Earlier this year, Gunnar Morling launched the One Billon Row Challenge, which has since gained a lot of popularity. Although the original challenge was meant to be done using Java, the amazing open-source community has since shared impressive solutions in different programming languages. I noticed that not many people had tried using Julia (or at least not publicly shared results), so decided to share my own humble attempt via this article.
A question that often came to my mind was what value does this challenge bring to a data scientist? Can we learn something more other than just doing a fun exercise? After all, the goal of the challenge is to “simply” parse a large dummy data file, calculate basic statistics (min, max and mean), and output the data in a specific format. This might not be a realistic situation for most if not all projects that data scientists usually work on.
Well, one aspect of the problem has to do with the size of the data versus the available RAM. When working locally (laptop or a desktop), for most people, it will be difficult to load the data all at once into memory. Dealing with larger than memory data sets therefore becomes an essential skill, which might come in handy when prototyping big data pipelines or performing big data analysis/visualization tasks. The rules of the original challenge also state that use of external libraries/packages should be avoided. This forces you to think of novel solutions and provides a fascinating opportunity to learn the nuances of the language itself.
In rest of the article, I will share results from both the approaches — using base Julia and also with external packages. This way, we get to compare the pros and cons of each. All experiments have been performed on a desktop equipped with AMD Ryzen 9 5900X (12 cores, 24 threads), 32 GB RAM and Samsung NVMe SSD. Julia 1.10.2 is running on Linux (Elementary OS 7.1 Horus). All relevant code is available here. Do note that the performance in this case is also tied to the hardware, so results may vary in case you decide to run the scripts on your own system.
Prerequisites
A recent release of Julia such as 1.10 is recommended. For those wanting to use a notebook, the repository shared above also contains a Pluto file, for which Pluto.jl needs to be installed. The input data file for the challenge is unique for everyone and needs to be generated using this Python script. Keep in mind that the file is about 15 GB in size.
python3 create_measurements.py 1000000000
Additionally, we will be running benchmarks using the BenchmarkTools.jl package. Note that this does not impact the challenge, it’s only meant to collect proper statistics to measure and quantify the performance of the Julia code.
Using base Julia
The structure of the input data file measurements.txt is as follows (only the first five lines are shown):
attipūdi;-49.2 Bas Limbé;-43.8 Oas;5.6 Nesebar;35.9 Saint George’s;-6.6
The file contains a billion lines (also known as rows or records). Each line has a station name followed by the ; separator and then the recorded temperature. The number of unique stations can be up to 10,000. This implies that the same station appears on multiple lines. We therefore need to collect all the temperatures for all distinct stations in the file, and then calculate the required statistics. Easy, right?
Let’s start slow but simple
My first attempt was to simply parse the file one line at a time, and then collect the results in a dictionary where every station name is a key and the temperatures are added to a vector of Float64 to be used as the value mapped to the key. I expected this to be slow, but our aim here is to get a number for the baseline performance.
Once the dictionary is ready, we can calculate the necessary statistics:
The output of all the data processing needs to be displayed in a certain format. This is achieved by the following function:
Since this implementation is expected to take long, we can run a simple test by timing @time the following only once:
<output omitted for brevity> 526.056399 seconds (3.00 G allocations: 302.881 GiB, 3.68% gc time)
Our poor man’s implementation takes about 526 seconds, so ~ 9 minutes. It’s definitely slow, but not that bad at all!
Taking it up a notch — Enter multithreading!
Instead of reading the input file one line at a time, we can try to split it into chunks, and then process all the chunks in parallel. Julia makes it quite easy to implement a parallel for loop. However, we need to take some precautions while doing so.
Before we get to the loop, we first need to figure out how to split the file into chunks. This can be achieved using memory mapping to read the file. Then we need to determine the start and end positions of each chunk. It’s important to note that each line in the input data file ends with a new-line character, which has 0x0a as the byte representation. So each chunk should end at that character to ensure that we don’t make any errors while parsing the file.
The following function takes the number of chunksnum_chunksas an input argument, then returns an array with each element as the memory mapped chunk.
Since we are parsing station and temperature data from different chunks, we also need to combine them in the end. Each chunk will first be processed into a dictionary as shown before. Then, we combine all chunks as follows:
Now we know how to split the file into chunks, and how we can combine the parsed dictionaries from the chunks at the end. However, the desired speedup can only be obtained if we are also able to process the chunks in parallel. This can be done in a for loop. Note that Julia should be started with multiple threads julia -t 12 for this solution to have any impact.
Additionally, we now want to run a proper statistical benchmark. This means that the challenge should be executed a certain number of times, and we should then be able to visualize the distribution of the results. Thankfully, all of this can be easily done with BenchmarkTools.jl. We cap the maximum number of samples to 10, maximum time for the total run to be 20 minutes and enable garbage collection (will free up memory) to execute between samples. All of this can be brought together in a single script. Note that the input arguments are now the name of the file fname and the number of chunks num_chunks.
Benchmark results along with the inputs used are shown below. Note that we have used 12 threads here.
