A complete guide to big data analysis using Apache Hadoop (HDFS) and PySpark library in Python on game reviews on the Steam gaming platform.
With over 100 zettabytes (= 10¹²GB) of data produced every year around the world, the significance of handling big data is one of the most required skills today. Data Analysis, itself, could be defined as the ability to handle big data and derive insights from the never-ending and exponentially growing data. Apache Hadoop and Apache Spark are two of the basic tools that help us untangle the limitless possibilities hidden in large datasets. Apache Hadoop enables us to streamline data storage and distributed computing with its Distributed File System (HDFS) and the MapReduce-based parallel processing of data. Apache Spark is a big data analytics engine capable of EDA, SQL analytics, Streaming, Machine Learning, and Graph processing compatible with the major programming languages through its APIs. Both when combined form an exceptional environment for dealing with big data with the available computational resources — just a personal computer in most cases!
Let us unfold the power of Big Data and Apache Hadoop with a simple analysis project implemented using Apache Spark in Python.
To begin with, let’s dive into the installation of Hadoop Distributed File System and Apache Spark on a MacOS. I am using a MacBook Air with macOS Sonoma with an M1 chip.
Thanks to Code With Arjun for the amazing article that helped me with the installation of Hadoop on my Mac. I seamlessly installed and ran Hadoop following his steps which I will show you here as well.
a. Installing HomeBrew
I use Homebrew for installing applications on my Mac for ease. It can be directly installed on the system with the below code —
Once it is installed, you can run the simple code below to verify the installation.
brew --version
Figure 1: Image by Author
However, you will likely encounter an error saying, command not found, this is because the homebrew will be installed in a different location (Figure 2) and it is not executable from the current directory. For it to function, we add a path environment variable for the brew, i.e., adding homebrew to the .bash_profile.
Figure 2: Image by Author
You can avoid this step by using the full path to Homebrew in your commands, however, it might become a hustle at later stages, so not recommended!
Now, when you try, brew –version, it should show the Homebrew version correctly.
b. Installing Hadoop
Disclaimer! Hadoop is a Java-based application and is supported by a Java Development Kit (JDK) version older than 11, preferably 8 or 11. Install JDK before continuing.
Thanks to Code With Arjun again for this video on JDK installation on MacBook M1.
Now, we install the Hadoop on our system using the brew command.
brew install hadoop
This command should install Hadoop seamlessly. Similar to the steps followed while installing HomeBrew, we should edit the path environment variable for Java in the Hadoop folder. The environment variable settings for the installed version of Hadoop can be found in the Hadoop folder within HomeBrew. You can use which hadoop command to find the location of the Hadoop installation folder. Once you locate the folder, you can find the variable settings at the below location. The below command takes you to the required folder for editing the variable settings (Check the Hadoop version you installed to avoid errors).
cd /opt/homebrew/Cellar/hadoop/3.3.6/libexec/etc/hadoop
You can view the files in this folder using the ls command. We will edit the hadoop-env.sh to enable the proper running of Hadoop on the system.
Figure 3: Image by Author
Now, we have to find the path variable for Java to edit the hadoop-ev.sh file using the following command.
/usr/libexec/java_home
Figure 4: Image by Author
We can open the hadoop-env.sh file in any text editor. I used VI editor, you can use any editor for the purpose. We can copy and paste the path — Library/Java/JavaVirtualMachines/adoptopenjdk-11.jdk/Contents/Home at the export JAVA_HOME = position.
Figure 5: hadoop-env.sh file opened in VI Text Editor
Next, we edit the four XML files in the Hadoop folder.
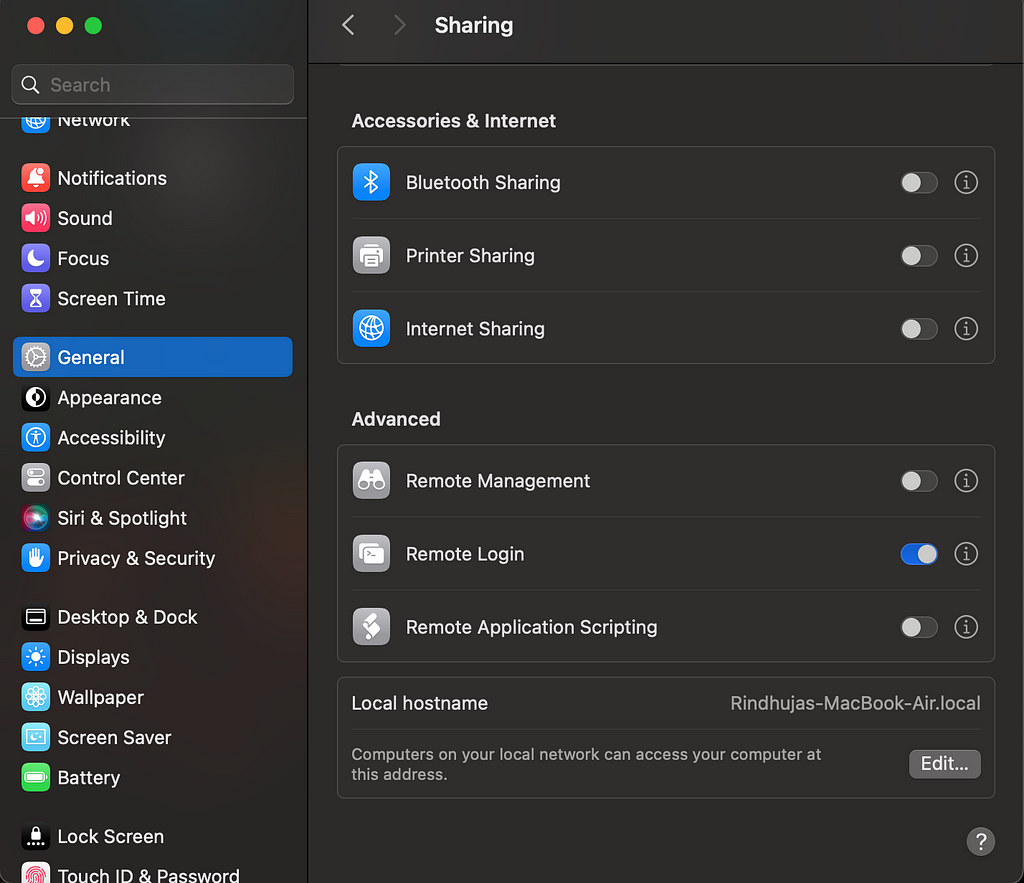
With this, we have successfully completed the installation and configuration of HDFS on the local. To make the data on Hadoop accessible with Remote login, we can go to Sharing in the General settings and enable Remote Login. You can edit the user access by clicking on the info icon.
Figure 6: Enable Remote Access. Image by Author
Let’s run Hadoop!
Execute the following commands
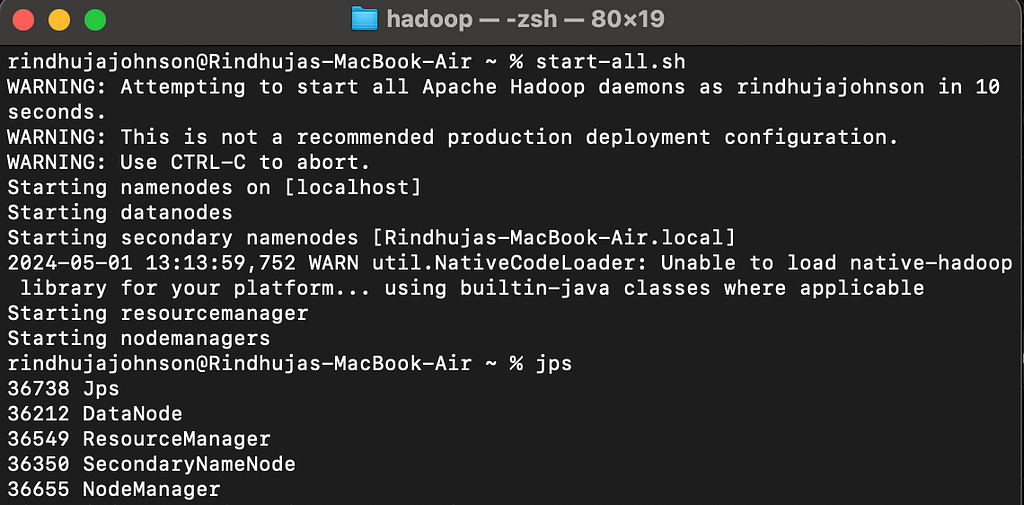
hadoop namenode -format
# starts the Hadoop environment % start-all.sh
# Gathers all the nodes functioning to ensure that the installation was successful % jps
Figure 7: Initiating Hadoop and viewing the nodes and resources running. Image by Author
We are all set! Now let’s create a directory in HDFS and add the data will be working on. Let’s quickly take a look at our data source and details.
Data
The Steam Reviews Dataset 2021(License: GPL 2) is a collection of reviews from about 21 million gamers covering over 300 different games in the year 2021. the data is extracted using Steam’s API — Steamworks — using the Get List function.
GET store.steampowered.com/appreviews/<appid>?json=1
The dataset consists of 23 columns and 21.7 million rows with a size of 8.17 GB (that is big!). The data consists of reviews in different languages and a boolean column that tells if the player recommends the game to other players. We will be focusing on how to handle this big data locally using HDFS and analyze it using Apache Spark in Python using the PySpark library.
c. Uploading Data into HDFS
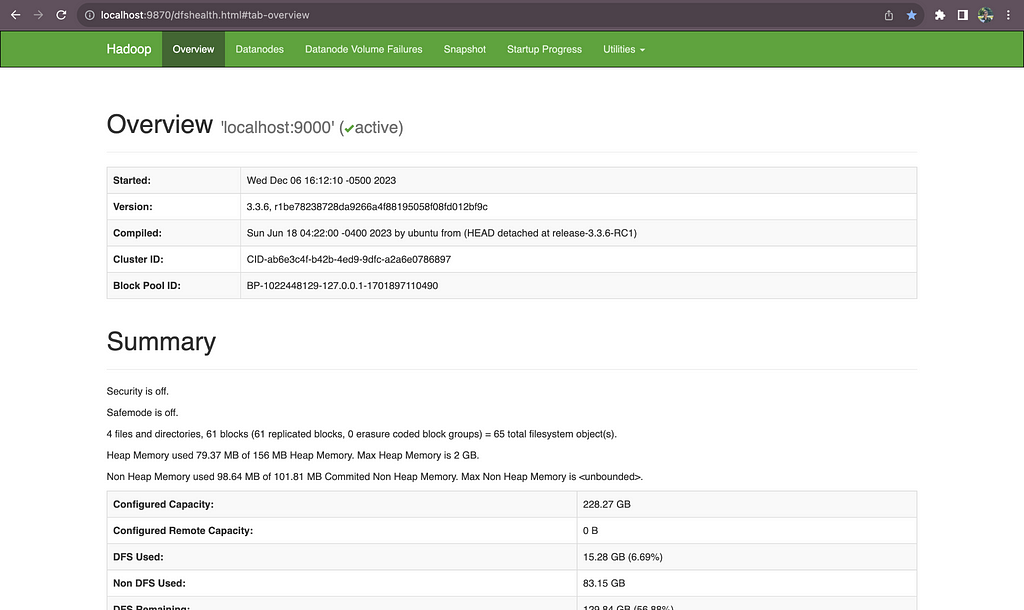
Firstly, we create a directory in the HDFS using the mkdir command. It will throw an error if we try to add a file directly to a non-existing folder.
