Eviden is a next-gen technology leader in data-driven, trusted, and sustainable digital transformation. With a strong portfolio of patented technologies and worldwide leading positions in advanced computing, security, AI, cloud, and digital platforms, Eviden provides deep expertise for a multitude of industries in more than 47 countries. Eviden is an AWS Premier partner, bringing together […]
Stable Diffusion XL by Stability AI is a high-quality text-to-image deep learning model that allows you to generate professional-looking images in various styles. Managed versions of Stable Diffusion XL are already available to you on Amazon SageMaker JumpStart (see Use Stable Diffusion XL with Amazon SageMaker JumpStart in Amazon SageMaker Studio) and Amazon Bedrock (see […]
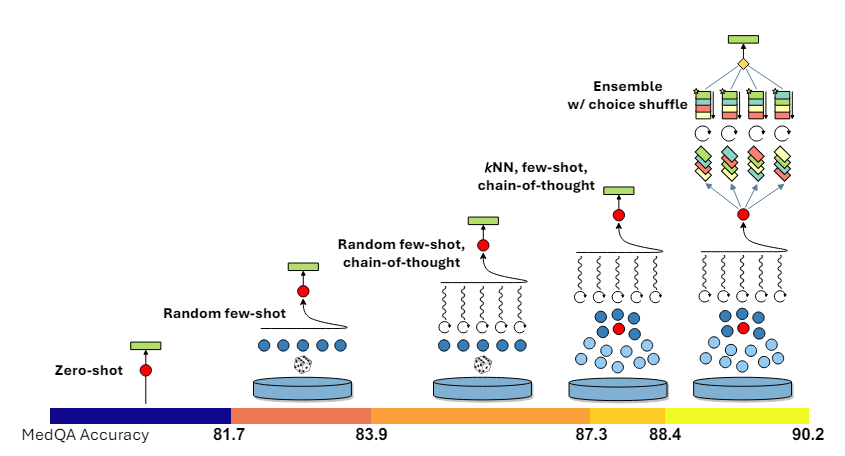
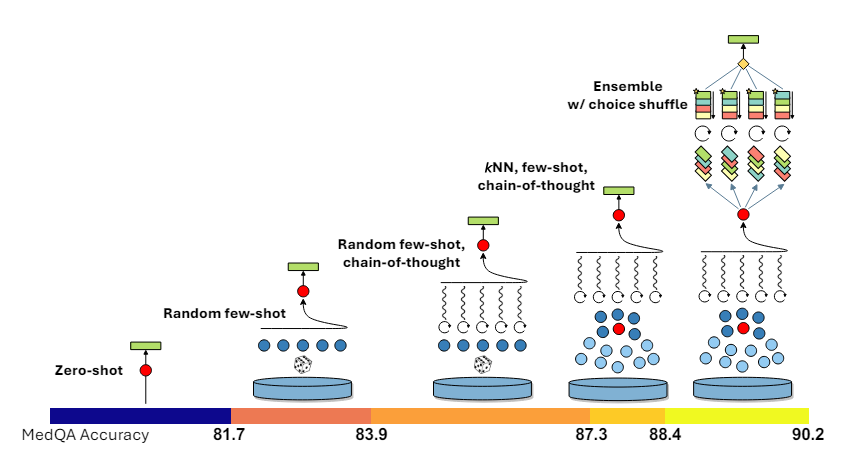
Digging into the details behind the prompting framework
Illustration of the various components of the Medprompt Strategy (Image taken from Fig:6 from the Medprompt paper [1] (https://arxiv.org/abs/2311.16452)
In my first blog post, I explored prompting and its significance in the context of Large Language Models (LLMs). Prompting is crucial for obtaining high-quality outputs from LLMs, as it guides the model’s responses and ensures they are relevant to the task at hand. Building on that foundation, two crucial questions often arise when trying to solve a use case using LLMs: how far can you push performance with prompting alone, and when do you bite the bullet and decide it might be more effective to fine-tune a model instead?
