Explore the nuances of the transformer architecture behind Llama 3 and its prospects for the GenAI ecosystem
Image by author (The shining LlaMA 3 rendition by my 4-year old.)
“In the rugged mountain of the Andes, lived three very beautiful creatures — Rio, Rocky and Sierra. With their lustrous coat and sparkling eyes, they stood out as a beacon of strength and resilience.
As the story goes, it was said that from a very young age their thirst for knowledge was never-ending. They would seek out the wise elders of their herd, listening intently to their stories and absorbing their wisdom like a sponge. With that grew their superpower which was working together with others and learning that teamwork was the key to acing the trials in the challenging terrain of the Andes.
If they encountered travelers who had lost their way or needed help, Rio took in their perspective and led them with comfort, Rocky provided swift solutions while Sierra made sure they had the strength to carry on. And with this they earned admiration and encouraged everyone to follow their example.
As the sun set over the Andes, Rio, Rocky, and Sierra stood together, their spirits intertwined like the mountains themselves. And so, their story lived on as a testament to the power of knowledge, wisdom and collaboration and the will to make a difference.
They were the super-Llamas and the trio was lovingly called LlaMA3!”
LlaMA 3 by Meta
And this story is not very far from the story of Meta’s open-source Large Language Model (LLM) — LlaMA 3 (Large Language Model Meta AI). On April 18, 2024, Meta released their LlaMa 3 family of large language models in 8B and 70B parameter sizes, claiming a major leap over LlaMA 2 and vying for the best state-of-the-art LLM models at that scale.
According to Meta, there were four key focus points while building LlaMA 3 — the model architecture, the pre-training data, scaling up pre-training, and instruction fine-tuning. This leads us to ponder what we can do to reap the most out of this very competent model — on an enterprise scale as well as at the grass-root level.
To help explore the answers to some of these questions, I collaborated with Edurado Ordax, Generative AI Lead at AWS and Prof. Tom Yeh, CS Professor at University of Colorado, Boulder.
So, let’s start the trek:
How can we leverage the power of LlaMA 3?
API vs Fine-Tuning
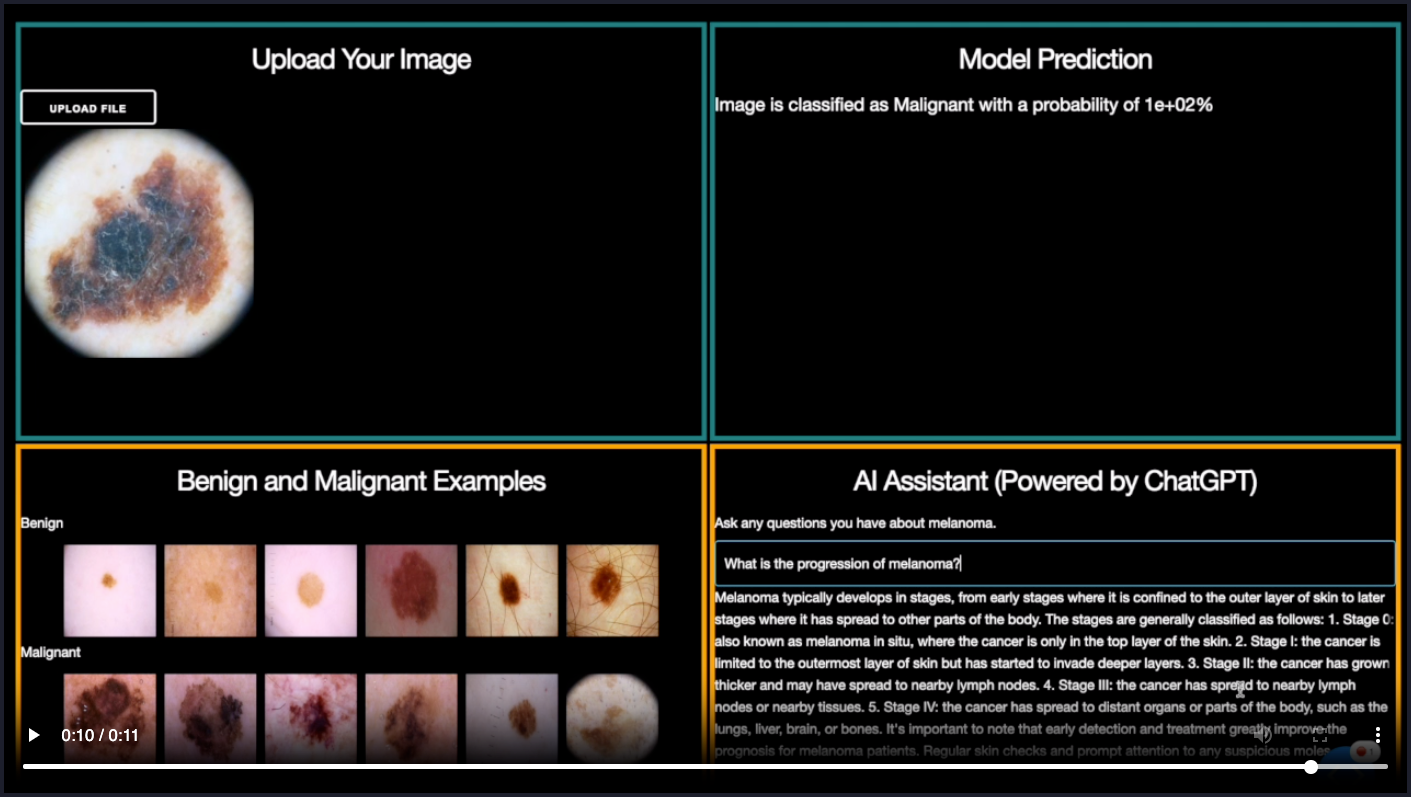
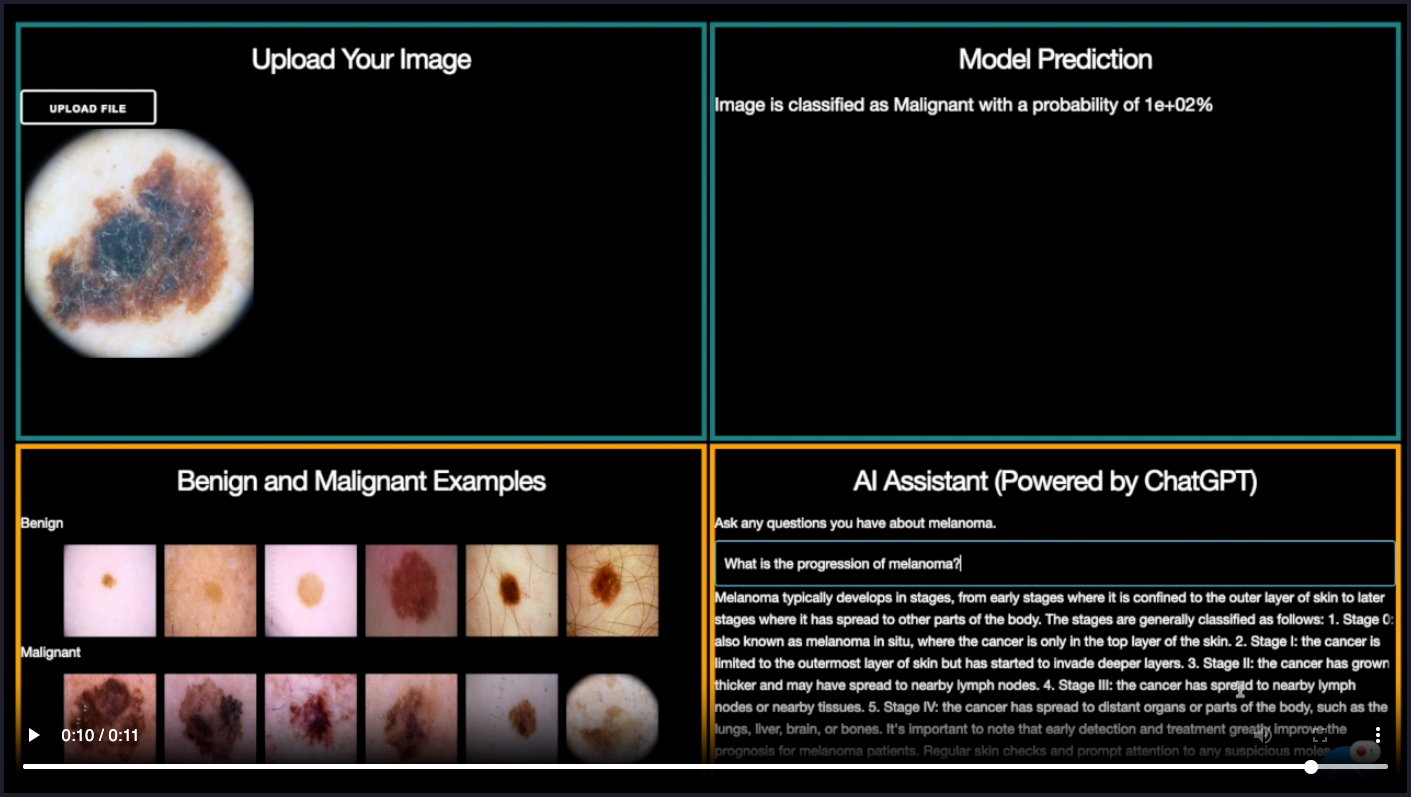
As per the recent practices, there are two main ways by which these LLMs are being accessed and worked with — API and Fine-Tuning. Even with those two very diverse approaches there are other factors in the process, as can be seen in the following images, that become crucial.
(All images in this section are courtesy to Eduardo Ordax.)