Figure 8: HDFS User Interface at localhost:9870. Image by Author
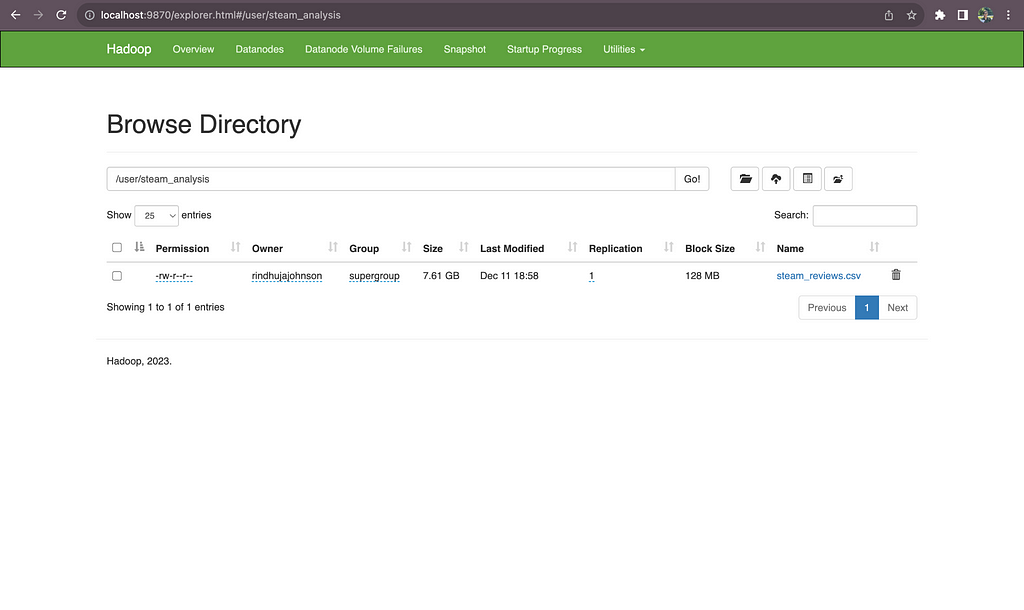
We can see the uploaded files as shown below.
Figure 10: Navigating files in HDFS. Image by Author
Once the data interaction is over, we can use stop-all.sh command to stop all the Apache Hadoop daemons.
Let us move to the next step — Installing Apache Spark
2. Installing Apache Spark
Apache Hadoop takes care of data storage (HDFS) and parallel processing (MapReduce) of the data for faster execution. Apache Spark is a multi-language compatible analytical engine designed to deal with big data analysis. We will run the Apache Spark on Python in Jupyter IDE.
After installing and running HDFS, the installation of Apache Spark for Python is a piece of cake. PySpark is the Python API for Apache Spark that can be installed using the pip method in the Jupyter Notebook. PySpark is the Spark Core API with its four components — Spark SQL, Spark ML Library, Spark Streaming, and GraphX. Moreover, we can access the Hadoop files through PySpark by initializing the installation with the required Hadoop version.
# By default, the Hadoop version considered will be 3 here. PYSPARK_HADOOP_VERSION=3 pip install pyspark
Let’s get started with the Big Data Analytics!
3. Steam Review Analysis using PySpark
Steam is an online gaming platform that hosts over 30,000 games streaming across the world with over 100 million players. Besides gaming, the platform allows the players to provide reviews for the games they play, a great resource for the platform to improve customer experience and for the gaming companies to work on to keep the players on edge. We used this review data provided by the platform publicly available on Kaggle.
3. a. Data Extraction from HDFS
We will use the PySpark library to access, clean, and analyze the data. To start, we connect the PySpark session to Hadoop using the local host address.
from pyspark.sql import SparkSession from pyspark.sql.functions import *
# Initializing the Spark Session spark = SparkSession.builder.appName("SteamReviewAnalysis").master("yarn").getOrCreate()
# Providing the url for accessing the HDFS data = "hdfs://localhost:9000/user/steam_analysis/steam_reviews.csv"
# Extracting the CSV data in the form of a Schema data_csv = spark.read.csv(data, inferSchema = True, header = True)
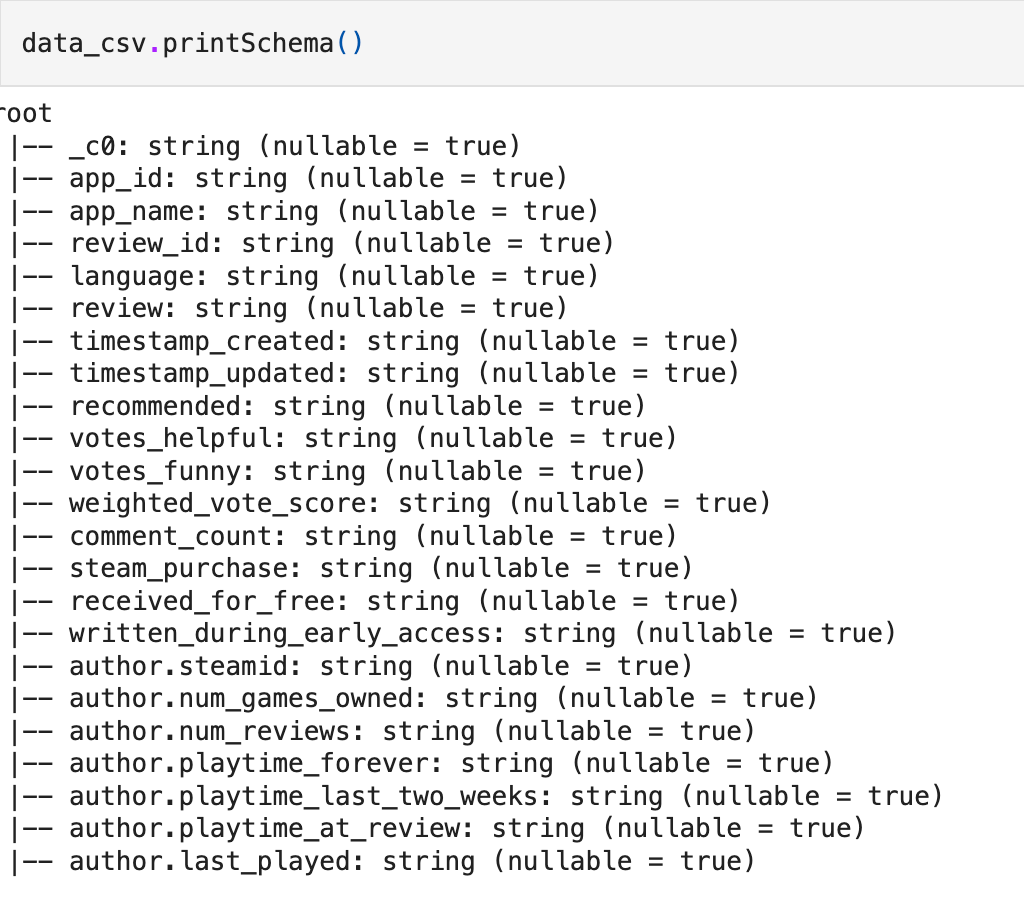
# Visualize the structure of the Schema data_csv.printSchema()
# Counting the number of rows in the dataset data_csv.count() # 40,848,659
3. b. Data Cleaning and Pre-Processing
We can start by taking a look at the dataset. Similar to the pandas.head() function in Pandas, PySpark has the SparkSession.show() function that gives a glimpse of the dataset.
Before that, we will remove the reviews column in the dataset as we do not plan on performing any NLP on the dataset. Also, the reviews are in different languages making any sentiment analysis based on the review difficult.
# Dropping the review column and saving the data into a new variable data = data_csv.drop("review")
# Displaying the data data.show()
Figure 11: The Structure of the Schema
We have a huge dataset with us with 23 attributes with NULL values for different attributes which does not make sense to consider any imputation. Therefore, I have removed the records with NULL values. However, this is not a recommended approach. You can evaluate the importance of the available attributes and remove the irrelevant ones, then try imputing data points to the NULL values.
# Drops all the records with NULL values data = data.na.drop(how = "any")
# Count the number of records in the remaining dataset data.count() # 16,876,852
We still have almost 17 million records in the dataset!
Now, we focus on the variable names of the dataset as in Figure 11. We can see that the attributes have a few characters like dot(.) that are unacceptable as Python identifiers. Also, we change the data type of the date and time attributes. So we change these using the following code —
from pyspark.sql.types import * from pyspark.sql.functions import from_unixtime
# Changing the data type of each columns into appropriate types data = data.withColumn("app_id",data["app_id"].cast(IntegerType())). withColumn("author_steamid", data["author_steamid"].cast(LongType())). withColumn("recommended", data["recommended"].cast(BooleanType())). withColumn("steam_purchase", data["steam_purchase"].cast(BooleanType())). withColumn("author_num_games_owned", data["author_num_games_owned"].cast(IntegerType())). withColumn("author_num_reviews", data["author_num_reviews"].cast(IntegerType())). withColumn("author_playtime_forever", data["author_playtime_forever"].cast(FloatType())). withColumn("author_playtime_at_review", data["author_playtime_at_review"].cast(FloatType()))
# Converting the time columns into timestamp data type data = data.withColumn("timestamp_created", from_unixtime("timestamp_created").cast("timestamp")). withColumn("author_last_played", from_unixtime(data["author_last_played"]).cast(TimestampType())). withColumn("timestamp_updated", from_unixtime(data["timestamp_updated"]).cast(TimestampType()))
Figure 12: A glimpse of the Steam review Analysis dataset. Image by Author
The dataset is clean and ready for analysis!
3. c. Exploratory Data Analysis
The dataset is rich in information with over 20 variables. We can analyze the data from different perspectives. Therefore, we will be splitting the data into different PySpark data frames and caching them to run the analysis faster.
# Creating new pyspark data frames using the grouped columns data_demo = data.select(*col_demo) data_author = data.select(*col_author) data_time = data.select(*col_time) data_rev = data.select(*col_rev) data_rec = data.select(*col_rec)
i. Games Analysis
In this section, we will try to understand the review and recommendation patterns for different games. We will consider the number of reviews analogous to the popularity of the game and the number of True recommendations analogous to the gamer’s preference for the game.
