

How to calculate probability when “we absolutely know nothing antecedently to any trials made” (Bayes, 1763)
Contents
- Introduction
- Priors and Frequentist Matching
– example 1: a normal distribution with unknown mean
– example 2: a normal distribution with unknown variance - The Binomial Distribution Prior
- Applications from Bayes and Laplace
– example 3: observing only 1s
– example 4: a lottery
– example 5: birth rates - Discussion
- Conclusion
- Notes and References
Introduction
In 1654 Pascal and Fermat worked together to solve the problem of the points [1] and in so doing developed an early theory for deductive reasoning with direct probabilities. Thirty years later, Jacob Bernoulli worked to extend probability theory to solve inductive problems. He recognized that unlike in games of chance, it was futile to a priori enumerate possible cases and find out “how much more easily can some occur than the others”:
But, who from among the mortals will be able to determine, for example, the number of diseases, that is, the same number of cases which at each age invade the innumerable parts of the human body and can bring about our death; and how much easier one disease (for example, the plague) can kill a man than another one (for example, rabies; or, the rabies than fever), so that we would be able to conjecture about the future state of life or death? And who will count the innumerable cases of changes to which the air is subjected each day so as to form a conjecture about its state in a month, to say nothing about a year? Again, who knows the nature of the human mind or the admirable fabric of our body shrewdly enough for daring to determine the cases in which one or another participant can gain victory or be ruined in games completely or partly depending on acumen or agility of body? [2, p. 18]
The way forward, he reasoned, was to determine probabilities a posteriori
Here, however, another way for attaining the desired is really opening for us. And, what we are not given to derive a priori, we at least can obtain a posteriori, that is, can extract it from a repeated observation of the results of similar examples. [2, p. 18]
To establish the validity of the approach, Bernoulli proved a version of the law of large numbers for the binomial distribution. Let X_n represent a sample from a Bernoulli distribution with parameter r/t (r and t integers). Then if c represents some positive integer, Bernoulli showed that for N large enough
In other words, the probability the sampled ratio from a binomial distribution is contained within the bounds (r−1)/t to (r+1)/t is at least c times more likely than the the probability it is outside the bounds. Thus, by taking enough samples, “we determine the [parameter] a posteriori almost as though it was known to us a prior”.
Bernoulli, additionally, derived lower bounds, given r and t, for how many samples would be needed to achieve a desired levels of accuracy. For example, if r = 30 and t = 50, he showed
having made 25550 experiments, it will be more than a thousand times more likely that the ratio of the number of obtained fertile observations to their total number is contained within the limits 31/50 and 29/50 rather than beyond them [2, p. 30]
This suggested an approach to inference, but it came up short in several respects. 1) The bounds derived were conditional on knowledge of the true parameter. It didn’t provide a way to quantify uncertainty when the parameter was unknown. And 2) the number of experiments required to reach a high level of confidence in an estimate, moral certainty in Bernoulli’s words, was quite large, limiting the approach’s practicality. Abraham de Moivre would later improve on Bernoulli’s work in his highly popular textbook The Doctrine of Chances. He derived considerably tighter bounds, but again failed to provide a way to quantify uncertainty when the binomial distribution’s parameter was unknown, offering only this qualitative guidance:
if after taking a great number of Experiments, it should be perceived that the happenings and failings have been nearly in a certain proportion, such as of 2 to 1, it may safely be concluded that the Probabilities of happening or failing at any one time assigned will be very near that proportion, and that the greater the number of Experiments has been, so much nearer the Truth will the conjectures be that are derived from them. [3, p. 242]
Inspired by de Moivre’s book, Thomas Bayes took up the problem of inference with the binomial distribution. He reframed the goal to
Given the number of times in which an unknown event has happened and failed: Required the chance that the probability of its happening in a single trial lies somewhere between any two degrees of probability that can be named. [4, p. 4]
Recognizing that a solution would depend on prior probability, Bayes sought to give an answer for
the case of an event concerning the probability of which we absolutely know nothing antecedently to any trials made concerning it [4, p. 11]
He reasoned that knowing nothing was equivalent to a uniform prior distribution [5, p. 184–188]. Using the uniform prior and a geometric analogy with balls, Bayes succeeded in approximating integrals of posterior distributions of the form
and was able to answer questions like “If I observe y success and n − y failures from a binomial distribution with unknown parameter θ, what is the probability that θ is between a and b?”.
