

A story about convergence of random variables set within the extraordinary voyage of the Nimrod
On the morning of Saturday, February 25, 1860, the passenger ship Nimrod pushed away from the docks at Liverpool in England. Her destination was the burgeoning port of Cork in Ireland — a distance of around 300 miles. Nimrod had plied this route dozens of times before as she and hundreds of other boats like her crisscrossed the sea between Ireland and England, picking up families from ports in Ireland and depositing them at ports in England before their migration to the United States.
Nimrod was a strong, iron-paddled boat powered by steam engines and a full set of sails — a modern, powerful, and sea-tested vessel of her era. At her helm was captain Lyall — an experienced seaman, an esteemed veteran of the Crimean war, and a gregarious, well-liked leader of the crew. Also on board were 45 souls and thousands of pounds worth of cargo. The year 1860 had been an unusually cold and wet year but on the weekend of February 25, the seas were calm and there was not a storm in sight.

By the evening of Monday, February 27, 1860 Nimrod had reached the Smalls lighthouse near the southern coast of Wales when her steam engines started failing. Fortunately, another steamboat — the City of Paris — happened to be in the vicinity and could have towed Nimrod to safety. Captain Lyall tried negotiating a fair price for the tow but failed. It seems the City of Paris’s captain demanded £1000 while Lyall could offer only a hundred although what actually transpired between the two captains is lost in the dustbin of history. What is known is that the City of Paris stayed with Nimrod for a short time before easing away, but not before her captain promised to apprise the harbormaster at Waterford about Nimrod’s distress.
Meanwhile, with over 100 miles of open sea waiting between him and Cork and no other tow in sight, Lyall wisely chose to stay close to the Welsh coast. Trying anything else would have been mad folly. Lyall set his course for the safety of Milford Haven, a nearby deep-water port in the south of Wales. Darkness had set but the lights of the coastal towns were clearly visible from the ship. It was past 10 pm on Monday, February 27. Hell was about to break loose.

As the captain navigated his impaired ship through the treacherous, rock-strewn, shallow waters off the Welsh coast, the winds picked up, first to a strong assertive breeze, then quickly to a gale, and soon to a full-throated hurricane. Instead of steering toward the quiet harbor of Milford Haven, Nimrod was getting blown by the storm toward the murderous cliffs of St. David’s Head. The captain dropped all anchors. For good measure, he also let loose the full length of iron chain, but the powerful winds kept dragging the ship. By the morning of Tuesday, February 28 with her sails blown to bits, Nimrod was getting pummeled by the waves and battered by the rocks at St. David’s head. The rescuers who had clambered on the cliff head threw rope upon rope at her but not one hook held. Around 8 AM on Tuesday, the waves struck Nimrod with such force, that she broke into three separate pieces. The people on the cliffs watched in horror and disbelief as she sank in under five minutes with all passengers lost. At the time of sinking, Nimrod was so maddeningly close to the shore that people on land could hear the desperate cries of the passengers as one by one they were swallowed by the waters.
The Irish Sea fills the land basin between Ireland and Britain. It contains one of the shallowest sea waters on the planet. In some places, water depth reaches barely 40 meters even as far out as 30 miles from the coastline. Also lurking beneath the surface are vast banks of sand waiting to snare the unlucky ship, of which there have been many. Often, a floundering ship would sink vertically taking its human occupants straight down with it and get lodged in the sand, standing erect on the seabed with the tops of her masts clearly visible above the water line — a gruesome marker of the human tragedy resting just 30 meters below the surface. Such was the fate of the Pelican when she sank on March 20, 1793, right inside Liverpool Harbor, a stone’s throw from the shoreline.
The geography of the Irish sea also makes it susceptible to strong storms that come from out of nowhere and surprise you with a stunning suddenness and an insolent disregard for any nautical experience you may have had. At the lightest encouragement from the wind, the shallow waters of the sea will coil up into menacingly towering waves and produce vast clouds of blindingly opaque spray. At the slightest slip of good judgement or luck, the winds and the sea and the sands of the Irish sea will run your ship aground or bring upon a worse fate. Nimrod was, sadly, just one of the hundreds of such wrecks that litter the floor of the Irish Sea.

