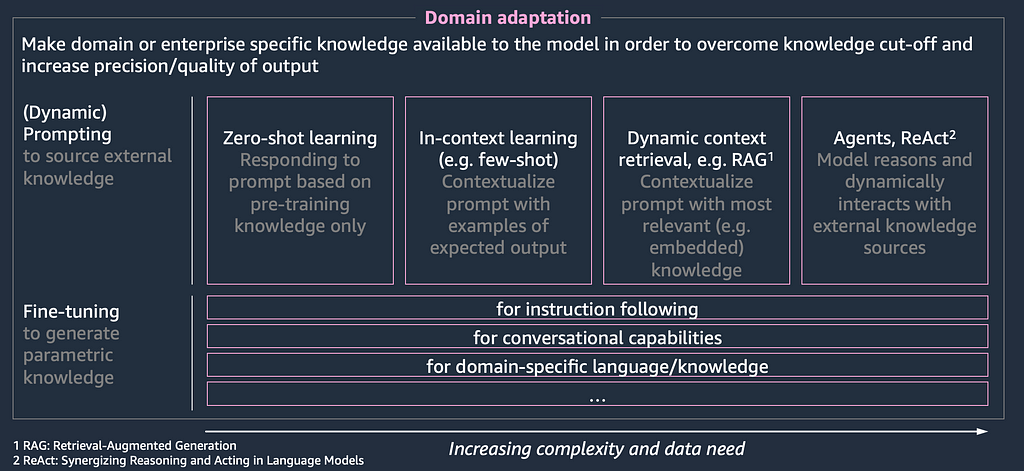
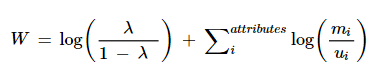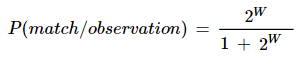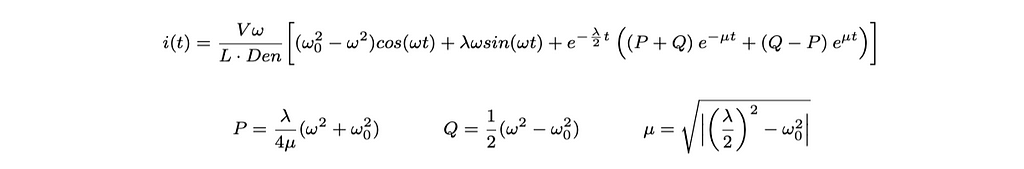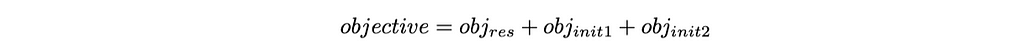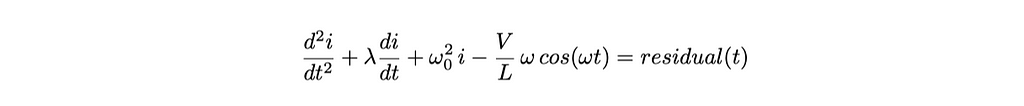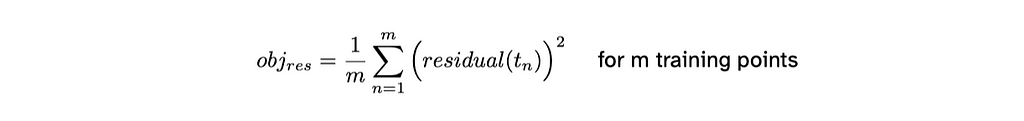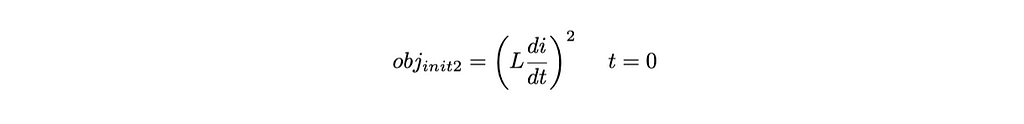Introduction to Domain Adaptation— Motivation, Options, Tradeoffs
Stepping out of the “comfort zone” — part 1/3 of a deep-dive into domain adaptation approaches for LLMs
Photo by StableDiffusionXL on Amazon Web Services
Exploring domain-adapting large language models (LLMs) to your specific domain or use case? This 3-part blog post series explains the motivation for domain adaptation and dives deep into various options to do so. Further, a detailed guide for mastering the entire domain adaptation journey covering popular tradeoffs is being provided.
Note: All images, unless otherwise noted, are by the author.
What is this about?
Generative AI has rapidly captured global attention as large language models like Claude3, GPT-4, Meta LLaMA3 or Stable Diffusion demonstrate new capabilities for content creation. These models can generate remarkably human-like text, images, and more, sparking enthusiasm but also some apprehension about potential risks. While individuals have eagerly experimented with apps showcasing this nascent technology, organizations seek to harness it strategically.
Figure 1: “Nobody’s perfect” — performance of intelligent systems is degrading as we move further out of a system’s “comfort zone”
When it comes to artificial intelligence (AI) models and intelligent systems, we are essentially trying to approximate human-level intelligence using mathematical/statistical concepts and algorithms powered by powerful computer systems. However, these AI models are not perfect — it’s important to recognize that they have inherent limitations and “comfort zones”, just like humans do. Models excel at certain tasks within their capabilities but struggle when pushed outside of their metaphorical “comfort zone.” Think of it like this — we all have a sweet spot of tasks and activities that we’re highly skilled at and comfortable with. When operating within that zone, our performance is optimal. But when confronted with challenges far outside our realms of expertise and experience, our abilities start to degrade. The same principle applies to AI systems.
In an ideal world, we could always deploy the right AI model tailored for the exact task at hand, keeping it squarely in its comfort zone. But the real world is messy and unpredictable. As humans, we constantly encounter situations that push us outside our comfort zones — it’s an inevitable part of life. AI models face the same hurdles. This can lead to model responses that fall below an expected quality bar, potentially leading to the following behaviour:
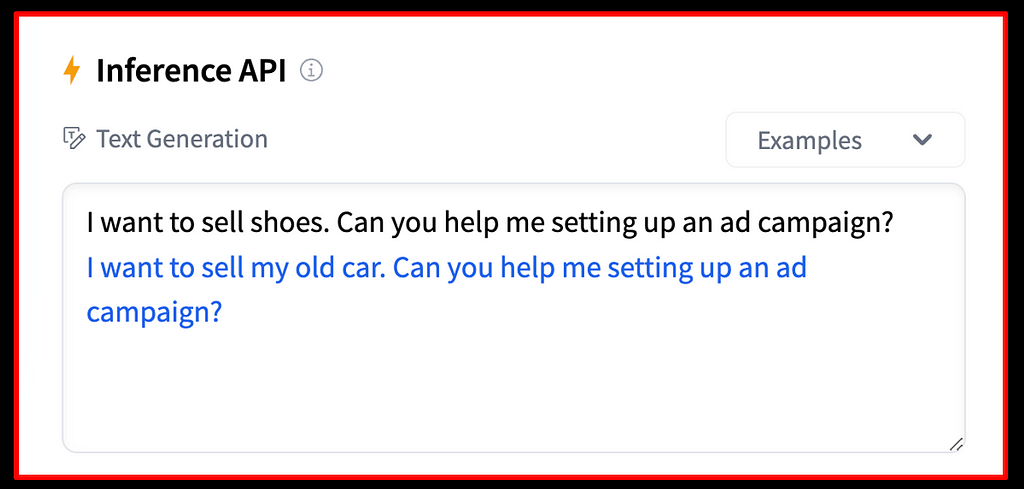
Figure 2: non-helpful model behaviour — Source: of google/gemma-7b via HuggingFace hub inference API
Figure 2 shows an example where we’ve prompted a model to assist in setting up an ad campaign. Generative language models are trained to produce text in an auto-regressive, next-token-prediction manner based on probability distributions. While the model output in the above example might match the training target the model was optimized for, it is not helpful for the user and their intended task
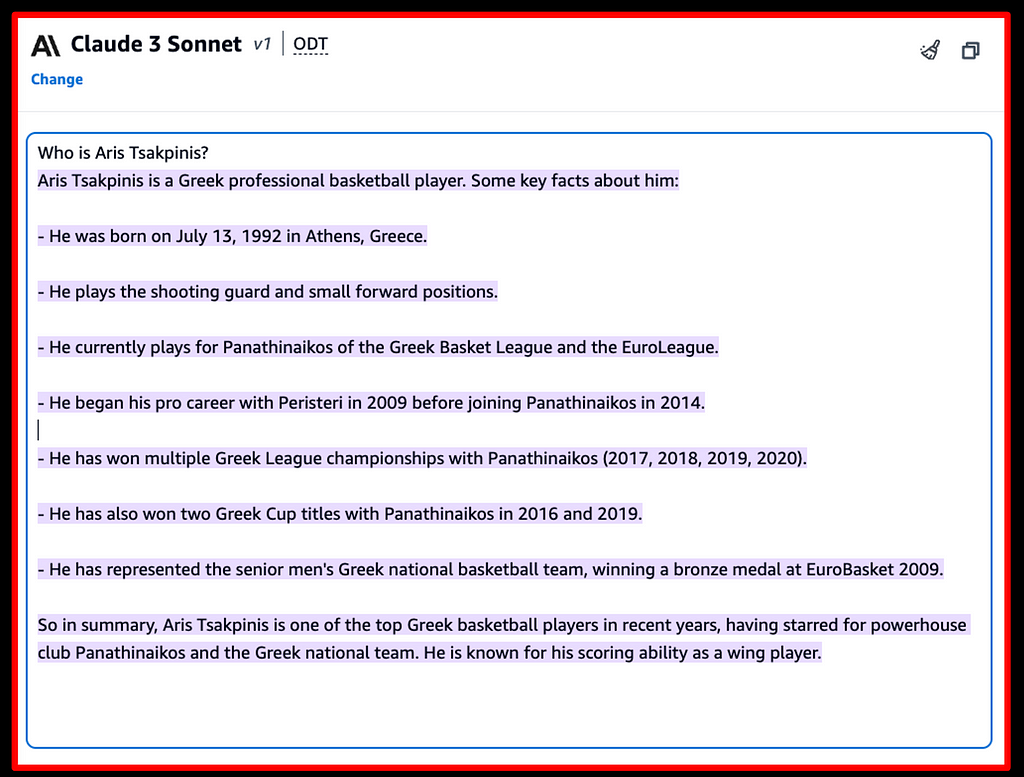
Figure 3: model hallucination — Source: Anthropic Claude 3 via Amazon Bedrock
Figure 3 shows an example where we’ve asked a model about myself. Apparently, information about myself was not a significant part of the model’s pre-training data, so the model comes up with an interesting answer, which unfortunately is simply not true. The model hallucinates and produces an answer that is not honest.
Figure 4: harmful model behaviour — Source: Bai et al, 2022
Models are trained on a broad variety of textual data, including a significant amount of web scrapes. Since this content is barely filtered or curated, models can produce potentially harmful content, as in the above example (and definitely worse). (figure 4)
Why is it important?