Despite Bayes’ success answering inferential questions, his method was not widely adopted and his work, published posthumously in 1763, remained obscure up until De Morgan renewed attention to it over fifty years later. A major obstacle was Bayes’ presentation; as mathematical historian Stephen Stigler writes,
Bayes essay ’Towards solving a problem in the doctrine of chances’ is extremely difficult to read today–even when we know what to look for. [5, p. 179]
A decade after Bayes’ death and likely unaware of his discoveries, Laplace pursued similar problems and independently arrive at the same approach. Laplace revisited the famous problem of the points, but this time considered the case of a skilled game where the probability of a player winning a round was modeled by a Bernoulli distribution with unknown parameter p. Like Bayes, Laplace assumed a uniform prior, noting only
because the probability that A will win a point is unknown, we may suppose it to be any unspecified number whatever between 0 and 1. [6]
Unlike Bayes, though, Laplace did not use a geometric approach. He approached the problems with a much more developed analytical toolbox and was able to derive more usable formulas with integrals and clearer notation.
Following Laplace and up until the early 20th century, using a uniform prior together with Bayes’ theorem became a popular approach to statistical inference. In 1837, De Morgan introduced the term inverse probability to refer to such methods and acknowledged Bayes’ earlier work:
De Moivre, nevertheless, did not discover the inverse method. This was first used by the Rev. T. Bayes, in Phil. Trans. liii. 370.; and the author, though now almost forgotten, deserves the most honourable rememberance from all who read the history of this science. [7, p. vii]
In the early 20th century, inverse probability came under serious attack for its use of a uniform prior. Ronald Fisher, one of the fiercest critics, wrote
I know only one case in mathematics of a doctrine which has been accepted and developed by the most eminent men of their time, and is now perhaps accepted by men now living, which at the same time has appeared to a succession of sound writers to be fundamentally false and devoid of foundation. Yet that is quite exactly the position in respect of inverse probability [8]
Note: Fisher was not the first to criticize inverse probability, and he references the earlier works of Boole, Venn, and Chrystal. See [25] for a detailed account of inverse probability criticism leading up to Fisher.
Fisher criticized inverse probability as “extremely arbitrary”. Reviewing Bayes’ essay, he pointed out how naive use of a uniform prior leads to solutions that depend on the scale used to measure probability. He gave a concrete example [9]: Let p denote the unknown parameter for a binomial distribution. Suppose that instead of p we parameterize by
and apply the uniform prior. Then the probability that θ is between a and b after observing S successes and F failures is
A change of variables back to p shows us this is equivalent to
Hence, the uniform prior in θ is equivalent to the prior 1/π p^{−1/2} (1 − p)^{−1/2} in p. As an alternative to inverse probability, Fisher promoted maximum likelihood methods, p-values, and a frequentist definition for probability.