When making design decisions about leveraging prompting, several considerations come into play. Techniques like few-shot prompting and Chain-of-Thought (CoT) [2] prompting can help in boosting the performance of LLMs for most tasks. Retrieval-Augmented Generation (RAG) pipelines can further enhances LLM performance by adapting to new domains without fine-tuning and providing controllability over grounding the generated outputs while reducing hallucinations. Overall, we have a suite of tools to push the needle in terms of LLM performance without explicitly resorting to fine-tuning.
Fine-tuning comes with its own set of challenges and complications, in terms of labelled data requirements and the costs associated with training of LLMs and their deployment. Fine-tuning may also increase the hallucinations of the LLM in certain cases [3]. Putting this all together, we can see that there is significant value in trying to optimize LLM performance for our task through prompting before resorting to fine-tuning.
So, how do we go about this? In this article, we explore Medprompt [1], a sophisticated prompting strategy introduced by Microsoft. Medprompt ties together principles from few-shot prompting, CoT prompting and RAG to enhance the performance of GPT-4 in the healthcare domain without any domain-specific fine-tuning.
LLMs have demonstrated impressive capabilities across various sectors, particularly in healthcare. Last year, Google introduced MedPaLM [4] and MedPaLM-2 [5], LLMs that not only excel in Medical Multiple-Choice Question Answering (MCQA) datasets but also perform competitively and even outperform clinicians in open-ended medical question answering . These models have been tailored specifically for the healthcare domain through instruction fine-tuning and the use of clinician-written Chain-of-Thought templates, significantly enhancing their performance.
In this context, the paper “Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine” [1]from Microsoft raises a compelling question:
Can the performance of a generalist model like GPT-4 be improved for a specific domain without relying on domain-specific fine-tuning or expert-crafted resources?
As part of this study, the paper introduces Medprompt, an innovative prompting strategy that not only improves the model’s performance but also surpasses specialized models such as MedPaLM-2.
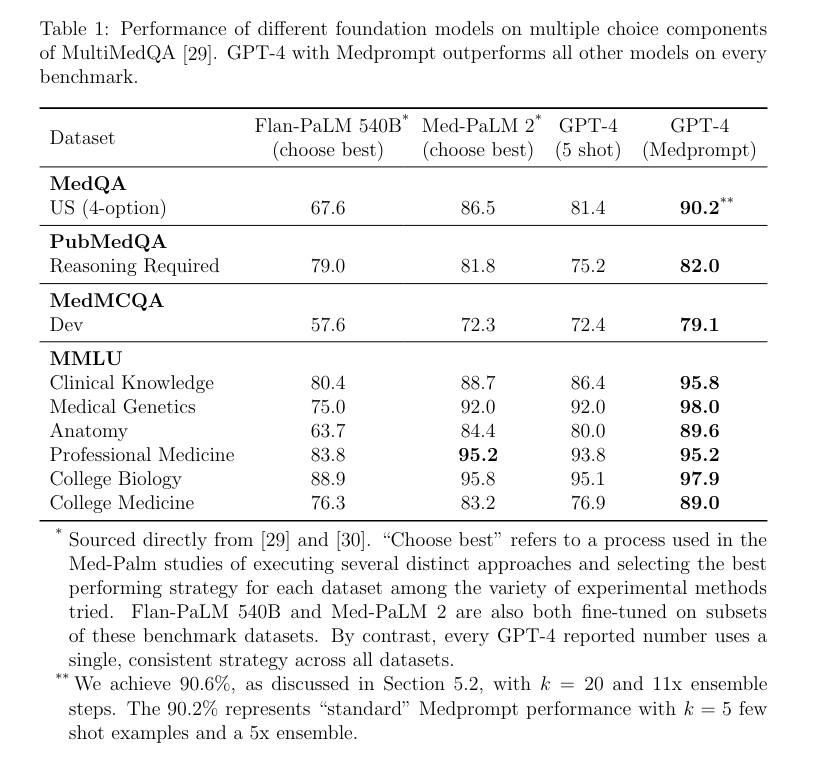
Comparison of various LLMs on medical knowledge benchmarks. GPT-4 with Medprompt outperforms Med-PaLM 2 across all these datasets. (Image of Table 1 from the Medprompt paper [1] (https://arxiv.org/abs/2311.16452))
GPT-4 with Medprompt outperforms Med-PaLM 2 across all medical MCQA benchmarks without any domain-specific fine-tuning. Let’s explore the components in Medprompt.