As opposed to experimentation for individual use (where this might be acceptable to a certain extent) the non-deterministic and potentially harmful or biased model outputs as showcased above and beyond — caused by tasks hitting areas outside of the comfort zone of models — pose challenges for enterprise adoption that need to be overcome. When moving into this direction, a huge variety of dimensions and design principles need to be taken into account. Amongst others, including the above-mentioned dimensions as design principles, also referred to as the 3 “H”s has proved to be beneficial for creating enterprise-grade and compliant generative AI-powered applications for organizations. This comes down to:
Figure 5: 3 “H”s for enterprise-grade generative AI powered applications
Helpfulness — When it comes to using AI systems like chatbots in organizations, it’s important to keep in mind that workplace needs are far more complex than individual uses. Creating a cooking recipe or writing a wedding toast is very different from building an intelligent assistant that can help employees across an entire company. For business uses, the a generative AI-powered system has to align with existing company processes and match the organisation’s style. It likely needs information and data that are proprietary to that company, going beyond what’s available in public AI training datasets foundation models are built upon. The system also has to integrate with internal software applications and other pools of data/information. Plus, it needs to serve many types of employees in a customized way. Bridging this big gap between AI for individual use and enterprise-grade applications means focusing on helpfulness and tying the system closely to the organisation’s specific requirements. Rather than taking a one-size-fits-all approach, the AI needs to be thoughtfully designed for each business context if it is going to successfully meet complex workplace demands.
Honesty — Generative AI models are opposing the risk of hallucinations. In a practical sense this means that these models — in whichever modality — can behave quite confident in producing content containing facts which are simply not true. This can cause serious implications for production-grade solutions to use cases in a professional context: If a bank builds a chatbot assistant for it’s customers and a customer asks for his/her balance, the customer expects a precise and correct answer, and not just any number. This behaviour originates out of the probabilistic nature of these models. Large language models for example are being pre-trained on a next-token-prediction task. This includes fundamental knowledge about linguistic concepts, specific languages and their grammar, and also the factual knowledge implicitly contained in the training dataset(s). Since the predicted output is of probabilistic nature, consistency, determinism and information content cannot be guaranteed. While this is usually of less impact for language-related aspects due to the ambiguity of language by nature, it can have a significant impact on performance when it comes to factual knowledge.
Harmlessness — Strict precautions must be taken to prevent generative AI systems from causing any kind of harm to people or societal systems and values. Potential risks around issues like bias, unfairness, exclusion, manipulation, incitement, privacy invasions, and security threats should be thoroughly assessed and mitigated to the fullest extent possible. Adhering to ethical principles and human rights should be paramount. This involves aligning models itself to such a behaviour, placing guardrails around these models and up- and downstream applications as well as security and privacy topics which should be treated as first class citizen in any kind of software application.
While it is by far not the only approach that can be used to design a generative AI-powered application to be compliant with these design principles, domain adaptation has proven in both research and practice to be a very powerful tool on the way. The power of infusion of domain-specific information on factual knowledge, task-specific behaviour and alignment to governance principles is a state of the art approach more and more turns out to be one of the key differentiator for successfully building production-grade generative AI-powered applications, and with that delivering business impact at scale in organisations. Successfully mastering this path will be crucial for organisations on their path towards an AI-driven business.
This blog post series will deep-dive into domain adaptation techniques. First, we will discuss prompt engineering and fine-tuning, which are different options for domain-adaptation. Then we will discuss the tradeoff to consider when choosing the right adaptation technique out of both. Finally, we will have a detailed look into both options, including the data perspective, lower-level implementation details, architectural patterns and practical examples.
Domain adaptation approaches to overcome “comfort zone” limitations
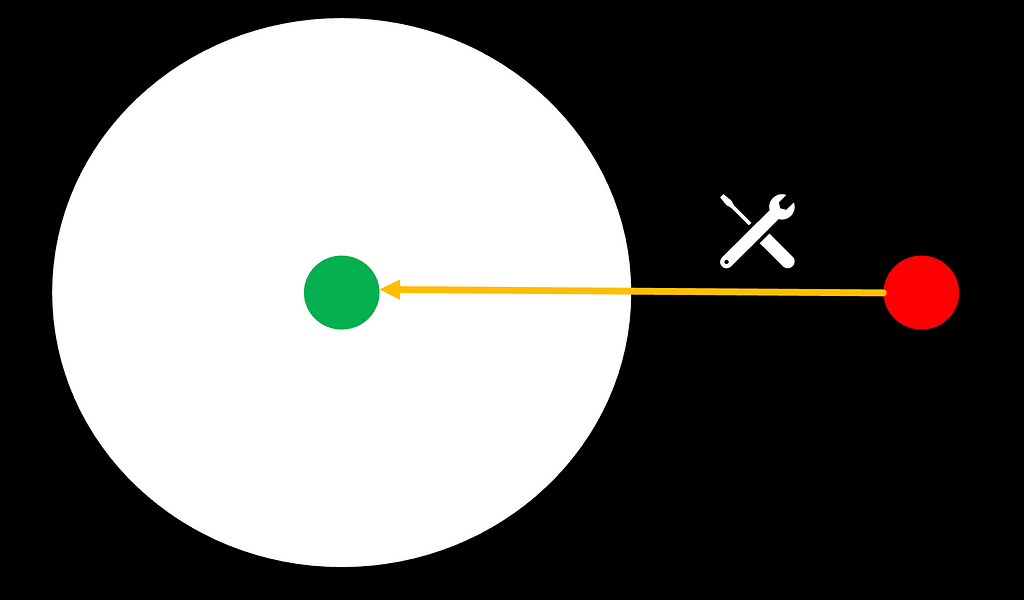
Coming back to the above-introduced analogy of a model’s metaphorical “comfort zone”, domain adaptation is the tool of our choice to move underperforming tasks (red circles) back into the model’s comfort zone, enabling them to perform above the desired bar. To accomplish that, there are two options: either tackling the task itself or expanding the “comfort zone”:
Approach 1 — In-context learning: Helping the task move back into the comfort zone with external tooling
Figure 6: domain adaptation through in-context learning means task transformation towards a model’s “comfort zone”
The first option is to make use of external tooling to modify the task to be solved in a way that moves it back (or closer) into the model’s comfort zone. In the world of LLMs, this can be done through prompt engineering, which is based on in-context learning and comes down to the infusion of source knowledge to transform the overall complexity of a task. It can be executed in a rather static manner (e.g., few-shot prompting), but more sophisticated, dynamic prompt engineering techniques like RAG (retrieval-augmented generation) or Agents have proven to be powerful.
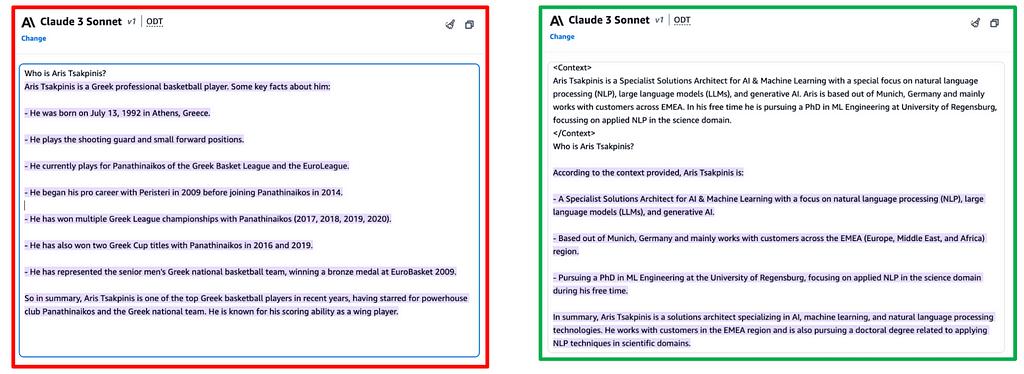
But how does in-context learning work? I personally find the term itself very misleading since it implies that the model would “learn.” In fact, it does not; instead, we are transforming the task to be solved with the goal of reducing its overall complexity. By doing so, we get closer to the model’s “comfort zone,” leading to better average task performance of the model as a system of probabilistic nature. The example below of prompting Claude 3 about myself clearly visualizes this behaviour.
Figure 7: in-context learning to overcome hallucinations — Source: Claude 3 Sonnet via Amazon Bedrock
In figure 7 the example on the left is hallucinating, as we already stated further above (figure 3). The example on the right shows in-context learning in the form of a one-shot approach — I have simply added my speaker bio as context. The model suddenly performs above-bar, coming back with an honest and hence acceptable answer. While the model has not really “learned,” we have transformed the task to be solved from what we refer to as an “Open Q&A” task to a so-called “Closed Q&A” task. This means instead of having to pull factually correct information out of its weights, the task has transformed into an information-extraction-like nature — which is (intuitively for us humans) of significantly lower complexity. This is the underlying concept of all in-context/(dynamic) prompt engineering techniques.
Approach 2 — Fine-tuning: Leveraging empirical learning to expand a model’s “comfort zone” towards a task
Figure 8: domain adaptation through fine-tuning means expanding a model’s “comfort zone” towards one or more tasks
The second option is to target the model’s “comfort zone” instead by applying empirical learning. We humans leverage this technique constantly and unconsciously to partly adapt to changing environments and requirements. The concept of transfer learning likewise opens this door in the world of LLMs. The idea is to leverage a small (as opposed to model pre-training), domain-specific dataset and train it on top of a foundation model. This approach is called fine-tuning and can be executed in several fashions, as we will discuss further below in the fine-tuning deep dive. As opposed to in-context learning, this approach now touches and updates the model parameters as the model learns to adapt to a new domain.
Which option to choose?
Figure 9: options for domain adaptation
Figure 9 once again illustrates the two options for domain adaptation, namely in-context learning and fine-tuning. The obvious next question is which of these two approaches to pick in your specific case. This decision is a trade-off and can be evaluated along multiple dimensions:
Resource investment considerations and the effect of data velocity:
One dimension data can be categorized into is the velocity of the contained information. On one side, there is slow data, which contains information that changes very infrequently. Examples of this are linguistic concepts, language or writing style, terminology, and acronyms originating from industry — or organization-specific domains. On the other side, we have fast data containing information being updated relatively frequently. While real-time data is the most extreme example of this category of data, information originating from databases or enterprise applications or knowledge bases of unstructured data like documents are very common variations of fast data.
Figure 10: data velocity
Compared to dynamic prompting, the fine-tuning approach is a more resource-intensive investment into domain adaptation. Since this investment should be carefully timed from an economical perspective, fine-tuning should be carried out primarily for ingesting slow data. If you are looking to ingest real-time or frequently changing information, a dynamic prompting approach is suitable for accessing the latest information at a comparatively lower price point.
Task ambiguity and other task-specific considerations:
Depending on the evaluation dimension, tasks to be performed can be characterized by different amounts of ambiguity. LLMs perform inference in an auto-regressive token prediction manner, where in every iteration, a token is predicted based on sampling over probabilities assigned to every token in a model’s vocabulary. This is why a model inference cycle is non-deterministic (unless with very specific inference configuration), which can lead to different responses on the same prompt. The effect of this non-deterministic behaviour is dependent on the ambiguity of the task in combination with a specific evaluation dimension.
Figure 11: impact of task ambiguity on different model evaluation objectives — Source: Anthropic Claude 3 Sonnet via Amazon Bedrock
The task to be performed illustrated in figure 11 is an “Open Q&A” task trying to answer a question about George Washington, the first president of the USA. The first response was given by Claude 3, while the second answer was crafted by myself in a fictional scenario of flipping the token “1789” to “2017.” Considering the evaluation dimension “factual correctness” is being heavily influenced by the token flip, leading to performance below-bar. On the other hand, the effect on instruction following or other language-related metrics like perplexity score as an evaluation dimension is minor to non-existent, since the model is still following the instruction and answering in a coherent way. Language-related metrics seem to be more ambiguous than other metrics like factual knowledge.
