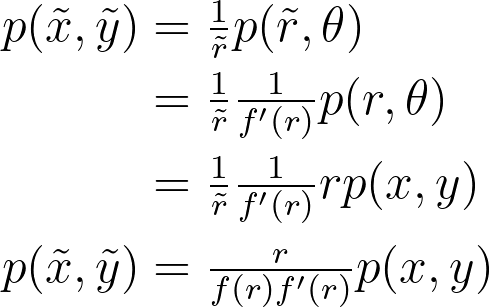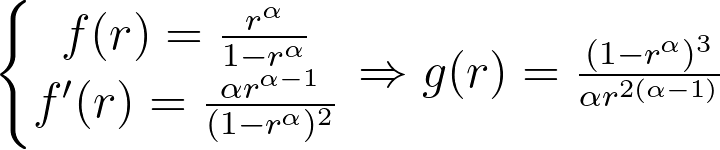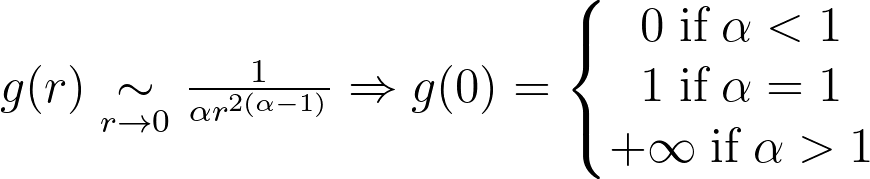Whether you are a Data Engineer, Machine Learning Engineer or Web developer, you ought to get used to this tool
There are quite a few use cases where Pydantic fits almost seamlessly. Data processing, among others, benefits from using Pydantic as well. However, it can be used in web development for parsing and structuring data in expected formats.
Today’s idea is to define a couple of pain points and show how Pydantic can be used. Let’s start with the most familiar use case, and that is data parsing and processing.
Let’s say we have a CSV file with a dozen columns and thousands of rows. The usual scenario in data analysis is to load this CSV into Pandas DataFrame and start fiddling with it. Often you start inspecting the data and types of columns, drop some of them, and create new ones. This process is based on your previous knowledge of what is in the dataset. Yet, this is not always transparent to the others. They either have to go and open a CSV file (or any other source of data) or skim through the code to figure out what columns are being used and created. This is all good for the initial steps of data analysis and research. However, once the data set is analyzed and we are ready to go into creating a data pipeline that will load, transform, and use data for analytics or machine learning purposes, we need a standardized way of making sure datasets and data types are in expected format. This is why we want a library that will give us the ability to declare or define this. There are few libraries for this, most of them are open source as well, but Pydantic, being open source as well, found its way into different frameworks and is universally accepted in different use cases.
Okay, let’s start.
Python — Type hinting
Before we get into the example I have previously mentioned, I’d like to start with some basics in Python.
Through its versions, Python introduced type hinting. What is type hinting, and why do we need it? Well, as we all know, Python is a dynamically typed scripting language. This means that data types are inferred in runtime. This has its benefits in engineers being able to write code faster. The bad part is that you will not be alarmed about type mismatches until you run your code. At that time, it may be a bit late to fix your error quickly. Because Python still remains a dynamically typed language, there was an intent to bridge this gap by introducing so-called “type hinting” that engineers can use to notify both readers and IDEs about expected data types.
Example:
def add(a, b):
return a + b
add(4, 3)
> 7
add(.3, 4)
> 4.3
add('a', 'b')
> 'ab'
This is a short example of how a defined function may be used in multiple use cases, some of which were not envisioned by its writer. For someone persistent enough, you will have to introduce many hoops so you can be assured your code is used in the intended way.
How does type hinting look?
def add(a: int, b: int) -> int:
return a + b
add(4, 3)
> 7
add(.3, 4)
> 4.3
add('a', 'b')
> 'ab'
This one works as well! Why? Well, this is still called “type hinting,” not “type enforcing”. As already mentioned, it is used as a way to “notify” readers and “users” about the intended way of use. One of the code “users” are IDEs, and your IDE of choice should be able to figure out and raise alerts in case you try to bypass the data type declarations.
Why did we go to describe something like this? Well, it is because Pydantic is built on top of this type of hinting. It uses type hinting to define data types and structures and validate them as well.
Pydantic — First steps
As I already mentioned, Pydantic is used to validate data structures and data types. There are four ways in which you can use it. Today I will go through the two most important:
- validate_call to validate function calls based on type hinting and annotations,
- BaseModel to define and validate models through class definitions.
Pydantic — validate_call
So, there is no better way to start with something new than to immerse yourself right away. This is how we shall start learning Pydantic.
