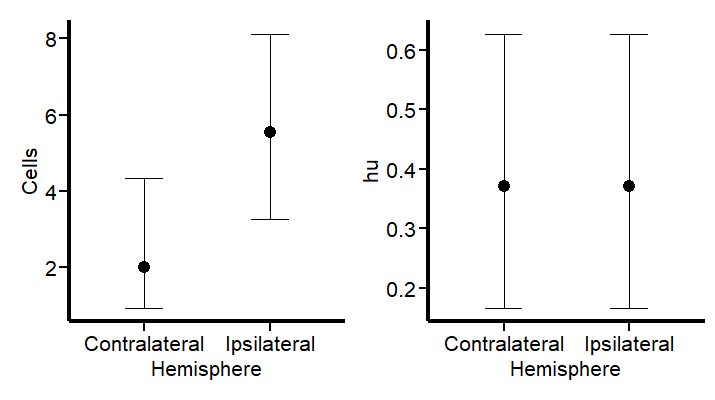
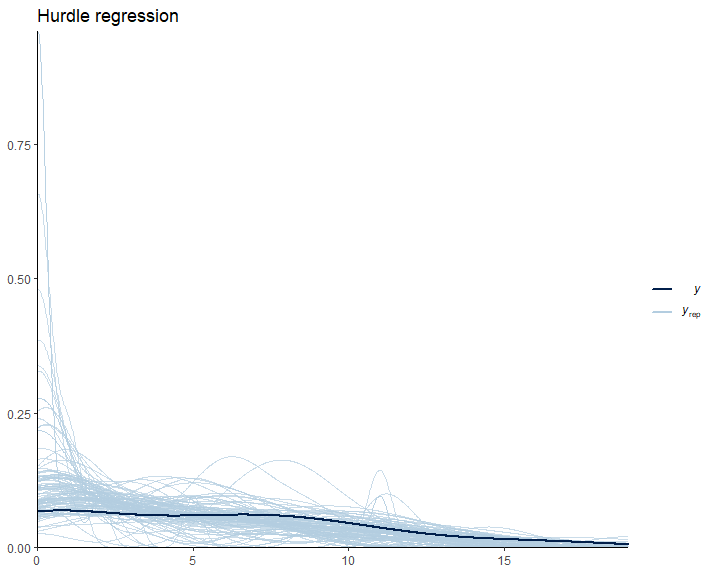
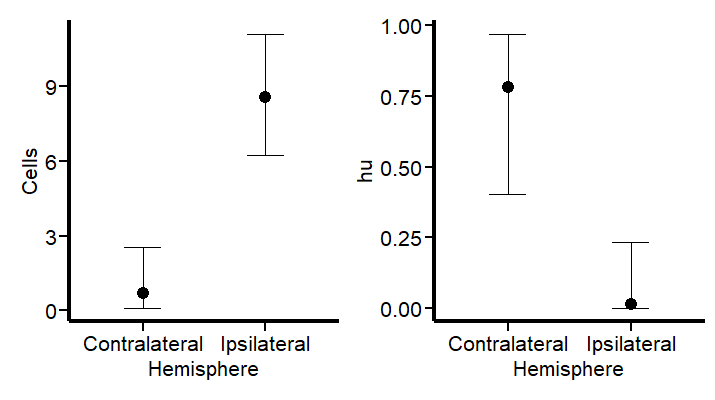
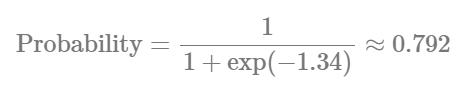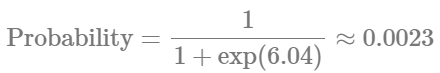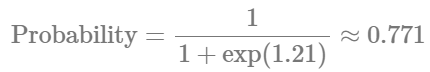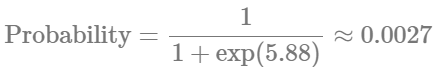AI solutions aren’t just a tool approach; it’s about well-understood use cases and ways to measure their impact
The world we are shaping around AI includes different types of organizations: those building sophisticated AI technologies, others developing AI-based solutions, and finally, organizations that aim to use AI for positive impact or to support their businesses. When initiatives to deploy AI in the last group take place, capacity building and training are mostly oriented towards technical infrastructure, data ecosystems or technical skills; and although its significance is indisputable, we fail to understand that in most cases, AI solutions aren’t just a tool approach; it’s about well-understood use cases and ways to measure their impact. This guide aims to be useful to anyone leading AI initiatives and to complement any strategy aimed to enhance innovation capabilities through AI.