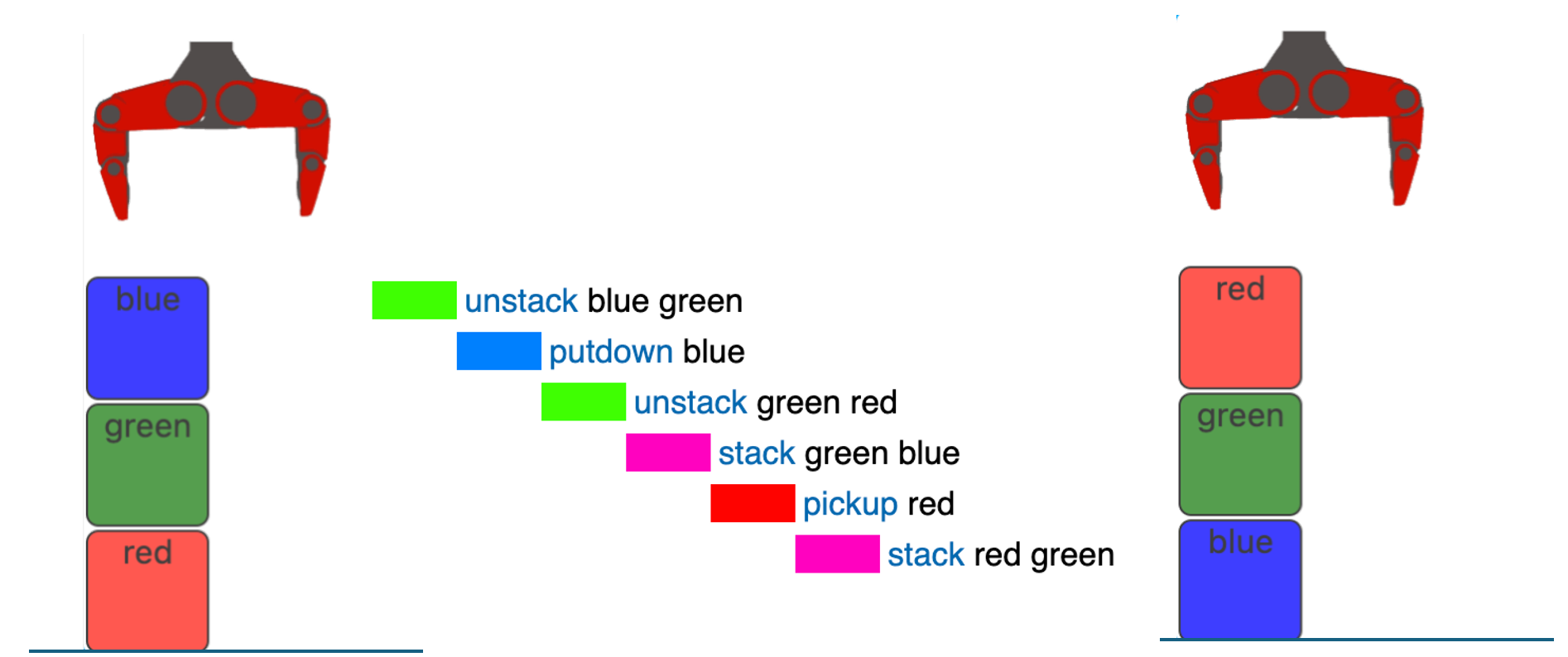
12 threads, number of chunks = 48 (Image by author)
Multi-threading provides a big performance boost, we are now down to roughly over 2 minutes. Let’s see what else we can improve.
Avoiding storing all temperature data
Until now, our approach has been to store all the temperatures, and then determine the required statistics (min, mean and max) at the very end. However, the same can already be achieved while we parse every line from the input file. We replace existing values each time a new value which is either larger (for maximum) or smaller (for minimum) is found. For mean, we sum all the values and keep a separate counter as to how many times a temperature for a given station has been found.
Overall, out new logic looks like the following:
The function to combine all the results (from different chunks) also needs to be updated accordingly.
Let’s run a new benchmark and see if this change improves the timing.
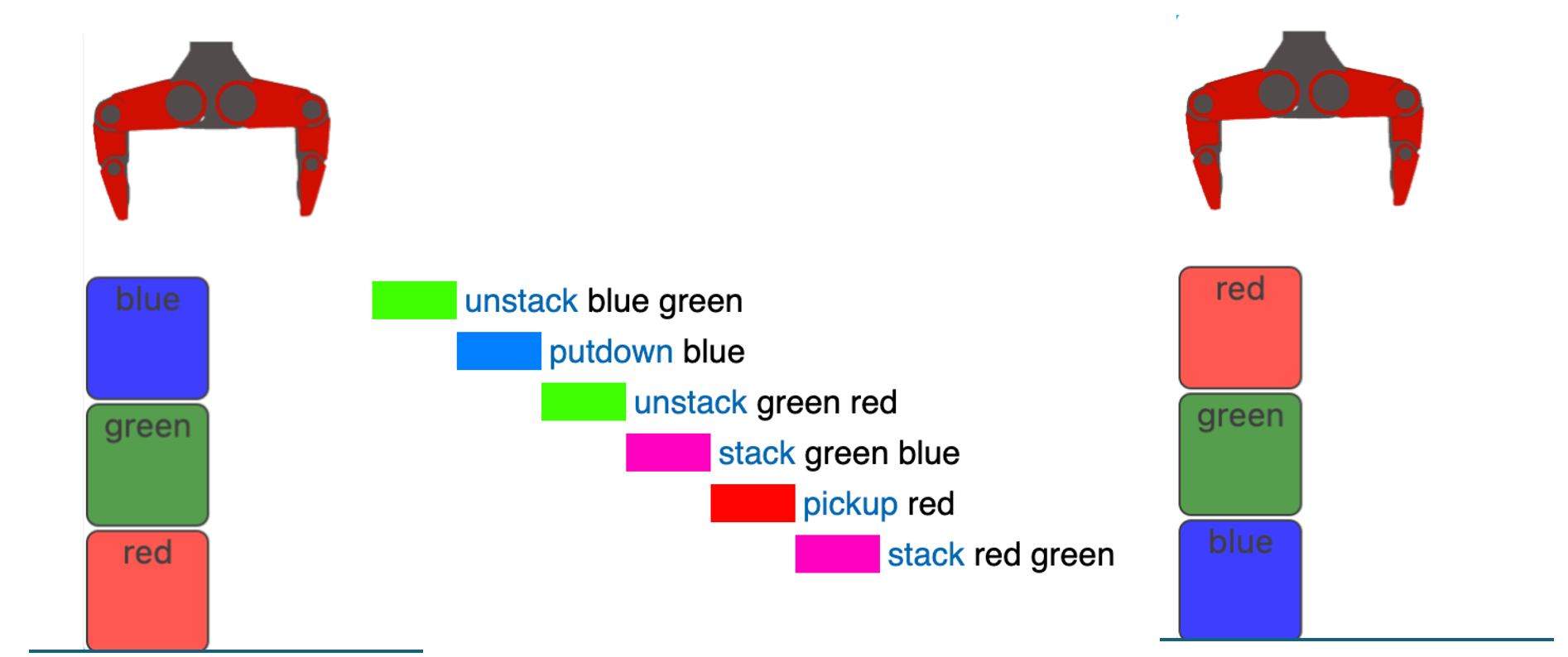
12 threads, number of chunks = 48 (Image by author)
The median time seems to have improved, but only slightly. It’s a win, nonetheless!