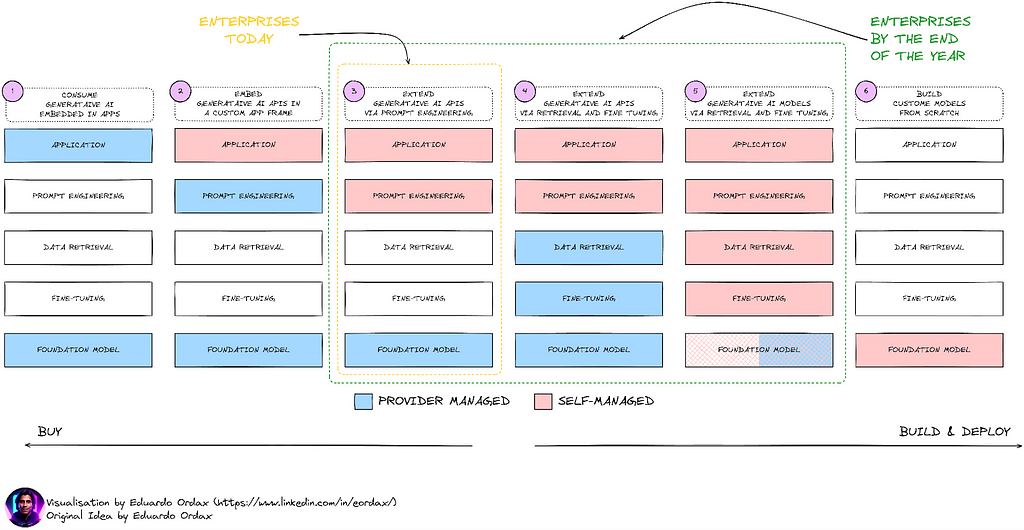
There are mainly 6 stages of how a user can interact with LlaMA 3.
Stage 1 : Cater to a broad-case usage by using the model as is.
Stage 2 : Use the model as per a user-defined application.
Stage 3 : Use prompt-engineering to train the model to produce the desired outputs.
Stage 4 : Use prompt-engineering on the user side along with delving a bit into data retrieval and fine-tuning which is still mostly managed by the LLM provider.
Stage 5 : Take most of the matters in your own hand (the user), starting from prompt-engineering to data retrieval and fine-tuning (RAG models, PEFT models and so on).
Stage 6 : Create the entire foundational model starting from scratch — pre-training to post-training.
To gain the most out of these models, it is suggested that the best approach would be entering Stage 5 because then the flexibility lies a lot with the user. Being able to customize the model as per the domain-need is crucial in order to maximize its gains. And for that, not getting involved into the systems does not yield optimal returns.
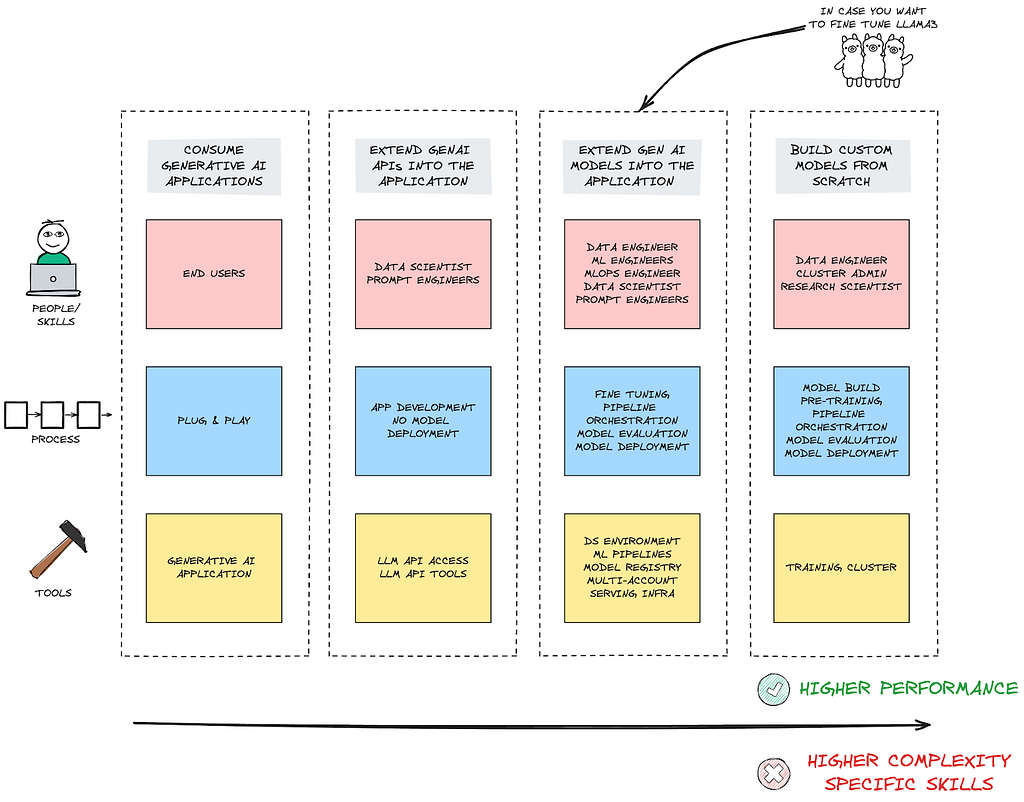
To be able to do so, here is a high-level picture of the tools that could prove to be useful:
The picture dictates that in order to get the highest benefit from the models, a set structure and a road map is essential. There are three components to it:
People: Not just end-users, but the whole range of data engineers, data scientists, MLOps Engineers, ML Engineers along with Prompt Engineers are important.
Process: Not just plugging in the LLM into an API but focusing on the entire lifecycle of model evaluation, model deployment and fine-tuning to cater to specific needs.
Tools: Not just the API access and API tools but the entire range of environments, different ML pipelines, separate accounts for access and running checks.
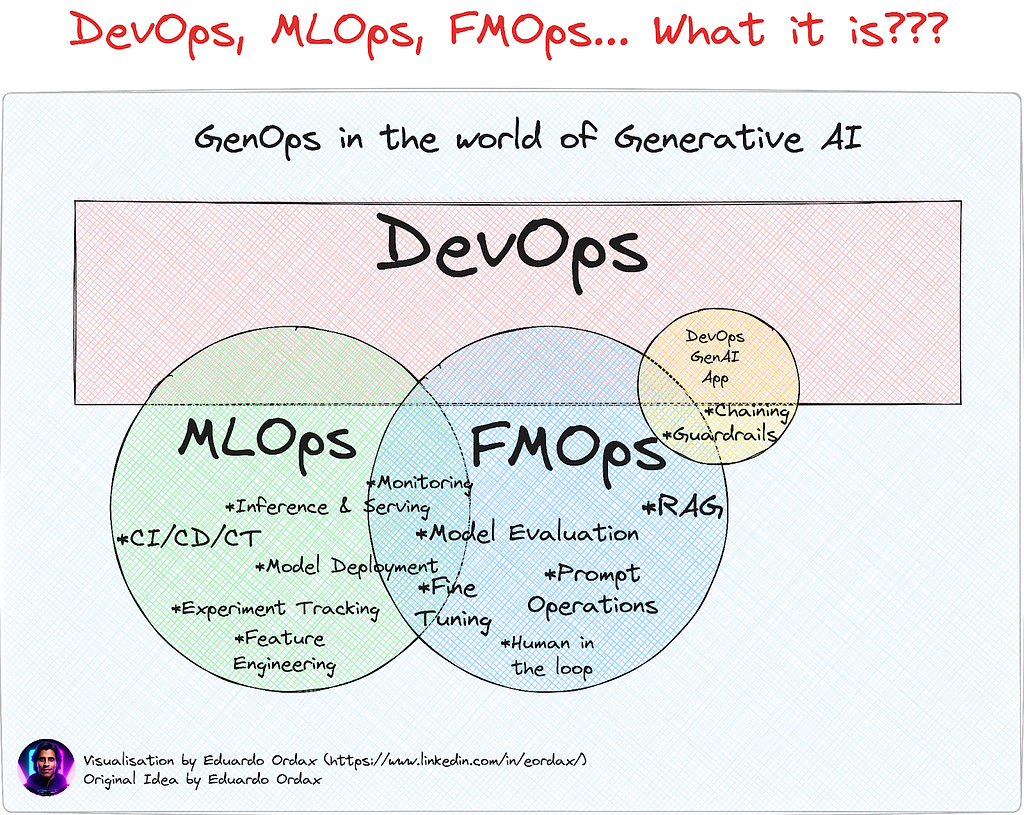
Of course, this is true for an enterprise-level deployment such that the actual benefits of the model can be reaped. And to be able to do so, the tools and practices under MLOps become very important. Combined with FMOps, these models can prove to be very valuable and enrich the GenAI ecosystem.
FMOps ⊆ MLOps ⊆ DevOps
MLOps also known as Machine Learning Operations is a part of Machine Learning Engineering that focuses on the development as well as the deployment, and maintenance of ML models ensuring that they run reliably and efficiently.
MLOps fall under DevOps (Development and Operations) but specifically for ML models.
FMOps (Foundational Model Operations) on the other hand work for Generative AI scenarios by selecting, evaluating and fine-tuning the LLMs.
With all if it being said, one thing however remains constant. And that is the fact that LlaMA 3 is after all an LLM and its implementation on the enterprise-level is possible and beneficial only after the foundational elements are set and validated with rigor. To be able to do so, let us explore the technical details behind LlaMA 3.
What is the secret sauce toward LlaMa 3’s claim to fame?
At the fundamental level, yes, it is the transformer. If we go a little higher up in the process, the answer would be the transformer architecture but highly optimized to achieve superior performance on the common industry benchmarks while also enabling newer capabilities.
Good news is that since LlaMa 3 is open (open-source at Meta’s discretion), we have access to the Model Card that gives us the details to how this powerful architecture is configured.
So, let’s dive in and unpack the goodness:
How does the transformer architecture coupled with self-attention play its role in LlaMA 3?
