The art of getting quick gains with agile model production
This post was written together with and inspired by Yuval Cohen
Introduction
Every day, numerous data science projects are discarded due to insufficient prediction accuracy. It’s a regrettable outcome, considering that often these models could be exceptionally well-suited for some subsets of the dataset.
Data Scientists often try to improve their models by using more complex models and by throwing more and more data at the problem. But many times there is a much simpler and more productive approach: Instead of trying to make all of our predictions better all at once, we could start by making good predictions for the easy parts of the data, and only then work on the harder parts.
This approach can greatly affect our ability to solve real-world problems. We start with the quick gain on the easy problems and only then focus our effort on the harder problems.
Thinking Agile
Agile production means focusing on the easy data first, and only after it has been properly modelled, moving on the the more complicated tasks. This allows a workflow that is iterative, value-driven, and collaborative.
It allows for quicker results, adaptability to changing circumstances, and continuous improvement, which are core ideas of agile production.
- Iterative and incremental approach: work in short, iterative cycles. Start by achieving high accuracy for the easy problems and then move on to the harder parts.
- Focus on delivering value: work on the problem with the highest marginal value for your time.
- Flexibility and adaptability: Allow yourself to adapt to changing circumstances. For example, a client might need you to focus on a certain subset of the data — once you’ve solved that small problem, the circumstances have changed and you might need to work on something completely different. Breaking the problem into small parts allows you to adapt to the changing circumstances.
- Feedback and continuous improvement: By breaking up a problem you allow yourself to be in constant and continuous improvement, rather than waiting for big improvements in large chunks.
- Collaboration: Breaking the problem into small pieces promotes parallelization of the work and collaboration between team members, rather than putting all of the work on one person.
Breaking down the complexity
In real-world datasets, complexity is the rule rather than the exception. Consider a medical diagnosis task, where subtle variations in symptoms can make the difference between life-threatening conditions and minor ailments. Achieving high accuracy in such scenarios can be challenging, if not impossible, due to the inherent noise and nuances in the data.
This is where the idea of coverage comes into play. Coverage refers to the portion of the data that a model successfully predicts or classifies with high confidence or high precision. Instead of striving for high accuracy across the entire dataset, researchers can choose to focus on a subset of the data where prediction is relatively straightforward. By doing so, they can achieve high accuracy on this subset while acknowledging the existence of a more challenging, uncovered portion.
For instance, consider a trained model with a 50% accuracy rate on a test dataset. In this scenario, it’s possible that if we could identify and select only the predictions we are very sure about (although we should decide what “very sure” means), we could end up with a model that covers fewer cases, let’s say around 60%, but with significantly improved accuracy, perhaps reaching 85%.
I don’t know any product manager who would say no in such a situation. Especially if there is no model in production, and this is the first model.
The two-step model
We want to divide our data into two distinct subsets: the covered and the uncovered. The covered data is the part of the data where the initial model achieves high accuracy and confidence. The uncovered data is the part of the data where our model does not give confident predictions and does not achieve high accuracy.
In the first step, a model is trained on the data. Once we identify a subset of data where the model achieves high accuracy, we deploy that model and let it run on that subset — the covered data.
In the second step, we move our focus to the uncovered data. We try to develop a better model for this data by collecting more data, using more advanced algorithms, feature engineering, and incorporating domain-specific knowledge to find patterns in the data.
At this step, the first thing you should do is look at the errors by eye. Many times you will easily identify many patterns this way before using any fancy tricks.
An example
This example will show how the concept of agile workflow can create great value. This is a very simple example that is meant to visualize this concept. Real-life examples will be a lot less obvious but the idea that you will see here is just as relevant.
Let’s look at this two-dimensional data that I simulated from three equally sized classes.