More performance enhancement
Our previous logic to calculate and save the mix, max for temperature can be further simplified. Moreover, following the suggestion from this Julia Discourse post, we can make use of views (using @view ) when parsing the station names and temperature data. This has also been discussed in the Julia performance manual. Since we are using a slice expression for parsing every line, @view helps us avoid the cost of allocation and copying.
Rest of the logic remains the same. Running the benchmark now gives the following:
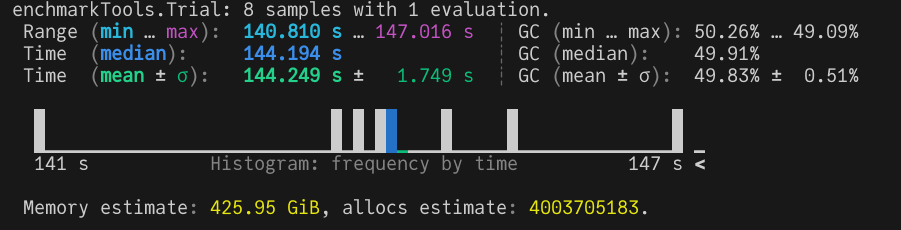
12 threads, number of chunks = 48 (Image by author)
Whoa! We managed to reach down to almost a minute. It seems switching to a view does make a big difference. Perhaps, there are further tweaks that could be made to improve performance even further. In case you have any suggestions, do let me know in the comments.
Using external packages
Restricting ourselves only to base Julia was fun. However, in the real world, we will almost always be using packages and thus making use of existing efficient implementations for performing the relevant tasks. In our case, CSV.jl (parsing the file in parallel) and DataFrames.jl (performing groupby and combine) will come in handy.
The function below performs the following tasks:
Use Mmap to read the large file
Split file into a predefined number of chunks
Loop through the chunks, read each chunk in parallel using CSV.read (12 threads passed to ntasks) into a DataFrame.
Use DataFrame groupby and combine to get the results for each station
Concatenate all DataFrames to combine results from all chunks
Once outside the loop, perform a groupby and combine again to get the final set of results for all stations.
We can now run the benchmark in the same manner as before.
12 threads, number of chunks = 48, using external packages (Image by author)
The performance using CSV.jl and DataFrames.jl is quite good, albeit slower than our base Julia implementation. When working on real world projects, these packages are an essential part of a data scientist’s toolkit. It would thus be interesting to explore if further optimizations are possible using this approach.
Conclusion
In this article, we tackled the One Billion Row Challenge using Julia. Starting from a very naive implementation that took ~ 10 minutes, we managed to gain significant performance improvement through iterative changes to the code. The most optimized implementation completes the challenge in ~ 1 minute. I am certain that there’s still more room for improvement. As an added bonus, we learned some valuable tricks on how to deal with larger than memory data sets. This might come in handy when doing some big data analysis and visualization using Julia.
I hope you found this exercise useful. Thank you for your time! Connect with me on LinkedIn or visit my Web 3.0 powered website.
Building a cross-lingual RAG system for Rabbinic texts
Robot studying The Mishnah. Credit: DALL-E-3.
Introduction:
I’m excited to share my journey of building a unique Retrieval-Augmented Generation (RAG) application for interacting with rabbinic texts in this post. MishnahBot aims to provide scholars and everyday users with an intuitive way to query and explore the Mishnah¹ interactively. It can help solve problems such as quickly locating relevant source texts or summarizing a complex debate about religious law, extracting the bottom line.
I had the idea for such a project a few years back, but I felt like the technology wasn’t ripe yet. Now, with advancements of large language models, and RAG capabilities, it is pretty straightforward.
This is what our final product will look like, which you could try out here:
RAG applications are gaining significant attention, for improving accuracy and harnessing the reasoning power available in large language models (LLMs). Imagine being able to chat with your library, a collection of car manuals from the same manufacturer, or your tax documents. You can ask questions, and receive answers informed by the wealth of specialized knowledge.
There are two emerging trends in improving language model interactions: Retrieval-Augmented Generation (RAG) and increasing context length, potentially by allowing very long documents as attachments.
One key advantage of RAG systems is cost-efficiency. With RAG, you can handle large contexts without drastically increasing the query cost, which can become expensive. Additionally, RAG is more modular, allowing you to plug and play with different knowledge bases and LLM providers. On the other hand, increasing the context length directly in language models is an exciting development that can enable handling much longer texts in a single interaction.
Setup
For this project, I used AWS SageMaker for my development environment, AWS Bedrock to access various LLMs, and the LangChain framework to manage the pipeline. Both AWS services are user-friendly and charge only for the resources used, so I really encourage you to try it out yourselves. For Bedrock, you’ll need to request access to Llama 3 70b Instruct and Claude Sonnet.
Let’s open a new Jupyter notebook, and install the packages we will be using:
The dataset for this project is the Mishnah, an ancient Rabbinic text central to Jewish tradition. I chose this text because it is close to my heart and also presents a challenge for language models since it is a niche topic. The dataset was obtained from the Sefaria-Export repository², a treasure trove of rabbinic texts with English translations aligned with the original Hebrew. This alignment facilitates switching between languages in different steps of our RAG application.
Note: The same process applied here can be applied to any other collection of texts of your choosing. This example also demonstrates how RAG technology can be utilized across different languages, as shown with Hebrew in this case.
Let’s Dive In
1. Loading the Dataset
First we will need to download the relevant data. We will use git sparse-checkout since the full repository is quite large. Open the terminal window and run the following.