To start with, here is a quick review on how the transformer works:
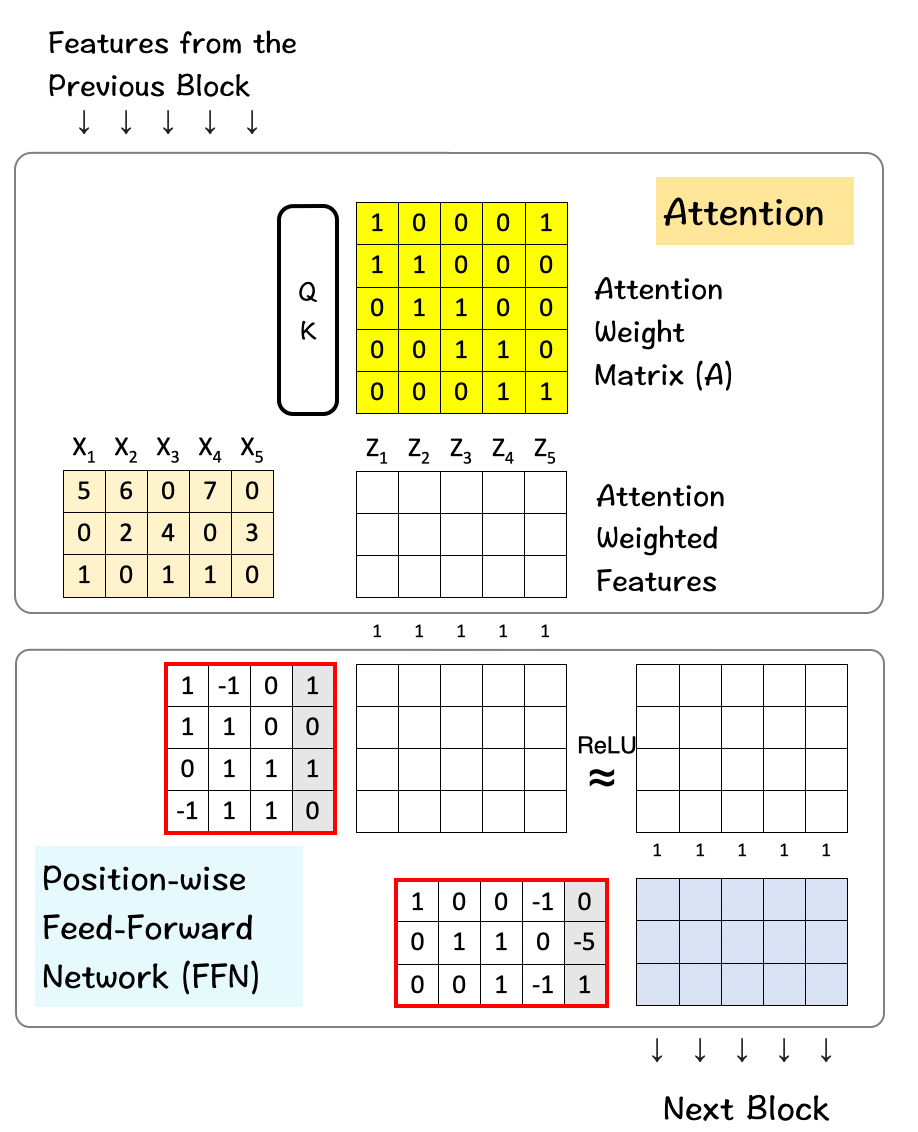
The transformer architecture can be perceived as a combination of the attention layer and the feed-forward layer.
The attention layer combines across features horizontally to produce a new feature.
The feed-forward layer (FFN) combines the parts or the characteristics of a feature to produce new parts/characteristics. It does it vertically across dimensions.
(All the images in this section, unless otherwise noted, are by Prof. Tom Yeh, which I have edited with his permission.)
Below is a basic form of how the architecture looks like and how it functions.
The transformer architecture containing the attention and the feed-forward blocks.
Here are the links to the deep-dive articles for Transformers and Self-Attention where the entire process is discussed in detail.
The essentials of LlaMA 3
It’s time to get into the nitty-gritty and discover how the transformer numbers play out in the real-life LlaMa 3 model. For our discussion, we will only consider the 8B variant. Here we go:
– What are the LlaMA 3 — 8B model parameters?
The primary numbers/values that we need to explore here are for the parameters that play a key role in the transformer architecture. And they are as below:
Layers : Layers here refer to the basic blocks of the transformers — the attention layer and the FFN as can be seen in the image above. The layers are stacked one above the other where the input flows into one layer and its output is passed on to the next layer, gradually transforming the input data.
Attention heads : Attention heads are part of the self-attention mechanism. Each head scans the input sequence independently and performs the attention steps (Remember: the QK-module, SoftMax function.)
Vocabulary words : The vocabulary refers to the number of words the model recognizes or knows. Essentially, think of it as humans’ way of building our word repertoire so that we develop knowledge and versatility in a language. Most times bigger the vocabulary, better the model performance.
Feature dimensions : These dimensions specify the size of the vectors representing each token in the input data. This number remains consistent throughout the model from the input embedding to the output of each layer.
Hidden dimensions : These dimensions are the internal size of the layers within the model, more commonly the size of hidden layers of the feed-forward layers. As is norm, the size of these layers can be larger than the feature dimension helping the model extract and process more complex representations from the data.
Context-window size : The ‘window-size’ here refers to the number of tokens from the input sequence that the model considers at once when calculating attention.
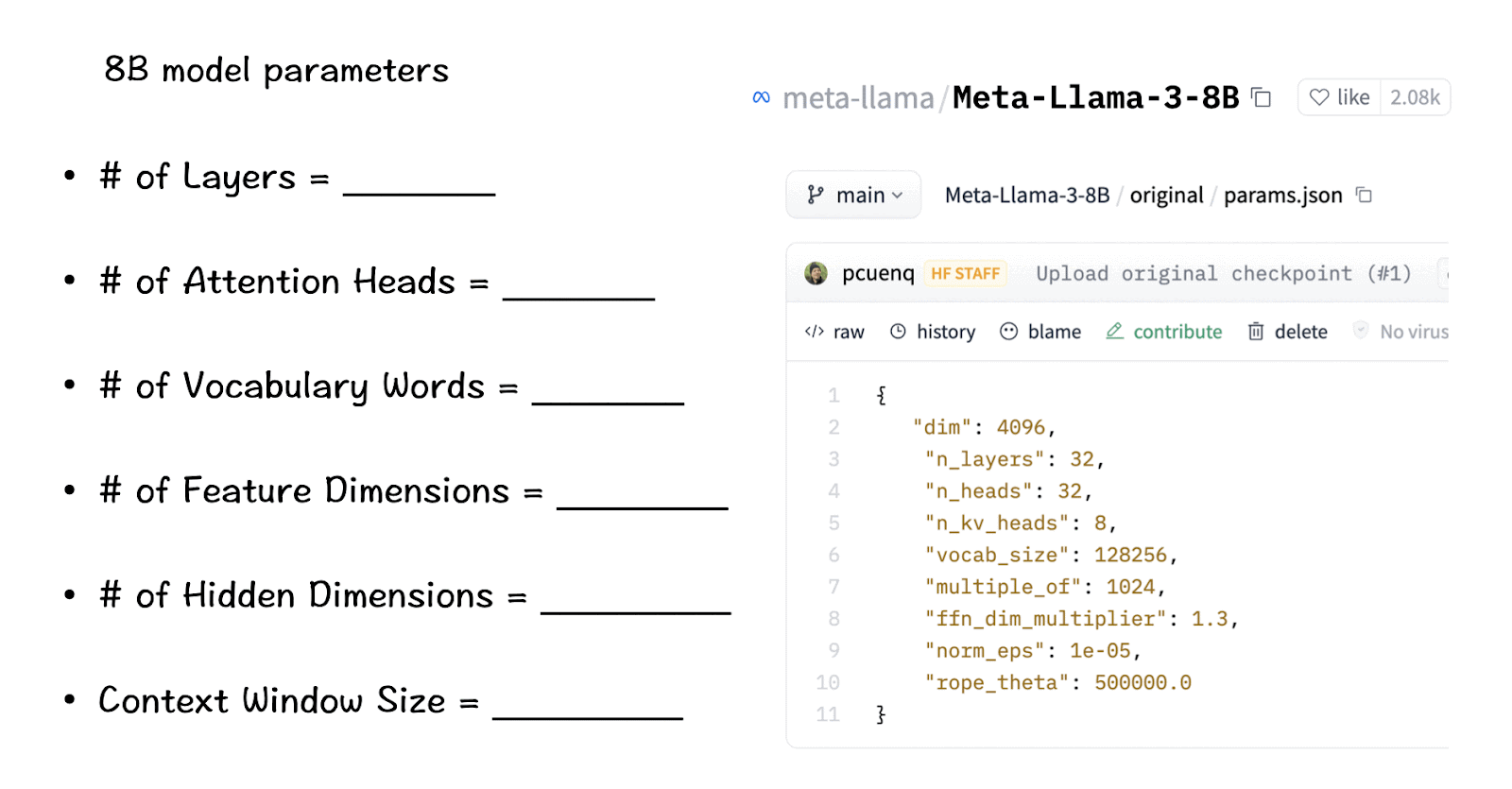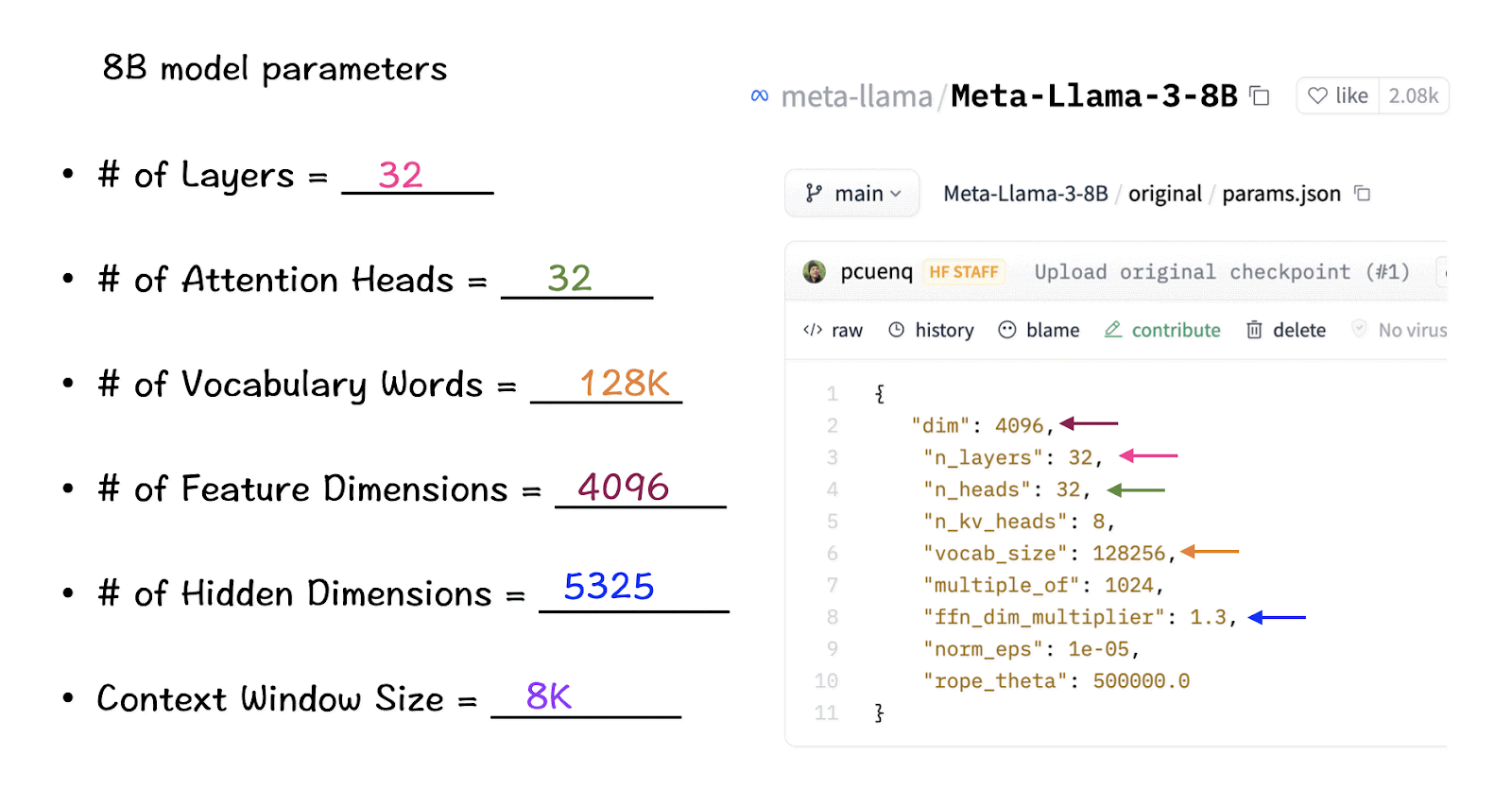
With the terms defined, let us refer to the actual numbers for these parameters in the LlaMA 3 model. (The original source code where these numbers are stated can be found here.)
