This digital assistant will offer comprehensive support by:
Identifying top farm destinations tailored to user location.
Providing detailed information on available activities at each farm.
Facilitating the booking of selected activities.
Offering a straightforward process for filing complaints, if necessary.
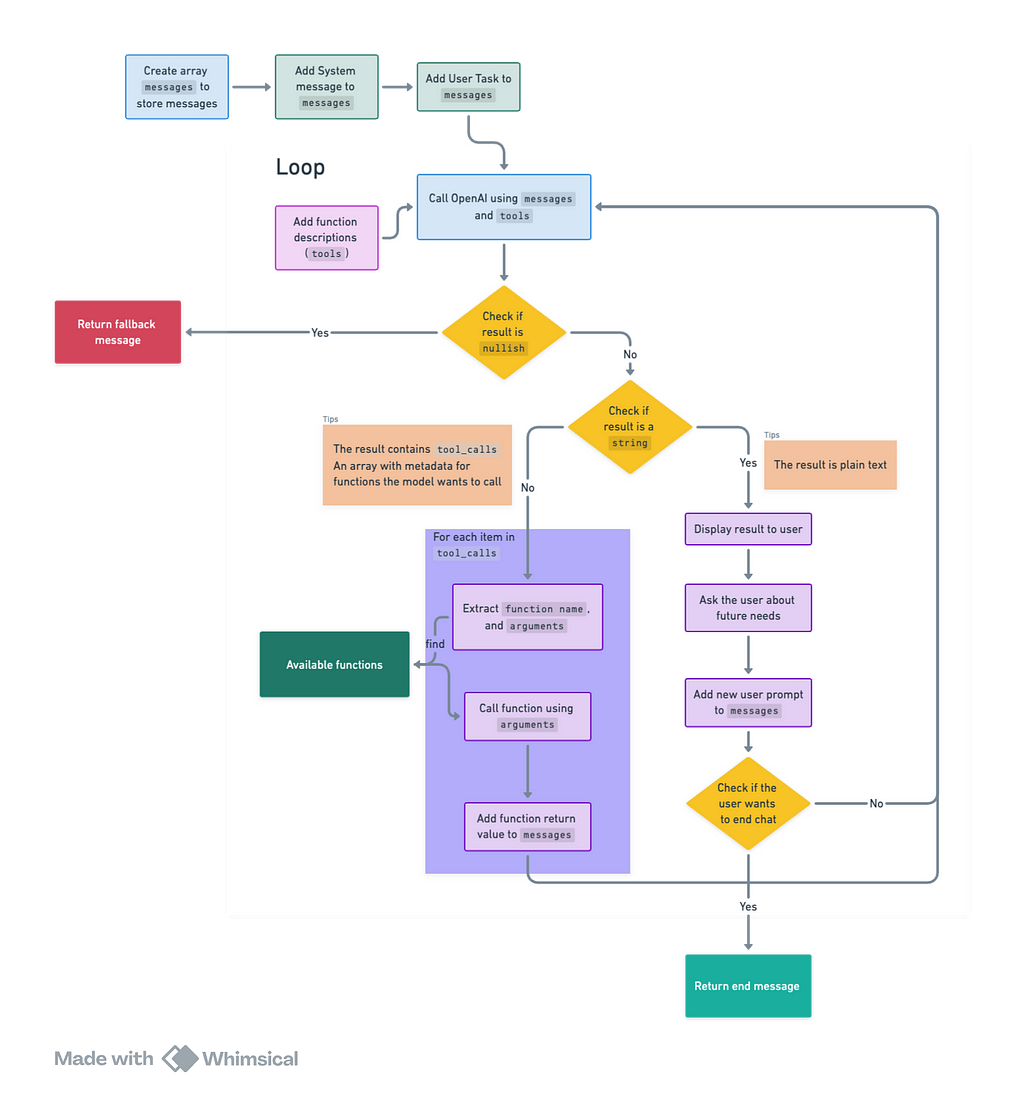
Application Architecture:
This flowchart shows the architecture of the application:
The flowchart of the agent
Pre-requisites:
OpenAI API key: You can obtain this from the OpenAI platform.