Finding the Most Popular Games
# the data frame is grouped by the game and the number of occurrences are counted app_names = data_rec.groupBy("app_name").count()
# the data frame is ordered depending on the count for the highest 20 games app_names_count = app_names.orderBy(app_names["count"].desc()).limit(20)
# a pandas data frame is created for plotting app_counts = app_names_count.toPandas()
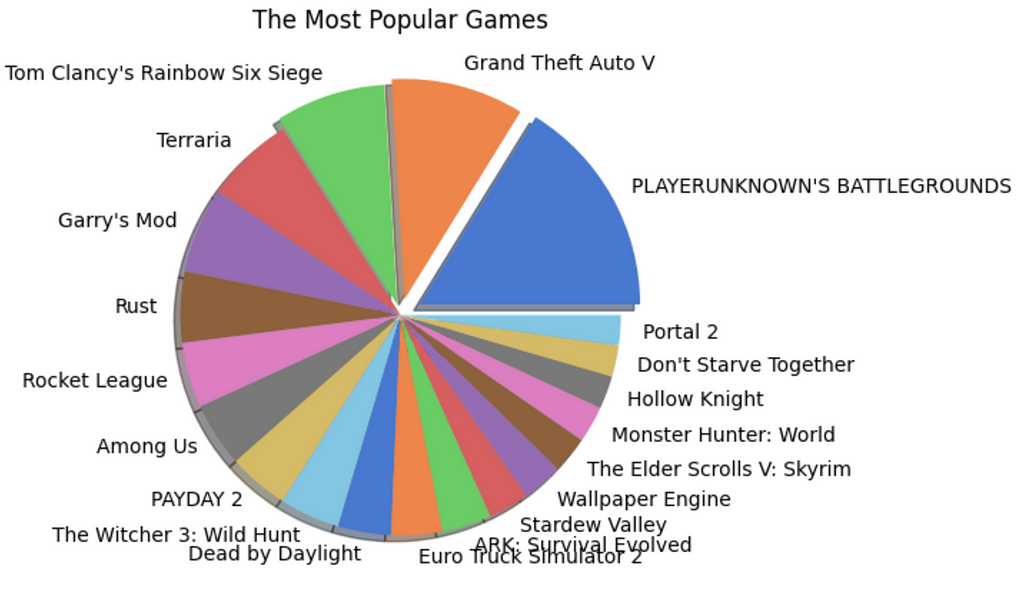
# A pie chart is created fig = plt.figure(figsize = (10,5)) colors = sns.color_palette("muted") explode = (0.1,0.075,0.05,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0) plt.pie(x = app_counts["count"], labels = app_counts["app_name"], colors = colors, explode = explode, shadow = True) plt.title("The Most Popular Games") plt.show()
Finding the Most Recommended Games
# Pick the 20 highest recommended games and convert it in to pandas data frame true_counts = data_rec.filter(data_rec["recommended"] == "true").groupBy("app_name").count() recommended = true_counts.orderBy(true_counts["count"].desc()).limit(20) recommended_apps = recommended.toPandas()
# Pick the games such that both they are in both the popular and highly recommended list true_apps = list(recommended_apps["app_name"]) true_app_counts = data_rec.filter(data_rec["app_name"].isin(true_apps)).groupBy("app_name").count() true_app_counts = true_app_counts.orderBy(true_app_counts["count"].desc()) true_app_counts = true_app_counts.toPandas()
# Evaluate the percent of true recommendations for the top games and sort them true_perc = [] for i in range(0,20,1): percent = (true_app_counts["count"][i]-recommended_apps["count"][i])/true_app_counts["count"][i]*100 true_perc.append(percent) recommended_apps["recommend_perc"] = true_perc recommended_apps = recommended_apps.sort_values(by = "recommend_perc", ascending = False)
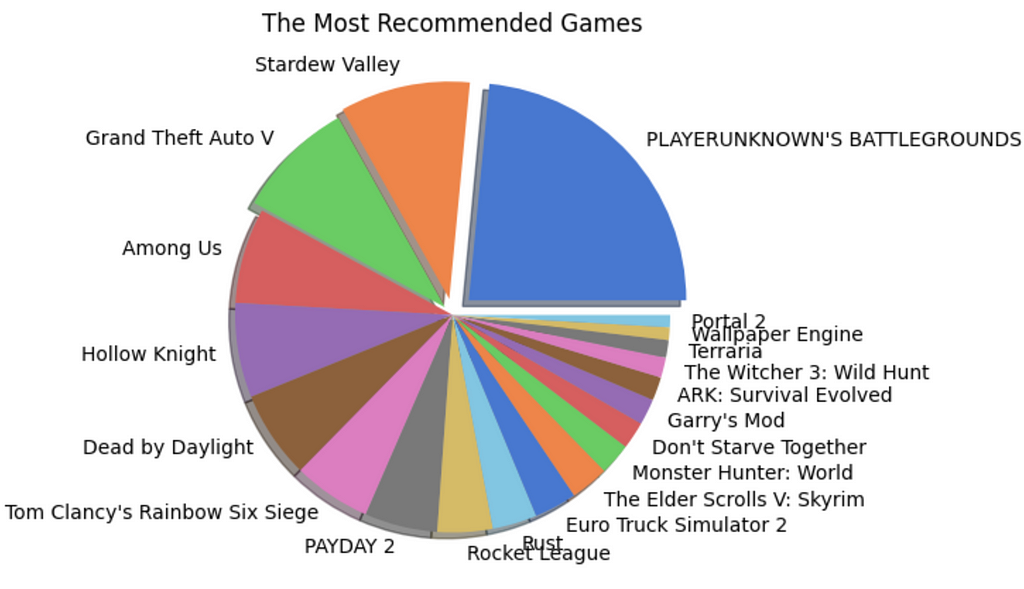
# Built a pie chart to visualize fig = plt.figure(figsize = (10,5)) colors = sns.color_palette("muted") explode = (0.1,0.075,0.05,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0) plt.pie(x = recommended_apps["recommend_perc"], labels = recommended_apps["app_name"], colors = colors, explode = explode, shadow = True) plt.title("The Most Recommended Games") plt.show()
Figure 13: Shows the pie charts for popular and recommended games. Images by Author
Insights
Player Unknown’s Battlegrounds (PUBG) is the most popular and most recommended game of 2021.
However, the second positions for the two categories are held by Grand Theft Auto V (GTA V) and Stardew Valley respectively. This shows that being popular does not mean all the players recommend the game to another player.
The same pattern is observed with other games also. However, the number of reviews for a game significantly affects this trend.
ii. Demographic Analysis
We will find the demography, especially, the locality of the gamers using the data_demo data frame. This analysis will help us understand the popular languages used for review and languages used by reviewers of popular games. We can use this trend to determine the demographic influence and sentiments of the players to be used for recommending new games in the future.
Finding Popular Review Languages
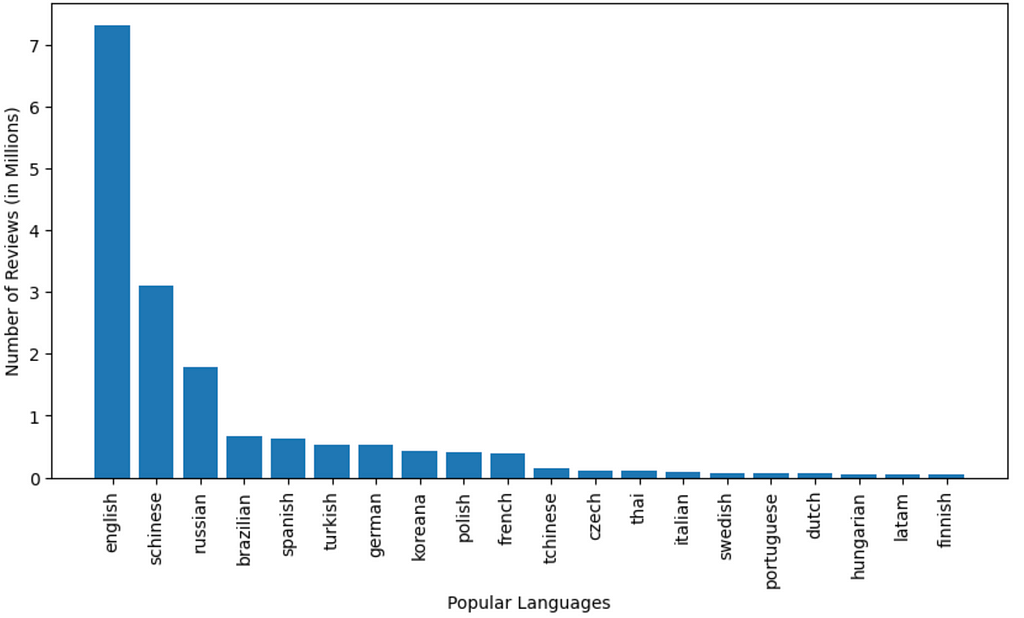
# We standardize the language names in the language column, then group them, # Count by the groups and convert into pandas df after sorting them the count author_lang = data_demo.select(lower("language").alias("language")) .groupBy("language").count().orderBy(col("count").desc()). limit(20).toPandas()
# Plotting a bar graph fig = plt.figure(figsize = (10,5)) plt.bar(author_lang["language"], author_lang["count"]) plt.xticks(rotation = 90) plt.xlabel("Popular Languages") plt.ylabel("Number of Reviews (in Millions)") plt.show()
Finding Review Languages of Popular Games
# We group the data frame based on the game and language and count each occurrence data_demo_new = data_demo.select(lower("language"). alias("language"), "app_name") games_lang = data_demo_new.groupBy("app_name","language").count().orderBy(col("count").desc()).limit(100).toPandas()
# Plot a stacked bar graph to visualize grouped_games_lang = games_lang_df.pivot(index='app_name', columns='language', values='count') grouped_games_lang.plot(kind='bar', stacked=True, figsize=(12, 6)) plt.title('Count of Different App Names and Languages') plt.xlabel('App Name') plt.ylabel('Count') plt.show()
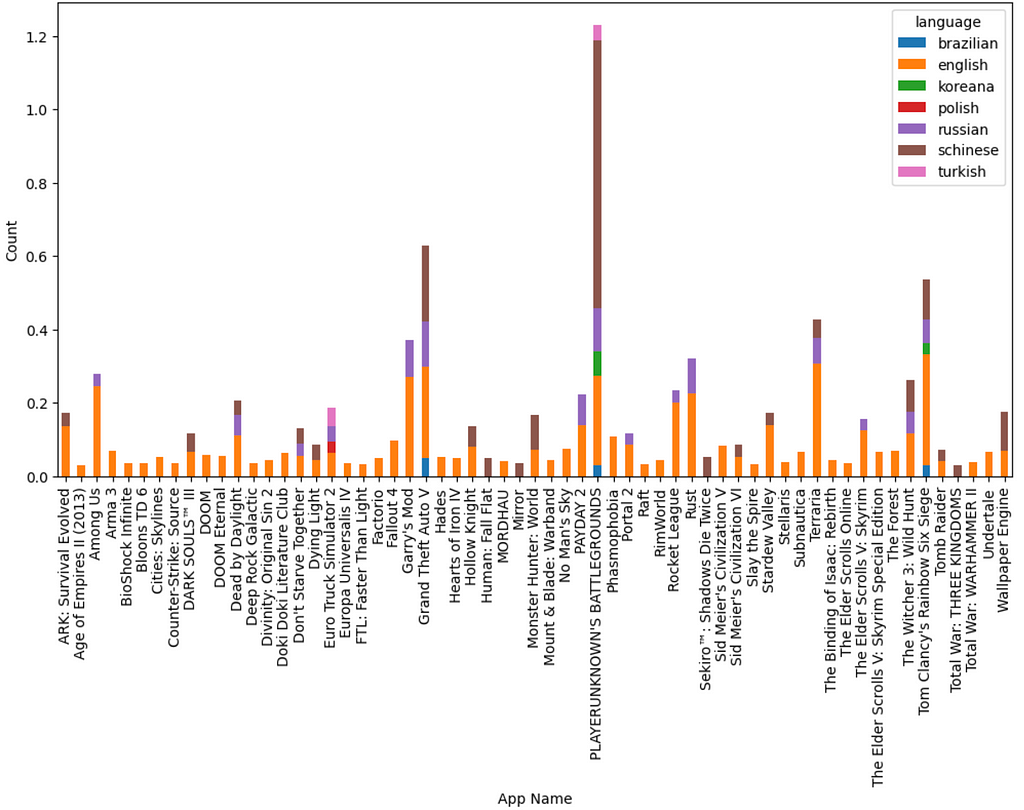
Figure 14: Language Popularity; Language Popularity among Popular games. Images by Author
Insights
English is the most popular language used by reviewers followed by Schinese and Russian
Schinese is the most widely used language for the most popular game (PUBG), whereas, English is widely used for the second most popular game (GTA V) and almost all others!