Before you are able to use it, you have to install it:
pip install pydantic
For the sake of clarity, let me note both Python and pydantic versions here as well:
python version: 3.10.5
pydantic version: 2.5.3
Then, you want to create a new Python project, create your first Python script, import Pydantic, and start using it. The first example will be to revise our previous function and use Pydantic to make sure it is used in the intended way. Example:
import pydantic
@pydantic.validate_call
def add(a: int, b: int) -> int:
return a + b
# ----
add(4, 4)
> 8
# ----
add('a', 'a')
> ValidationError: 2 validation errors for add
0
Input should be a valid integer, unable to parse string as an integer [type=int_parsing, input_value='a', input_type=str]
For further information visit <https://errors.pydantic.dev/2.5/v/int_parsing>
1
Input should be a valid integer, unable to parse string as an integer [type=int_parsing, input_value='a', input_type=str]
For further information visit <https://errors.pydantic.dev/2.5/v/int_parsing>
# ----
add(.4, .3)
> ValidationError: 2 validation errors for add
0
Input should be a valid integer, got a number with a fractional part [type=int_from_float, input_value=0.4, input_type=float]
For further information visit <https://errors.pydantic.dev/2.5/v/int_from_float>
1
Input should be a valid integer, got a number with a fractional part [type=int_from_float, input_value=0.3, input_type=float]
For further information visit <https://errors.pydantic.dev/2.5/v/int_from_float>
# ----
add('3', 'a')
> ValidationError: 1 validation error for add
1
Input should be a valid integer, unable to parse string as an integer [type=int_parsing, input_value='a', input_type=str]
For further information visit <https://errors.pydantic.dev/2.5/v/int_parsing>
# ----
add('3', '3')
> 6
# ----
add('3', '3.3')
> ValidationError: 1 validation error for add
1
Input should be a valid integer, unable to parse string as an integer [type=int_parsing, input_value='3.3', input_type=str]
For further information visit <https://errors.pydantic.dev/2.5/v/int_parsing>
A couple of things to clarify:
- validate_call is used as a decorator. This is basically a wrapper around the function declared that introduces additional logic that can be run at the time the function is defined as well as when you call the function. Here, it is used to make sure the data you pass to the function call conforms to the expected data types (hints).
- A validated function call raises ValidationError in a case you start using your function in an unintended way. This error is verbose and says a lot about why it was raised.
- By principle of charity, Pydantic tries to figure out what you meant and tries to use type coercion. This can result in string values passed to a function call being implicitly converted to the expected type.
- Type coercion is not always possible, and in that case, ValidationError is raised.
Don’t know what Python decorator function is? Read one of my previous articles on this subject:
What about default values and argument extractions?
from pydantic import validate_call
@validate_call(validate_return=True)
def add(*args: int, a: int, b: int = 4) -> int:
return str(sum(args) + a + b)
# ----
add(4,3,4)
> ValidationError: 1 validation error for add
a
Missing required keyword only argument [type=missing_keyword_only_argument, input_value=ArgsKwargs((4, 3, 4)), input_type=ArgsKwargs]
For further information visit <https://errors.pydantic.dev/2.5/v/missing_keyword_only_argument>
# ----
add(4, 3, 4, a=3)
> 18
# ----
@validate_call
def add(*args: int, a: int, b: int = 4) -> int:
return str(sum(args) + a + b)
# ----
add(4, 3, 4, a=3)
> '18'
Takeaways from this example:
- You can annotate the type of the variable number of arguments declaration (*args).
- Default values are still an option, even if you are annotating variable data types.
- validate_call accepts validate_return argument, which makes function return value validation as well. Data type coercion is also applied in this case. validate_return is set to False by default. If it is left as it is, the function may not return what is declared in type hinting.
What about if you want to validate the data type but also constrain the values that variable can take? Example:
from pydantic import validate_call, Field
from typing import Annotated
type_age = Annotated[int, Field(lt=120)]
@validate_call(validate_return=True)
def add(age_one: int, age_two: type_age) -> int:
return age_one + age_two
add(3, 300)
> ValidationError: 1 validation error for add
1
Input should be less than 120 [type=less_than, input_value=200, input_type=int]
For further information visit <https://errors.pydantic.dev/2.5/v/less_than>
This example shows:
- You can use Annotated and pydantic.Field to not only validate data type but also add metadata that Pydantic uses to constrain variable values and formats.
- ValidationError is yet again very verbose about what was wrong with our function call. This can be really helpful.