“AI is not about its capabilities and promises, but also about how its used…” (The age of AI: And our Human Future -Kissinger, Schmidt, Huttenlocher)
Every process of innovation through artificial intelligence consists of two parts: capturing knowledge and utilizing knowledge. This guide aims to demonstrate the strong relationship between both and the five dimensions that compose them (Use Cases, Early Wins, People, Technology, and Governance). Although they can independently coexist, together, they can significantly improve the chances of identifying and deploying AI-based solutions to make a substantial impact.
I would like to clarify the intended scope of this guide. There is a lot of good work on this topic by consulting firms (Deloitte, McKinsey, BCG, Gartner, to name a few) and companies in the private sector or independent research ( Catalyst Fund,Profit.co,Dorien Herremans , to name a few). Therefore, it’s not my intention to present another bespoke conceptual framework or reinvent the wheel. In fact, some of the steps presented may sound very familiar to anyone leading an AI practice in a B2B tech consulting company. My intention is to move away from the abstraction of a conceptual framework and attempt to operationalize a set of steps with some tools that can help companies significantly improve their chances of identifying and deploying AI-based solutions to make a substantial impact.
01: It’s all about Use Cases
It’s not an AI tool approach; it’s all about USE CASES. This means that to increase our success rate on our AI project, we must identify real problems that affect our end users or the company we are working with. This really isn’t anything new, as most frameworks around AI strategy emphasize the importance of identifying good business cases as a starting point.
This part is what I call “capturing knowledge”, and although everyone recognizes it as an important step, there is little information about the “How?” to do it. For this guide, I divide this capturing knowledge step into two dimensions: The identifying process and the prioritization process, which specifies parameters to help select which use case could be more relevant to engage with, and achieve Early Wins.
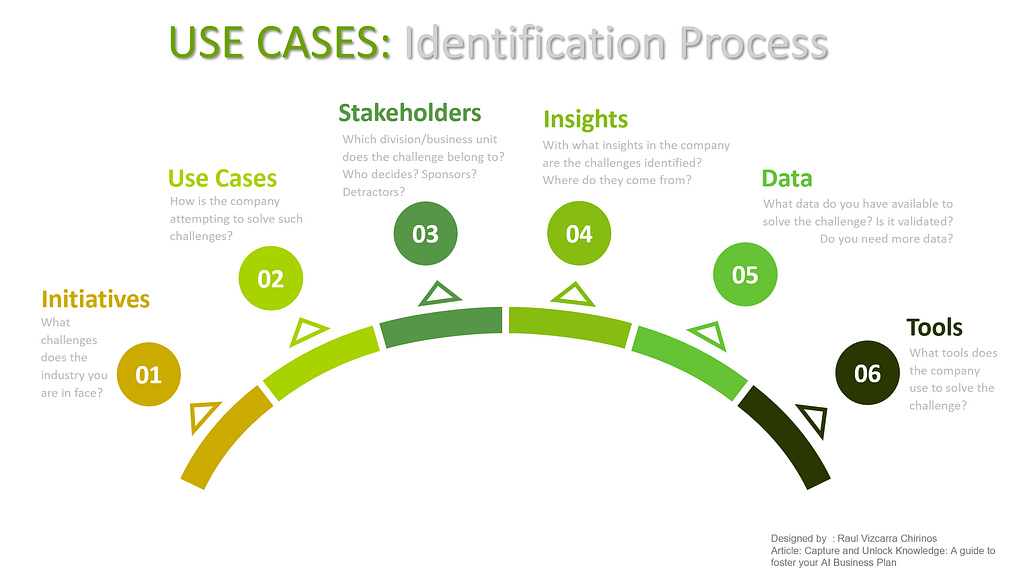
How to identify good opportunities to deploy AI?
01) Initiatives: What challenges does the industry you are in face?
02) Use Cases: How is the company attempting to solve such challenges?