The original source code where these numbers are stated can be found here.
Keeping these values in mind, the next steps illustrate how each of them play their part in the model. They are listed in their order of appearance in the source-code.
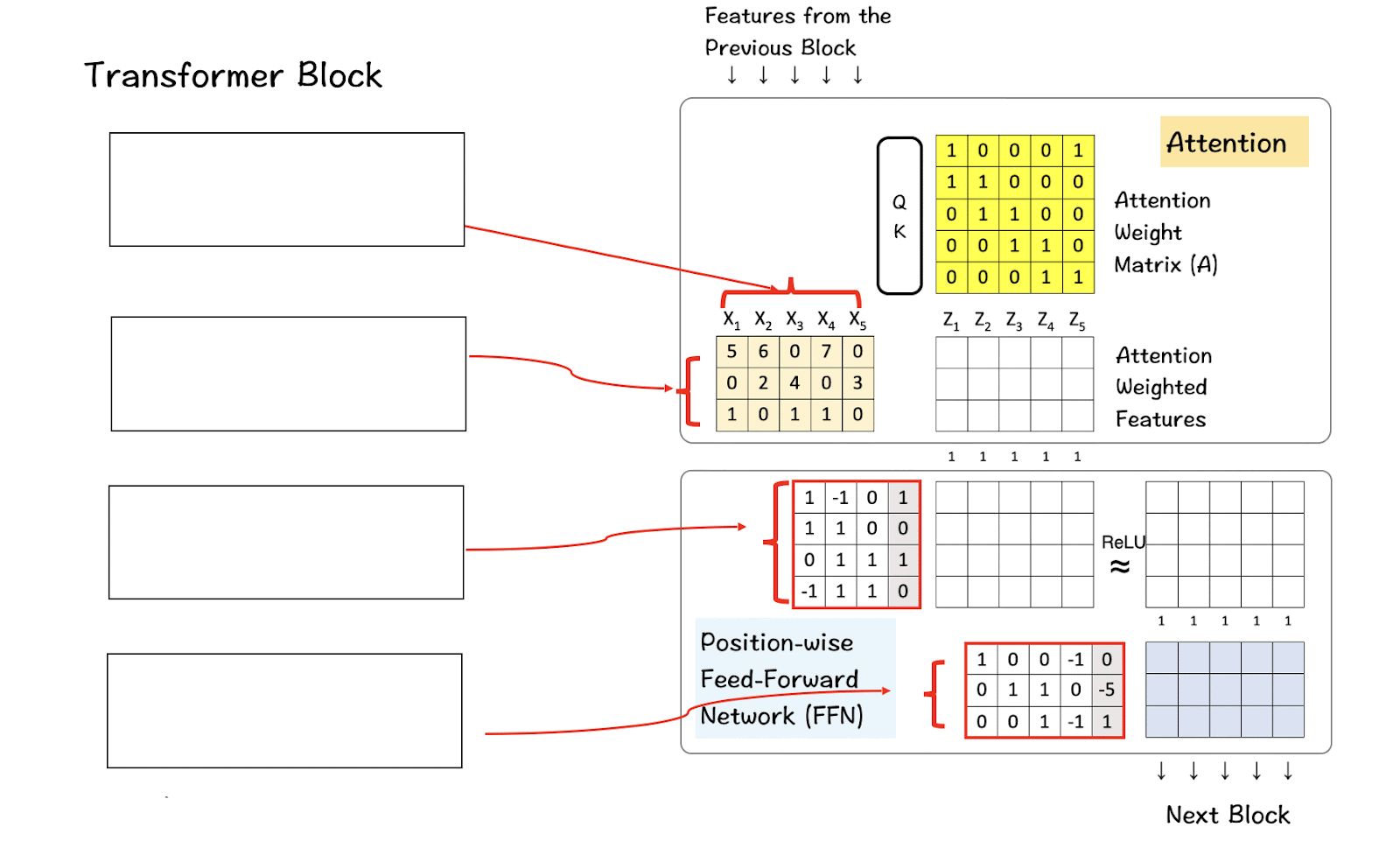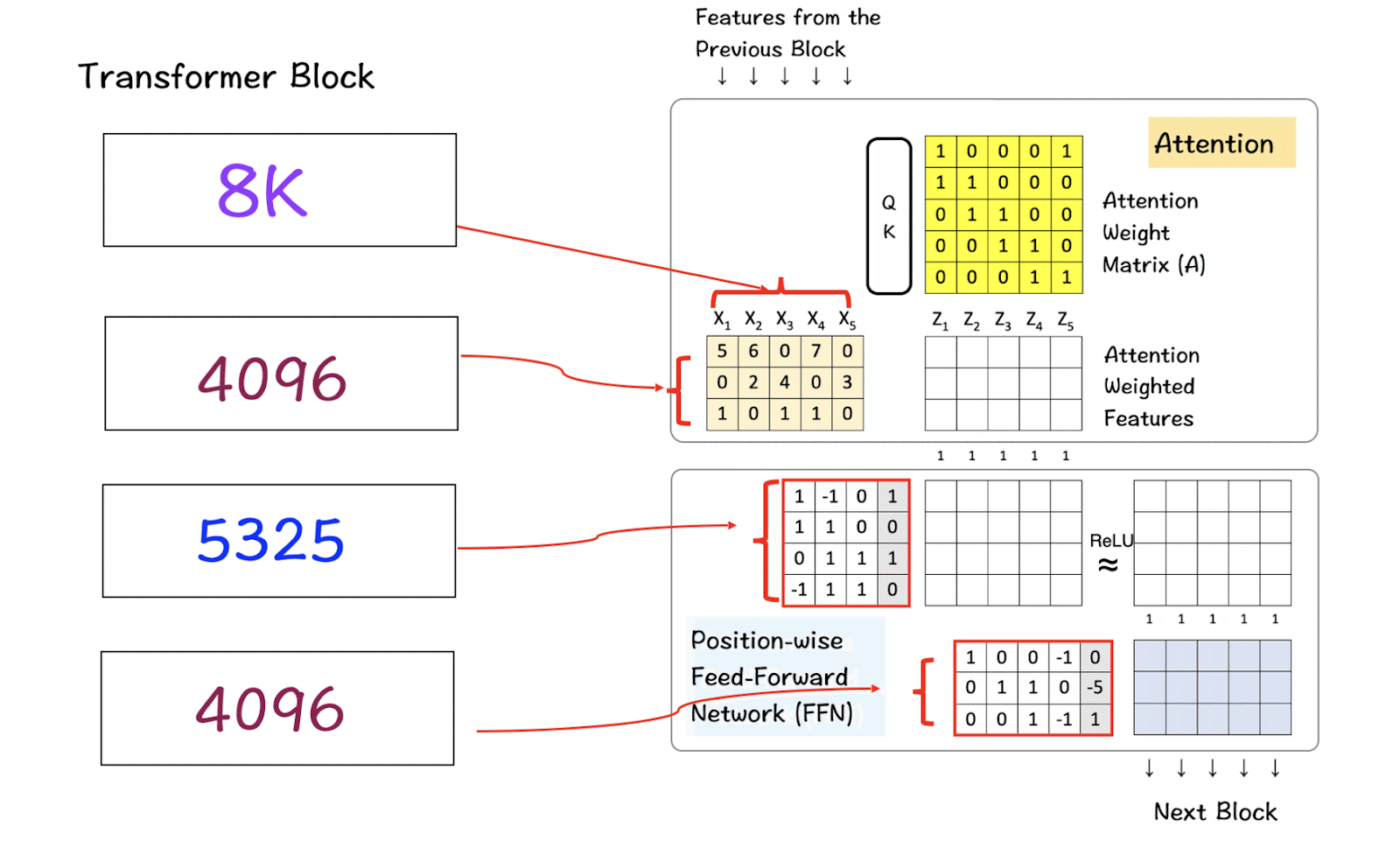
[1] The context-window
While instantiating the LlaMa class, the variable max_seq_len defines the context-window. There are other parameters in the class but this one serves our purpose in relation to the transformer model. The max_seq_len here is 8K which implies the attention head is able to scan 8K tokens at one go.
