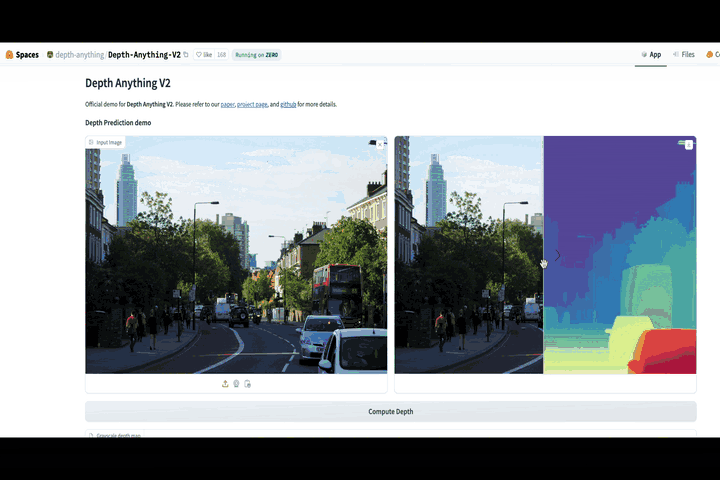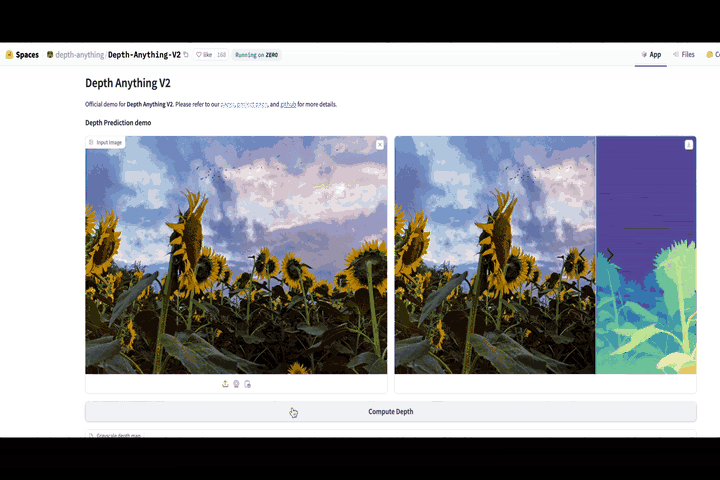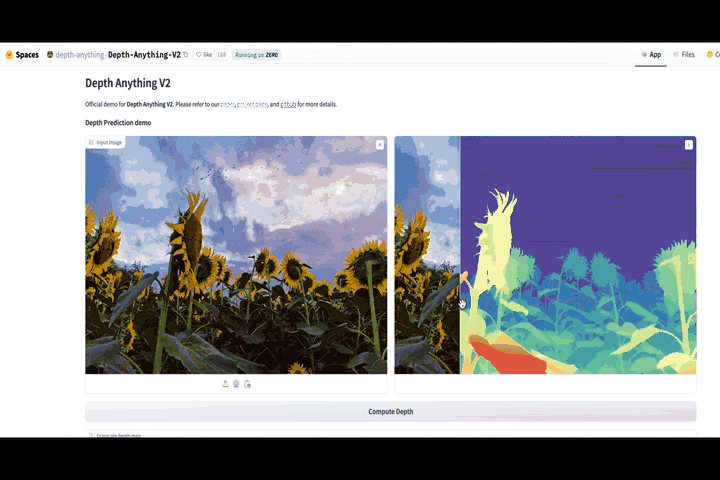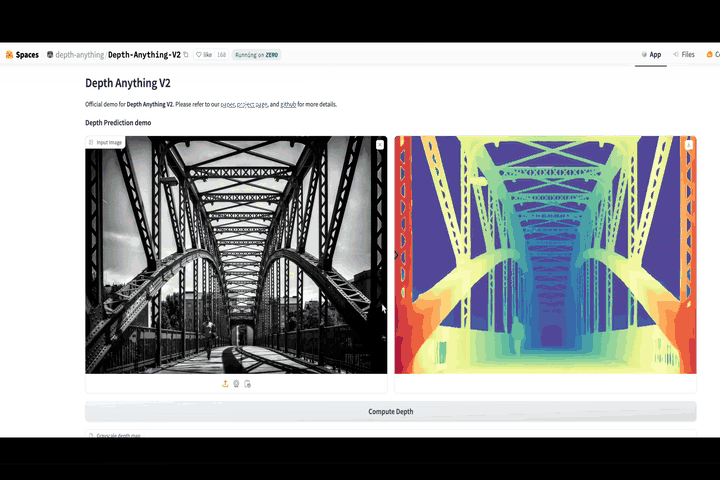
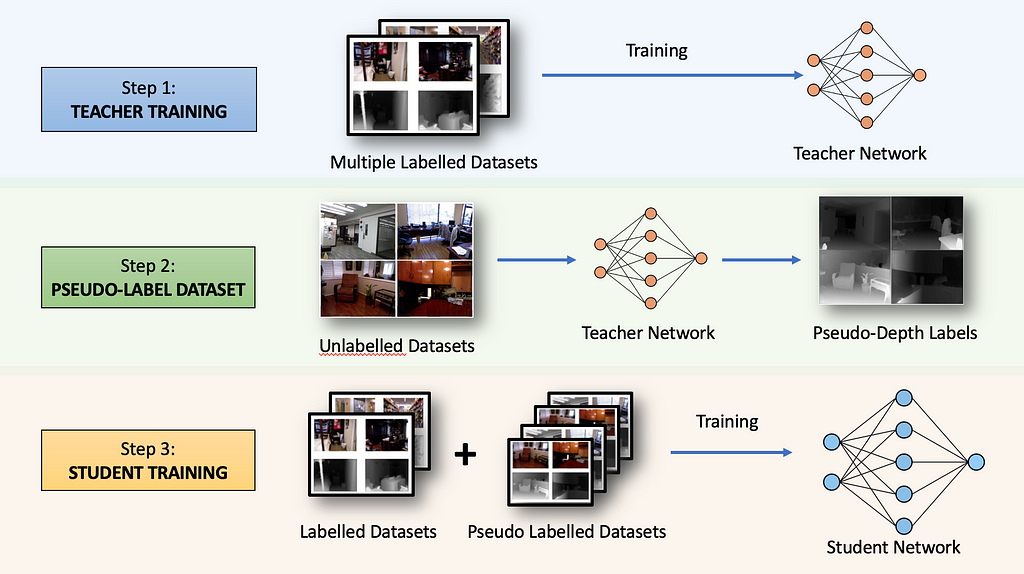
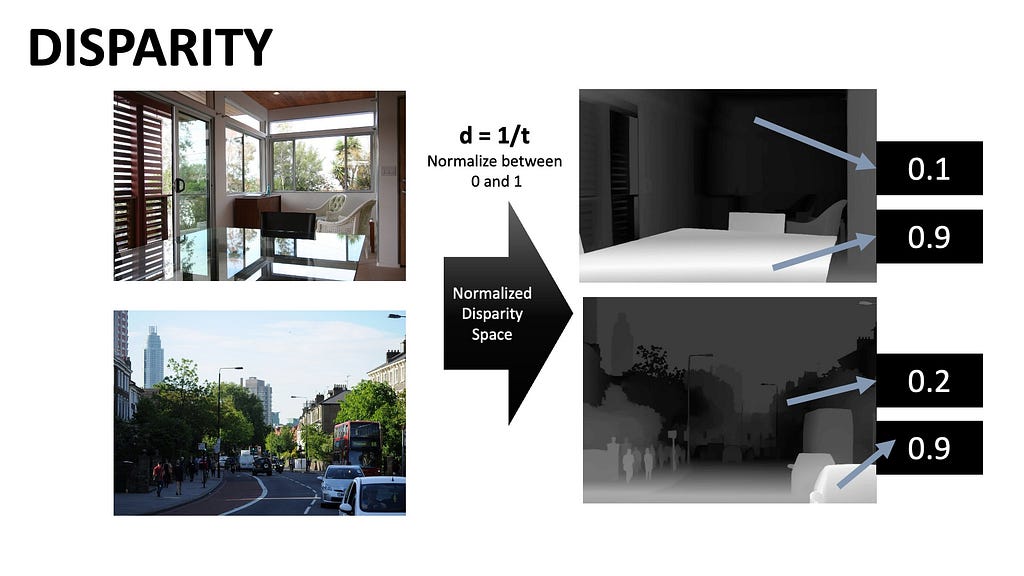
Understanding the 4 key types of memory (short term, short long term, long term, and working), the methods of language model grounding, and the role memory plays in the process of grounding.
In the context of Language Models and Agentic AI, memory and grounding are both hot and emerging fields of research. And although they are often placed closely in a sentence and are often related, they serve different functions in practice. In this article, I hope to clear up the confusion around these two terms and demonstrate how memory can play a role in the overall grounding of a model.
Memory in Language Models
In my last article, we discussed the important role of memory in Agentic AI. Memory in language models refers to the ability of AI systems to retain and recall pertinent information, contributing to its ability to reason and continuously learn from its experiences. Memory can be thought of in 4 categories: short term memory, short long term memory, long term memory, and working memory.
It sounds complex, but let’s break them down simply:
Short Term Memory (STM):
STM retains information for a very brief period of time, which could be seconds to minutes. If you ask a language model a question it needs to retain your messages for long enough to generate an answer to your question. Just like people, language models struggle to remember too many things simultaneously.
Miller’s law, states that “Short-term memory is a component of memory that holds a small amount of information in an active, readily available state for a brief period, typically a few seconds to a minute. The duration of STM seems to be between 15 and 30 seconds, and STM’s capacity is limited, often thought to be about 7±2 items.”
So if you ask a language model “what genre is that book that I mentioned in my previous message?” it needs to use its short term memory to reference recent messages and generate a relevant response.
