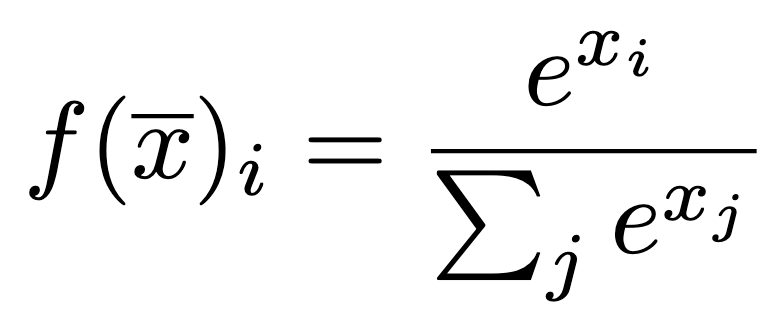Transform boring default Matplotlib line charts into stunning, customized visualizations
Cover, image by the Author
Everyone who has used Matplotlib knows how ugly the default charts look like. In this series of posts, I’ll share some tricks to make your visualizations stand out and reflect your individual style.
We’ll start with a simple line chart, which is widely used. The main highlight will be adding a gradient fill below the plot — a task that’s not entirely straightforward.
So, let’s dive in and walk through all the key steps of this transformation!
Let’s make all the necessary imports first.
import pandas as pd import numpy as np import matplotlib.dates as mdates import matplotlib.pyplot as plt import matplotlib.ticker as ticker from matplotlib import rcParams from matplotlib.path import Path from matplotlib.patches import PathPatch
np.random.seed(38)
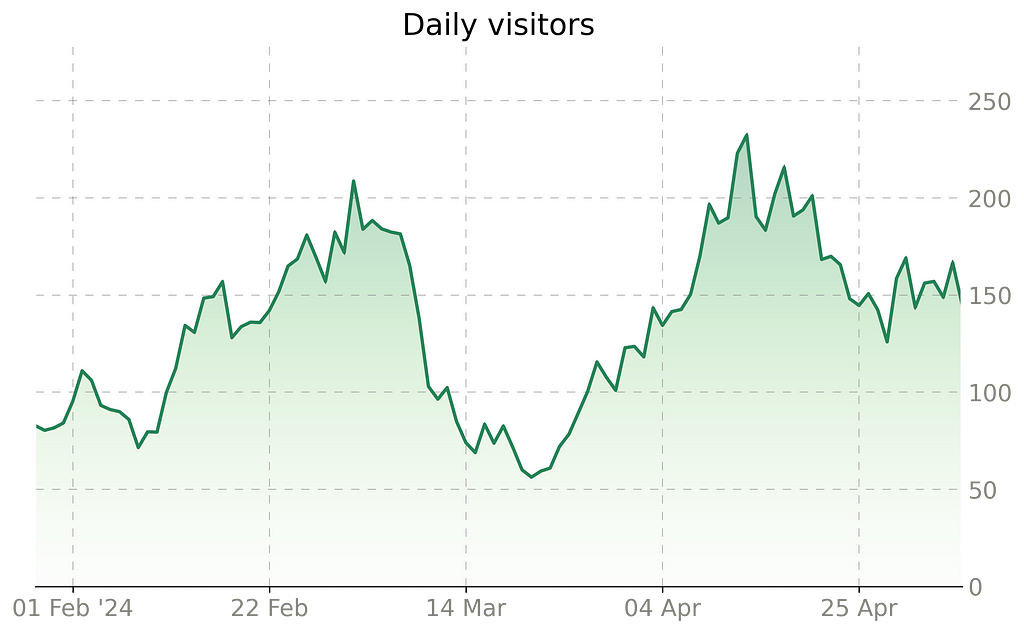
Now we need to generate sample data for our visualization. We will create something similar to what stock prices look like.
# Remove ticks from axis Y ax.tick_params(axis='y', length=0)
Grid added, image by Author
Now we’re adding a tine esthetic detail — year near the first tick on the axis X. Also we make the font color of tick labels more pale.
# Add year to the first date on the axis def custom_date_formatter(t, pos, dates, x_interval): date = dates[pos*x_interval] if pos == 0: return date.strftime('%d %b '%y') else: return date.strftime('%d %b') ax.xaxis.set_major_formatter(ticker.FuncFormatter((lambda x, pos: custom_date_formatter(x, pos, dates=dates, x_interval=x_interval))))
# Ticks label color [t.set_color('#808079') for t in ax.yaxis.get_ticklabels()] [t.set_color('#808079') for t in ax.xaxis.get_ticklabels()]
Year near first date, image by Author
And we’re getting closer to the trickiest moment — how to create a gradient under the curve. Actually there is no such option in Matplotlib, but we can simulate it creating a gradient image and then clipping it with the chart.
# Gradient numeric_x = np.array([i for i in range(len(x))]) numeric_x_patch = np.append(numeric_x, max(numeric_x)) numeric_x_patch = np.append(numeric_x_patch[0], numeric_x_patch) y_patch = np.append(y, 0) y_patch = np.append(0, y_patch)
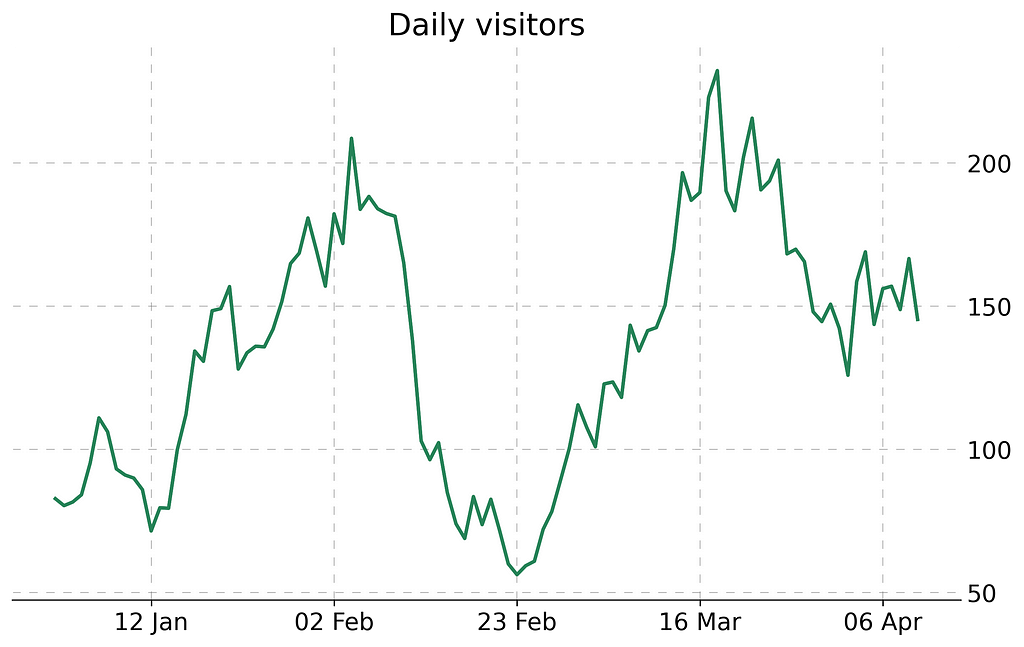
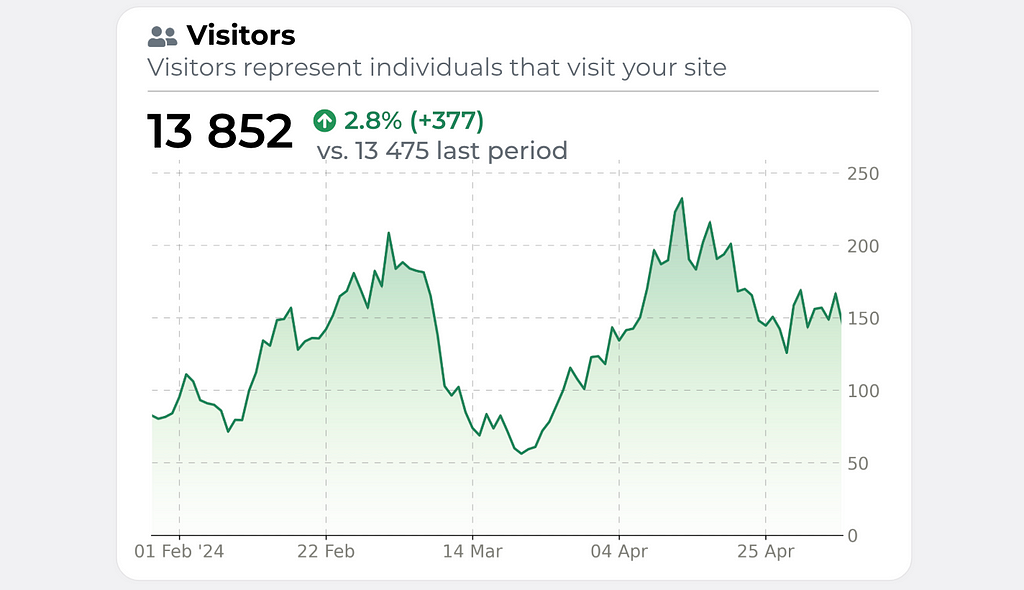
Now it looks clean and nice. We just need to add several details using any editor (I prefer Google Slides) — title, round border corners and some numeric indicators.
Final visualization, image by Author
The full code to reproduce the visualization is below:
The inspiration for this project came from hosting a Jira ticket creation tool on a web application I had developed for internal users. I also added automated Jira ticket creation upon system errors.
Users and system errors often create similar tickets, so I wanted to see if the reasoning capabilities of LLMs could be used to automatically triage tickets by linking related issues, creating user stories, acceptance criteria, and priority.
Additionally, giving users and product/managerial stakeholders easier access to interact directly with Jira in natural language without any technical competencies was an interesting prospect.
Jira has become ubiquitous within software development and is now a leading tool for project management.
Concretely, advances in Large Language Model (LLM) and agentic research would imply there is an opportunity to make significant productivity gains in this area.
Jira-related tasks are a great candidate for automation since; tasks are in the modality of text, are highly repetitive, relatively low risk and low complexity.
In the article below, I will present my open-source project — AI Jira Assistant: a chat interface to interact with Jira via an AI agent, with a custom AI agent tool to triage newly created Jira tickets.
All code has been made available via the GitHub repo at the end of the article.
The project makes use of LangChain agents, served via Django (with PostgreSQL) and Google Mesop. Services are provided in Docker to be run locally.
The prompting strategy includes a CO-STAR system prompt, Chain-of-Thought (CoT) reasoning with few-shot prompting.
This article will include the following sections.
Definitions
Mesop interface: Streamlit or Mesop?
Django REST framework
Custom LangChain agent tool and prompting
Jira API examples
Next steps
1. Definitions
Firstly, I wanted to cover some high-level definitions that are central to the project.