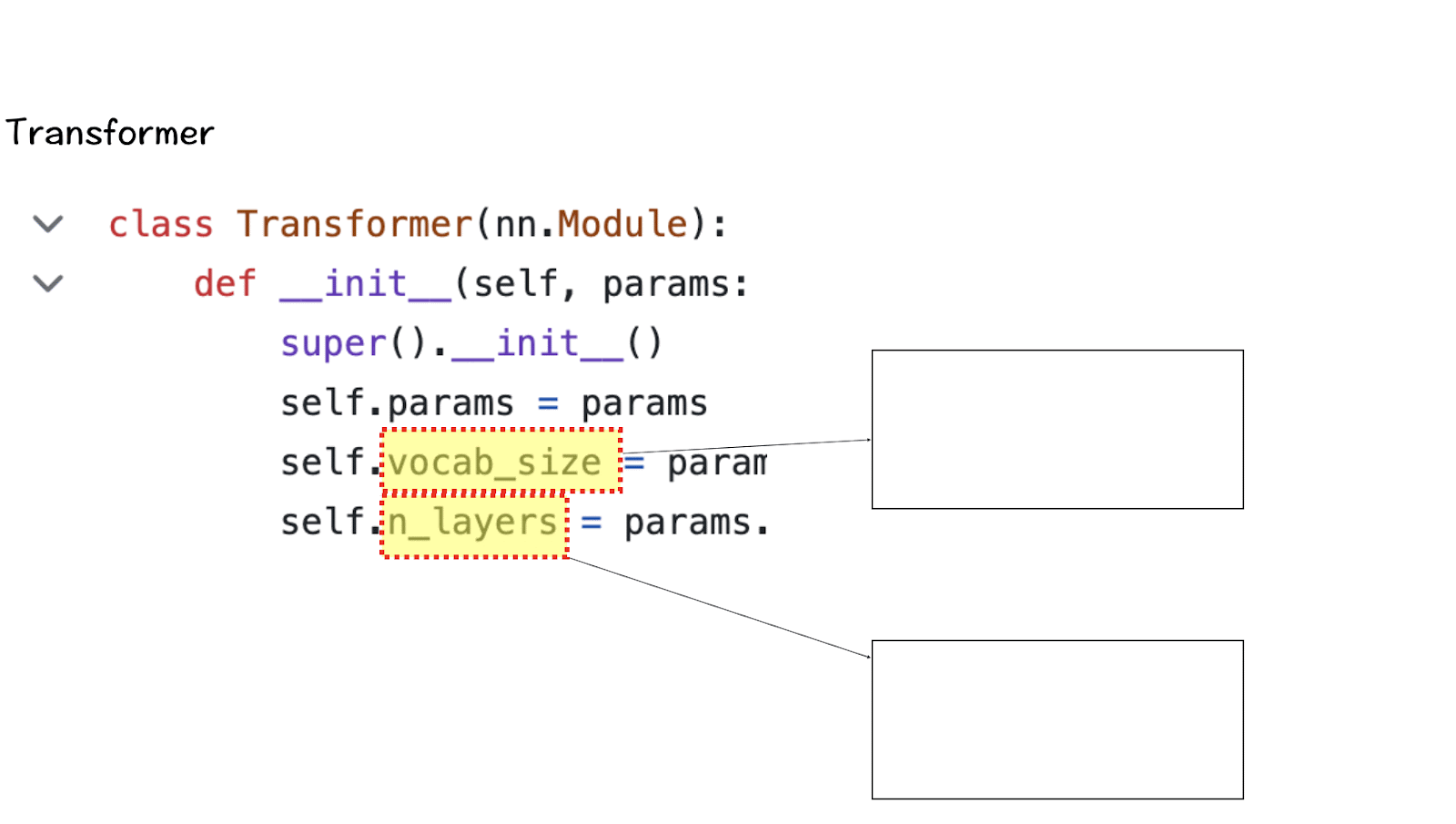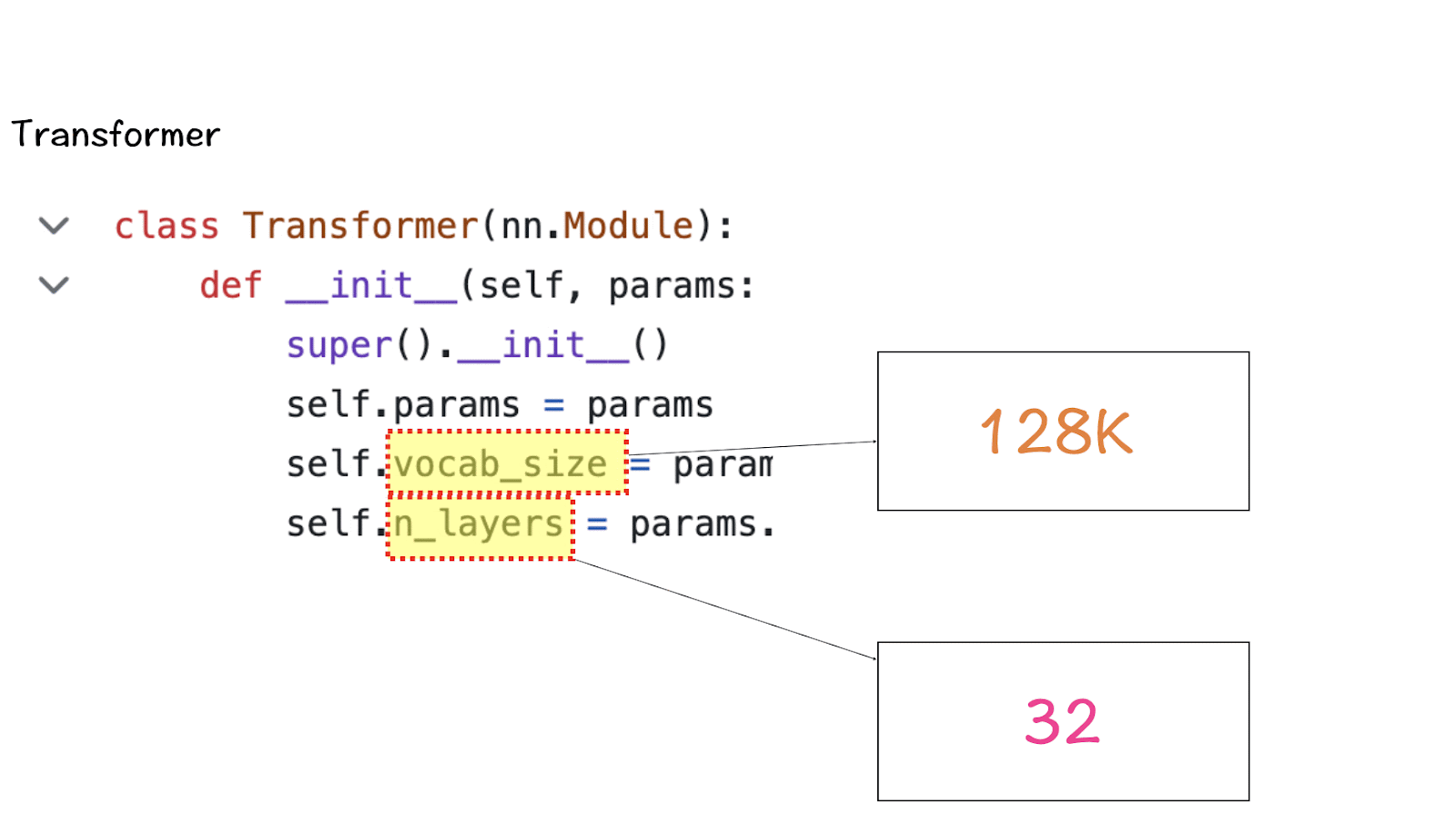
[2] Vocabulary-size and Attention Layers
Next up is the Transformer class which defines the vocabulary size and the number of layers. Once again the vocabulary size here refers to the set of words (and tokens) that the model can recognize and process. Attention layers here refer to the transformer block (the combination of the attention and feed-forward layers) used in the model.