Implementation:
Context is stored in external systems, such as session variables or databases, which hold a portion of the conversation history. Each new user input and assistant response is appended to the existing context to create conversation history. During inference, context is sent along with the user’s new query to the language model to generate a response that considers the entire conversation. This research paper offers a more in depth view of the mechanisms that enable short term memory.
Short Long Term Memory (SLTM):
SLTM retains information for a moderate period, which can be minutes to hours. For example, within the same session, you can pick back up where you left off in a conversation without having to repeat context because it has been stored as SLTM. This process is also an external process rather than part of the language model itself.
Implementation:
Sessions can be managed using identifiers that link user interactions over time. Context data is stored in a way that it can persist across user interactions within a defined period, such as a database. When a user resumes conversation, the system can retrieve the conversation history from previous sessions and pass that to the language model during inference. Much like in short term memory, each new user input and assistant response is appended to the existing context to keep conversation history current.
Long Term Memory (LTM):
LTM retains information for a admin defined amount of time that could be indefinitely. For example, if we were to build an AI tutor, it would be important for the language model to understand what subjects the student performs well in, where they still struggle, what learning styles work best for them, and more. This way, the model can recall relevant information to inform its future teaching plans. Squirrel AI is an example of a platform that uses long term memory to “craft personalized learning pathways, engages in targeted teaching, and provides emotional intervention when needed”.
Implementation:
Information can be stored in structured databases, knowledge graphs, or document stores that are queried as needed. Relevant information is retrieved based on the user’s current interaction and past history. This provides context for the language model that is passed back in with the user’s response or system prompt.
Working Memory:
Working memory is a component of the language model itself (unlike the other types of memory that are external processes). It enables the language model to hold information, manipulate it, and refine it — improving the model’s ability to reason. This is important because as the model processes the user’s ask, its understanding of the task and the steps it needs to take to execute on it can change. You can think of working memory as the model’s own scratch pad for its thoughts. For example, when provided with a multistep math problem such as (5 + 3) * 2, the language model needs the ability to calculate the (5+3) in the parentheses and store that information before taking the sum of the two numbers and multiplying by 2. If you’re interested in digging deeper into this subject, the paper “TransformerFAM: Feedback attention is working memory” offers a new approach to extending the working memory and enabling a language model to process inputs/context window of unlimited length.
Implementation:
Mechanisms like attention layers in transformers or hidden states in recurrent neural networks (RNNs) are responsible for maintaining intermediate computations and provide the ability to manipulate intermediate results within the same inference session. As the model processes input, it updates its internal state, which enables stronger reasoning abilities.
All 4 types of memory are important components of creating an AI system that can effectively manage and utilize information across various timeframes and contexts.

Grounding
The response from a language model should always make sense in the context of the conversation — they shouldn’t just be a bunch of factual statements. Grounding measures the ability of a model to produce an output that is contextually relevant and meaningful. The process of grounding a language model can be a combination of language model training, fine-tuning, and external processes (including memory!).
Language Model Training and Fine Tuning
The data that the model is initially trained on will make a substantial difference in how grounded the model is. Training a model on a large corpora of diverse data enables it to learn language patterns, grammar, and semantics, to predict the next most relevant word. The pre-trained model is then fine-tuned on domain-specific data, which helps it generate more relevant and accurate outputs for particular applications that require deeper domain specific knowledge. This is especially important if you require the model to perform well on specific texts which it might not have been exposed to during its initial training. Although our expectations of a language model’s capabilities are high, we can’t expect it to perform well on something it has never seen before. Just like we wouldn’t expect a student to perform well on an exam if they hadn’t studied the material.
External Context
Providing the model with real-time or up-to-date context-specific information also helps it stay grounded. There are many methods of doing this, such as integrating it with external knowledge bases, APIs, and real-time data. This method is also known as Retrieval Augmented Generation (RAG).
Memory Systems
Memory systems in AI play a crucial role in ensuring that the system remains grounded based on its previously taken actions, lessons learned, performance over time, and experience with users and other systems. The four types of memory outlined previously in the article play a crucial role in grounding a language model’s ability to stay context-aware and produce relevant outputs. Memory systems work in tandem with grounding techniques like training, fine-tuning, and external context integration to enhance the model’s overall performance and relevance.
Conclusion
Memory and grounding are interconnected elements that enhance the performance and reliability of AI systems. While memory enables AI to retain and manipulate information across different timeframes, grounding ensures that the AI’s outputs are contextually relevant and meaningful. By integrating memory systems and grounding techniques, AI systems can achieve a higher level of understanding and effectiveness in their interactions and tasks.
Note: The opinions expressed both in this article and paper are solely those of the authors and do not necessarily reflect the views or policies of their respective employers.
If you still have questions or think that something needs to be further clarified? Drop me a DM on Linkedin! I‘m always eager to engage in food for thought and iterate on my work.
References:
https://openreview.net/pdf?id=QNW1OrjynpT
https://www.simplypsychology.org/short-term-memory.html
The Intersection of Memory and Grounding in AI Systems was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
The Intersection of Memory and Grounding in AI Systems
Go Here to Read this Fast! The Intersection of Memory and Grounding in AI Systems