Now let’s load the documents in our Jupyter notebook environment:
import os import json import pandas as pd from tqdm import tqdm
# Function to load all documents into a DataFrame with progress bar def load_documents(base_path): data = [] for seder in tqdm(os.listdir(base_path), desc="Loading Seders"): seder_path = os.path.join(base_path, seder) if os.path.isdir(seder_path): for tractate in tqdm(os.listdir(seder_path), desc=f"Loading Tractates in {seder}", leave=False): tractate_path = os.path.join(seder_path, tractate) if os.path.isdir(tractate_path): english_file = os.path.join(tractate_path, "English", "merged.json") hebrew_file = os.path.join(tractate_path, "Hebrew", "merged.json") if os.path.exists(english_file) and os.path.exists(hebrew_file): with open(english_file, 'r', encoding='utf-8') as ef, open(hebrew_file, 'r', encoding='utf-8') as hf: english_data = json.load(ef) hebrew_data = json.load(hf) for chapter_index, (english_chapter, hebrew_chapter) in enumerate(zip(english_data['text'], hebrew_data['text'])): for mishnah_index, (english_paragraph, hebrew_paragraph) in enumerate(zip(english_chapter, hebrew_chapter)): data.append({ "seder": seder, "tractate": tractate, "chapter": chapter_index + 1, "mishnah": mishnah_index + 1, "english": english_paragraph, "hebrew": hebrew_paragraph }) return pd.DataFrame(data) # Load all documents base_path = "Mishnah" df = load_documents(base_path) # Save the DataFrame to a file for future reference df.to_csv(os.path.join(base_path, "mishnah_metadata.csv"), index=False) print("Dataset successfully loaded into DataFrame and saved to file.")
And take a look at the Data:
df.shape (4192, 7)
print(df.head()[["tractate", "mishnah", "english"]]) tractate mishnah english 0 Mishnah Arakhin 1 <b>Everyone takes</b> vows of <b>valuation</b>... 1 Mishnah Arakhin 2 With regard to <b>a gentile, Rabbi Meir says:<... 2 Mishnah Arakhin 3 <b>One who is moribund and one who is taken to... 3 Mishnah Arakhin 4 In the case of a pregnant <b>woman who is take... 4 Mishnah Arakhin 1 <b>One cannot be charged for a valuation less ...
Looks good, we can move on to the vector database stage.
2. Vectorizing and Storing in ChromaDB
Next, we vectorize the text and store it in a local ChromaDB. In one sentence, the idea is to represent text as dense vectors — arrays of numbers — such that texts that are similar semantically will be “close” to each other in vector space. This is the technology that will enable us to retrieve the relevant passages given a query.
We opted for a lightweight vectorization model, the all-MiniLM-L6-v2, which can run efficiently on a CPU. This model provides a good balance between performance and resource efficiency, making it suitable for our application. While state-of-the-art models like OpenAI’s text-embedding-3-large may offer superior performance, they require substantial computational resources, typically running on GPUs.
For more information about embedding models and their performance, you can refer to the MTEB leaderboard which compares various text embedding models on multiple tasks.
Here’s the code we will use for vectorizing (should only take a few minutes to run on this dataset on a CPU machine):
import numpy as np from sentence_transformers import SentenceTransformer import chromadb from chromadb.config import Settings from tqdm import tqdm
# Initialize the embedding model model = SentenceTransformer('all-MiniLM-L6-v2', device='cpu') # Initialize ChromaDB chroma_client = chromadb.Client(Settings(persist_directory="chroma_db")) collection = chroma_client.create_collection("mishnah") # Load the dataset from the saved file df = pd.read_csv(os.path.join("Mishnah", "mishnah_metadata.csv")) # Function to generate embeddings with progress bar def generate_embeddings(paragraphs, model): embeddings = [] for paragraph in tqdm(paragraphs, desc="Generating Embeddings"): embedding = model.encode(paragraph, show_progress_bar=False) embeddings.append(embedding) return np.array(embeddings) # Generate embeddings for English paragraphs embeddings = generate_embeddings(df['english'].tolist(), model) df['embedding'] = embeddings.tolist() # Store embeddings in ChromaDB with progress bar for index, row in tqdm(df.iterrows(), desc="Storing in ChromaDB", total=len(df)): collection.add(embeddings=[row['embedding']], documents=[row['english']], metadatas=[{ "seder": row['seder'], "tractate": row['tractate'], "chapter": row['chapter'], "mishnah": row['mishnah'], "hebrew": row['hebrew'] }]) print("Embeddings and metadata successfully stored in ChromaDB.")
3. Creating Our RAG in English
With our dataset ready, we can now create our Retrieval-Augmented Generation (RAG) application in English. For this, we’ll use LangChain, a powerful framework that provides a unified interface for various language model operations and integrations, making it easy to build sophisticated applications.
LangChain simplifies the process of integrating different components like language models (LLMs), retrievers, and vector stores. By using LangChain, we can focus on the high-level logic of our application without worrying about the underlying complexities of each component.
Here’s the code to set up our RAG system:
from langchain.chains import LLMChain, RetrievalQA from langchain.llms import Bedrock from langchain.prompts import PromptTemplate from sentence_transformers import SentenceTransformer import chromadb from chromadb.config import Settings from typing import List
# Define the prompt template prompt_template = PromptTemplate( input_variables=["context", "question"], template=""" Answer the following question based on the provided context alone: Context: {context} Question: {question} Answer (short and concise): """, )
# Initialize and test SimpleQAChain qa_chain = SimpleQAChain(retriever=simple_retriever, llm_chain=llm_chain)
Explanation:
AWS Bedrock Initialization: We initialize AWS Bedrock with Llama 3 70B Instruct. This model will be used for generating responses based on the retrieved context.
Prompt Template: The prompt template is defined to format the context and question into a structure that the LLM can understand. This helps in generating concise and relevant answers. Feel free to play around and adjust the template as needed.
Embedding Model: We use the ‘all-MiniLM-L6-v2’ model for generating embeddings for the queries as well. We hope the query will have similar representation to relevant answer paragraphs. Note: In order to boost retrieval performance, we could use an LLM to modify and optimize the user query so that it is more similar to the style of the RAG database.
LLM Chain: The LLMChain class from LangChain is used to manage the interaction between the LLM and the retrieved context.
SimpleQAChain: This custom class integrates the retriever and the LLM chain. It retrieves relevant paragraphs, formats them into a context, and generates an answer.
Alright! Let’s try it out! We will use a query related to the very first paragraphs in the Mishnah.
response = qa_chain({"query": "What is the appropriate time to recite Shema?"})
print("#"*50) print("Response:") print(response)
################################################## Retrieved paragraphs: The beginning of tractate <i>Berakhot</i>, the first tractate in the first of the six orders of Mish... <b>From when does one recite <i>Shema</i> in the morning</b>? <b>From</b> when a person <b>can disti... Beit Shammai and Beit Hillel disputed the proper way to recite <i>Shema</i>. <b>Beit Shammai say:</b... ################################################## Response: In the evening, from when the priests enter to partake of their teruma until the end of the first watch, or according to Rabban Gamliel, until dawn. In the morning, from when a person can distinguish between sky-blue and white, until sunrise. ################################################## Sources: Seder Zeraim Mishnah Berakhot Chapter 1, Mishnah 1 Seder Zeraim Mishnah Berakhot Chapter 1, Mishnah 2 Seder Zeraim Mishnah Berakhot Chapter 1, Mishnah 3
That seems pretty accurate.