The popularity of a game seems to have roots in the area of origin. PUBG is a product of a South Korean gaming company and we observe that it has the Korean language among one of the highly used.
Time, author, and review analyses are also performed on this data, however, do not give any actionable insights. Feel free to visit the GitHub repository for the full project documentation.
3. d. Game Recommendation using Spark ML Library
We have reached the last stage of this project, where we will implement the Alternating Least Squares (ALS) machine-learning algorithm from the Spark ML Library. This model utilizes the collaborative filtering technique to recommend games based on player’s behavior, i.e., the games they played before. This algorithm identifies the game selection pattern for players who play each available game on the Steam App.
For the algorithm to work,
We require three variables — the independent variable, target variable(s) — depending on the number of recommendations, here 5, and a rating variable.
We encode the games and the authors to make the computation easier. We also convert the booleanrecommended column into a rating column with True = 5, and False = 1.
Also, we will be recommending 5 new games for each played game and therefore we consider the data of the players who have played more than five for modeling the algorithm.
# Convert author_steamid and app_id to indices, and use the recommended column for rating author_indexer = StringIndexer(inputCol="author_steamid", outputCol="author_index").fit(new_pair_games) app_indexer = StringIndexer(inputCol="app_name", outputCol="app_index").fit(new_pair_games) new_pair_games = new_pair_games.withColumn("Rating", when(col("recommended") == True, 5).otherwise(1))
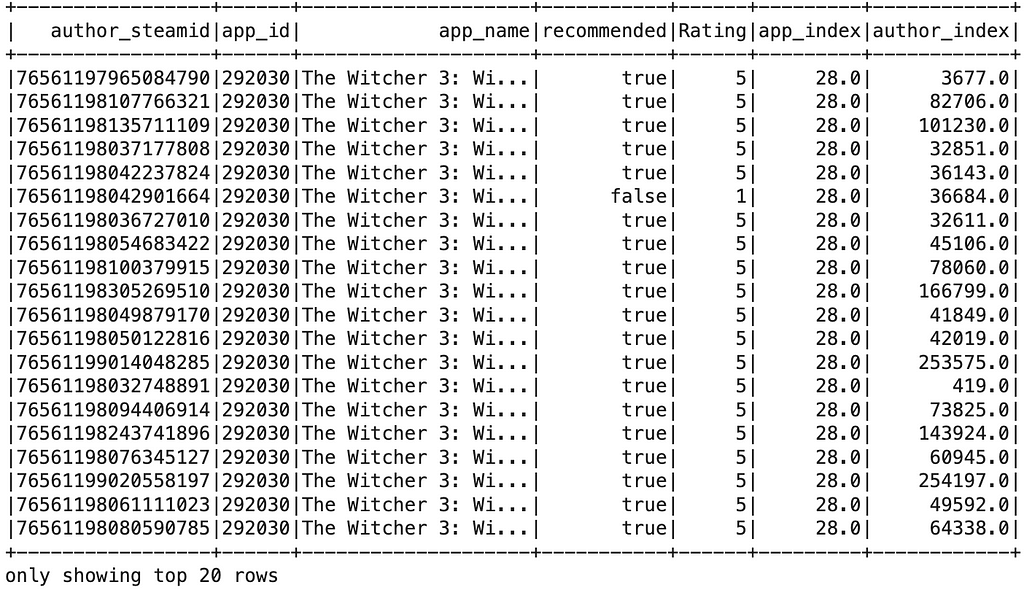
# We apply the indexing to the data frame by invoking the reduce phase function transform() new_pair = author_indexer.transform(app_indexer.transform(new_pair_games)) new_pair.show()
# The reference chart for games games = new_pair.select("app_index","app_name").distinct().orderBy("app_index")
Figure 16: The game list with the corresponding index for reference. Image by Author
Implementing ALS Algorithm
# Create an ALS (Alternating Least Squares) model als = ALS(maxIter=10, regParam=0.01, userCol="app_index", itemCol="author_index", ratingCol="Rating", coldStartStrategy="drop")
# Fit the model to the data model = als.fit(new_pair)
# Generate recommendations for all items app_recommendations = model.recommendForAllItems(5) # Number of recommendations per item
# Display the recommendations app_recommendations.show(truncate=False)
Figure 17: The recommendation and rating generated for each author based on their gaming history. Image by Author
We can cross-match the indices from Figure 16 to find the games recommended for each player. Thus, we implemented a basic recommendation system using the Spark Core ML Library.
3. e. Conclusion
In this project, we could successfully implement the following —
Download and install the Hadoop ecosystem — HDFS and MapReduce — to store, access, and extract big data efficiently, and implement big data analytics much faster using a personal computer.
Install the Apache Spark API for Python (PySpark) and integrate it with the Hadoop ecosystem, enabling us to carry out big data analytics and some machine-learning operations.
The games and demographic analysis gave us some insights that can be used to improve the gaming experience and control the player churn. Keeping the players updated and informed about the trends in their peers should be a priority for the Steam platform. Suggestions like “most played”, “most played in your region”, “most recommended”, and “don’t miss out on these new games” can keep the players active.
The Steam Application can use the ALS recommendation system to recommend new games to existing players based on their profile and keep them engaged and afresh.
4. What Next?
Implement Natural Language Processing techniques in the review column, for different languages to extract the essence of the reviews and improve the gaming experience.
Steam can report bugs in the games based on the reviews. Developing an AI algorithm that captures the review content, categorizes it, and sends it to appropriate personnel could do wonders for the platform.
We have all experienced at least one demo that has fallen flat. This is particularly a problem in data science, a field where a lot can go wrong on the day. Data scientists often have to balance challenges when presenting to audiences with varying experience levels. It can be challenging to both show the value and explain core concepts of a solution to a wide audience.
This article aims to help overcome the hurdles and help you share your hard work! We always work so hard to improve models, process data, and configure infrastructure. It’s only fair that we also work hard to make sure others see the value in that work. We will explore using the Gradio tool to share AI products. Gradio is an important part of the Hugging Face ecosystem. It’s also used by Google, Amazon and Facebook so you’ll be in great company! Whilst we will use Gradio, a lot of the key concepts can be replicated in common alternatives like StreamLit with Python or Shiny with R.
The importance of stakeholder/customer engagement in data science
The first challenge when pitching is ensuring that you are pitching at the right level. To understand how your AI model solves problems, customers first need to understand what it does, and what the problems are. They may have a PhD in data science, or they may never have heard of a model before. You don’t need to teach them linear algebra nor should you talk through a white paper of your solution. Your goal is to convey the value added by your solution, to all audiences.
This is where a practical demo comes in. Gradio is a lightweight open source package for making practical demos [1]. It is well documented that live demos can feel more personal, and help to drive conversation/generate new leads [2]. Practical demos can be crucial in building trust and understanding with new users. Trust builds from seeing you use the tool, or even better testing with your own inputs. When users can demo the tool they know there is no “Clever Hans” [3] process going on and what they see is what they get. Understanding grows from users seeing the “if-this-then-that” patterns in how your solution operates.
Then comes the flipside … everyone has been to a bad live demo. We have all sat through or made others sit through technical difficulties.
But technical difficulties aren’t the only thing that give us reason to fear live demos. Some other common off-putting factors are:
Information dumping: Pitching to customers should never feel like a lecture. Adding demos that are inaccessible can give customers too much to learn too quickly.
Developing a demo: Demos can be slow to build and actually slow down development. Regularly feeding back in “show and tells” is a particular problem for agile teams. Getting content for the show and tell can be an ordeal. Especially if customers grow accustomed to a live demo.
Broken dependencies: If you are responsible for developing a demo you might rely on some things staying constant. If they change you’ll need to start again.
Introducing Gradio
Now to the technical part. Gradio is a framework for demonstrating machine learning/AI models and it integrates with the rest of the Hugging Face ecosystem. The framework can be implemented using Python or JavaScript SDKs. Here, we will use Python. Before we build a demo an example Gradio app for named entity recognition is below:
Image Source: Hugging Face Documentation [4]
You can implement Gradio anywhere you currently work, and this is a key benefit of using the framework. If you are quickly prototyping code in a notebook and want instant feedback from stakeholders/colleagues you can add a Gradio interface. In my experience of using Gradio, I have implemented in Jupyter and Google Colab notebooks. You can also implement Gradio as a standalone site, through a public link hosted on HuggingFace. We will explore deployment options later.
Gradio demos help us solve the problems above, and get us over the fear of the live demo:
Information dumping: Gradio provides a simple interface that abstracts away a lot of the difficult information. Customers aren’t overloaded with working out how to interact with our tool and what the tool is all at once.
Developing a demo: Gradio demos have the same benefits as StreamLit and Shiny. The demo code is simple and builds on top of Python code you have already written for your product. This means you can make changes quickly and get instant feedback. You can also see the demo from the customer point of view.
Broken dependencies: No framework will overcome complete project overhauls. Gradio is built to accomodate new data, data types and even new models. The simplicity and range of allowed inputs/outputs, means that Gradio demos are kept quite constant. Not only that but if you have many tools, many customers and many projects the good news is that most of your demo code won’t change! You can just swap a text output to an image output and you’re all set up to move from LLM to Stable Diffusion!
Step-by-step guide to creating a demo using Gradio
The practical section of this article takes you from complete beginner to demonstration expert in Gradio. That being said, sometimes less can be more, if you are looking for a really simple demo to highlight the impact of your work by all means, stick to the basics!
For more information on alternatives like StreamLit, check out my earlier post:
Let’s start with a Hello World style example so that we can learn more about what makes up a Gradio demo. We have three fundamental components:
Input variables: We provide any number of input variables which users can input using toggles, sliders or other input widgets in our demo.
Function: The author of the demo makes a function which does the heavy lifting. This is where code changes between demos the most. The function will transform input variables into an output that the user sees. This is where we can call a model, transform data or do anything else we may need.
Interface: The interface combines the input variables, input widgets, function and output widgets into one demo.
So let’s see how that looks in code form:
This gives us the following demo. Notice how the input and output are both of the text type as we defined above:
Image Source: Image by Author
Now that we understand the basic components of Gradio, let’s get a bit more technical.