Components of Medprompt
Medprompt ties together principles from few-shot prompting, CoT prompting and RAG. Specifically there are 3 components in this pipeline:
Dynamic Few-shot Selection`
Few-shot prompting refers to utilizing example input-output pairs as context for prompting the LLM. If these few-shot samples are static, the downside is that they may not be the most relevant examples for the new input. Dynamic Few-shot Selection, the first component in Medprompt, helps overcome this by selecting the few-shot examples based on each new task input. This method involves training a K-Nearest Neighbors (K-NN) algorithm on the training set, which then retrieves the most similar training set examples to the test input based on cosine similarity in an embedding space. This strategy efficiently utilizes the existing training dataset to retrieve relevant few-shot examples for prompting the LLM.
Self-Generated CoT
As noted in the paper [1], CoT traditionally relies on manually crafted few-shot exemplars that include detailed reasoning steps, as used with MedPaLM-2, where such prompts were written by medical professionals. Medprompt introduces Self-Generated CoT as the second module, where the LLM is used to produce detailed, step-by-step explanations of its reasoning process, culminating in a final answer choice. By automatically generating CoT reasoning steps for each training datapoint, the need for manually crafted exemplars is bypassed. To ensure that only correct predictions with reasoning steps are retained and incorrect responses are filtered out, the answer generated by GPT-4 is cross-verified against the ground truth.
Choice Shuffling Ensemble
The Choice Shuffling Ensemble technique is the third technique introduced by Medprompt. It is designed to combat the inherent biases that may affect the model’s decision-making process, particularly position bias in multiple-choice settings. The ordering of the answer choices is shuffled, and this process is repeated k times to create k variants of the same question with shuffled answer choices. During inference, each variant is used to generate an answer, and a majority vote is performed over all variants to pick the final predicted option.
How are these components used in the preprocessing and inference stage?
Let’s now have a look at the preprocessing and inference stages in Medprompt.
Preprocessing Stage
In the preprocessing pipeline, we begin by taking each question from the training dataset and incorporating detailed instructions within the prompt to guide the generation of both an answer and its associated reasoning steps. The LLM is prompted to generate the answer and reasoning steps. After obtaining the generated response, we verify its accuracy by comparing the predicted answer to the ground truth for that particular question.
Medprompt Preprocessing Pipeline (Image by Author)
If the prediction is incorrect, we exclude this instance from our database of relevant questions. If the prediction is correct, we proceed by embedding the question using a text embedding model. We then store the question, question embedding, answer, and Chain of Thought (CoT) reasoning in a buffer. Once all questions have been processed, we utilize the embeddings for training a KNN model. This trained KNN model acts as our retriever in a RAG pipeline, enabling us to efficiently query and retrieve the top-k similar data points based on cosine similarity within the embedding space.
Inference Pipeline
During the inference stage, each question from our test set is first embedded using the text embedding model. We then utilize the KNN model to identify the top-k most similar questions. For each retrieved data point, we have access to the self-generated Chain of Thought (CoT) reasoning and the predicted answer. We format these elements — question, CoT reasoning, and answer — into few-shot examples for our eventual prompt.
Medprompt Inference Pipline (Image by Author)
We now perform choice shuffling ensembling by shuffling the order of answer choices for each test question, creating multiple variants of the same question. The LLM is then prompted with these variants, along with the corresponding few-shot exemplars, to generate reasoning steps and an answer for each variant. Finally, we perform a majority vote over the predictions from all variants and select the final prediction.
Implementing Medprompt
We use the MedQA [6] dataset for implementing and evaluating Medprompt. We first define helper functions for parsing the jsonl files.
def write_jsonl_file(file_path, dict_list): """ Write a list of dictionaries to a JSON Lines file.