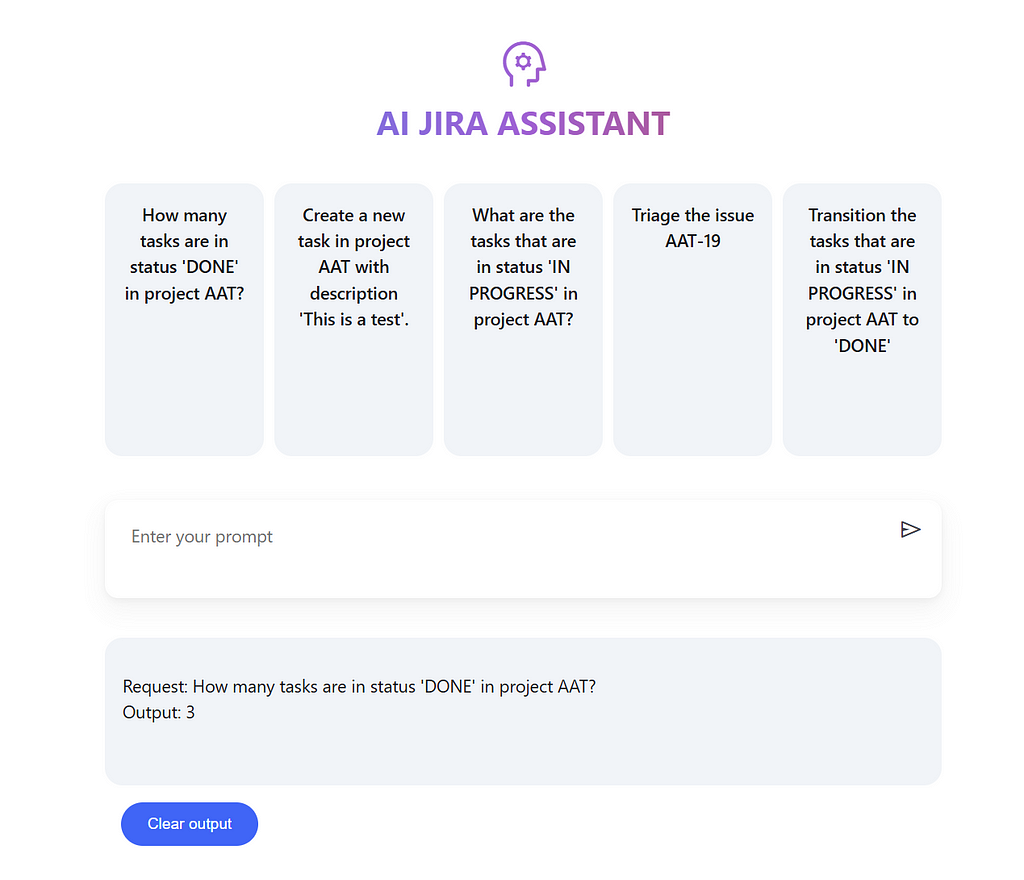
AI Jira Assistant
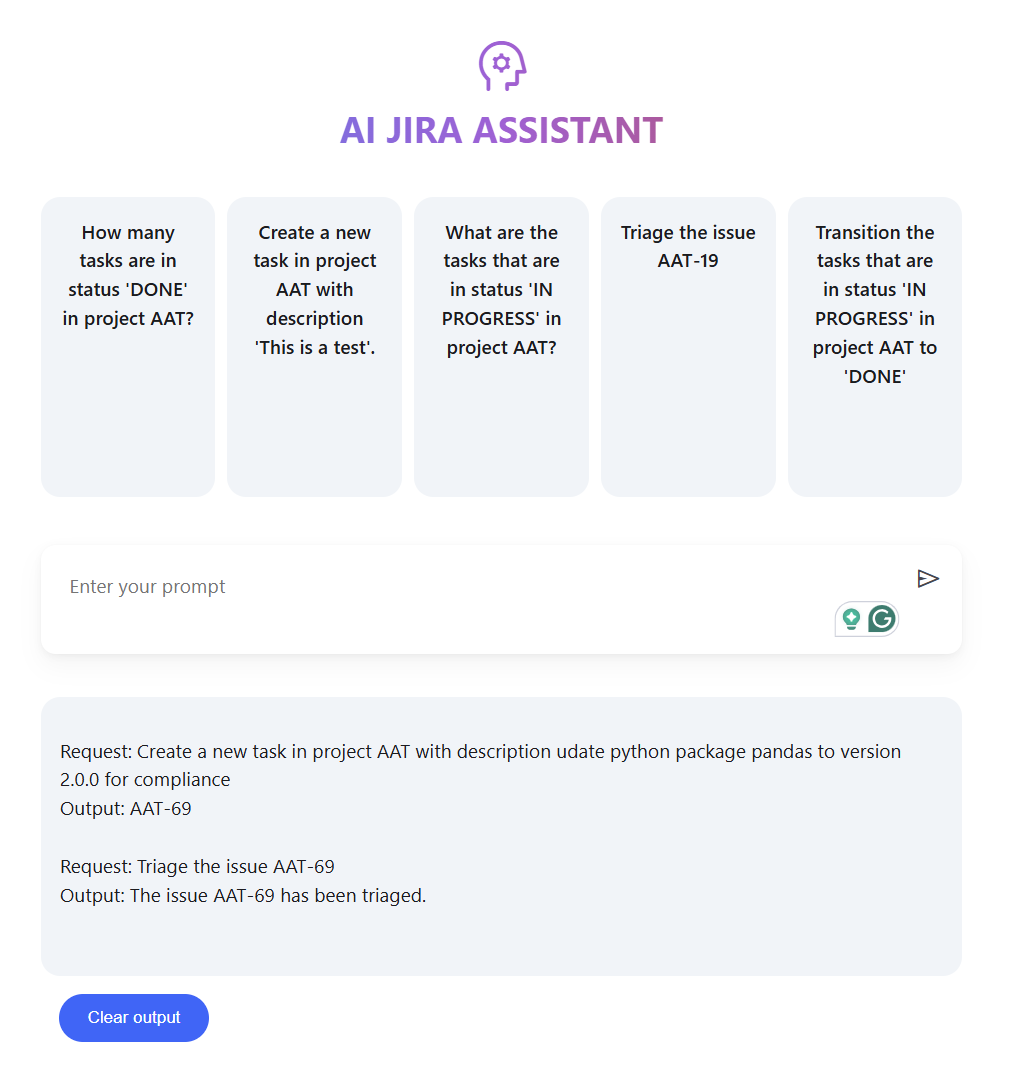
The open source project presented here, when ran locally looks as the below.
Including a chat interface for user prompts, example prompts to pre-populate the chat interface, a box for displaying model responses and a button to clear model responses.
Code snippets for the major technical challenges throughout the project are discussed in detail.
AI Jira Assistant
What is Google Mesop?
Mesop is a relatively recent (2023) Python web framework used at Google for rapid AI app development.
“Mesop provides a versatile range of 30 components, from low-level building blocks to high-level, AI-focused components. This flexibility lets you rapidly prototype ML apps or build custom UIs, all within a single framework that adapts to your project’s use case.” — Mesop Homepage
What is an AI Agent?
The origins of the Agent software paradigm comes from the word Agency, a software program that can observe its environment and act upon it.
“An artificial intelligence (AI) agent is a software program that can interact with its environment, collect data, and use the data to perform self-determined tasks to meet predetermined goals.
Humans set goals, but an AI agent independently chooses the best actions it needs to perform to achieve those goals.
AI agents are rational agents. They make rational decisions based on their perceptions and data to produce optimal performance and results.
An AI agent senses its environment with physical or software interfaces.” — AWS Website
What is CO-STAR prompting?
This is a guide to the formatting of prompts such that the following headers are included; context, objective, style, tone, audience and response. This is widely accepted to improve model output for LLMs.
“The CO-STAR framework, a brainchild of GovTech Singapore’s Data Science & AI team, is a handy template for structuring prompts.
It considers all the key aspects that influence the effectiveness and relevance of an LLM’s response, leading to more optimal responses.” — Sheila Teo’s Medium Post
What is Chain-of-Thought (CoT) prompting?
Originally proposed in a Google paper; Wei et al. (2022). Chain-of-Thought (CoT) prompting means to provide few-shot prompting examples of intermediate reasoning steps. Which was proven to improve common-sense reasoning of the model output.
What is Django?
Django is one of the more sophisticated widely used Python frameworks.
“Django is a high-level Python web framework that encourages rapid development and clean, pragmatic design. It’s free and open source.” — Django Homepage
What is LangChain?
LangChain is one of the better know open source libraries for supporting a LLM applications, up to and including agents and prompting relevant to this project.
“LangChain’s flexible abstractions and AI-first toolkit make it the #1 choice for developers when building with GenAI. Join 1M+ builders standardizing their LLM app development in LangChain’s Python and JavaScript frameworks.” — LangChain website
This was the first opportunity to use Mesop in anger — so I thought a comparison might be useful.
Mesop is designed to give more fine-grained control over the CSS styling of components and natively integrates with JS web comments. Mesop also has useful debugging tools when running locally. I would also say from experience that the multi-page app functionality is easier to use.
However, this does mean that there is a larger barrier to entry for say machine learning practitioners less well-versed in CSS styling (myself included). Streamlit also has a larger community for support.
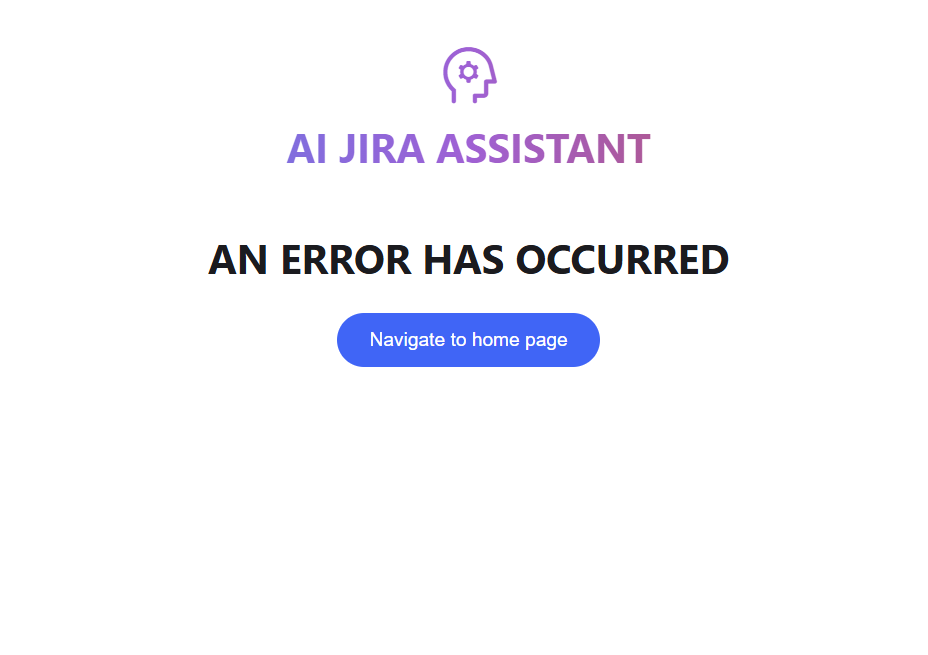
From the code snippet, we can set up different page routes. The project only contains two pages. The main page and an error page.
import mesop as me
# local imports try: from .utils import ui_components except Exception: from utils import ui_components
def render_error_page(): is_mobile = me.viewport_size().width < 640 with me.box( style=me.Style( position="sticky", width="100%", display="block", height="100%", font_size=50, text_align="center", flex_direction="column" if is_mobile else "row", gap=10, margin=me.Margin(bottom=30), ) ): me.text( "AN ERROR HAS OCCURRED", style=me.Style( text_align="center", font_size=30, font_weight=700, padding=me.Padding.all(8), background="white", justify_content="center", display="flex", width="100%", ), ) me.button( "Navigate to home page", type="flat", on_click=navigate_home )
We must also create the State class, this allows data to persist within the event loop.
import mesop as me
@me.stateclass class State: input: str output: str in_progress: bool
To clear the model output from the interface, we can then assign the output variable to an empty string. There are also different button supported types, as of writing are; default, raised, flat and stroked.
def clear_output(): with me.box(style=me.Style(margin=me.Margin.all(15))): with me.box(style=me.Style(display="flex", flex_direction="row", gap=12)): me.button("Clear output", type="flat", on_click=delete_state_helper)
Similarly, to send the request to the Django service we use the code snippet below. We use a Walrus Operator (:=) to determine if the request has received a valid response as not None (status code 200) and append the output to the state so it can be rendered in the UI, otherwise we redirect the user to the error page as previously discussed.
For completeness, I have provided the request code to the Django endpoint for running the AI Jira Agent.
import requests
# local imports from . import config
def call_jira_agent(request): try: data = {"request": request} if (response := requests.post(f"{config.DJANGO_URL}api/jira-agent/", data=data)) and (response.status_code == 200) and (output := response.json().get("output")): return f"Request: {request}<br>Output: {output}<br><br>" except Exception as e: print(f"ERROR call_jira_agent: {e}")
For this to run locally, I have included the relevant Docker and Docker compose files.
This Docker file for running Mesop was provided via the Mesop project homepage.
The Docker compose file consists of three services. The back-end Django application, the front-end Mesop application and a PostgreSQL database instance to be used in conjunction with the Django application.
I wanted to call out the environment variable being passed into the Mesop Docker container, PYTHONUNBUFFERED=1 ensures Python output, stdout, and stderr streams are sent to the terminal. Having used the recommended Docker image for Mesop applications it took me some time to determine the root cause of not seeing any output from the application.
The DOCKER_RUNNING=true environment variable is a convention to simply determine if the application is being run within Docker or for example within a virtual environment.
It is important to point out that environment variables will be populated via the config file ‘config.ini’ within the config sub-directory referenced by the env_file element in the Docker compose file.
To run the project, you must populate this config file with your Open AI and Jira credentials.
In this article, I will cover apps, models, serializers, views and PostgreSQL database integration.
An app is a logically separated web application that has a specific purpose.
In our instance, we have named the app “api” and is created by running the following command.
django-admin startapp api
Within the views.py file, we define our API endpoints.
“A view function, or view for short, is a Python function that takes a web request and returns a web response. This response can be the HTML contents of a web page, or a redirect, or a 404 error, or an XML document, or an image . . . or anything, really. The view itself contains whatever arbitrary logic is necessary to return that response.” — Django website
The endpoint routes to Django views are defined in the app urls.py file as below. The urls.py file is created at the initialization of the app. We have three endpoints in this project; a health check endpoint, an endpoint for returning all records stored within the database and an endpoint for handling the call out to the AI agent.
The views are declared classes, which is the standard convention within Django. Please see the file in its completeness.
Most of the code is self-explanatory though this snippet is significant as it will saves the models data to the database.
The snippet below returns all records in the DB from the ModelRequest model, I will cover models next.
class GetRecords(APIView): def get(self, request): """Get request records endpoint""" data = models.ModelRequest.objects.all().values() return Response({'result': str(data)})
“A model is the single, definitive source of information about your data. It contains the essential fields and behaviors of the data you’re storing. Generally, each model maps to a single database table.” — Django website
Our model for this project is simple as we only want to store the user request and the final model output, both of which are text fields.
The __str__ method is a common Python convention which for example, is called by default in the print function. The purpose of this method is to return a human-readable string representation of an object.
The serializer maps fields from the model to validate inputs and outputs and turn more complex data types in Python data types. This can be seen in the views.py detailed previously.
“A ModelSerializer typically refers to a component of the Django REST framework (DRF). The Django REST framework is a popular toolkit for building Web APIs in Django applications. It provides a set of tools and libraries to simplify the process of building APIs, including serializers.
The ModelSerializer class provides a shortcut that lets you automatically create a Serializer class with fields that correspond to the Model fields.
The ModelSerializer class is the same as a regular Serializer class, except that:
It will automatically generate a set of fields for you, based on the model.
It will automatically generate validators for the serializer, such as unique_together validators.
It includes simple default implementations of .create() and .update().” — Geeks for geeks
The complete serializers.py file for the project is as follows.
For the PostgreSQL database integration, the config within the settings.py file must match the databse.ini file.
The default database settings must be changed to point at the PostgreSQL database, as this is not the default database integration for Django.
The database.ini file defines the config for the PostgreSQL database at initialization.
To ensure database migrations are applied once the Docker container has been run, we can use a bash script to apply the migrations and then run the server. Running migrations automatically will mean that the database is always modified with any change in definitions within source control for Django, which saves time in the long run.
The entry point to the Dockerfile is then changed to point at the bash script using the CMD instruction.
I’m using the existing LangChain agent functionality combined with the Jira toolkit, which is a wrapper around the Atlassian Python API.
The default library is quite useful out of the box, sometimes requiring some trial and error on the prompt though I’d think it should improve over time as research into the area progresses.
For this project however, I wanted to add some custom tooling to the agent. This can be seen as the function ‘triage’ below with the @tool decorator.