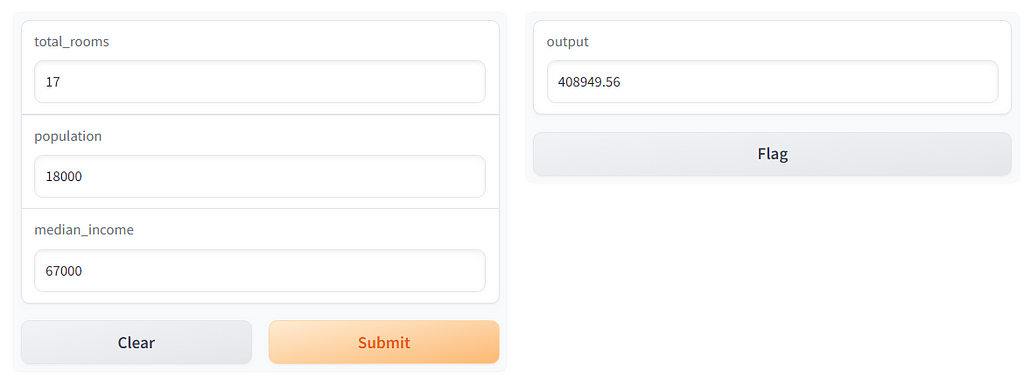
To see how we can apply Gradio to a machine learning problem, we will use the simplest algorithm we can. A linear regression. For the first example. We will build a linear regression using the California House Prices dataset. First, we update the basic code so that the function makes a prediction based on a linear model:
Then we update the interface so that the inputs and outputs match what we need. Note that we also use the Number type here as an input:
Then we hit run and see how it looks:
Image Source: Image by Author
Why stop now! We can use Blocks in Gradio to make our demos even more complex, insightful and engaging.
Controlling the interface
Blocks are more or less exactly as described. They are the building blocks of Gradio applications. So far, we have only used the higher level Interface wrapper. In the example below we will use blocks which has a slightly different coding pattern. Let’s update the last example to use blocks so that we can understand how they work:
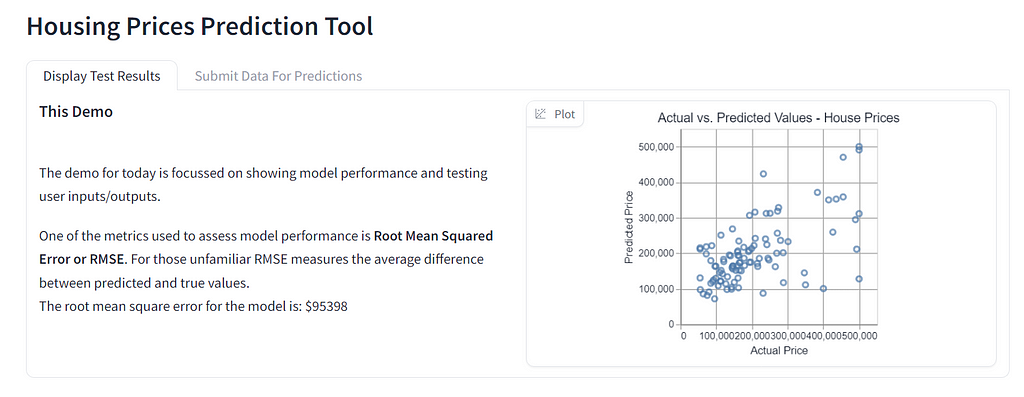
Instead of before when we had inputs, function and interface. We have now rolled everything back to its most basic form in Gradio. We no longer set up an interface and ask for it to add number inputs for us! Now we provide each individual Number input and one Number output. Building like this gives us much more control of the display.
With this new control over the demo we can even add new tabs. Tabs enable us to control the user flows and experience. We can first explain a concept, like how our predictions are distributed. Then on the next tab, we have a whole new area to let users prompt the model for predictions of their own. We can also use tabs to overcome technical difficulties. The first tab gives users a lot of information about model performance. This is all done through functions that were implemented earlier. If the model code doesn’t run on the day we still have something insightful to share. It’s not perfect, but it’s a lot better than a blank screen!
Note: This doesn’t mean we can hide technical difficulties behind tabs! We can just use tabs to give audiences something to go on if all else fails. Then reshare the demo when we resolve the technical issues.
Image Source: Image by Author
Ramping up the complexity shows how useful Gradio can be to show all kinds of information! So far though we have kept to a pretty simple model. Let’s now explore how we would use Gradio for something a bit more complex.
Gradio for AI Models and Images
The next application will look at using Gradio to demonstrate Generative AI. Once again, we will use Blocks to build the interface. This time the demo will have two core components:
An intro tab explaining the limitations, in and out of scope uses of the model.
An inspiration tab showing some images generated earlier.
An interactive tab where users can submit prompts to generate images.
In this blog we will just demo a pre-trained model. To learn more about Stable Diffusion models, including key concepts and fine-tuning, check out my earlier blog:
As this is a demo, we will start from the most difficult component. This ensures we will have the most time to deliver the hardest piece of work. The interactive tab is likely to be the most challenging, so we will start there. So that we have an idea of what we are aiming for our demo page will end up looking something like this:
Image Source: Image by Author. Stable Diffusion Images are AI Generated.
To achieve this the demo code will combine the two examples above. We will use blocks, functions, inputs and buttons. Buttons enable us to work in a similar way to before where we have inputs, outputs and functions. We use buttons as event listeners. Event listeners help to control our logic flow.
Let’s imagine we are trying to start our demo. At runtime (as soon as the demo starts), we have no inputs. As we have no input, the model the demo uses has no prompt. With no prompt, the model cannot generate an image. This will cause an error. To overcome the error we use an event listener. The button listens for an event, in this case, a click of the button. Once it “hears” the event, or gets clicked, it then triggers an action. In this case, the action will be submitting a completed prompt to the model.
Let’s review some new code that uses buttons and compare it to the previous interface examples:
The button code looks like the interface code, but there are some big conceptual changes:
The button code uses blocks. This is because whilst we are using the button in a similar way to interface,we still need something to determine what the demo looks like.
Input and output widgets are used as objects instead of strings. If you go back to the first example, our input was “text” of type string but here it is prompt of type gr.Text().
We use button.click() instead of Interface.launch(). This is because the interface was our whole demo before. This time the event is the button click.
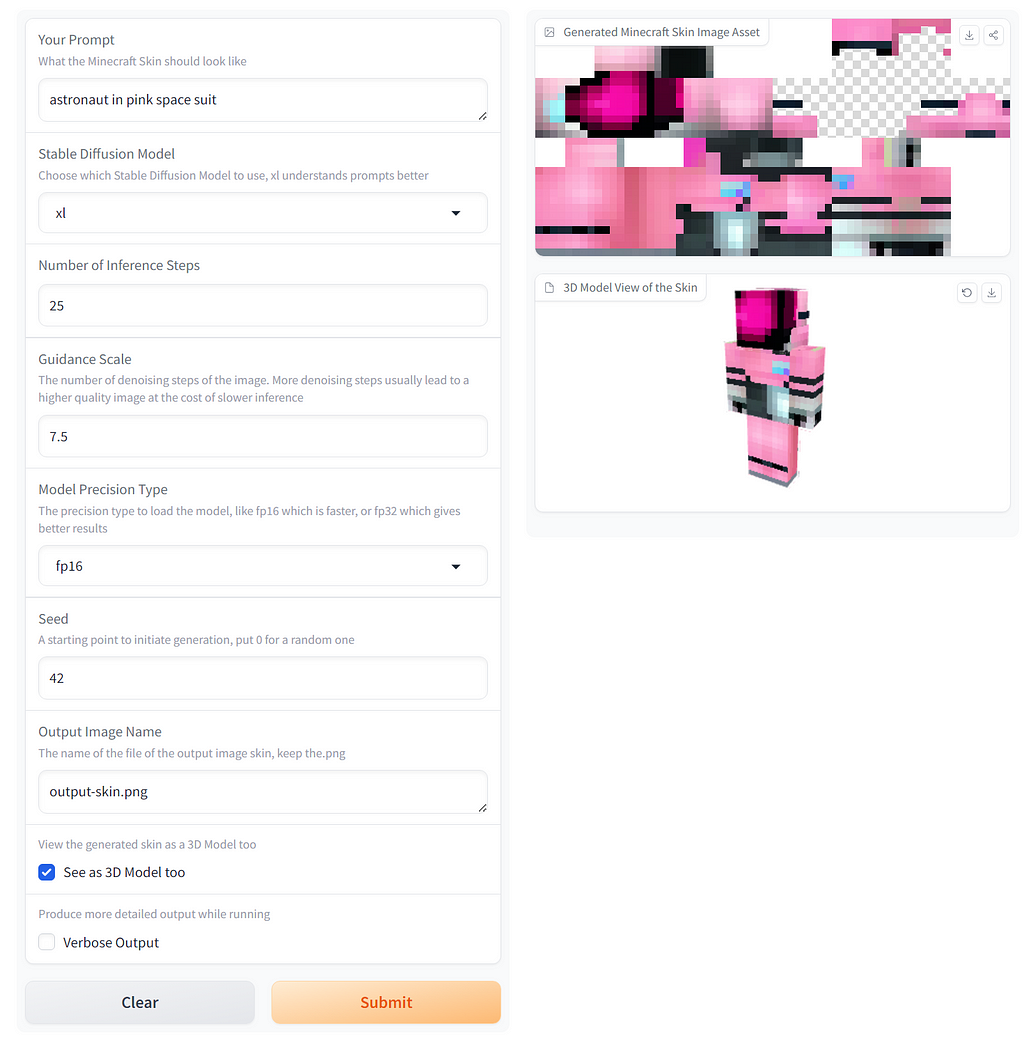
This is how the demo ends up looking:
Image Source: Image by Author. Stable Diffusion Images are AI Generated.
Can you see how important an event listener is! It has saved us lots of work in trying to make sure things happen in the right order. The beauty of Gradio means we also get some feedback on how long we will have to wait for images. The progress bar and time information on the left are great for user feedback and engagement.
The next part of the demo is sharing images we generated beforehand. This will serve as inspiration to customers. They will be able to see what is possible from the tool. For this we will implement another new output widget, a Gallery. The gallery displays the images we just generated:
An important note: We actually make use of our generate_images() function from before. As we said above, all of these lightweight app libraries enable us to simply build on top of our existing code.
The demo now looks like this, users are able to switch between two core functionalities:
Image Source: Image by Author. Stable Diffusion Images are AI Generated.
Finally we will tie everything together with a landing page for the demo. In a live or recorded demo the landing page will give us something to talk through. It’s useful but not essential. The main reason we include a landing page, is for any users that will test the tool without us being present. This helps to build accessibility of the tool and trust and understanding in users. If you need to be there every time customers use your product, it’s not going to deliver value.
This time we won’t be using anything new. Instead we will show the power of the Markdown() component. You may have noticed we have used some Markdown already. For those familiar, Markdown can help express all kinds of information in text. The code below has some ideas, but for your demos, get creative and see how far you can take Markdown in Gradio:
Image Source: Image by Author
The finished demo is below. Let me know what you think in the comments!
Image Source: Image by Author. Stable Diffusion Images are AI Generated.
Sharing with customers
Whether you’re a seasoned pro, or pitching beginner sharing the demo can be daunting. Building demonstrations and pitching are two very different skillsets. This article so far has helped to build your demo. There are great resources online to help pitching [5]. Let’s now focus on the intersection of the two, how you can share the demo you built, effectively.
Baring in mind your preferred style, live demo is guaranteed to liven up your pitch (pun intended!). To a technical audience we can set off our demo right in our notebook. This is useful to those who want to get into the code. I recommend sharing this way with new colleagues, senior developers and anyone looking to collaborate or expand your work. If you are using an alternative to Gradio, I’d still recommend sharing your code at a high level with this audience. It can help bring new developers onboard, or explain your latest changes to senior developers.
An alternative is to present the live demo using just a “front-end”. This can be done using the link provided when you run the demo. When you share this way customers don’t have to get bogged down in code to see your demo. This is how the screenshots so far have been taken. I’d recommend this for live non-technical audiences, new customers and for agile feedback/show and tell sessions. We can get to this using a link provided if you built your demo in Gradio.