03) Stakeholders: Which division/business unit does the challenge belong to? Who decides? Sponsors? Detractors?
04) Insights: With what insights in the company are the challenges identified? Where do they come from?
05) Data: What data do you have available to solve the challenge? Is it validated? Do you need more data?
06) Tools: What tools (technology) does the company use to solve the challenge?
02: Early Wins & Gains
Every development follows an adoption curve; technology moves faster than the capacity of human beings to adopt it, and much faster than companies’ adaptation to this new customer behavior. This is kind of the essence of the “Collingridge Dilemma”, but it’s also relevant for understanding success in AI initiatives.
Trajectories differ among companies; large corporations may have more tolerance for research, testing, and failure at the beginning in order to achieve significant results or radical innovations around AI. However, as mentioned before, many organizations are willing to use AI to support their businesses but face different dynamics, such as limited budgets and less tolerance for waiting for results. But Early wins aren’t just about profit or quick success, extracting some concepts from Kotter’s Change Management Framework, it’s about building momentum that excites people to pursue a common vision, to do things they’ve never done before, and to inspire discovery.

Early wins and gains can be viewed from two different perspectives. From a business goal perspective, basic ideas have stayed the same in companies over time, any project that generates increased sales or reduces costs is always a good fit. Therefore, any AI initiative that demonstrates (meaning evidence with measurable data) the ability to drive efficiency, enable automation, or make predictions to accelerate decision-making processes would be a good place to start. From a Use Case perspective, it’s important to consider that NOT everything needs to be solved with AI, projects that can’t be addressed through traditional means, are data-rich, or involve large amounts of labor are likely to be well received. Finally, don’t forget that early executive buy-in is important; a strong endorsement can be the difference between reaching the deployment stage or getting stuck in the middle of the journey.
“Wins are the molecules of results. They must be recognized, collected, and communicated — early and often — to track progress and energize volunteers to persist”. (The 8 Steps for Leading Change-John Kotter)
03: A Team Committed to Continuous Learning
Although it may sound like a cliché, people and skills are important, and almost every framework emphasizes it. However, while the size and expertise of the team will depend on the size of the company or budget, the velocity at which the team identifies potential AI initiatives to pursue and deploy them will exclusively depend on what I call “Continuous Learning”, inspired by the continuity concept behind practices like DevOps or MLOps and Peter Senge’s “The Learning Organization”. Let’s deconstruct the concept:

The Skills You Have Vs. the Skills You Need: The artificial intelligence field encompasses a diverse range of skills and roles. As you begin to identify good AI initiatives, you may find situations where your team lacks the necessary skills to execute them. In the early stages of developing an AI Business Plan, focus on leveraging the skills that enable you to design, validate, and deploy “Early Wins”. Then, as these Early Wins are deployed, credibility is gained, and AI initiatives become more challenging, transition to acquire or develop more sophisticated skills.
Awareness and Rituals: AI initiatives are neither a one-shot game nor a one-man show. It’s about continuously feeding the team with ideas to evaluate and pursue; some will succeed, and some may fail, but you need a pipeline of ideas continuously flowing. Primarily, you should have AI Initiatives flowing through three types of stages: Planting (stage of research, where the company’s Pains/Gains that could be resolved with AI are discussed), Growth (initiatives approved to proceed to a design, testing, or validation process), and Harvest (initiatives deployed and ready to scale or be replicated).
To establish a funnel of AI initiatives continuously flowing through each stage, include in your AI business plan an assessment to identify:
01) How does the team capture AI initiatives?
02) How do the teams collaborate with other teams in the company, customers or end users to identify AI initiatives?
03) How are relevant initiatives prioritized? Who determines their relevance?
04) How are new AI initiatives tested or validated? How is the acquired knowledge documented and shared?

The message is, Get out of the building! Organize daily meetings within the team and workshops with other business units, schedule visits with your customers and end users (not to sell them, but to understand their business pains) and conduct workshops with them as well.
Remember that a funnel of AI initiatives is like a muscle; a continuous learning culture isn’t built in just one day. With that said, practices shouldn’t be done just once, but frequently, in order to transform awareness and rituals into attitudes and beliefs. In the long run, attitudes and beliefs are the ones that inspire discovery and push you to develop new capabilities and explore new grounds where you haven’t yet applied AI. One thing is for sure, if you don’t train the muscle frequently, ideas will stop flowing.
