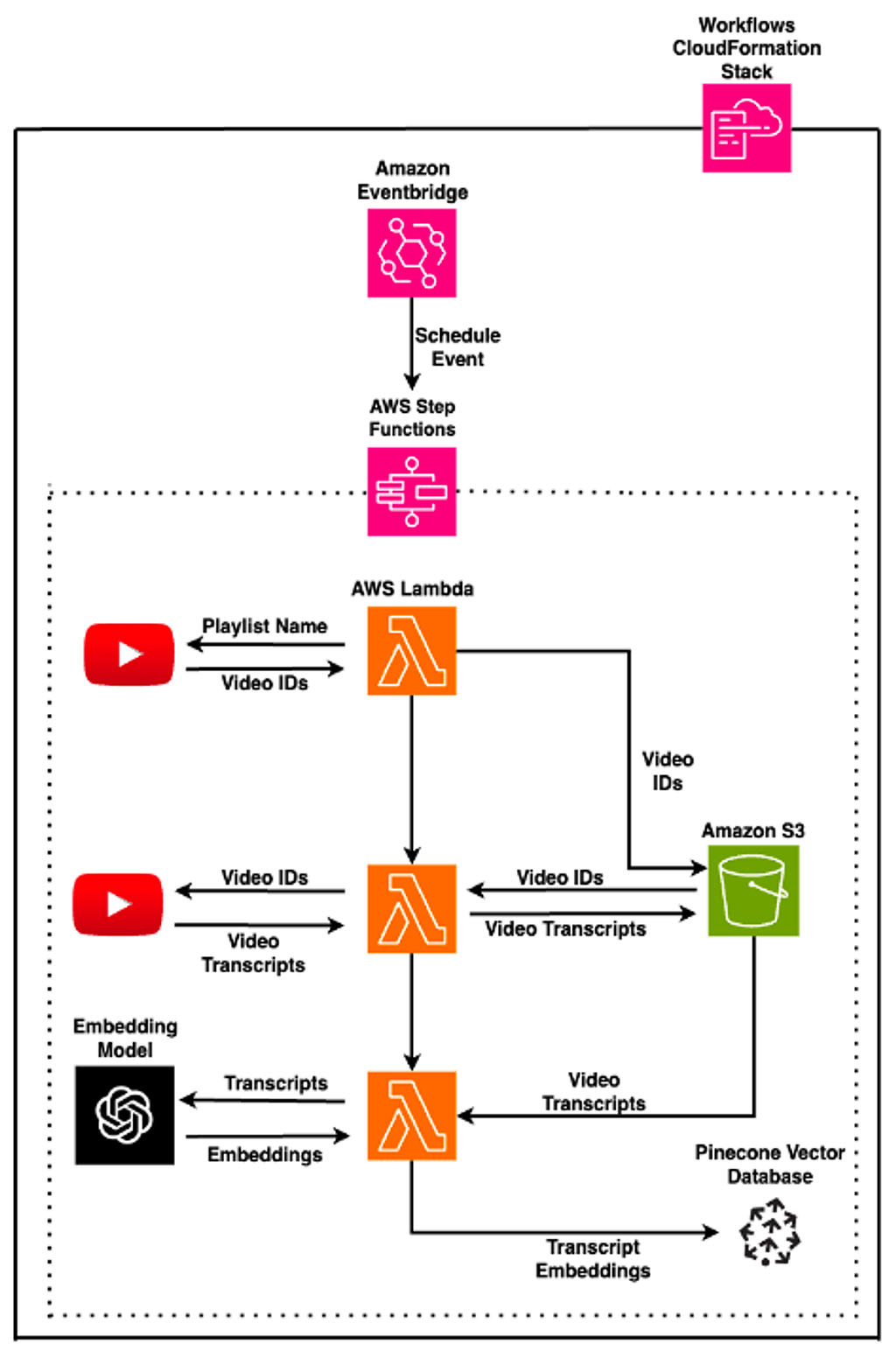
Reflections on How I Use AI in my University Lectures and Assessment
I would like to start with a clear disclaimer: While I have been lecturing at a university level since 2011, I am not a formally trained educator. What I am sharing in this article are my personal views and learning methods that I developed with my students. These might not necessarily be the same views as those of the University of Malta, where I lecture.
Generative AI requires educators to rethink assessment and embrace transparency for a student-centred, ethically informed learning future.
This is how I structured my reflections in this article:
- Why do I teach?
- How did we get here?
- Is AI a threat to Education?
- What can Educators do About It?
- What About Graded Work?
- Way Forward?
Why do I teach?
I am an AI scientist, and teaching is a core part of my academic role, which I enjoy. In class, I believe my duty is to find the most effective ways to communicate my research area to my students. My students are my peers, and we are on a learning journey together in an area of study that is fast-evolving and heavily impacting humanity. Since 2015, I have also been leading Malta’s Google Developers Group (GDG), allowing me to share learning experiences with different professionals.