The link we can use to share also allows us to share the demo with others. By setting a share parameter when we launch the demo:
demo.launch(debug=True, share=True)
This works well for users who can’t make the live session, or want more time to experiment with the product. This link is available for 72 hours. There is a need for caution at this point as demos are hosted publicly from your machine. It is advised that you consider the security aspects of your system before sharing this way. One thing we can do to make this a bit more secure is to share our demo with password protection:
You can take this further by using authorisation techniques. Examples include using Hugging Face directly or Google for OAuth identity providers [6]. Further protections can be put in place for blocked files and file paths on the host machine [6].
This does not solve security concerns with sharing this way completely. If you are looking to share privately, containerisation through a cloud provider may be a better option [7].
For wider engagement, you may want to share your demo publicly to an online audience. This can be brilliant for finding prospective customers, building word of mouth or getting some feedback on your latest AI project. I have been sharing work publicly for feedback for years on Medium, Kaggle and GitHub. The feedback I have had has definitely improved my work over time.
If you are using Gradio demos can be publicly shared through Hugging Face. Hugging Face provides Spaces which are used for sharing Gradio apps. Spaces provide a free platform to share your demo. There are costs attached to GPU instances (ranging from $0.40 to $5 per hour). To share to spaces, the following documentation is available [6]. The docs explain how you can:
Share to spaces
Implement CI/CD of spaces with GitHub actions
Embedding Gradio demos in your own website from spaces!
Spaces are helpful for reaching a wider audience, without worrying about resources. It is also a permanent link for prospective customers. It does make it more important to include as much guidance as possible. Again, this is a public sharing platform on compute you do not own. For more secure requirements, containerisation and dedicated hosting may be preferred. A particularly great example is this Minecraft skin generator [8].
The elephant in the room in the whole AI community right now is of course LLMs. Gradio has plenty of components built with LLM in mind. This includes using agentic workflows and models as a service [9].
It is also worth mentioning custom components. Custom components have been developed by other data scientists and developers. They are extensions on top of the Gradio framework. Some great examples are:
Extensions are not unique to Gradio. If you choose to use StreamLit or Shiny to build your demo there are great extensions to those frameworks as well:
A final word on sharing work, in an agile context. When sharing regularly through show and tells or feedback sessions lightweight demos are a game changer. The ability to easily layer on from MVP to final product really helps customers see their journey with your product.
In summary, Gradio is a lightweight, open source tool for sharing AI products. Some important security steps may need consideration depending on your requirements. I really hope you are feeling more prepared with your demos!
If you enjoyed this article please consider giving me a follow, sharing this article or leaving a comment. I write a range of content across the data science field, so please checkout more on my profile.
An open-source library for building knowledge graphs from text corpus using open-source LLMs like Llama 3 and Mixtral.
Image generated by the Author using Adobe Photoshop
In this article, I will share a Python library — the Graph Maker — that can create a Knowledge Graph from a corpus of text as per a given Ontology. The Graph Maker uses open-source LLMs like Llama3, Mistral, Mixtral or Gemma to extract the KG.
We will go through the basics of ‘Why’ and ‘What’ of the Graph Maker, a brief recap of the previous article, and how the current approach addresses some of its challenges. I will share the GitHub repository at the end of this article.
Introduction
This article is a sequel to the article I wrote a few months ago about how to convert any text into a Graph.