The function type hints and comment description of the tool are necessary to communicate to the agent what is expected when a call is made. The returned string of the function is observed by the agent, in this instance, we simply return “Task complete” such that the agent then ceases to conduct another step.
The custom triage tool performs the following steps;
Get all unresolved Jira tickets for the project
Get the description and summary for the Jira issue key the agent is conducting the triage on
Makes asynchronous LLM-based comparisons with all unresolved tickets and automatically tags the ones that appear related from a text-to-text comparison, then uses the Jira API to link them
An LLM is then used to generate; user stories, acceptance criteria and priority, leaving this model result as a comment on the primary ticket
from langchain.agents import AgentType, initialize_agent from langchain_community.agent_toolkits.jira.toolkit import JiraToolkit from langchain_community.utilities.jira import JiraAPIWrapper from langchain_openai import OpenAI from langchain.tools import tool from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
llm = OpenAI(temperature=0)
@tool def triage(ticket_number:str) -> None: """triage a given ticket and link related tickets""" ticket_number = str(ticket_number) all_tickets = jira_utils.get_all_tickets() primary_issue_key, primary_issue_data = jira_utils.get_ticket_data(ticket_number) find_related_tickets(primary_issue_key, primary_issue_data, all_tickets) user_stories_acceptance_criteria_priority(primary_issue_key, primary_issue_data) return "Task complete"
Both LLM tasks use a CO-STAR system prompt and chain-of-thought few-shot prompting strategy. Therefore I have abstracted these tasks into an LLMTask class.
They are instantiated in the following code snippet. Arguably, we could experiment with different LLMs for each tasks though in the interest of time I have not done any experimentation around this — please feel free to comment below if you do pull the repo and have any experience to share.
For the linking tasks, the CO-STAR system prompt is below. The headings of Context, Objective, Style, Tone, Audience and Response are the standard headings for the CO-STAR method. We define the context and outputs including the tagging of each element of the model results.
Explicitly defining the audience, style and tone helps to ensure the model output is appropriate for a business context.
# CONTEXT # I want to triage newly created Jira tickets for our software company by comparing them to previous tickets. The first ticket will be in <ticket1> tags and the second ticket will be in <ticket2> tags.
# OBJECTIVE # Determine if two tickets are related if the issue describes similar tasks and return True in <related> tags, also include your thinking in <thought> tags.
# STYLE # Keep reasoning concise but logical.
# TONE # Create an informative tone.
# AUDIENCE # The audience will be business stake holders, product stakeholders and software engineers.
# RESPONSE # Return a boolean if you think the tickets are related in <related> tags and also return your thinking as to why you think the tickets are related in <thought> tags.
For performing the product style ticket evaluation (user stories, acceptance criteria, and priority), the system prompt is below. We explicitly define the priority as either LOW, MEDIUM, or HIGH.
We also dictate that the model has the style of a product owner/ manager for which this task would have traditionally been conducted.
# CONTEXT # You are a product owner working in a large software company, you triage new tickets from their descriptions in <description> tags as they are raised from users.
# OBJECTIVE # From the description in <description> tags, you should write the following; user stories in <user_stories> tags, acceptance criteria in <acceptance_criteria> tags and priority in <priority>. Priority must be either LOW, MEDIUM OR HIGH depending on the what you deem is most appropriate for the given description. Also include your thinking in <thought> tags for the priority.
# STYLE # Should be in the style of a product owner or manager.
# TONE # Use a professional and business oriented tone.
# AUDIENCE # The audience will be business stake holders, product stakeholders and software engineers.
# RESPONSE # Respond with the following format. User stories in <user_stories> tags. Acceptance criteria in <acceptance_criteria> tags. Priority in <priority> tags.
I will now provide the Chain-of-thought few-shot prompt for linking Jira tickets, we append both the summary and description for both tickets in <issue1> and <issue2> tags respectively. The thinking of the model is captured in the <thought> tags in the model output, this constitutes the Chain-of-Thought element.
The few-shot designation comes from the point that multiple examples are being fed into the model.
The <related> tags contain the determination if the two tickets provided are related or not, if the model deems them to be related then a value of True is returned.
We later regex parse the model output and have a helper function to link the related tickets via the Jira API, all Jira API helper functions for this project are provided later in the article.
"examples_linking": [ { "input": "<issue1>Add Jira integration ticket creation Add a Jira creation widget to the front end of the website<issue1><issue2>Add a widget to the front end to create a Jira Add an integration to the front end to allow users to generated Jira tickets manually<issue2>", "output": "<related>True<related><thought>Both tickets relate to a Jira creation widget, they must be duplicate tickets.<thought>" }, { "input": "<issue1>Front end spelling error There is a spelling error for the home page which should read 'Welcome to the homepage' rather than 'Wellcome to the homepage'<issue1><issue2>Latency issue there is a latency issue and the calls to the Open AI should be made asynchronous<issue2>", "output": "<related>False<related><thought>The first ticket is in relation to a spelling error and the second is a latency, therefore they are not related.<thought>" }, { "input": "<issue1>Schema update We need to add a column for model requests and responses<issue1><issue2>Update schema to include both model requests and model responses Add to two new additional fields to the schema<issue2>", "output": "<related>True<related><thought>Both tickets reference a schema update with two new fields for model requests and model responses, therefore they must be related.<thought>" } ]
Similarly for ticket evaluation, the user story is provided in <user_stories> tags, acceptance criteria in <acceptance_criteria> tags, and priority in <priority> tags. The <thought> tags are also used for capturing the reasoning from the model specifically in terms of the priority given.
All of the examples were annotated manually by myself.
"examples_product": [ { "input": "<description>Add Jira integration ticket creation Add a Jira creation widget to the front end of the website<description>", "output": "<user_stories>As a user, I want to be able to create a Jira ticket directly from the website.nAs a product owner, I want to streamline the process of creating Jira tickets for our team.<user_stories>n<acceptance_criteria>The Jira creation widget should be easily accessible on the front end of the website.nThe widget should allow users to input all necessary information for a Jira ticket, such as title, description, and assignee.nOnce submitted, the widget should create a new Jira ticket in the designated project.nThe widget should have proper error handling in case of any issues with creating the ticket.<acceptance_criteria>n<priority>MEDIUM<priority>n<thought>By adding a Jira integration and creation widget to the website, we can improve the efficiency and accuracy of creating Jira tickets for our team. This will ultimately save time and resources for both the business and the development team. Though there is no immediate need for this to be completed. Therefore, I believe this ticket should be prioritized as MEDIUM.<thought>" }, { "input": "<description>Urgent schema update We need to add a column for model requests and responses for compliance<description>", "output": "<user_stories>As a developer, I want to be able to view and track model requests and responses for compliance purposes.nAs a product owner, I want to ensure our system is compliant with regulations and standards.<user_stories>n<acceptance_criteria>A new column should be added to the schema for model requests and responses.nThe column should accurately track and store all relevant information for compliance purposes.nThe column should be easily accessible and viewable for authorized users.nThe update should not disrupt any existing functionality of the system.<acceptance_criteria>n<priority>HIGH<priority>n<thought>This ticket is marked as urgent, indicating that it is a high priority for the business. Compliance is a critical aspect of our business and it is important that we address this issue as soon as possible. By adding a new column for model requests and responses, we can ensure that our system is compliant and avoid any potential legal or regulatory issues. Therefore, I believe this ticket should be prioritized as HIGH.<thought>" }, { "input": "<description>Homepage CSS error There is a CSS error for the homepage which is affecting a call to action button and negatively impacting conversion<description>", "output": "<user_stories>As a user, I want the CSS error on the homepage to be fixed so that I can easily access the call to action button.nAs a product owner, I want to improve the conversion rate of our website by fixing any CSS errors.<user_stories>n<acceptance_criteria>The CSS error should be identified and fixed on the homepage.nThe call to action button should be easily visible and accessible for users.nThe fix should not affect any other functionality of the website.<acceptance_criteria>n<priority>HIGH<priority>n<thought>This CSS error is directly impacting the conversion rate of our website, which is a key metric for our business. It is important that we address this issue as soon as possible to improve the user experience and ultimately increase conversions. Therefore, I believe this ticket should be prioritized as HIGH.<thought>" } ],
This code snippet uses a muti-threaded approach to linking Jira issues concurrently. This will vastly reduce the time it takes to make pair comparisons with all the open tickets within a project to determine if they are related.
def check_issue_and_link_helper(args): key, data, primary_issue_key, primary_issue_data = args if key != primary_issue_key and llm_check_ticket_match(primary_issue_data, data): jira_utils.link_jira_issue(primary_issue_key, key)
def find_related_tickets(primary_issue_key, primary_issue_data, issues): args = [(key, data, primary_issue_key, primary_issue_data) for key, data in issues.items()] with concurrent.futures.ThreadPoolExecutor(os.cpu_count()) as executor: executor.map(check_issue_and_link_helper, args)
def llm_check_ticket_match(ticket1, ticket2): llm_result = linking_model.run_llm(f"<ticket1>{ticket1}<ticket1><ticket2>{ticket2}<ticket2>") if ((result := jira_utils.extract_tag_helper(llm_result))) and (result == 'True'): return True
An example workflow of the tool, creating a ticket and triaging it.
Working ticket creation and triage
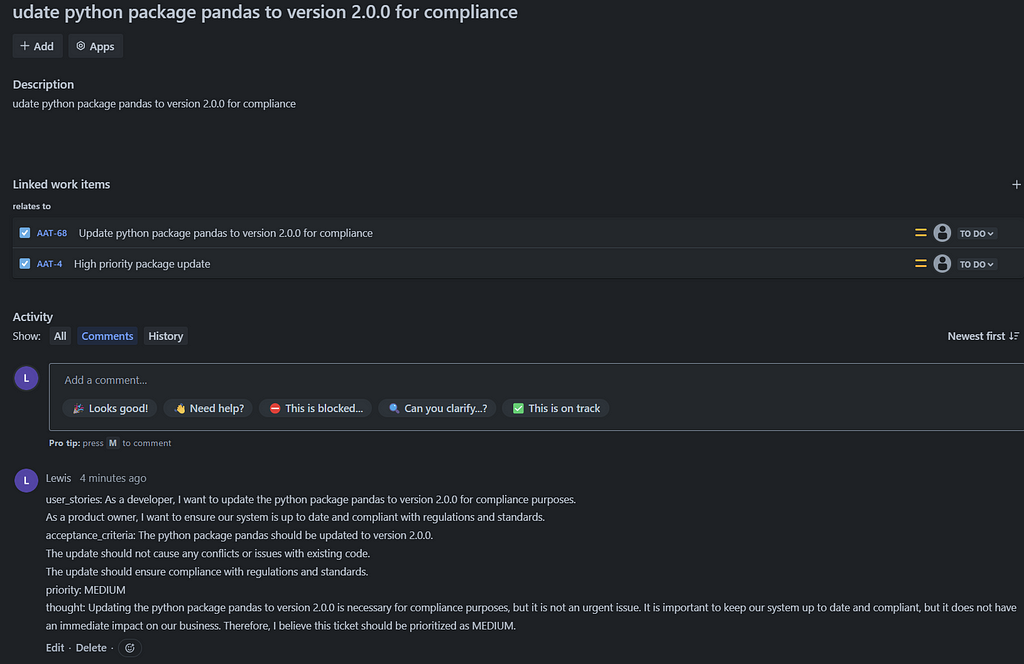
The result of these actions is captured in Jira ticket. Related tickets have been linked automatically, the user stories, acceptance criteria, priority and thought have been captured as a Jira comment.
Linked tickets, user stories, acceptance criteria and priority
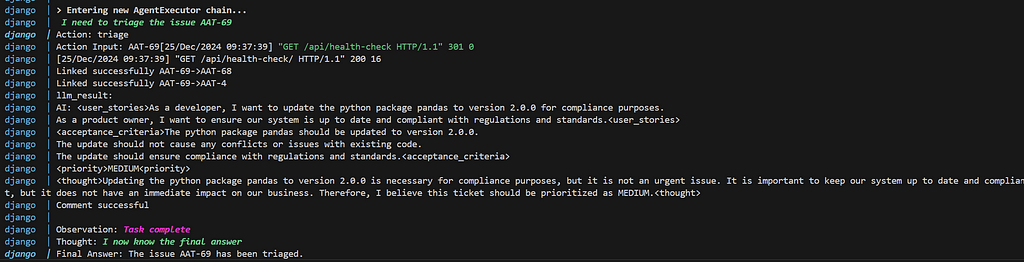
We can see the agent intermediate steps in the print statements of the Docker container.