04: Technology
In technology, budget will be a limitation but not a restriction. Fortunately, we are living in exciting times in AI development, so for computing, modeling, testing, and deployment, you could benefit from either the open-source ecosystem built around AI or the free tiers offered by some service providers (Google, AWS, Azure, IBM cloud, Oracle cloud). While these come with restrictions, they can help with the research, design, and testing stages, which we aim to accelerate to validate good use cases for deployment.
So, what we aim to achieve is convenience; either building something from scratch to have full control over the architecture or leveraging pre-developed use cases and consuming them as a service, either entirely or as part of a mixed architecture. Inspired by the multi-step strategy playbook for managing digital disruption developed by the IMD-Digital Business Transformation Center, the following dimensions could help you choose the best technology to start with and how to scale:

If you lead a small AI business unit or building one that needs to achieve “Erly Wins” quickly, perhaps your best option would be to leverage the open-source ecosystem, pre-built models, or prebuilt solutions. Rather than aiming for radical disruption with AI, aim for incremental benefits by using what has already been proven and tested. This approach is faster for validating ideas and designing, testing, and deploying AI initiatives, which is essential in the early stages to build confidence among your stakeholders for pursuing later disruptive challenges.
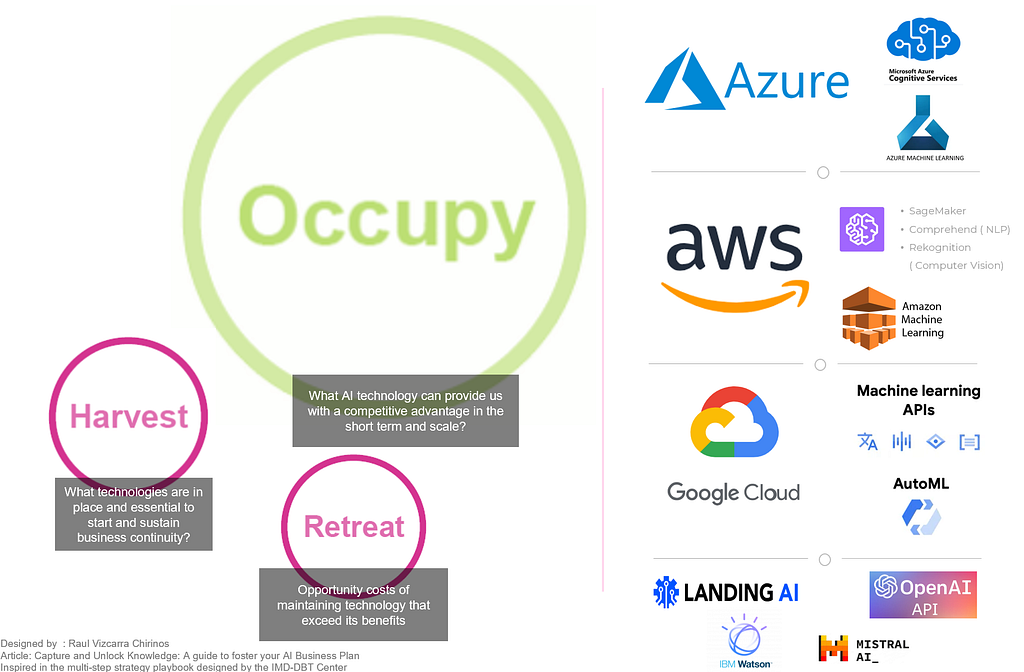
If there is some flexibility in waiting for early successes (Early Wins), your best bet could be to start from scratch rather than using pre-existing solutions. While this approach can offer significant rewards in the long term, it also presents challenges in terms of managing feasibility, time constraints, and value. Results can wait, but they must be visible when the time comes.