In other words, my responsibility is two-fold: 1) Research the subject matter and 2) Facilitate my student’s learning experience by sharing my knowledge and pushing boundaries as a team.
How did we get here?
I was expecting the events of December 2022. At the end of May 2020, OpenAI released GPT3, demonstrating the capability of generating good-quality text with a few gentle prompts. It was the first time we could see an AI technique ‘writing something about itself,’ as this article reported. However, this was only accessible and ‘usable’ by those with a relatively strong technical background. In the summer of 2022, OpenAI released the beta version of its text-to-image generator DALL-E. Long story short: AI was getting better and more accessible month after month. I recently wrote another article about handling this fast rate of change.
ChatGPT, Gemini, Claude and all the generative AI products that followed made this transformative technology accessible.
Generative AI empowers us to explore countless topics and even achieve more. Do you need to draft an email complaint to your insurance company? Do you need to plan a marketing campaign? Do you need a SWOT analysis for your new project? Do you need a name for a pet? The list goes on. It’s there, quickly and freely accessible for anything we can think about.
So why not help us understand something better? Why not help students learn in more efficient and effective ways? Why not help us rethink our delivery?
Is AI a threat to education?
Short answer: No. Long answer: it’s a bit more complicated than it sounds.
EdTech or not?
This article is not about the formal aspect of EdTech or e-Learning. These terms generally refer to software and hardware or their combination with educational theory to facilitate learning. There is well-researched work, such as a book by Matthew Montebello, a colleague of mine, titled “AI-Injected e-Learning”, which covers this area more extensively. In this article, I focus on off-the-shelf chat interfaces I use in class.
Generative AI
The term ‘Generative AI’ does not help. While it fits most use cases, it triggers a negative connotation in education. [This is the same for art, which deserves another article.] As educators, we do not wish/want our students to generate answers for the tasks we give them and hand them in for grading. That is why there is usually an adverse first reaction to AI in the learning process.
But that’s only until we explore how this powerful technology can positively transform learning experiences—those of students and educators alike. From my experience, the more I use these methods in class, the more I broaden my expertise and knowledge in the subject area while finding better ways to communicate complex concepts.
Is it plagiarism?
I notice that many link the use of AI to plagiarism. The definition of plagiarism is “the unacknowledged use, as one’s own, of work of another person, whether or not such work has been published.” I do not wish to get into this debate, but I can comfortably say that I see a clear distinction between the use of AI and pre-AI plagiarism.
Shall we detect it using software?
Let’s be clear: It is wrong if a student or academic uses AI to generate content and submit it as if it were their work. It is academic misconduct, and it is helpful not to categorise it as plagiarism.
We expect authenticity when we consume any work, whether casual like this article or a formal academic paper. The lack of authenticity is what bothers us when it comes to plagiarism and using AI to generate content.
Generative AI works so well because (among other principles) it is based on a probabilistic approach. This means that every output differs from the one before, even if the same prompt is used to create it. If I copy someone else’s work and submit it as my own, what I copy is comparable and detected as plagiarism. Using Generative AI to create your work is a different form of misconduct. Because it is probabilistic, it follows detecting it is also probabilistic.
For this reason, I am against using any tool that claims to detect AI-generated content in an educational setting. While it can indicate whether someone used AI to generate work, the lack of certainty makes me uncomfortable taking action on a student, which might impact their career, when I know the possibility of the detection being a false positive.

If still in doubt, I wish to share that this is also OpenAI’s perspective. In January 2023 (less than a month after releasing ChatGPT), they launched an AI text classifier which claimed to predict whether a body of text is or is not AI-generated. Guess what happened? They shut it down by July 2023 because it was “impossible to make this prediction”. So why should you jeopardize a student’s future on an unreliable probabilistic decision?
What can educators do about it?
One of the main challenges in using AI is that it can limit critical thinking if students rely on generated answers. There is also a reasonable concern that this technology will deepen educational inequities if access to it is uneven.
Fight, Freeze or Flight? That would only mean we’re giving up on education because we have this new revolutionary technology. This is an opportunity and the start of a new era in education.
My three guiding principles in handling this are the following:
- Transparency and Open Dialogue — We need these values in education, the workplace and society. So, let’s start by making it easy for our students to be transparent and open in how they use these tools in an educational setting where it should always be a safe space to try out new ideas.
- Focus on the Learning Process—Education has (nearly) always been about the final output, be it examinations, assignments, or dissertations. This is an opportunity to shift the focus towards helping students demonstrate their thought processes in understanding the material and finding solutions to real-life problems.