Step 1: Prepare to call the model:
To initiate a conversation, begin with a system message and a user prompt for the task:
Create a messages array to keep track of the conversation history.
Include a system message in the messages array to to establish the assistant’s role and context.
Welcome the users with a greeting message and prompt them to specify their task.
As my personal preference, all the prompts are stored in map objects for easy access and modification. Please refer to the following code snippets for all the prompts used in the application. Feel free to adopt or modify this approach as suits you.
StaticPromptMap: Static messages that are used throughout the conversation.
export const StaticPromptMap = { welcome: "Welcome to the farm assistant! What can I help you with today? You can ask me what I can do.", fallback: "I'm sorry, I don't understand.", end: "I hope I was able to help you. Goodbye!", } as const;
UserPromptMap: User messages that are generated based on user input.
import { ChatCompletionUserMessageParam } from "openai/resources/index.mjs";
type UserPromptMapKey = "task"; type UserPromptMapValue = ( userInput?: string ) => ChatCompletionUserMessageParam; export const UserPromptMap: Record<UserPromptMapKey, UserPromptMapValue> = { task: (userInput) => ({ role: "user", content: userInput || "What can you do?", }), };
SystemPromptMap: System messages that are generated based on system context.
import { ChatCompletionSystemMessageParam } from "openai/resources/index.mjs";
type SystemPromptMapKey = "context"; export const SystemPromptMap: Record< SystemPromptMapKey, ChatCompletionSystemMessageParam > = { context: { role: "system", content: "You are an farm visit assistant. You are upbeat and friendly. You introduce yourself when first saying `Howdy!`. If you decide to call a function, you should retrieve the required fields for the function from the user. Your answer should be as precise as possible. If you have not yet retrieve the required fields of the function completely, you do not answer the question and inform the user you do not have enough information.", }, };
FunctionPromptMap: Function messages that are basically the return values of the functions.
import { ChatCompletionToolMessageParam } from "openai/resources/index.mjs";
As mentioned earlier, tools are essentially the descriptions of functions that the model can call. In this case, we define four tools to meet the requirements of the farm trip assistant agent:
get_farms: Retrieves a list of farm destinations based on user’s location.
get_activities_per_farm: Provides detailed information on activities available at a specific farm.
book_activity: Facilitates the booking of a selected activity.
file_complaint: Offers a straightforward process for filing complaints.
The following code snippet demonstrates how these tools are defined:
import { ChatCompletionTool, FunctionDefinition, } from "openai/resources/index.mjs"; import { ConvertTypeNameStringLiteralToType, JsonAcceptable, } from "../utils/type-utils.js";
// An enum to define the names of the functions. This will be shared between the function descriptions and the actual functions export enum DescribedFunctionName { FileComplaint = "file_complaint", getFarms = "get_farms", getActivitiesPerFarm = "get_activities_per_farm", bookActivity = "book_activity", } // This is a utility type to narrow down the `parameters` type in the `FunctionDefinition`. // It pairs with the keyword `satisfies` to ensure that the properties of parameters are correctly defined. // This is a workaround as the default type of `parameters` in `FunctionDefinition` is `type FunctionParameters = Record<string, unknown>` which is overly broad. type FunctionParametersNarrowed< T extends Record<string, PropBase<JsonAcceptable>> > = { type: JsonAcceptable; // basically all the types that JSON can accept properties: T; required: (keyof T)[]; }; // This is a base type for each property of the parameters type PropBase<T extends JsonAcceptable = "string"> = { type: T; description: string; }; // This utility type transforms parameter property string literals into usable