Keep in mind that you can also achieve “Early Wins” when building AI initiatives from scratch (It’s all about use cases). For example, Python has lots of resources for developing supervised machine learning models, such as forecasting time series or predicting the probability of events like customer purchases, bill payments, or churn models for customer retention (Take into account that implementing these models will require your team to be stronger in statistical inference and modeling rather than technology). If your AI initiative involves unstructured data like text or videos, tools like PyTorch or the Hugging Face community offer open-source models for projects requiring text processing or video and image recognition. (If you’re interested, here are some examples: this one involves using Python for text processing and sentiment analysis, while this one utilizes Hugging Face resources for video analysis)
Finally, while carrying out your technology assessment for your AI Business Plan, there are two considerations you must take into account:
01) Balance between Skills and Technology: The technical skills that your team currently has, as well as those being developed, must align with the technology needed in the short term for Early Wins and the technology planned for future use. It goes both ways, if you intend to utilize a specific technology, ensure that your team has the appropriate skills to manage it or the ability to learn it quickly. Technical skills can be found in the labor market (depending on the technical skills required, they may come at a price) or developed internally, but requires time, and time is a constraint when pursuing Early Wins.
02) Wide Funnel-Fast Testing: The balance between validated AI initiatives, People, and Technology should result in a broad funnel of AI initiatives, big in opportunities and efficient in testing speed. The portfolio should continuously include a mix of AI initiatives: Incremental AI initiatives for early wins and a steady stream of income, Evolutionary AI initiatives to replicate successful deployments in other markets, and Disruptive AI initiatives to remain at the forefront and anticipate future trends. The portfolio-mix depends on the tolerance for waiting for early wins. AI is not a solitary endeavor; it involves managing a portfolio of AI initiatives. The key is to continually expand the funnel and shorten the testing process so that AI initiatives can be tested and deployed quickly at low cost.(For further insights on managing an innovation portfolio, consider reading this article)
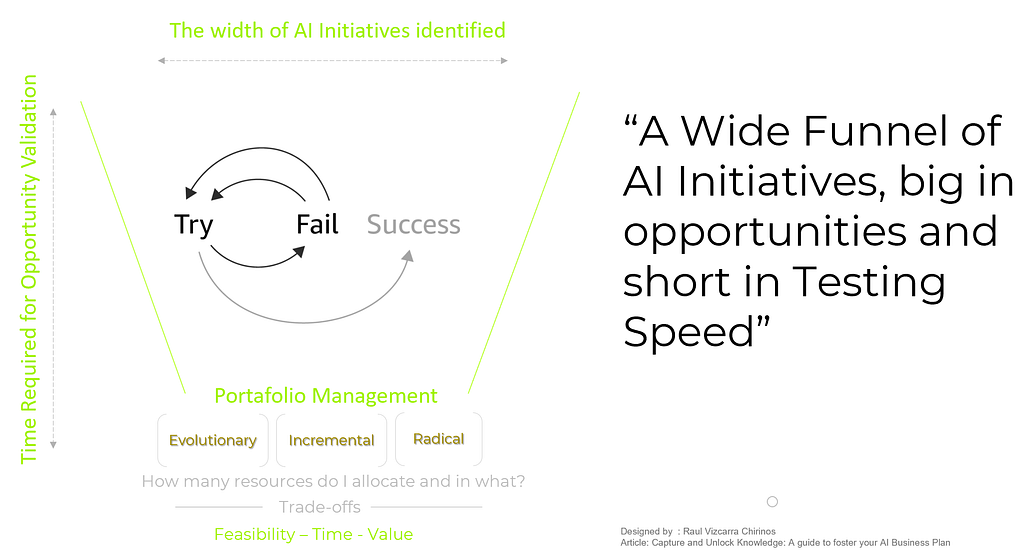
05: Governance
A famous quote states, “Normal is an illusion; what is normal for the spider is chaos for the fly”. Recent years have highlighted the reality that we live in uncertain and dynamic business environments, where resilience and the ability to adapt quickly are essential assets. Applied to AI initiatives, this means that in order to deploy and scale rapidly, we need Machine Learning pipelines that are efficient, support frequent execution, and are reliable. For data management, good work has been done with frameworks like DAMA-DMBOK and DataOps, and for AI, we have MLOps.
