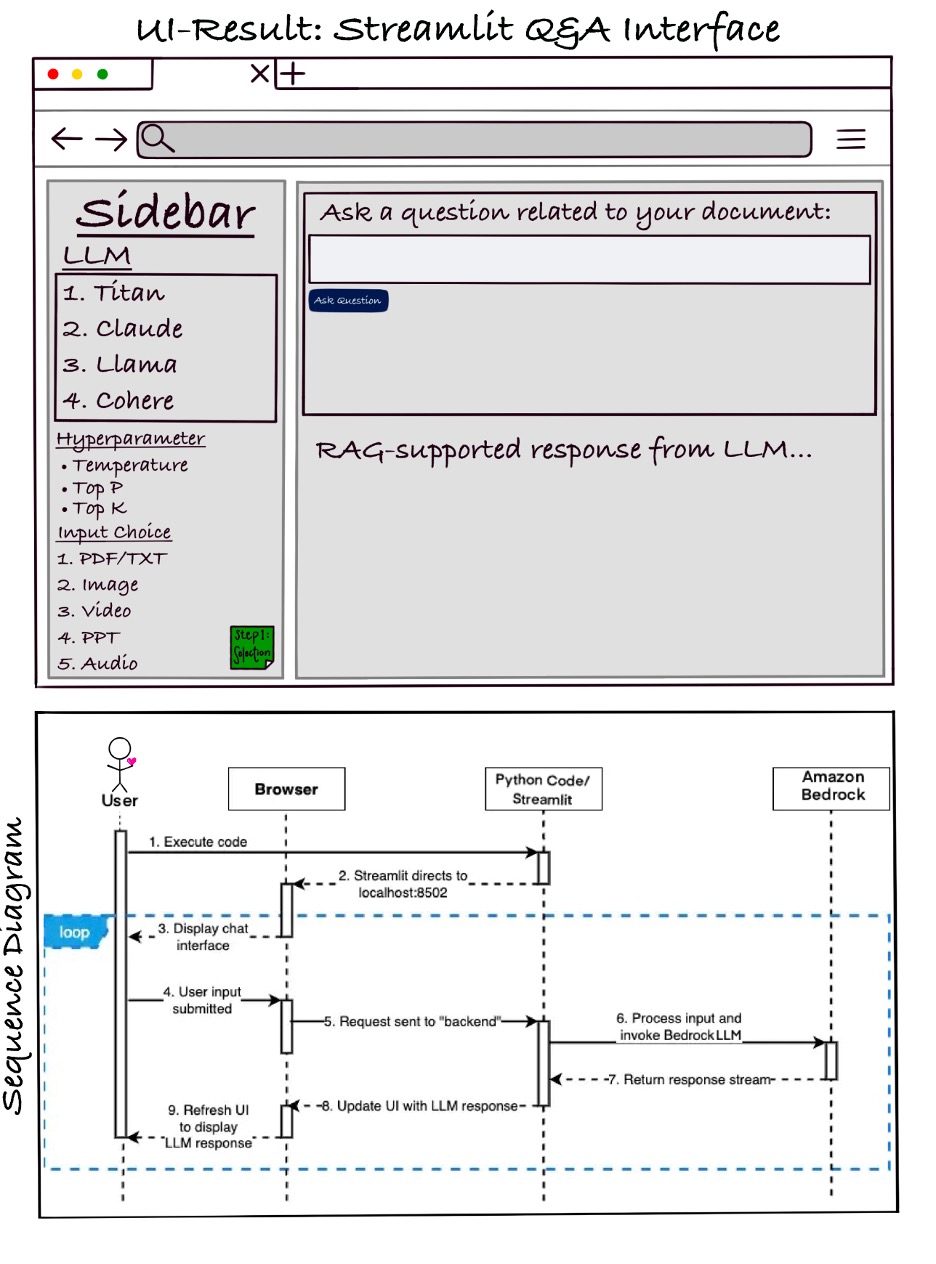
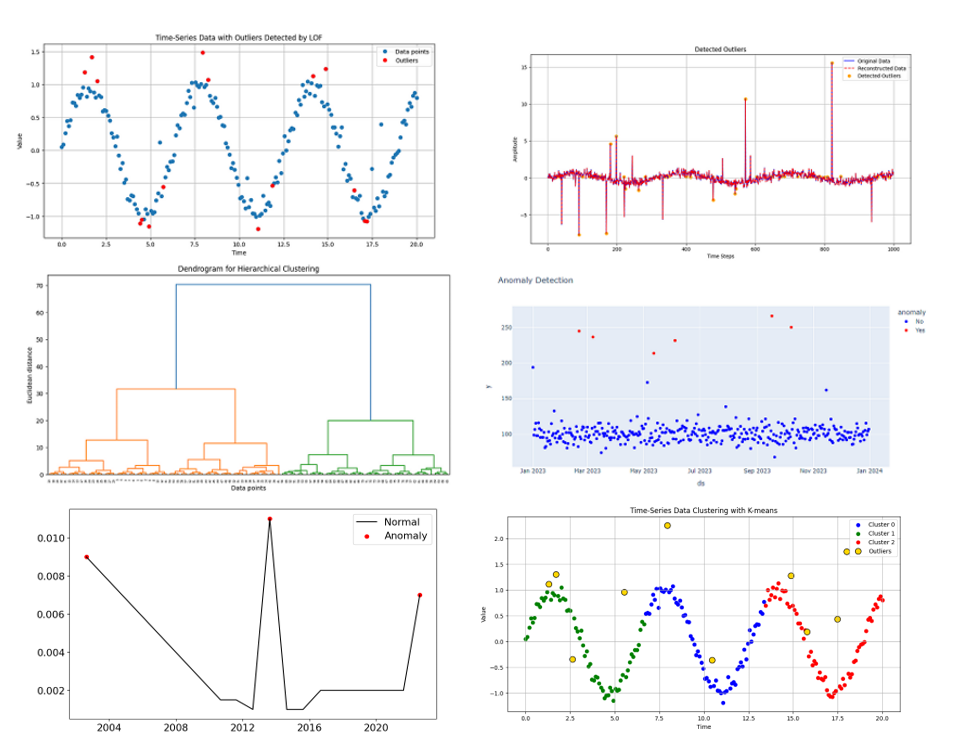
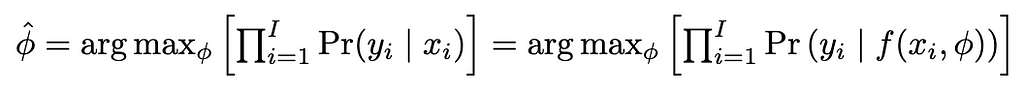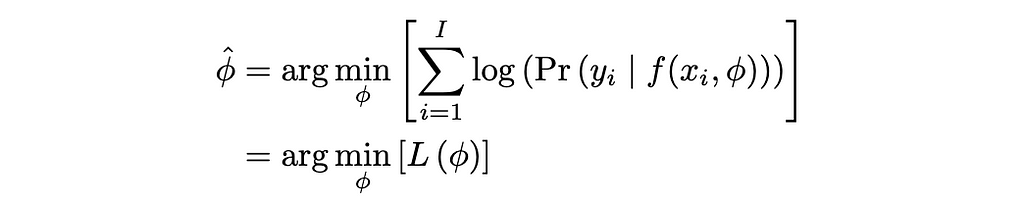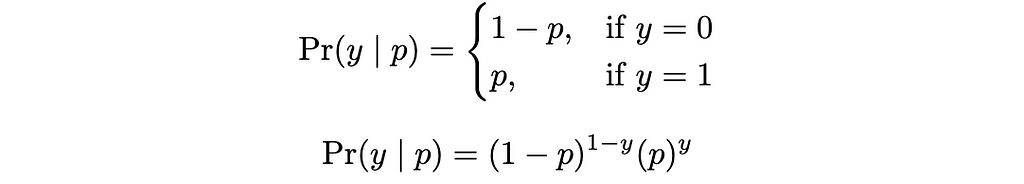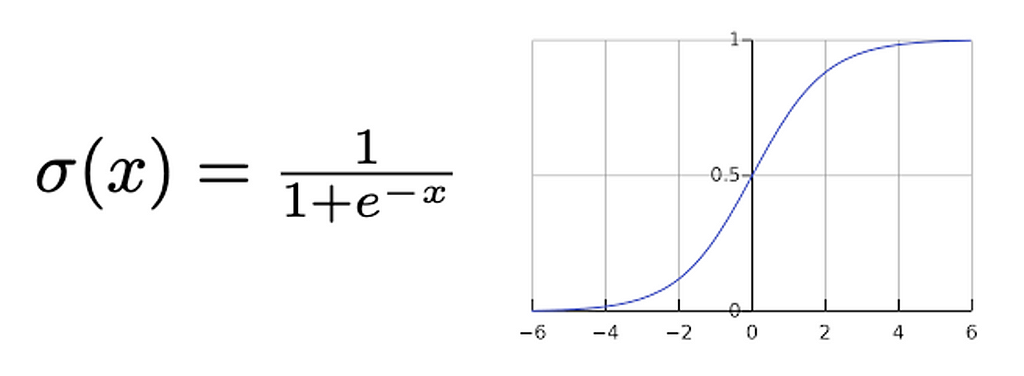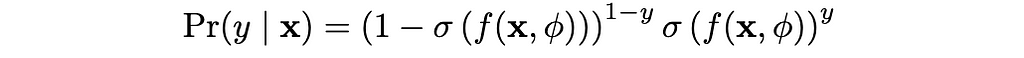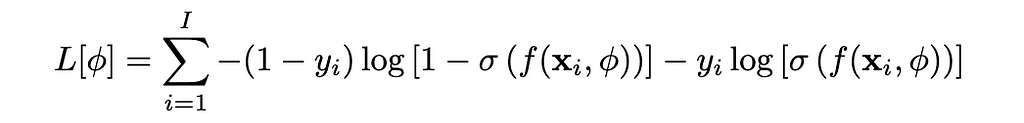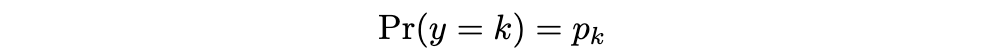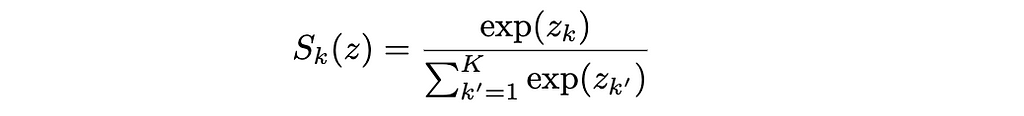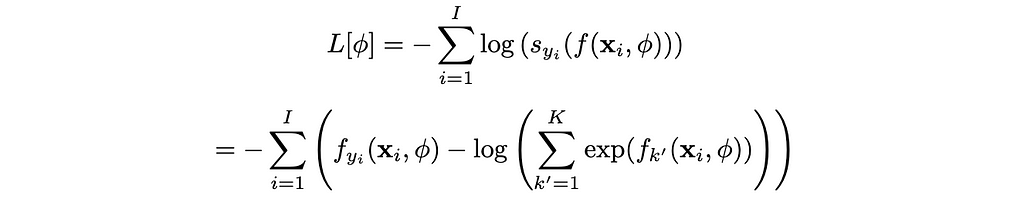With the advent of generative artificial intelligence (AI), foundation models (FMs) can generate content such as answering questions, summarizing text, and providing highlights from the sourced document. However, for model selection, there is a wide choice from model providers, like Amazon, Anthropic, AI21 Labs, Cohere, and Meta, coupled with discrete real-world data formats in PDF, […]
