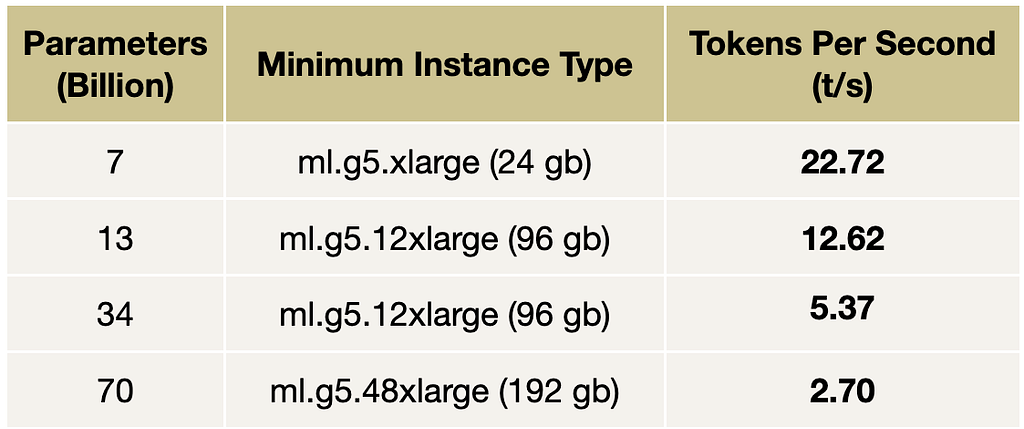
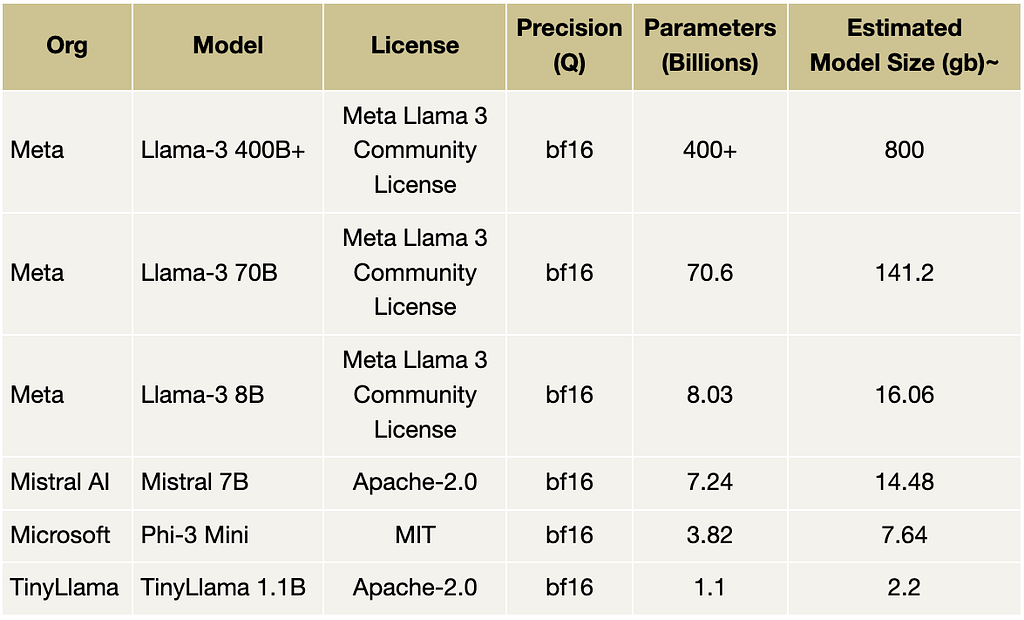
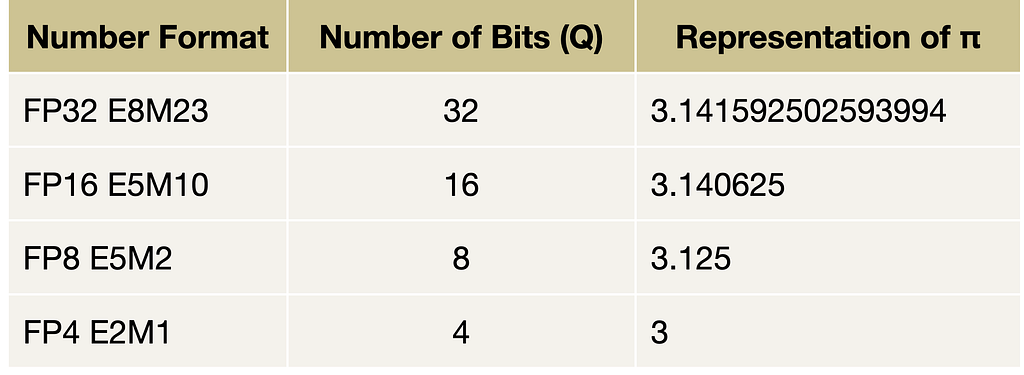
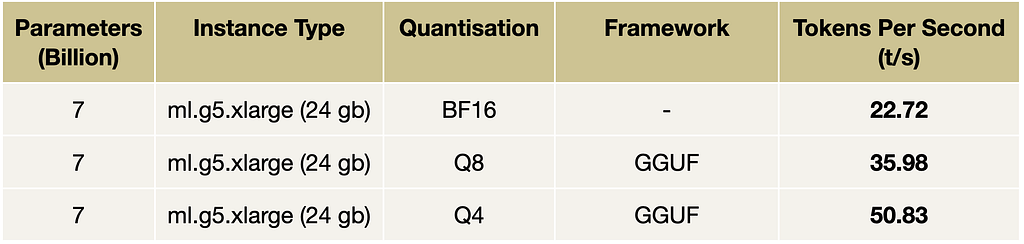
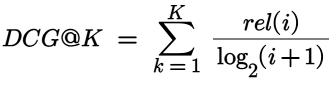Research paper in pills: “Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet”

Have you ever wondered how an AI model “thinks”? Imagine peering inside the mind of a machine and watching the gears turn. This is exactly what a groundbreaking paper from Anthropic explores. Titled “Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet”, the research delves into understanding and interpreting the thought processes of AI.
The researchers managed to extract features from the Claude 3 Sonnet model that show what it was thinking about famous people, cities, and even security vulnerabilities in software. It’s like getting a glimpse into the AI’s mind, revealing the concepts it understands and uses to make decisions.
Research Paper Overview
In the paper, the Anthropic team, including Adly Templeton, Tom Conerly, Jonathan Marcus, and others, set out to make AI models more transparent. They focused on Claude 3 Sonnet, a medium-sized AI model, and aimed to scale monosemanticity — essentially making sure that each feature in the model has a clear, single meaning.
But why is scaling monosemanticity so important? And what exactly is monosemanticity? We’ll dive into that soon.
Importance of the Study
Understanding and interpreting features in AI models is crucial. It helps us see how these models make decisions, making them more reliable and easier to improve. When we can interpret these features, debugging, refining, and optimizing AI models becomes easier.
This research also has significant implications for AI safety. By identifying features linked to harmful behaviors, such as bias, deception, or dangerous content, we can develop ways to reduce these risks. This is especially important as AI systems become more integrated into everyday life, where ethical considerations and safety are essential.
One of the key contributions of this research is showing us how to understand what a large language model (LLM) is “thinking.” By extracting and interpreting features, we can get an insight into the internal workings of these complex models. This helps us see why they make certain decisions, providing a way to peek into their “thought processes.”
Background
Let’s review some of the odd terms mentioned earlier:
Monosemanticity
Monosemanticity is like having a single, specific key for each lock in a huge building. Imagine this building represents the AI model; each lock is a feature or concept the model understands. With monosemanticity, every key (feature) fits only one lock (concept) perfectly. This means whenever a particular key is used, it always opens the same lock. This consistency helps us understand exactly what the model is thinking about when it makes decisions because we know which key opened which lock.
