Sheref Nasereldin, Ph.D. in Theoretical Physics

Originally appeared here:
Mastering Statistical Tests (Part II): Your Guide to Choosing the Right Test for Your Data
Evaluate generative and analytical models to build Knowledge Graphs and facilitate them to power highly performing RAGs
Originally appeared here:
Implementing Generative and Analytical Models to Create and Enrich Knowledge Graphs for RAGs
“Data as a Product” is a core principle in Data Mesh. Why the current definition needs adaptation to fully enable the mesh.
Originally appeared here:
Challenges and Solutions in Data Mesh — Part 2
Go Here to Read this Fast! Challenges and Solutions in Data Mesh — Part 2


Originally appeared here:
Enhance image search experiences with Amazon Personalize, Amazon OpenSearch Service, and Amazon Titan Multimodal Embeddings in Amazon Bedrock

Originally appeared here:
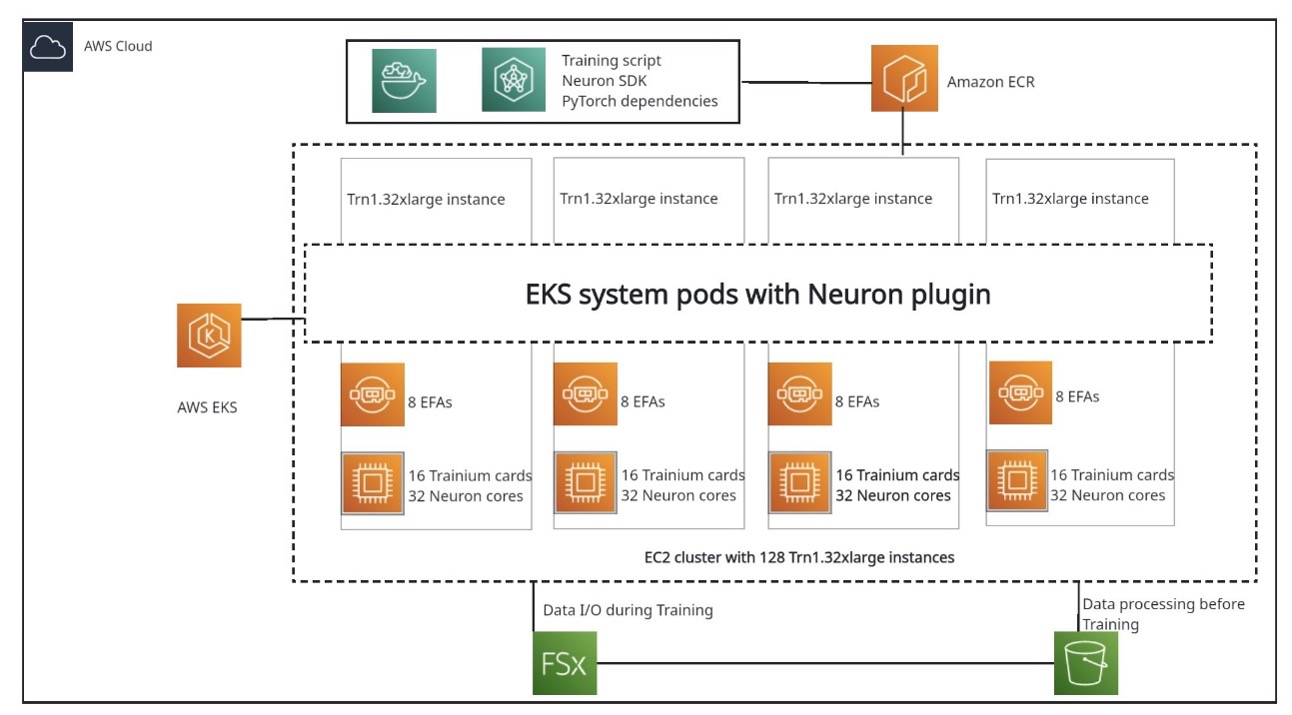
End-to-end LLM training on instance clusters with over 100 nodes using AWS Trainium

Originally appeared here:
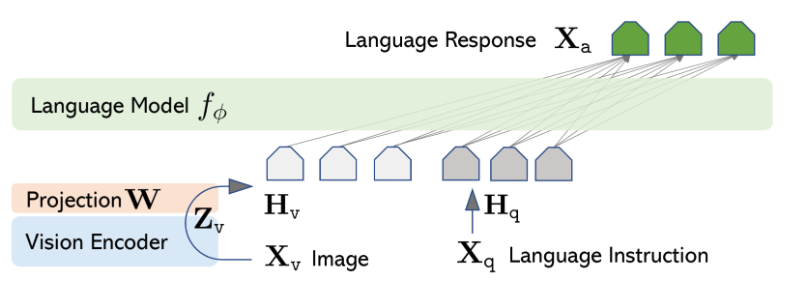
Fine-tune large multimodal models using Amazon SageMaker
Go Here to Read this Fast! Fine-tune large multimodal models using Amazon SageMaker


Flash attention is a power optimization transformer attention mechanism which provides 15% efficiency in terms of wall-clock speed with no approximation.