While Fisher and others advocated for abandoning inverse probability in favor of frequentist methods, Harold Jeffreys worked to put inverse probability on a firmer foundation. He acknowledged earlier approaches had lacked consistency, but he agreed with their goal of delivering statistical results in terms of degree of belief and thought frequentist definitions of probability to be hopelessly flawed:
frequentist definitions themselves lead to no results of the kind that we need until the notion of reasonable degree of belief is reintroduced, and that since the whole purpose of these definitions is to avoid this notion they necessarily fail in their object. [10, p. 34]
Jeffreys pointed out that inverse probability needn’t be tied to the uniform prior:
There is no more need for [the idea that the uniform distribution of
the prior probability was a necessary part of the principle of inverse probability] than there is to say that an oven that has once cooked roast beef can never cook anything but roast beef. [10, p. 103]
Seeking to achieve results that would be consistent under reparameterization, Jeffreys proposed priors based on the Fisher information matrix,
writing,
If we took the prior probability density for the parameters to be proportional to [(det I(θ))^{1/2}] … any arbitrariness in the choice of the parameters could make no difference to the results, and it is proved that for this wide class of laws a consistent theory of probability can be constructed. [10, p. 159]
Note: If Θ denotes a region of the parameter space and φ(u) is an injective continuous function whose range includes Θ, then applying the change-of-variables formula will show that
where I^φ denotes the Fisher information matrix with respect to the reparameterization, φ.
Twenty years later, Welch and Peers investigated priors from a different perspective [11]. They analyzed one-tailed credible sets from posterior distributions and asked how closely probability mass coverage matched frequentist coverage. They found that for the case of a single parameter, the prior Jeffreys proposed was asymptotically optimal, providing further justification for the prior that aligned with how intuition suggests we might quantify Bayes criterion of “knowing absolutely nothing”.
Note: Deriving good priors in the multi-parameter case is considerably more involved. Jeffreys himself was dissatisfied with the priors his rule produced for multi-parameter models and proposed an alternative known as Jeffreys independent prior but never developed a rigorous approach. José-Miguel Bernardo and James Berger would later develop reference priors as a refinement of Jeffreys prior. Reference priors provide a general mechanism to produce good priors that works for multi-parameter models and cases where the Fisher information matrix doesn’t exist. See [13] and [14, part 3].
In an unfortunate turn of events, mainstream statistics mostly ignored Jeffreys approach to inverse probability to chase a mirage of objectivity that frequentist methods seemed to provide.
Note: Development of inverse probability in the direction Jeffreys outlined continued under the name objective Bayesian analysis; however, it hardly occupies the center stage of statistics, and many people mistakenly think of Bayesian analysis as more of a subjective theory.
See [21] for background on why the objectivity that many perceive frequentist methods to have is largely false.
But much as Jeffreys had anticipated with his criticism that frequentist definitions of probability couldn’t provide “results of the kind that we need”, a majority of practitioners filled in the blank by misinterpreting frequentist results as providing belief probabilities. Goodman coined the term P value fallacy to refer to this common error and described just how prevalent it is
In my experience teaching many academic physicians, when physicians are presented with a single-sentence summary of a study that produced a surprising result with P = 0.05, the overwhelming majority will confidently state that there is a 95% or greater chance that the null hypothesis is incorrect. [12]
James Berger and Thomas Sellke established theoretical and simulation results that show how spectacularly wrong this notion is
it is shown that actual evidence against a null (as measured, say, by posterior probability or comparative likelihood) can differ by an order of magnitude from the P value. For instance, data that yield a P value of .05, when testing a normal mean, result in a posterior probability of the null of at least .30 for any objective prior distribution. [15]
They concluded
for testing “precise” hypotheses, p values should not be used directly, because they are too easily misinterpreted. The standard approach in teaching–of stressing the formal definition of a p value while warning against its misinterpretation–has simply been an abysmal failure. [16]
In this post, we’ll look closer at how priors for objective Bayesian analysis can be justified by matching coverage; and we’ll reexamine the problems Bayes and Laplace studied to see how they might be approached with a more modern methodology.
Priors and Frequentist Matching
The idea of matching priors intuitively aligns with how we might think about probability in the absence of prior knowledge. We can think of the frequentist coverage matching metric as a way to provide an answer to the question “How accurate are the Bayesian credible sets produced with a given prior?”.
Note: For more background on frequentist coverage matching and its relation to objective Bayesian analysis, see [17] and [14, ch. 5].