Agent output for triage step
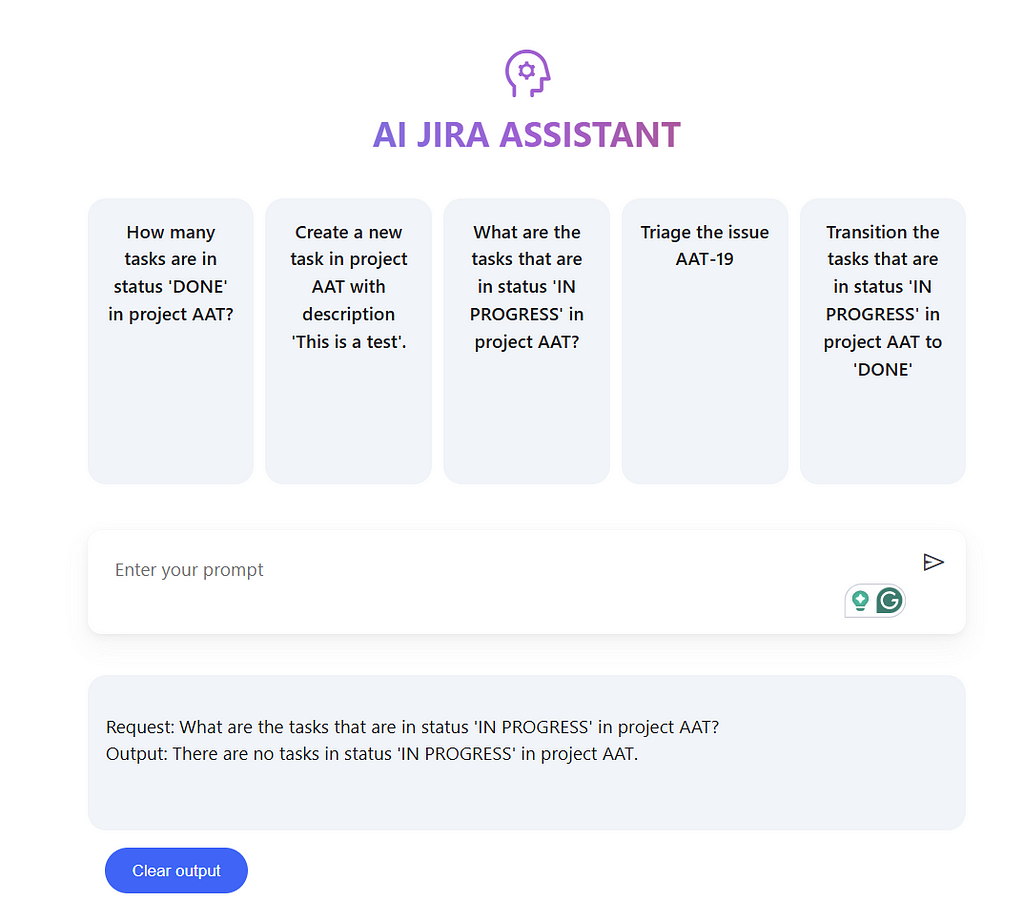
5. Jira API examples
AI Jira Assitant finding in progress tickets
All examples in this project where I have explicitly used the Jira REST API have been included below for visibility.
The regex extraction helper function used to parse model results is also included. There is also a Python SDK for Jira though I elected to use the requests library in this instance such that is more easily translated into other programming languages.
6. Next steps
The natural next step would be to include code generation by integrating with source control for a near fully automated software development lifecycle, with a human in the loop this could be a feasible solution.
We can already see that AI code generation is making an impact on the enterprise — if BAU tasks can be partially automated then software developers/product practitioners can focus on more interesting and meaningful work.
If there is a lot of interest on this article then perhaps I could look into this as a follow-up project.
I hope you found this article insightful, as promised — you can find all the code in the Github repo here, and feel free to connect with me on LinkedIn also.
A few words on thresholding, the softmax activation function, introducing an extra label, and considerations regarding output activation functions.
In many real-world applications, machine learning models are not designed to make decisions in an all-or-nothing manner. Instead, there are situations where it is more beneficial for the model to flag certain predictions for human review — a process known as human-in-the-loop. This approach is particularly valuable in high-stakes scenarios such as fraud detection, where the cost of false negatives is significant. By allowing humans to intervene when a model is uncertain or encounters complex cases, businesses can ensure more nuanced and accurate decision-making.
In this article, we will explore how thresholding, a technique used to manage model uncertainty, can be implemented within a deep learning setting. Thresholding helps determine when a model is confident enough to make a decision autonomously and when it should defer to human judgment. This will be done using a real-world example to illustrate the potential.
By the end of this article, the hope is to provide both technical teams and business stakeholders with some tips and inspiration for making decisions about modelling, thresholding strategies, and the balance between automation and human oversight.
Business Case: Detecting Fraudulent Transactions with Confidence
To illustrate the value of thresholding in a real-world situation, let’s consider the case of a financial institution tasked with detecting fraudulent transactions. We’ll use the Kaggle fraud detection dataset (DbCL license), which contains anonymized transaction data with labels for fraudulent activity. The institutions process lots of transactions, making it difficult to manually review each one. We want to develop a system that accurately flags suspicious transactions while minimizing unnecessary human intervention.
The challenge lies in balancing precision and efficiency. Thresholding is a strategy used to introduce this trade-off. With this strategy we add an additional label to the sample space—unknown. This label serves as a signal from the model when it is uncertain about a particular prediction, effectively deferring the decision to human review. In situations where the model lacks enough certainty to make a reliable prediction, marking a transaction as unknown ensures that only the most confident predictions are acted upon.
Also, thresholding might come with another positive side effect. It helps overcome potential tech skepticism. When a model indicates uncertainty and defers to human judgment when needed, it can foster greater trust in the system. In previous projects, this has been of help when rolling projects out in various organisations.
Technical and analytical aspects.
We will explore the concept of thresholding in a deep learning context. However, it’s important to note that thresholding is a model agnostic technique with application across various types of situations, not just deep learning.
When implementing a thresholding step in a neural network, it is not obvious in what layer to put it. In a classification setting, an output transformation can be implemented. The sigmoid function is an option, but also a softmax function. Softmax offers a very practical transformation, making the logits adhere to certain nice statistical properties. These properties are that we are guaranteed logits will sum to one, and they will all be between zero and one.
Softmax function. Image by author.
However, in this process, some information is lost. Softmax captures only the relative certainty between labels. It does not provide an absolute measure of certainty for any individual label, which in turn can lead to overconfidence in cases where the true distribution of uncertainty is more nuanced. This limitation becomes critical in applications requiring precise decision thresholds.
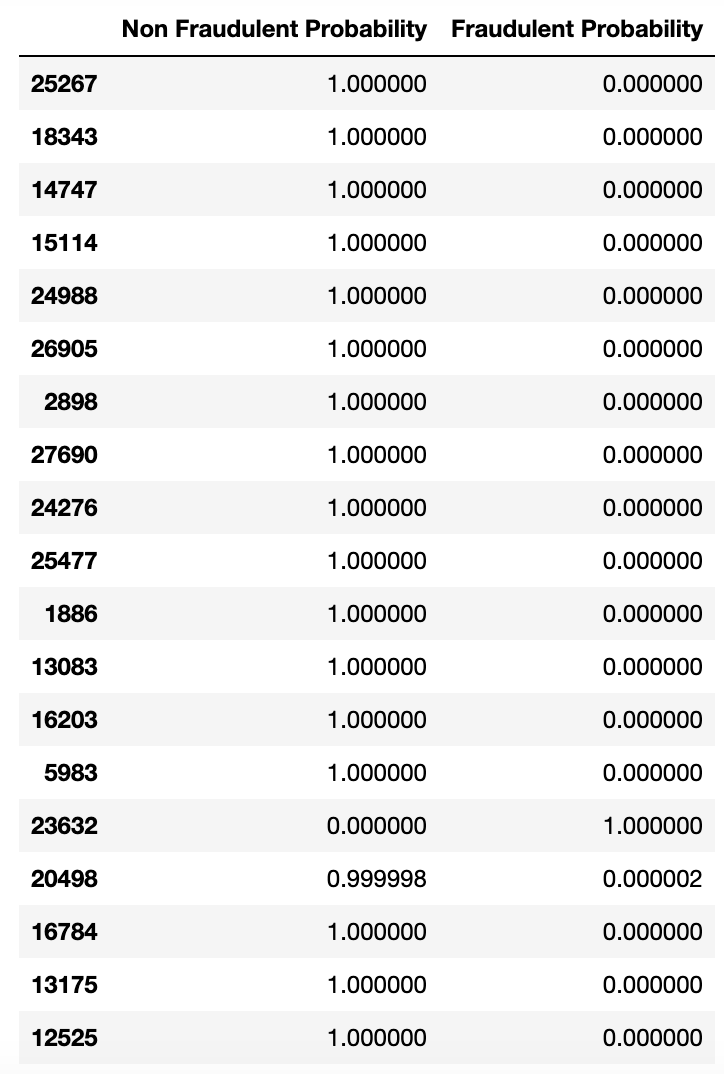
This article will not delve into the details of the model architecture, as these are covered in an upcoming article for those interested. The only thing being used from the model are the outcomes before and after the softmax transformation has been implemented, as the final layer. A sample of the output is depicted here.
Sample of twenty predictions, after softmax has been applied.
As seen, the outputs are rather homogenic. And without knowing the mechanics of the softmax, it looks as if the model is pretty certain about the classifications. But as we will see further down in the article, the strong relationship we are capturing here is not the true certainty of the labels. Rather, this is to be interpreted as one label’s predictions in comparison with the other. In our case, this means the model may capture some labels as being significantly more likely than others, but it does not reflect the overall certainty of the model.
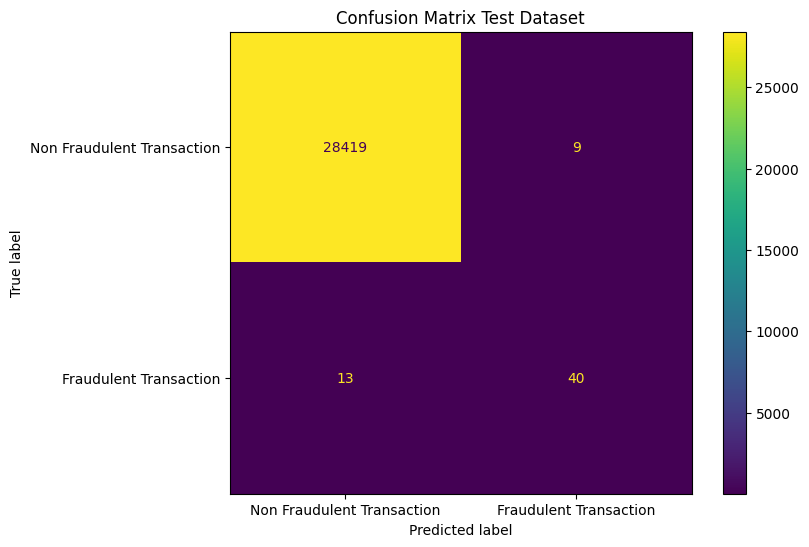
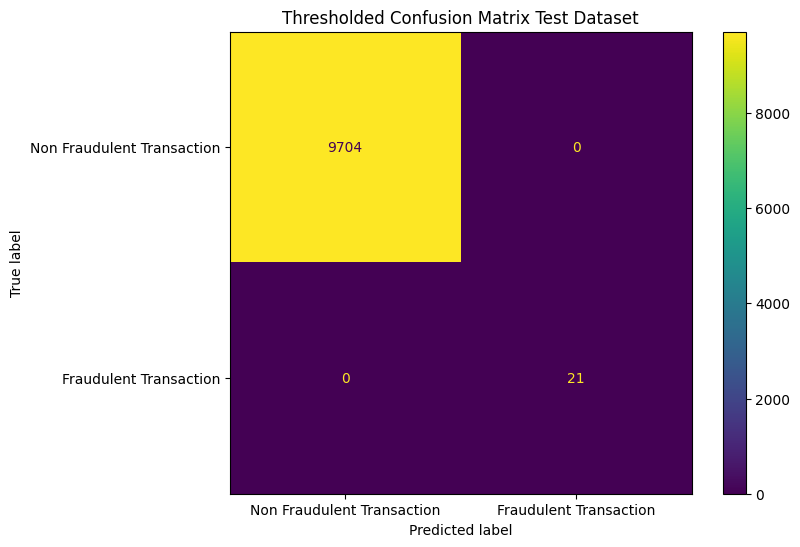
With this understanding of the interpretation of the outputs, let’s explore how the model performs in practice. Looking at the confusion matrix.
Confusion matrix for the entire, un-thresholded test dataset.
The model does not perform terribly, although it is far from perfect. With these base results at hand, we will look into implementing a threshold.
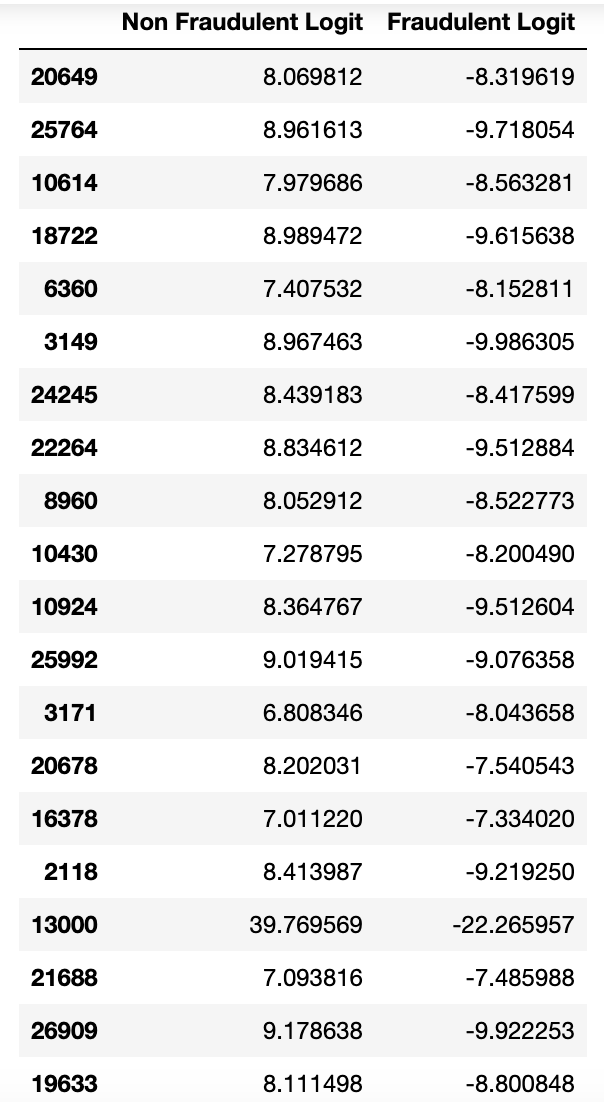
We will be starting out going one layer into the network — examining the values right before the final activation function. This renders the following logits.
Sample of twenty predictions, before softmax transformation have been applied.
Here we see a larger variety of values. This layer provides a more detailed view of the model’s uncertainty in its predictions and it is here where the threshold layer is inserted.