Args: - file_path (str): The path to the file where the data will be written. - dict_list (list): A list of dictionaries to write to the file. """ with open(file_path, 'w') as file: for dictionary in dict_list: json_line = json.dumps(dictionary) file.write(json_line + 'n')
def read_jsonl_file(file_path): """ Parses a JSONL (JSON Lines) file and returns a list of dictionaries.
Args: file_path (str): The path to the JSONL file to be read.
Returns: list of dict: A list where each element is a dictionary representing a JSON object from the file. """ jsonl_lines = [] with open(file_path, 'r', encoding="utf-8") as file: for line in file: json_object = json.loads(line) jsonl_lines.append(json_object)
return jsonl_lines
Implementing Self-Generated CoT
For our implementation, we utilize the training set from MedQA. We implement a zero-shot CoT prompt and process all the training questions. We use GPT-4o in our implementation. For each question, we generate the CoT and the corresponding answer. We define a prompt which is based on the template provided in the Medprompt paper.
system_prompt = """You are an expert medical professional. You are provided with a medical question with multiple answer choices. Your goal is to think through the question carefully and explain your reasoning step by step before selecting the final answer. Respond only with the reasoning steps and answer as specified below. Below is the format for each question and answer:
Output: ## Answer (model generated chain of thought explanation) Therefore, the answer is [final model answer (e.g. A,B,C,D)]"""
def build_few_shot_prompt(system_prompt, question, examples, include_cot=True): """ Builds the zero-shot prompt.
Args: system_prompt (str): Task Instruction for the LLM content (dict): The content for which to create a query, formatted as required by `create_query`.
Returns: list of dict: A list of messages, including a system message defining the task and a user message with the input question. """ messages = [{"role": "system", "content": system_prompt}]
for elem in examples: messages.append({"role": "user", "content": create_query(elem)}) if include_cot: messages.append({"role": "assistant", "content": format_answer(elem["cot"], elem["answer_idx"])}) else: answer_string = f"""## AnswernTherefore, the answer is {elem["answer_idx"]}""" messages.append({"role": "assistant", "content": answer_string})
def get_response(messages, model_name, temperature = 0.0, max_tokens = 10): """ Obtains the responses/answers of the model through the chat-completions API.
Args: messages (list of dict): The built messages provided to the API. model_name (str): Name of the model to access through the API temperature (float): A value between 0 and 1 that controls the randomness of the output. A temperature value of 0 ideally makes the model pick the most likely token, making the outputs deterministic. max_tokens (int): Maximum number of tokens that the model should generate
Returns: str: The response message content from the model. """ response = client.chat.completions.create( model=model_name, messages=messages, temperature=temperature, max_tokens=max_tokens ) return response.choices[0].message.content
We also define helper functions for parsing the reasoning and the final answer option from the LLM response.
def matches_ans_option(s): """ Checks if the string starts with the specific pattern 'Therefore, the answer is [A-Z]'.
Args: s (str): The string to be checked.
Returns: bool: True if the string matches the pattern, False otherwise. """ return bool(re.match(r'^Therefore, the answer is [A-Z]', s))
def extract_ans_option(s): """ Extracts the answer option (a single capital letter) from the start of the string.
Args: s (str): The string containing the answer pattern.
Returns: str or None: The captured answer option if the pattern is found, otherwise None. """ match = re.search(r'^Therefore, the answer is ([A-Z])', s) if match: return match.group(1) # Returns the captured alphabet return None
def matches_answer_start(s): """ Checks if the string starts with the markdown header '## Answer'.
Args: s (str): The string to be checked.
Returns: bool: True if the string starts with '## Answer', False otherwise. """ return s.startswith("## Answer")
def validate_response(s): """ Validates a multi-line string response that it starts with '## Answer' and ends with the answer pattern.
Args: s (str): The multi-line string response to be validated.