Let’s try a more sophisticated question:
response = qa_chain({"query": "What is the third prohibited kind of work on the sabbbath?"})
print("#"*50) print("Response:") print(response)
################################################## Retrieved paragraphs: They said an important general principle with regard to the sabbatical year: anything that is food f... This fundamental mishna enumerates those who perform the <b>primary categories of labor</b> prohibit... <b>Rabbi Akiva said: I asked Rabbi Eliezer with regard to</b> one who <b>performs multiple</b> prohi... ################################################## Response: One who reaps. ################################################## Sources: Seder Zeraim Mishnah Sheviit Chapter 7, Mishnah 1 Seder Moed Mishnah Shabbat Chapter 7, Mishnah 2 Seder Kodashim Mishnah Keritot Chapter 3, Mishnah 10
Very nice.
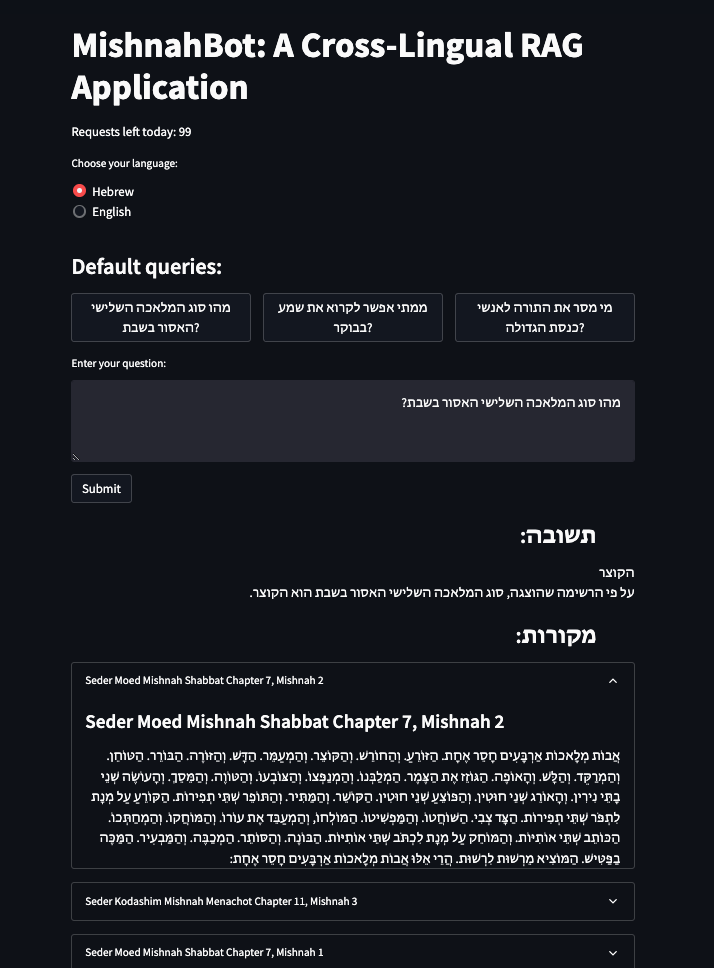
Could We Have Achieved the Same Thing by Querying Claude Directly?
I tried that out, here’s what I got:
Claude Sonnet fails to give an exact answer to the question. Image by author.
The response is long and not to the point, and the answer that is given is incorrect (reaping is the third type of work in the list, while selecting is the seventh). This is what we call a hallucination.
While Claude is a powerful language model, relying solely on an LLM for generating responses from memorized training data or even using internet searches lacks the precision and control offered by a custom database in a Retrieval-Augmented Generation (RAG) application. Here’s why:
Precision and Context: Our RAG application retrieves exact paragraphs from a custom database, ensuring high relevance and accuracy. Claude, without specific retrieval mechanisms, might not provide the same level of detailed and context-specific responses.
Efficiency: The RAG approach efficiently handles large datasets, combining retrieval and generation to maintain precise and contextually relevant answers.
Cost-Effectiveness: By utilizing a relatively small LLM such as Llama 3 70B Instruct, we achieve accurate results without needing to send a large amount of data with each query. This reduces costs associated with using larger, more resource-intensive models.
This structured retrieval process ensures users receive the most accurate and relevant answers, leveraging both the language generation capabilities of LLMs and the precision of custom data retrieval.
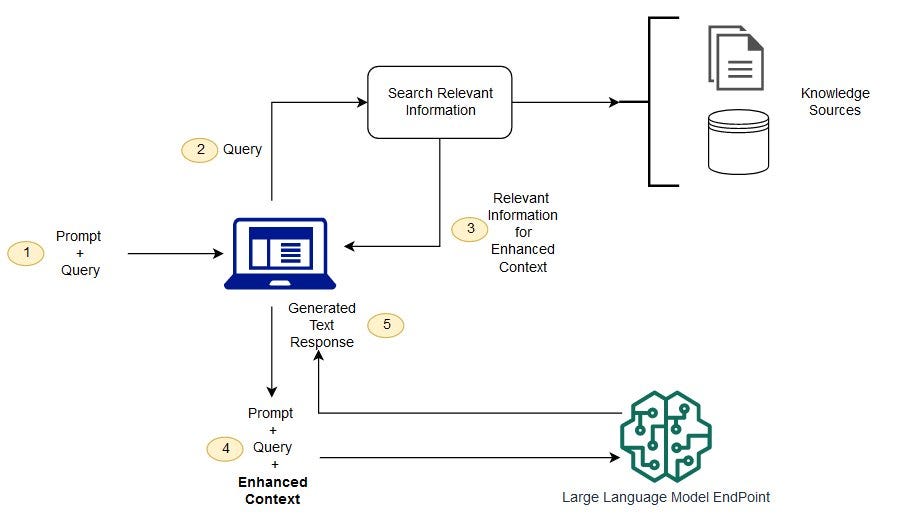
4. Cross-Lingual RAG Approach
Finally, we will address the challenge of interacting in Hebrew with the original Hebrew text. The same approach can be applied to any other language, as long as you are able to translate the texts to English for the retrieval stage.
