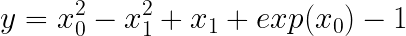LLM Alignment: Reward-Based vs Reward-Free Methods
Optimization methods for LLM alignment
Context
Language models have demonstrated remarkable abilities in producing a wide range of compelling text based on prompts provided by users. However, defining what constitutes “good” text is challenging, as it often depends on personal preferences and the specific context. For instance, in storytelling, creativity is key; in crafting informative content, accuracy and reliability are crucial; and when generating code, ensuring it runs correctly is essential. Hence the “LLM alignment problem,” which refers to the challenge of ensuring that large language models (LLMs) act in ways that are consistent with human values, intentions, and preferences.
Designing a loss function that captures the diverse qualities we value in text — like creativity, accuracy, or executability — is highly complex and often impractical. Concepts like these are not differentiable and hence not back-propagated and cannot be trained upon with simple next token generation.
Imagine if we could harness human feedback to evaluate the quality of generated text or, even better, use that feedback as a guiding loss function to improve the model’s performance. This concept is at the heart of Reinforcement Learning from Human Feedback (RLHF). By applying reinforcement learning techniques, RLHF allows us to fine-tune language models based on direct human feedback, aligning the models more closely with nuanced human values and expectations. This approach has opened up new possibilities for training language models that are not only more responsive but also more aligned with the complexity of human preferences.
Below, we will aim to learn more about RLHF via reward-based and then about RLHF via reward-free methods.
What is Reinforcement learning through human feedback (RLHF) via a reward-based system?
Let’s go through Reinforcement learning through human feedback (RLHF). It consist of 3 main stages:
- Supervised fine tuning
- Reward modeling phase
- RL fine-tuning phase
Supervised fine tuning
RLHF is a pre-trained model which is fine tuned already on a high quality data set. Its objective is simple i.e. when given an input (prompt), it produces an output. The ultimate objective here is to further fine tune this model to produce output according to human preference. Hence, let’s call this a base model for reference. Currently, this model is a vanilla base model which is not aware of any human preference.
Reward Modelling Phase
Reward model innovation: This is where the new innovation begins on how reward models are incorporated into RLHF. The idea behind the reward model is that a new LLM model, which can be same as the above mentioned base model, will have the ability to generate human preference score. The reason it is similar to a large language model is because this model also needs to understand the language semantics before it can rate if an output is human preferred or not. Since the reward is scalar, we add a linear layer on top of LLM to generate a scalar score in terms of human preference.
Data collection phase: This is done from the supervised fine tuning stage where the base model is asked to generate 2 outputs for a given text. Example: For an input token x, two output tokens are generated, y1 and y2 by the base model. These outputs are shown to human raters to rate and human preference is recorded for each individual output.
Training phase: Once the data sample is collected from the data collection phase, the reward model is trained with the following prompt. “Given the following input: <x>, LLM generated <y> output. Can you rate the performance of the output?”. The model will output r(reward) and we already know the actual value of reward r1 from the data collection phase. Now, this can be back-propagated with the loss function and the model can be trained. Below is the objective loss function which the model optimises for through back-propagation:
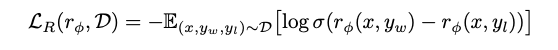
Notation:
- rΦ(x, y): a reward model parameterized by Φ which estimates the reward. Parameterized means we don’t know the actual value and this needs to be optimized from the above equation. This is the reward LLM model itself. Mostly, the LLM parameters are frozen here and only few parameters are left to change. Most important layer is the linear layer added at the top. This does most of the learning to rate the score of output.
- Ɗ: A dataset of triplets (x, yw, yl) where x: input, yw: the winner output and yl: the loser output
- σ: the sigmoid function which maps the difference in reward to a probability (0–1)
- ∑(x, y,w yl) ~Ɗ means x, yw, yl are all sampled from Ɗ
Example scenario: Imagine you’re training a reward model to evaluate responses. You have pairs of responses to a given prompt, and human feedback tells you which response is better. For context, x(“What is the capital of France?”), you have yw(“The capital of France is Paris.”) as winner and yl(“The capital of France is Berlin.” ) as loser. The reward model should eventually learn to give higher reward for “The capital of France is Paris.” output when compared to “The capital of France is Berlin.” output if “What is the capital of France?” input is given.