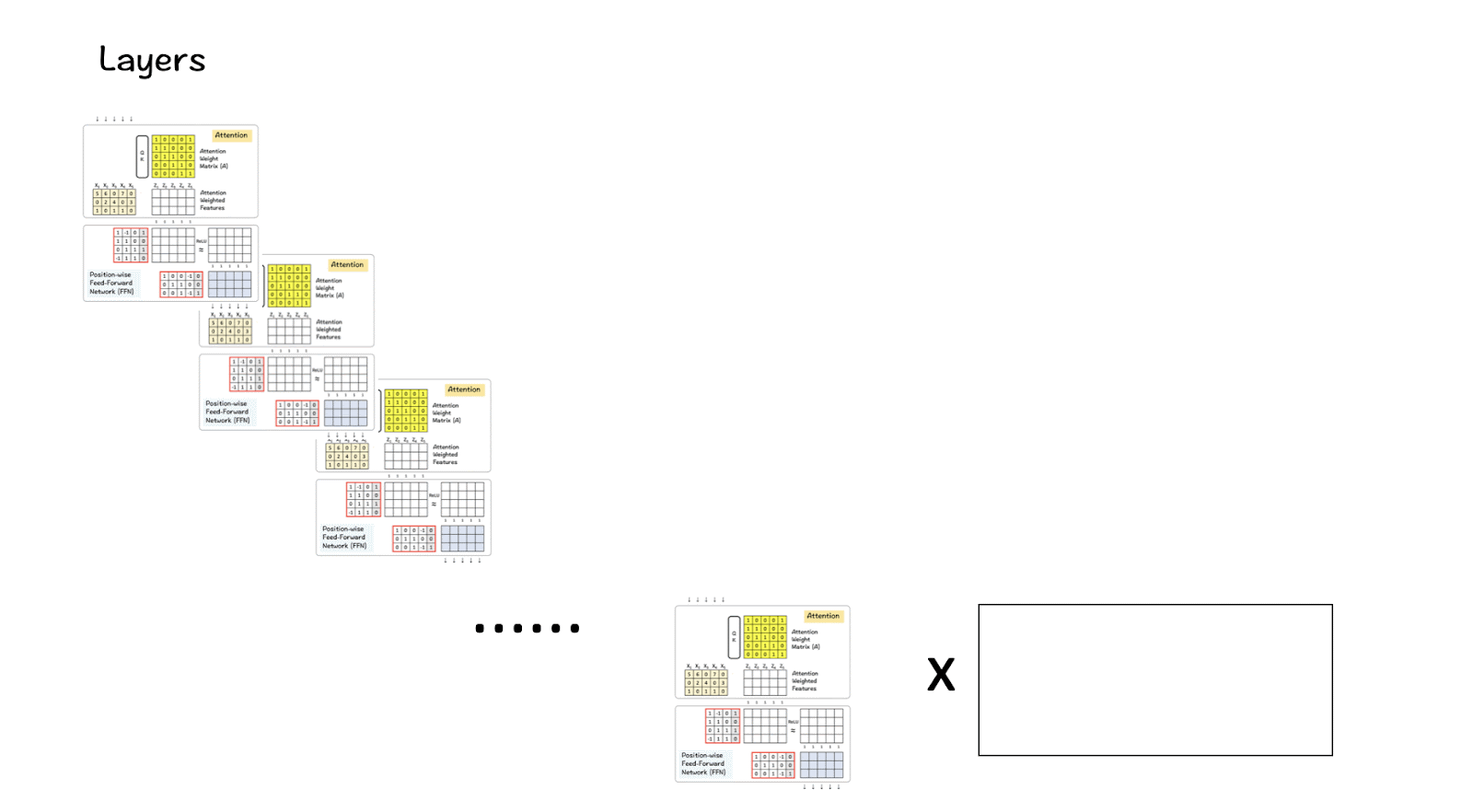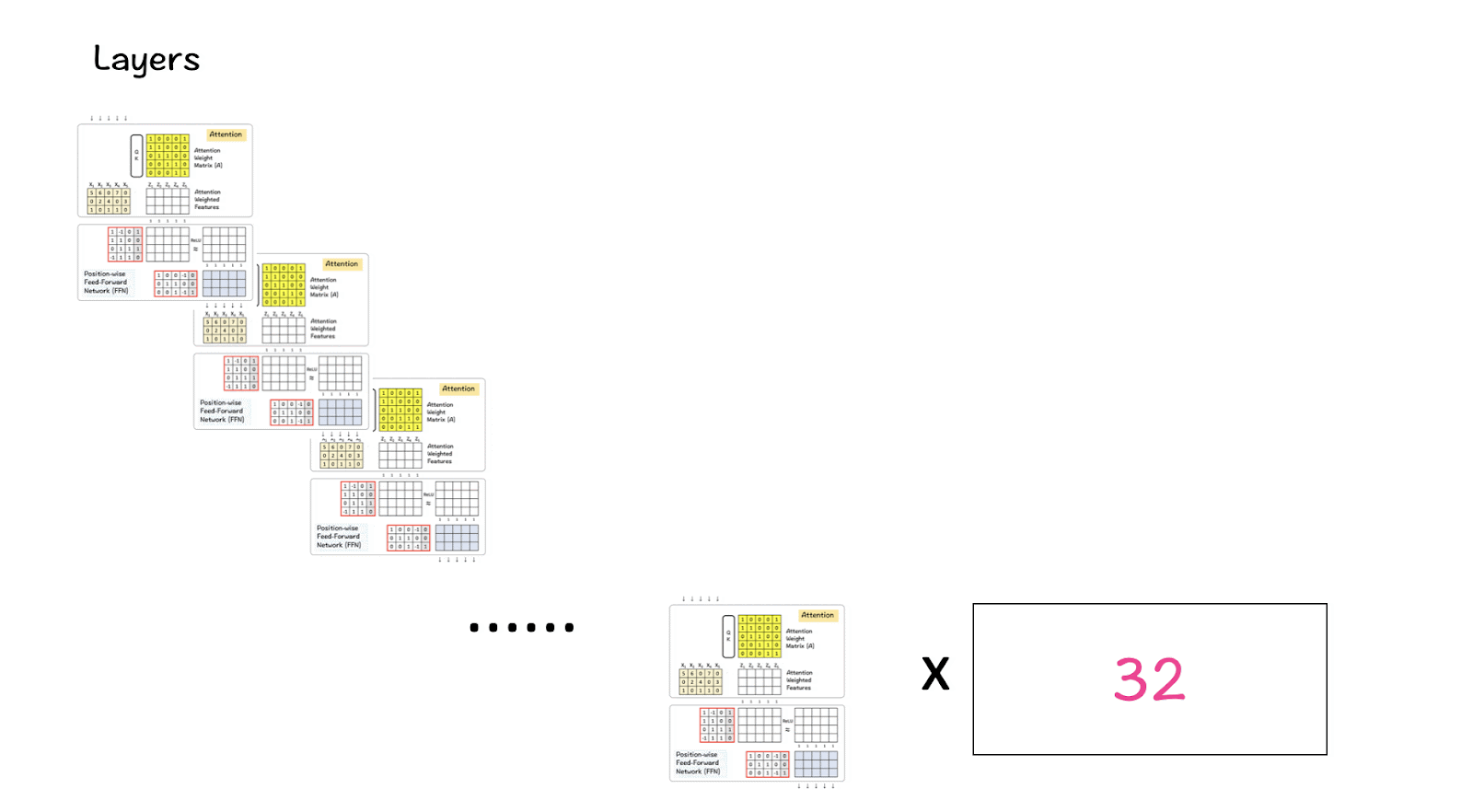
Based on these numbers, LlaMA 3 has a vocabulary size of 128K which is quite large. Additionally, it has 32 copies of the transformer block.
[3] Feature-dimension and Attention-Heads
The feature dimension and the attention-heads make their way into the Self-Attentionmodule. Feature dimension refers to the vector-size of the tokens in the embedding space and the attention-heads consist of the QK-module that powers the self-attention mechanism in the transformers.
[4] Hidden Dimensions
The hidden dimension features in the Feed-Forward class specifying the number of hidden layers in the model. For LlaMa 3, the hidden layer is 1.3 