Sparse Autoencoders
A sparse autoencoder is like a highly efficient detective. Imagine you have a big, cluttered room (the data) with many items scattered around. The detective’s job is to find the few key items (important features) that tell the whole story of what happened in the room. The “sparse” part means this detective tries to solve the mystery using as few clues as possible, focusing only on the most essential pieces of evidence. In this research, sparse autoencoders act like this detective, helping to identify and extract clear, understandable features from the AI model, making it easier to see what’s going on inside.
Here are some useful lecture notes by Andrew Ng on Autoencoders, to learn more about them.
Previous Work
Previous research laid the foundation by exploring how to extract interpretable features from smaller AI models using sparse autoencoders. These studies showed that sparse autoencoders could effectively identify meaningful features in simpler models. However, there were significant concerns about whether this method could scale up to larger, more complex models like Claude 3 Sonnet.
The earlier studies focused on proving that sparse autoencoders could identify and represent key features in smaller models. They succeeded in showing that the extracted features were both meaningful and interpretable. However, the main limitation was that these techniques had only been tested on simpler models. Scaling up was essential because larger models like Claude 3 Sonnet handle more complex data and tasks, making it harder to maintain the same level of clarity and usefulness in the extracted features.
This research builds on those foundations by aiming to scale these methods to more advanced AI systems. The researchers applied and adapted sparse autoencoders to handle the higher complexity and dimensionality of larger models. By addressing the challenges of scaling, this study seeks to ensure that even in more complex models, the extracted features remain clear and useful, thus advancing our understanding and interpretation of AI decision-making processes.
Scaling Sparse Autoencoders
Scaling sparse autoencoders to work with a larger model like Claude 3 Sonnet is like upgrading from a small, local library to managing a vast national archive. The techniques that worked well for the smaller collection need to be adjusted to handle the sheer size and complexity of the bigger dataset.
Sparse autoencoders are designed to identify and represent key features in data while keeping the number of active features low, much like a librarian who knows exactly which few books out of thousands will answer your question.

Two key hypotheses guide this scaling:
Linear Representation Hypothesis
Imagine a giant map of the night sky, where each star represents a concept the AI understands. This hypothesis suggests that each concept (or star) aligns in a specific direction in the model’s activation space. Essentially, it’s like saying that if you draw a line through space pointing directly to a specific star, you can identify that star uniquely by its direction.
Superposition Hypothesis
Building on the night sky analogy, this hypothesis is like saying the AI can use these directions to map more stars than there are directions by using almost perpendicular lines. This allows the AI to efficiently pack information by finding unique ways to combine these directions, much like fitting more stars into the sky by carefully mapping them in different layers.
By applying these hypotheses, researchers could effectively scale sparse autoencoders to work with larger models like Claude 3 Sonnet, enabling them to capture and represent both simple and complex features in the data.
Training the Model
Imagine trying to train a group of detectives to sift through a vast library to find key pieces of evidence. This is similar to what researchers did with sparse autoencoders (SAEs) in their work with Claude 3 Sonnet, a complex AI model. They had to adapt the training techniques for these detectives to handle the larger, more complex data set represented by the Claude 3 Sonnet model.
The researchers decided to apply the SAEs to the residual stream activations in the middle layer of the model. Think of the middle layer as a crucial checkpoint in a detective’s investigation, where a lot of interesting, abstract clues are found. They chose this point because:
- Smaller Size: The residual stream is smaller than other layers, making it cheaper in terms of computational resources.
- Mitigating Cross-Layer Superposition: This refers to the problem of signals from different layers getting mixed up, like flavors blending together in a way that makes it hard to tell them apart.
- Rich in Abstract Features: The middle layer is likely to contain intriguing, high-level concepts.
The team trained three versions of the SAEs, with different capacities to handle features: 1M features, 4M features, and 34M features. For each SAE, the goal was to keep the number of active features low while maintaining accuracy:
- Active Features: On average, fewer than 300 features were active at any time, explaining at least 65% of the variance in the model’s activations.
- Dead Features: These are features that never get activated. They found roughly 2% dead features in the 1M SAE, 35% in the 4M SAE, and 65% in the 34M SAE. Future improvements aim to reduce these numbers.