RL fine-tuning phase
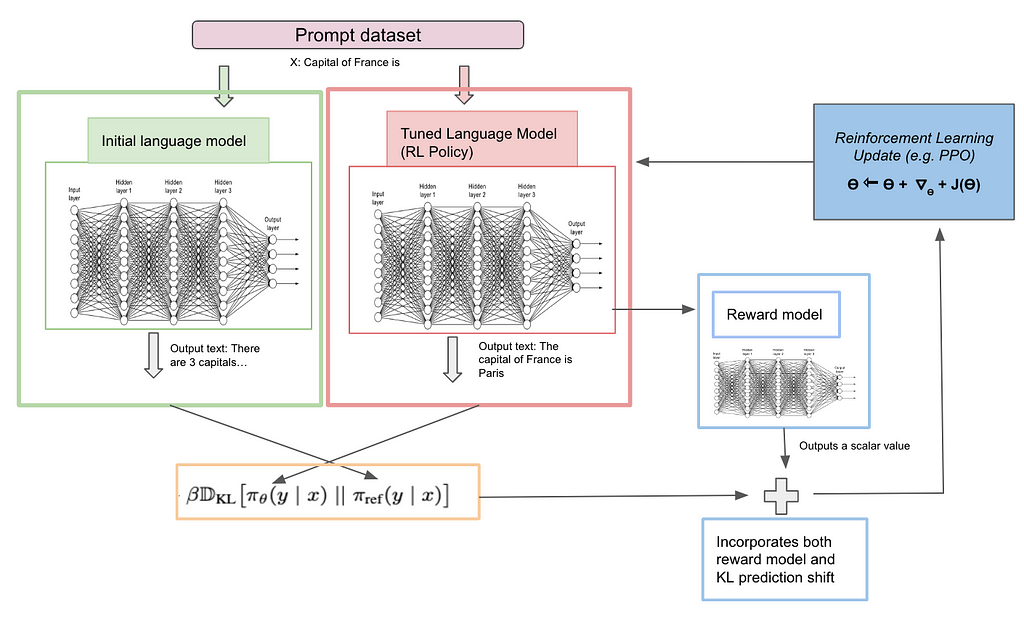
Reinforcement learning idea: Now the base model and reward model are trained, the idea is how to leverage reward model score and update base model parameters to reflect human preference. Since the reward model outputs a scalar score and is not differentiable, we cannot use simple back-propogation to update the base model param. Hence, we need other techniques to update the base model. This is where reinforcement learning comes which helps the base model to change the params through reward model score. This is done through PPO (proximal policy optimization). Understanding the core architecture of PPO is not required to grasp this concept and hence we will not cover it here but on a high level, the idea is that PPO can use scalar score to update base model parameters. Now let’s understand how base and reward models are incorporated to make base models learn human preference.
RL fine-tuning idea: In reinforcement learning, we have action, space and rewards. The idea is to come up with a policy which any action agent can take in the space which maximizes the reward. This becomes quite complicated but in a simplified sense, π is the policy which is our base LLM model only. Πref means the base model and ΠӨ means a different LLM optimal model which we are trying to generate. We need to find ΠӨ (the base model’s neural network weights will be fine-tuned) which gives human-preferred output. It’s just that we don’t know ΠӨ and the idea is to find this optimal model.
