Creating a scalable testing solution for AI agents for operation by non-coders
Langfuse is a useful tool for flexible testing of AI Agents. Recently, we set out to implement a framework for testing chat-based AI Agents. The following is an account of our journey to navigate the available tools.
We’ll focus mostly on how to accomplish this task now, but at the end we’ll address some thoughts on the challenges still facing us, and what the tools at hand can do to better support this sort of use case moving forward.
Use Case Overview
Before reviewing how we built our system, we’ll quickly go into our goals and success criteria.
Generative AI use cases are generally easy to deploy but difficult to control. When deploying an agent with a large-context model, upstream changes in model prompts, temperature settings, content moderation policy, etc., can drastically impact its performance.
The challenge is to create a system that can evaluate an agent’s ability to accomplish specific tasks without hallucinating or breaking content policy. We equate this to unit testing, ensuring that your agent maintains its ability to accomplish a broad list of tasks, even when the team behind may be focusing on specific improvements. Doing this sort of testing manually can be imprecise, time-consuming, and difficult to track.
So, we set out to create a system that could easily create these tests and monitor their results. Importantly, we wanted this system to be operable with a minimum frequency of required code changes so that a Product Manager or QA tester might contribute to it without having to touch code.
Why we chose Langfuse
We set out with a few key parameters for our search:
HIPAA Compliance, as both the products we build and many of our consulting partners are in the healthcare space.
Low-Cost, both to stand up and to operate, since we operate fairly lean, as do our partners.
Developmental Momentum. The LLM observability space is rapidly evolving. From the outset of our search, we were prepared to be wrong, but we wanted to minimize this chance by picking a tool that was likely to evolve with us.
Custom LLM Evaluation Capability. The ability to stand up & run a custom evaluator was surprisingly something we didn’t find easily supported amongst all of the options we found, particularly amongst open-source options.
To simplify our search, we identified the following players in both the enterprise & open-source categories which appeared to meet our criteria, listed here in rough rank order.
Enterprise
Open Source
We chose Langfuse primarily because it is easy to self-deploy without interacting with an enterprise sales team and because we believe It has the critical features we require. This has, so far, turned out to be correct.
Deployment
We found the deployment process, overall, to be relatively simple. Langfuse provides an easy-to-use docker image and solid documentation on how to deploy locally. Building a YAML file and deploying to EKS was straightforward, and we had a demo instance up and running within a couple of hours. We did not set up SSO for our POC, so we were using the basic user management provided out of the box (not much) and relying on anonymized data to meet security requirements. A free-tier PG database on RDS could handle many queries, evals, and prompt management for multiple users. The application is very lightweight. A few issues we did run into:
- There is no way to get a list of prompts in the SDK programmatically. This meant that when we were putting together various system prompts or unit testing chats, we had to store prompt names in the configs of whatever entry point we used for a particular use-case (e.g., a list of unit tests in the system prompt for an agent)
- We didn’t find a way to get a list of variables in prompts for use in compilation. We were using different variables for different system prompts we’d pull in and had to either hard-code which bits of data would get compiled into each or do some trial and error.
- Observations were not well documented. When logging scores into Langfuse, we saw that you could add an observationId, but the generally good docs did not provide additional context. We will likely use them in the future once we figure out all the possibilities they enable
A No-Code Unit Testing Framework
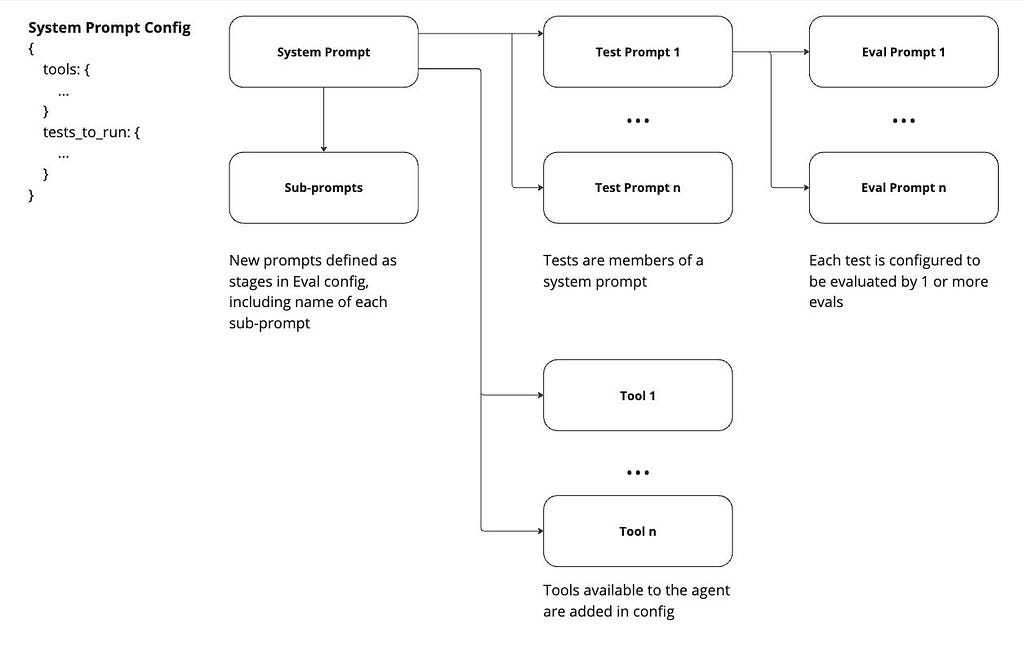
A diagram of how we used System Prompt configs to create a central, no-code testing system in Langfuse
With a couple weeks of work, we’ve set up a system of end-to-end testing. Langfuse offers more functionality than we’ve utilized thus far, but we’ve focused on using prompts, sessions, & traces.