The article received an overwhelming response. The GitHub repository shared in the article has more than 180 Forks and more than 900 Stars. The article itself was read by more than 80K readers on the Medium. Recently the article was attributed in the following paper published by Prof Markus J. Buehler at MIT.
This is a fascinating paper that demonstrates the gigantic potential of Knowledge Graphs in the era of AI. It demonstrates how KGs can be used, not only to retrieve knowledge but also to discover new knowledge. Here is one of my favourite excerpts from this paper.
“For instance, we will show how this approach can relate seemingly disparate concepts such as Beethoven’s 9th symphony with bio-inspired materials science”
These developments are a big reaffirmation of the ideas I presented in the previous article and encouraged me to develop the ideas further.
I also received numerous feedback from fellow techies about the challenges they encountered while using the repository, and suggestions for improving the idea. I incorporated some of these suggestions into a new Python package I share here.
Before we discuss the working of the package — The Graph Maker — let us discuss the ‘Why’ and the ‘What’ of it.
A Brief Recap
We should probably start with ‘Why Graphs’. However, We discussed this briefly in my previous article. Feel free to hop onto that article for a refresher. However, let us briefly discuss the key concepts that are relevant to our current discussion here.
TL;DR this section if you are already well versed in the lore of Knowledge Graphs.
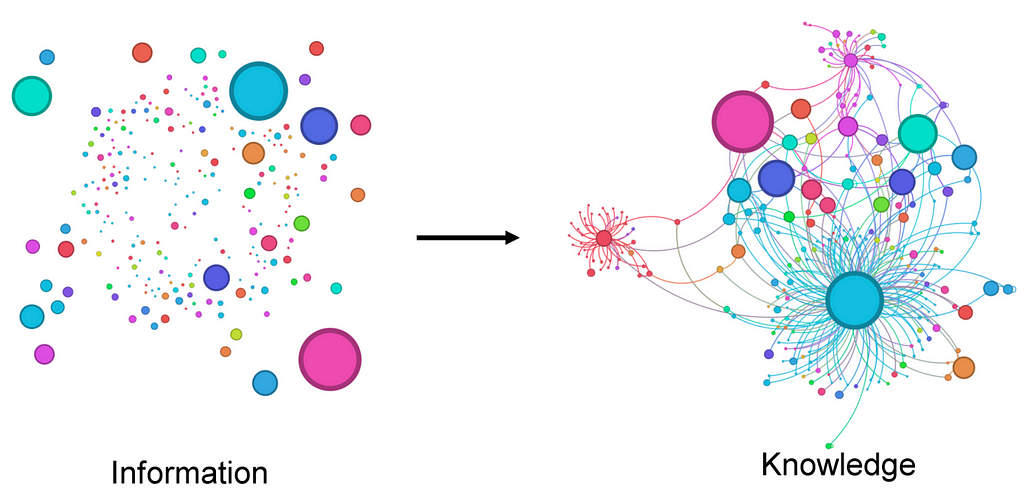
Here is an illustration that sums up the idea of Knowledge Graphs neatly.
To create a KG, we need two pieces of information.
Knowledge Base: This can be a corpus of text, a code base, a collection of articles, etc.
Ontology: The categories of the entities, and the types of their relationships we care about. I am probably oversimplifying the definition of ontology here but it works for our purpose.
Here is a simple ontology
Entities: Person, Place Relationships: Person — related to → Person Person — lives in → Place Person — visits → Place
Given these two pieces of information, we can build a KG from a text that mentions people and places. However, let’s say our knowledge base is about a clinical study of prescription drugs and their interactions. We might use a different ontology where Compounds, Usage, Effects, Reactions etc may form our ontology.
Although this approach lacks the rigour of the traditional methods of generating KGs, it has its merits. It can generate KGs with unstructured data more easily than traditional methods. The KGs that it generates are, in some sense, also unstructured. However, they are easier to build and are richer in information. They are well suited for GRAG (Graph Retrieval Augmented Generation) like applications.
Why The Graph Maker?
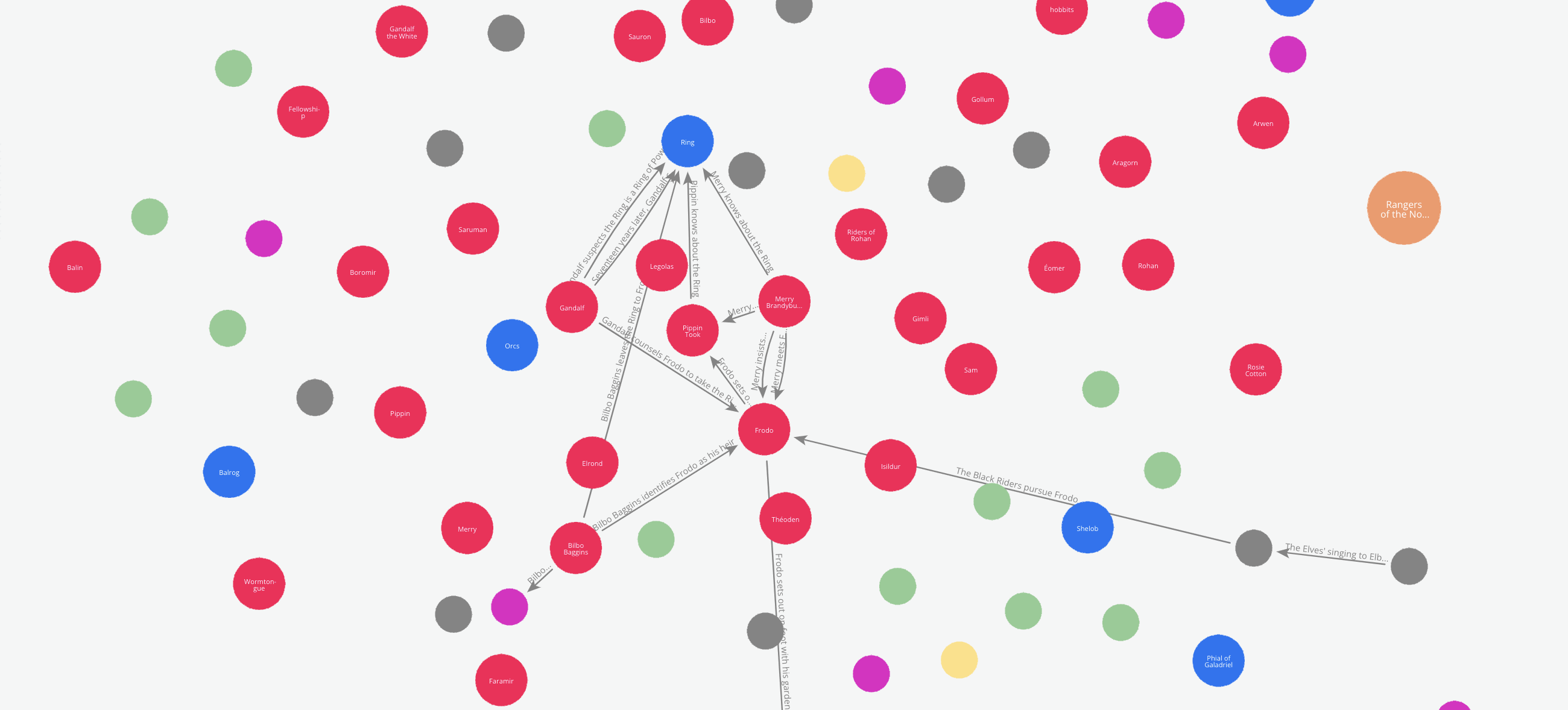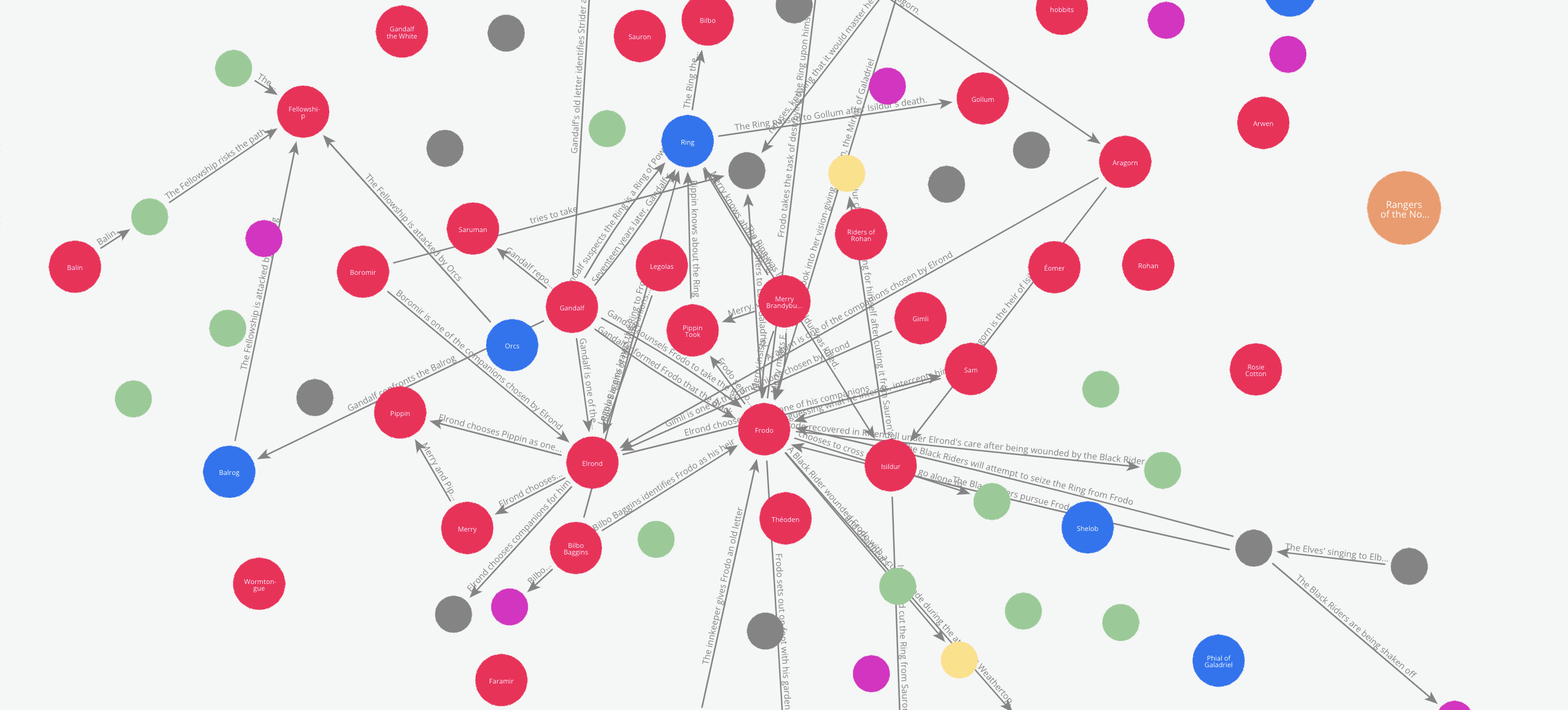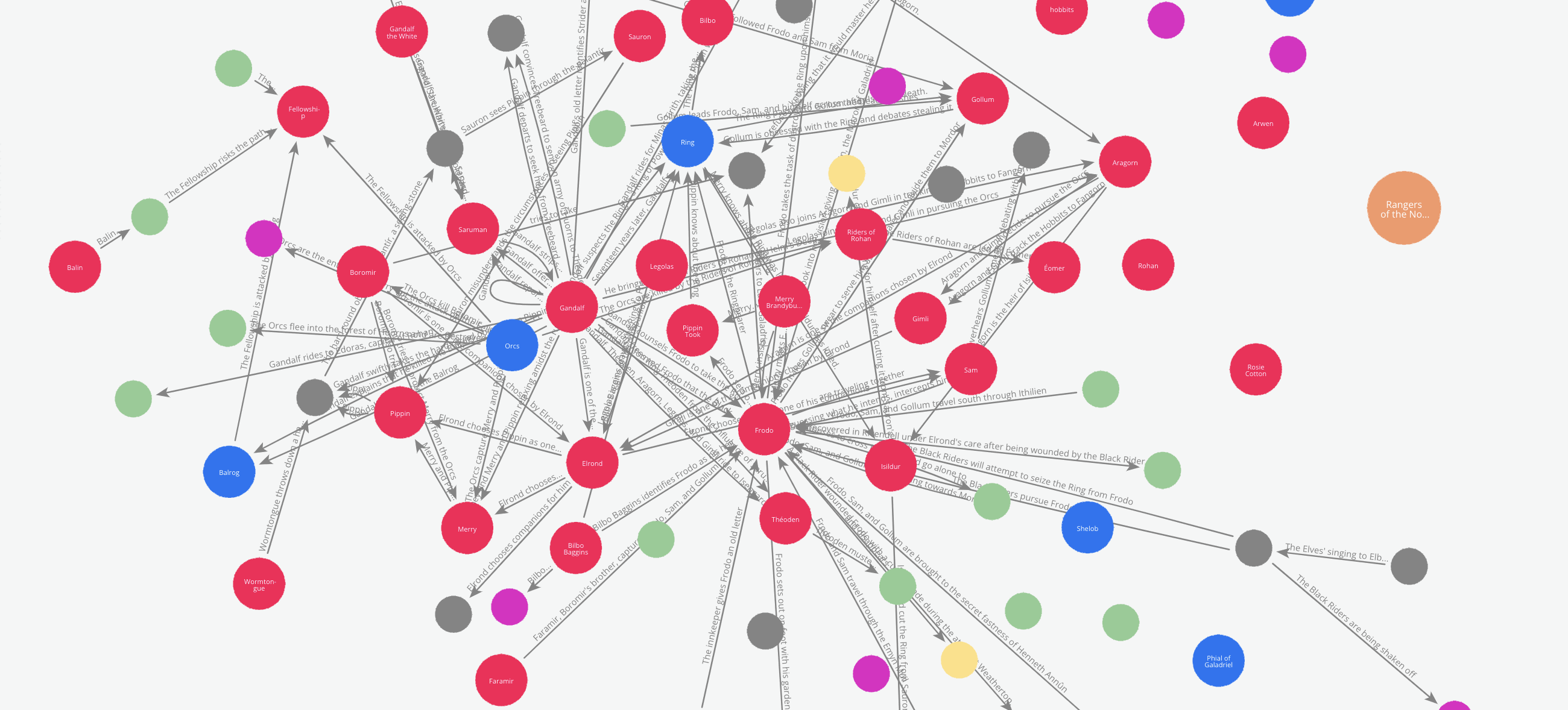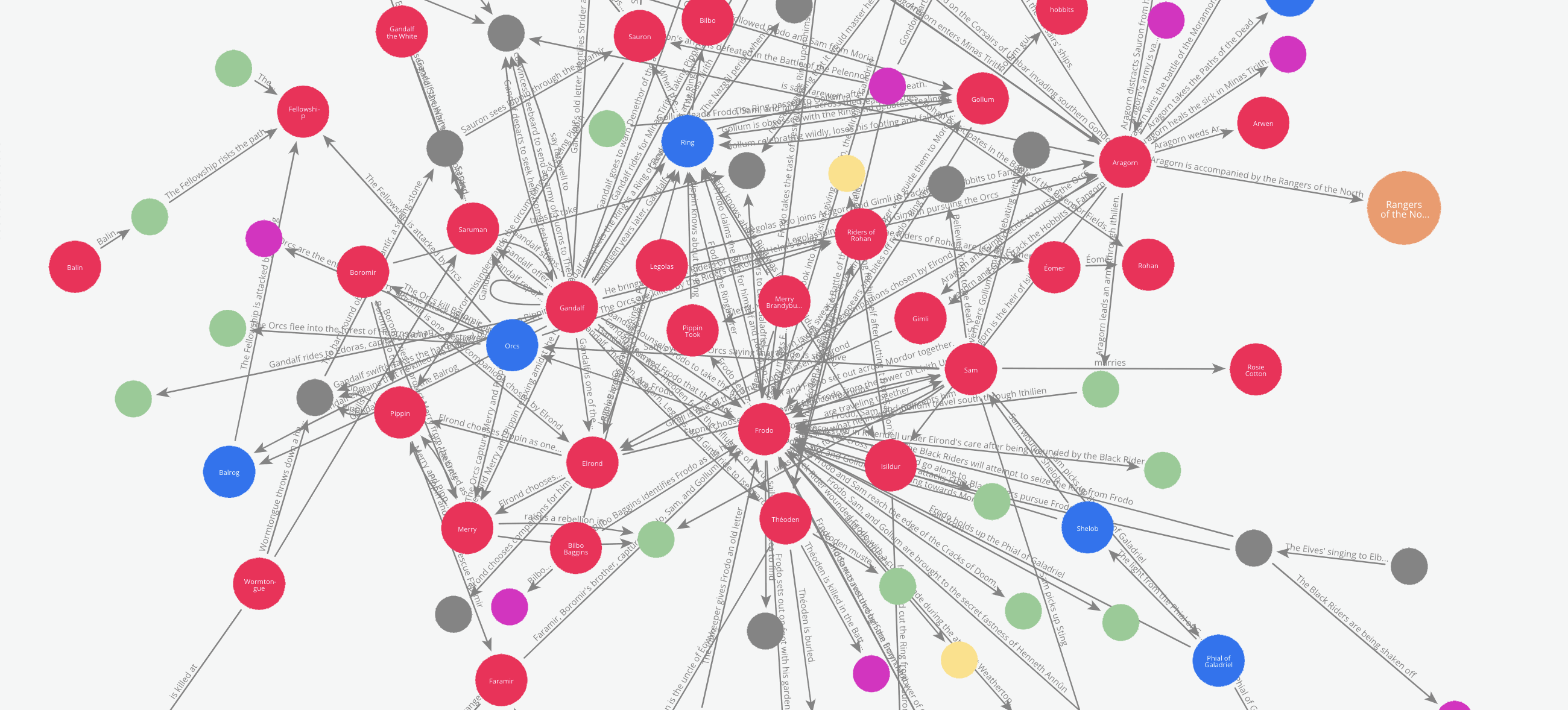
Let me list a few challenges and observations I received in the feedback for my previous article. It will help us understand the challenges in creating KGs with LLMs. Let us use the Wikipedia summary of the Lord of the Rings books. One cant not love the Lord of the Rings after all!
Meaningful Entities
Given a free run, the entities that the LLM extracts can be too diverse in their categories. It mistakes by marking abstract concepts as entities. For example in the text “Bilbo Baggins celebrates his birthday and leaves the Ring to Frodo”, the LLM may extract “Bilbo Baggins celebrates his birthday” or “Celebrates his birthday” as ‘Action’. But it may be more useful if it extracts “Birthday” as an ‘Event’.
Consistent Entities
It can also mistake marking the same entity differently in different contexts. For example:
‘Sauron’, ‘the Dark Lord Sauron’and‘the Dark Lord’Should not be extracted as different entities. Or if they are extracted as different entities, they should be connected with an equivalence relationship.
Resilience in parsing
The output of the LLMs is, by nature, indeterministic. To extract the KG from a large document, we must split the corpus into smaller text chunks and then generate subgraphs for every chunk. To build a consistent graph, the LLM must output JSON objects as per the given schema consistently for every subgraph. Missing even one may affect the connectivity of the entire graph adversely.
