
My techniques and methods for learning data science and technical fields
Originally appeared here:
How I Self-Study Data Science
My techniques and methods for learning data science and technical fields
Originally appeared here:
How I Self-Study Data Science

Enhancing Code Generation with LLMs via Prompt Engineering
Originally appeared here:
Prompt Engineering for Coding Tasks
Go Here to Read this Fast! Prompt Engineering for Coding Tasks


Getting statistical insights with Python, Pandas, and Plotly
Originally appeared here:
Exploratory Data Analysis: Lost Property Items on the Transport of London
Go Here to Read this Fast! Exploratory Data Analysis: Lost Property Items on the Transport of London


Helping Entry-Level Data Scientists to Transform Ideas into Industrial-Level applications.
Originally appeared here:
Seven Requisite Skills for Navigating from Data Science to Applications
Go Here to Read this Fast! Seven Requisite Skills for Navigating from Data Science to Applications


A simple way to understand parameters to the Archie Water Saturation equation using Python
Originally appeared here:
Using Python to Explore and Understand Equations in Petrophysics
Go Here to Read this Fast! Using Python to Explore and Understand Equations in Petrophysics


There has been a new development in our neighborhood.
A ‘Robo-Truck,’ as my son likes to call it, has made its new home on our street.
It is a Tesla Cyber Truck and I have tried to explain that name to my son many times but he insists on calling it Robo-Truck. Now every time I look at Robo-Truck and hear that name, it reminds me of the movie Transformers where robots could transform to and from cars.
And isn’t it strange that Transformers as we know them today could very well be on their way to powering these Robo-Trucks? It’s almost a full circle moment. But where am I going with all these?
Well, I am heading to the destination — Transformers. Not the robot car ones but the neural network ones. And you are invited!
Transformers are essentially neural networks. Neural networks that specialize in learning context from the data.
But what makes them special is the presence of mechanisms that eliminate the need for labeled datasets and convolution or recurrence in the network.
There are many. But the two mechanisms that are truly the force behind the transformers are attention weighting and feed-forward networks (FFN).