Consider a probability model with a single parameter θ. If we’re given a prior, π(θ), how do we test if the prior reasonably expresses Bayes’ requirement of knowing nothing? Let’s pick a size n, a value θ_true, and randomly sample observations y = (y1, . . ., yn)^T from the distribution P( · |θ_true). Then let’s compute the two-tailed credible set [θ_a, θ_b] that contains 95% of the probability mass of the posterior,
and record whether or not the credible set contains θ_true. Now suppose we repeat the experiment many times and vary n and θ_true. If π(θ) is a good prior, then the fraction of trials where θ_true is contained within the credible set will consistently be close to 95%.
Here’s how we might express this experiment as an algorithm:
function coverage-test(n, θ_true, α):
cnt ← 0
N ← a large number
for i ← 1 to N do
y ← sample from P(·|θ_true)
t ← integrate_{-∞}^θ_true π(θ | y)dθ
if (1 - α)/2 < t < 1 - (1 - α)/2:
cnt ← cnt + 1
end if
end for
return cnt / N
Example 1: a normal distribution with unknown mean
Suppose we observe n normally distributed values, y, with variance 1 and unknown mean, μ. Let’s consider the prior
Note: In this case Jeffreys prior and the constant prior in μ are the same.
Then
Thus,
I ran a 95% coverage test with 10000 trials and various values of μ and n. As the table below shows, the results are all close to 95%, indicating the constant prior is a good choice in this case. [Source code for example].
Example 2: a normal distribution with unknown variance
Now suppose we observe n normally distributed values, y, with unknown variance and zero mean, μ. Let’s test the constant prior and Jeffreys prior,
We have
where s²=y’y/n. Put u=ns²/(2σ²). Then
Thus,
Similarly,
The table below shows the results for a 95% coverage test with the constant prior. We can see that coverage is notably less than 95% for smaller values of n.
In comparison, coverage is consistently close to 95% for all values of n if we use Jeffreys prior. [Source code for example].
The Binomial Distribution Prior
Let’s apply Jeffreys approach to inverse probability to the binomial distribution.
Suppose we observe n values from the binomial distribution. Let y denote the number of successes and θ denote the probability of success. The likelihood function is given by
Taking the log and differentiating, we have
Thus, the Fisher information matrix for the binomial distribution is
and Jeffreys prior is
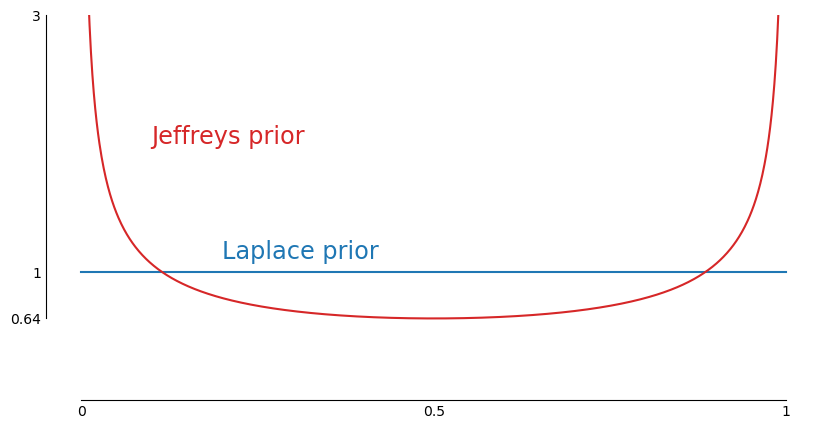
The posterior is then
which we can recognize as the beta distribution with parameters y+1/2 and n-y+1/2.