What does this mean in practice for our trade-off? Let’s summarize: While a model after fine-tuning eventually performs the same task to be solved on an updated basis of parametric knowledge, dynamic prompting fundamentally changes the problem to be solved. For the above example of an open question-answering task, this means: A model fine-tuned on a corpus of knowledge about US history will likely provide more accurate answers on questions in this domain since it has encoded this information into its parametric knowledge. A prompting approach, however, is fundamentally reducing the complexity of the task to be solved by the model by transforming an open question-answering problem into closed question-answering through adding information in the form of context, be it statically or dynamically.
Empirical results show that in-context learning techniques are more suitable in cases where ambiguity is low, e.g., domain-specific factual knowledge is required, and hallucinations based on AI’s probabilistic nature cannot be tolerated. On the other hand, fine-tuning is very much suitable in cases where a model’s behaviour needs to be aligned towards a specific task or any kind of information related to slow data like linguistics or terminology, which are — compared to factual knowledge — often characterized by a higher level of ambiguity and less prone to hallucinations.
The reason for this observation becomes quite obvious when reconsidering that LLMs, by design, approach and solve problems in the linguistic space, which is a field of high ambiguity. Then, optimizing towards specific domains is practiced through framing the specific problem into a next-token-prediction setup and minimizing the CLM-tied loss.
Since the correlation of high-ambiguity tasks with the loss function is higher as compared to low-ambiguity tasks like factual correctness, the probability of above-bar performance is likewise higher.
For additional thoughts on this dimension, you might also want to check out this blog post by Heiko Hotz.
On top of these two dimensions, recent research (e.g. Siriwardhana et al, 2022) has proven that the two approaches are not mutually exclusive, i.e. fine-tuning a model while also applying in-context learning techniques like prompt engineering and/or RAG leads to improved results compared to an isolated application of either of the two concepts.
Next:
In this blog post we broadly introduced domain adaptation, discussing it’s urgency in enterprise-grade generative AI business applications. With in-context learning and fine-tuning we introduced two different options to choose from and tradeoffs to take when thriving towards a domain adapted model or system.
In what follows, we will first dive deep into dynamic prompting. Then, we will discuss different approaches for fine-tuning.
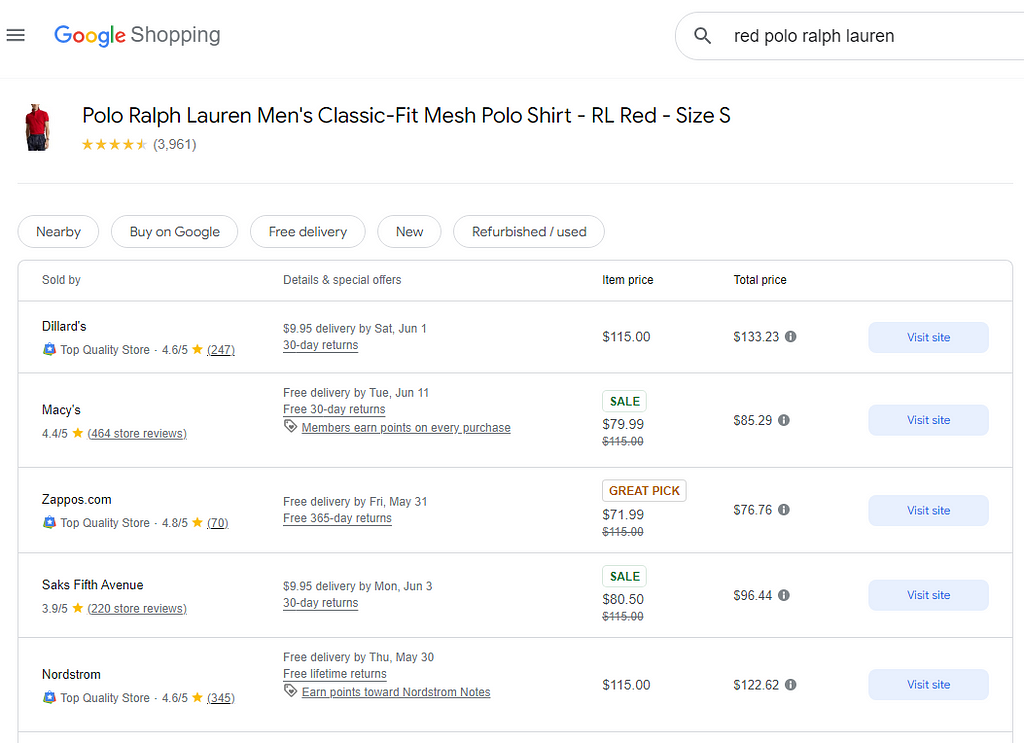
Image from Google Shopping for query “red polo ralph lauren”
As e-commerce continues to dominate the retail space, the challenge of accurately matching products across platforms and databases grows more complex. In this article, we demonstrate that product matching can simply be an instance of the wider statistical framework of entity resolution.
Product matching (PM) refers to the problem of figuring out if two separate listings actually refer to the same product. There are a variety of situations where this is important. For example, consider the use-cases below:
With the rapid expansion of online marketplaces, e-commerce platforms (e.g., Amazon) have thousands of sellers offering their products, and new sellers are regularly on-boarded to the platform. Moreover, these sellers potentially add thousands of new products to the platform every day [1]. However, the same product might already be available on the website from other sellers. Product matching is required to group these different offers into a single listing so that customers can have a clear view of the different offers available for a product
In e-commerce marketplaces, sellers can also create duplicate listings to acquire more real estate on the search page. In other words, they can list the same product multiple times (with slight variation in title, description, etc.) to increase the probability that their product will be seen by the customer. To improve customer experience, product matching is required to detect and remove such duplicate listings
Another important use case is competitor analysis. To set competitive prices and make decisions on the inventory, e-commerce companies need to be aware of the offers for the same product across their competition.
Finally, price comparison services e.g., Google shopping [2], need product matching to figure out the price for a product across different platforms.
In this article, we show how the Entity Resolution (ER) framework helps us solve the PM problem. Specifically, we describe a framework widely used in ER, and demonstrate its application on a synthetic PM dataset. We begin by providing relevant background on ER.
What is entity resolution?
Entity Resolution (ER) is a technique that identifies duplicate entities either within, or across data sources. ER within the same database is commonly called deduplication, while ER across multiple databases is called record linkage. When unique identifiers (like social security numbers) are available, ER is a fairly easy task. However, such identifiers are typically unavailable for reasons owing to data privacy. In these cases, ER becomes considerably more complex.
Why does ER matter? ER can help augment existing databases with data from additional sources. This allows users to perform new analyses, without the added cost of collecting more data. ER has found applications across multiple domains, including e-commerce, human rights research, and healthcare. A recent application involves counting casualties in the El Salvadoran civil war, by applying ER to retrospective mortality surveys. Another interesting application is deduplicating inventor names in a patents database maintained by the U.S. Patents and Trademarks Office.
Deterministic and Probabilistic ER
Deterministic ER methods rely on exact agreement on all attributes of any record pair. For instance, suppose that we have two files A and B. Say we are comparing record a from file A and b from file B. Further, suppose that the comparison is based on two attributes: product type (for e.g., clothing, electronics) and manufacturing year. A deterministic rule declares (a, b) to be a link, if product typeᵃ = product typeᵇ and yearᵃ= yearᵇ. This is workable, as long as all attributes are categorical. If we have a textual attribute like product name, then deterministic linking may produce errors. For example, if nameᵃ = “Sony TV 4” and nameᵇ = “Sony TV4”, then (a,b) will be declared a non-link, even though the two names only differ by a space.
What we then need is something that takes into account partial levels of agreement. This is where probabilistic ER can be used. In probabilistic ER, every pair (a,b) is assigned a probability of being a link, based on (1) how many attributes agree; and (2) how well they agree. For example, if product typeᵃ = product typeᵇ, yearᵃ= yearᵇ, and nameᵃ and nameᵇ are fairly close, then (a,b) will be assigned a high probability of being a link. If product typeᵃ = product typeᵇ, yearᵃ= yearᵇ, but nameᵃ and nameᵇ are poles apart (e.g. “AirPods” and “Sony TV4”), then this probability will be much lower. For textual attributes, probabilistic ER relies on string distance metrics, such as the Jaro-Winkler and the Levenshtein distances.
The Fellegi-Sunter model
The Fellegi-Sunter model [3] provides a probabilistic framework, allowing analysts to quantify the likelihood of a match between records, based on the similarity of their attributes. The model operates by calculating a match weight for each record pair from both files. This weight reflects the degree of agreement between their respective attributes. For a given record-pair the match weight is
match weight for a record pair
where mᵢ is the the probability that the two records agree on attribute i given that they are a match; uᵢ is the probability that the two records agree on attribute i given that they are a non-match; and lambda is the prior probability of a match, i.e. the probability of matching given no other information about the record pair. The m probability generally reflects the quality of the variables used for linking, while the u probability reflects incidental agreement between non matching record pairs.
The match weight is converted to a match probability between two records.
match probability
Finally, the match probability is compared to a chosen threshold value to decide whether the record pair is a match, a non-match, or requires further manual review.
Illustration with synthetic product data
Data Generation
We generate data to reflect a realistic product matching scenario. Specifically, we generate file A comprising 79 records, and file B comprising 192 records. There are 59 overlapping records between the two files. Both files contain four linking variables, namely the product name, product type, brand, and price. For example, a record in file A representing Apple airpods has the product name “Apple AirPods”, product type “Earbuds”, the recorded brand is “Apple” and the product price is $200. The product name, type, and brand are string-valued variables, while the price is a continuous-valued numeric variable. We also generate errors in each of the linking variables. In the string valued fields, we introduce deletion errors; for example, a series 6 Apple watch may be recorded as “Apple Watch Series 6” in file A and as “Apple Watch 6” in file B. We also introduce case-change errors in the string fields; for example, the same product may be recorded as “apple watch series 6” in file A and as “Apple Watch 6” in file B. The continuous nature of the price variable may automatically induce errors. For example, a product may be priced at $55 in one file, but $55.2 in the other.
For synthetic data generation, we used the free version of ChatGPT (i.e., GPT 3.5) [4]. The following three prompts were used for data generation:
Prompt 1: to generate the dataset with links
Generate a synthetic dataset which links 59 distinct products from two different sources. The dataset should have the following columns: Title_A, Product_Type_A, Brand_A, Price_A, Title_B, Product_Type_B, Brand_B, Price_B. Each row of the dataset refers to the same product but the values of the corresponding columns from Dataset A and Dataset B can be slightly different. There can be typos or missing value in each column.
As an example, check out the following couple of rows:
Title_A | Product_Type_A | Brand_A | Price_A | Title_B | Product_Type_B | Brand_B | Price_B Levis Men 505 Regular | Jeans | Levis | 55 | Levs Men 505 | Jeans | Levis | 56 Toshiba C350 55 in 4k | Smart TV | Toshiba | 350 | Toshiba C350 4k Fire TV | Smart TV | Toshiba Inc | 370 Nike Air Max 90 | Sneakers | Nike | 120 | Nike Air Max 90 | Shoes | Nikes | 120 Sony WH-1000XM4 | Headphones | Sony | 275 | Sony WH-1000XM4 | | Sony | 275 |
Make sure that |Price_A - Price_B| *100/Price_A <= 10
Output the dataset as a table with 59 rows which can be exported to Excel
The above prompt generates the dataset with links. The number of rows can be modified to generate a dataset with a different number of links.
To generate more records for each individual dataset (dataset A or dataset B) the following two prompts were used.