RL training and feedback loop phase: An input x is given to 2 policy models, Πref (baseline model) and ΠӨ (optimal model which we are trying to generate). Initially both models are kept the same. Input x to two models individually will give two outputs correspondingly. The output from ΠӨ model is also fed to reward model (input: x, output: y; as discussed above) and asked to output the reward score which is rΦ(x, y). Now we have 3 things, output from the baseline model, output from the optimal model, and a reward score from the optimal model. There are 2 things we are optimizing here, one is to maximize the reward because eventually we want the model to be as close as human preference and another is to minimize the divergence from baseline model. Maximizing the reward is easy since it is already a scalar quantity but how do we minimize the divergence of baseline and optimal model. Here we use “Kullback–Leibler divergence” which estimates the difference between 2 continuous probability distributions. Let’s take a deeper look into the objective loss function
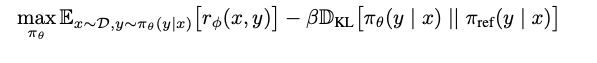
Notation:
- rΦ(x, y): a scalar value for an input x and output y (from optimal model). To be explicit, output from the optimal model is fed into the reward model.
- Dkl (ΠӨ (y | x) || Πref (y | x)): This computes the Kullback–Leibler divergence between 2 probability distributions. Each token from each model is a probability distribution. KL estimates how far the distribution is from each other.
- β : Hyperparameter which is used to determine how important it is to have optimal model close to baseline model.
Example scenario: Imagine you are asking (“What is the capital of France?”), Πref (baseline model) says: “The capital of France is Berlin.” and ΠӨ (optimal model) “There are 3 capitals, Paris, Versailles, and Lyon, but Paris is considered as the official capital”. Now rΦ(“x: What is the capital…”, “y: There are 3 capital..”) should give low score as it is less human-preferred and Kullback–Leibler divergence of (ΠӨ (y | x) || Πref (y | x)) should be high as well since the probability distribution space differs for both individual output. Hence the loss will be high from both terms. We do not want the model to only optimize for reward but also stay closer to the baseline model and hence both the terms are used to optimize the reward. In the next iteration with learning let’s say, ΠӨ (optimal model) says “The capital of France is Delhi”, in this case model learned to stay closer to Πref (baseline model) and output the format closer to baseline model but the reward component will still be lower. Hopefully, in the third iteration ΠӨ (optimal model) should be able to learn and output “The capital of France is Paris” with higher reward and model output aligning closely with baseline model.
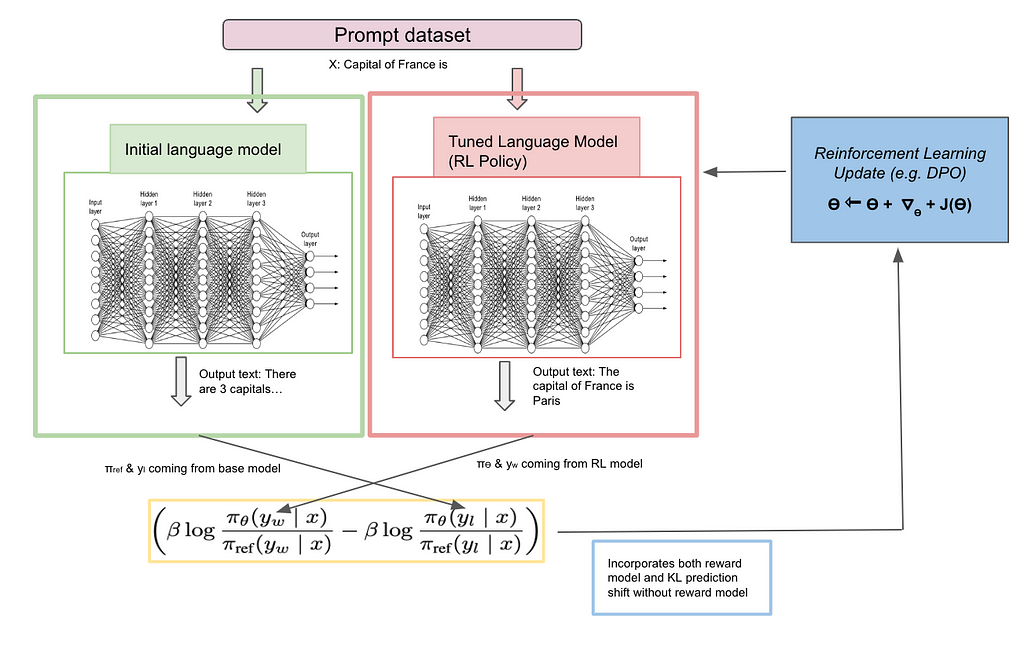
The below diagram helps illustrate the logic. I will also highly recommend to go through RLHF link from hugging face.