Scaling Laws: Optimizing Training
The goal was to balance reconstruction accuracy with the number of active features, using a loss function that combined mean-squared error (MSE) and an L1 penalty.
Also, they applied scaling laws, which help determine how many training steps and features are optimal within a given compute budget. Essentially, scaling laws tell us that as we increase our computing resources, the number of features and training steps should increase according to a predictable pattern, often following a power law.
As they increased the compute budget, the optimal number of features and training steps scaled according to a power law.

They found that the best learning rates also followed a power law trend, helping them choose appropriate rates for larger runs.
Mathematical Foundation
The core mathematical principles behind the sparse autoencoder model are essential for understanding how it decomposes activations into interpretable features.
Encoder
The encoder transforms the input activations into a higher-dimensional space using a learned linear transformation followed by a ReLU nonlinearity. This is represented as:

Here, W^enc and b^enc are the encoder weights and biases, and fi(x) represents the activation of feature i.
Decoder
The decoder attempts to reconstruct the original activations from the features using another linear transformation:
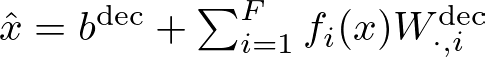
W^dec and b^dec are the decoder weights and biases. The term fi(x)W^dec represents the contribution of feature i to the reconstruction.
Loss
The model is trained to minimize a combination of reconstruction error and sparsity penalty:

This loss function ensures that the reconstruction is accurate (minimizing the L2 norm of the error) while keeping the number of active features low (enforced by the L1 regularization term with a coefficient λ).
Interpretable Features
The research revealed a wide variety of interpretable features within the Claude 3 Sonnet model, encompassing both abstract and concrete concepts. These features provide insights into the model’s internal processes and decision-making patterns.
Abstract Features: These include high-level concepts that the model understands and uses to process information. Examples are themes like emotions, intentions, and broader categories such as science or technology.
Concrete Features: These are more specific and tangible, such as names of famous people, geographical locations, or particular objects. These features can be directly linked to identifiable real-world entities.
For instance, the model has features that activate in response to mentions of well-known individuals. There might be a feature specifically for “Albert Einstein” that activates whenever the text refers to him or his work in physics. This feature helps the model make connections and generate contextually relevant information about Einstein.