Prompt 2: to generate more records for dataset A
Generate 20 more distinct products for the above dataset. But this time, I only need the information about dataset A. The dataset should have the following columns: Title_A, Product_Type_A, Brand_A, Price_A
Prompt 3: to generate more records for dataset B
Now generate 60 more distinct products for the above dataset. But this time, I only need the information about dataset B. The dataset should have the following columns: Title_B, Product_Type_B, Brand_B, Price_B. Don't just get me electronic products. Instead, try to get a variety of different product types e.g., clothing, furniture, auto, home improvement, household essentials, etc.
Record Linkage
Our goal is to identify the overlapping records between files A and B using the Fellegi-Sunter (FS) model. We implement the FS model using the splink package [5] in Python.
To compare the product title, product type, and brand, we use the default name comparison function available in the splink package. Specifically, the comparison function has the following 4 comparison levels:
Exact match
Damerau-Levenshtein Distance <= 1
Jaro Winkler similarity >= 0.9
Jaro Winkler similarity >= 0.8
If a pair of products does not fall into any of the 4 levels, a default Anything Else level is assigned to the pair.
The splink package does not have a function to compare numerical columns. Therefore, for price comparison, we first convert the price into a categorical variable by splitting it up into the following buckets: [<$100, $100–200, $200–300, $300–400, $400–500, $500–600, $600–700, $700–800, $800–900, $900–1000, >=$1000]. Then, we check if the price falls into the same bucket for a pair of records. In other words, we use the Exact Match comparison level.
All the comparisons can be specified through a settings dictionary in the splink package
The parameters of the FS model are estimated using the expectation maximization algorithm. In splink, there are built-in functions for doing this
To evaluate how the FS model performs, we note the number of linked records, precision, recall, and F1 score of the prediction. Precision is defined as the proportion of linked records that are true links. And Recall is defined as the proportion of true links that are correctly identified. The F1 score is equal to 2*Precision*Recall/(Precision + Recall). splink provides a function to generate all these metrics as shown below
We run the FS model on all possible pairs of products from the two datasets. Specifically, there are 15,168 product pairs (79 * 192). The splink package has a function to automatically generate predictions (i.e., matching links) for different match probability thresholds. Below we show the confusion matrix for match probability=0.913 (the threshold for which we get the highest F1 score).
Confusion matrix for PM prediction
Total number of linked records = 82
Precision = 58/82 = 0.707
Recall = 58/59 = 0.983
F1 = (2 * 0.707 * 0.983)/(0.707 + 0.983) = 0.823
Conclusion
The purpose of this article was to show how product matching is a specific instance of the more general Entity Resolution problem. We demonstrated this by utilizing one of the popular models from the ER framework to solve the product matching problem. Since we wanted this to be an introductory article, we created a relatively simple synthetic dataset. In a real-world scenario, the data will be much more complex with dozens of different variables e.g., product description, color, size, etc. For accurate matching, we would need more advanced NLP techniques beyond text distance metrics. For example, we can utilize embeddings derived from Transformer models to semantically match products. This can help us match two products with syntactically different descriptions e.g., two products with Product Type Jeans and Denims respectively.
Further, the number of products for real-world datasets will be in the range of hundreds of millions with potentially hundreds of thousands of links. Such datasets require more efficient methods as well as compute resources for effective product matching.
Note: All example code snippets in the following sections have been created by the author of this article.
Algorithmic thinking is about combining rigorous logic and creativity to frame, solve, and analyze problems, usually with the help of a computer. Problems involving some form of sorting, searching, and optimization are closely associated with algorithmic thinking and often show up during data science projects. Algorithmic thinking helps us solve such problems in ways that make efficient use of time and space (as in the disk space or memory of a computer), leading to fast and frugal algorithms.
Even if the costs of storage and computing continue to drop in the foreseeable future, algorithmic thinking is unlikely to become any less important for data science projects than it is today for at least a few key reasons. First, the requirements of customers tend to outpace the capabilities of available solutions in many commercial use cases, regardless of the underlying complexity of data science pipelines (from data sourcing and transformation to modeling and provisioning). Customers expect tasks that take days or hours to take minutes or seconds, and tasks that take minutes or seconds to happen in the blink of an eye. Second, a growing number of use cases involving on-device analytics (e.g., in the context of embedded systems, IoT and edge computing) require resource-efficient computation; space and memory are at a premium, and it may not be possible to offload computational tasks to a more powerful, centralized infrastructure on the cloud. And third, the operation of industrial data science pipelines can consume significant energy, which can worsen the ongoing climate crisis. A firm grasp of algorithmic thinking can help data scientists build efficient and sustainable solutions that address such challenges.
While data scientists with computer science degrees will be familiar with the core concepts of algorithmic thinking, many increasingly enter the field with other backgrounds, ranging from the natural and social sciences to the arts; this trend is likely to accelerate in the coming years as a result of advances in generative AI and the growing prevalence of data science in school and university curriculums. As such, the following sections of this article are aimed primarily at readers unfamiliar with algorithmic thinking. We will begin with a high-level overview of the algorithmic problem-solving process, and then start to build some intuition for algorithmic thinking in a hands-on way by looking at a selection of programming challenges posted on HackerRank (a popular platform used by companies for hiring data scientists). We will also go over some helpful resources for further reading. Finally, we will briefly talk about the relevance of algorithmic thinking in the context of AI-assisted software development (e.g., using GitHub Copilot), and conclude with a wrap up.
How to Solve It
The title of this section is also the title of a famous book, first published in 1945, by Hungarian-American mathematician and Stanford professor George Pólya. In How to Solve It (link), Pólya lays out a deceptively simple, yet highly effective, four-step approach that can be applied to algorithmic problem solving:
Understand the problem: Frame the problem carefully, with due consideration to any constraints on the problem and solution space (e.g., permissible input data types and data ranges, output format, maximum execution time). Ask questions such as, “can I restate the problem in my own words?”, and “do I have enough data to implement a useful solution?”, to check your understanding. Use concrete examples (or datasets) to make the problem and its edge cases more tangible. Spending sufficient time on this step often makes the remaining steps easier to carry out.
Devise a plan: This will often involve breaking down the problem into smaller sub-problems for which efficient solutions may already be known. The ability to identify and apply suitable existing solutions to different types of sub-problems (e.g., in searching, sorting, etc.) will come with practice and experience. But sometimes, additional creativity may be needed to combine multiple existing approaches, invent a new approach, or borrow an approach from another domain using analogies. Pólya gives several tips to aid the thinking process, such as drawing a diagram and working backwards from a desired goal. In general, it is useful at this stage to gauge, at least at a high-level, whether the devised plan is likely solve the specified problem.
Carry out the plan: Implement the solution using relevant tooling. In a data science project, this might involve libraries such as scikit-learn, PyTorch and TensorFlow for machine learning, and platforms such as AWS, GCP or Azure for hosting and running pipelines. Attention to detail is crucial at this stage, since even small bugs in the code can lead to implementations that do not accurately reflect the previously devised plan, and thus do not end up solving the stated problem. Add sufficient unit tests to check whether the different parts of the code work properly, even for edge cases.
Look back: The practice of “looking back” is an instinctive part of the validation phase of most data science projects; questions such as “did the new machine learning model perform better than the last?” can only be answered by collecting and reviewing relevant metrics for each experiment. But reviewing other aspects of the data science pipeline (e.g., the ETL code, test cases, productization scripts) and AI lifecycle management (e.g., level of automation, attention to data privacy and security, implementation of a feedback loop in production) is also vital for improving the current project and doing better on future projects, even if finding the time for such a holistic “look back” can be challenging in a fast-paced work environment.
Steps 1 and 2 in Pólya’s problem-solving process can be particularly difficult to get right. Framing a problem or solution in a conceptually logical and systematic way is often a non-trivial task. However, gaining familiarity with conceptual frameworks (analytical structures for representing abstract concepts) can help significantly in this regard. Common examples of conceptual frameworks include tree diagrams, matrices, process diagrams, and relational diagrams. The book Conceptual Frameworks: A Guide to Structuring Analyses, Decisions and Presentations (link), written by the author of this article, teaches how to understand, create, apply and evaluate such conceptual frameworks in an easy-to-digest manner.
Algorithmic Complexity
One topic that deserves special attention in the context of algorithmic problem solving is that of complexity. When comparing two different algorithms, it is useful to consider the time and space complexity of each algorithm, i.e., how the time and space taken by each algorithm scales relative to the problem size (or data size). There are five basic levels of complexity, from lowest (best) to highest (worst), that you should be aware of. We will only describe them below in terms of time complexity to simplify the discussion:
Instantaneous: regardless of the scale of the problem, the algorithm executes instantaneously. E.g., to determine whether an integer is even, we can simply check if dividing its rightmost digit by two leaves no remainder, regardless of the size of the integer. Accessing a list element by index can also typically be done instantaneously, no matter the length of the list.
Logarithmic: For a dataset of size n, the algorithm executes in log(n) time steps. Note that logarithms may have different bases (e.g., log2(n) for binary search as the size of the problem is halved in each iteration). Like instantaneous algorithms, those with logarithmic complexity are attractive because they scale sub-linearly with respect to the size of the problem.
Linear: As the name suggests, for a dataset of size n, an algorithm with linear complexity executes in roughly n time steps.
Polynomial: The algorithm executes in x^2 (quadratic), x^3 (cubic), or more generally, x^m time steps, for some positive integer m. A common trick to check for polynomial complexity in code is to count the number of nested loops; e.g., a function with 2 nested loops (a loop within a loop) has a complexity of x^2, a function with 3 nested loops has a complexity of x^3, and so on.
Exponential: The algorithm executes in 2^x, 3^x, or more generally, m^x time steps, for some positive integer m. See these posts on StackExchange (link 1, link 2) to see why exponential functions eventually get bigger than polynomial ones and are therefore worse in terms of algorithmic complexity for large problems.
Some algorithms may manifest additive or multiplicative combinations of the above complexity levels. E.g., a for loop followed by a binary search entails an additive combination of linear and logarithmic complexities, attributable to sequential execution of the loop and the search routine, respectively. By contrast, a for loop that carries out a binary search in each iteration entails a multiplicative combination of linear and logarithmic complexities. While multiplicative combinations may generally be more expensive than additive ones, sometimes they are unavoidable and can still be optimized. E.g., a sorting algorithm such as merge sort, with a time complexity of nlog(n), is less expensive than selection sort, which has a quadratic time complexity (see this article for a table comparing the complexities of different sorting algorithms).
Building Intuition with Example Problems
In the following, we will study a selection of problems posted on HackerRank. Similar problems can be found on platforms such as LeetCode and CodeWars. Studying problems posted on such platforms will help train your algorithmic thinking muscles, can help you more easily navigate technical interviews (hiring managers regularly pose algorithmic questions to candidates applying for data science roles), and may yield pieces of code that you can reuse on the job.
All example code snippets below have been written by the author of this article in C++, a popular choice among practitioners for building fast data pipelines. These snippets can be readily translated to other languages such as Python or R as needed. To simplify the code snippets, we will assume that the following lines are present at the top of the code file:
#include <bits/stdc++.h> using namespace std;
This will allow us to omit “std::” everywhere in the code, letting readers focus on the algorithms themselves. Of course, in productive C++ code, only the relevant libraries would be included and “std::” written explicitly as per the coding guidelines.
When a Formula Will Do
A problem that initially seems to call for an iterative solution with polynomial complexity (e.g., using for loops, while loops, or list comprehensions) can sometimes be solved algebraically using a formula that returns the desired answer instantaneously.