Chat history as context to testing
One key requirement we had in performing testing on a chat-based agent was the ability to drop an agent into the middle of a chat scenario, using the prior messages exchanged as context. Any custom prompt could be made to include chat history, but Langfuse makes it particularly easy.
Furthermore, we built a chat interface for the agent that allows users to test and spawn new test prompts in situ for evaluations. This solves one of the
potential problems with injecting prompts as context, the chats must represent actual outputs the model might create.
This creates a potential vulnerability: The chat histories we’re using as context must be refreshed if the model’s underlying behavior changes. That said, we see this method as more controllable and consistent than potential alternatives, such as having one agent interact with another — something that we’re going to explore as another addition to this sort of system.
No-code test creation & test run management
The other key challenge we addressed was how to create an entire test suite without requiring code. First, to define a test set, we created a config object in the system prompt for the agent, which defined the list of tests to be run against it.
This also allowed us to pass in the system prompt as a variable when running a suite of tests. One of the primary benefits of a system like Langfuse is its ability to enable prompt management-as-code in its UI. To that end, follow-up system prompts that may get injected into the system are also linked to the system prompt in config, allowing us to force the underlying model into specific states during testing while hardening the system against changes to either the primary or follow-on system prompts.
By managing the list of tests to be run as configs in the system prompt, we require code change only once per agent. The list of tests to be run can be changed and expanded within the Langfuse UI.
Each test prompt is linked to its evaluator as part of its config. Each test prompt has at least 1 custom eval running against it, with prompts that all roughly follow this template:a helpful AI evaluator who will provide feedback and scoring on the task below.
You are a helpful AI evaluator who will provide feedback and scoring on the task below.
[Describe the scenario and how the agent has been instructed to behave in said scenario]
Based on the transcript output, you will determine whether this task was successfully completed. You will return a JSON object in the following form:
-------------
Example outputs:
{"score": -1, "comment": [Description of an example negative case}
{“score”: 1, “comment”: [Description of an example positive case]}
------------
In this object, score is a number between -1 and 1, with 1 indicating complete success and a -1 indicating complete failure. The comment is a string indicating your reasoning for the score.
-------------
BEGIN TRANSCRIPT:
{{transcript}}
END TRANSCRIPT
--------------
Do not return any output except the JSON object referenced above.
Using this System
We see this tests & eval framework as a reasonable set of compromises to create a low-cost, easy-to-operate system. We see its primary applications as part of a CI/CD pipeline, ensuring that or as the source of a quick scorecard for someone looking to tweak a system’s prompts who wants more thorough input than they can get through manual testing.
Based on the models underpinning the agent and your evaluators, token utilization can mean that a full test suite run, which in our case can easily contain dozens of test prompts & evaluators, can cost in the tens of dollars.
One way to control the cost of running a system like this as a means of iterating on prompts & tools, particularly when making large numbers of changes in an attempt to iteratively improve performance, is to start with a smaller model, measuring relative performance, and stepping up testing to larger models only when you find an encouraging result.
Langfuse Impressions
Overall, we’re happy with our decision to use Langfuse. With a reasonably small amount of work, we could deploy something that fit our needs. The system was flexible enough to allow us to customize the system to suit our use case relatively quickly.
We have noticed a few shortcomings that we hope will be addressed with future development:
The Langfuse UX lacks some polish, which would significantly increase the quality of life for its users. Examples include the inability to duplicate a prompt and the inability to search available prompts by any parameter other than their name.
The self-hosted option doesn’t allow you to trigger new test runs from within the UI, meaning that someone operating the system needs to do so through the command line or another UI developed for this purpose.
We understand that this environment is rapidly evolving, but we believe that this rough framework is reasonably portable, should we ultimately decide to implement it in another system.
Future Innovation Potential
AI-generated test prompt variants
One way to increase our test coverage would be to create variants of our existing test prompts. Tools such as TestGen-LLM are emerging in the space, but overall, the space of using GenAI to test GenAI is young. Since these payloads are essentially JSON objects, it is certainly possible to instruct an LLM to create variants. The question, then, is how to control the quality of those variants so that they still represent valid tests.
Using Datasets
Langfuse datasets are an interesting tool feature, allowing users to link particular portions of traces as inputs and expected outputs of a model. While we could have used something like this in our unit testing, we found it simpler to create chat prompts as inputs and generally describe what we were looking for in evaluation prompts rather than make an “expected output” to be used in a dataset evaluation. We believe datasets are the clear way to go for tests that can be evaluated in code (e.g., did the chatbot return the correct year when asked? Did the chatbot return functional JSON?). We may use them in the future for more general testing, but we found it faster to spin up new tests by creating the prompts separately.
Thanks for reading! I’m Jack Moore, Founder and CEO of Auril.ai. This post was first published on our tech blog, where we’ll be exploring topics relevant to taking Generative AI from conceptual intrigue to productionalized value.
All views are our own. We have no affiliation or partnership with Langfuse
Unless otherwise noted, all images are by the author
AI Agent Unit Testing in Langfuse was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
AI Agent Unit Testing in Langfuse
Go Here to Read this Fast! AI Agent Unit Testing in Langfuse