By introducing an upper and lower confidence threshold, the model only labels approximately 34% of the dataset, focusing on the most certain predictions. But in turn, the results are more certain, depicted in the following confusion matrix. It’s important to note that thresholding does not have to be uniform. For example, some labels may be more difficult to predict than others, and label imbalance can also affect the thresholding strategy.
Confusion matrix after thresholding have been applied.
Metrics.
In this scenario, we have only touched upon the two edge cases in thresholding; the ones letting all predictions through (base case) and the ones that removed all faulty predictions.
Based on practical experience, deciding whether to label fewer data points with high certainty (which might reduce the total number of flagged transactions) or label more data points with lower certainty is quite a complex trade-off. This decision can impact operational efficiency and could be informed by business priorities, such as risk tolerance or operational constraints. Discussing this together with subject matter experts is a perfectly viable way of figuring out the thresholds. Another, is if you are able to optimise this in conjunction with a known or approximated metric. This can be done by aligning thresholds with specific business metrics, such as cost per false negative or operational capacity.
Summarization.
In conclusion, the goal is not to discard the softmax transformation, as it provides valuable statistical properties. Rather, we suggest introducing an intermediate threshold layer to filter out uncertain predictions and leave room for an unknown label when necessary.
The exact way to implement this I believe comes down to the project at hand. The fraud example also highlights the importance of understanding the business need aimed to solve. Here, we showed an example where we had thresholded away all faulty predictions, but this is not at all necessary in all use cases. In many cases, the optimal solution lies in finding a balance between accuracy and coverage.
Thank you for taking the time to explore this topic.
I hope you found this article useful and/or inspiring. If you have any comments or questions, please reach out. You can also connect with me on LinkedIn.
Using knowledge graphs and AI to retrieve, filter, and summarize medical journal articles
The accompanying code for the app and notebook are here.
Knowledge graphs (KGs) and Large Language Models (LLMs) are a match made in heaven. My previousposts discuss the complementarities of these two technologies in more detail but the short version is, “some of the main weaknesses of LLMs, that they are black-box models and struggle with factual knowledge, are some of KGs’ greatest strengths. KGs are, essentially, collections of facts, and they are fully interpretable.”
This article is all about building a simple Graph RAG app. What is RAG? RAG, or Retrieval-Augmented Generation, is about retrieving relevant information to augment a prompt that is sent to an LLM, which generates a response. Graph RAG is RAG that uses a knowledge graph as part of the retrieval portion. If you’ve never heard of Graph RAG, or want a refresher, I’d watch this video.
The basic idea is that, rather than sending your prompt directly to an LLM, which was not trained on your data, you can supplement your prompt with the relevant information needed for the LLM to answer your prompt accurately. The example I use often is copying a job description and my resume into ChatGPT to write a cover letter. The LLM is able to provide a much more relevant response to my prompt, ‘write me a cover letter,’ if I give it my resume and the description of the job I am applying for. Since knowledge graphs are built to store knowledge, they are a perfect way to store internal data and supplement LLM prompts with additional context, improving the accuracy and contextual understanding of the responses.
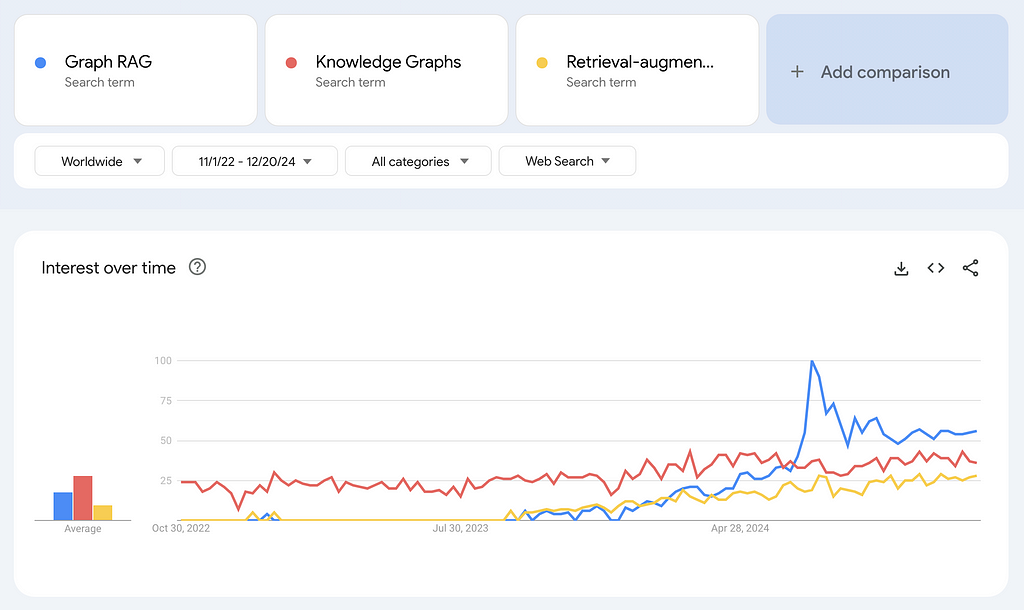
Graph RAG has experienced a surge in search interest, even surpassing terms like knowledge graphs and retrieval-augmented generation. Note that Google Trends measures relative search interest, not absolute number of searches. The spike in July 2024 for searches of Graph RAG coincides with the week Microsoft announced that their GraphRAG application would be available on GitHub.
The excitement around Graph RAG is broader than just Microsoft, however. Samsung acquired RDFox, a knowledge graph company, in July of 2024. The article announcing that acquisition did not mention Graph RAG explicitly, but in this article in Forbes published in November 2024, a Samsung spokesperson stated, “We plan to develop knowledge graph technology, one of the main technologies of personalized AI, and organically connect with generated AI to support user-specific services.”
In October 2024, Ontotext, a leading graph database company, and Semantic Web company, the maker of PoolParty, a knowledge graph curation platform, merged to form Graphwise. According to the press release, the merger aims to “democratize the evolution of Graph RAG as a category.”
While some of the buzz around Graph RAG may come from the broader excitement surrounding chatbots and generative AI, it reflects a genuine evolution in how knowledge graphs are being applied to solve complex, real-world problems. One example is that LinkedIn applied Graph RAG to improve their customer service technical support. Because the tool was able to retrieve the relevant data (like previously solved similar tickets or questions) to feed the LLM, the responses were more accurate and the mean resolution time dropped from 40 hours to 15 hours.
This post will go through the construction of a pretty simple, but I think illustrative, example of how Graph RAG can work in practice. The end result is an app that a non-technical user can interact with. Like my last post, I will use a dataset consisting of medical journal articles from PubMed. The idea is that this is an app that someone in the medical field could use to do literature review. The same principles can be applied to many use cases however, which is why Graph RAG is so exciting.
The structure of the app, along with this post is as follows:
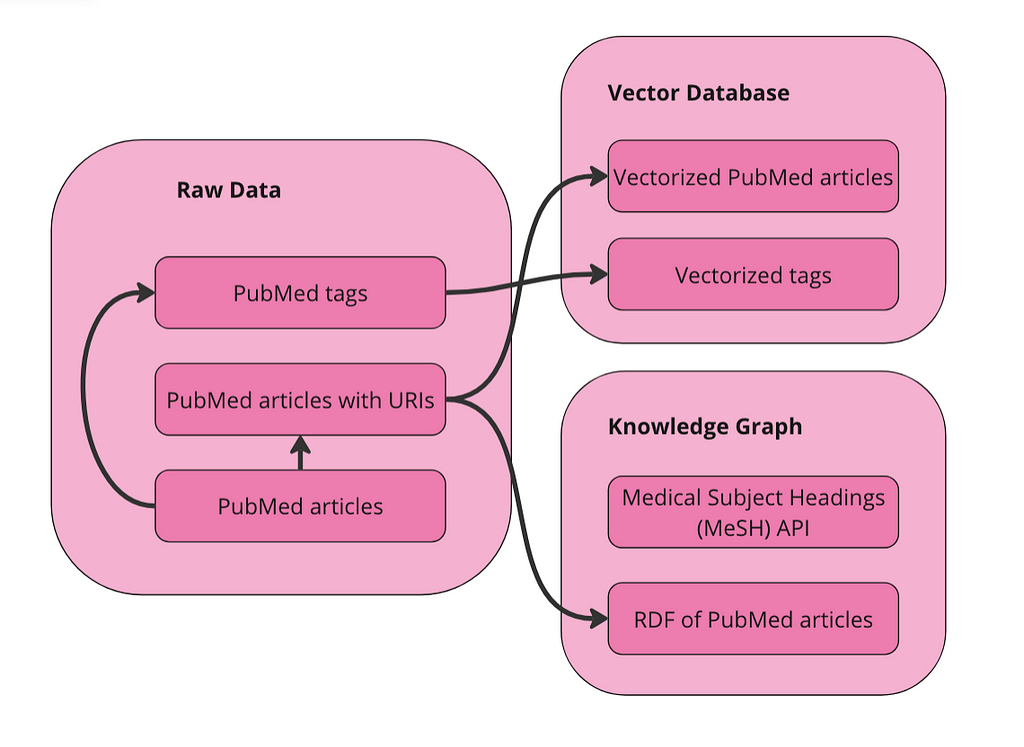
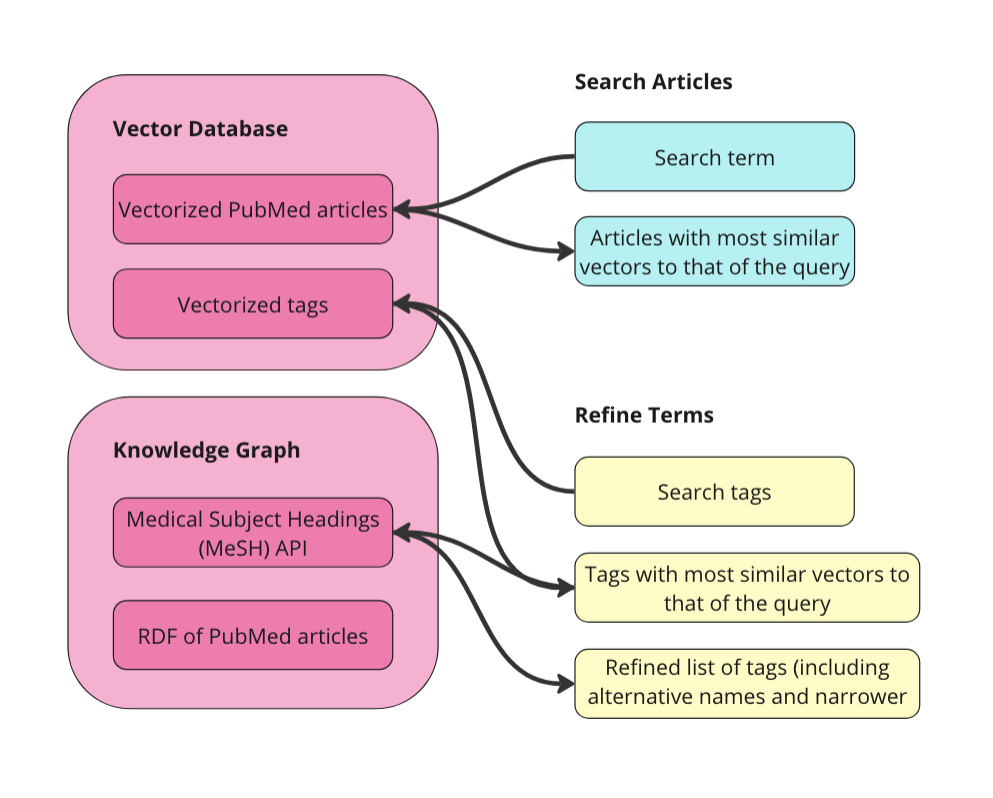
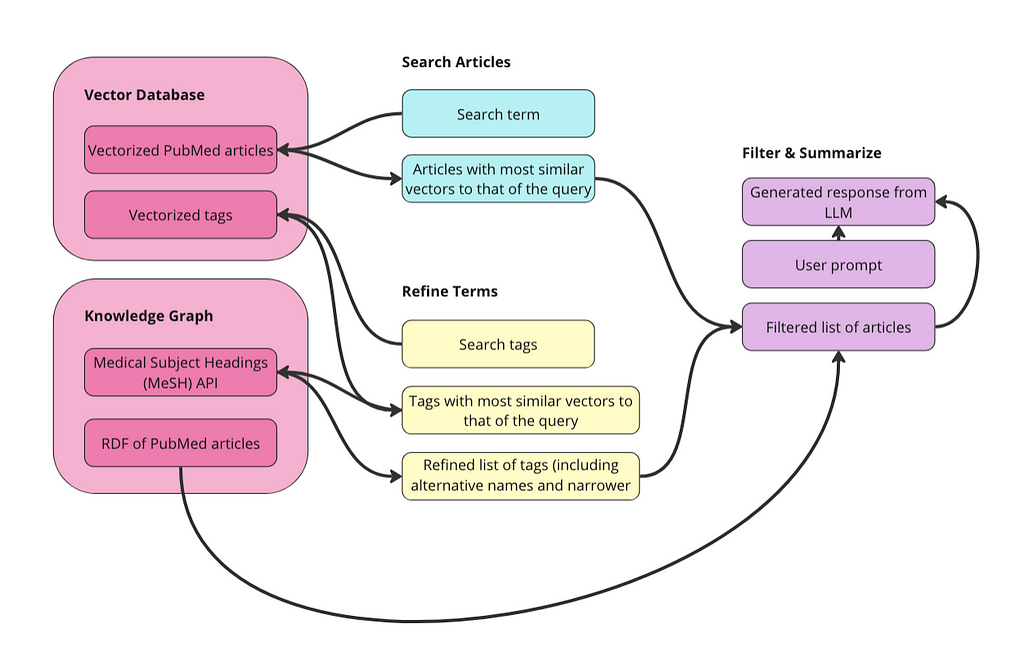
Step zero is preparing the data. I will explain the details below but the overall goal is to vectorize the raw data and, separately, turn it into an RDF graph. As long as we keep URIs tied to the articles before we vectorize, we can navigate across a graph of articles and a vector space of articles. Then, we can:
Search Articles: use the power of the vector database to do an initial search of relevant articles given a search term. I will use vector similarity to retrieve articles with the most similar vectors to that of the search term.