Given transformer models are slow and memory hungry on long sequences (time and memory complexity is quadratic in nature), flash attention(paper) provides a 15% end-to-end wall-clock speedup on BERT-large, 3x speed on GPT-2.
Considering, enormous amount of energy consumed in training these large models, Flash attention with software and hardware optimization is able to provide 15% efficiency which is a huge win in terms of improvement.
Below, discussion helps to explain some of the basic concepts behind flash attention and how it is implemented.
Before we dive deeper into compute and memory, let’s revisit them:
What is Compute?
What is Memory?
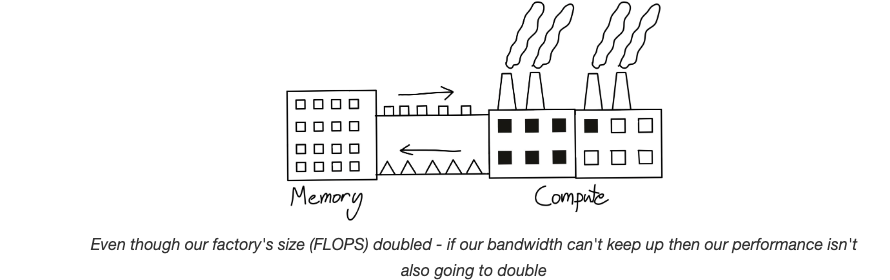
Ideally, we want our gCPU to be performing matrix multiplication all the time and not restricted by memory. But in reality, compute have made more progress as compared to memory and we are in a world where gCPU sits idle waiting for data to be loaded. This is usually called memory bound operation. Refer below on illustrative diagram depicting this. Matrix multiplication is considered compute and memory is storing the data (considering it as a warehouse). Compute need data to process and memory bandwidth has to support that operation.
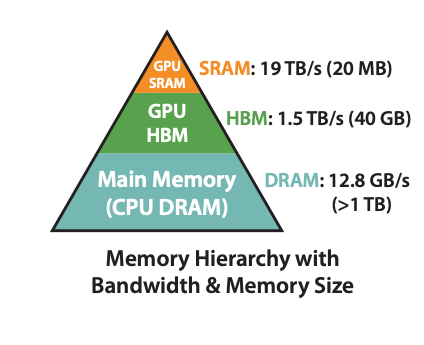
The A100 GPU has 40–80GB of high bandwidth memory with a bandwidth of 1.5–2.0 TB/s and 192KB of on-chip SRAM with each 108 streaming multiprocessors with bandwidth estimated around 19TB/s.