Here is one more example of how you can both validate and constrain variable values. We will simulate a payload (dictionary) that you want to process in your function after it has been validated:
from pydantic import HttpUrl, PastDate
from pydantic import Field
from pydantic import validate_call
from typing import Annotated
Name = Annotated[str, Field(min_length=2, max_length=15)]
@validate_call(validate_return=True)
def process_payload(url: HttpUrl, name: Name, birth_date: PastDate) -> str:
return f'{name=}, {birth_date=}'
# ----
payload = {
'url': 'httpss://example.com',
'name': 'J',
'birth_date': '2024-12-12'
}
process_payload(**payload)
> ValidationError: 3 validation errors for process_payload
url
URL scheme should be 'http' or 'https' [type=url_scheme, input_value='httpss://example.com', input_type=str]
For further information visit <https://errors.pydantic.dev/2.5/v/url_scheme>
name
String should have at least 2 characters [type=string_too_short, input_value='J', input_type=str]
For further information visit <https://errors.pydantic.dev/2.5/v/string_too_short>
birth_date
Date should be in the past [type=date_past, input_value='2024-12-12', input_type=str]
For further information visit <https://errors.pydantic.dev/2.5/v/date_past>
# ----
payload = {
'url': '<https://example.com>',
'name': 'Joe-1234567891011121314',
'birth_date': '2020-12-12'
}
process_payload(**payload)
> ValidationError: 1 validation error for process_payload
name
String should have at most 15 characters [type=string_too_long, input_value='Joe-1234567891011121314', input_type=str]
For further information visit <https://errors.pydantic.dev/2.5/v/string_too_long>
This was the basics of how to validate function arguments and their return value.
Now, we will go to the second most important way Pydantic can be used to validate and process data: through defining models.
Pydantic — BaseModel
This part is more interesting for the purposes of data processing, as you will see.
So far, we have used validate_call to decorate functions and specified function arguments and their corresponding types and constraints.
Here, we define models by defining model classes, where we specify fields, their types, and constraints. This is very similar to what we did previously. By defining a model class that inherits from Pydantic BaseModel, we use a hidden mechanism that does the data validation, parsing, and serialization. What this gives us is the ability to create objects that conform to model specifications.
Here is an example:
from pydantic import Field
from pydantic import BaseModel
class Person(BaseModel):
name: str = Field(min_length=2, max_length=15)
age: int = Field(gt=0, lt=120)
# ----
john = Person(name='john', age=20)
> Person(name='john', age=20)
# ----
mike = Person(name='m', age=0)
> ValidationError: 2 validation errors for Person
name
String should have at least 2 characters [type=string_too_short, input_value='j', input_type=str]
For further information visit <https://errors.pydantic.dev/2.5/v/string_too_short>
age
Input should be greater than 0 [type=greater_than, input_value=0, input_type=int]
For further information visit <https://errors.pydantic.dev/2.5/v/greater_than>
You can use annotation here as well, and you can also specify default values for fields. Let’s see another example:
from pydantic import Field
from pydantic import BaseModel
from typing import Annotated
Name = Annotated[str, Field(min_length=2, max_length=15)]
Age = Annotated[int, Field(default=1, ge=0, le=120)]
class Person(BaseModel):
name: Name
age: Age
# ----
mike = Person(name='mike')
> Person(name='mike', age=1)
Things get very interesting when your use case gets a bit complex. Remember the payload that we defined? I will define another, more complex structure that we will go through and validate. To make it more interesting, let’s create a payload that we will use to query a service that acts as an intermediary between us and LLM providers. Then we will validate it.
Here is an example:
from pydantic import Field
from pydantic import BaseModel
from pydantic import ConfigDict
from typing import Literal
from typing import Annotated
from enum import Enum
payload = {
"req_id": "test",
"text": "This is a sample text.",
"instruction": "embed",
"llm_provider": "openai",
"llm_params": {
"llm_temperature": 0,
"llm_model_name": "gpt4o"
},
"misc": "what"
}
ReqID = Annotated[str, Field(min_length=2, max_length=15)]
class LLMProviders(str, Enum):
OPENAI = 'openai'
CLAUDE = 'claude'
class LLMParams(BaseModel):
temperature: int = Field(validation_alias='llm_temperature', ge=0, le=1)
llm_name: str = Field(validation_alias='llm_model_name',
serialization_alias='model')
class Payload(BaseModel):
req_id: str = Field(exclude=True)
text: str = Field(min_length=5)
instruction: Literal['embed', 'chat']
llm_provider: LLMProviders
llm_params: LLMParams
# model_config = ConfigDict(use_enum_values=True)
# ----
validated_payload = Payload(**payload)
validated_payload
> Payload(req_id='test',
text='This is a sample text.',
instruction='embed',
llm_provider=<LLMProviders.OPENAI: 'openai'>,
llm_params=LLMParams(temperature=0, llm_name='gpt4o'))
# ----
validated_payload.model_dump()
> {'text': 'This is a sample text.',
'instruction': 'embed',
'llm_provider': <LLMProviders.OPENAI: 'openai'>,
'llm_params': {'temperature': 0, 'llm_name': 'gpt4o'}}
# ----
validated_payload.model_dump(by_alias=True)
> {'text': 'This is a sample text.',
'instruction': 'embed',
'llm_provider': <LLMProviders.OPENAI: 'openai'>,
'llm_params': {'temperature': 0, 'model': 'gpt4o'}}
# ----
# After adding
# model_config = ConfigDict(use_enum_values=True)
# in Payload model definition, you get
validated_payload.model_dump(by_alias=True)
> {'text': 'This is a sample text.',
'instruction': 'embed',
'llm_provider': 'openai',
'llm_params': {'temperature': 0, 'model': 'gpt4o'}}
Some of the important insights from this elaborated example are:
- You can use Enums or Literal to define a list of specific values that are expected.