Supporting Hebrew interactions adds an extra layer of complexity since embedding models and large language models (LLMs) tend to be stronger in English. While some embedding models and LLMs do support Hebrew, they are often less robust than their English counterparts, especially the smaller embedding models that likely focused more on English during training.
To tackle this, we could train our own Hebrew embedding model. However, another practical approach is to leverage a one-time translation of the text to English and use English embeddings for the retrieval process. This way, we benefit from the strong performance of English models while still supporting Hebrew interactions.
Processing Steps
Diagram of cross-lingual RAG Architecture. Image by author.
In our case, we already have professional human translations of the Mishnah text into English. We will use this to ensure accurate retrievals while maintaining the integrity of the Hebrew responses. Here’s how we can set up this cross-lingual RAG system:
Input Query in Hebrew: Users can input their queries in Hebrew.
Translate the Query to English: We use an LLM to translate the Hebrew query into English.
Embed the Query: The translated English query is then embedded.
Find Relevant Documents Using English Embeddings: We use the English embeddings to find relevant documents.
Retrieve Corresponding Hebrew Texts: The corresponding Hebrew texts are retrieved as context. Essentially we are using the English texts as keys and the Hebrew texts as the corresponding values in the retrieval operation.
Respond in Hebrew Using an LLM: An LLM generates the response in Hebrew using the Hebrew context.
For generation, we use Claude Sonnet since it performs significantly better on Hebrew text compared to Llama 3.
Here is the code implementation:
from langchain.chains import LLMChain, RetrievalQA from langchain.llms import Bedrock from langchain_community.chat_models import BedrockChat from langchain.prompts import PromptTemplate from sentence_transformers import SentenceTransformer import chromadb from chromadb.config import Settings from typing import List import re
# Initialize AWS Bedrock for Llama 3 70B Instruct with specific configurations for translation translation_llm = Bedrock( model_id="meta.llama3-70b-instruct-v1:0", model_kwargs={ "temperature": 0.0, # Set lower temperature for translation "max_gen_len": 50 # Limit number of tokens for translation } )
# Initialize AWS Bedrock for Claude Sonnet with specific configurations for generation generation_llm = BedrockChat( model_id="anthropic.claude-3-sonnet-20240229-v1:0" )
# Define the translation prompt template translation_prompt_template = PromptTemplate( input_variables=["text"], template="""Translate the following Hebrew text to English: Input text: {text} Translation: """ )
# Define the prompt template for Hebrew answers hebrew_prompt_template = PromptTemplate( input_variables=["context", "question"], template="""ענה על השאלה הבאה בהתבסס על ההקשר המסופק בלבד: הקשר: {context} שאלה: {question} תשובה (קצרה ותמציתית): """ )
# Define the embedding model embedding_model = SentenceTransformer('all-MiniLM-L6-v2', device='cpu')
# Translation chain for translating queries from Hebrew to English translation_chain = LLMChain( llm=translation_llm, prompt=translation_prompt_template )
# Initialize the LLM chain for Hebrew answers hebrew_llm_chain = LLMChain( llm=generation_llm, prompt=hebrew_prompt_template )
# Define a simple retriever function for Hebrew texts def simple_retriever(query: str, k: int = 3) -> List[str]: query_embedding = embedding_model.encode(query).tolist() results = collection.query(query_embeddings=[query_embedding], n_results=k) documents = [meta['hebrew'] for meta in results['metadatas'][0]] # Access Hebrew texts sources = results['metadatas'][0] # Access the metadata for sources return documents, sources
# Function to remove vowels from Hebrew text def remove_vowels_hebrew(hebrew_text): pattern = re.compile(r'[u0591-u05C7]') hebrew_text_without_vowels = re.sub(pattern, '', hebrew_text) return hebrew_text_without_vowels
# Perform the translation using the translation chain with specific configurations translated_query = self.translation_chain.run({"text": hebrew_query}) print("#" * 50) print(f"Translated Query: {translated_query}") # Print the translated query for debugging
retrieved_docs, sources = self.retriever(translated_query) retrieved_docs = [remove_vowels_hebrew(doc) for doc in retrieved_docs]
context = "n".join(retrieved_docs)
# Print the final prompt for generation final_prompt = hebrew_prompt_template.format(context=context, question=hebrew_query) print("#" * 50) print(f"Final Prompt for Generation:n {final_prompt}")
response = self.llm_chain.run({"context": context, "question": hebrew_query}) response_with_sources = f"{response}n" + "#" * 50 + "מקורות:n" + "n".join( [f"{source['seder']} {source['tractate']} פרק {source['chapter']}, משנה {source['mishnah']}" for source in sources] ) return response_with_sources
# Initialize and test SimpleQAChainWithTranslation qa_chain = SimpleQAChainWithTranslation(translation_chain, simple_retriever, hebrew_llm_chain)
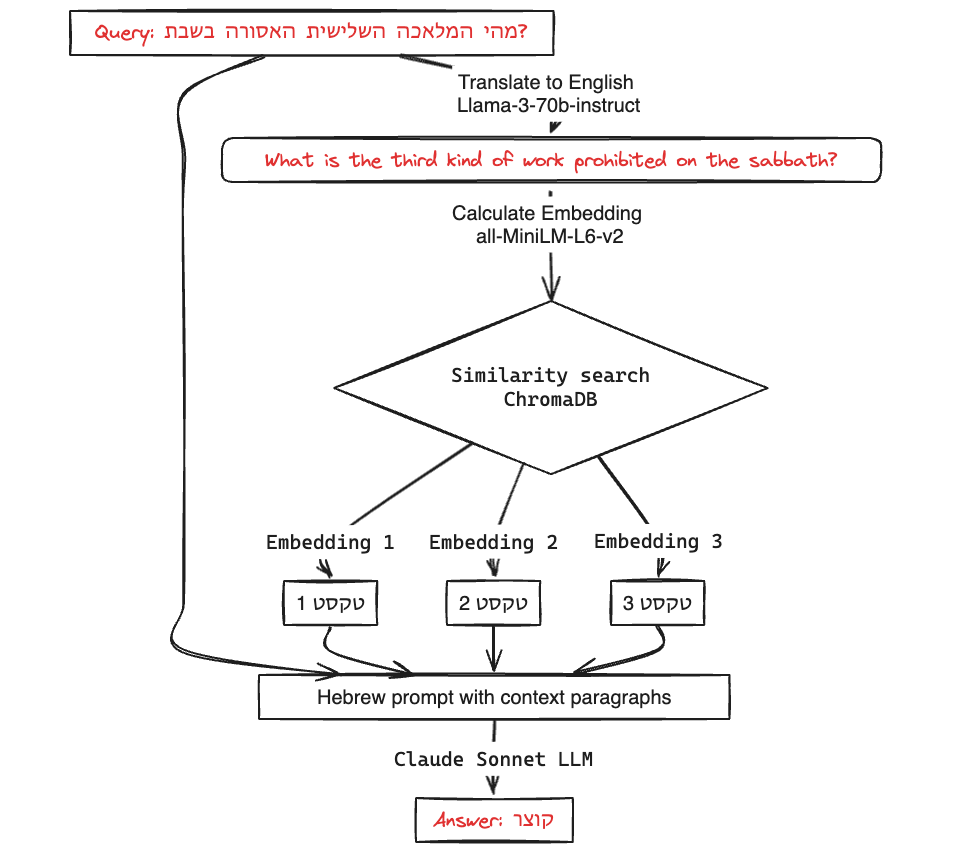