types for function parameters. // Example: { email: { type: "string" } } -> { email: string } export type ConvertedFunctionParamProps< Props extends Record<string, PropBase<JsonAcceptable>> > = { [K in keyof Props]: ConvertTypeNameStringLiteralToType<Props[K]["type"]>; }; // Define the parameters for each function export type FileComplaintProps = { name: PropBase; email: PropBase; text: PropBase; }; export type GetFarmsProps = { location: PropBase; }; export type GetActivitiesPerFarmProps = { farm_name: PropBase; }; export type BookActivityProps = { farm_name: PropBase; activity_name: PropBase; datetime: PropBase; name: PropBase; email: PropBase; number_of_people: PropBase<"number">; }; // Define the function descriptions const functionDescriptionsMap: Record< DescribedFunctionName, FunctionDefinition > = { [DescribedFunctionName.FileComplaint]: { name: DescribedFunctionName.FileComplaint, description: "File a complaint as a customer", parameters: { type: "object", properties: { name: { type: "string", description: "The name of the user, e.g. John Doe", }, email: { type: "string", description: "The email address of the user, e.g. [email protected]", }, text: { type: "string", description: "Description of issue", }, }, required: ["name", "email", "text"], } satisfies FunctionParametersNarrowed<FileComplaintProps>, }, [DescribedFunctionName.getFarms]: { name: DescribedFunctionName.getFarms, description: "Get the information of farms based on the location", parameters: { type: "object", properties: { location: { type: "string", description: "The location of the farm, e.g. Melbourne VIC", }, }, required: ["location"], } satisfies FunctionParametersNarrowed<GetFarmsProps>, }, [DescribedFunctionName.getActivitiesPerFarm]: { name: DescribedFunctionName.getActivitiesPerFarm, description: "Get the activities available on a farm", parameters: { type: "object", properties: { farm_name: { type: "string", description: "The name of the farm, e.g. Collingwood Children's Farm", }, }, required: ["farm_name"], } satisfies FunctionParametersNarrowed<GetActivitiesPerFarmProps>, }, [DescribedFunctionName.bookActivity]: { name: DescribedFunctionName.bookActivity, description: "Book an activity on a farm", parameters: { type: "object", properties: { farm_name: { type: "string", description: "The name of the farm, e.g. Collingwood Children's Farm", }, activity_name: { type: "string", description: "The name of the activity, e.g. Goat Feeding", }, datetime: { type: "string", description: "The date and time of the activity", }, name: { type: "string", description: "The name of the user", }, email: { type: "string", description: "The email address of the user", }, number_of_people: { type: "number", description: "The number of people attending the activity", }, }, required: [ "farm_name", "activity_name", "datetime", "name", "email", "number_of_people", ], } satisfies FunctionParametersNarrowed<BookActivityProps>, }, }; // Format the function descriptions into tools and export them export const tools = Object.values( functionDescriptionsMap ).map<ChatCompletionTool>((description) => ({ type: "function", function: description, }));
Understanding Function Descriptions
Function descriptions require the following keys:
name: Identifies the function.
description: Provides a summary of what the function does.
parameters: Defines the function’s parameters, including their type, description, and whether they are required.
type: Specifies the parameter type, typically an object.
properties: Details each parameter, including its type and description.
required: Lists the parameters that are essential for the function to operate.
Adding a New Function
To introduce a new function, proceed as follows:
Extend DescribedFunctionName with a new enum, such as DoNewThings.
Define a Props type for the parameters, e.g., DoNewThingsProps.
Insert a new entry in the functionDescriptionsMap object.
Implement the new function in the function directory, naming it after the enum value.
Step 3: Call the model with the messages and the tools
With the messages and tools set up, we’re ready to call the model using them.