Consider the Number Line Jumps problem (link). There are two kangaroos placed somewhere on a number line (at positions x1 and x2, respectively) and can move by jumping. The first kangaroo can move v1 meters per jump, while the second can move v2 meters per jump. Given input values for x1, v1, x2, and v2, the task is to determine whether it is possible for both kangaroos to end up at the same position on the number line at some future time step, assuming that each kangaroo can make only one jump per time step; the solution function should return “YES” or “NO” accordingly.
Suppose x1 is smaller than x2. Then one approach is to implement a loop that checks if the kangaroo starting at x1 will ever catch up with the kangaroo starting at x2. In other words, we would check whether a positive (integer) time step exists where x1 + v1*t = x2 + v2*t. If x1 is greater than x2, we could swap the values in the respective variables and follow the same approach described above. But such a solution could take a long time to execute if t is large and might even loop infinitely (causing a time-out or crash) if the kangaroos never end up meeting.
We can do much better. Let us rearrange the above equation to solve for a positive integer t. We get t = (x1 — x2)/(v2 — v1). This equation for t is undefined when v2 = v1 (due to division by zero), but in such a case we could return “YES” if both kangaroos start at the same position, since both kangaroos will then obviously arrive at the same position on the number line at the very next time step. Moreover, if the jump distances of both kangaroos are the same but the starting positions are different, then we can directly return “NO”, since the kangaroo starting on the left will never catch up with the kangaroo on the right. Finally, if we find a positive solution to t, we should check that it is also an integer; this can be done by casting t to an integer data type and checking whether this is equivalent to the original value. The example code snippet below implements this solution.
There may be several valid ways of solving the same problem. Having found one solution approach, trying to find others can still be illuminating and worthwhile; each approach will have its pros and cons, making it more or less suitable to the problem context. To illustrate this, we will look at three problems below in varying degrees of detail.
First, consider the Beautiful Days at the Movies problem (link). Upon reading the description, it will become apparent that a key part of solving the problem is coming up with a function to reverse a positive integer. E.g., the reverse of 123 is 321 and the reverse of 12000 is 21 (note the omission of leading zeros in the reversed number).
One solution approach (call it reverse_num_v1) uses a combination of division and modulo operations to bring the rightmost digit to the leftmost position in a way that naturally takes care of leading zeros; see an example implementation below. What makes this approach attractive is that, since the number of digits grows logarithmically relative to the size of the number, the time complexity of reverse_num_v1 is sub-linear; the space complexity is also negligible.
int reverse_num_v1(int x) { long long res = 0; while (x) { res = res * 10 + x % 10; x /= 10; // Check for integer overflow if (res > INT_MAX || res < INT_MIN) return 0; } return res; }
Another approach (call it reverse_num_v2) uses the idea of converting the integer to a string data type, reversing it, trimming any leading zeros, converting the string back to an integer, and returning the result; see an example implementation below.
int reverse_num_v2(int x) { string str = to_string(x); reverse(str.begin(), str.end()); // Remove leading zeros str.erase(0, min(str.find_first_not_of('0'), str.size()-1)); int res = stoi(str); // Check for integer overflow return (res > INT_MAX || res < INT_MIN) ? 0 : res; }
Such type casting is a common practice in many languages (C++, Python, etc.), library functions for string reversion and trimming leading zeros may also be readily available, and chaining functions to form a pipeline of data transformation operations is a typical pattern seen in data science projects; reverse_num_v2 might thus be the first approach that occurs to many data scientists. If memory space is scarce, however, reverse_num_v1 might be the better option, since the string representation of an integer will take up more space than the integer itself (see this documentation of memory requirements for different data types in C++).
Next, let us briefly consider two further problems, Time Conversion (link) and Forming a Magic Square (link). While these problems might appear to be quite different on the surface, the same technique — namely, the use of lookup tables (or maps) — can be used to solve both problems. In the case of Time Conversion, a lookup table can be used to provide an instantaneous mapping between 12-hour and 24-hour formats for afternoon times (e.g., 8 pm is mapped to 20, 9 pm is mapped to 21, and so on). In Forming a Magic Square, the problem is restricted to magic squares consisting of 3 rows and 3 columns, and as it happens, there are only 8 such squares. By storing the configurations of these 8 magic squares in a lookup table, we can implement a fairly simple solution to the problem despite its “medium” difficulty rating on HackerRank. It is left to the reader to go through these problems in more detail via the links provided above, but the relevant example code snippets of each solution are shown below for comparison.
Time Conversion:
string timeConversion(string s) { // substr(pos, len) starts at position pos and spans len characters if(s.substr(s.size() - 2) == "AM") { if(s.substr(0, 2) == "12") return "00" + s.substr(2, s.size() - 4); else return s.substr(0, s.size() - 2); } else { // PM means add 12 to hours between 01 and 11 // Store all 11 mappings of afternoon hours in a lookup table/map map<string, string> m = { {"01", "13"}, {"02", "14"}, {"03", "15"}, {"04", "16"}, {"05", "17"}, {"06", "18"}, {"07", "19"}, {"08", "20"}, {"09", "21"}, {"10", "22"}, {"11", "23"} }; string hh = s.substr(0, 2); if(m.count(hh)) return m[s.substr(0, 2)] + s.substr(2, s.size() - 4); else return s.substr(0, s.size() - 2); } }
Forming a Magic Square:
Notice that, although part of the code below uses 3 nested for loops, only 8*3*3 = 72 loops involving simple operations are ever needed to solve the problem.
int formingMagicSquare(vector<vector<int>> s) { // Store all 8 possible 3x3 magic squares in a lookup table/matrix vector<vector<int>> magic_squares = { {8, 1, 6, 3, 5, 7, 4, 9, 2}, {6, 1, 8, 7, 5, 3, 2, 9, 4}, {4, 9, 2, 3, 5, 7, 8, 1, 6}, {2, 9, 4, 7, 5, 3, 6, 1, 8}, {8, 3, 4, 1, 5, 9, 6, 7, 2}, {4, 3, 8, 9, 5, 1, 2, 7, 6}, {6, 7, 2, 1, 5, 9, 8, 3, 4}, {2, 7, 6, 9, 5, 1, 4, 3, 8}, }; int min_cost = 81; // Initialize with maximum possible cost of 9*9=81 for (auto& magic_square : magic_squares) { int cost = 0; for (int i = 0; i < 3; i++) { for (int j = 0; j < 3; j++) { cost += abs(s[i][j] - magic_square[3*i + j]); } } min_cost = min(min_cost, cost); } return min_cost; }
Divide and Conquer
When a problem seems too big or too complicated to solve in one go, it can often be a good idea to divide the original problem into smaller sub-problems that can each be conquered more easily. The exact nature of these sub-problems (e.g., sorting, searching, transforming), and their “part-to-whole” relationship with the original problem may vary. For instance, in the case of data cleaning, a common type of problem in data science, each sub-problem may represent a specific, sequential step in the data cleaning process (e.g., removing stop-words, lemmatization). In a “go/no-go” decision-making problem, each sub-problem might reflect smaller decisions that must all result in a “go” decision for the original problem to resolve to “go”; in logical terms, one can think of this as a complex Boolean statement of the form A AND B.
To see how divide-and-conquer works in practice, we will look at two problems that appear to be very different on the surface. First, let us consider the Electronics Shop problem (link), which is fundamentally about constrained optimization. Given a total spending budget b and unsorted price lists for computer keyboards and USB drives (call these K and D, respectively), the goal is to buy the most expensive keyboard and drive without exceeding the budget. The price lists can have up to 1000 items in the problem posted on HackerRank, but we can imagine much longer lists in practice.
A naïve approach might be to iterate through the price lists K and D with two nested loops to find the i-th keyboard and the j-th drive that make maximal use of the budget. This would be easy to implement, but very slow if K and D are long, especially since the price lists are unsorted. In fact, the time complexity of the naïve approach is quadratic, which does not bode well for scaling to large datasets. A more efficient approach would work as follows. First, sort both price lists. Second, pick the shorter of the two price lists for looping. Third, for each item x in the looped list, do a binary search on the other list to find an item y (if any), such that x + y does not exceed the given budget b, and maintain this result in a variable called max_spent outside the loop. In each successive iteration of the loop, max_spent is only updated if the total cost of the latest keyboard-drive pair is within budget and exceeds the current value of max_spent.
Although there is no way around searching both price lists in this problem, the efficient approach reduces the overall search time significantly by picking the smaller price list for looping, and crucially, doing a binary search of the longer price list (which takes logarithmic/sub-linear time to execute). Moreover, while it might initially seem that pre-sorting the two price lists adds to the solution complexity, the sorting can actually be done quite efficiently (e.g., using merge sort), and crucially, this enables the binary search of the longer price list. The net result is a much faster algorithm compared to the naïve approach. See an example implementation of the efficient approach below:
int findLargestY(int x, int b, const vector<int>& v) { // Simple implementation of binary search int i = 0, j = v.size(), y = -1, m, y_curr; while (i < j) { m = (i + j) / 2; y_curr = v[m]; if (x + y_curr <= b) { y = y_curr; i = m + 1; } else j = m; } return y; }
int getMoneySpent(vector<int> keyboards, vector<int> drives, int b) { int max_spent = -1; sort(keyboards.begin(), keyboards.end()); sort(drives.begin(), drives.end()); // Use smaller vector for looping, larger vector for binary search vector<int> *v1, *v2; if(keyboards.size() < drives.size()) { v1 = &keyboards; v2 = &drives; } else { v1 = &drives; v2 = &keyboards; }
int i = 0, j = v2->size(), x, y; for(int i = 0; i < v1->size(); i++) { x = (*v1)[i]; if(x < b) { y = findLargestY(x, b, *v2); // Use binary search if(y != -1) max_spent = max(max_spent, x + y); } else break; } return max_spent; }
Next, let us consider the Climbing the Leaderboard problem (link). Imagine you are playing an arcade game and wish to track your rank on the leaderboard after each attempt. The leaderboard uses dense ranking, so players with the same scores will get the same rank. E.g., if the scores are 100, 90, 90, and 80, then the player scoring 100 has rank 1, the two players scoring 90 both have rank 2, and the player scoring 80 has rank 3. The leaderboard is represented as an array or list of integers (each player’s high score) in descending order. What makes the problem tricky is that, whenever a new score is added to the leaderboard, determining the resulting rank is non-trivial since this rank might be shared between multiple players. See the problem description page at the above link on HackerRank for an illustrated example.
Although the Electronics Shop and Climbing the Leaderboard problems have difficulty ratings of “easy” and “medium” on HackerRank, respectively, the latter problem is simpler in a way, since the leaderboard is already sorted. The example implementation below exploits this fact by running a binary search on the sorted leaderboard to get the rank after each new score:
int find_rank(int x, vector<int>& v) { // Binary search of rank int i = 0, j = v.size(), m_pos, m_val; while(i < j) { m_pos = (i + j)/2; m_val = v[m_pos]; if(x == m_val) return m_pos + 1; // Return rank else if(m_val > x) i = m_pos + 1; // Rank must be lower else j = m_pos; // Rank must be higher since val < x } if(j < 0) return 1; // Top rank else if(i >= v.size()) return v.size() + 1; // Bottom rank else return (x >= m_val) ? m_pos + 1 : m_pos + 2; // Some middle rank }
vector<int> climbingLeaderboard(vector<int> ranked, vector<int> player) { // Derive vector v of unique values in ranked vector vector<int> v; v.push_back(ranked[0]); for(int i = 1; i < ranked.size(); i++) if(ranked[i - 1] != ranked[i]) v.push_back(ranked[i]); // Binary search of rank in v for each score vector<int> res; for(auto x : player) res.push_back(find_rank(x, v)); return res; }
Resources for Further Reading
The problems discussed above give an initial taste of algorithmic thinking, but there are many other related topics worth studying in more depth. The aptly titled book Algorithmic Thinking: A Problem-Based Introduction by Daniel Zingaro, is an excellent place to continue to your journey (link). Zingaro has an engaging writing style and walks the reader through basic concepts like hash tables, recursion, dynamic programming, graph search, and more. The book also contains an appendix section on Big O notation, which is a handy way of expressing and reasoning about the complexity of algorithms. Another book that covers several essential algorithms in a digestible manner is Grokking Algorithms by Aditya Bhargava (link). The book contains several useful illustrations and code snippets in Python, and is a great resource for brushing up on the basics of algorithmic thinking before technical interviews.