- Educate and Don’t Punish—We are there to educate and not punish, starting with a positive outlook. If we are transparent and provide students with a process that empowers them to be open about the way they use AI, we will have countless opportunities to give them constructive feedback about how they use this technology well without the need to punish them.
AI is providing me with an opportunity to renew the way I teach. This is how I am making the best out of this opportunity:
- Personalised Learning — Ask students to prompt an AI system about a topic in various ways to help them better grasp the concept.
- Stimulate Class Discussions—Invite students to discuss the output they got from AI systems and moderate the discussion to open the way for new topics to be explored while also handling any misconceptions about the topic.
- Give students more realistic and real-life challenges — I use this to invite more mature students to apply topics covered in class to real-life scenarios or topics featured in current affairs.
- Helping those with learning difficulties — If you know that some of your students have learning difficulties, AI can help you create variations of your content to tailor the variations to help students with different abilities.
- Restructuring my courses — Once a course is over, I take feedback from students about what I can improve. I then combine the feedback with the course information and have ‘conversations’ with an AI system to help me reflect on fine-tuning the subsequent delivery, especially when introducing new topics.
- Improving my course material — I find AI systems helpful when rewriting specific topics and pitching the delivery to students with varying backgrounds. You can also use Generative AI to suggest different ways of delivering the same content or material.
And what about graded work?
This is the elephant in the room. It’s easy to favour using AI to have a better experience in class, but what about its use during graded assignments or work?
I reflected a lot about this when this technology became very accessible. I decided to zoom out and look at the context holistically and from first principles. These are the principles upon which I base my decisions:
- AI has been evolving for 80 years and is here to stay
- These AI tools will only get better due to commercial interests in them
- My students today are tomorrow’s workforce, and employers will expect them to use AI to be more productive
- I want my students to be smart about using different tools and accountable to their leaders in how they use AI
- There are so many topics which I wish to cover in class, but it is (till now) difficult to do so.
The way forward was/is clear: My duty is to design assessments that motivate my students, ensure their understanding, and prepare them to build a better tomorrow. The actionable way forward was to restructure my assessments to match this new reality and motivate students to use AI in an accountable manner.
Type of Assessment
The availability of AI challenged the nature of assessment. Some questions and tasks can be inputted as prompts, and students can get an outstanding output that they can submit without giving it much thought. While such behaviour is not right and shouldn’t happen, it also says a lot about the assessments we give students.
Consider the case of an essay about a concept, such as freedom of speech, where students would be expected to write 2000 words about the subject. The process would be that the students leave class and write the essay, submit it for correction, and the lecturer corrects it and gives a grade. This approach is an open invitation to the dilemmas I mentioned above.
Generative AI Journal
What do we look for in an employee? I believe that accountability tops the list because anything else follows. Based on this reasoning, I decided to develop the idea of a Generative AI Journal for my students to complete when they’re working on assignments I give. This journal explains how they used generative AI and how it went. In return, they get marks (in the region of 10%).
The key reasoning is the following. I am fine with my employees using AI to be more productive, but I need to know how they use it. This will help me be a better mentor and evaluate the task. Students are tomorrow’s employees. They will work in an environment where AI is available and ready for use. They will be expected to be as productive as possible. The aggregate of all these thoughts is that generative AI should be used accountable and transparently. Based on this reasoning, I came up with the idea of this journal. This 10-page journal is structured accordingly:
- Introduction: Briefly describe the generative AI models (ChatGPT, Gemini, VS Co-Pilot, etc.) used and the rationale behind that choice. (Maximum of 1 page)
- Ethical Considerations: Discuss the ethical aspects of using generative AI in the project. This should include issues like data bias and privacy together with measures of good academic conduct (Maximum of 1 page)
- Methodology: Outline the methods and steps to integrate the generative AI model into the work. How did Generative AI fit into the assignment workflow?
- Prompts and Responses: List the specific prompts used with the generative AI model that contributed to levelling up the work. Include the generated response for each prompt and explain how it improved your project.
- Improvements and Contributions: Discuss the specific areas where generative AI enhanced the deliverables. This can include, but is not limited to, data analysis, formulation of ethical considerations, enhancement of literature reviews, or idea generation.
- Individual Reflection: Reflection on the personal experience using generative AI in the project. Discuss what was learned, what surprised you, and how your perspective on using AI in academic projects has changed, if at all.
- References and List of Resources Used
This is not something definitive. It is a work in progress that I am constantly updating to reflect the needs of my students and the context of the Generative AI evolution.
Way forward?
This is not a journey with a destination. The probable scenario is that education (and the workplace) will have to evolve along with the evolution of Generative AI.