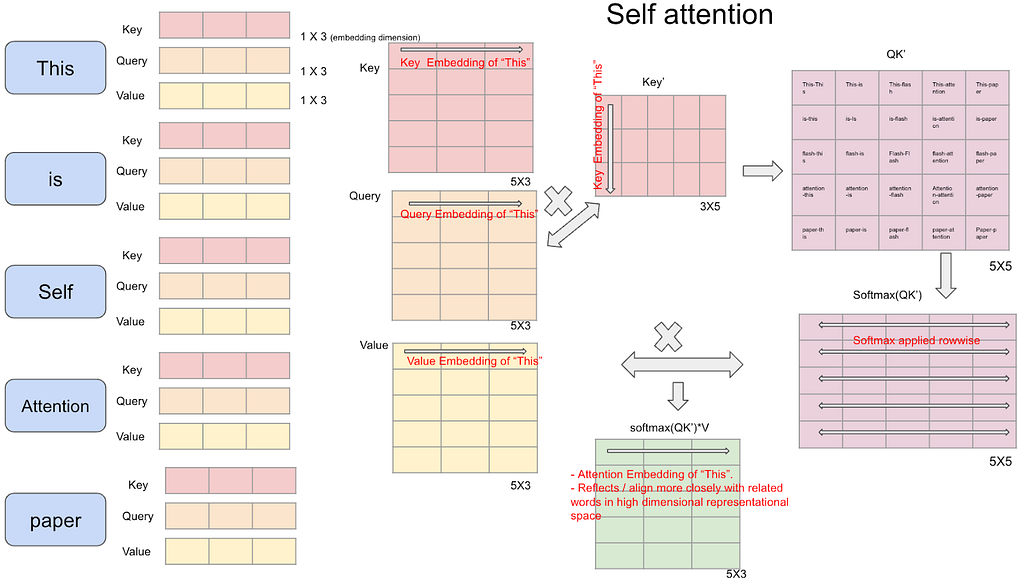
With the above context in mind, self attention architecture is memory-bound.
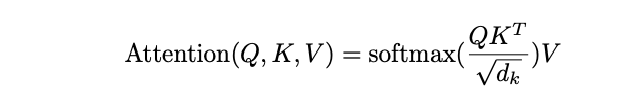
Looking at attention math, it is a softmax operation which causes the memory-bound.
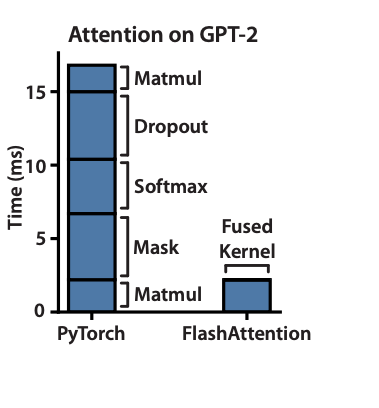
The scale at which it operates is our biggest bottleneck. In the below diagram
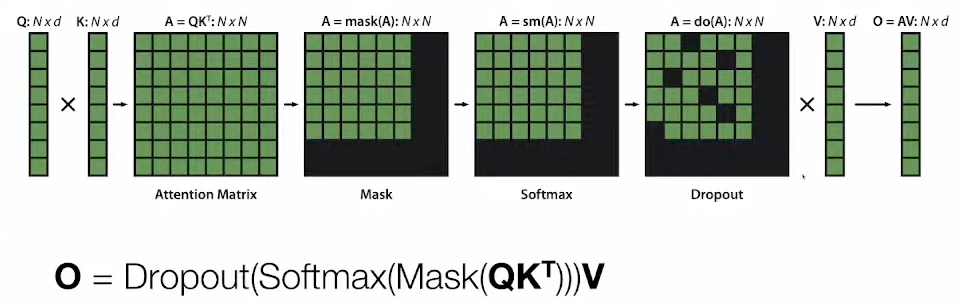
Below is the algorithm of implementing self attention mechanism

As noted in the above section, transferring information to HBM (write S to HBM) and then loading back from HBM to gCPU to compute softmax and then writing back to HBM is a lot of information traveling making it memory-bound operation.