Let’s try it! We will use the same question as before, but in Hebrew this time:
response = qa_chain({"query": "מהו סוג העבודה השלישי האסור בשבת?"}) print("#" * 50) print(response)
################################################## Hebrew query: מהו סוג העבודה השלישי האסור בשבת? ################################################## Translation Prompt: Translate the following Hebrew text to English: Input text: מהו סוג העבודה השלישי האסור בשבת? Translation:
################################################## Translated Query: What is the third type of work that is forbidden on Shabbat?
Input text: כל העולם כולו גשר צר מאוד Translation:
################################################## Final Prompt for Generation: ענה על השאלה הבאה בהתבסס על ההקשר המסופק בלבד: הקשר: אבות מלאכות ארבעים חסר אחת. הזורע. והחורש. והקוצר. והמעמר. הדש. והזורה. הבורר. הטוחן. והמרקד. והלש. והאופה. הגוזז את הצמר. המלבנו. והמנפצו. והצובעו. והטווה. והמסך. והעושה שני בתי נירין. והאורג שני חוטין. והפוצע שני חוטין. הקושר. והמתיר. והתופר שתי תפירות. הקורע על מנת לתפר שתי תפירות. הצד צבי. השוחטו. והמפשיטו. המולחו, והמעבד את עורו. והמוחקו. והמחתכו. הכותב שתי אותיות. והמוחק על מנת לכתב שתי אותיות. הבונה. והסותר. המכבה. והמבעיר. המכה בפטיש. המוציא מרשות לרשות. הרי אלו אבות מלאכות ארבעים חסר אחת:
חבתי כהן גדול, לישתן ועריכתן ואפיתן בפנים, ודוחות את השבת. טחונן והרקדן אינן דוחות את השבת. כלל אמר רבי עקיבא, כל מלאכה שאפשר לה לעשות מערב שבת, אינה דוחה את השבת. ושאי אפשר לה לעשות מערב שבת, דוחה את השבת:
הקורע בחמתו ועל מתו, וכל המקלקלין, פטורין. והמקלקל על מנת לתקן, שעורו כמתקן:
שאלה: מהו סוג העבודה השלישי האסור בשבת? תשובה (קצרה ותמציתית):
################################################## הקוצר. ##################################################מקורות: Seder Moed Mishnah Shabbat פרק 7, משנה 2 Seder Kodashim Mishnah Menachot פרק 11, משנה 3 Seder Moed Mishnah Shabbat פרק 13, משנה 3
We got an accurate, one word answer to our question. Pretty neat, right?
Interesting Challenges and Solutions
The translation with Llama 3 Instruct posed several challenges. Initially, the model produced nonsensical results no matter what I tried. (Apparently, Llama 3 instruct is very sensitive to prompts starting with a new line character!)
After resolving that issue, the model tended to output the correct response, but then continue with additional irrelevant text, so stopping the output at a newline character proved effective.
Controlling the output format can be tricky. Some strategies include requesting a JSON format or providing examples with few-shot prompts.
In this project, we also remove vowels from the Hebrew texts since most Hebrew text online does not include vowels, and we want the context for our LLM to be similar to text seen during pretraining.
Conclusion
Building this RAG application has been a fascinating journey, blending the nuances of ancient texts with modern AI technologies. My passion for making the library of ancient rabbinic texts more accessible to everyone (myself included) has driven this project. This technology enables chatting with your library, searching for sources based on ideas, and much more. The approach used here can be applied to other treasured collections of texts, opening up new possibilities for accessing and exploring historical and cultural knowledge.
It’s amazing to see how all this can be accomplished in just a few hours, thanks to the powerful tools and frameworks available today. Feel free to check out the full code on GitHub, and play with the MishnahBot website.
Please share your comments and questions, especially if you’re trying out something similar. If you want to see more content like this in the future, do let me know!
Footnotes
The Mishnah is one of the core and earliest rabbinic works which serves as the basis for the Talmud.
The licenses for the texts differ and are detailed in the corresponding JSON files within the repository. The Hebrew texts used in this project are in the public domain. The English translations are from the Mishnah Yomit translation by Dr. Joshua Kulp and are licensed under a CC-BY license.
Shlomo Tannor is an AI/ML engineer at Avanan (A Check Point Company), specializing in leveraging NLP and ML to enhance cloud email security. He holds an MSc in Computer Science with a thesis in NLP and a BSc in Mathematics and Computer Science.
This blog post is an updated version of part of a conference talk I gave at GOTO Amsterdam last year. The talk is also available to watch online.
Providing value and positive impact through machine learning product initiatives is not an easy job. One of the main reasons for this complexity is the fact that, in ML initiatives developed for digital products, two sources of uncertainty intersect. On one hand, there is the uncertainty related to the ML solution itself (will we be able to predict what we need to predict with good enough quality?). On the other hand, there is the uncertainty related to the impact the whole system will be able to provide (will users like this new functionality? will it really help solve the problem we are trying to solve?).