When prompt engineering first emerged as a mainstream workflow for data and machine learning professionals, it seemed to generate two common (and somewhat opposing) views.
In the wake of ChatGPT’s splashy arrival, some commentators declared it an essential task that would soon take over entire product and ML teams; six-figure job postings for prompt engineers soon followed. At the same time, skeptics argued that it was not much more than an intermediary approach to fill in the gaps in LLMs’ current abilities, and as models’ performance improves, the need for specialized prompting knowledge would dissipate.
Almost two years later, both camps seem to have made valid points. Prompt engineering is still very much with us; it continues to evolve as a practice, with a growing number of tools and techniques that support practitioners’ interactions with powerful models. It’s also clear, however, that as the ecosystem matures, optimizing prompts might become not so much a specialized skill as a mode of thinking and problem-solving integrated into a wide spectrum of professional activities.
To help you gauge the current state of prompt engineering, catch up with the latest approaches, and look into the field’s future, we’ve gathered some of our strongest recent articles on the topic. Enjoy your reading!
Introduction to Domain Adaptation — Motivation, Options, Tradeoffs For anyone taking their first steps working hands-on with LLMs, Aris Tsakpinis’s three-part series is a great place to start exploring the different approaches for making these massive, unwieldy, and occasionally unpredictable models produce dependable results. The first part, in particular, does a great job introducing prompt engineering: why it’s needed, how it works, and what tradeoffs it forces us to consider.