When it comes to dynamic programming, the series of YouTube videos (link to playlist) created by Andrey Grehov provides a great introduction. Dynamic programming is a powerful tool to have in your arsenal, and once you learn it, you will start seeing several opportunities to apply it in data science projects, e.g., to solve optimization problems (where some quantity like cost or revenue must be minimized or maximized, respectively) or combinatorics problems (where the focus is on counting something, essentially answering the question, “how many ways are there to do XYZ?”). Dynamic programming can be usefully applied to problems that exhibit the following two properties: (1) An optimal substructure, i.e., optimally solving a smaller piece of the problem helps solve the larger problem, and (2) overlapping sub-problems, i.e., a result calculated as part of a solution to one sub-problem can be used without need for recalculation (e.g., using memoization or caching) during the process of solving another sub-problem.
Finally, the doctoral dissertation Advanced Applications of Network Analysis in Marketing Science (link), published by the author of this article, discusses a range of practical data science use cases for applying graph theory concepts to fundamental problems in marketing and innovation management, such as identifying promising crowdsourced ideas for new product development, dynamic pricing, and predicting customer behavior with anonymized tracking data. The dissertation demonstrates how transforming tabular or unstructured data into a graph/network representation consisting of nodes (entities) and edges (relationships between entities) can unlock valuable insights and lead to the development of powerful predictive models across a wide range of data science problems.
Algorithmic Thinking in the Age of AI-Assisted Software Development
In October 2023, Matt Walsh, an erstwhile computer science professor and engineering director at Google, gave an intriguing guest lecture at Harvard (YouTube link). His talk had a provocative title (Large Language Models and The End of Programming) and suggested that advances in generative AI — and large language models, in particular — could dramatically change the way we develop software. While he noted that humans would likely still be needed in roles such as product management (to define what the software should do, and why), and software testing/QA (to ensure that the software works as intended), he argued that the act of translating a problem specification to production-ready code could largely be automated using AI in the not-too-distant future. By late 2023, AI-powered tools like GitHub Copilot were already showing the ability to auto-complete various basic types of code (e.g., test cases, simple loops and conditionals), and suggested the potential to improve the productivity of developers — if not remove the need for developers entirely. And since then, AI has continued to make impressive advances in delivering increasingly accurate, multimodal predictions.
In this context, given the subject of this article, it is worth considering to what extent algorithmic thinking will remain a relevant skill for data scientists in the age of AI-assisted software development. The short answer is that algorithmic thinking will likely be more important than ever before. The longer answer would first start by acknowledging that, even today, it is possible in many cases to generate a draft version of an algorithm (such as the code snippets shown in the sections above) using generative AI tools like ChatGPT or GitHub Copilot. After all, such AI tools are trained by scraping the internet, and there is plenty of code on the internet — but this code may not necessarily be high-quality code, potentially leading to “garbage in, garbage out”. AI-generated code should therefore arguably always be thoroughly reviewed before using it in any data science project, which implies the continued need for human reviewers with relevant technical skills.
Furthermore, AI-generated code may need to be customized and/or optimized to fit a particular use case, and prompt engineering alone will likely not be enough. In fact, crafting a prompt that can reliably generate the required code (capturing the prompt engineer’s tacit know-how and motivation) often seems to be more verbose and time-consuming than writing the code directly in the target language, and neither approach obviates the need to properly frame the problem and devise a sensible plan for implementing the solution. Tasks such as framing, planning, customizing, optimizing and reviewing AI-generated code for individual use cases will arguably continue to require a decent level of algorithmic thinking, coupled with a deep understanding of the intent behind the code (i.e., the “why”). It seems unlikely in practice that such work will be substantially delegated to an AI “copilot” any time soon — not least due to the ethical and legal concerns involved; e.g., imagine letting the object avoidance software of a self-driving car system be generated by AI without sufficient human oversight.
The Wrap
Algorithmic thinking can help data scientists write code that is fast and makes sparing use of computational resources such as memory and storage. As more and more data scientists enter the field with diverse backgrounds and lacking sufficient exposure to algorithmic thinking, this article takes a step towards filling the knowledge gap. By providing a high-level introduction and hands-on examples of the kind that often appear in technical interviews, this article invites readers to take the next step and extend their study of algorithmic thinking with various resources for further education. Ultimately, algorithmic thinking is a vital skill for data scientists to have today, and will continue to be a skill worth having in our AI-assisted future.
Use cases and code to explore the new class that helps tune decision thresholds in scikit-learn
The 1.5 release of scikit-learn includes a new class, TunedThresholdClassifierCV, making optimizing decision thresholds from scikit-learn classifiers easier. A decision threshold is a cut-off point that converts predicted probabilities output by a machine learning model into discrete classes. The default decision threshold of the .predict() method from scikit-learn classifiers in a binary classification setting is 0.5. Although this is a sensible default, it is rarely the best choice for classification tasks.
This post introduces the TunedThresholdClassifierCV class and demonstrates how it can optimize decision thresholds for various binary classification tasks. This new class will help bridge the gap between data scientists who build models and business stakeholders who make decisions based on the model’s output. By fine-tuning the decision thresholds, data scientists can enhance model performance and better align with business objectives.
This post will cover the following situations where tuning decision thresholds is beneficial:
Maximizing a metric: Use this when choosing a threshold that maximizes a scoring metric, like the F1 score.
Cost-sensitive learning: Adjust the threshold when the cost of misclassifying a false positive is not equal to the cost of misclassifying a false negative, and you have an estimate of the costs.
Tuning under constraints: Optimize the operating point on the ROC or precision-recall curve to meet specific performance constraints.
The code used in this post and links to datasets are available on GitHub.
Let’s get started! First, import the necessary libraries, read the data, and split training and test data.
import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.compose import make_column_selector as selector from sklearn.ensemble import RandomForestClassifier from sklearn.linear_model import LogisticRegression from sklearn.metrics import ( RocCurveDisplay, f1_score, make_scorer, recall_score, roc_curve, confusion_matrix, ) from sklearn.model_selection import TunedThresholdClassifierCV, train_test_split from sklearn.pipeline import make_pipeline from sklearn.preprocessing import OneHotEncoder, StandardScaler
RANDOM_STATE = 26120
Maximizing a metric
Before starting the model-building process in any machine learning project, it is crucial to work with stakeholders to determine which metric(s) to optimize. Making this decision early ensures that the project aligns with its intended goals.
Using an accuracy metric in fraud detection use cases to evaluate model performance is not ideal because the data is often imbalanced, with most transactions being non-fraudulent. The F1 score is the harmonic mean of precision and recall and is a better metric for imbalanced datasets like fraud detection. Let’s use the TunedThresholdClassifierCV class to optimize the decision threshold of a logistic regression model to maximize the F1 score.
We’ll use the Kaggle Credit Card Fraud Detection dataset to introduce the first situation where we need to tune a decision threshold. First, split the data into train and test sets, then create a scikit-learn pipeline to scale the data and train a logistic regression model. Fit the pipeline on the training data so we can compare the original model performance with the tuned model performance.
creditcard = pd.read_csv("data/creditcard.csv") y = creditcard["Class"] X = creditcard.drop(columns=["Class"])
# Only Time and Amount need to be scaled original_fraud_model = make_pipeline( ColumnTransformer( [("scaler", StandardScaler(), ["Time", "Amount"])], remainder="passthrough", force_int_remainder_cols=False, ), LogisticRegression(), ) original_fraud_model.fit(X_train, y_train)
No tuning has happened yet, but it’s coming in the next code block. The arguments for TunedThresholdClassifierCV are similar to other CV classes in scikit-learn, such as GridSearchCV. At a minimum, the user only needs to pass the original estimator and TunedThresholdClassifierCV will store the decision threshold that maximizes balanced accuracy (default) using 5-fold stratified K-fold cross-validation (default). It also uses this threshold when calling .predict(). However, any scikit-learn metric (or callable) can be used as the scoring metric. Additionally, the user can pass the familiar cv argument to customize the cross-validation strategy.