Along with the diagram, below steps help explain how self attention is computed through matrix multiplication
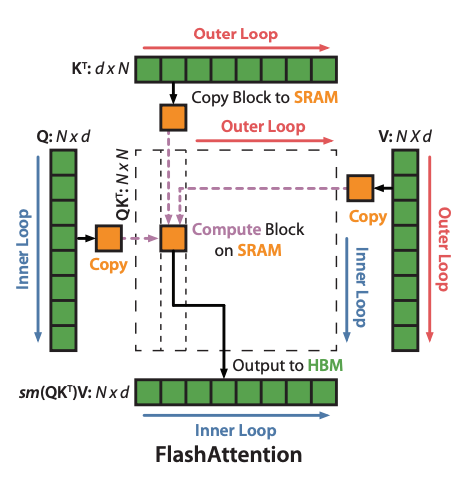
Basic idea is explained through the below diagram where blocks of key, query and value are propagated from HBM to SRAM and through some mathematical tricks (explained below), the computation done here is not an approximate but actual correct answer.
With this implementation, paper is able to reduce the wall-speed time by accessing information in blocks without sacrificing correctness.
This is the most complex part of the paper. Let’s break this problem into sub-aspects and dive deeper.
Below diagram breaks the matrix into blocks and how each block is used to compute partial softmax and then correct softmax.

Step 0
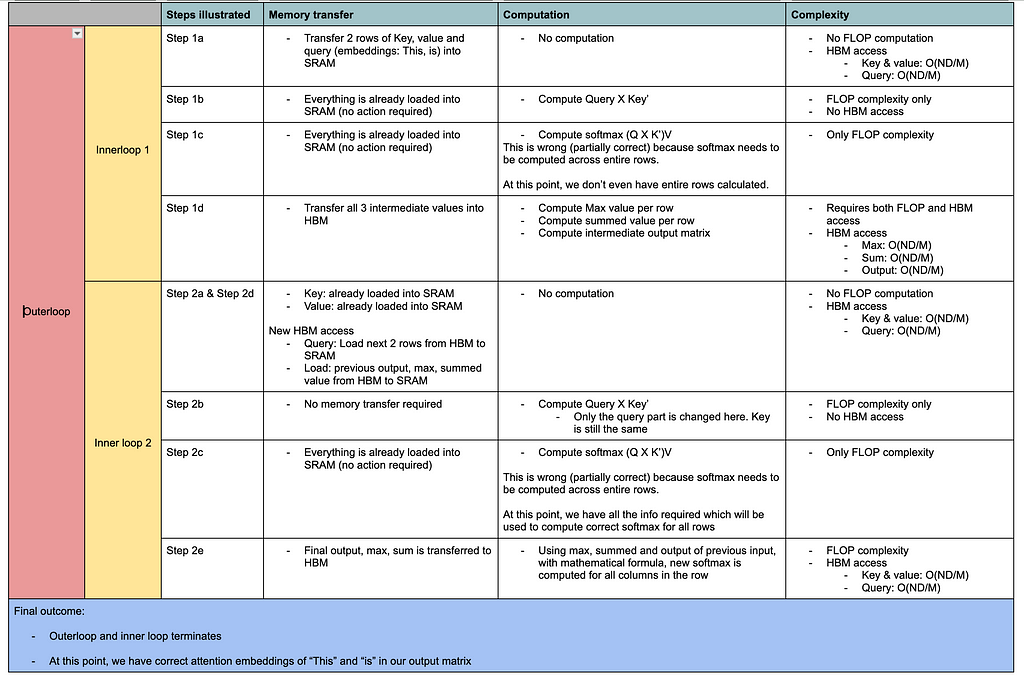
Step 1 & 2: Adding a table below which illustrates steps 1 and 2 on how flash attention works and compare memory and computation aspect of it.
Below diagram helps visualize matrix multiplication (block by block) used in flash attention.