Refine Terms: explore the Medical Subject Headings (MeSH) biomedical vocabulary to select terms to use to filter the articles from step 1. This controlled vocabulary contains medical terms, alternative names, narrower concepts, and many other properties and relationships.
Filter & Summarize: use the MeSH terms to filter the articles to avoid ‘context poisoning’. Then send the remaining articles to an LLM along with an additional prompt like, “summarize in bullets.”
Some notes on this app and tutorial before we get started:
This set-up uses knowledge graphs exclusively for metadata. This is only possible because each article in my dataset has already been tagged with terms that are part of a rich controlled vocabulary. I am using the graph for structure and semantics and the vector database for similarity-based retrieval, ensuring each technology is used for what it does best. Vector similarity can tell us “esophageal cancer” is semantically similar to “mouth cancer”, but knowledge graphs can tell us the details of the relationship between “esophageal cancer” and “mouth cancer.”
The data I used for this app is a collection of medical journal articles from PubMed (more on the data below). I chose this dataset because it is structured (tabular) but also contains text in the form of abstracts for each article, and because it is already tagged with topical terms that are aligned with a well-established controlled vocabulary (MeSH). Because these are medical articles, I have called this app ‘Graph RAG for Medicine.’ But this same structure can be applied to any domain and is not specific to the medical field.
What I hope this tutorial and app demonstrate is that you can improve the results of your RAG application in terms of accuracy and explainability by incorporating a knowledge graph into the retrieval step. I will show how KGs can improve the accuracy of RAG applications in two ways: by giving the user a way of filtering the context to ensure the LLM is only being fed the most relevant information; and by using domain specific controlled vocabularies with dense relationships that are maintained and curated by domain experts to do the filtering.
What this tutorial and app don’t directly showcase are two other significant ways KGs can enhance RAG applications: governance, access control, and regulatory compliance; and efficiency and scalability. For governance, KGs can do more than filter content for relevancy to improve accuracy — they can enforce data governance policies. For instance, if a user lacks permission to access certain content, that content can be excluded from their RAG pipeline. On the efficiency and scalability side, KGs can help ensure RAG applications don’t die on the shelf. While it’s easy to create an impressive one-off RAG app (that’s literally the purpose of this tutorial), many companies struggle with a proliferation of disconnected POCs that lack a cohesive framework, structure, or platform. That means many of those apps are not going to survive long. A metadata layer powered by KGs can break down data silos, providing the foundation needed to build, scale, and maintain RAG applications effectively. Using a rich controlled vocabulary like MeSH for the metadata tags on these articles is a way of ensuring this Graph RAG app can be integrated with other systems and reducing the risk that it becomes a silo.
As mentioned, I’ve again decided to use this dataset of 50,000 research articles from the PubMed repository (License CC0: Public Domain). This dataset contains the title of the articles, their abstracts, as well as a field for metadata tags. These tags are from the Medical Subject Headings (MeSH) controlled vocabulary thesaurus. The PubMed articles are really just metadata on the articles — there are abstracts for each article but we don’t have the full text. The data is already in tabular format and tagged with MeSH terms.
We can vectorize this tabular dataset directly. We could turn it into a graph (RDF) before we vectorize, but I didn’t do that for this app and I don’t know that it would help the final results for this kind of data. The most important thing about vectorizing the raw data is that we add Unique Resource Identifiers (URIs) to each article first. A URI is a unique ID for navigating RDF data and it is necessary for us to go back and forth between vectors and entities in our graph. Additionally, we will create a separate collection in our vector database for the MeSH terms. This will allow the user to search for relevant terms without having prior knowledge of this controlled vocabulary. Below is a diagram of what we are doing to prepare our data.
Image by Author
We have two collections in our vector database to query: articles and terms. We also have the data represented as a graph in RDF format. Since MeSH has an API, I am just going to query the API directly to get alternative names and narrower concepts for terms.
Vectorize data in Weaviate
First import the required packages and set up the Weaviate client:
import weaviate from weaviate.util import generate_uuid5 from weaviate.classes.init import Auth import os import json import pandas as pd
client = weaviate.connect_to_weaviate_cloud( cluster_url="XXX", # Replace with your Weaviate Cloud URL auth_credentials=Auth.api_key("XXX"), # Replace with your Weaviate Cloud key headers={'X-OpenAI-Api-key': "XXX"} # Replace with your OpenAI API key )
Read in the PubMed journal articles. I am using Databricks to run this notebook so you may need to change this, depending on where you run it. The goal here is just to get the data into a pandas DataFrame.
df = spark.sql("SELECT * FROM workspace.default.pub_med_multi_label_text_classification_dataset_processed").toPandas()
If you’re running this locally, just do:
df = pd.read_csv("PubMed Multi Label Text Classification Dataset Processed.csv")
Then clean the data up a bit:
import numpy as np # Replace infinity values with NaN and then fill NaN values df.replace([np.inf, -np.inf], np.nan, inplace=True) df.fillna('', inplace=True)
# Convert columns to string type df['Title'] = df['Title'].astype(str) df['abstractText'] = df['abstractText'].astype(str) df['meshMajor'] = df['meshMajor'].astype(str)
Now we need to create a URI for each article and add that in as a new column. This is important because the URI is the way we can connect the vector representation of an article with the knowledge graph representation of the article.
# Function to create a valid URI def create_valid_uri(base_uri, text): if pd.isna(text): return None # Encode text to be used in URI sanitized_text = urllib.parse.quote(text.strip().replace(' ', '_').replace('"', '').replace('<', '').replace('>', '').replace("'", "_")) return URIRef(f"{base_uri}/{sanitized_text}")
# Function to create a valid URI for Articles def create_article_uri(title, base_namespace="http://example.org/article/"): """ Creates a URI for an article by replacing non-word characters with underscores and URL-encoding.
Args: title (str): The title of the article. base_namespace (str): The base namespace for the article URI.
Returns: URIRef: The formatted article URI. """ if pd.isna(title): return None # Replace non-word characters with underscores sanitized_title = re.sub(r'W+', '_', title.strip()) # Condense multiple underscores into a single underscore sanitized_title = re.sub(r'_+', '_', sanitized_title) # URL-encode the term encoded_title = quote(sanitized_title) # Concatenate with base_namespace without adding underscores uri = f"{base_namespace}{encoded_title}" return URIRef(uri)
# Add a new column to the DataFrame for the article URIs df['Article_URI'] = df['Title'].apply(lambda title: create_valid_uri("http://example.org/article", title))
We also want to create a DataFrame of all of the MeSH terms that are used to tag the articles. This will be helpful later when we want to search for similar MeSH terms.
# Function to clean and parse MeSH terms def parse_mesh_terms(mesh_list): if pd.isna(mesh_list): return [] return [ term.strip().replace(' ', '_') for term in mesh_list.strip("[]'").split(',') ]
# Function to create a valid URI for MeSH terms def create_valid_uri(base_uri, text): if pd.isna(text): return None sanitized_text = urllib.parse.quote( text.strip() .replace(' ', '_') .replace('"', '') .replace('<', '') .replace('>', '') .replace("'", "_") ) return f"{base_uri}/{sanitized_text}"
# Extract and process all MeSH terms all_mesh_terms = [] for mesh_list in df["meshMajor"]: all_mesh_terms.extend(parse_mesh_terms(mesh_list))
# Create a DataFrame of MeSH terms and their URIs mesh_df = pd.DataFrame({ "meshTerm": unique_mesh_terms, "URI": [create_valid_uri("http://example.org/mesh", term) for term in unique_mesh_terms] })
# Display the DataFrame print(mesh_df)
Vectorize the articles DataFrame:
from weaviate.classes.config import Configure
#define the collection articles = client.collections.create( name = "Article", vectorizer_config=Configure.Vectorizer.text2vec_openai(), # If set to "none" you must always provide vectors yourself. Could be any other "text2vec-*" also. generative_config=Configure.Generative.openai(), # Ensure the `generative-openai` module is used for generative queries )
with articles.batch.dynamic() as batch: for index, row in df.iterrows(): batch.add_object({ "title": row["Title"], "abstractText": row["abstractText"], "Article_URI": row["Article_URI"], "meshMajor": row["meshMajor"], })
Now vectorize the MeSH terms:
#define the collection terms = client.collections.create( name = "term", vectorizer_config=Configure.Vectorizer.text2vec_openai(), # If set to "none" you must always provide vectors yourself. Could be any other "text2vec-*" also. generative_config=Configure.Generative.openai(), # Ensure the `generative-openai` module is used for generative queries )
with terms.batch.dynamic() as batch: for index, row in mesh_df.iterrows(): batch.add_object({ "meshTerm": row["meshTerm"], "URI": row["URI"], })
You can, at this point, run semantic search, similarity search, and RAG directly against the vectorized dataset. I won’t go through all of that here but you can look at the code in my accompanying notebook to do that.
Turn data into a knowledge graph
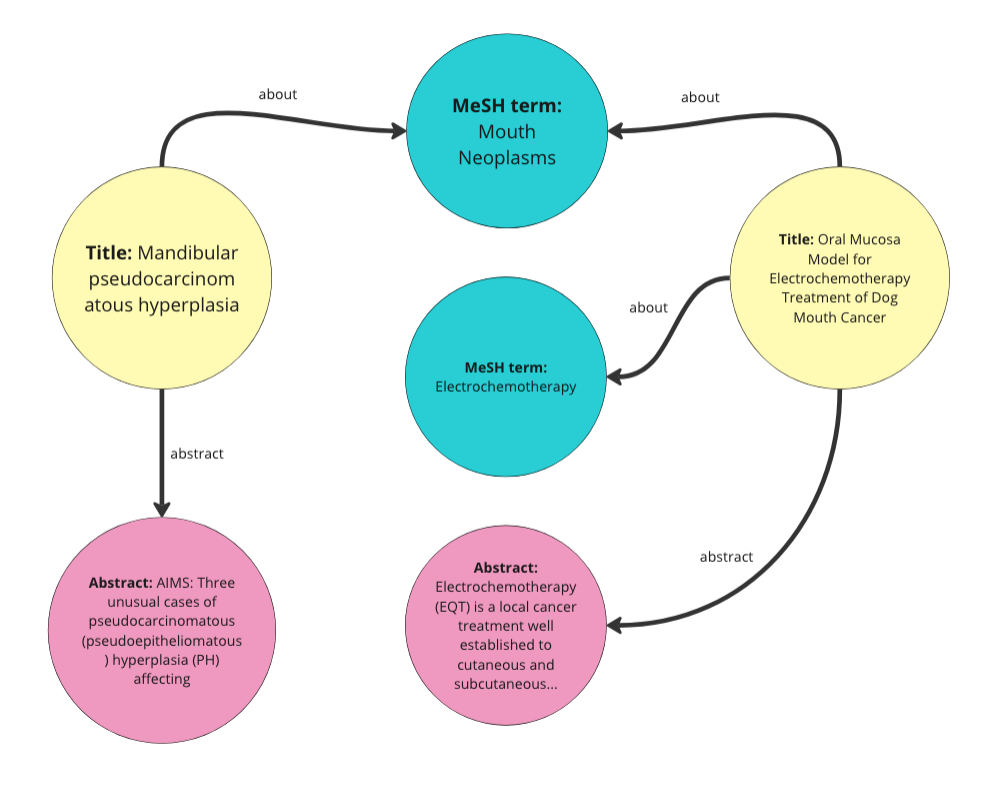
I am just using the same code we used in the last post to do this. We are basically turning every row in the data into an “Article” entity in our KG. Then we are giving each of these articles properties for title, abstract, and MeSH terms. We are also turning every MeSH term into an entity as well. This code also adds random dates to each article for a property called date published and a random number between 1 and 10 to a property called access. We won’t use those properties in this demo. Below is a visual representation of the graph we are creating from the data.
Image by Author
Here is how to iterate through the DataFrame and turn it into RDF data:
from rdflib import Graph, RDF, RDFS, Namespace, URIRef, Literal from rdflib.namespace import SKOS, XSD import pandas as pd import urllib.parse import random from datetime import datetime, timedelta import re from urllib.parse import quote
# --- Initialization --- g = Graph()
# Define namespaces schema = Namespace('http://schema.org/') ex = Namespace('http://example.org/') prefixes = { 'schema': schema, 'ex': ex, 'skos': SKOS, 'xsd': XSD } for p, ns in prefixes.items(): g.bind(p, ns)
# Function to clean and parse MeSH terms def parse_mesh_terms(mesh_list): if pd.isna(mesh_list): return [] return [term.strip() for term in mesh_list.strip("[]'").split(',')]
# Enhanced convert_to_uri function def convert_to_uri(term, base_namespace="http://example.org/mesh/"): """ Converts a MeSH term into a standardized URI by replacing spaces and special characters with underscores, ensuring it starts and ends with a single underscore, and URL-encoding the term.
Args: term (str): The MeSH term to convert. base_namespace (str): The base namespace for the URI.
Returns: URIRef: The formatted URI. """ if pd.isna(term): return None # Handle NaN or None terms gracefully
# Step 1: Strip existing leading and trailing non-word characters (including underscores) stripped_term = re.sub(r'^W+|W+$', '', term)
# Step 2: Replace non-word characters with underscores (one or more) formatted_term = re.sub(r'W+', '_', stripped_term)
# Step 3: Replace multiple consecutive underscores with a single underscore formatted_term = re.sub(r'_+', '_', formatted_term)
# Step 4: URL-encode the term to handle any remaining special characters encoded_term = quote(formatted_term)
# Step 5: Add single leading and trailing underscores term_with_underscores = f"_{encoded_term}_"
# Step 6: Concatenate with base_namespace without adding an extra underscore uri = f"{base_namespace}{term_with_underscores}"
return URIRef(uri)
# Function to generate a random date within the last 5 years def generate_random_date(): start_date = datetime.now() - timedelta(days=5*365) random_days = random.randint(0, 5*365) return start_date + timedelta(days=random_days)
# Function to generate a random access value between 1 and 10 def generate_random_access(): return random.randint(1, 10)
# Function to create a valid URI for Articles def create_article_uri(title, base_namespace="http://example.org/article"): """ Creates a URI for an article by replacing non-word characters with underscores and URL-encoding.