It stands to reason that over the years, the Irish sea has become one of the most heavily studied and minutely monitored bodies of water on the planet. From sea temperature at different depths, to surface wind speed, to carbon chemistry of the sea water, to the distribution of commercial fish, the governments of Britain and Ireland keep a close watch on hundreds of marine parameters. Dozens of sea-buoys, surveying vessels, and satellites gather data round the clock and feed them into sophisticated statistical models that run automatically and tirelessly, swallowing thousands of measurements and making forecasts of sea-conditions for several days into the future — forecasts that have made shipping on the Irish Sea a largely safe endeavor.
It’s within this copious abundance of data that we’ll study the concepts of statistical convergence of random variables. Specifically, we’ll study the following four types of convergence:
- Convergence in distribution
- Convergence in probability
- Convergence in the mean
- Almost sure convergence
There is a certain hierarchy inherent among the four types of convergences with the convergence in probability implying a convergence in distribution, and a convergence in the mean and almost sure convergence independently implying a convergence in probability.
To understand any of the four types of convergences, it’s useful to understand the concept of sequences of random variables. Which pivots us back to Nimrod’s voyage out of Liverpool.
Sequences of random variables
It’s hard to imagine circumstances more conducive to a catastrophe than what Nimrod experienced. Her sinking was the inescapable consequence of a seemingly endless parade of misfortunes. If only her engines hadn’t failed, or Captain Lyall had secured a tow, or he had chosen a different port of refuge or the storm hadn’t turned into a hurricane, or the waves and rocks hadn’t broken her up, or the rescuers had managed to reach the stricken ship. The what-ifs seem to march away to a point on the distant horizon.
Nimrod’s voyage — be it a successful journey to Cork, or safely reaching one of the many possible ports of refuge, or sinking with all hands on board or any of the other possibilities limited only by how much you will allow yourself to twist your imagination — can be represented by any one of many possible sequences of events. Between the morning of February 25, 1860 and the morning of February 28, 1860, exactly one of these sequences materialized — a sequence that was to terminate in a unwholesomely bitter finality.
If you permit yourself to look at the reality of Nimrod’s fate in this way, you may find it worth your while to represent her journey as a long, theoretically infinite, sequence of random variables, with the final variable in the sequence representing the many different ways in which Nimrod’s journey could have concluded.
Let’s represent this sequence of variables as X_1, X_2, X_3,…,X_n.
In Statistics, we regard a random variable as a function. And just like any other function, a random variable maps values from a domain to a range. The domain of a random variable is a sample space of outcomes that arise from performing a random experiment. The act of tossing a single coin is an example of a random experiment. The outcomes that arise from this random experiment are Heads and Tails. These outcomes produce the discrete sample space {Heads, Tails} which can form the domain of some random variable. A random experiment consists of one or more ‘devices’ which when when operated, together produce a random outcome. A coin is such a device. Another example of a device is a random number generator — which can be a software program — that outputs a random number from the sample space [0, 1] which, as against {Heads, Tails}, is continuous in nature and infinite in size. The range of a random variable is a set of values which are often encoded versions of things you care about in the physical world that you inhabit. Consider for example, the random variable X_3 in the sequence X_1, X_2,X_3,…,X_n. Let X_3 designate the boolean event of Captain Lyall’s securing (or not securing) a tow for his ship. X_3’s range could be the discrete and finite set {0, 1} where 0 could mean that Captain Lyall failed to secure a tow for his ship, while 1 could mean that he succeeded in doing so. What could be the domain of X_3, or for that matter any variable in the rest of the sequence?
In the sequence X_1, X_2, X_3,…X_k,…,X_n, we’ll let the domain of each X_k be the continuous sample space [0, 1]. We’ll also assume that the range of X_k is a set of values that encode the many different things that can theoretically happen to Nimrod during her journey from Liverpool. Thus, the variables X_1, X_2, X_3,…,X_n are all functions of some value s ϵ [0, 1]. They can therefore be represented as X_1(s), X_2(s), X_3(s),…,X_n(s). We’ll make the additional crucial assumption that X_n(s), which is the final (n-th) random variable in the sequence, represents the many different ways in which Nimrod’s voyage can be considered to conclude. Every time ‘s’ takes up a value in [0, 1], X_n(s) represents a specific way in which Nimrod’s voyage ended.
How might one observe a particular sequence of values? Such a sequence would be observed (a.k.a. would materialize or be realized) when you draw a value of s at random from [0, 1]. Since we don’t know anything about the how s is distributed over the interval [0, 1], we’ll take refuge in the principle of insufficient reason to assume that s is uniformly distributed over [0, 1]. Thus, each one of the infinitely uncountable numbers of real numbered values of s in the interval [0, 1] is equally probable. It’s a bit like throwing an unbiased die that has an uncountably infinite number of faces and selecting the value that it comes up as, as your chosen value of s.
Uncountable infinities and uncountably infinite-faced dice are mathematical creatures that you’ll often encounter in the weirdly wondrous world of real numbers.
So anyway, suppose you toss this fantastically chimerical die, and it comes up as some value s_a ϵ [0, 1]. You will use this value to calculate the value of each X_k(s=s_a) in the sequence which will yield an event that happened during Nimrod’s voyage. That would yield the following sequence of observed events:
X_1(s=s_a), X_2(s=s_a), X_3(s=s_a),…,X_n(s=s_a).
If you toss the die again, you might get another value s_b ϵ [0, 1] which will yield another possible ‘observed’ sequence:
X_1(s_b), X_2(s_b), X_3(s_b),…,X_n(s_b).
It’s as if each time you toss your magical die, you are spawning a new universe and couched within this universe is the reality of a newly realized sequence of random variables. Allow this thought to intrigue your mind for a bit. We’ll make abundant use of this concept while studying the principles of convergence in the mean and almost sure convergence later in the article.
Meanwhile, let’s turn our attention to knowing about the easiest form of convergence that you can get your head around: convergence in distribution.
In what follows, I’ll mostly drop the parameter ‘s’ while talking about a random variable. Instead of saying X(s), I’ll simply say X. We’ll assume that X always acts upon ‘s’ unless I otherwise say. And we’ll assume that every value of ‘s’ is a proxy for a unique probabilistic universe.
Convergence in distribution
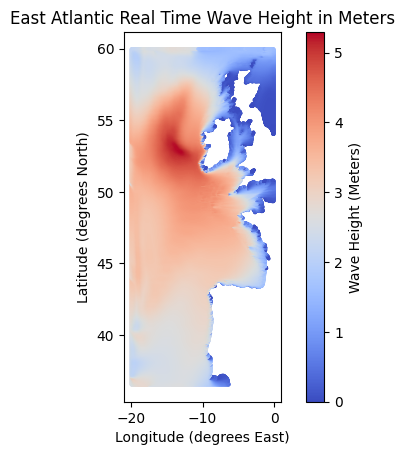
This is the easiest form of convergence to understand. To aid our understanding, I’ll use a dataset of surface wave heights measured in meters on a portion of the East Atlantic. This data are published by the Marine Institute of the Government of Ireland. Here’s a scatter plot of 272,000 wave heights indexed by latitude, longitude, and measured on March 19, 2024.
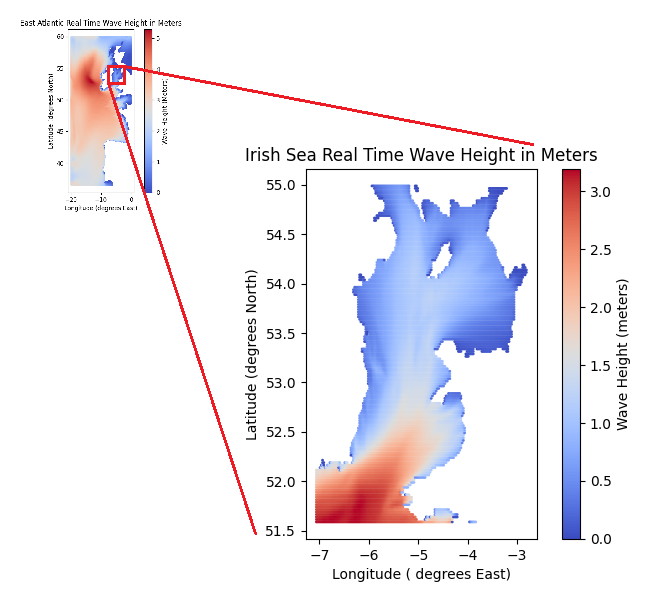
Let’s zoom into a subset of this data set that corresponds to the Irish Sea.
Now imagine a scenario where you received a chunk of funds from a funding agency to monitor the mean wave height on the Irish Sea. Suppose you received enough grant money to rent five wave height sensors. So you dropped the sensors at five randomly selected locations on the Irish Sea, collected the measurements from those sensors and took the mean of the five measurements. Let’s call this mean X_bar_5 (imagine X_bar_5 as an X with a bar on its head and with a subscript of 5). If you repeated this “drop-sensors-take-measurements-calculate-average” exercise at five other random spots on the sea, you would have most definitely got a different mean wave height. A third such experiment would yield one more value for X_bar_5. Clearly, X_bar_5 is a random variable. Here’s a scatter plot of 100 such values of X_bar_5:

To get these 100 values, all I did was to repeatedly sample the dataset of wave heights that corresponds to the geo-extents of the Irish Sea. This subset of the wave heights database contains 11,923 latitude-longitude indexed wave height values that correspond to the surface area of the Irish Sea. I chose 5 random locations from this set of 11,923 locations and calculated the mean wave height for that sample. I repeated this sampling exercise 100 times (with replacement) to get 100 values of X_bar_5. Effectively, I treated the 11,923 locations as the population. Which means I cheated a bit. But hey, when will you ever have access to the true population of anything? In fact, there happens to be a gentrified word for this self-deceiving art of repeated random sampling from what is itself a random sample. It’s called bootstrapping.
Since X_bar_5 is a random variable, we can also plot its (empirically defined) Cumulative Distribution Function (CDF). We’ll plot this CDF, but not of X_bar_5. We’ll plot the CDF of Z_bar_5 where Z_bar_5 is the standardized version of X_bar_5 obtained by subtracting the mean of the 100 sample means from each observed value of X_bar_5 and dividing the difference by the standard deviation of the 100 sample means. Here’s the CDF of Z_bar_5:

Now suppose you convinced your funding agency to pay for 10 more sensors. So you dropped the 15 sensors at 15 random spots on the sea, collected their measurements and calculated their mean. Let’s call this mean X_bar_15. X_bar_15 is a also random variable for the same reason that X_bar_5 is. And just as with X_bar_5, if you repeated the drop-sensors-take-measurements-calculate-average experiment a 100 times, you’d have got 100 values of X_bar_15 from which you can plot the CDF of its standardized version, namely Z_bar_15. Here’s a plot of this CDF:
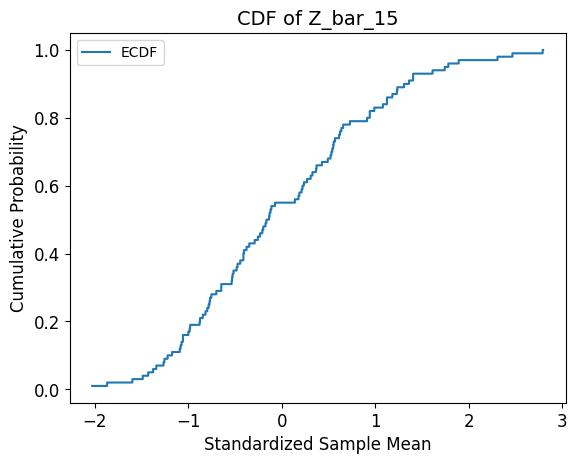
Supposing your funding grew at astonishing speed. You rented more and more sensors and repeated the drop-sensors-take-measurements-calculate-average experiment with 5, 15, 105, 255, and 495 sensors. Each time, you plotted the CDF of the standardized copies of X_bar_15, X_bar_105, X_bar_255, and X_bar_495. So let’s take a look at all the CDFs you plotted.

What do we see? We see that the shape of the CDF of Z_bar_n, where n is the sample size, appears to be converging to the CDF of the standard normal random variable N(0, 1) — a random variable with zero mean and unit variance. I’ve shown its CDF at the bottom-right in orange.
In this case, the convergence of the CDF will continue relentlessly as you increase the sample size until you reach the theoretically infinite sample size. When n tends to infinity, the CDF of Z_bar_n it will look identical to the CDF of N(0, 1).
This form of convergence of the CDF of a sequence of random variables to the CDF of a target random variable is called convergence in distribution.
Convergence in distribution is defined as follows:
The sequence of random variables X_1, X_2, X_3,…,X_n is said to converge in distribution to the random variable X, if the following condition holds true:
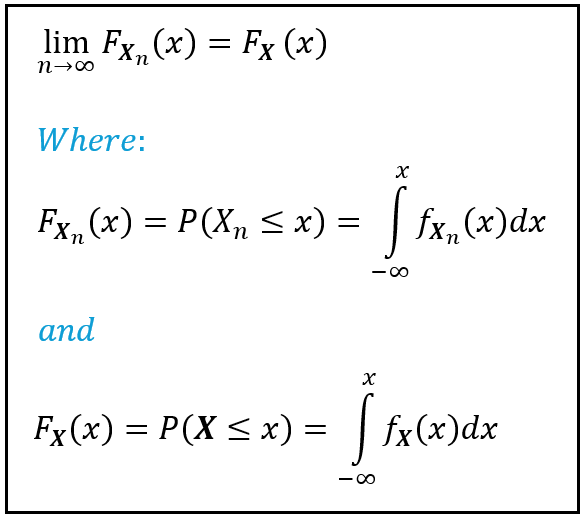
In the above figure, F(X) and F_X(x) are notations used for the Cumulative Distribution Function of a continuous random variable. f(X) and f_X(x) are notations usually used for the Probability Density Function of a continuous random variable. Incidentally, P(X) or P_X(x) are notations used for the Probability Mass Function of a discrete random variable. The principles of convergence apply to both continuous and discrete random variables although in the above figure, I’ve illustrated it for a continuous random variable.
Convergence in distribution is represented in short-hand form as follows:

In the above notation, when we say X_n converges to X, we assume the presence of the sequence X_1, X_2,…,X_(n-1) that precedes it. In our wave height scenario, Z_bar_n converges in distribution to N(0, 1).
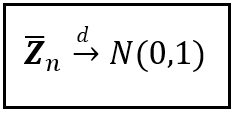
Not all sequences of random variables will converge in distribution to a target variable. But the mean of a random sample does converge in distribution. To be precise, the CDF of the standardized sample mean is guaranteed to converge to the CDF of the standard normal random variable N(0, 1). This iron-clad guarantee is supplied by the Central Limit Theorem. In fact, the Central Limit Theorem is quite possibly the most well known application of convergence in distribution.
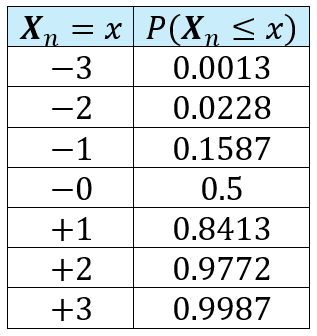
In spite of having a super-star client like the Central Limit Theorem, convergence in distribution is actually a rather weak form of convergence. Think about it: if X_n converges in distribution to X, all that means is that for any x, the fraction of observed values of X_n that are less than or equal to x is the same for both X_n and X. And that’s the only promise that convergence in distribution gives you. For example, if the sequence of random variables X_1, X_2, X_3,…,X_n converges in distribution to N(0, 1), the following table shows the fraction of observed values of X_n that are guaranteed to be less than or equal to x = — 3, — 2, — 1, 0, +1, +2, and +3:
A form of convergence that is stronger than convergence in distribution is convergence in probability which is our next topic.
Convergence in Probability
At any point in time, all the waves in the Irish Sea will exhibit a certain sea-wide average wave height. To know this average, you’d need to know the heights of the literally uncountable number of waves frolicking on the sea at that point in time. It’s clearly impossible to get this data. So let me put it another way: you will never be able to calculate the sea-wide average wave height. This unobservable, incalculable wave height, we denote as the population mean μ. A passing storm will increase μ while a period of calm will depress its value. Since you won’t be able to calculate the population mean μ, the best you can do is find a way to estimate it.
An easy way to estimate μ is to measure the wave heights at random locations on the Irish Sea and calculate the mean of this sample. This sample mean X_bar can be used as a working estimate for the population mean μ. But how accurate an estimate is it? And if its accuracy doesn’t meet your needs, can you improve its accuracy somehow, say by increasing the size of your sample? The principle of convergence in probability will help you answer these very practical questions.
So let’s follow through with our thought experiment of using a finite set of wave height sensors to measure wave heights. Suppose you collect 100 random samples with 5 sensors each and calculate the mean of each sample. As before, we’ll designate the mean by X_bar_5. Here again for our recollection is a scatter plot of X_bar_5:
Which takes us back to the question: How accurate is X_bar_5 as an estimate of the population mean μ? By itself, this question is thoroughly unanswerable because you simply don’t know μ. But suppose you knew μ to have a value of, oh say, 1.20 meters. This value happens to be the mean of 11,923 measurements of wave height in the subset of the wave height data set that relates to the Irish Sea, which I’ve so conveniently designated as the “population”. You see once you decide you want to cheat your way through your data, there is usually no stopping the moral slide that follows.
So anyway, from your network of 5 buoys, you have collected 100 sample means and you just happen to have the population mean of 1.20 meters in your back pocket to compare them with. If you allow yourself an error of +/—10% (0.12 meters), you might want to know how many of those 100 sample means fall within +/ — 0.12 meters of μ. The following plot shows the 100 sample means w.r.t. to the population mean 1.20 meters, and two threshold lines representing (1.20 — 0.12) and (1.20+0.12) meters:
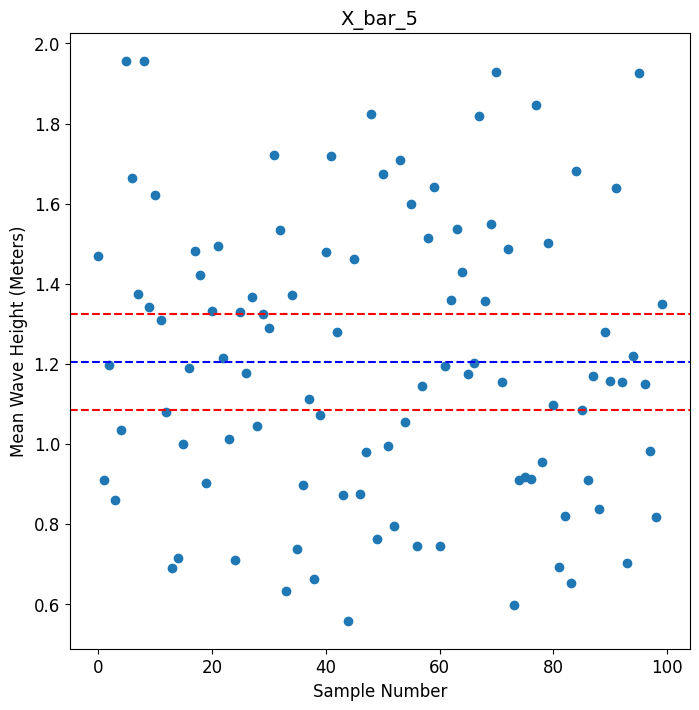
In the above plot, you’ll find that only 21 out of the 100 sample means lie within the [1.08, 1.32] interval. Thus, the probability of chancing upon a random sample of 5 wave height measurements whose mean lies within your chosen +/ — 10% threshold of tolerance is only 0.21 or 21%. The odds of running into such a random sample are p/(1 — p) = 0.21/(1 — 0.21) = 0.2658 or approximately 27%. That’s worse — much, much worse — than the odds of a fair coin landing a Heads! This is the point at which you should ask for more money to rent more sensors.
If your funding agency demands an accuracy of at least 10%, what better time than this to highlight these terrible odds to them. And to tell them that if they want better odds, or a higher accuracy at the same odds, they’ll need to stop being tightfisted and let you rent more sensors.
But what if they ask you to prove your claim? Before you go about proving anything to anyone, why don’t we prove it to ourselves. We’ll sample the data set with the following sequence of sample sizes [5, 15, 45, 75, 155, 305]. Why these sizes in particular? There’s nothing special about them. It’s only because starting with 5, we are increasing the sample size by 10. For each sample size, we’ll randomly choose 100 wave height values with replacement from the wave heights database. And we’ll calculate and plot the 100 sample means thus found. Here’s the collage of the 6 scatter plots:

These plots seem to make it clear as day that when you dial up the sample size, the number of sample means lying within the threshold bars increases until practically all of them lie within the chosen error threshold.
The following plot is another way to visualize this behavior. The X-axis contains the sample size varying from 5 to 495 in steps of 10, while the Y-axis displays the 100 sample means for each sample size.
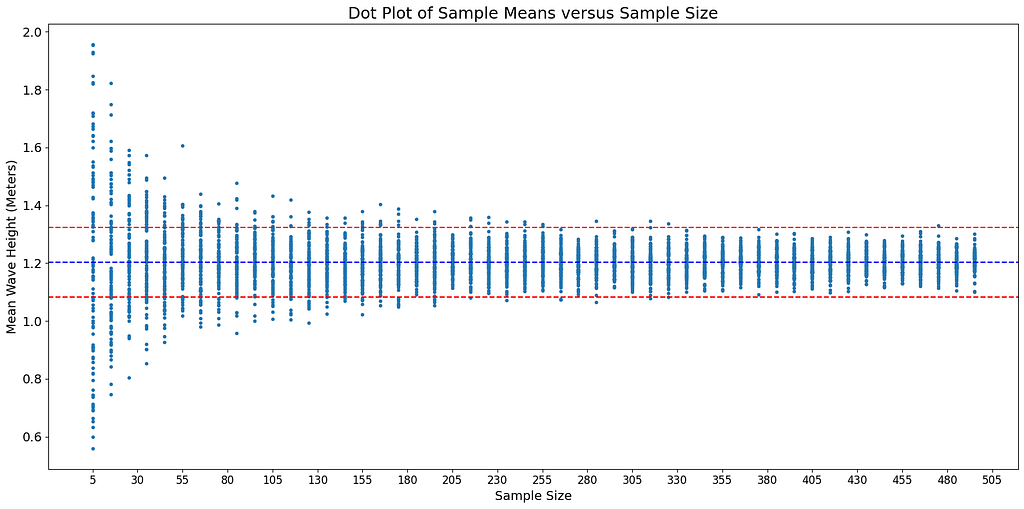
By the time the sample size rises to around 330, the sample means have converged to a confident accuracy of 1.08 to 1.32 meters, i.e. within +/ — 10% of 1.2 meters.
This behavior of the sample mean carries through no matter how small is your chosen error threshold, in other words, how narrow is the channel formed by the two red lines in the above chart. At some really large (theoretically infinite) sample size n, all sample means will lie within your chosen error threshold (+/ — ϵ). And thus, at this asymptomatic sample size, the probability of the mean of any randomly selected sample of this size being within +/ — ϵ of the population mean μ will be 1.0, i.e. an absolute certainty.
This particular manner of convergence of the sample mean to the population mean is called convergence in probability.
In general terms, convergence in probability is defined as follows:
A sequence of random variables X_1, X_2, X_3,…,X_n converges in probability to some target random variable X if the following expression holds true for any positive value of ϵ no matter how small it might be:

In shorthand form, convergence in probability is written as follows:

In our example, the sample mean X_bar_n is seen to converge in probability to the population mean μ.

Just as the Central Limit Theorem is the famous application of the principle of convergence in distribution, the Weak Law of Large Numbers is the equally famous application of convergence in probability.
Convergence in probability is “stronger” than convergence in distribution in the sense that if a sequence of random variables X_1, X_2, X_3,…,X_n converges in probability to some random variable X, it also converges in distribution to X. But the vice versa isn’t necessarily true.
To illustrate the ‘vice versa’ scenario, we’ll draw an example from the land of coins, dice, and cards that textbooks on statistics love so much. Imagine a sequence of n coins such that each coin has been biased to come up Tails by a different degree. The first coin in the sequence is so hopelessly biased that it always comes up as Tails. The second coin is biased a little less than the first one so that at least occasionally it comes up as Heads. The third coin is biased to an even lesser extent and so on. Mathematically, we can represent this state of affairs by creating a Bernoulli random variable X_k to represent the k-th coin. The sample space (and the domain) of X_k is {Tails, Heads}. The range of X_k is {0, 1} corresponding to an input of Tails and Heads respectively. The bias on the k-th coin can be represented by the Probability Mass Function of X_k as follows:
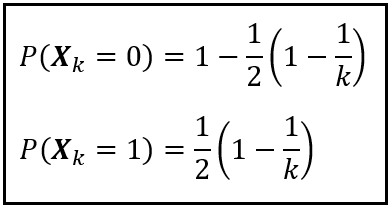
Its easy to verify that P(X_k=0) + P(X_k = 1) = 1. So the design our PMF is sound. You may also want to verify when k = 1, the term (1 — 1/k) = 0, so P(X_k=0) = 1 and P(X_k=1) = 0. Thus, the first coin in the sequence is biased to always come up as Tails. When k = ∞, (1 — 1/k) = 1. This time, P(X_k=0) and P(X_k=1) are both exactly 1/2, Thus, the infinite-th coin in the sequence is a perfectly fair coin. Just the way we wanted.
It should be intuitively apparent that X_n converges in distribution to the Bernoulli random variable X ~ Bernoulli(0.5) with the following Probability Mass Function:
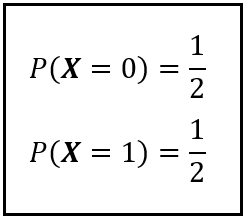
In fact, if you plot the CDF of X_n for a sequence of ever increasing n, you’ll see the CDF converging to the CDF of Bernoulli(0.5). Read the plots shown below from top-left to bottom-right. Notice how the horizontal line moves lower and lower until it comes to a rest at y=0.5.