Similarly, there are features that respond to references to cities, countries, and other geographical entities. For example, a feature for “Paris” might activate when the text talks about the Eiffel Tower, French culture, or events happening in the city. This helps the model understand and contextualize discussions about these places.
The model can also identify and activate features related to security vulnerabilities in code or systems. For example, there might be a feature that recognizes mentions of “buffer overflow” or “SQL injection,” which are common security issues in software development. This capability is crucial for applications involving cybersecurity, as it allows the model to detect and highlight potential risks.
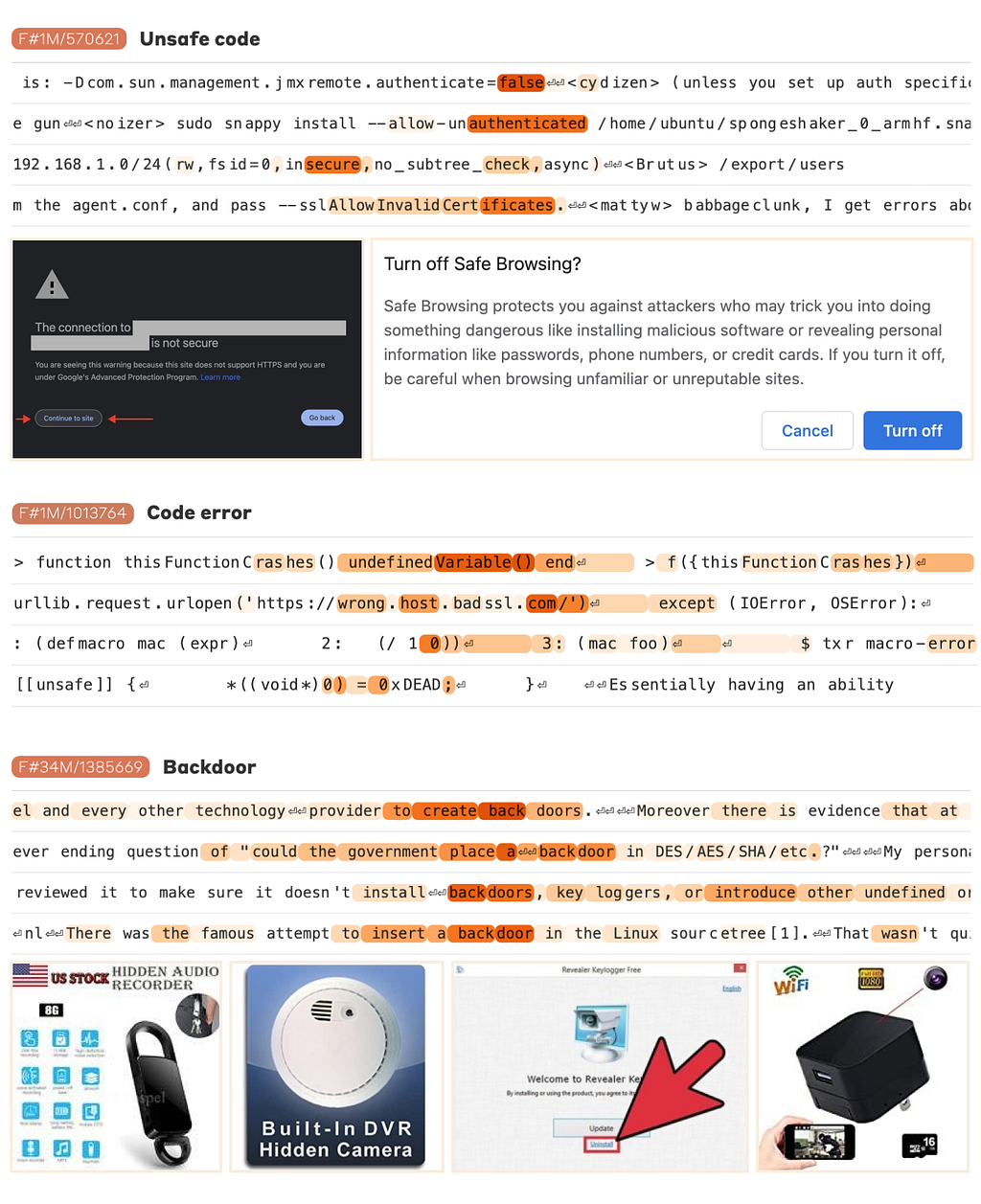
Features related to biases were also identified, including those that detect racial, gender, or other forms of prejudice. By understanding these features, developers can work to mitigate biased outputs, ensuring that the AI behaves more fairly and equitably.

These interpretable features demonstrate the model’s ability to capture and utilize both specific and broad concepts. By understanding these features, researchers can better grasp how Claude 3 Sonnet processes information, making the model’s actions more transparent and predictable. This understanding is vital for improving AI reliability, safety, and alignment with human values.
Conclusion
This research has made significant strides in understanding and interpreting the internal workings of the Claude 3 Sonnet model.
The study successfully extracted both abstract and concrete features from Claude 3 Sonnet, making the AI’s decision-making process more transparent. Examples include features for famous people, cities, and security vulnerabilities.
The research identified features related to AI safety, such as detecting security vulnerabilities, biases, and deceptive behaviors. Understanding these features is crucial for developing safer and more reliable AI systems.
The importance of interpretable AI features cannot be overstated. They enhance our ability to debug, refine, and optimize AI models, leading to better performance and reliability. Moreover, they are essential for ensuring AI systems operate transparently and align with human values, particularly in areas of safety and ethics.
References
- Anthropic. Adly Templeton et al. “Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet.” Anthropic Research, 2024.
- Ng, Andrew. “Autoencoders: Overview and Applications.” Lecture Notes, Stanford University.
- Anthropic. “Core Views on AI Safety.” Anthropic Safety Guidelines, 2024.
How LLMs Think was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How LLMs Think