Although LLMs are getting better at responding with well-formatted JSON objects, It is still far from perfect. LLMs with limited context windows may also generate incomplete responses.
Categorisation of the Entities
LLMs can error generously when recognising entities. This is a bigger problem when the context is domain-specific, or when the entities are not named in standard English. NER models can do better at that, but they too are limited to the data they are trained on. Moreover, they can’t understand the relations between the entities.
To coerce an LLM to be consistent with categories is an art in prompt engineering.
Implied relations
Relations can be explicitly mentioned, or implied by the context. For example:
“Bilbo Baggins celebrates his birthday and leaves the Ring to Frodo” implies the relationships: Bilbo Baggins → Owner → Ring Bilbo Baggins → heir → Frodo Frodo → Owner → Ring
Here I think LLMs at some point in time will become better than any traditional method of extracting relationships. But as of now, this is a challenge that needs clever prompt engineering.
The Graph Maker
The graph maker library I share here improves upon the previous approach by travelling halfway between the rigour and the ease — halfway between the structure and the lack of it. It does remarkably better than the previous approach I discussed on most of the above challenges.
As opposed to the previous approach, where the LLM is free to discover the ontology by itself, the graph maker tries to coerce the LLM to use a user-defined ontology.
Here is how it works in 5 easy steps.
1. Define the Ontology of your Graph
The library understands the following schema for the Ontology. Behind the scenes, ontology is a pedantic model.
ontology = Ontology( # labels of the entities to be extracted. Can be a string or an object, like the following. labels=[ {"Person": "Person name without any adjectives, Remember a person may be referenced by their name or using a pronoun"}, {"Object": "Do not add the definite article 'the' in the object name"}, {"Event": "Event event involving multiple people. Do not include qualifiers or verbs like gives, leaves, works etc."}, "Place", "Document", "Organisation", "Action", {"Miscellaneous": "Any important concept can not be categorised with any other given label"}, ], # Relationships that are important for your application. # These are more like instructions for the LLM to nudge it to focus on specific relationships. # There is no guarantee that only these relationships will be extracted, but some models do a good job overall at sticking to these relations. relationships=[ "Relation between any pair of Entities", ], )
I have tuned the prompts to yield results that are consistent with the given ontology. I think it does a pretty good job at it. However, it is still not 100% accurate. The accuracy depends on the model we choose to generate the graph, the application, the ontology, and the quality of the data.
2. Split the text into chunks.
We can use as large a corpus of text as we want to create large knowledge graphs. However, LLMs have a finite context window right now. So we need to chunk the text appropriately and create the graph one chunk at a time. The chunk size that we should use depends on the model context window. The prompts that are used in this project eat up around 500 tokens. The rest of the context can be divided into input text and output graph. In my experience, smaller chunks of 200 to 500 tokens generate a more detailed graph.
3. Convert these chunks into Documents.
The document is a pedantic model with the following schema
## Pydantic document model class Document(BaseModel): text: str metadata: dict
The metadata we add to the document here is tagged to every relation that is extracted out of the document.
We can add the context of the relation, for example, the page number, chapter, the name of the article, etc. into the metadata. More often than not, Each node pairs have multiple relations with each other across multiple documents. The metadata helps contextualise these relationships.
4. Run the Graph Maker.
The Graph Maker directly takes a list of documents and iterates over each of them to create one subgraph per document. The final output is the complete graph of all the documents.
Here is a simple example of how to achieve this.
from graph_maker import GraphMaker, Ontology, GroqClient
## -> Select a groq supported model model = "mixtral-8x7b-32768" # model ="llama3–8b-8192" # model = "llama3–70b-8192" # model="gemma-7b-it" ## This is probably the fastest of all models, though a tad inaccurate.
## -> Create a graph out of a list of Documents. graph = graph_maker.from_documents(docs) ## result: a list of Edges.
print("Total number of Edges", len(graph)) ## 1503
The Graph Makers run each document through the LLM and parse the response to create the complete graph. The final graph is as a list of edges, where every edge is a pydantic model like the following.
I have tuned the prompts so they generate fairly consistent JSONs now. In case the JSON response fails to parse, the graph maker also tries to manually split the JSON string into multiple strings of edges and then tries to salvage whatever it can.
5. Save to Neo4j
We can save the model to Neo4j either to create an RAG application, run Network algorithms, or maybe just visualise the graph using the Bloom
Each edge of the graph is saved to the database as a transaction. If you are running this code for the first time, then set the `create_indices` to true. This prepares the database by setting up the uniqueness constraints on the nodes.
5.1 Visualise, just for fun if nothing else In the previous article, we visualised the graph using networkx and pyvis libraries. Here, because we are already saving the graph to Neo4J, we can leverage Bloom directly to visualise the graph.
To avoid repeating ourselves, let us generate a different visualisation from what we did in the previous article.
Let’s say we like to see how the relations between the characters evolve through the book.
We can do this by tracking how the edges are added to the graph incrementally while the graph maker traverses through the book. To enable this, the Edge model has an attribute called ‘order’. This attribute can be used to add a temporal or chronological dimension to the graph.
In our example, the graph maker automatically adds the sequence number in which a particular text chunk occurs in the document list, to every edge it extracts from that chunk. So to see how the relations between the characters evolve, we just have to cross section the graph by the order of the edges.
Here is an animation of these cross-sections.
Animation generated by the Author
Graph and RAG
The best application of this kind of KG is probably in RAG. There are umpteen articles on Medium on how to augment your RAG applications with Graphs.
Essentially Graphs offer a plethora of different ways to retrieve knowledge. Depending on how we design the Graph and our application, some of these techniques can be more powerful than simple semantic search.
At the very basic, we can add embedding vectors into our nodes and relationships, and run a semantic search against the vector index for retrieval. However, I feel the real power of the Graphs for RAG applications is when we mix Cypher queries and Network algorithms with Semantic Search.
I have been exploring some of these techniques myself. I am hoping to write about them in my next article.
The Code
Here is the GitHub Repository. Please feel free to take it for a spin. I have also included an example Python notebook in the repository that can help you get started quickly.
Please note that you will need to add your GROQ credentials in the .env file before you can get started.
Initially, I developed this codebase for a few of my pet projects. I feel it can be helpful for many more applications. If you use this library for your applications, please share it with me. I would love to learn about your use cases.
Also if you feel you can contribute to this open source project, please do so and make it your own.
I hope you find the graph maker useful. Thanks for reading.
I am a learner of architecture (not the buildings… the tech kind). In the past, I have worked with Semiconductor modelling, Digital circuit design, Electronic Interface modelling, and the Internet of Things.
Currently, Data and Consumer Analytics @Walmart Keeps me busy.
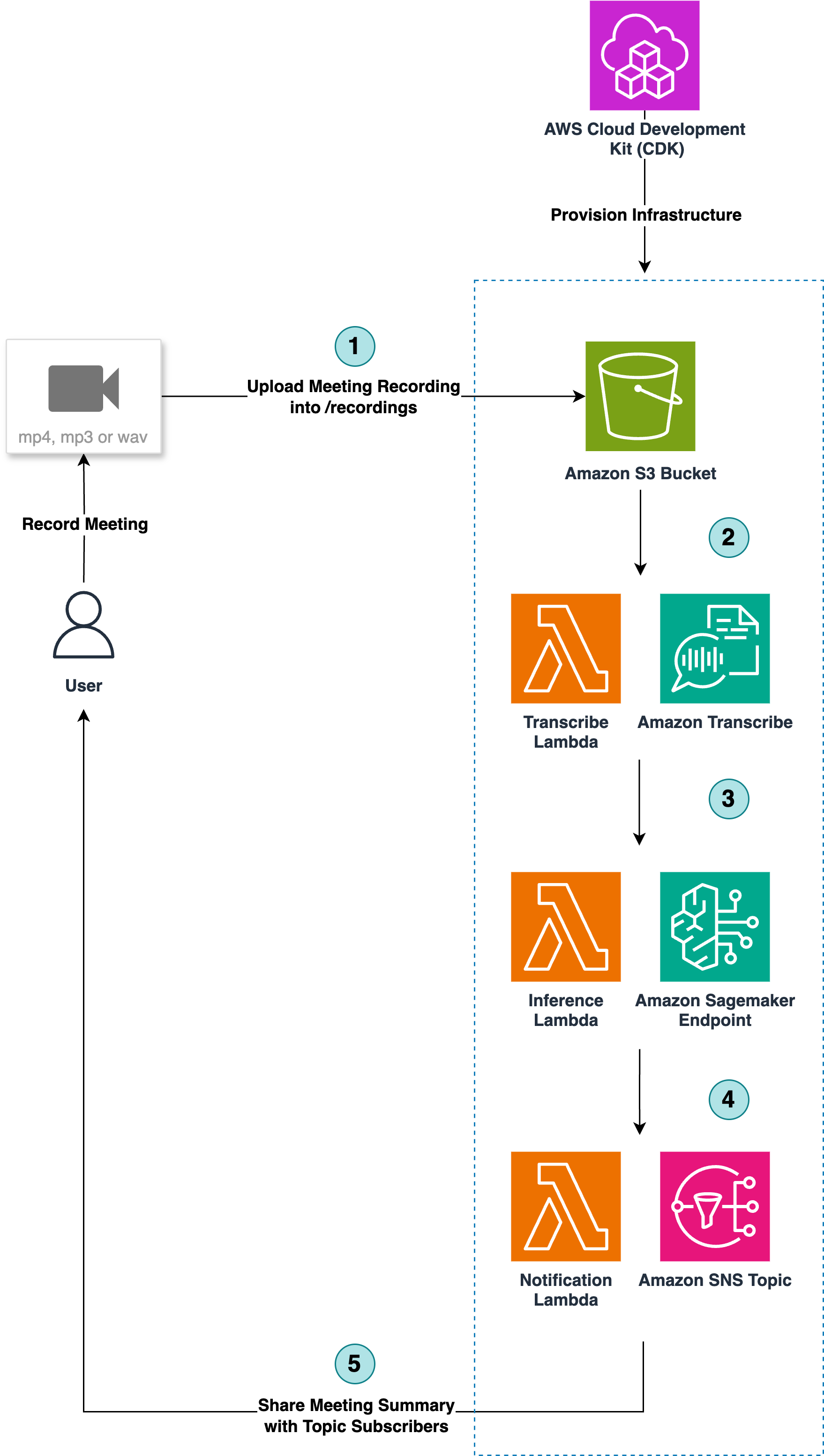
This post presents a solution to automatically generate a meeting summary from a recorded virtual meeting (for example, using Amazon Chime) with several participants. The recording is transcribed to text using Amazon Transcribe and then processed using Amazon SageMaker Hugging Face containers to generate the meeting summary. The Hugging Face containers host a large language model (LLM) from the Hugging Face Hub.
This post is co-written with Tim Camara, Senior Product Manager at Veritone. Veritone is an artificial intelligence (AI) company based in Irvine, California. Founded in 2014, Veritone empowers people with AI-powered software and solutions for various applications, including media processing, analytics, advertising, and more. It offers solutions for media transcription, facial recognition, content summarization, object […]
Large language models (LLMs) have unlocked new possibilities for extracting information from unstructured text data. Although much of the current excitement is around LLMs for generative AI tasks, many of the key use cases that you might want to solve have not fundamentally changed. Tasks such as routing support tickets, recognizing customers intents from a […]
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.