Args: title (str): The title of the article. base_namespace (str): The base namespace for the article URI.
Returns: URIRef: The formatted article URI. """ if pd.isna(title): return None # Encode text to be used in URI sanitized_text = urllib.parse.quote(title.strip().replace(' ', '_').replace('"', '').replace('<', '').replace('>', '').replace("'", "_")) return URIRef(f"{base_namespace}/{sanitized_text}")
# Loop through each row in the DataFrame and create RDF triples for index, row in df.iterrows(): article_uri = create_article_uri(row['Title']) if article_uri is None: continue
# Add random datePublished and access random_date = generate_random_date() random_access = generate_random_access() g.add((article_uri, date_published, Literal(random_date.date(), datatype=XSD.date))) g.add((article_uri, access, Literal(random_access, datatype=XSD.integer)))
# Add MeSH Terms mesh_terms = parse_mesh_terms(row['meshMajor']) for term in mesh_terms: term_uri = convert_to_uri(term, base_namespace="http://example.org/mesh/") if term_uri is None: continue
# Link Article to MeSH Term g.add((article_uri, schema.about, term_uri))
# Path to save the file file_path = "/Workspace/PubMedGraph.ttl"
# Save the file g.serialize(destination=file_path, format='turtle')
print(f"File saved at {file_path}")
OK, so now we have a vectorized version of the data, and a graph (RDF) version of the data. Each vector has a URI associated with it, which corresponds to an entity in the KG, so we can go back and forth between the data formats.
Build an app
I decided to use Streamlit to build the interface for this graph RAG app. Similar to the last blog post, I have kept the user flow the same.
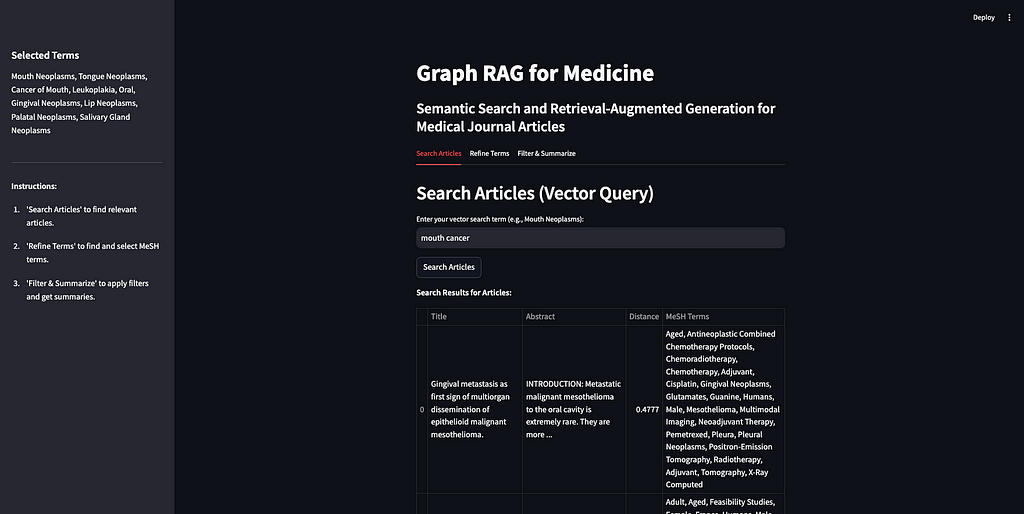
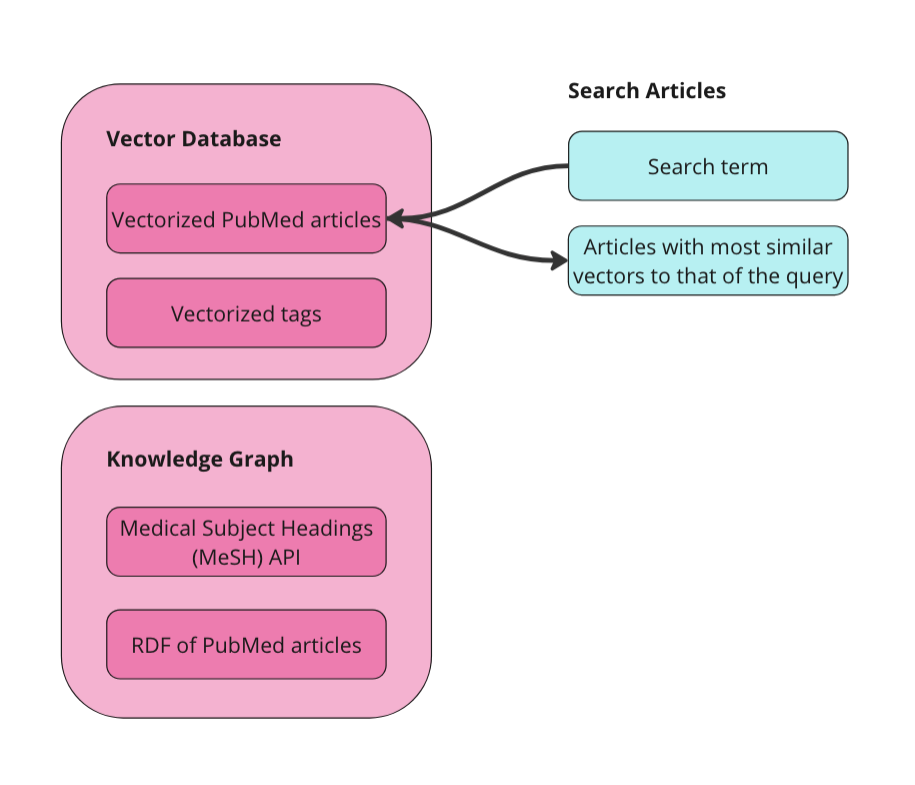
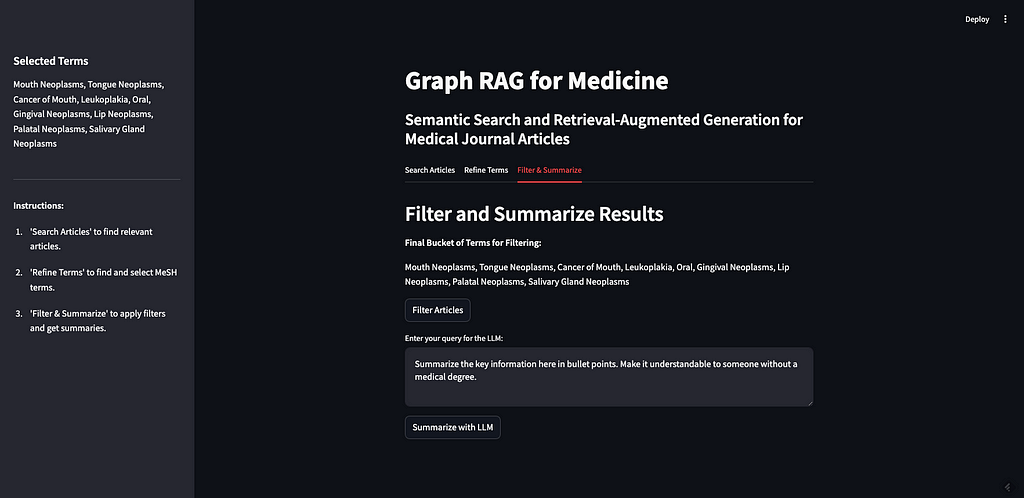
Search Articles: First, the user searches for articles using a search term. This relies exclusively on the vector database. The user’s search term(s) is sent to the vector database and the ten articles nearest the term in vector space are returned.
Refine Terms: Second, the user decides the MeSH terms to use to filter the returned results. Since we also vectorized the MeSH terms, we can have the user enter a natural language prompt to get the most relevant MeSH terms. Then, we allow the user to expand these terms to see their alternative names and narrower concepts. The user can select as many terms as they want for their filter criteria.
Filter & Summarize: Third, the user applies the selected terms as filters to the original ten journal articles. We can do this since the PubMed articles are tagged with MeSH terms. Finally, we let the user enter an additional prompt to send to the LLM along with the filtered journal articles. This is the generative step of the RAG app.
Let’s go through these steps one at a time. You can see the full app and code on my GitHub, but here is the structure:
-- app.py (a python file that drives the app and calls other functions as needed) -- query_functions (a folder containing python files with queries) -- rdf_queries.py (python file with RDF queries) -- weaviate_queries.py (python file containing weaviate queries) -- PubMedGraph.ttl (the pubmed data in RDF format, stored as a ttl file)
Search Articles
First, want to do is implement Weaviate’s vector similarity search. Since our articles are vectorized, we can send a search term to the vector database and get similar articles back.
Image by Author
The main function that searches for relevant journal articles in the vector database is in app.py:
# --- TAB 1: Search Articles --- with tab_search: st.header("Search Articles (Vector Query)") query_text = st.text_input("Enter your vector search term (e.g., Mouth Neoplasms):", key="vector_search")
# Extract URIs here article_uris = [ result["properties"].get("article_URI") for result in article_results if result["properties"].get("article_URI") ]
# Store article_uris in the session state st.session_state.article_uris = article_uris
} for result in article_results ] client.close() except Exception as e: st.error(f"Error during article search: {e}")
if st.session_state.article_results: st.write("**Search Results for Articles:**") st.table(st.session_state.article_results) else: st.write("No articles found yet.")
This function uses the queries stored in weaviate_queries to establish the Weaviate client (initialize_weaviate_client) and search for articles (query_weaviate_articles). Then we display the returned articles in a table, along with their abstracts, distance (how close they are to the search term), and the MeSH terms that they are tagged with.
The function to query Weaviate in weaviate_queries.py looks like this:
# Function to query Weaviate for Articles def query_weaviate_articles(client, query_text, limit=10): # Perform vector search on Article collection response = client.collections.get("Article").query.near_text( query=query_text, limit=limit, return_metadata=MetadataQuery(distance=True) )
# Parse response results = [] for obj in response.objects: results.append({ "uuid": obj.uuid, "properties": obj.properties, "distance": obj.metadata.distance, }) return results
As you can see, I put a limit of ten results here just to make it simpler, but you can change that. This is just using vector similarity search in Weaviate to return relevant results.
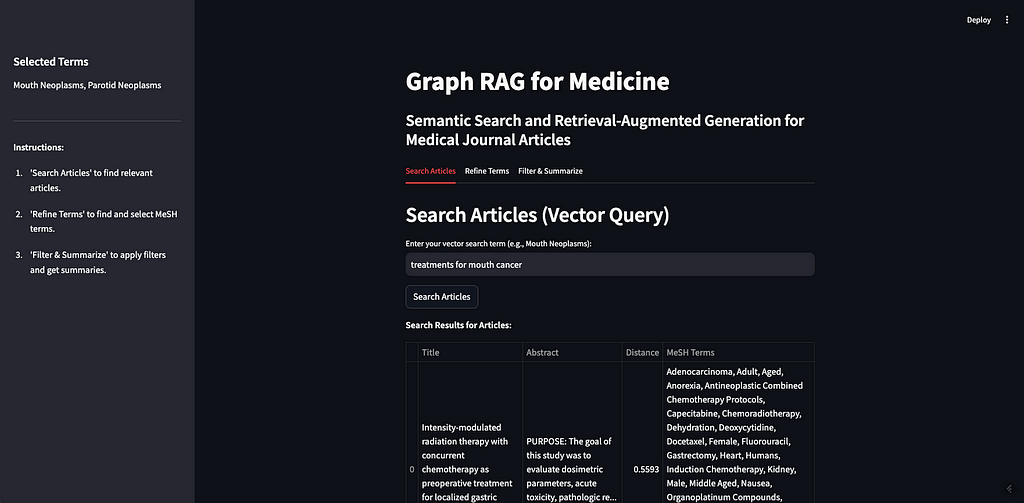
The end result in the app looks like this:
Image by Author
As a demo, I will search the term “treatments for mouth cancer”. As you can see, 10 articles are returned, mostly relevant. This demonstrates both the strengths and weaknesses of vector based retrieval.
The strength is that we can build a semantic search functionality on our data with minimal effort. As you can see above, all we did was set up the client and send the data to a vector database. Once our data has been vectorized, we can do semantic searches, similarity searches, and even RAG. I have put some of that in the notebook accompanying this post, but there’s a lot more in Weaviate’s official docs.
The weakness of vector based retrieval, as I mentioned above are that they are black-box and struggle with factual knowledge. In our example, it looks like most of the articles are about some kind of treatment or therapy for some kind of cancer. Some of the articles are about mouth cancer specifically, some are about a sub-type of mouth cancer like gingival cancer (cancer of the gums), and palatal cancer (cancer of the palate). But there are also articles about nasopharyngeal cancer (cancer of the upper throat), mandibular cancer (cancer of the jaw), and esophageal cancer (cancer of the esophagus). None of these (upper throat, jaw, or esophagus) are considered mouth cancer. It is understandable why an article about a specific cancer radiation therapy for nasopharyngeal neoplasms would be considered similar to the prompt “treatments for mouth cancer” but it may not be relevant if you are only looking for treatments for mouth cancer. If we were to plug these ten articles directly into our prompt to the LLM and ask it to “summarize the different treatment options,” we would be getting incorrect information.
The purpose of RAG is to give an LLM a very specific set of additional information to better answer your question — if that information is incorrect or irrelevant, it can lead to misleading responses from the LLM. This is often referred to as “context poisoning”. What is especially dangerous about context poisoning is that the response isn’t necessarily factually inaccurate (the LLM may accurately summarize the treatment options we feed it), and it isn’t necessarily based on an inaccurate piece of data (presumably the journal articles themselves are accurate), it’s just using the wrong data to answer your question. In this example, the user could be reading about how to treat the wrong kind of cancer, which seems very bad.