- In case you want to name a model’s field differently from the field name in the validated data, you can use validation_alias. It specifies the field name in the data being validated.
- serialization_alias is used when the model’s internal field name is not necessarily the same name you want to use when you serialize the model.
- Field can be excluded from serialization with exclude=True.
- Model fields can be Pydantic models as well. The process of validation in that case is done recursively. This part is really awesome, since Pydantic does the job of going into depth while validating nested structures.
- Fields that are not taken into account in the model definition are not parsed.
Pydantic — Use cases
Here I will show you the snippets of code that show where and how you can use Pydantic in your day-to-day tasks.
Data processing
Say you have data you need to validate and process. It can be stored in CSV, Parquet files, or, for example, in a NoSQL database in the form of a document. Let’s take the example of a CSV file, and let’s say you want to process its content.
Here is the CSV file (test.csv) example:
name,age,bank_account
johnny,0,20
matt,10,0
abraham,100,100000
mary,15,15
linda,130,100000
And here is how it is validated and parsed:
from pydantic import BaseModel
from pydantic import Field
from pydantic import field_validator
from pydantic import ValidationInfo
from typing import List
import csv
FILE_NAME = 'test.csv'
class DataModel(BaseModel):
name: str = Field(min_length=2, max_length=15)
age: int = Field(ge=1, le=120)
bank_account: float = Field(ge=0, default=0)
@field_validator('name')
@classmethod
def validate_name(cls, v: str, info: ValidationInfo) -> str:
return str(v).capitalize()
class ValidatedModels(BaseModel):
validated: List[DataModel]
validated_rows = []
with open(FILE_NAME, 'r') as f:
reader = csv.DictReader(f, delimiter=',')
for row in reader:
try:
validated_rows.append(DataModel(**row))
except ValidationError as ve:
# print out error
# disregard the record
print(f'{ve=}')
validated_rows
> [DataModel(name='Matt', age=10, bank_account=0.0),
DataModel(name='Abraham', age=100, bank_account=100000.0),
DataModel(name='Mary', age=15, bank_account=15.0)]
validated = ValidatedModels(validated=validated_rows)
validated.model_dump()
> {'validated': [{'name': 'Matt', 'age': 10, 'bank_account': 0.0},
{'name': 'Abraham', 'age': 100, 'bank_account': 100000.0},
{'name': 'Mary', 'age': 15, 'bank_account': 15.0}]}
FastAPI request validation
FastAPI is already integrated with Pydantic, so this one is going to be very brief. The way FastAPI handles requests is by passing them to a function that handles the route. By passing this request to a function, validation is performed automatically. Something similar to validate_call that we mentioned at the beginning of this article.
Example of app.py that is used to run FastAPI-based service:
from fastapi import FastAPI
from pydantic import BaseModel, HttpUrl
class Request(BaseModel):
request_id: str
url: HttpUrl
app = FastAPI()
@app.post("/search/by_url/")
async def create_item(req: Request):
return item
Conclusion
Pydantic is a really powerful library and has a lot of mechanisms for a multitude of different use cases and edge cases as well. Today, I explained the most basic parts of how you should use it, and I’ll provide references below for those who are not faint-hearted.
Go and explore. I’m sure it will serve you well on different fronts.
References
- Python type hinting.
- Pydantic models.
- Validate call decorator.
- Pydantic fields.
- Pydantic validators.
Applied Python Chronicles: A Gentle Intro to Pydantic was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Applied Python Chronicles: A Gentle Intro to Pydantic
Go Here to Read this Fast! Applied Python Chronicles: A Gentle Intro to Pydantic