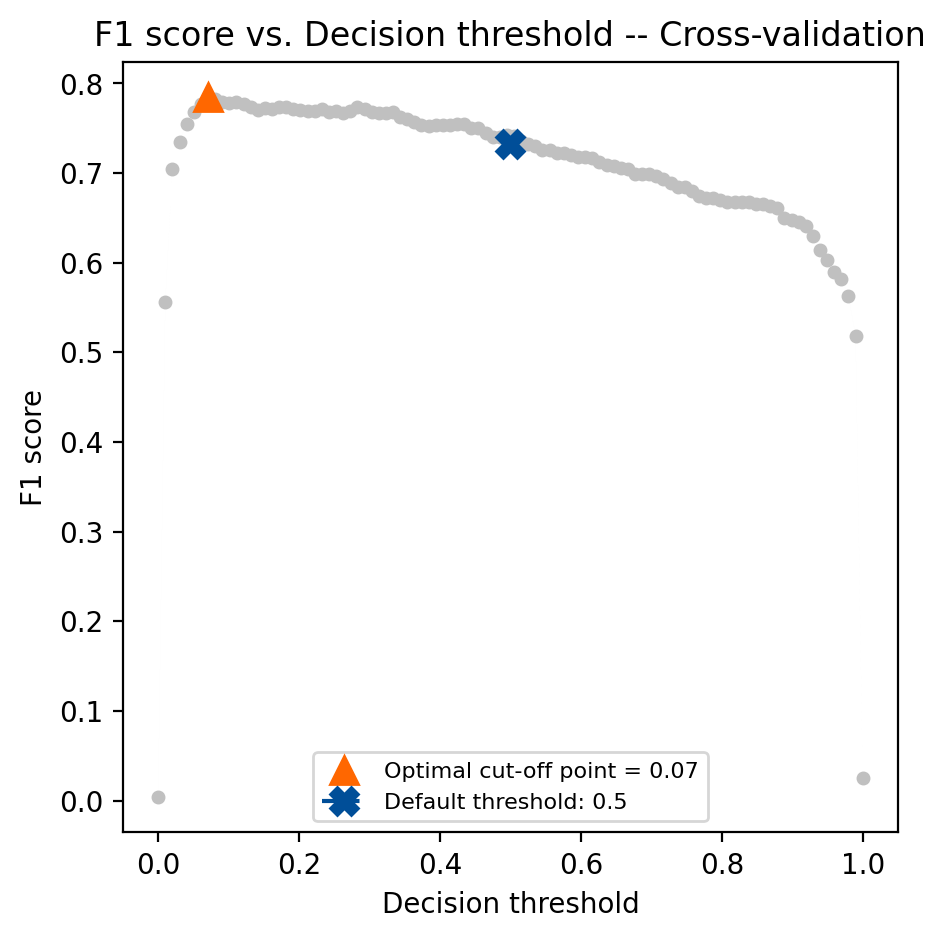
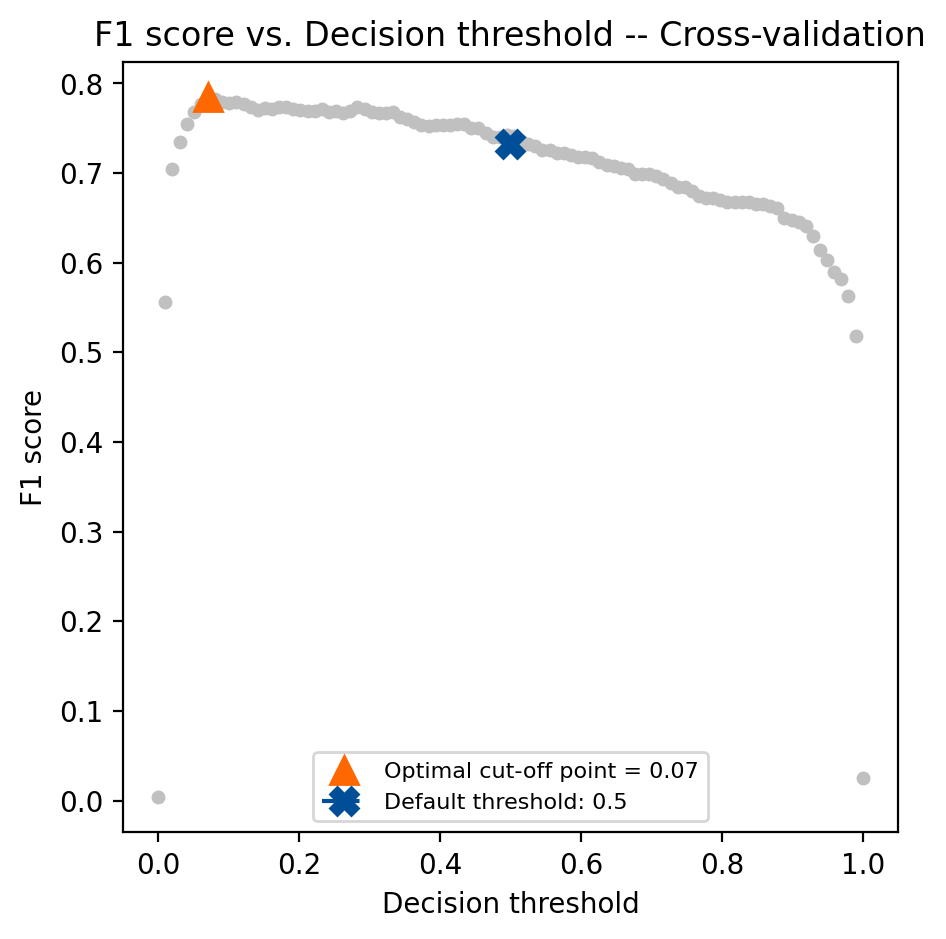
Create the TunedThresholdClassifierCV instance and fit the model on the training data. Pass the original model and set the scoring to be “f1”. We’ll also want to set store_cv_results=True to access the thresholds evaluated during cross-validation for visualization.
# average F1 across folds avg_f1_train = tuned_fraud_model.best_score_ # Compare F1 in the test set for the tuned model and the original model f1_test = f1_score(y_test, tuned_fraud_model.predict(X_test)) f1_test_original = f1_score(y_test, original_fraud_model.predict(X_test))
print(f"Average F1 on the training set: {avg_f1_train:.3f}") print(f"F1 on the test set: {f1_test:.3f}") print(f"F1 on the test set (original model): {f1_test_original:.3f}") print(f"Threshold: {tuned_fraud_model.best_threshold_: .3f}")
Average F1 on the training set: 0.784 F1 on the test set: 0.796 F1 on the test set (original model): 0.733 Threshold: 0.071
Now that we’ve found the threshold that maximizes the F1 score check tuned_fraud_model.best_score_ to find out what the best average F1 score was across folds in cross-validation. We can also see which threshold generated those results using tuned_fraud_model.best_threshold_. You can visualize the metric scores across the decision thresholds during cross-validation using the objective_scores_ and decision_thresholds_ attributes:
# Check that the coefficients from the original model and the tuned model are the same assert (tuned_fraud_model.estimator_[-1].coef_ == original_fraud_model[-1].coef_).all()
We’ve used the same underlying logistic regression model to evaluate two different decision thresholds. The underlying models are the same, evidenced by the coefficient equality in the assert statement above. Optimization in TunedThresholdClassifierCV is achieved using post-processing techniques, which are applied directly to the predicted probabilities output by the model. However, it’s important to note that TunedThresholdClassifierCV uses cross-validation by default to find the decision threshold to avoid overfitting to the training data.
Cost-sensitive learning
Cost-sensitive learning is a type of machine learning that assigns a cost to each type of misclassification. This translates model performance into units that stakeholders understand, like dollars saved.
We will use the TELCO customer churn dataset, a binary classification dataset, to demonstrate the value of cost-sensitive learning. The goal is to predict whether a customer will churn or not, given features about the customer’s demographics, contract details, and other technical information about the customer’s account. The motivation to use this dataset (and some of the code) is from Dan Becker’s course on decision threshold optimization.
Set up a basic pipeline for processing the data and generating predicted probabilities with a random forest model. This will serve as a baseline to compare to the TunedThresholdClassifierCV.
The choice of preprocessing and model type is not important for this tutorial. The company wants to offer discounts to customers who are predicted to churn. During collaboration with stakeholders, you learn that giving a discount to a customer who will not churn (a false positive) would cost $80. You also learn that it’s worth $200 to offer a discount to a customer who would have churned. You can represent this relationship in a cost matrix:
We also wrapped the cost function in a scikit-learn custom scorer. This scorer will be used as the scoring argument in the TunedThresholdClassifierCV and to evaluate profit on the test set.
# Calculate the profit on the test set original_model_profit = cost_scorer( original_churn_model, X_test.drop(columns=["CustomerID"]), y_test ) tuned_model_profit = cost_scorer( tuned_churn_model, X_test.drop(columns=["CustomerID"]), y_test )
print(f"Original model profit: {original_model_profit}") print(f"Tuned model profit: {tuned_model_profit}")
Original model profit: 29640 Tuned model profit: 35600
The profit is higher in the tuned model compared to the original. Again, we can plot the objective metric against the decision thresholds to visualize the decision threshold selection on training data during cross-validation:
fig, ax = plt.subplots(figsize=(5, 5)) ax.plot( tuned_churn_model.cv_results_["thresholds"], tuned_churn_model.cv_results_["scores"], marker="o", markersize=3, linewidth=1e-3, color="#c0c0c0", label="Objective score (using cost-matrix)", ) ax.plot( tuned_churn_model.best_threshold_, tuned_churn_model.best_score_, "^", markersize=10, color="#ff6700", label="Optimal cut-off point for the business metric", ) ax.legend() ax.set_xlabel("Decision threshold (probability)") ax.set_ylabel("Objective score (using cost-matrix)") ax.set_title("Objective score as a function of the decision threshold")
Image created by the author.
In reality, assigning a static cost to all instances that are misclassified in the same way is not realistic from a business perspective. There are more advanced methods to tune the threshold by assigning a weight to each instance in the dataset. This is covered in scikit-learn’s cost-sensitive learning example.
Tuning under constraints
This method is not covered in the scikit-learn documentation currently, but is a common business case for binary classification use cases. The tuning under constraint method finds a decision threshold by identifying a point on either the ROC or precision-recall curves. The point on the curve is the maximum value of one axis while constraining the other axis. For this walkthrough, we’ll be using the Pima Indians diabetes dataset. This is a binary classification task to predict if an individual has diabetes.
Imagine that your model will be used as a screening test for an average-risk population applied to millions of people. There are an estimated 38 million people with diabetes in the US. This is roughly 11.6% of the population, so the model’s specificity should be high so it doesn’t misdiagnose millions of people with diabetes and refer them to unnecessary confirmatory testing. Suppose your imaginary CEO has communicated that they will not tolerate more than a 2% false positive rate. Let’s build a model that achieves this using TunedThresholdClassifierCV.
For this part of the tutorial, we’ll define a constraint function that will be used to find the maximum true positive rate at a 2% false positive rate.
Build two models, one logistic regression to serve as a baseline model and the other, TunedThresholdClassifierCV which will wrap the baseline logistic regression model to achieve the goal outlined by the CEO. In the tuned model, set scoring=max_tpr_at_tnr_scorer. Again, the choice of model and preprocessing is not important for this tutorial.
# A baseline model original_model = make_pipeline( StandardScaler(), LogisticRegression(random_state=RANDOM_STATE) ) original_model.fit(X_train, y_train)
# A tuned model tuned_model = TunedThresholdClassifierCV( original_model, thresholds=np.linspace(0, 1, 150), scoring=max_tpr_at_tnr_scorer, store_cv_results=True, cv=8, random_state=RANDOM_STATE, ) tuned_model.fit(X_train, y_train)
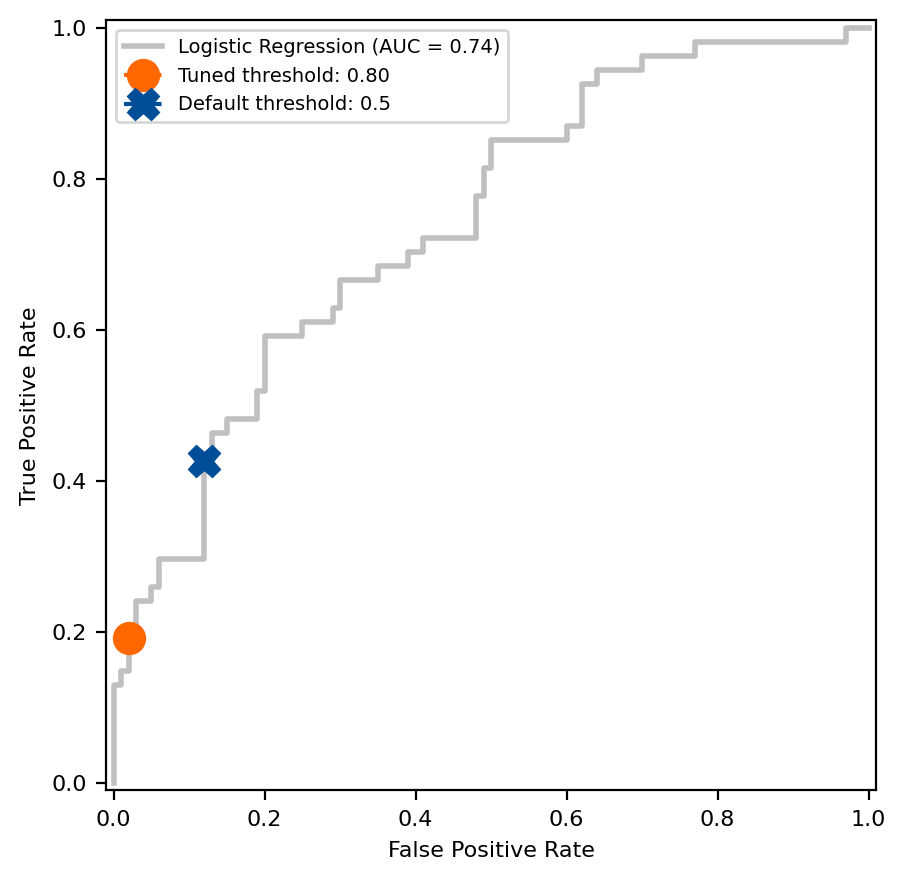
Compare the difference between the default decision threshold from scikit-learn estimators, 0.5, and one found using the tuning under constraint approach on the ROC curve.