Attention-weighting is a technique by which the model learns which part of the incoming sequence needs to be focused on. Think of it as the ‘Eye of Sauron’ scanning everything at all times and throwing light on the parts that are relevant.
Fun-fact: Apparently, the researchers had almost named the Transformer model ‘Attention-Net’, given Attention is such a crucial part of it.
In the context of transformers, FFN is essentially a regular multilayer perceptron acting on a batch of independent data vectors. Combined with attention, it produces the correct ‘position-dimension’ combination.
So, without further ado, let’s dive into how attention-weighting and FFN make transformers so powerful.
This discussion is based on Prof. Tom Yeh’s wonderful AI by Hand Series on Transformers . (All the images below, unless otherwise noted, are by Prof. Tom Yeh from the above-mentioned LinkedIn posts, which I have edited with his permission.)
So here we go:
The key ideas here : attention weighting and feed-forward network (FFN).
Keeping those in mind, suppose we are given:
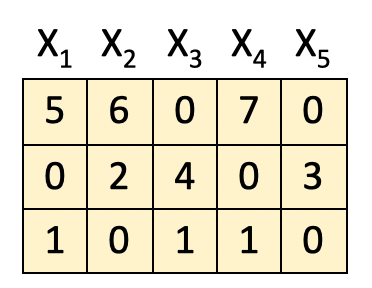