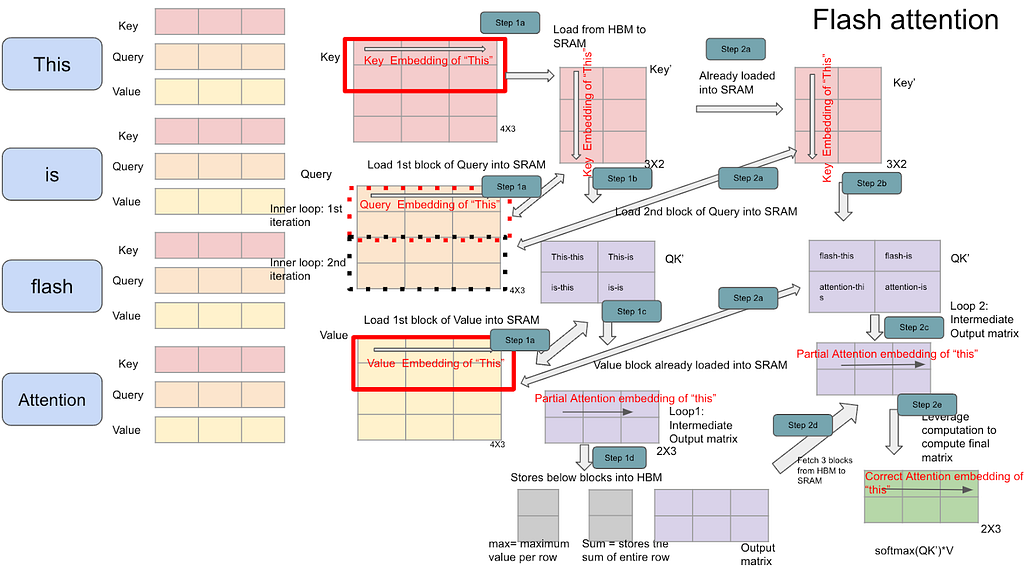
One of the most critical aspects of the paper on how breaking down matrices still results in computing softmax accuracy. Leaving the mathematical example below on how to show two different matrices can be clubbed to compute softmax again.
Intuition
Logic is quite complex and hence leaving an example below to go through. Once familiarized with an example, the above intuition will make a lot of sense.

Let’s look at complexity analysis to get a sense of how things changed
Self attention
Flash attention
Such a complex paper with huge improvement in efficiency. I hope the above explanation gives some intuition on how flash attention optimizes and improves the performance. I haven’t covered block sparse flash attention, how does this compare with other optimization techniques, forwards pass optimization etc. Hopefully to cover it in a future post.