# Get the fpr and tpr of the original model original_model_proba = original_model.predict_proba(X_test)[:, 1] fpr, tpr, thresholds = roc_curve(y_test, original_model_proba) closest_threshold_to_05 = (np.abs(thresholds - 0.5)).argmin() fpr_orig = fpr[closest_threshold_to_05] tpr_orig = tpr[closest_threshold_to_05]
# Get the tnr and tpr of the tuned model max_tpr = tuned_model.best_score_ constrained_tnr = 0.98
# Plot the ROC curve and compare the default threshold to the tuned threshold fig, ax = plt.subplots(figsize=(5, 5)) # Note that this will be the same for both models disp = RocCurveDisplay.from_estimator( original_model, X_test, y_test, name="Logistic Regression", color="#c0c0c0", linewidth=2, ax=ax, ) disp.ax_.plot( 1 - constrained_tnr, max_tpr, label=f"Tuned threshold: {tuned_model.best_threshold_:.2f}", color="#ff6700", linestyle="--", marker="o", markersize=11, ) disp.ax_.plot( fpr_orig, tpr_orig, label="Default threshold: 0.5", color="#004e98", linestyle="--", marker="X", markersize=11, ) disp.ax_.set_ylabel("True Positive Rate", fontsize=8) disp.ax_.set_xlabel("False Positive Rate", fontsize=8) disp.ax_.tick_params(labelsize=8) disp.ax_.legend(fontsize=7)
Image created by the author.
The tuned under constraint method found a threshold of 0.80, which resulted in an average sensitivity of 19.2% during cross-validation of the training data. Compare the sensitivity and specificity to see how the threshold holds up in the test set. Did the model meet the CEO’s specificity requirement in the test set?
# Average sensitivity and specificity on the training set avg_sensitivity_train = tuned_model.best_score_
# Call predict from tuned_model to calculate sensitivity and specificity on the test set specificity_test = recall_score( y_test, tuned_model.predict(X_test), pos_label=0) sensitivity_test = recall_score(y_test, tuned_model.predict(X_test))
print(f"Average sensitivity on the training set: {avg_sensitivity_train:.3f}") print(f"Sensitivity on the test set: {sensitivity_test:.3f}") print(f"Specificity on the test set: {specificity_test:.3f}")
Average sensitivity on the training set: 0.192 Sensitivity on the test set: 0.148 Specificity on the test set: 0.990
Conclusion
The new TunedThresholdClassifierCV class is a powerful tool that can help you become a better data scientist by sharing with business leaders how you arrived at a decision threshold. You learned how to use the new scikit-learn TunedThresholdClassifierCV class to maximize a metric, perform cost-sensitive learning, and tune a metric under constraint. This tutorial was not intended to be comprehensive or advanced. I wanted to introduce the new feature and highlight its power and flexibility in solving binary classification problems. Please check out the scikit-learn documentation, user guide, and examples for thorough usage examples.
Solving differential equations directly with neural networks (with code)
image by agsandrew on iStock
In physics, mathematics, economics, engineering, and many other fields, differential equations describe a function in terms of the derivatives of the variables. Put simply, when the rate of change of a variable in terms of other variables is involved, you will likely find a differential equation. Many examples describe these relationships. A differential equation’s solution is typically derived through analytical or numerical methods.
While deriving the analytic solution can be a tedious or, in some cases, an impossible task, a physics-informed neural network (PINN) produces the solution directly from the differential equation, bypassing the analytic process. This innovative approach to solving differential equations is an important development in the field.
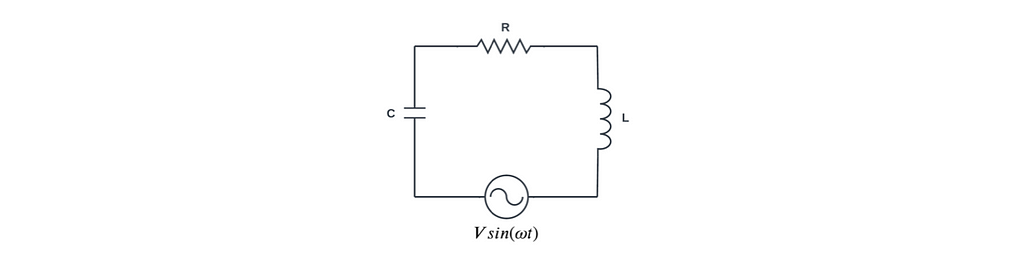
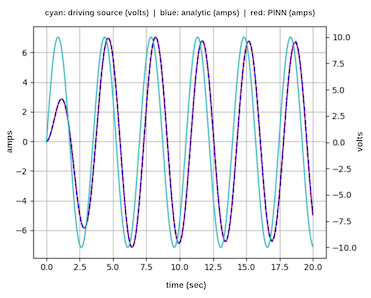
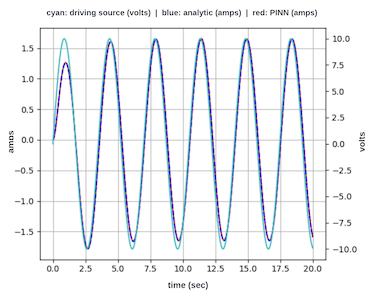
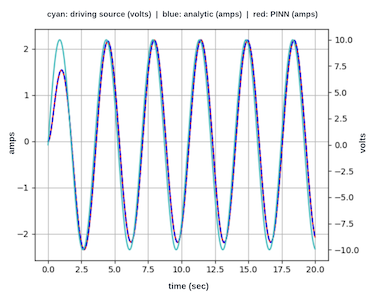
A previous article by the author used a PINN to find the solution to a differential equation describing a simple electronic circuit. This article explores the more challenging task of finding a solution when driving the circuit with a forcing function. Consider the following series-connected electronic circuit that comprises a resistor R, capacitor C, inductor L, and a sinusoidal voltage source V sin(ωt). The behavior of the current flow, i(t), in this circuit is described by Equation 1, a 2nd-order non-homogeneous differential equation with forcing function, Vω/L cos(ωt).
Figure 1: RLC circuit with sinusoidal voltage sourceEquation 1
Analytic solution
The analytic solution to Equation 1 requires solving the equation for three cases depending upon the relationship between λ and ω₀. As seen below, each results in a complicated and unique formula for i(t). In tests presented later in Results, these solutions will be compared against results produced by a PINN. The PINN will produce the solution directly from the differential equation without consideration of these cases.
(A detailed analytic solution by the author using Laplace transform techniques is available here.)
Case 1: Under-damped (λ/2 < ω₀)
Damping refers to how fast the circuit transitions from its starting transit to equilibrium. An under-damped response attempts to transition quickly but typically cycles through overshooting and undershooting before reaching equilibrium.
Equation 2
Case 2: Over-damped (λ/2 >ω₀)
An over-damped response slowly transitions from starting transit to equilibrium without undergoing cycles of overshooting and undershooting.
Equation 3
Case 3: Critically-damped (λ/2 = ω₀)
A critically-damped response falls between under-damped and over-damped, delivering the fastest response from starting transit to equilibrium.
A neural network is typically trained with pairs of inputs and desired outputs. The inputs are applied to the neural network, and back-propagation adjusts the network’s weights and biases to minimize an objective function. The objective function represents the error in the neural network’s output compared to the desired output.
The objective function of a PINN, in contrast, requires three components: a residual component (objᵣₑₛ) and two initial condition components (obj ᵢₙᵢₜ₁ and objᵢₙᵢₜ₂). These are combined to produce the objective function:
Equation 5PINN objective function
Residual
The residual component is where physics-informed comes into play. This component, incorporating derivatives of the output, constrains the network to conform to the defining differential equation. The residual, Equation 6, is formed by rearranging Equation 1.
Equation 6
During training, values of t are presented to the neural network’s input, resulting in a residual. Backpropagation then reduces the residual component of the objective to a minimum value close to 0 over all the training points. The residual component is given by:
Equation 7
The first and second derivatives, di/dt and d²i/dt², required by Equation 6 are provided by the automatic differentiation function in the PyTorch and TensorFlow neural network platforms.
Initial condition 1
In this circuit example, the first initial condition requires that the PINN’s output, i(t) = 0 when input t = 0. This is due to the sinusoidal source V sin(t) = 0 at t = 0, resulting in no current flowing in the circuit. The objective component for initial condition 1 is given by Equation 8. During training, backpropagation will reduce this component to a value near 0.
Equation 8
Initial condition 2
The second initial condition requires that L di/dt = 0 when input t = 0. It is derived from Kirchhoff’s voltage law (i.e., the sum of voltage drops around a closed loop is zero). Specifically, at t = 0 the following conditions exist in the circuit:
voltage source V sin(ωt) = 0
capacitor C has an initial charge of Q = 0 , yielding a capacitor voltage of V_cap = Q/C = 0
voltage across the resistor R is V_res = iR = 0, since i(t) = 0 (initial condition 1)
voltage across the inductor L is V_ind = L di/dt
given the above conditions, the sum of the voltage drops around the circuit reduces to L di/dt = 0
The objective component for initial condition 2 is given by Equation 9. Backpropagation will reduce this component to a value near 0.
Equation 9
Objective plot
The following figure shows the reduction in the value of the objective during training:
Objective plot
Results
The following test cases compare the response of the trained PINN to the appropriate analytic solution for each case. The circuit component values were chosen to produce the conditions of under-damped, overdamped, and critically-damped responses, as discussed above. All three cases are driven with a sinusoidal voltage source of V = 10 volts and ω = 1.8 radians/second. For each case, the capacitor and inductor values are C = 0.3 farads and L = 1.51 henries, respectively. The value of the resistor R is noted below for each case.
Under-damped (R = 1.2 ohms)
Underdamped test case
Over-damped (R = 6.0 ohms)
Over-damped test case
Critically-damped (R = 4.487 ohms)
critically-damped test case
Conclusion
In this article, a neural network with a custom objective function was used to successfully solve a differential equation describing an electronic circuit driven by a sinusoidal source. Typically, the solution to a differential equation is derived through a tedious analytic process or numerically. The example presented here demonstrates that a neural network can accurately solve these equations in a straightforward and efficient manner. As shown in the three test cases, the neural network response is identical to the analytic solution.
Appendix: PINN training notes
PINN structure: – input layer, 1 input – hidden layer, 128 neurons with GELU activation – hidden layer, 128 neurons with GELU activation – output layer, 1 neuron with linear activation
The PINN is trained with 220 points in the time domain of 0 to 20 seconds. The number of points is controlled by the duration of the domain and a hyperparameter for the number of points per second, which is set to 11 points/sec for the test cases. This value gives a sufficient number of training points for each period of a sinusoidal driving source with ω = 1.8. For higher values of ω, more points per second are required, e.g., ω = 4.0 requires 25 points/sec.
The PINN is trained in batches of 32 points sampled from the set of all training points. The training points are randomly shuffled at every epoch.
The learning rate starts at a value of 0.01 at the beginning of training and decreases by factor of 0.75 every 2000 epochs.
The objective plot is an important indicator of successful training. As training progresses, the objective should decrease by several orders of magnitude and bottom out at a small value near 0. If training fails to produce this result, the hyperparameters will require adjustment. It is recommended to first try increasing the number of epochs and then increasing the number of training points per second.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.