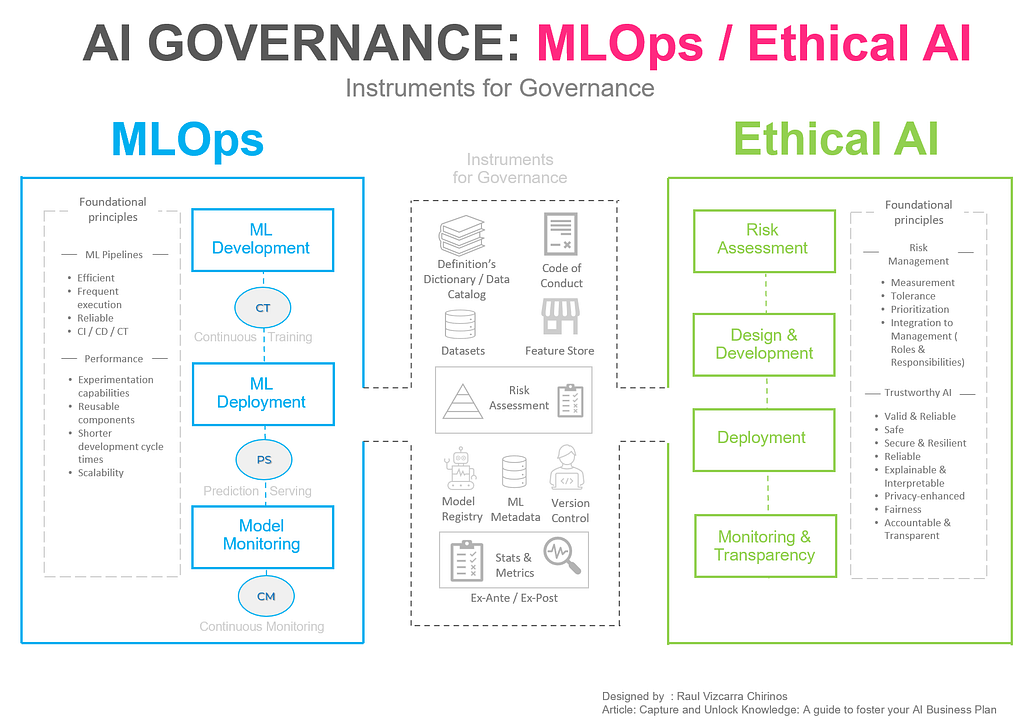
MLOps: Deployment presents challenges such as potential issues with the handoff between Data Scientists and IT teams, tracking of the development stage, and impacts produced by changes in data or model drifting. With MLOps, we gain several benefits. First, in the Development stage, it’s all about “experimentation” (data exploration, feature engineering, model prototyping, and validation) while keeping records and knowledge of this process. Second, in version controlling, we answer questions like who?, why?, and how? for future compliance and reusable components (such as a feature store for data). Lastly, in monitoring for changes in data or model deviations and ensuring model fairness. You can find a useful guide in Google’s Practitioners Guide to MLOps.
Ethical AI Governance: Another issue related to AI governance is compliance. While the debate on regulatory frameworks is ongoing (with some in the final stages of implementation), companies can begin with self-regulated frameworks for risk assessment, controlled testing environments, development protocols, and ongoing monitoring to achieve ethical and responsible AI deployments. In this article, I share some ideas of a self-regulated framework based on the EU AI Act that could be useful for your AI business plan. Another valuable resource that is essential to read for guidance is the Artificial Intelligence Risk Management Framework from the US National Institute of Standards and Technology (NIST).
FINAL THOUGHT
The idea of human-like machines has always fascinated humanity, as described in a 2022 essay by Erik Brynjolfsson from Stanford University, where he also discusses its economic impacts, emphasizing the benefits of augmenting human capabilities over mere automation. Both automation and augmentation foster productivity; the difference is that the latter pushes humankind to do things they never could before, inspiring discovery and boosting living standards.
It’s certain that we will continue to search for technology that replicates human behavior. The difference lies in how we perceive concepts like automation and AI. Focusing only on mimicking the world as it is, overlooks all the new things that we can make with AI to shape a better tomorrow.
Thank you for reading!, Did I miss anything? Your suggestions are always welcome and keep the conversation going.
Capture and Unlock Knowledge: A guide to foster your AI Business Plan was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Capture and Unlock Knowledge: A guide to foster your AI Business Plan
Go Here to Read this Fast! Capture and Unlock Knowledge: A guide to foster your AI Business Plan