It’s important to note that as of March 2024, function calling is supported only by the gpt-3.5-turbo-0125 and gpt-4-turbo-preview models.
messages, // The messages array we created earlier tools, // The function descriptions we defined earlier tool_choice: "auto", // The model will decide whether to call a function and which function to call }); const { message } = response.choices[0] ?? {}; if (!message) { throw new Error("Error: No response from the API."); } messages.push(message); return processMessage(message); };
tool_choice Options
The tool_choice option controls the model’s approach to function calls:
Specific Function: To specify a particular function, set tool_choice to an object with type: “function” and include the function’s name and details. For instance, tool_choice: { type: “function”, function: { name: “get_farms”}} tells the model to call the get_farms function regardless of the context. Even a simple user prompt like “Hi.” will trigger this function call.
No Function: To have the model generate a response without any function calls, use tool_choice: “none”. This option prompts the model to rely solely on the input messages for generating its response.
Automatic Selection: The default setting, tool_choice: “auto”, lets the model autonomously decide if and which function to call, based on the conversation’s context. This flexibility is beneficial for dynamic decision-making regarding function calls.
Step 4: Handling Model Responses
The model’s responses fall into two primary categories, with a potential for errors that necessitate a fallback message:
Function Call Request: The model indicates a desire to call function(s). This is the true potential of function calling. The model intelligently selects which function(s) to execute based on context and user queries. For instance, if the user asks for farm recommendations, the model may suggest calling the get_farms function.
But it doesn’t just stop there, the model also analyzes the user input to determine if it contains the necessary information (arguments) for the function call. If not, the model would prompt the user for the missing details.
Once it has gathered all required information (arguments), the model returns a JSON object detailing the function name and arguments. This structured response can be effortlessly translated into a JavaScript object within our application, enabling us to invoke the specified function seamlessly, thereby ensuring a fluid user experience.
Additionally, the model can choose to call multiple functions, either simultaneously or in sequence, each requiring specific details. Managing this within the application is crucial for smooth operation.
Example of model’s response:
{ "role": "assistant", "content": null, "tool_calls": [ { "id": "call_JWoPQYmdxNXdNu1wQ1iDqz2z", "type": "function", "function": { "name": "get_farms", // The function name to be called "arguments": "{"location":"Melbourne"}" // The arguments required for the function } } ... // multiple function calls can be present ] }
2. Plain Text Response: The model provides a direct text response. This is the standard output we’re accustomed to from AI models, offering straightforward answers to user queries. Simply returning the text content suffices for these responses.
Example of model’s response:
{ "role": "assistant", "content": { "text": "I can help you with that. What is your location?" } }
The key distinction is the presence of a tool_calls key for function calls. If tool_calls is present, the model is requesting to execute a function; otherwise, it delivers a straightforward text response.
To process these responses, consider the following approach based on the response type:
type ChatCompletionMessageWithToolCalls = RequiredAll< Omit<ChatCompletionMessage, "function_call"> >;
// If the message contains tool_calls, it extracts the function arguments. Otherwise, it returns the content of the message. export function processMessage(message: ChatCompletionMessage) { if (isMessageHasToolCalls(message)) { return extractFunctionArguments(message); } else { return message.content; } } // Check if the message has `tool calls` function isMessageHasToolCalls( message: ChatCompletionMessage ): message is ChatCompletionMessageWithToolCalls { return isDefined(message.tool_calls) && message.tool_calls.length !== 0; } // Extract function name and arguments from the message function extractFunctionArguments(message: ChatCompletionMessageWithToolCalls) { return message.tool_calls.map((toolCall) => { if (!isDefined(toolCall.function)) { throw new Error("No function found in the tool call"); } try { return { tool_call_id: toolCall.id, function_name: toolCall.function.name, arguments: JSON.parse(toolCall.function.arguments), }; } catch (error) { throw new Error("Invalid JSON in function arguments"); } }); }
The arguments extracted from the function calls are then used to execute the actual functions in the application, while the text content helps to carry on the conversation.