[1] Obtain attention weight matrix A
The first step in the process is to obtain the attention weight matrix A. This is the part where the self-attention mechanism comes to play. What it is trying to do is find the most relevant parts in this input sequence.
We do it by feeding the input features into the query-key (QK) module. For simplicity, the details of the QK module are not included here.
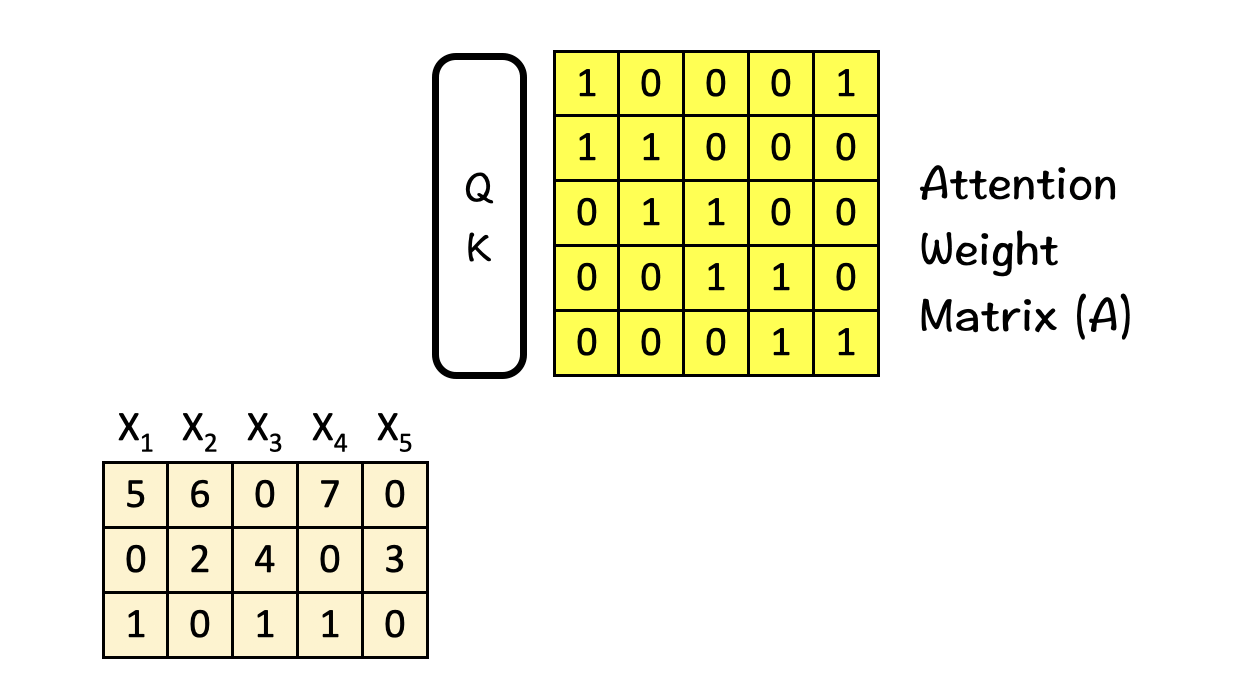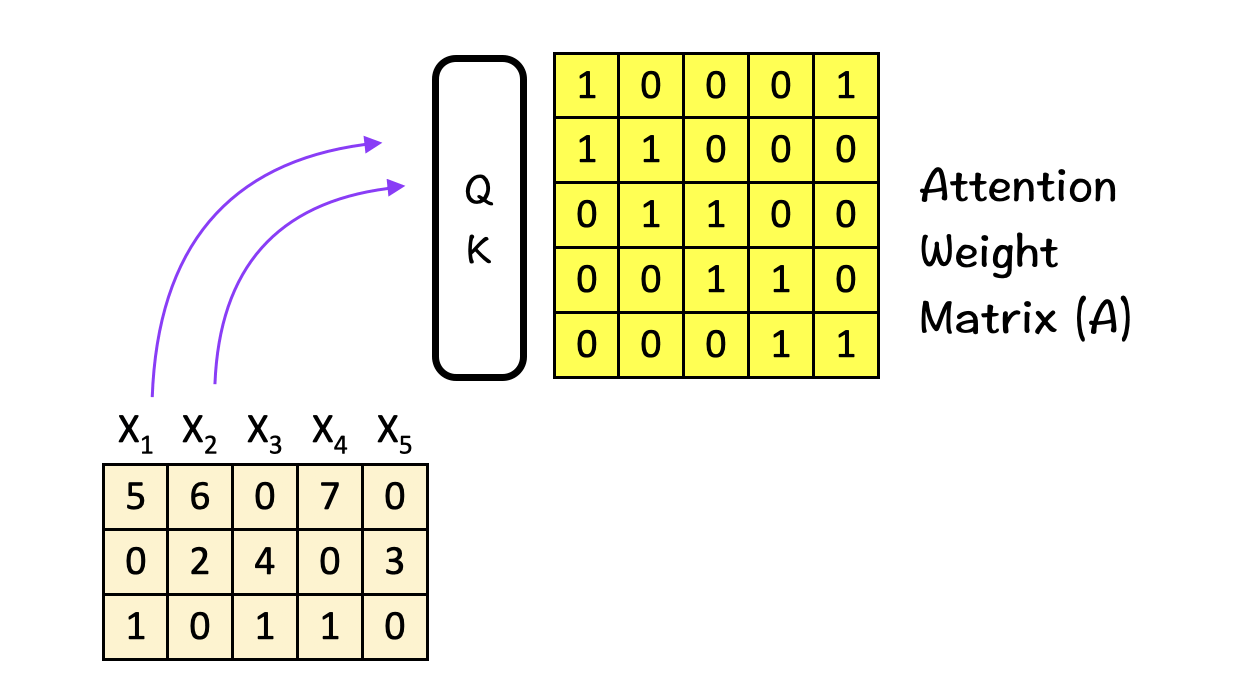
[2] Attention Weighting
Once we have the attention weight matrix A (5×5), we multiply the input features (3×5) with it to obtain the attention-weighted features Z.
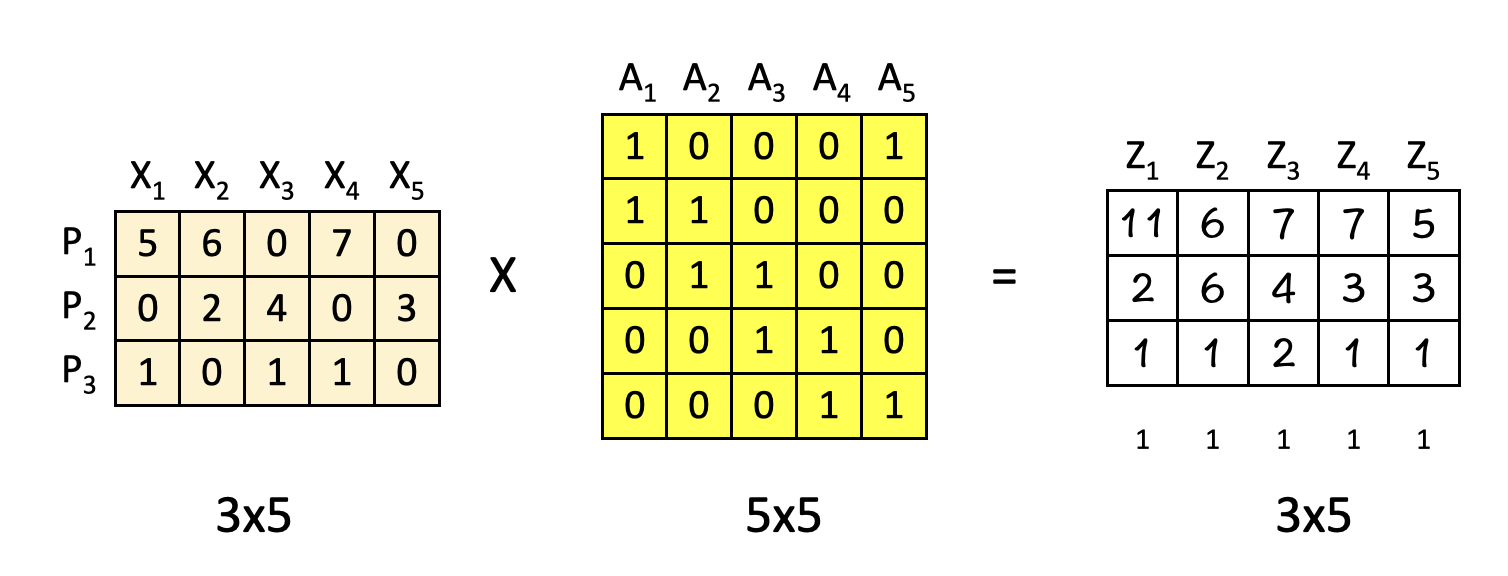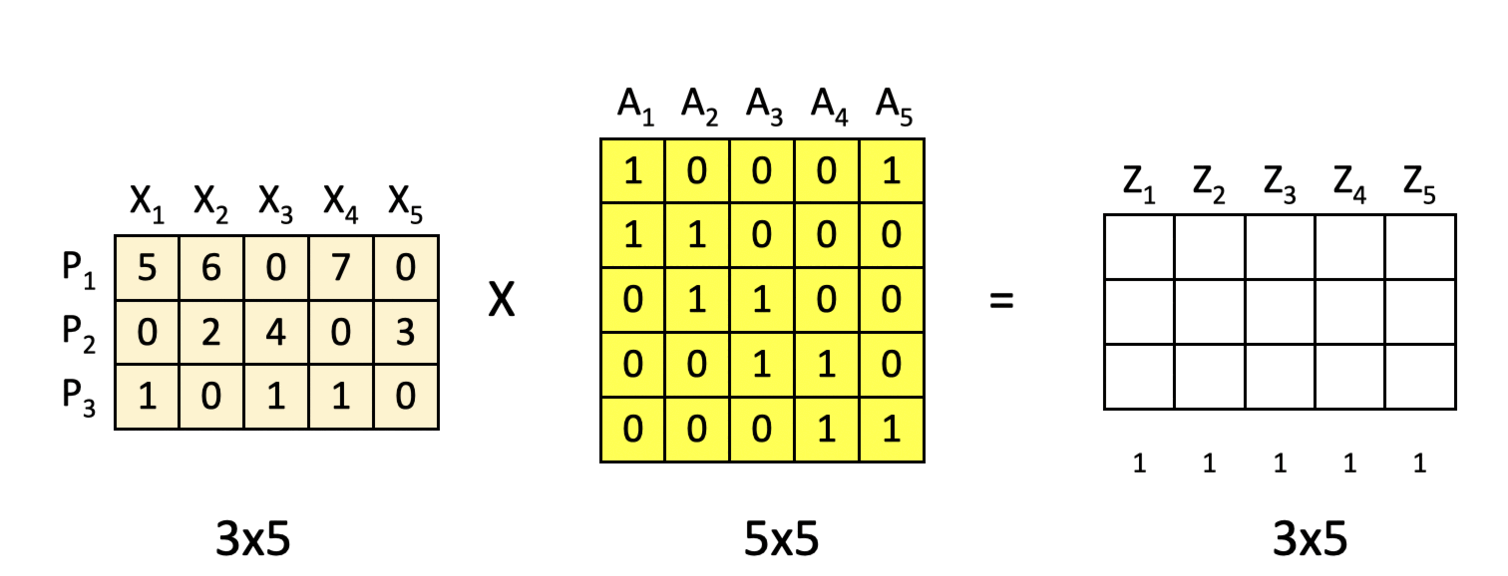
The important part here is that the features here are combined based on their positions P1, P2 and P3 i.e. horizontally.
To break it down further, consider this calculation performed row-wise:
P1 X A1 = Z1 → Position [1,1] = 11
P1 X A2 = Z2 → Position [1,2] = 6
P1 X A3 = Z3 → Position [1,3] = 7
P1 X A4 = Z4 → Position [1,4] = 7
P1 X A5 = Z5 → Positon [1,5] = 5
.
.
.
P2 X A4 = Z4 → Position [2,4] = 3
P3 X A5 = Z5 →Position [3,5] = 1
As an example:

It seems a little tedious in the beginning but follow the multiplication row-wise and the result should be pretty straight-forward.
Cool thing is the way our attention-weight matrix A is arranged, the new features Z turn out to be the combinations of X as below :
Z1 = X1 + X2
Z2 = X2 + X3
Z3 = X3 + X4
Z4 = X4 + X5
Z5 = X5 + X1
(Hint : Look at the positions of 0s and 1s in matrix A).
[3] FFN : First Layer
The next step is to feed the attention-weighted features into the feed-forward neural network.
However, the difference here lies in combining the values across dimensions as opposed to positions in the previous step. It is done as below:

What this does is that it looks at the data from the other direction.
– In the attention step, we combined our input on the basis of the original features to obtain new features.
– In this FFN step, we consider their characteristics i.e. combine features vertically to obtain our new matrix.
Eg: P1(1,1) * Z1(1,1)
+ P2(1,2) * Z1 (2,1)
+ P3 (1,3) * Z1(3,1) + b(1) = 11, where b is bias.
Once again element-wise row operations to the rescue. Notice that here the number of dimensions of the new matrix is increased to 4 here.
[4] ReLU
Our favorite step : ReLU, where the negative values obtained in the previous matrix are returned as zero and the positive value remain unchanged.

[5] FFN : Second Layer
Finally we pass it through the second layer where the dimensionality of the resultant matrix is reduced from 4 back to 3.

The output here is ready to be fed to the next block (see its similarity to the original matrix) and the entire process is repeated from the beginning.
The two key things to remember here are:
And this is the secret sauce behind the power of the transformers — the ability to analyze data from different directions.
To summarize the ideas above, here are the key points:
Neural networks have existed for quite some time now. Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) had been reigning supreme but things took quite an eventful turn once Transformers were introduced in the year 2017. And since then, the field of AI has grown at an exponential rate — with new models, new benchmarks, new learnings coming in every single day. And only time will tell if this phenomenal idea will one day lead the way for something even bigger — a real ‘Transformer’.
But for now it would not be wrong to say that an idea can really transform how we live!

P.S. If you would like to work through this exercise on your own, here is the blank template for your use.
Blank Template for hand-exercise
Now go have some fun and create your own Robtimus Prime!
Deep Dive into Transformers by Hand ✍︎ was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Deep Dive into Transformers by Hand ✍︎
Go Here to Read this Fast! Deep Dive into Transformers by Hand ✍︎
Annotations are a powerful development tool. Read this article to learn how and where to use them.
Originally appeared here:
Enhancing Readability of Python Code via Annotations
Go Here to Read this Fast! Enhancing Readability of Python Code via Annotations
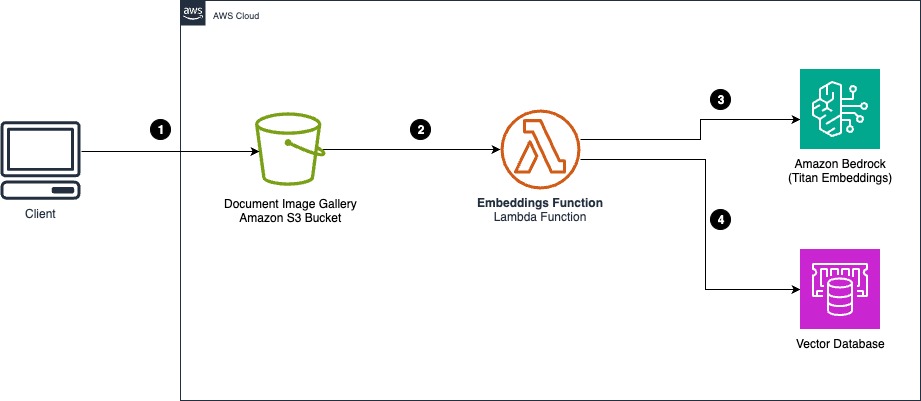

Originally appeared here:
Cost-effective document classification using the Amazon Titan Multimodal Embeddings Model


SQL can now replace Python for most supervised ML tasks. Should you make the switch?
Originally appeared here:
How to Train a Decision Tree Classifier… In SQL
Go Here to Read this Fast! How to Train a Decision Tree Classifier… In SQL