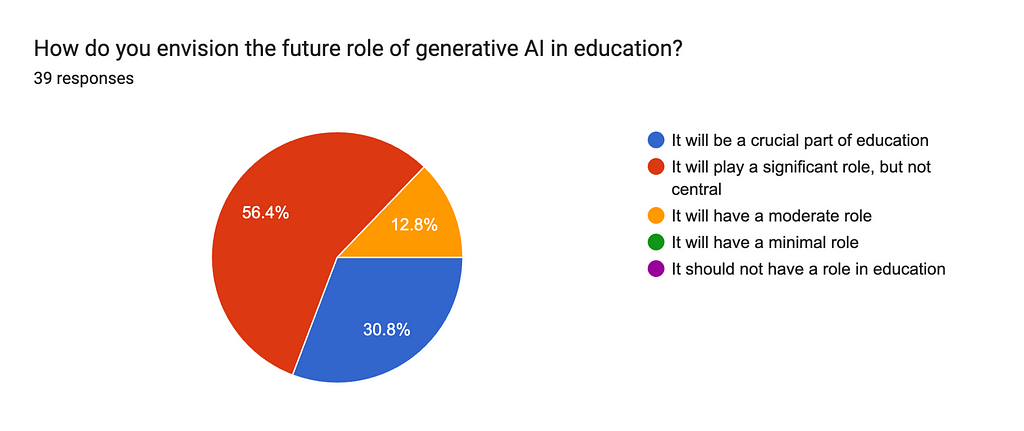
At the start of this article, I shared my perspective of seeing my students as my peers in the research journey. I’m linking this perspective to the way forward. At the end of the first semester of the academic year 2023/24, I distributed an anonymous questionnaire to 60 of my students. In this article, I am sharing the responses to two questions where I asked them what they thought about the way forward after using Generative AI, as described above.
When asked how they envision the future of Generative AI in education, 56% said that it will play a significant role but not central, with 12% saying it will only have a moderate role. 30% said that it will be a crucial part of education. This is meaningful because it shows that students feel and see the value in using this technology in class and that it should augment human educators rather than be a replacement.
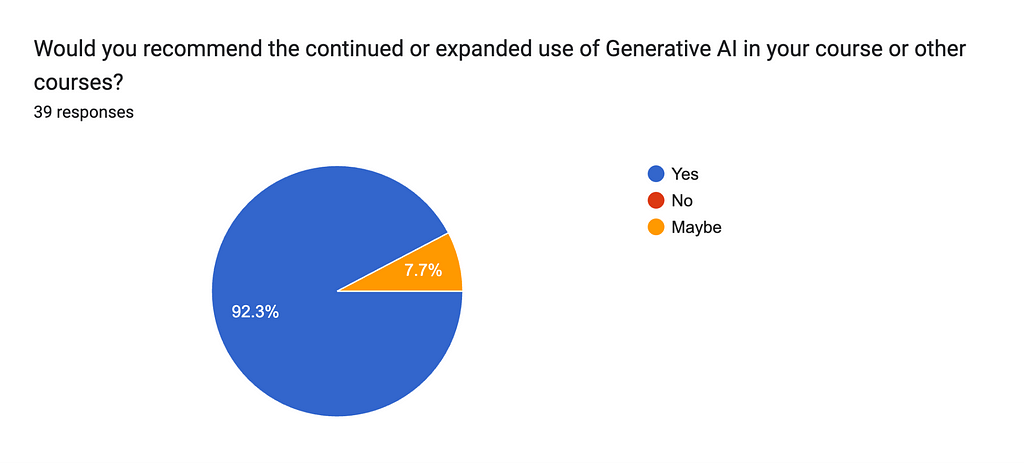
I asked my students for advice on whether I should keep using Generative AI in class. 92% think I should…and I will. The 8% were unsure, and that is also meaningful. Above all, this is a work in progress, and more work should be done to deliver meaningful educational experiences…but this doesn’t mean we shouldn’t start trying today.
This technology will improve every week and is here to stay. At the time of publishing this article, OpenAI released the GPT-4o Model and Google released countless AI products and features at the Google IO. We’re still scratching the surface of possibilities.
The future is not about fearing AI in the classroom. It is about using it as humanity’s latest invention to handle knowledge and information, hence empowering all stakeholders in the educational system.
Dr Dylan Seychell is a resident academic at the University of Malta’s Department of Artificial Intelligence, specialising in Computer Vision and Applied Machine Learning. With a background in academia and industry, he holds a PhD in Computer Vision and has published extensively on AI in international peer-reviewed conferences, journals and books.
Outside of the academic setting, he actively applies his expertise through his enterprise, focusing on enhancing tourist experiences through technological and cultural heritage innovations. He leads Malta’s Google Developers Group (GDG), is a technical expert certified by the Malta Digital Innovation Authority and is a Tourism Operators Business Section committee member within The Malta Chamber.
AI Knocking on the Classroom’s Door was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
AI Knocking on the Classroom’s Door
Go Here to Read this Fast! AI Knocking on the Classroom’s Door