To test frequentist coverages, we can use an exact algorithm.
function binomial-coverage-test(n, θ_true, α):
cov ← 0
for y ← 0 to n do
t ← integrate_0^θ_true π(θ | y)dθ
if (1 - α)/2 < t < 1 - (1 - α)/2:
cov ← cov + binomial_coefficient(n, y) * θ_true^y * (1 - θ_true)^(n-y)
end if
end for
return cov
Here are the coverage results for α=0.95 and various values of p and n using the Bayes-Laplace uniform prior:
and here are the coverage results using Jeffreys prior:
We can see coverage is identical for many table entries. For smaller values of n and p_true, though, the uniform prior gives no coverage while Jeffreys prior provides decent results. [source code for experiment]
Applications from Bayes and Laplace
Let’s now revisit some applications Bayes and Laplace studied. Given that the goal in all of these problems is to assign a belief probability to an interval of the parameter space, I think that we can make a strong argument that Jeffreys prior is a better choice than the uniform prior since it has asymptotically optimal frequentist coverage performance. This also addresses Fisher’s criticism of arbitrariness.
Note: See [14, p. 105–106] for a more through discussion of the uniform prior vs Jeffreys prior for the binomial distribution
In each of these problems, I’ll show both the answer given by Jeffreys prior and the original uniform prior that Bayes and Laplace used. One theme we’ll see is that many of the results are not that different. A lot of fuss is often made over minor differences in how objective priors can be derived. The differences can be important, but often the data dominates and different reasonable choices will lead to nearly the same result.
Example 3: Observing Only 1s
In an appendix Richard Price added to Bayes’ essay, he considers the following problem:
Let us then first suppose, of such an event as that called M in the essay, or an event about the probability of which, antecedently to trials, we know nothing, that it has happened once, and that it is enquired what conclusion we may draw from hence with respct to the probability of it’s happening on a second trial. [4, p. 16]
Specifically, Price asks, “what’s the probability that θ is greater than 1/2?” Using the uniform prior in Bayes’ essay, we derive the posterior distribution
Integrating gives us the answer
Using Jeffreys prior, we derive a beta distribution for the posterior
and the answer
Price then continues with the same problem but supposes we see two 1s, three 1s, etc. The table below shows the result we’d get up to ten 1s. [source code]
Example 4: A Lottery
Price also considers a lottery with an unknown chance of winning:
Let us then imagine a person present at the drawing of a lottery, who knows nothing of its scheme or of the proportion of Blanks to Prizes in it. Let it further be supposed, that he is obliged to infer this from the number of blanks he hears drawn compared with the number of prizes; and that it is enquired what conclusions in these circumstances he may reasonably make. [4, p. 19–20]
He asks this specific question:
Let him first hear ten blanks drawn and one prize, and let it be enquired what chance he will have for being right if he gussses that the proportion of blanks to prizes in the lottery lies somewhere between the proportions of 9 to 1 and 11 to 1. [4, p. 20]
With Bayes prior and θ representing the probability of drawing a blank, we derive the posterior distribution
and the answer
Using Jeffreys prior, we get the posterior
and the answer
Price then considers the same question (what’s the probability that θ lies between 9/10 and 11/12) for different cases where an observer of the lottery sees w prizes and 10w blanks. Below I show posterior probabilities using both Bayes’ uniform prior and Jeffreys prior for various values of w. [source code]
Example 5: Birth Rates
Let’s now turn to a problem that fascinated Laplace and his contemporaries: The relative birth rate of boys-to-girls. Laplace introduces the problem,
The consideration of the [influence of past events on the probability of future events] leads me to speak of births: as this matter is one of the most interesting in which we are able to apply the Calculus of probabilities, I manage so to treat with all care owing to its importance, by determining what is, in this case, the influence of the observed events on those which must take place, and how, by its multiplying, they uncover for us the true ratio of the possibilities of the births of a boy and of a girl. [18, p. 1]
Like Bayes, Laplace approaches the problem using a uniform prior, writing
When we have nothing given a priori on the possibility of an event, it is necessary to assume all the possibilities, from zero to unity, equally probable; thus, observation can alone instruct us on the ratio of the births of boys and of girls, we must, considering the thing only in itself and setting aside the events, to assume the law of possibility of the births of a boy or of a girl constant from zero to unity, and to start from this hypothesis into the different problems that we can propose on this object. [18, p. 26]
Using data collection from Paris between 1745 and 1770, where 251527 boys and 241945 girls had been born, Laplace asks, what is “the probability that the possibility of the birth of a boy is equal or less than 1/2“?