Returns: bool: True if the response is valid, False otherwise. """ file_content = s.split("n")
return matches_ans_option(file_content[-1]) and matches_answer_start(s)
def parse_answer(response): """ Parses a response that starts with '## Answer', extracting the reasoning and the answer choice.
Args: response (str): The multi-line string response containing the answer and reasoning.
Returns: tuple: A tuple containing the extracted CoT reasoning and the answer choice. """ split_response = response.split("n") assert split_response[0] == "## Answer" cot_reasoning = "n".join(split_response[1:-1]).strip() ans_choice = extract_ans_option(split_response[-1]) return cot_reasoning, ans_choice
We now process the questions in the training set of MedQA. We obtain CoT responses and answers for all questions and store them to a folder.
for idx, item in enumerate(tqdm(train_data)): if str(idx) + ".txt" in existing_files: continue
prompt = build_zero_shot_prompt(system_prompt, item) try: response = get_response(prompt, model_name="gpt-4o", max_tokens=500) cot_responses.append(response) with open(os.path.join("cot_responses", str(idx) + ".txt"), "w", encoding="utf-8") as f: f.write(response) except Exception as e : print(str(e)) cot_responses.append("")
We now iterate across all the generated responses to check if they are valid and adhere to the prediction format defined in the prompt. We discard responses that do not conform to the required format. After that, we check the predicted answers against the ground truth for each question and only retain questions for which the predicted answers match the ground truth.
questions_dict = [] ctr = 0 for idx, question in enumerate(tqdm(train_data)): file = open(os.path.join("cot_responses/", str(idx) + ".txt"), encoding="utf-8").read() if not validate_response(file): continue
filtered_questions_dict = [] for item in tqdm(questions_dict): pred_ans = item["options"][item["pred_ans"]] if pred_ans == item["answer"]: filtered_questions_dict.append(item)
Implementing the KNN model
Having processed the training set and obtained the CoT response for all these questions, we now embed all questions using the text-embedding-ada-002 from OpenAI.
for item in tqdm(filtered_questions_dict): item["embedding"] = get_embedding(item["question"]) inv_options_map = {v:k for k,v in item["options"].items()} item["answer_idx"] = inv_options_map[item["answer"]]
We now train a KNN model using these question embeddings. This acts as a retriever at inference time, as it helps us to retrieve similar datapoints from the training set that are most similar to the question from the test set.
import numpy as np from sklearn.neighbors import NearestNeighbors
embeddings = np.array([d["embedding"] for d in filtered_questions_dict]) indices = list(range(len(filtered_questions_dict)))
Implementing the Dynamic Few-Shot and Choice Shuffling Ensemble Logic
We can now run inference. We subsample 500 questions from the MedQA test set for our evaluation. For each question, we retrieve the 5 most similar questions from the train set using the KNN module, along with their respective CoT reasoning steps and predicted answers. We construct a few-shot prompt using these examples.
For each question, we also shuffle the order of the options 5 times to create different variants. We then utilize the constructed few-shot prompt to get the predicted answer for each of the variants with shuffled options.
def shuffle_option_labels(answer_options): """ Shuffles the options of the question.
Parameters: answer_options (dict): A dictionary with the options.
Returns: dict: A new dictionary with the shuffled options. """ options = list(answer_options.values()) random.shuffle(options) labels = [chr(i) for i in range(ord('A'), ord('A') + len(options))] shuffled_options_dict = {label: option for label, option in zip(labels, options)}
for question in tqdm(test_samples, colour ="green"): question_variants = [] prompt_variants = [] cot_responses = [] question_embedding = get_embedding(question["question"]) distances, top_k_indices = knn.kneighbors([question_embedding], n_neighbors=5) top_k_dicts = [filtered_questions_dict[i] for i in top_k_indices[0]] question["outputs"] = []
for idx in range(5): question_copy = question.copy() shuffled_options = shuffle_option_labels(question["options"]) inv_map = {v:k for k,v in shuffled_options.items()}
We now evaluate the results of Medprompt over the test set. For each question, we have five predictions generated through the ensemble logic. We take the mode, or most frequently occurring prediction, for each question as the final prediction and evaluate the performance. Two edge cases are possible here:
Two different answer options are predicted two times each, with no clear winner.