times the size of the feature dimension. A larger number of hidden layers allows the network to create and manipulate richer representations internally before projecting them back to the smaller output dimension.
[5] Combining the above parameters to form the Transformer
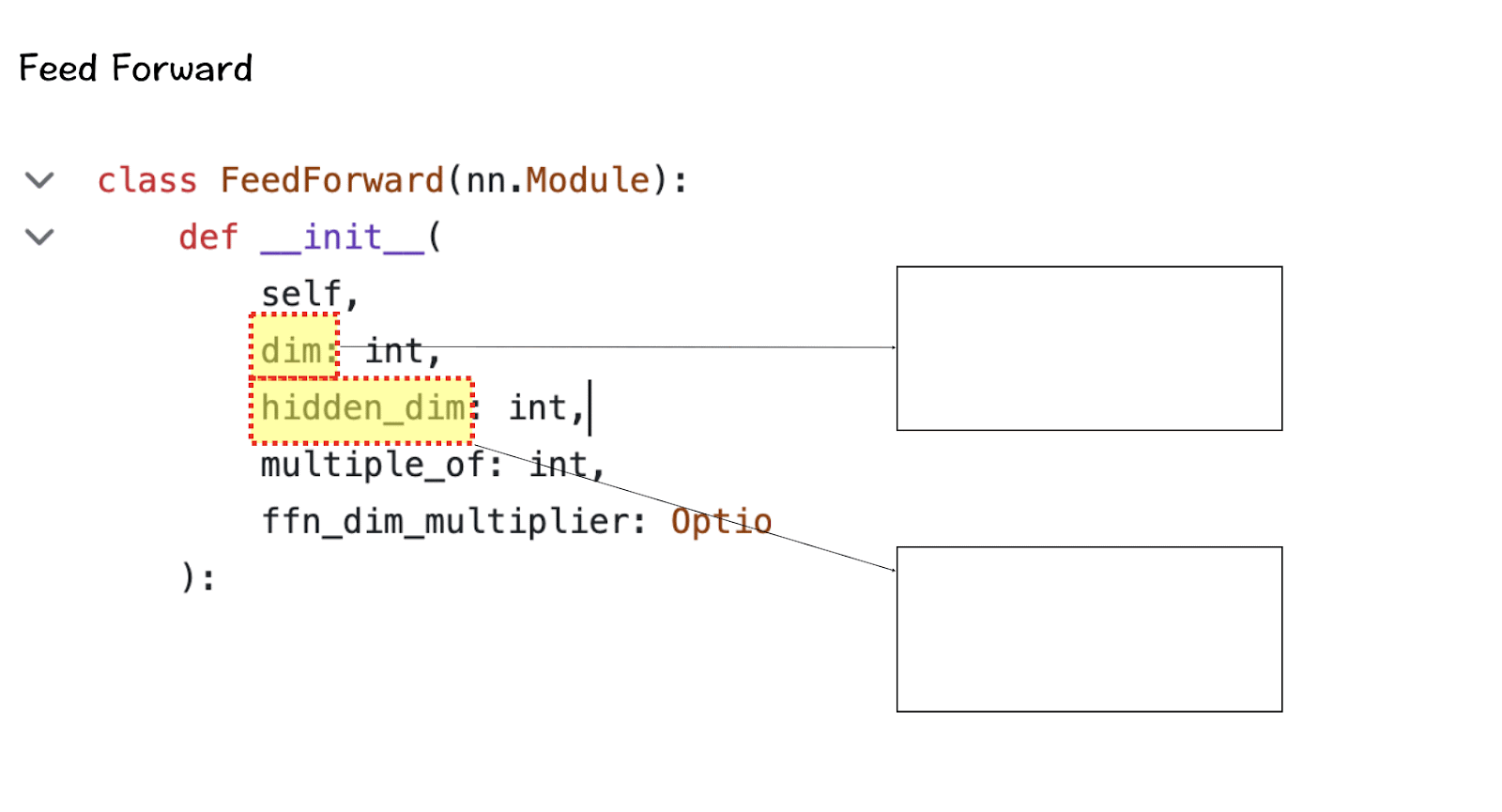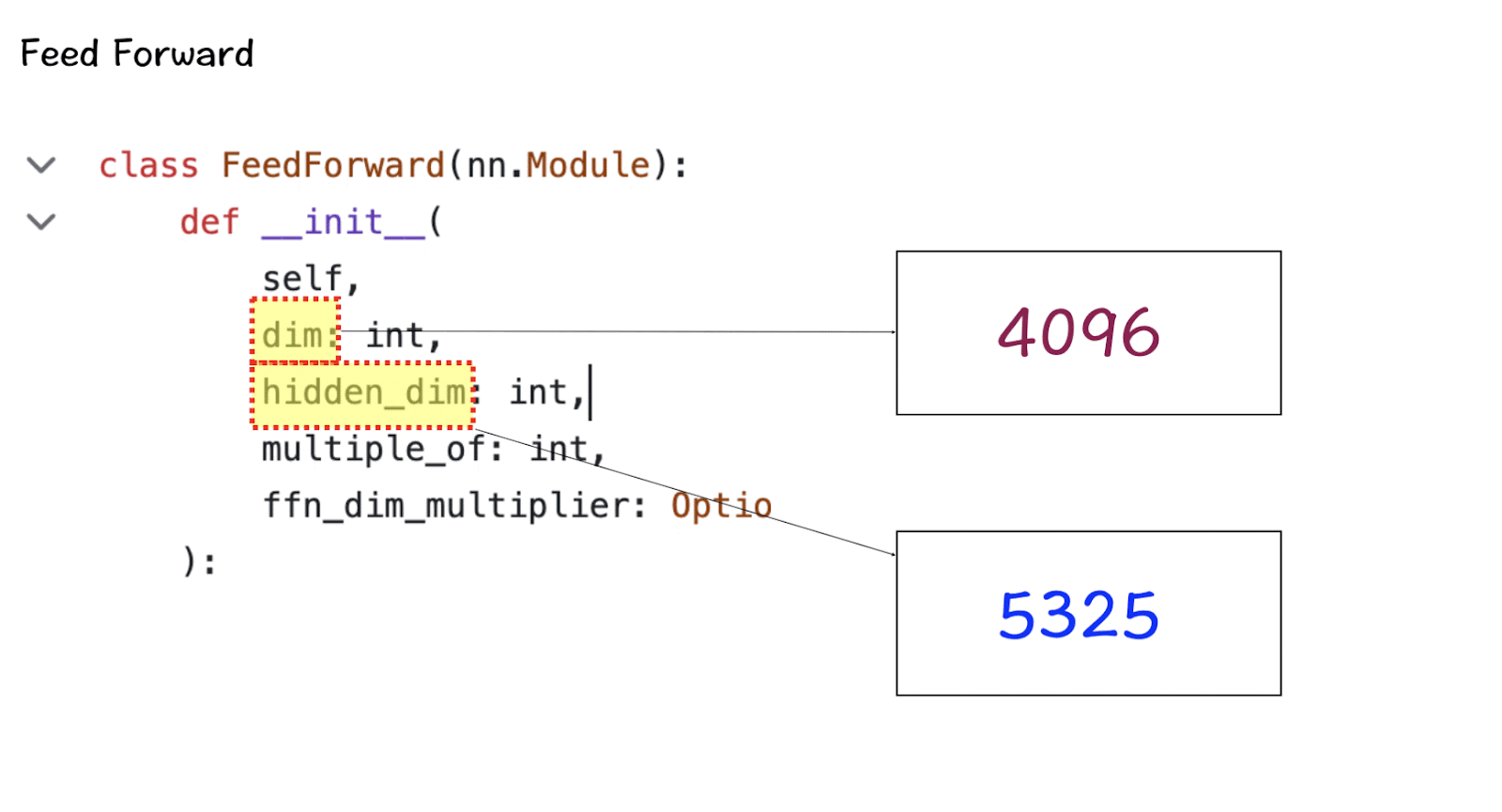
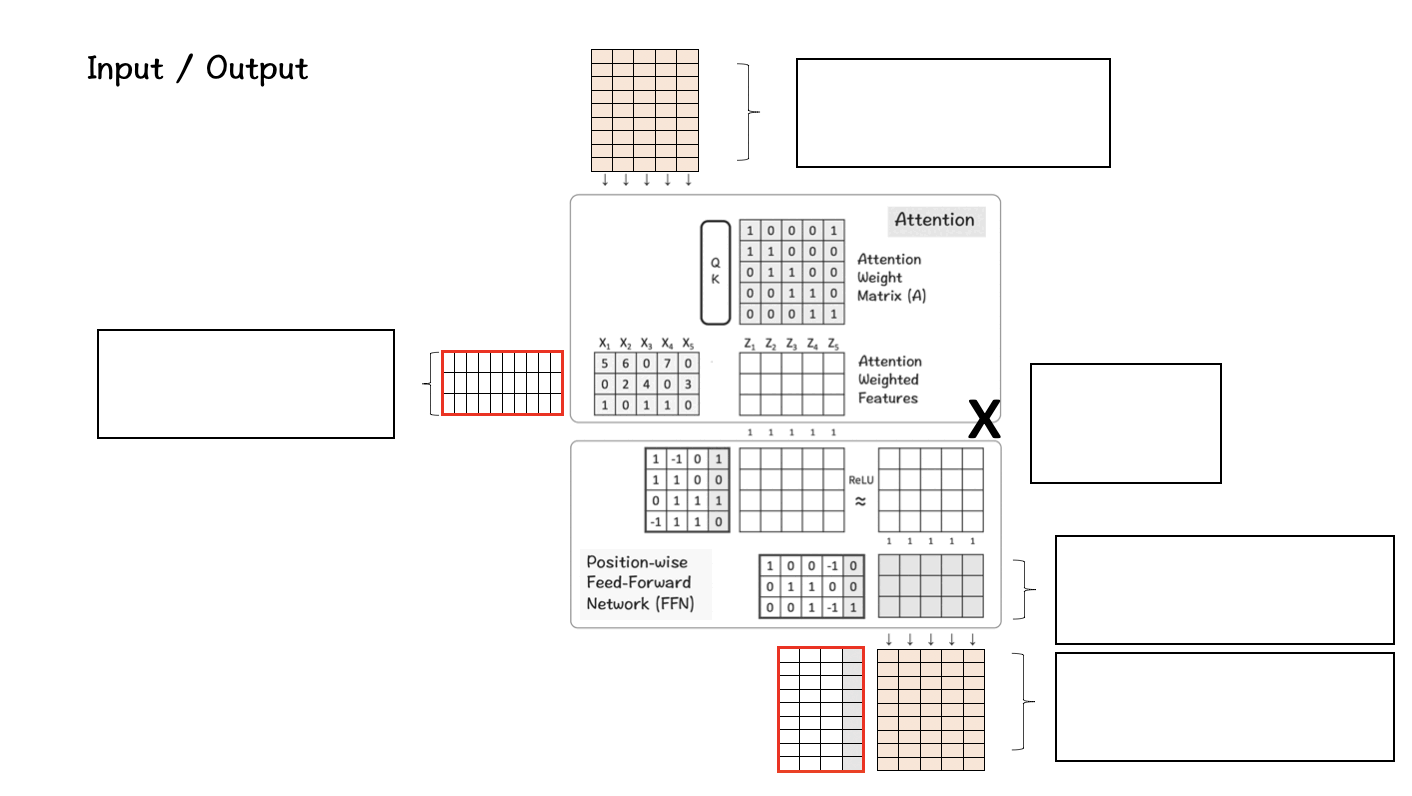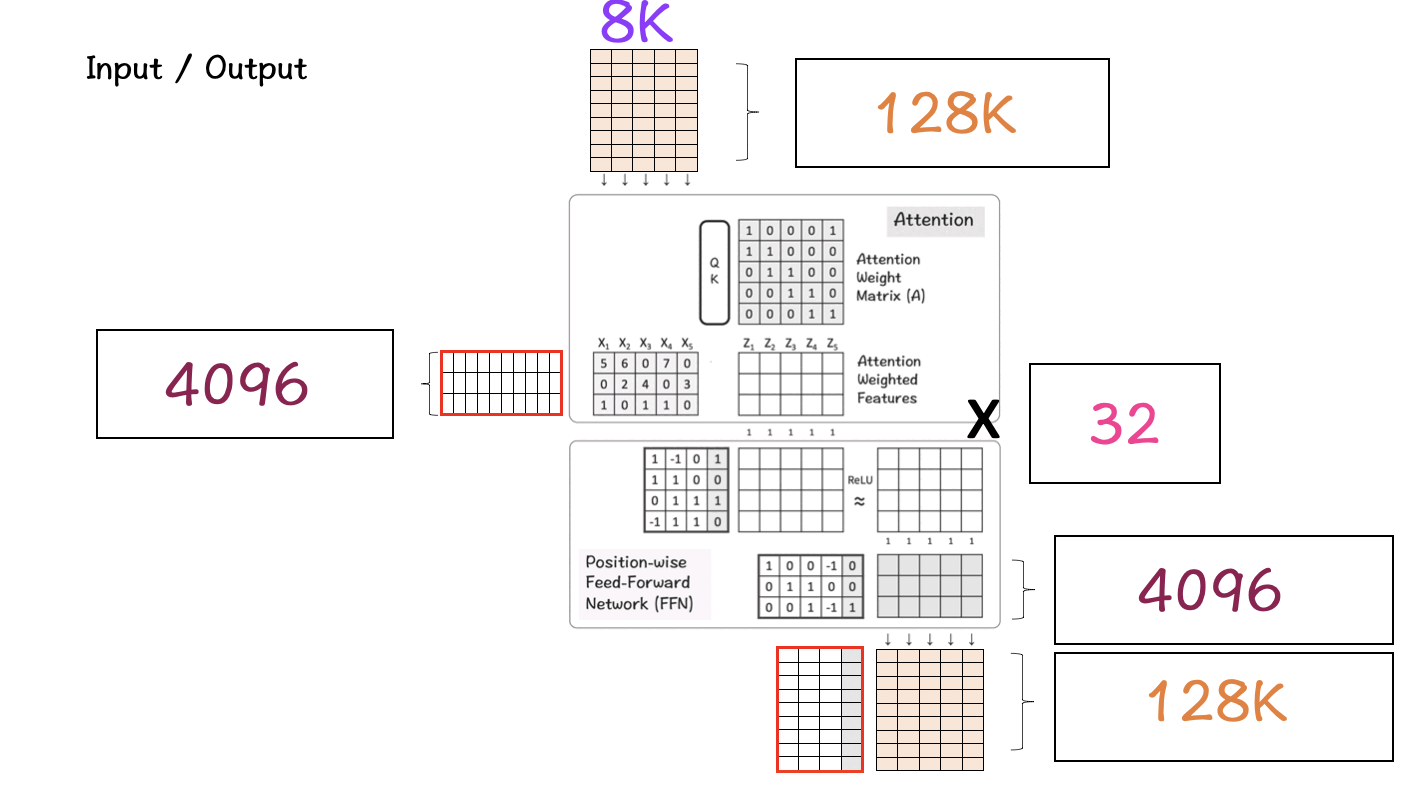
The first matrix is the input feature matrix which goes through the Attention layer to create the Attention Weighted features. In this image the input feature matrix only has a size of 5 x 3 matrix, but in the real-world Llama 3 model it grows up to be 8K x 4096 which is enormous.