With a uniform prior, B = 251527, G = 241945, and θ representing the probability that a boy is born, we obtain the posterior
and the answer
With Jeffreys prior, we similarly derive the posterior
and the answer
Here’s some simulated data using p_true = B / (B + G) that shows how the answers might evolve as more births are observed.
Discussion
Q1: Where does objective Bayesian analysis belong in statistics?
I think Jeffreys was right and standard statistical procedures should deliver “results of the kind we need”. While Bayes and Laplace might not have been fully justified in their choice of a uniform prior, they were correct in their objective of quantifying results in terms of degree of belief. The approach Jeffreys outlined (and was later evolved with reference priors) gives us a pathway to provide “results of the kind we need” while addressing the arbitrariness of a uniform prior. Jeffreys approach isn’t the only way to get to results as degrees of belief, and a more subjective approach can also be valid if the situation allows, but his approach give us good answers for the common case “of an event concerning the probability of which we absolutely know nothing” and can be used as a drop-in replacement for frequentist methods.
To answer more concretely, I think when you open up a standard introduction-to-statistics textbook and look up a basic procedure such as a hypothesis test of whether the mean of normally distributed data with unknown variance is non-zero, you should see a method built on objective priors and Bayes factor like [19] rather than a method based on P values.
Q2: But aren’t there multiple ways of deriving good priors in the absence of prior knowledge?
I highlighted frequentist coverage matching as a benchmark to gauge whether a prior is a good candidate for objective analysis, but coverage matching isn’t the only valid metric we could use and it may be possible to derive multiple priors with good coverage. Different priors with good frequentist properties, though, will likely be similar, and any results will be determined more by observations than the prior. If we are in a situation where multiple good priors lead to significantly differing results, then that’s an indicator we need to provide subjective input to get a useful answer. Here’s how Berger addresses this issue:
Inventing a new criterion for finding “the optimal objective prior” has proven to be a popular research pastime, and the result is that many competing priors are now available for many situations. This multiplicity can be bewildering to the casual user.
I have found the reference prior approach to be the most successful approach, sometimes complemented by invariance considerations as well as study of frequentist properties of resulting procedures. Through such considerations, a particular prior usually emerges as the clear winner in many scenarios, and can be put forth as the recommended objective prior for the situation. [20]
Q3. Doesn’t that make inverse probability subjective, whereas frequentist methods provide an objective approach to statistics?
It’s a common misconception that frequentist methods are objective. Berger and Berry provides this example to demonstrate [21]: Suppose we watch a research study a coin for bias. We see the researcher flip the coin 17 times. Heads comes up 13 times and tails comes up 4 times. Suppose θ represents the probability of heads and the researcher is doing a standard P-value test with the null hypothesis that the coin is not bias, θ=0.5. What P-value would they get? We can’t answer the question because the researcher would get remarkably different results depending on their experimental intentions.
If the researcher intended to flip the coin 17 times, then the probability of seeing a value less extreme than 13 heads under the null hypothesis is given by summing binomial distribution terms representing the probabilities of getting 5 to 12 heads,
which gives us a P-value of 1–0.951=0.049.
If, however, the researcher intended to continue flipping until they got at least 4 heads and 4 tails, then the probability of seeing a value less extreme than 17 total flips under the null hypothesis is given by summing negative binomial distribution terms representing the probabilities of getting 8 to 16 total flips,
which gives us a P-value of 1–0.979=0.021
The result is dependent on not just the data but also on the hidden intentions of the researcher. As Berger and Berry argue “objectivity is not generally possible in statistics and … standard statistical methods can produce misleading inferences.” [21] [source code for example]
Q4. If subjectivity is unavoidable, why not just use subjective priors?