I Took a Certification in AI. Here’s What It Taught Me About Prompt Engineering. “Prompt engineering is a simple concept. It’s just a way of asking the LLM to complete a task by providing it with instructions.” Writing from the perspective of a seasoned software developer who wants to stay up-to-date with the latest industry trends, Kory Becker walks us through the experience of branching out into the sometimes-counterintuitive ways humans and models interact.
Automating Prompt Engineering with DSPy and Haystack Many ML professionals who’ve already tinkered with prompting quickly realize that there’s a lot of room for streamlining and optimization when it comes to prompt design and execution. Maria Mestre recently shared a clear, step-by-step tutorial—focused on the open-source DSPy framework—for anyone who’d like to automate major chunks of this workflow.
Understanding Techniques for Solving GenAI Challenges We tend to focus on the nitty-gritty implementation aspects of prompt engineering, but just like other LLM-optimization techniques, it also raises a whole set of questions for product and business stakeholders. Tula Masterman’s new article is a handy overview that does a great job offering “guidance on when to consider different approaches and how to combine them for the best outcomes.”
Streamline Your Prompts to Decrease LLM Costs and Latency Once you’ve established a functional prompt-engineering system, you can start focusing on ways to make it more efficient and resource-conscious. For actionable advice on moving in that direction, don’t miss Jan Majewski’s five tips for optimizing token usage in your prompts (but without sacrificing accuracy).
From Prompt Engineering to Agent Engineering For an incisive reflection on where the field might be headed in the near future, we hope you check out Giuseppe Scalamogna’s high-level analysis: “it seems necessary to begin transitioning from prompt engineering to something broader, a.k.a. agent engineering, and establishing the appropriate frameworks, methodologies, and mental models to design them effectively.”
Ready to branch out into some other topics this week? Here are several standout articles well worth your time:
Payal Patel invites us to explore the open-source LIDA library, which brings together the power of LLMs and the ability to generate data visualizations, and offers hands-on guidance on how to get started.
Rebounding from job loss is about much more than learning new skills or going through the motions of submitting your resume. Amy Mashares a several helpful insights and learnings from the year she spent between jobs.
Thank you for supporting the work of our authors! We love publishing articles from new authors, so if you’ve recently written an interesting project walkthrough, tutorial, or theoretical reflection on any of our core topics, don’t hesitate to share it with us.
A simpler way to understand derivations of loss functions for classification and when/how to apply them in PyTorch
Source: GPT4o Generated
Whether you are new to exploring neural networks or a seasoned pro, this should be a beneficial read to gain more intuition about loss functions. As someone testing many different loss functions during model training, I would get tripped up on small details between functions. I spent hours researching an intuitive depiction of loss functions from textbooks, research papers, and videos. I wanted to share not only the derivations that helped me grasp the concepts, but common pitfalls and use cases for classification in PyTorch.
Terminology
Before we get started, we need to define some basic terms I will be using.
Training dataset: {xᵢ, yᵢ}
Loss function: L[φ]
Model prediction output f[xᵢ, φ] with parameters φ
Conditional probability: Pr(y|x)
Parametric distribution: Pr(y|ω) with ω representing network parameters for distribution over y
Introduction
Let’s first go back to the basics. A common thought is that neural networks compute a scalar output from the model f[xᵢ, φ]. However, most neural networks these days are trained to predict parameters of a distribution y. (as oppose to to predicted the value of y).
In reality, a network will output a conditional probability distribution Pr(y|x) over possible outputs y. In other words, every input data point will lead to a probability distribution generated for each output. The network wants to learn the parameters for the probability distribution and then use the parameters and distribution to predict the output.
The traditional definition of a loss function is a function that compares target and predicted outputs. But we just said a network raw output is a distribution instead of a scalar output, so how is this possible?
Thinking about this from the view we just defined, a loss function pushes each yᵢ to have a higher probability in the distribution Pr(yᵢ|xᵢ). The key part to remember is that our distribution is being used to predict the true output based on parameters from our model output. Instead of using our input xᵢ for the distribution, we can think of a parametric distribution Pr(y|ω) where ω represents probability distribution parameters. We are still considering the input, but there will be a different ωᵢ = f[xᵢ, φ] for each xᵢ.