All this uncertainty means failure in ML product initiatives is something relatively frequent. Still, there are strategies to manage and improve the probabilities of success (or at least to survive through them with dignity!). Starting ML initiatives on the right foot is key. I discussed my top learnings in that area in a previous post: start with the problem (and define how predictions will be used from the beginning), start small (and maintain small if you can), and prioritize the right data (quality, volume, history).
However, starting a project is just the beginning. The challenge to successfully manage an ML initiative and provide a positive impact continues throughout the whole project lifecycle. In this post, I’ll share my top three learnings on how to survive and thrive during ML initiatives:
Embrace uncertainty: innovation, stopping, pivoting, and failing.
Surround yourself with the right people: roles, skills, diversity, and the network.
Learn from the data: right direction, be able to improve, and detect failures and have a plan.
Embrace uncertainty
It is really hard (impossible even!) to plan ML initiatives beforehand and to develop them according to that initial plan.
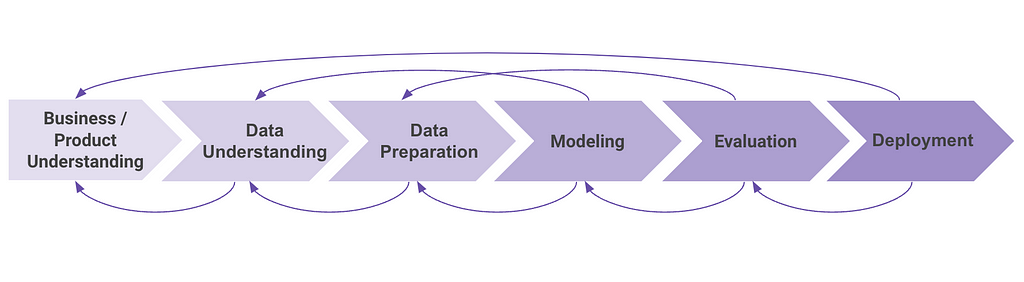
The most popular project plan for ML initiatives is the ML Lifecycle, which splits the phases of an ML project into business understanding, data understanding, data preparation, modeling, evaluation, and deployment. Although these phases are drawn as consecutive steps, in many representations of this lifecycle you’ll find arrows pointing backward: at any point in the project, you might learn something that forces you to go back to a previous phase.
The ML Lifecycle (and it’s arrows pointing backward), image by author
This translates into projects where it is really hard to know when they will finish. For example, during the evaluation step, you might realize thanks to model explainability techniques that a specific feature wasn’t well encoded, and this forces you to go back to the data preparation phase. It could also happen that the model isn’t able to predict with the quality you need, and might force you to go back to the beginning in the business understanding phase to redefine the project and business logic.
Whatever your role in an ML initiative or project is, it is key to acknowledge things won’t go according to plan, to embrace all this uncertainty from the beginning, and to use it to your advantage. This is important both to managing stakeholders (expectations, trust) and for yourself and the rest of the team (motivation, frustration). How?
Avoid too ambitious time or delivery constraints, by ensuring ML initiatives are perceived as what they really are: innovation that needs to explore the unknown and has high risk, but high reward and potential too.
Know when to stop, by balancing the value of each incremental improvement (ML models can always be improved!) with its price in terms of time, effort, and opportunity cost.
Be ready to pivot and fail, by continuously leveraging the learnings and insights the project grants you, and to decide to modify the project scope, or even to kill it if that is what those new learnings tell you.
Any project starts with people. The right combination of people, skills, perspectives, and a network that empowers you.
The days when Machine Learning (ML) models were confined to the Data Scientist’s laptop are over. Today, the true potential of ML is realised when models are deployed and integrated into the company’s processes. This means more people and skills need to collaborate to make that possible (Data Scientists, Machine Learning Engineers, Backend Developers, Data Engineers…).
The first step is identifying the skills and roles that are required to successfully build the end-to-end ML solution. However, more than a group of roles covering a list of skills is required. Having a diverse team that can bring different perspectives and empathize with different user segments has proven to help teams improve their ways of working and build better solutions (“why having a diverse team will make your products better”).
People don’t talk about this enough, but the key people to deliver a project go beyond the team itself. I refer to these other people as “the network”. The network is people you know are really good at specific things, you trust to ask for help and advice when needed, and can unblock, accelerate, or empower you and the team. The network can be your business stakeholders, manager, staff engineers, user researchers, data scientists from other teams, customer support team… Ensure you build your own network and identify who is that ally who you can go to depending on each specific situation or need.
Learn from your data
A project is a continuous learning opportunity, and many times learnings and insights come from checking the right data and monitors.
In ML initiatives there are 3 big groups of metrics and measures that can bring a lot of value in terms of learnings and insights: model performance monitoring, service performance, and final impact monitoring. In a previous post I deep dive into this topic.
Checking at the right data and monitors while developing or deploying ML solutions is key to:
Ensure moving in the right direction: this includes many things from the right design of the solution or choosing the right features, to understanding if there is a need to pivot or even stop the project.
Know what or how to improve: to understand if outcome goals were reached (e.g. through experimentation or a/b testing), and to deep dive on what went well, what didn’t, and how to continue delivering value.
Detect failure on time and have a plan: to enable quick responses to issues, ideally before they impact the business. Even if they do impact the business, having the right metrics should allow you to understand the why behind the failure, maintain things under control, and prepare a plan to move forward (while maintaining the trust of your stakeholders).
Wrapping it up
Effectively managing ML initiatives from beginning until end is a complex task with multiple dimensions. In this blogpost I shared, based on my experience first as Data Scientist and lately as ML Product Manager, the factors I consider key when dealing with an ML project: embracing uncertainty, surrounding yourself with the right people, and learning from the data.
I hope these insights help you successfully manage your ML initiatives and drive positive impact through them. Stay tuned for more posts about the intersection of Machine Learning and Product Management 🙂
As customers seek to incorporate their corpus of knowledge into their generative artificial intelligence (AI) applications, or to build domain-specific models, their data science teams often want to conduct A/B testing and have repeatable experiments. In this post, we discuss a solution that uses infrastructure as code (IaC) to define the process of retrieving and […]
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.