When subjective input is possible, we should incorporate it. But we should also acknowledge that Bayes’ “event concerning the probability of which we absolutely know nothing” is an important fundamental problem of inference that needs good solutions. As Edwin Jaynes writes
To reject the question, [how do we find the prior representing “complete ignorance”?], as some have done, on the grounds that the state of complete ignorance does not “exist” would be just as absurd as to reject Euclidean geometry on the grounds that a physical point does not exist. In the study of inductive inference, the notion of complete ignorance intrudes itself into the theory just as naturally and inevitably as the concept of zero in arithmetic.
If one rejects the consideration of complete ignorance on the grounds that the notion is vague and ill-defined, the reply is that the notion cannot be evaded in any full theory of inference. So if it is still ill-defined, then a major and immediate objective must be to find a precise definition which will agree with intuitive requirements and be of constructive use in a mathematical theory. [22]
Moreover, systematic approaches such as reference priors can certainly do much better than pseudo-Bayesian techniques such as choosing a uniform prior over a truncated parameter space or a vague proper prior such as a Gaussian over a region of the parameter space that looks interesting. Even when subjective information is available, using reference priors as building blocks is often the best way to incorporate it. For instance, if we know that a parameter is restricted to a certain range but don’t know anything more, we can simply adapt a reference prior by restricting and renormalizing it [14, p. 256].
Note: The term pseudo-Bayesian comes from [20]. See that paper for a more through discussion and comparison with objective Bayesian analysis.
Conclusion
The common and repeated misinterpretation of statistical results such as P values or confidence intervals as belief probabilities shows us that there is a strong natural tendency to want to think about inference in terms of inverse probability. It’s no wonder that the method dominated for 150 years.
Fisher and others were certainly correct to criticize naive use of a uniform prior as arbitrary, but this is largely addressed by reference priors and adopting metrics like frequentist matching coverage that quantify what it means for a prior to represent ignorance. As Berger puts it,
We would argue that noninformative prior Bayesian analysis is the single most powerful method of statistical analysis, in the sense of being the ad hoc method most likely to yield a sensible answer for a given investment of effort. And the answers so obtained have the added feature of being, in some sense, the most “objective” statistical answers obtainable [23, p. 90]
Notes & References
[1]: Problem of the points: Suppose two players A and B each contribute an equal amount of money into a prize pot. A and B then agree to play repeated rounds of a game of chance, with the players having an equal probability of winning any round, until one of the players has won k rounds. The player that first reaches k wins takes the entirety of the prize pot. Now, suppose the game is interrupted with neither player reaching k wins. If A has w_A wins and B has w_B wins, what’s a fair way to split the pot?
[2]: Bernoulli, J. (1713). On the Law of Large Numbers, Part Four of Ars Conjectandi. Translated by Oscar Sheynin.
[3]: De Moivre, A. (1756). The Doctrine of Chances.
[4]: Bayes, T. (1763). An essay towards solving a problem in the doctrine of chances. by the late rev. mr. bayes, f. r. s. communicated by mr. price, in a letter to john canton, a. m. f. r. s. Philosophical Transactions of the Royal Society of London 53, 370–418.
[5]: Stigler, S. (1990). The History of Statistics: The Measurement of Uncer- tainty before 1900. Belknap Press.
[6]: Laplace, P. (1774). Memoir on the probability of the causes of events. Translated by S. M. Stigler.
[7]: De Morgan, A. (1838). An Essay On Probabilities: And On Their Application To Life Contingencies And Insurance Offices.
[8]: Fisher, R. (1930). Inverse probability. Mathematical Proceedings of the Cambridge Philosophical Society 26(4), 528–535.