Note: To clarify a confusing concept, φrepresents the model parameters and ω represents the probability distribution parameters
Deriving Negative Log-Likelihood Loss
Going back to the traditional definition of a loss function, we need to get an output we can use from the model. From our probability distribution, it seems logical to take φ that produces the greatest probability for each xᵢ. Thus, we need the overall φ that produces the greatest probability across all training points I (all derivations are adapted from Understanding Deep Learning [1]):
Maximizing parameters from output model probability distributions [1]
We multiply the generated probabilities from each distribution to find φ that produces the maximum probability (called max likelihood). In order to do this, we must assume the data is independent and identically distributed. But now we run into a problem: what if the probabilities are very small? Our multiplication output will approach 0 (similar to a vanishing gradient issue). Furthermore, our program may not be able to process such small numbers.
To fix this, we bring in a logarithmicfunction! Utilizing the properties of logs, we can add together our probabilities instead of multiplying them. We know that the logarithm is a monotonically increasing function, so our original output is preserved and scaled by the log.
Using logarithms to add probabilities [1]
The last thing we need to get our traditional negative log-likelihood is to minimize the output. We are currently maximizing the output, so simply multiply by a negative and take the minimum argument (think about some graphical examples to convince yourself of this):
Negative Log-Likelihood [1]
Just by visualizing the model output as a probability distribution, attempting to maximize φ that creates the max probability, and applying a log, we have derived negative log-likelihood loss! This can be applied to many tasks by choosing a logical probability distribution. Common classification examples are shown below.
If you are wondering how a scalar output is generated from the model during inference, it’s just the max of the distribution:
Generating an output from inference [1]
Note: This is just a derivation of negative log-likelihood. In practice, there will most likely be regularization present in the loss function too.
Loss for Classification
Up to this point, we derived negative log-likelihood. Important to know, but it can be found in most textbooks or online resources. Now, let’s apply this to classification to understand it’s application.
Side note: If you are interested in seeing this applied to regression, Understanding Deep Learning [1] has great examples with univariate regression and a Gaussian Distribution to derive Mean Squared Error
Binary Classification
The goal of binary classification is to assign an input x to one of two class labels y ∈ {0, 1}. We are going to use the Bernoulli distribution as our probability distribution of choice.
Mathematical Representation of Bernoulli Distribution. Image by Author
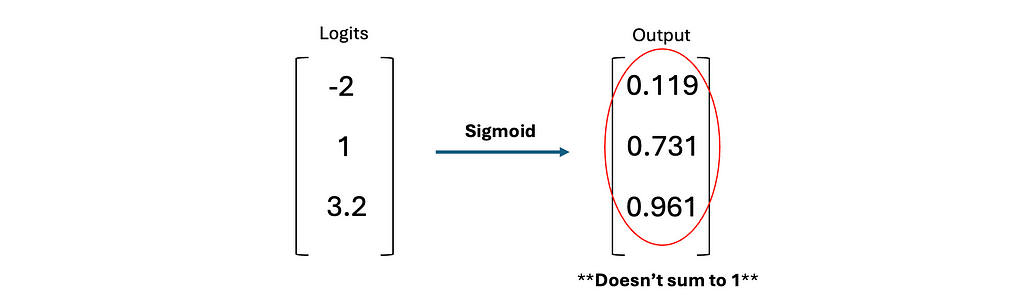
This is just a fancy way of saying the probability that the output is true, but the equation is necessary to derive our loss function. We need the model f[x, φ] to output p to generate the predicted output probability. However, before we can input p into Bernoulli, we need it to be between 0 and 1 (so it’s a probability). The function of choice for this is a sigmoid: σ(z)
A sigmoid will compress the output p to between 0 and 1. Therefore our input to Bernoulli will be p = σ(f[x, φ]). This makes our probability distribution:
New Probability Distribution with Sigmoid and Bernoulli. Image by Author
Going back to negative log-likehood, we get the following:
Binary Cross Entropy. Image by Author
Look familiar? This is the binary cross entropy (BCE) loss function! The main intuition with this is understanding why a sigmoid is used. We have a scalar output and it needs to be scaled to between 0 and 1. There are other functions capable of this, but the sigmoid is the most commonly used.
BCE in PyTorch
When implementing BCE in PyTorch, there are a few tricks to watch out for. There are two different BCE functions in PyTorch: BCELoss() and BCEWithLogitsLoss(). A common mistake (that I have made) is incorrectly swapping the use cases.
BCELoss(): This torch function outputs the loss WITH THE SIGMOID APPLIED. The output will be a probability.
BCEWithLogitsLoss(): The torch function outputs logits which are the raw outputs of the model. There is NO SIGMOID APPLIED. When using this, you will need to apply a torch.sigmoid() to the output.