There is an error with the response generated, meaning that we don’t have a predicted answer option.
For both of these edge cases, we consider the question to be wrongly answered by the LLM.
def find_mode_string_list(string_list): """ Finds the most frequently occurring strings.
Parameters: string_list (list of str): A list of strings. Returns: list of str or None: A list containing the most frequent string(s) from the input list. Returns None if the input list is empty. """ if not string_list: return None
string_counts = Counter(string_list) max_freq = max(string_counts.values()) mode_strings = [string for string, count in string_counts.items() if count == max_freq] return mode_strings
ctr = 0 for item in test_samples: pred_ans = [x["pred_ans"] for x in item["outputs"]] freq_ans = find_mode_string_list(pred_ans)
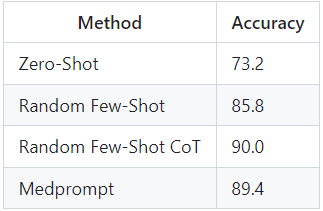
We evaluate the performance of Medprompt with GPT-4o in terms of accuracy on the MedQA test subset. Additionally, we benchmark the performance of Zero-shot prompting, Random Few-Shot prompting, and Random Few-Shot with CoT prompting.
Results of our evaluation (Image by Author)
We observe that Medprompt and Random Few-Shot CoT prompting outperform the Zero and Few-Shot prompting baselines. However, surprisingly, we notice that Random Few-Shot CoT outperforms our Medprompt performance. This could be due to a couple of reasons:
The original Medprompt paper benchmarked the performance of GPT-4. We observe that GPT-4o outperforms GPT-4T and GPT-4 on various text benchmarks significantly (https://openai.com/index/hello-gpt-4o/), indicating that Medprompt could have a lesser effect on a stronger model like GPT-4o.
We restrict our evaluation to 500 questions subsampled from MedQA. The Medprompt paper evaluates other Medical MCQA datasets and the full version of MedQA. Evaluating GPT-4o on the complete versions of the datasets could give a better picture of the overall performance.
Conclusion
Medprompt is an interesting framework for creating sophisticated prompting pipelines, particularly for adapting a generalist LLM to a specific domain without the need for fine-tuning. It also highlights the considerations involved in deciding between prompting and fine-tuning for various use cases. Exploring how far prompting can be pushed to enhance LLM performance is important, as it offers a resource and cost-efficient alternative to fine-tuning.
References:
[1] Nori, H., Lee, Y. T., Zhang, S., Carignan, D., Edgar, R., Fusi, N., … & Horvitz, E. (2023). Can generalist foundation models outcompete special-purpose tuning? case study in medicine. arXiv preprint arXiv:2311.16452. (https://arxiv.org/abs/2311.16452)
[2] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., … & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824–24837. (https://openreview.net/pdf?id=_VjQlMeSB_J)
[3] Gekhman, Z., Yona, G., Aharoni, R., Eyal, M., Feder, A., Reichart, R., & Herzig, J. (2024). Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?. arXiv preprint arXiv:2405.05904. (https://arxiv.org/abs/2405.05904)
[4] Singhal, K., Azizi, S., Tu, T., Mahdavi, S. S., Wei, J., Chung, H. W., … & Natarajan, V. (2023). Large language models encode clinical knowledge. Nature, 620(7972), 172–180. (https://www.nature.com/articles/s41586-023-06291-2)
[5] Singhal, K., Tu, T., Gottweis, J., Sayres, R., Wulczyn, E., Hou, L., … & Natarajan, V. (2023). Towards expert-level medical question answering with large language models. arXiv preprint arXiv:2305.09617. (https://arxiv.org/abs/2305.09617)
[6] Jin, D., Pan, E., Oufattole, N., Weng, W. H., Fang, H., & Szolovits, P. (2021). What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences, 11(14), 6421. (https://arxiv.org/abs/2009.13081) (Original dataset is released under a MIT License)
An Illustrated Overview of Mathematical Logic Used in AI Training
It’s always beneficial to understand how things work. In this article, I will provide a very simple overview of the basic mathematical logic used in training AI models. I promise that if you have a basic education, the following examples will be understandable, and you’ll gain a slightly better understanding of the field of artificial intelligence.