What is Reinforcement learning through human feedback (RLHF) via reward-free method ?
With RLHF using a reward-based method in mind, let’s move to the reward-free method. According to the paper: “our key insight is to leverage an analytical mapping from reward functions to optimal policies, which enables us to transform a loss function over reward functions into a loss function over policies. This change-of-variables approach avoids fitting an explicit, standalone reward model, while still optimizing under existing models of human preferences”. Very complicated to understand, but let’s try to break this down in simple phases in the next section.
Reward-free method’s key idea: In RLHF, a separate new reward model is trained which is expensive and costly to maintain. Is there any mechanism to avoid training a new reward model and use the existing base model to achieve a new optimal model? This is exactly what reward-free method does i.e. it avoids training a new reward model and in turn changes the equation in such a way that there is no reward model term in the loss function of DPO (Direct preference optimization). One way to think about this is that we need to reach optimal model policy(ΠӨ) from base model (Πref). It can be reached either through optimizing the reward function space which helps build a proxy to reach optimal model policy or directly learning a mapping function from reward to policy and in turn optimize for policy itself. This is exactly what the authors have tried by removing the reward function component in loss function and substitute it directly by model policy parameter. This is what the author meant when they say “leverage an analytical mapping from reward function to optimal policies …. into a loss function over policies”. This is the core innovation of the paper.
DPO training and feedback loop phase: Using Πref (baseline model), input x is given and asked to produce 2 outputs (y1 and y2). All x, y1 and y2 are used by human raters to decide winning yw and losing yl. Offline data set is collected with triplet information <x, yw and yl>. With this information, we know what the winning (human preferred) and losing (human not preferred) answers are. Now, the same input x is given to 2 policy (models) Πref (baseline model) and ΠӨ (optimal model). Initially both models are kept the same for training purposes. Input x to two models individually will give two outputs correspondingly. We compute how far the output is from winning and losing answers from both reference and optimal model through “Kullback–Leibler divergence”. Let’s take a deeper look into the objective loss function
Equation
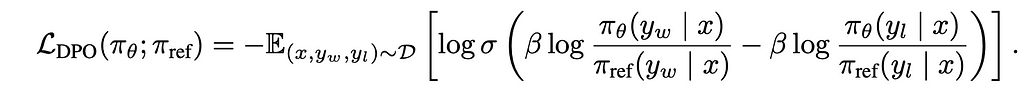
- ΠӨ (yw | x) -> Given x(input), how far is the corresponding output of the model say youtput from the winning output yw. Output youtput and yw are probability distributions and differences among both will be computed through “Kullback–Leibler divergence”. This will be a scalar value. Also this is computed for both models with different combinations of Πref (yw | x), Πref (yl | x), ΠӨ (yw | x) and ΠӨ (yl | x).
- β : Hyperparameter which is used to determine how important it is to have optimal model close to baseline model.
Conclusion
- Naturally, the question comes down to which one is better, RLHF through reward-based method using PPO or reward-free method using DPO. There is no right answer to this question. A recent paper compares “Is DPO superior to PPO for LLM alignment” (paper link) and concludes that PPO is generally better than DPO and that DPO suffers more heavily from out-of-distribution data. “Out-of-distribution” data means the human preference data is different from the baseline trained data. This can happen if base model training is done on some dataset while preference output is done for some other dataset.
- Overall, the research is still out on which one is better while we have seen companies like OpenAI, Anthropic, Meta leverage both RLHF via PPO and DPO as a tool for LLM alignment.
Reference
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model: https://arxiv.org/pdf/2305.18290
- Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study https://arxiv.org/pdf/2404.10719
- Hugging face RLHF article https://huggingface.co/blog/rlhf
LLM alignment: Reward-based vs reward-free methods was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
LLM alignment: Reward-based vs reward-free methods
Go Here to Read this Fast! LLM alignment: Reward-based vs reward-free methods