This is especially important for Transfer Learning as the model even if you know the model is trained with BCE, make sure to use the right one. If not, you make accidentally apply a sigmoid after BCELoss() causing the network to not learn…
Once a probability is calculated using either function, it needs to be interpreted during inference. The probability is the model’s prediction of the likelihood of being true (class label of 1). Thresholding is needed to determine the cutoff probability of a true label. p = 0.5 is commonly used, but it’s important to test out and optimize different threshold probabilities. A good idea is to plot a histogram of output probabilities to see the confidence of outputs before deciding on a threshold.
Multiclass Classification
The goal of multiclass classification is to assign an input x to one of K > 2 class labels y ∈ {1, 2, …, K}. We are going to use the categorical distribution as our probability distribution of choice.
Categorical Distribution. Image by Author
This is just assigning a probability for each class for a given output and all probabilities must sum to 1. We need the model f[x, φ] to output p to generate the predicted output probability. The sum issue arises as in binary classification. Before we can input p into Bernoulli, we need it to be a probability between 0 and 1. A sigmoid will no longer work as it will scale each class score to a probability, but there is no guarantee all probabilities will sum to 1. This may not immediately be apparent, but an example is shown:
Sigmoid does not generate probability distribution in multiclass classification. Image by Author
We need a function that can ensure both constraints. For this, a softmax is chosen. A softmax is an extension of a sigmoid, but it will ensure all the probabilities sum to 1.
Softmax Function. Image by Author
This means the probability distribution is a softmax applied to the model output. The likelihood of calculating a label k: Pr(y = k|x) = Sₖ(f[x, φ]).
To derive the loss function for multiclass classification, we can plug the softmax and model output into the negative log-likelihood loss:
Multiclass Cross Entropy. Image by Author
This is the derivation for multiclass cross entropy. It is important to remember the only term contributing to the loss function is the probability of the true class. If you have seen cross entropy, you are more familiar with a function with a p(x) and q(x). This is identical to the cross entropy loss equation shown where p(x) = 1 for the true class and 0 for all other classes. q(x) is the softmax of the model output. The other derivation of cross entropy comes from using KL Divergence, and you can reach the same loss function by treating one term as a Dirac-delta function where true outputs exist and the other term as the model output with softmax. It is important to note that both routes lead to the same loss function.
Cross Entropy in PyTorch
Unlike binary cross entropy, there is only one loss function for cross entropy in PyTorch. nn.CrossEntropyLoss returns the model output with the softmax already applied. Inference can be performed by taking the largest probability softmax model output (taking the highest probability as would be expected).
Applications