num_samples_A = 500
num_samples_B = 500
num_samples_C = 500
# Class A
mean_A = [3, 2]
cov_A = [[0.1, 0], [0, 0.1]] # Low variance
class_A = np.random.multivariate_normal(mean_A, cov_A, num_samples_A)
# Class B
mean_B = [0, 0]
cov_B = [[1, 0.5], [0.5, 1]] # Larger variance with some overlap with class C
class_B = np.random.multivariate_normal(mean_B, cov_B, num_samples_B)
# Class C
mean_C = [0, 1]
cov_C = [[2, 0.5], [0.5, 2]] # Larger variance with some overlap with class B
class_C = np.random.multivariate_normal(mean_C, cov_C, num_samples_C)
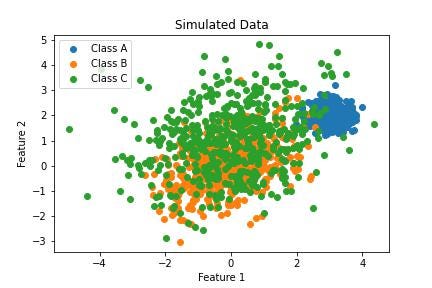
Now we try to fit a machine learning classifier to this data, it looks like an SVM classifier with a Gaussian (‘rbf’) kernel might do the trick:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# Creating DataFrame
data = np.concatenate([class_A, class_B, class_C])
labels = np.concatenate([np.zeros(num_samples_A), np.ones(num_samples_B), np.ones(num_samples_C) * 2])
df = pd.DataFrame(data, columns=['x', 'y'])
df['label'] = labels.astype(int)
# Splitting data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(df[['x', 'y']], df['label'], test_size=0.2, random_state=42)
# Training SVM model with RBF kernel
svm_rbf = SVC(kernel='rbf', probability= True)
svm_rbf.fit(X_train, y_train)
# Predict probabilities for each class
svm_rbf_probs = svm_rbf.predict_proba(X_test)
# Get predicted classes and corresponding confidences
svm_rbf_predictions = [(X_test.iloc[i]['x'], X_test.iloc[i]['y'], true_class, np.argmax(probs), np.max(probs)) for i, (true_class, probs) in enumerate(zip(y_test, svm_rbf_probs))]
svm_predictions_df = pd.DataFrame(svm_rbf_predictions).rename(columns={0:'x',1:'y' ,2: 'true_class', 3: 'predicted_class', 4: 'confidence'})
How does this model perform on our data?
accuracy = (svm_predictions_df['true_class'] == svm_predictions_df['predicted_class']).mean()*100
print(f'Accuracy = {round(accuracy,2)}%')
Accuracy = 75.33%
75% percent accuracy is disappointing, but does this mean that this model is useless?
Now we want to look at the most confident predictions and see how the model performs on them. How do we define the most confident predictions? We can try out different confidence (predict_proba) thresholds and see what coverage and accuracy we get for each threshold and then decide which threshold meets our business needs.
thresholds = [.5, .55, .6, .65, .7, .75, .8, .85, .9]
results = []
for threshold in thresholds:
svm_df_covered = svm_predictions_df.loc[svm_predictions_df['confidence'] > threshold]
coverage = len(svm_df_covered) / len(svm_predictions_df) * 100
accuracy_covered = (svm_df_covered['true_class'] == svm_df_covered['predicted_class']).mean() * 100
results.append({'Threshold': threshold, 'Coverage (%)': round(coverage,2), 'Accuracy on covered data (%)': round(accuracy_covered,2)})
results_df = pd.DataFrame(results)
print(results_df)
And we get

Or if we want a more detailed look we can create a plot of the coverage and accuracy by threshold:
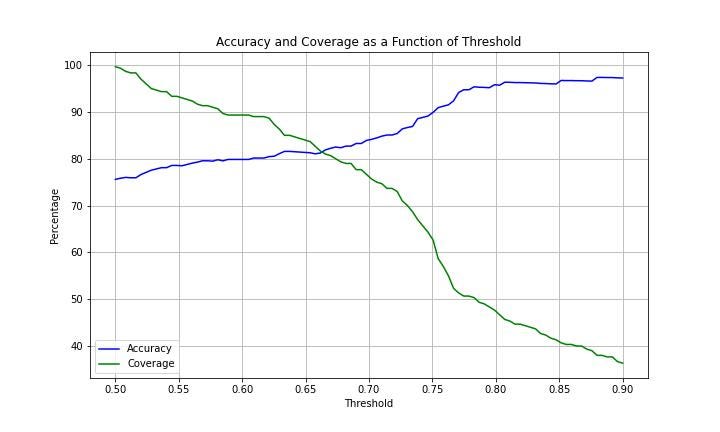
We can now select the threshold that fits our business logic. For example, if our company’s policy is to guarantee at least 90% accuracy, then we can choose a threshold of 0.75 and get an accuracy of 90% for 62% of the data. This is a huge improvement to throwing out the model, especially if we don’t have any model in production!
Now that our model is happily working in production on 60% of the data, we can shift our focus to the rest of the data. We can collect more data, do more feature engineering, try more complex models, or get help from a domain expert.
Balancing act
The two-step model allows us to aim for accuracy while acknowledging that it is perfectly fine to start with a high accuracy for only a subset of the data. It is counterproductive to insist that a model will have high accuracy on all the data before deploying it to production.
The agile approach presented in this post aims for resource allocation and efficiency. Instead of spending computational resources on getting high accuracy all across. Focus your resources on where the marginal gain is highest.
Conclusion
In data science, we try to achieve high accuracy. However, in the reality of messy data, we need to find a clever approach to utilize our resources in the best way. Agile model production teaches us to focus on the parts of the data where our model works best, deploy the model for those subsets, and only then start working on a new model for the more complicated part. This strategy will help you make the best use of your resources in the face of real data science problems.
Think production, Think Agile.
Coverage vs. Accuracy: Striking a Balance in Data Science was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Coverage vs. Accuracy: Striking a Balance in Data Science
Go Here to Read this Fast! Coverage vs. Accuracy: Striking a Balance in Data Science