Creating an AI for Sales Forecasting
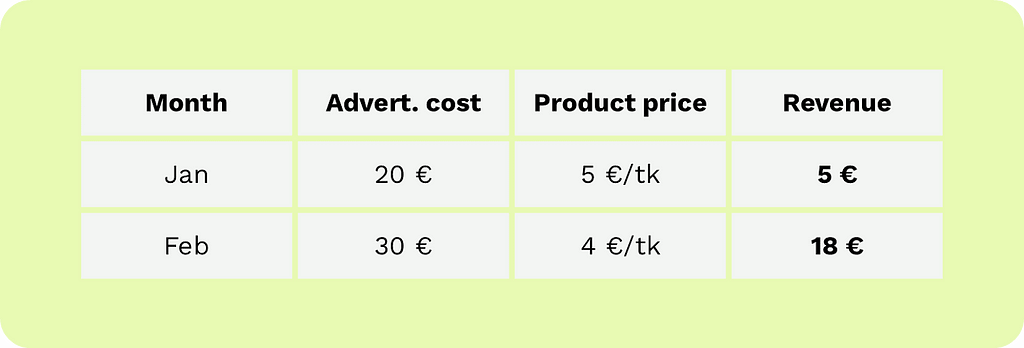
Let’s assume we want to create a new AI model to forecast our company’s sales revenue. We have data on the sales revenue of the past two months, advertising costs, and product prices.
Illustration by author
In other words, we want to create a model that tells us how our sales revenue depends on the price of our product and the advertising expenses. Using such a tool, a marketing specialist could, for example, calculate the expected sales revenue if they spend €50 on advertising and set the product price at €6.
AI as a Mathematical Formula
At its core, AI is nothing more than a mathematical formula (or a set of formulas). Our sales forecasting example could be presented as a mathematical formula like this:
Illustration by author
The formula exists, but we don’t know the values to assign to the model’s parameters m and n. In other words, we don’t know how much increasing advertising costs and adjusting the product price affects our sales revenue.
Starting to Learn
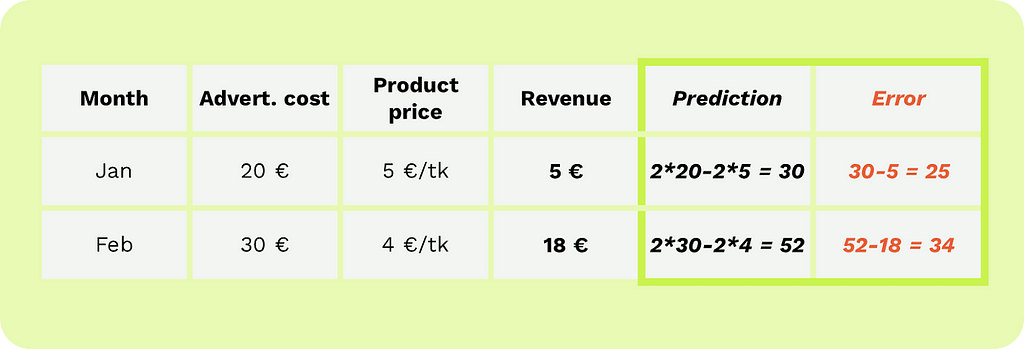
When we start training the AI, we can assign random values to the model’s parameters. For example, we initially set the advertising cost parameter to 2 and the price parameter to -2.
Illustration by author
Now, we simply try it out. If we multiply the advertising cost and product price by their respective parameter values, we see that our initial model is overly optimistic. In the first month, the actual sales revenue was €5, but our model predicted €30. In the second month, the actual sales revenue was €18, and our model predicted €52.
Illustration by author
The Learning Rule
If the error is 0, the model is perfect, and no adjustment is needed.