These were two well studied classification examples. For a more complex task, it may take some time to decide on a loss function and probability distribution. There are a lot of charts matching probability distributions with intended tasks, but there is always room to explore.
For certain tasks, it may be helpful to combine loss functions. A common use case for this is in a classification task where it maybe helpful to combine a [binary] cross entropy loss with a modified Dice coefficient loss. Most of the time, the loss functions will be added together and scaled by some hyperparameter to control each individual functions contribution to loss.
Hopefully this derivation of negative log-likelihood loss and its applications proved to be useful!
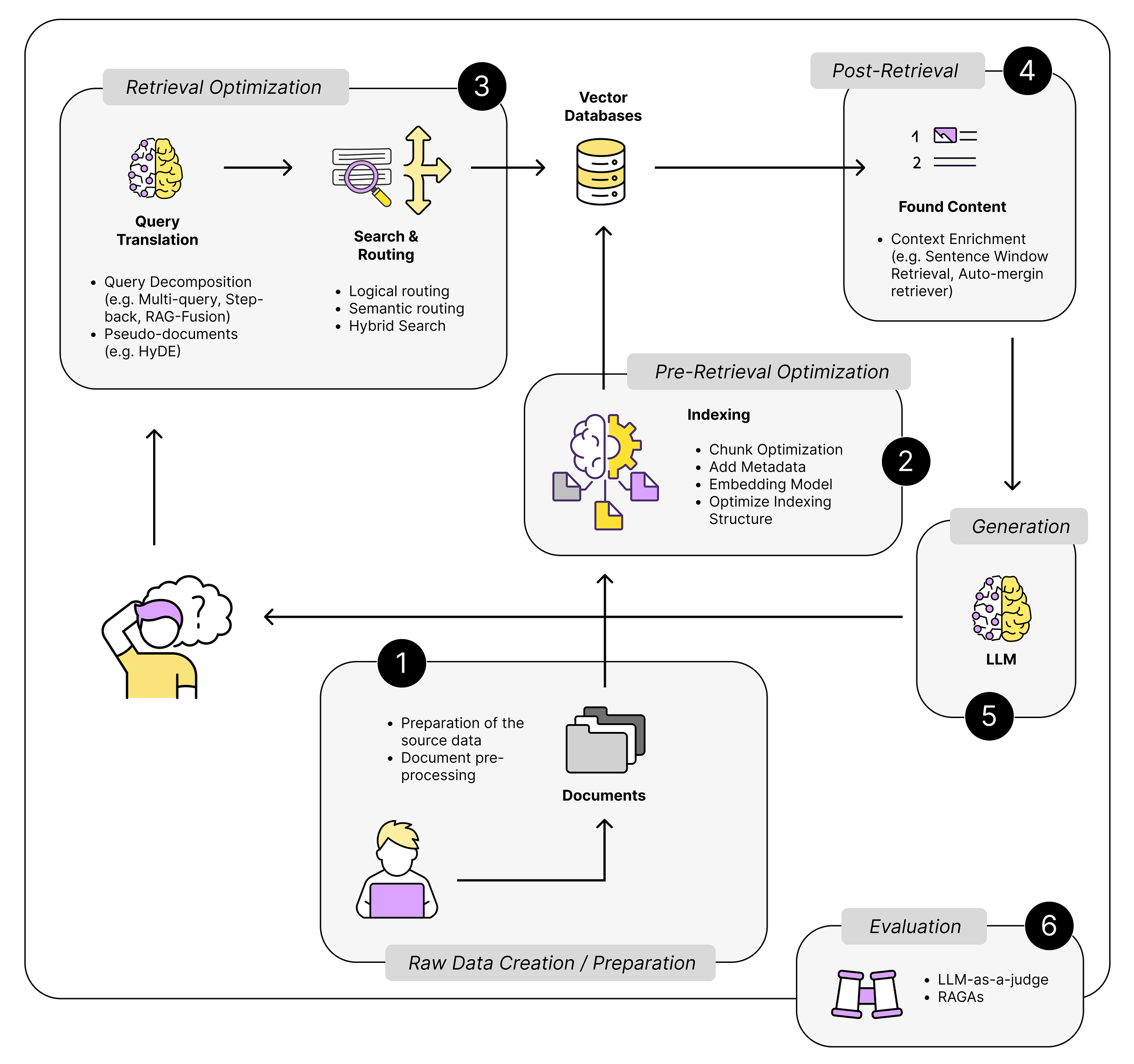
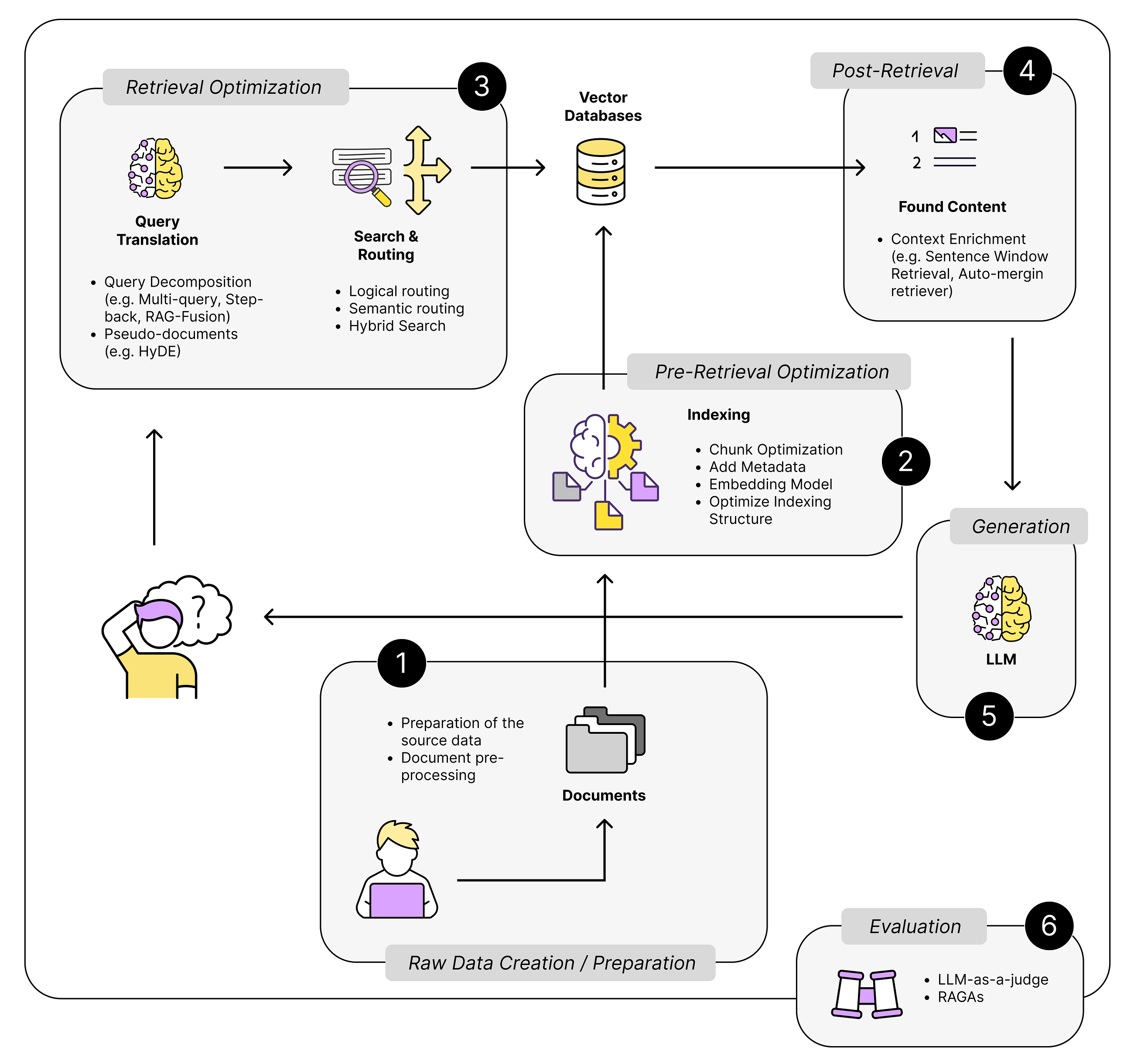
In this post, we show how you can automate and intelligently process derivative confirms at scale using AWS AI services. The solution combines Amazon Textract, a fully managed ML service to effortlessly extract text, handwriting, and data from scanned documents, and AWS Serverless technologies, a suite of fully managed event-driven services for running code, managing data, and integrating applications, all without managing servers.
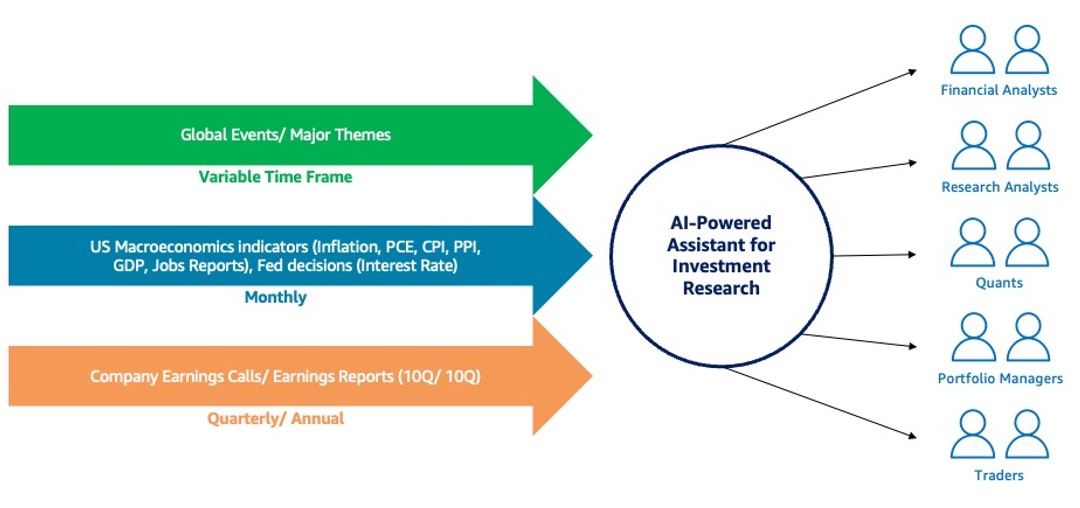
This post is a follow-up to Generative AI and multi-modal agents in AWS: The key to unlocking new value in financial markets. This blog is part of the series, Generative AI and AI/ML in Capital Markets and Financial Services. Financial analysts and research analysts in capital markets distill business insights from financial and non-financial data, […]
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.