The next one is the hidden layer in the Feed-Forward Network that grows up to 5325 and then comes back down to 4096 in the final layer.
[6] Multiple-layers of the Transformer block
LlaMA 3 combines 32 of these above transformer blocks with the output of one passing down into the next block until the last one is reached.
[7] Let’s put it all together
Once we have set all the above pieces in motion, it is time to put it all together and see how they produce the LlaMA effect.
So, what is happening here?
Step 1 : First we have our input matrix, which is the size of 8K (context-window) x 128K (vocabulary-size). This matrix undergoes the process of embedding which takes this high-dimensional matrix into a lower dimension.
Step 2 : This lower dimension in this case turns out to be 4096 which is the specified dimension of the features in the LlaMA model as we had seen before. (A reduction from 128K to 4096 is immense and noteworthy.)
Step 3: This feature goes through the Transformer block where it is processed first by the Attention layer and then the FFN layer. The attention layer processes it across features horizontally whereas the FFN layer does it vertically across dimensions.
Step 4: Step 3 is repeated for 32 layers of the Transformer block. In the end the resultant matrix has the same dimension as the one used for the feature dimension.
Step 5: Finally this matrix is transformed back to the original size of the vocabulary matrix which is 128K so that the model can choose and map those words as available in the vocabulary.
And that’s how LlaMA 3 is essentially scoring high on those benchmarks and creating the LlaMA 3 effect.
The LlaMA 3 Effect
LlaMA 3 was released in two model versions — 8B and 70B parameters to serve a wide range of use-cases. In addition to achieving state-of-the-art performances on standard benchmarks, a new and rigorous human-evaluation set was also developed. And Meta promises to release better and stronger versions of the model with it becoming multilingual and multimodal. The news is newer and larger models are coming soon with over 400B parameters (early reports here show that it is already crushing benchmarks by an almost 20% score increase over LlaMA 3).
However, it is imperative to say that in spite of all the upcoming changes and all the updates, one thing is going to remain the same — the foundation of it all — the transformer architecture and the transformer block that enables this incredible technical advancement.
It could be a coincidence that LlaMA models were named so, but based on legend from the Andes mountains, the real llamas have always been revered for their strength and wisdom. Not very different from the Gen AI — ‘LlaMA’ models.
So, let’s follow along in this exciting journey of the GenAI Andes while keeping in mind the foundation that powers these large language models!
P.S. If you would like to work through this exercise on your own, here is a link to a blank template for your use.
Extracting and structuring text elements with high accuracy using small models
Image generated by an AI by the author
In this post, I’ll introduce a paradigm recently developed at Anaplan for extracting temporal information from natural language text, as part of an NLQ (natural language query) project. While I will focus on time extraction, the paradigm is versatile and applicable for parsing various unstructured texts and extracting diverse patterns of information. This includes named entity recognition, text-to-SQL conversion, quantity extraction, and more.
The paradigm’s core lies in constructing a flexible pipeline, which provides maximal flexibility, making it easy to fine-tune a model to extract the meaning from any conceivable expression in the language. It is based on a deep learning model (transformers) but for us, it achieved a 99.98% accuracy which is relatively rare for ML methods. Additionally, it does not utilize LLMs (large language models), in fact, it requires a minimal transformer model. This yields a compact, adaptable ML model, exhibiting the precision of rule-based systems.
For those seeking time, numerical value, or phone number extraction, Facebook’s Duckling package offers a rule-based solution. However, if Duckling falls short of your requirements or you’re eager to explore a new ML paradigm, read on.
Can LLMs capture the meaning?
LLMs, despite their capabilities, face challenges in parsing such phrases and extracting their meaning comprehensively. Consider the expression “the first 15 weeks of last year.” Converting this to a date range necessitates the model to determine the current year, subtract one, and calculate the position of the 15th week as it adjusts for leap years. Language models were not built for this kind of computation.
In my experience, LLMs can accurately output the correct date range around 90–95% of the time but struggle with the remaining 5–10%, no matter the prompting techniques you use. Not to mention: LLMs are resource-intensive and slow.
Thankfully, by following three principles, compact transformers can successfully accomplish the task
Separate information extraction from logical deduction.
Auto-generate a dataset using structured patterns.
Constrain the generative AI to the required structure.
In this post, I will cover the first two, as the third one I covered in a previous post.
Separate information extraction from logical deduction
The first principle is to ensure that the language model’s role is to extract information from free text, rather than to make any logical deduction: logical deductions can easily be implemented in code.
Consider the phrase: “How many movies came out two years ago?” The language model’s task should be to identify that the relevant year is: this_year – 2, without calculating the actual year (which means it doesn’t need to know the current year). Its focus is parsing the meaning and structuring unstructured language. Once that formula is extracted, we can implement its calculation in code.
For this to work, we introduce a Structured Time Language (STL) capable of expressing time elements. For instance, “on 2020” translates to “TIME.year==2020,” and “three months from now” becomes “NOW.month==3.” While the entire STL language isn’t detailed here, it should be relatively intuitive: you can reference attributes like year, quarter, and month for an absolute time or relative to NOW. The translation of “the last 12 weeks of last year” is “NOW.year==-1 AND TIME.week>=-12”
By removing any logical deduction or calculation from the task, we take a huge burden off the language model and allow it to focus on information extraction. This division of labor will improve its accuracy significantly. After the translation process is complete, it is straightforward to develop code for a parser that reads the structured language and retrieves the necessary date range.
Since this is a translation task — from natural language to STL — we used an encoder-decoder transformer. We used the Bart model from Hugging Face, which can easily be fine-tuned for this task.
But how do we get the data for training the model?
Auto-generate a dataset using structured patterns
Since a training dataset for this translation task does not exist, we must generate it ourselves. This was done by following these steps:
Step one: Write functions to map datetime objects to both “natural language” and STL formats:
Given a datetime object, these functions return a tuple of free text and its corresponding STL, for instance: “since 2020”, “TIME.year >= 2020”.
Step two: Sample a random function, and sample a random date within a specified range:
date = np.random.choice(pd.date_range('1970/1/1', '2040/12/31'))
now insert the datetime to the function.
Step three: Append the free text to a random question (we can easily randomly generate questions or draw them from some question dataset, their quality and meaning is not very important).
With this pipeline, we can quickly generate 1000s of text-STL pairs, for example:
“What was the GDP growth in Q2–2019?”, “TIME.quarter==2 AND TIME.year==2019”
“Since 2017, who won the most Oscars?”, “TIME.year>=2017”
“Who was the president on 3 May 2020?”, “TIME.date==2020/05/03”
This approach ensures flexibility in adding new patterns effortlessly. If you find a time expression that is not covered by one of these functions (e.g. “In N years”), you can write a function that will generate examples for this pattern within seconds.
In practice, we can optimize the code efficiency further. Rather than separate functions for each pattern like “since 2020” and “until 2020,” we can randomly sample connective words like “since,” “until,” “on,” etc. This initial batch of functions may require some time to develop, but you can quickly scale to 100s of patterns. Subsequently, addressing any missing expressions becomes trivial, as the pipeline is already established. With a few iterations, nearly all relevant expressions can be covered.
Moreover, we don’t need to cover all the expressions: Since the transformer model we used is pre-trained on a huge corpus of text, it will generalize from the provided patterns to new ones.
Finally, we can use an LLM to generate more examples. Simply ask an LLM:
Hey, what's another way to write "What was the revenue until Aug 23"
And it may return:
"How much did we make before August 2023".
This data augmentation process can be automated too: sending numerous examples to an LLM, thus adding variety to our dataset. Given that the LLM’s role is solely in dataset creation, considerations of cost and speed become inconsequential.
Combining the flexibility of adding new patterns, the generalization of the pre-trained model, and data augmentation using an LLM, we can effectively cover almost any expression.
The final principle of this paradigm is to constrain the generative AI to produce only STL queries, ensuring adherence to the required structure. The method to achieve this, as well as a method for optimizing the tokenization process, was discussed in a previous post.
By adhering to these three principles, we achieved an impressive accuracy of 99.98% on our test dataset. Moreover, this paradigm gave us the flexibility to address new, unsupported, time expressions swiftly.
Summary
Large Language Models (LLMs) aren’t always the optimal solution for language tasks. With the right approach, shallower transformer models can efficiently extract information from natural language with high accuracy and flexibility, at a reduced time and cost.
The key principles to remember are:
Focusing the model only on information extraction, avoiding complex logical deductions. This may require generating a mediating language and implementing a parser and logical deduction in code.
Establishing a pipeline for generating a dataset and training a model, so that adding new functionality (new language patterns) is straightforward and fast. This pipeline can include the use of an LLM, adding more variety to the dataset.
Confining the model generation to the constraints of a structured language.
While this post focused on extracting time elements, the paradigm applies to extracting any information from free text and structuring it into various formats. With this paradigm, you can achieve the accuracy of a rule-based engine, with the flexibility of a machine learning model.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.