[9]: Fisher, R. (1922). On the mathematical foundations of theoretical statistics. Philosophical Transactions of the Royal Society of London. Series A, Containing Papers of a Mathematical or Physical Character 222, 309–368.
[10]: Jeffreys, H. (1961). Theory of Probability (3 ed.). Oxford Classic Texts in the Physical Sciences.
[11]: Welch, B. L. and H. W. Peers (1963). On formulae for confidence points based on integrals of weighted likelihoods. Journal of the Royal Statistical Society Series B-methodological 25, 318–329.
[12]: Goodman, S. (1999, June). Toward evidence-based medical statistics. 1: The p value fallacy. Annals of Internal Medicine 130 (12), 995–1004.
[13]: Berger, J. O., J. M. Bernardo, and D. Sun (2009). The formal definition of reference priors. The Annals of Statistics 37 (2), 905–938.
[14]: Berger, J., J. Bernardo, and D. Sun (2024). Objective Bayesian Inference. World Scientific.
[15]: Berger, J. and T. Sellke (1987). Testing a point null hypothesis: The irreconcilability of p values and evidence. Journal of the American Statistical Association 82(397), 112–22.
[16]: Selke, T., M. J. Bayarri, and J. Berger (2001). Calibration of p values for testing precise null hypotheses. The American Statistician 855(1), 62–71.
[17]: Berger, J., J. Bernardo, and D. Sun (2022). Objective bayesian inference and its relationship to frequentism.
[18]: Laplace, P. (1778). Mémoire sur les probabilités. Translated by Richard J. Pulskamp.
[19]: Berger, J. and J. Mortera (1999). Default bayes factors for nonnested hypothesis testing. Journal of the American Statistical Association 94 (446), 542–554.
[20]: Berger, J. (2006). The case for objective Bayesian analysis. Bayesian Analysis 1(3), 385–402.
[21]: Berger, J. O. and D. A. Berry (1988). Statistical analysis and the illusion of objectivity. American Scientist 76(2), 159–165.
[22]: Jaynes, E. T. (1968). Prior probabilities. Ieee Transactions on Systems and Cybernetics (3), 227–241.
[23]: Berger, J. (1985). Statistical Decision Theory and Bayesian Analysis. Springer.
[24]: The portrait of Thomas Bayes is in the public domain; the portrait of Pierre-Simon Laplace is by Johann Ernst Heinsius (1775) and licensed under Creative Commons Attribution-Share Alike 4.0 International; and use of Harold Jeffreys portrait qualifies for fair use.
[25]: Zabell, S. (1989). R. A. Fisher on the History of Inverse Probability. Statistical Science 4(3), 247–256.
An Introduction to Objective Bayesian Inference was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
An Introduction to Objective Bayesian Inference
Go Here to Read this Fast! An Introduction to Objective Bayesian Inference

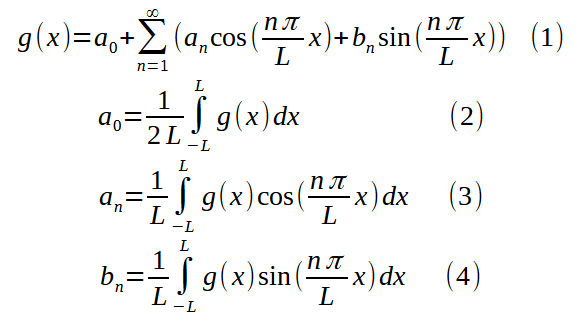

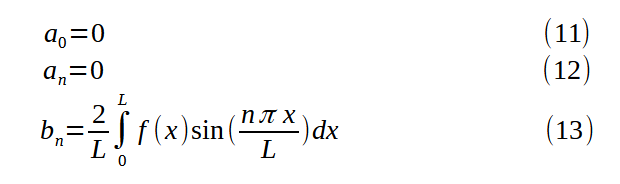



















{kind=link}
.jpg){kind=link}
{kind=link}