Below is an if-else block illustrating how this process unfolds:
const result = await startChat(messages);
if (!result) { // Fallback message if response is empty (e.g., network error) return console.log(StaticPromptMap.fallback); } else if (isNonEmptyString(result)) { // If the response is a string, log it and prompt the user for the next message console.log(`Assistant: ${result}`); const userPrompt = await createUserMessage(); messages.push(userPrompt); } else { // If the response contains function calls, execute the functions and call the model again with the updated messages for (const item of result) { const { tool_call_id, function_name, arguments: function_arguments } = item; // Execute the function and get the function return const function_return = await functionMap[ function_name as keyof typeof functionMap ](function_arguments); // Add the function output back to the messages with a role of "tool", the id of the tool call, and the function return as the content messages.push( FunctionPromptMap.function_response({ tool_call_id, content: function_return, }) ); } }
Step 5: Execute the function and call the model again
When the model requests a function call, we execute that function in our application and then update the model with the new messages. This keeps the model informed about the function’s result, allowing it to give a pertinent reply to the user.
Maintaining the correct sequence of function executions is crucial, especially when the model chooses to execute multiple functions in a sequence to complete a task. Using a for loop instead of Promise.all preserves the execution order, essential for a successful workflow. However, if the functions are independent and can be executed in parallel, consider custom optimizations to enhance performance.
Here’s how to execute the function:
for (const item of result) { const { tool_call_id, function_name, arguments: function_arguments } = item;
console.log( `Calling function "${function_name}" with ${JSON.stringify( function_arguments )}` ); // Available functions are stored in a map for easy access const function_return = await functionMap[ function_name as keyof typeof functionMap ](function_arguments); }
And here’s how to update the messages array with the function response:
for (const item of result) { const { tool_call_id, function_name, arguments: function_arguments } = item;
console.log( `Calling function "${function_name}" with ${JSON.stringify( function_arguments )}` ); const function_return = await functionMap[ function_name as keyof typeof functionMap ](function_arguments); // Add the function output back to the messages with a role of "tool", the id of the tool call, and the function return as the content messages.push( FunctionPromptMap.function_response({ tool_call_id, content: function_return, }) ); }
After running the functions and updating the message array, we re-engage the model with these updated messages to brief the user on the outcomes. This involves repeatedly invoking the startChat function via a loop.
To avoid endless looping, it’s crucial to monitor for user inputs signaling the end of the conversation, like “Goodbye” or “End,” ensuring the loop terminates appropriately.
export function isChatEnding( message: ChatCompletionMessageParam | undefined | null ) { // If the message is not defined, log a fallback message if (!isDefined(message)) { return console.log(StaticPromptMap.fallback); } // Check if the message is from the user if (!isUserMessage(message)) { return false; } const { content } = message; return CHAT_END_SIGNALS.some((signal) => { if (typeof content === "string") { return includeSignal(content, signal); } else { // content has a typeof ChatCompletionContentPart, which can be either ChatCompletionContentPartText or ChatCompletionContentPartImage // If user attaches an image to the current message first, we assume they are not ending the chat const contentPart = content.at(0); if (contentPart?.type !== "text") { return false; } else { return includeSignal(contentPart.text, signal); } } }); } function isUserMessage( message: ChatCompletionMessageParam ): message is ChatCompletionUserMessageParam { return message.role === "user"; } function includeSignal(content: string, signal: string) { return content.toLowerCase().includes(signal); }
Conclusion
OpenAI’s function calling represents a major advancement in AI, allowing models to perform custom functions in response to user queries. This feature simplifies obtaining structured data from outputs, improving user interaction and enabling more complex exchanges.
Enjoyed This Story?
Selina Li (Selina Li, LinkedIn) is a Principal Data Engineer working at Officeworks in Melbourne Australia. Selina is passionate about AI/ML, data engineering and investment.
Jason Li (Tianyi Li, LinkedIn) is a Full-stack Developer working at Mindset Health in Melbourne Australia. Jason is passionate about AI, front-end development and space related technologies.
Selina and Jason would love to explore technologies to help people achieve their goals.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.