Flash attention(Fast and Memory-Efficient Exact Attention with IO-Awareness): A deep dive was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Flash attention(Fast and Memory-Efficient Exact Attention with IO-Awareness): A deep dive
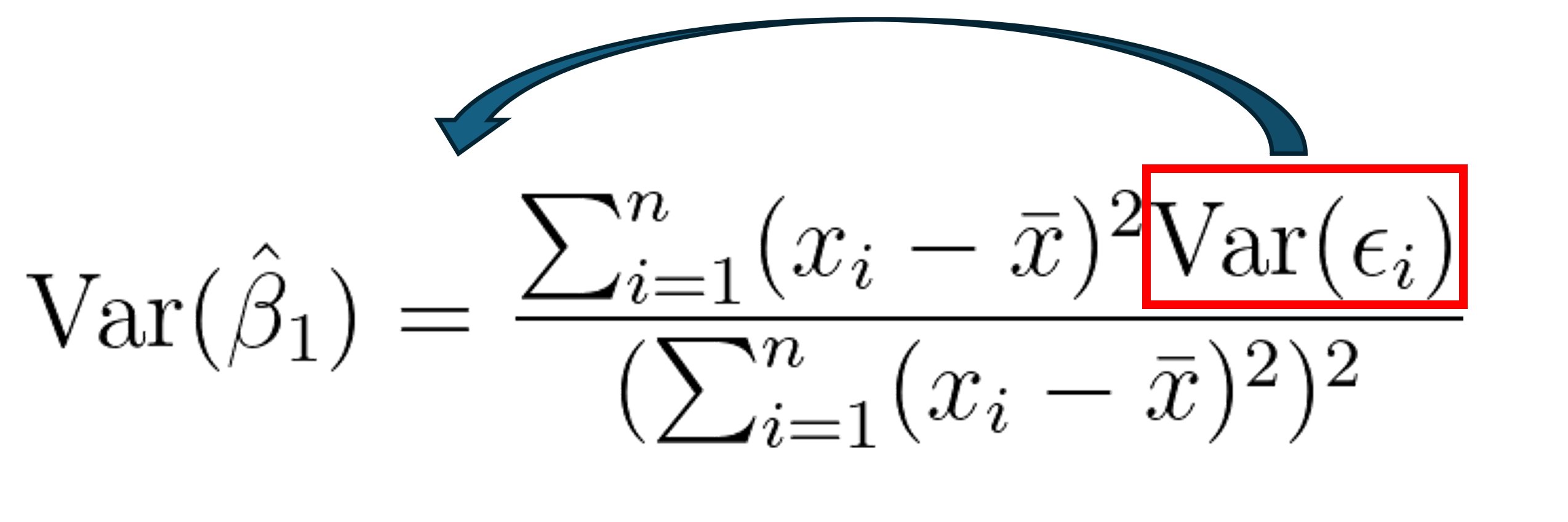
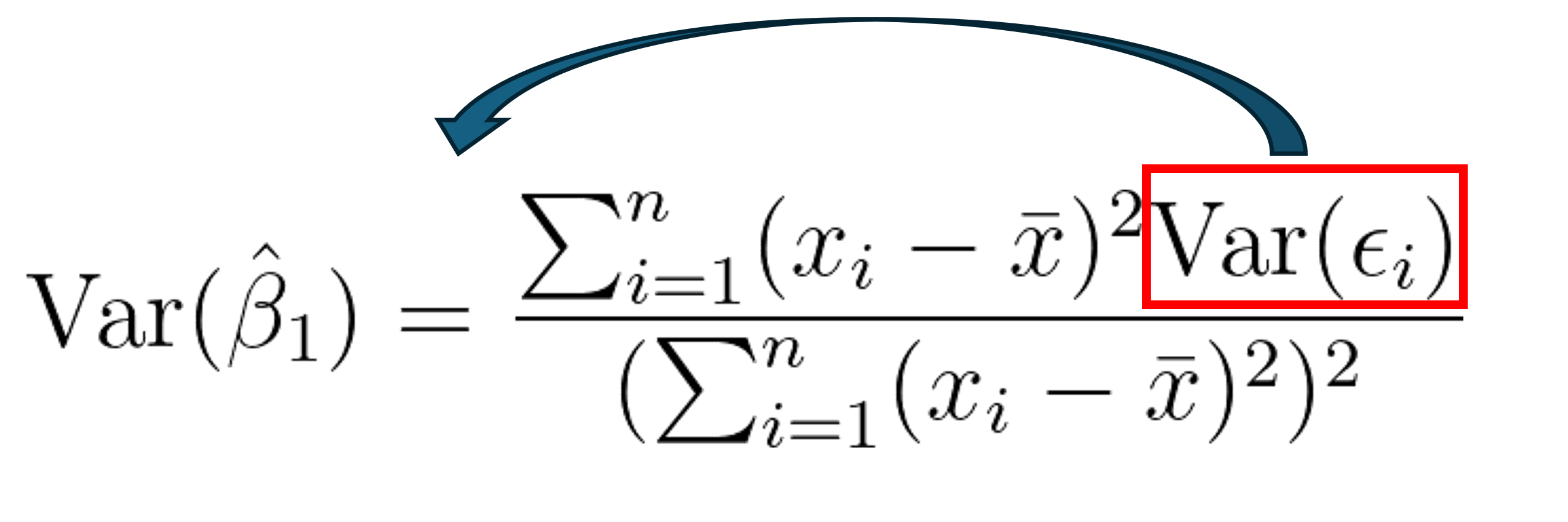
How to adjust standard errors for heteroscedasticity and why it works
Originally appeared here:
Bite Size Data Science: Heteroscedastic Robust Errors
Go Here to Read this Fast! Bite Size Data Science: Heteroscedastic Robust Errors
Teaching a Car to Cross a Mountain using Policy Gradient Methods in Python: A Mathematical Deep Dive into Reinforcement Learning
Originally appeared here:
Policy Gradient Methods in Reinforcement Learning
Go Here to Read this Fast! Policy Gradient Methods in Reinforcement Learning