As you will have seen from the plots, the CDF of X_n (or X_k) as k (or n) tends to infinity converges to the CDF of X ~ Bernoulli(0.5). Thus, the sequence X_1, X_2, …, X_n converges in distribution to X. But does it converge in probability to X? It turns out, it doesn’t. Like two different coins, X_n and X are two independent Bernoulli random variables. We saw that when n tends to infinity, X_n turns into a perfectly fair coin. X, by design, always behaves like a perfectly fair coin. But the realized values of the random variable |X_n — X| will always bounce between 0 and 1 as the two coins turn up as Tails (0) or as Heads (1) independent of each other. Thus, the proportion of observations of |X_n — X| that equate to zero to the total number of observations of |X_n — X| will never converge to 0. Thus, the following condition for convergence in probability isn’t guaranteed to be met:
And thus we see that, while X_n converges in distribution to X ~ Bernoulli(0.5), X_n most definitely does not convergence in probability to X.
As strong a form of convergence is convergence in probability, there are sequences of random variables that express even stronger forms of convergence. There are the following two such types of convergences:
- Convergence in mean
- Almost sure convergence
We’ll look at convergence in mean next.
Convergence in mean
Let’s return to the joyless outcome of Nimrod’s final voyage. From the time it departed from Liverpool to when it sank at St. David’s Head, Nimrod’s chances of survival progressed incessantly downward until they hit zero when it actually sank. Suppose we look at Nimrod’s journey as the following sequence of twelve incidents:
(1) Left Liverpool →
(2) Engines failed near Smalls Light House →
(3) Failed to secure a towing →
(4) Sailed toward Milford Haven →
(5) Met by a storm →
(6) Met by a hurricane →
(7) Blown toward St. David’s Head →
(8) Anchors failed →
(9) Sails blown to bits →
(10) Crashed into rocks →
(11) Broken into 3 pieces by giant wave →
(12) Sank
Now let’s define a Bernoulli(p) random variable X_k. Let the domain of X_k be a boolean value that indicates whether all incidents from 1 through k have occurred. Let the range of X_k be {0, 1} such that:
X_k = 0, implies Nimrod sank before reaching shore or sank at the shore.
X_k = 1, implies Nimrod reached shore safely.
Let’s also ascribe meaning to the probability associated with the above two outcomes in the range {0, 1}:
P(X_k = 0 | (k) ) is the probability that Nimrod will NOT reach shore safely given that incidents 1 through k have occurred.
P(X_k = 1 | (k) ) is the probability that Nimrod WILL reach the shore safely given that incidents 1 through k have occurred.
We’ll now design the Probability Mass Function of X_k. Recall that X_k is a Bernoulli(p) variable where p is the probability that Nimrod WILL reach the shore safely given that incidents 1 through k have occurred . Thus:
P(X_k = 1 | (k) ) = p
When k = 1, we initialize p to 0.5 indicating that when Nimrod left Liverpool there was a 50/50 chance of its successfully finishing its trip. As k increases from 1 to 12, we reduce p uniformly from 0.5 down to 0.0. Since Nimrod sank at k = 12, there was a zero probability of Nimrod’s successfully completing its journey. For k > 12, p stays 0.
Given this design, here’s how the PMF of X_k looks like:
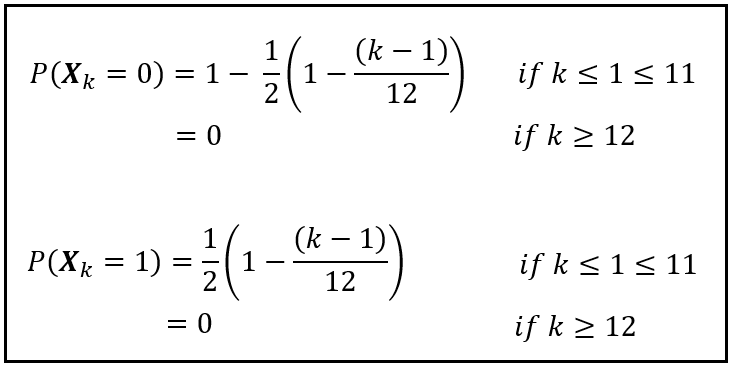
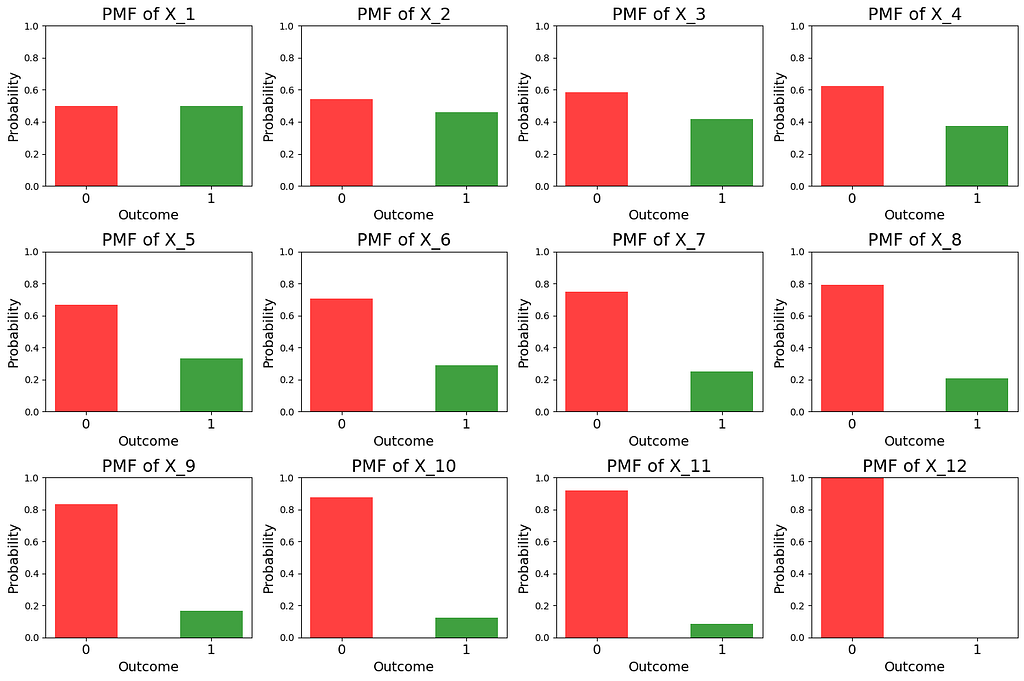
You may want to verify that when k = 1, the term (k — 1)/12 = 0 and therefore, P(X_k = 0) = P(X_k = 1) = 0.5. For 1 < k ≤ 11, the term (k — 1)/12 gradually approaches 1. Hence the probability P(X_k = 0) gradually waxes while P(X_k = 1) correspondingly wanes. For example, as per our model, when Nimrod was broken into three separate pieces by the large wave at St. David’s head, k = 11. At that point, her future chance of survival was 0.5(1 — 11/12) = 0.04167 or just 4%.
Here’s a set of bar plots of the PMFs of X_1 through X_12. Read the plots from top-left to bottom-right. In each plot, the Y-axis represents the probability and it goes from 0 to 1. The red bar on the left side of each figure represents the probability that Nimrod will eventually sink.
Now let’s define another Bernoulli random variable X with the following PMF:

We’ll assume that X is independent of X_k. So X and X_k are like two completely different coins which will come up Heads or Tails independent of each other.
Let’s define one more random variable W_k. W_k is the absolute difference between the observed values of X_k and X.
W= |X_k — X|
What can we say about the expected value of W_k, i.e. E(W_k)?
E(W_k) is the mean of the absolute difference between the observed values of X_k and X. E(W_k) can be calculated using the formula for the expected value of a discrete random variable as follows:
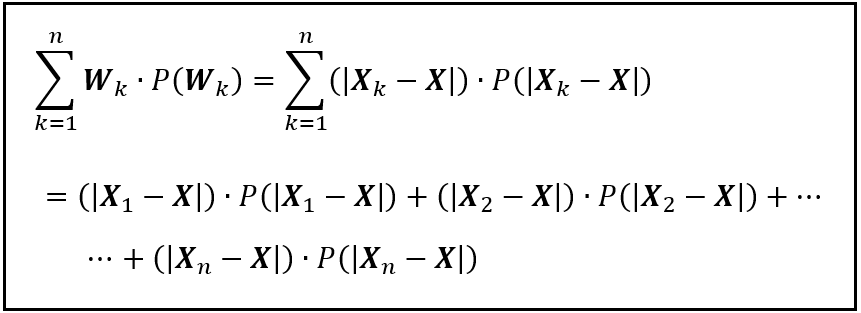
Now let’s ask the question that lies at the heart of the principle of convergence in the mean:
Under what circumstances will E(W) be zero?
|X_k — X| being the absolute value will never be negative. Hence, the only two ways in which the E(|X_k — X|) will be zero is if:
- For every pair of observed values of X_k and X, |X_k — X| is zero, OR
- The probability of observing any non-zero difference in values is zero.
Either way, across all probabilistic universes, the observed values of X_k and X will need to be moving in perfect tandem.
In our scenario, this happens for k ≥ 12. That’s because, when k ≥ 12, Nimrod sinks at St. David’s Head and therefore X_12 ~ Bernoulli(0). That means X_12 always comes up as 0. Recall that X is Bernoulli(0) by construction. So it too always comes up as 0. Thus, for k ≥ 12, |X_k — X| is always 0 and so is E(|X_k — X|).
We can express this situation as follows:
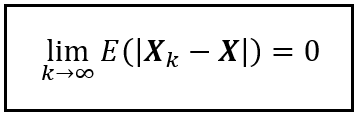
By our model’s design, the above condition is satisfied starting from k ≥ 12 and it stays satisfied for all k up through infinity. So the above condition will be trivially satisfied when k tends to infinity.
This form of convergence of a sequence of random variables to a target variable is called convergence in the mean.
You can think of convergence in the mean as a situation in which two random variables are perfectly in sync w.r.t. their observed values.
In our illustration, X_k’s range was {0, 1} with probabilities {(1— p), p}, and X_k was a Bernoulli random variable. We can easily extend the concept of convergence in the mean to non-Bernoulli random variables.
To illustrate, let X_1, X_2, X_3,…,X_n be random variables that each represents the outcome of throwing a unique 6-sided die. Let X represent the outcome from throwing another 6-sided die. You begin by throwing the set of (n+1) dice. Each die comes up as a number from 1 through 6 independent of the others. After each set of (n+1) throws, you observe that values of some of the X_1, X_2, X_3,…,X_n match the observed value of X. Others don’t. For any X_k in the sequence X_1, X_2, X_3,…,X_n, the expected value of the absolute difference between the observed values of X_k and X i.e. |X_k — X| is clearly not zero no matter how large is n. Thus, the sequence X_1, X_2, X_3,…,X_n does not converge to X in the mean.
However, suppose in some bizarro universe, you find that as the length of the sequence n tends to infinity, the infinite-th die always comes up as the exact same number as X. No matter how many times you throw the set of (n+1) dice, you find that the observed values of X_n and X are always the same, but only as n tends to infinity. And so the expected value of the difference |X_n — X| converges to zero as n tends to infinity. In other words, the sequence X_1, X_2, X_3,…,X_n has converged in the mean to X.
The concept of convergence in mean can be extended to the r-th mean as follows:
Let X_1, X_2, X_3,…,X_n be a sequence of n random variables. X_n converges to X in the r-th mean or the L to the power r-th norm if the following holds true:

To see why convergence in the mean makes a stronger statement about convergence than convergence in probability, you should look at the latter as making a statement only about aggregate counts and not about individual observed values of the random variable. For a sequence X_1, X_2, X_3,…,X_n to converge in probability to X, it’s only necessary that the ratio of the number of observed values of X_n that lie within the interval [X — ϵ, X+ϵ] to the total number of observed values of X_n tends to 1 as n tends to infinity. The principle of convergence in probability couldn’t care less about the behaviors of specific observed values of X_n, particularly about their needing to perfectly match the corresponding observed values of X. This latter requirement of convergence in the mean is a much stronger demand that one places upon X_n than the one placed by convergence in probability.
Just like convergence in the mean, there is another strong flavor of convergence called almost sure convergence which is what we’ll study next.
Almost sure convergence
At the beginning of the article, we looked at how to represent Nimrod’s voyage as a sequence of random variables X_1(s), X_2(s),…,X_n(s). And we noted that a random variable such as X_1 is a function that takes an outcome s from a sample space S as a parameter and maps it to some encoded version of reality in the range of X_1. For instance, X_k(s) is a function that maps values from the continuous real-valued interval [0, 1] to a set of values that represent the many possible incidents that can occur during Nimrod’s voyage. Each time s is assigned a random value from the interval [0, 1], a new theoretical universe is spawned containing a realized sequence of values which represents the physical reality of a materialized sea-voyage.
Now let’s define one more random variable called X(s). X(s) also draws from s. X(s)’s range is a set of values that encode the many possible fates of Nimrod. In that respect, X(s)’s range matches the range of X_n(s) which is the last random variable in the sequence X_1(s), X_2(s),…,X_n(s).
Each time s is assigned a random value from [0, 1], X_1(s),…,X_n(n) acquire a set of realized values. The value attained by X_n(s) represents the final outcome of Nimrod’s voyage in that universe. Also attaining a value in this universe is X(s). But the value that X(s) attains may not be the same as the value that X_n(s) attains.
If you toss your chimerical infinite-sided die many, many times, you would have spawned a large number of theoretical universes and thus also a large number of theoretical realizations of the random sequence X_1(s) thru X_n(s), and also the corresponding set of observed values of X(s). In some of these realized sequences, the observed value X_n(s) will match the value of the corresponding X(s).
Now suppose you modeled Nimrod’s journey at ever increasing detail so that the length ’n’ of the sequence of random variables you used to model her journey progressively increased until at some point it reached a theoretical value of infinity. At that point, you would notice exactly one of two things happening:
You would notice that no matter how many times you tossed your die, for certain values of s ϵ [0, 1], the corresponding sequence X_1(s),X_2(s),…,X_n(s) did not converge to the corresponding X(s).
Or, you’d notice the following:
You’d observe that for every single value of s ϵ [0, 1], the corresponding realization X_1(s),X_2(s),…,X_n(s) converged to X(s). In each of these realized sequences, the value attained by X_n(s) perfectly matched the value attained by X(s). If this is what you observed, then the sequence of random variables X_1, X_2,…,X_n has almost surely converged to the target random variable X.
The formal definition of almost sure convergence is as follows:
A sequence of random variables X_1(s), X_2(s),…,X(s) is said to have almost surely converged to a target random variable X(s) if the following condition holds true:
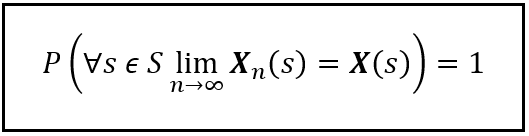
In short-hand form, almost sure convergence is written as follows:
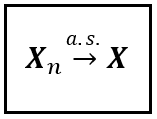
If we model X(s) as a Bernoulli(p) variable where p=1, i.e. it always comes up a certain outcome, it can lead to some thought-provoking possibilities.
Suppose we define X(s) as follows:

In the above definition, we are saying that the observed value of X will always be 0 for any s ϵ [0, 1].
Now suppose you used the sequence X_1(s), X_2(s),…,X_n(s) to model a random process. Nimrod’s voyage is an example of such a random process. If you are able to prove that as n tends to infinity, the sequence X_1(s), X_2(s),…,X_n(s) almost surely converges to X(s), what you’ve effectively proved is that in every single theoretical universe, the random process that represents Nimrod’s voyage will converge to 0. You may spawn as many alternative versions of reality as you want. They will all converge to a perfect zero — whatever you wish that zero to represent. Now there’s a thought to chew upon.

References and Copyrights
R. Larn, “Shipwrecks of Great Britain and Ireland”, David & Charles, 1981
“The Pembrokeshire Herald and General Advertiser”, 2 March 1860, 3 March 1860, 9 March 1860, and 16 March 1860
“The Illustrated Usk Observer and Raglan Herald”, 10 March 1860
“The Welshman”, 9 March 1860
“Wrexham and Denbighshire Advertiser and Cheshire Shropshire and North Wales Register” 10 March 1860
“The Monmouthshire Merlin”, 3 March 1860, 10 March 1860, 17 March 1860, and 31 March 1860
“The North Wales Chronicle and Advertiser for the Principality”, 24 March 1860
“The Daily Southern Cross”, 29 May 1860, Page 4
Site record on “Coflein.gov.uk — The online catalogue of archaeology, buildings, industrial and maritime heritage in Wales”
Site record on the “WRECK SITE”
Wreck Tour 173: The Nimrod on “DIVERNET”
R. Holmes, D. R. Tappin, DTI Strategic Environmental Assessment Area 6, Irish Sea, seabed and surficial geology and processes. British Geological Survey, 81pp. (CR/05/057N) 2005 (Unpublished)
Data set
East Atlantic SWAN Wave Model Significant Wave Height. Published by the Marine Institute, Government of Ireland. Used under license CC BY 4.0
Images and Videos
All images and videos in this article are copyright Sachin Date under CC-BY-NC-SA, unless a different source and copyright are mentioned underneath the image or video.
Thanks for reading! If you liked this article, please follow me to receive more content on statistics and statistical modeling.
Statistical Convergence and its Consequences was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Statistical Convergence and its Consequences
Go Here to Read this Fast! Statistical Convergence and its Consequences














{kind=link}
{kind=link}
{kind=link}
{kind=link}