If the error is > 0, the model gave an overly optimistic result:
Decrease the weights (parameters) if the corresponding input feature (e.g., advertising cost or product price) has a positive value.
Increase the weights (parameters) if the corresponding input feature has a negative value.
If the error is < 0, the model was too pessimistic:
Increase the weights (parameters) if the corresponding input feature has a positive value.
Decrease the weights (parameters) if the corresponding input feature has a negative value.
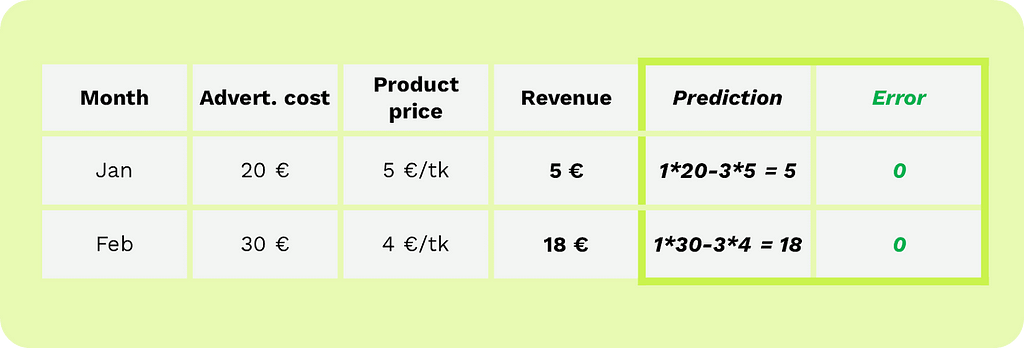
Following the learning rule, we need to decrease both parameters because both advertising cost and product price have positive value. For instance, we reduce the advertising cost weight from 2 to 1 and the price parameter from -2 to -3.
Illustration by author
If we recalculate, we see that our model now predicts accurately. Great, our first manually trained AI model is ready.
Illustration by author
Testing the Model on Data Not Used for Training
If you think the above model is too good to be true, you are correct. Our model worked perfectly on the training data. To assess the model’s accuracy, it must be tested on data that wasn’t used in the training process.
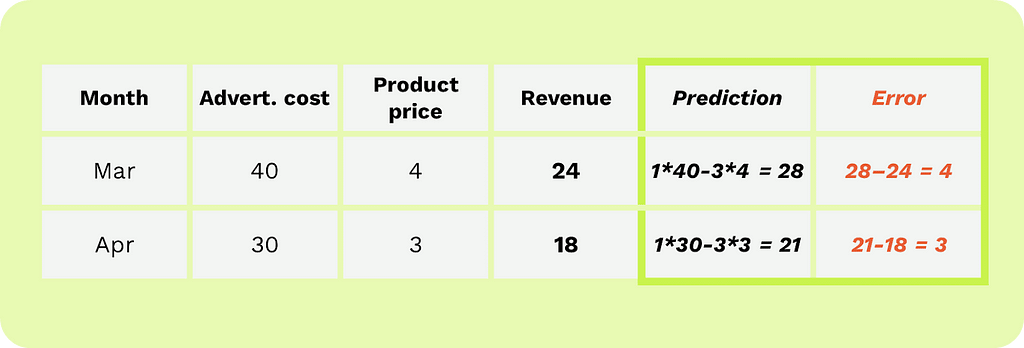
We trained our model on data from January and February. Now, let’s check how well the model can predict the sales revenue for March and April.
Illustration by author
From the table above, we see that the model predicts the sales revenue for March as €28 (actual €24) and for April as €21 (actual €18). On average, our model makes an error of €3.5 on new data, which we can call the accuracy of our model.
Conclusion
In conclusion, AI at its core is a mathematical formula. In our example, the formula had two parameters; the GPT-4 model has more than a trillion (1 trillion = 1,000,000,000,000) parameters. Both are trained on the same principle: gradually adjusting the model’s parameters to reduce the error.
It is also important to remember that AI learns on training data, but its accuracy can only be assessed using data not used during training (test data).
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.