Refine Terms
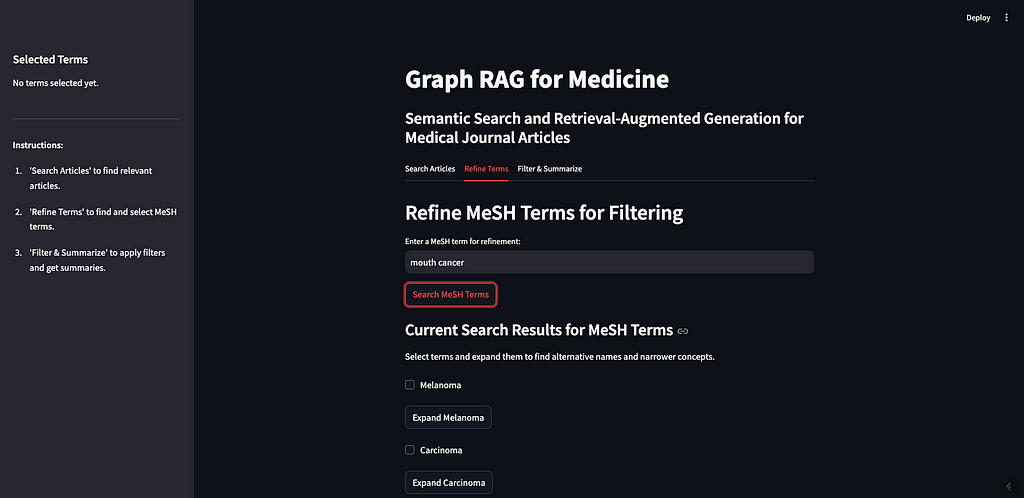
KGs can help improve the accuracy of responses and reduce the likelihood of context poisoning by refining the results from the vector database. The next step is for selecting what MeSH terms we want to use to filter the articles. First, we do another vector similarity search against the vector database but on the Terms collection. This is because the user may not be familiar with the MeSH controlled vocabulary. In our example above, I searched for, “therapies for mouth cancer”, but “mouth cancer” is not a term in MeSH — they use “Mouth Neoplasms”. We want the user to be able to start exploring the MeSH terms without having a prior understanding of them — this is good practice regardless of the metadata used to tag the content.
Image by Author
The function to get relevant MeSH terms is nearly identical to the previous Weaviate query. Just replace Article with term:
# Function to query Weaviate for MeSH Terms def query_weaviate_terms(client, query_text, limit=10): # Perform vector search on MeshTerm collection response = client.collections.get("term").query.near_text( query=query_text, limit=limit, return_metadata=MetadataQuery(distance=True) )
# Parse response results = [] for obj in response.objects: results.append({ "uuid": obj.uuid, "properties": obj.properties, "distance": obj.metadata.distance, }) return results
Here is what it looks like in the app:
Image by Author
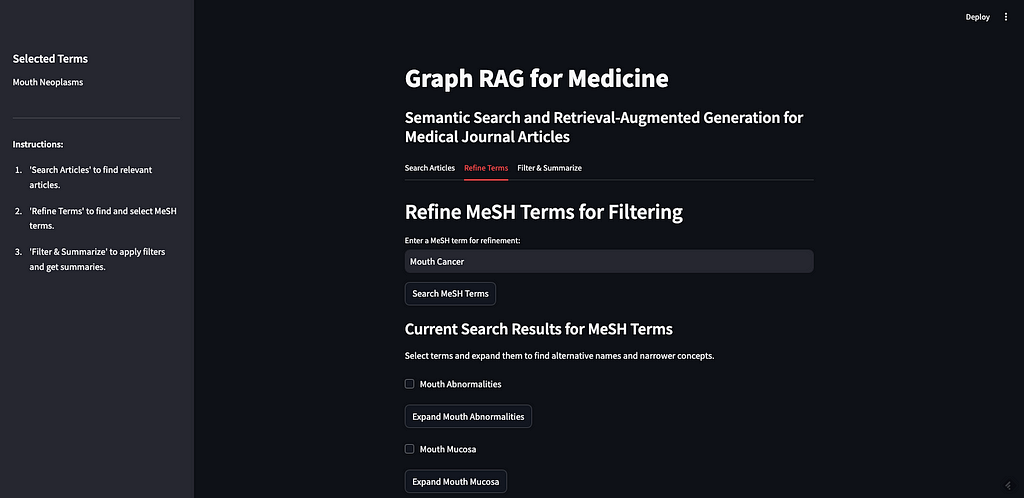
As you can see, I searched for “mouth cancer” and the most similar terms were returned. Mouth cancer was not returned, as that is not a term in MeSH, but Mouth Neoplasms is on the list.
The next step is to allow the user to expand the returned terms to see alternative names and narrower concepts. This requires querying the MeSH API. This was the trickiest part of this app for a number of reasons. The biggest problem is that Streamlit requires that everything has a unique ID but MeSH terms can repeat — if one of the returned concepts is a child of another, then when you expand the parent you will have a duplicate of the child. I think I took care of most of the big issues and the app should work, but there are probably bugs to find at this stage.
The functions we rely on are found in rdf_queries.py. We need one to get the alternative names for a term:
# Fetch alternative names and triples for a MeSH term def get_concept_triples_for_term(term): term = sanitize_term(term) # Sanitize input term sparql = SPARQLWrapper("https://id.nlm.nih.gov/mesh/sparql") query = f""" PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX meshv: <http://id.nlm.nih.gov/mesh/vocab#> PREFIX mesh: <http://id.nlm.nih.gov/mesh/>
triples = set() for result in results["results"]["bindings"]: obj_label = result.get("oLabel", {}).get("value", "No label") triples.add(sanitize_term(obj_label)) # Sanitize term before adding
# Add the sanitized term itself to ensure it's included triples.add(sanitize_term(term)) return list(triples)
except Exception as e: print(f"Error fetching concept triples for term '{term}': {e}") return []
We also need functions to get the narrower (child) concepts for a given term. I have two functions that achieve this — one that gets the immediate children of a term and one recursive function that returns all children of a given depth.
# Fetch narrower concepts for a MeSH term def get_narrower_concepts_for_term(term): term = sanitize_term(term) # Sanitize input term sparql = SPARQLWrapper("https://id.nlm.nih.gov/mesh/sparql") query = f""" PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX meshv: <http://id.nlm.nih.gov/mesh/vocab#> PREFIX mesh: <http://id.nlm.nih.gov/mesh/>
concepts = set() for result in results["results"]["bindings"]: subject_label = result.get("narrowerConceptLabel", {}).get("value", "No label") concepts.add(sanitize_term(subject_label)) # Sanitize term before adding
return list(concepts)
except Exception as e: print(f"Error fetching narrower concepts for term '{term}': {e}") return []
# Recursive function to fetch narrower concepts to a given depth def get_all_narrower_concepts(term, depth=2, current_depth=1): term = sanitize_term(term) # Sanitize input term all_concepts = {} try: narrower_concepts = get_narrower_concepts_for_term(term) all_concepts[sanitize_term(term)] = narrower_concepts
if current_depth < depth: for concept in narrower_concepts: child_concepts = get_all_narrower_concepts(concept, depth, current_depth + 1) all_concepts.update(child_concepts)
except Exception as e: print(f"Error fetching all narrower concepts for term '{term}': {e}")
return all_concepts
The other important part of step 2 is to allow the user to select terms to add to a list of “Selected Terms”. These will appear in the sidebar on the left of the screen. There are a lot of things that can improve this step like:
There is no way to clear all but you can clear the cache or refresh the browser if needed.
There is no way to ‘select all narrower concepts’ which would be helpful.
There is no option to add rules for filtering. Right now, we are just assuming that the article must contain term A OR term B OR term C etc. The rankings at the end are based on the number of terms the articles are tagged with.
Here is what it looks like in the app:
Image by Author
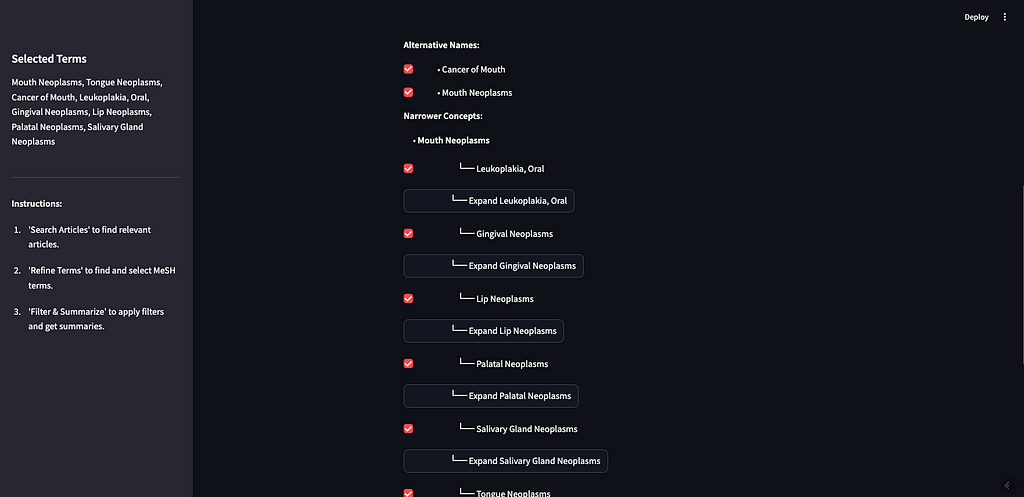
I can expand Mouth Neoplasms to see the alternative names, in this case, “Cancer of Mouth”, along with all of the narrower concepts. As you can see, most of the narrower concepts have their own children, which you can expand as well. For the purposes of this demo, I am going to select all children of Mouth Neoplasms.
Image by Author
This step is important not just because it allows the user to filter the search results, but also because it is a way for the user to explore the MeSH graph itself and learn from it. For example, this would be the place for the user to learn that nasopharyngeal neoplasms are not a subset of mouth neoplasms.
Filter & Summarize
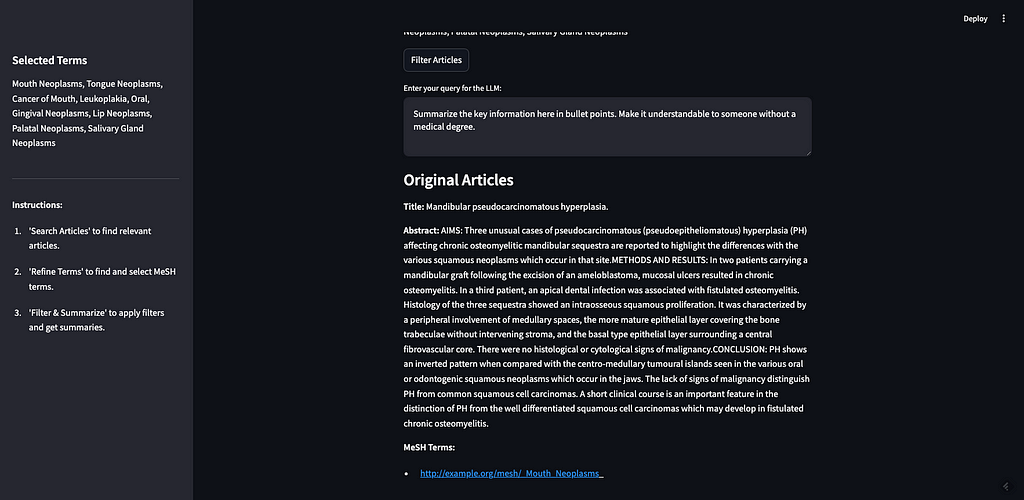
Now that you’ve got your articles and your filter terms, you can apply the filter and summarize the results. This is where we bring the original 10 articles returned in step one together with the refined list of MeSH terms. We allow the user to add additional context to the prompt before sending it to the LLM.
Image by Author
The way we do this filtering is that we need to get the URIs for the 10 articles from the original search. Then we can query our knowledge graph for which of those articles have been tagged with the associated MeSH terms. Additionally, we save the abstracts of these articles for use in the next step. This would be the place where we could filter based on access control or other user-controlled parameters like author, filetype, date published, etc. I didn’t include any of that in this app but I did add in properties for access control and date published in case we want to add that in this UI later.
Here is what the code looks like in app.py:
if st.button("Filter Articles"): try: # Check if we have URIs from tab 1 if "article_uris" in st.session_state and st.session_state.article_uris: article_uris = st.session_state.article_uris
# Convert list of URIs into a string for the VALUES clause or FILTER article_uris_string = ", ".join([f"<{str(uri)}>" for uri in article_uris])
FILTER (?article IN ({article_uris})) }} """ # Insert the article URIs into the query query = SPARQL_QUERY.format(article_uris=article_uris_string) else: st.write("No articles selected from Tab 1.") st.stop()
# Query the RDF and save results in session state top_articles = query_rdf(LOCAL_FILE_PATH, query, final_terms) st.session_state.filtered_articles = top_articles
if top_articles:
# Combine abstracts from top articles and save in session state def combine_abstracts(ranked_articles): combined_text = " ".join( [f"Title: {data['title']} Abstract: {data['abstract']}" for article_uri, data in ranked_articles] ) return combined_text
else: st.write("No articles found for the selected terms.") except Exception as e: st.error(f"Error filtering articles: {e}")
This uses the function query_rdf in the rdf_queries.py file. That function looks like this:
# Function to query RDF using SPARQL def query_rdf(local_file_path, query, mesh_terms, base_namespace="http://example.org/mesh/"): if not mesh_terms: raise ValueError("The list of MeSH terms is empty or invalid.")
print("SPARQL Query:", query)
# Create and parse the RDF graph g = Graph() g.parse(local_file_path, format="ttl")
article_data = {}
for term in mesh_terms: # Convert the term to a valid URI mesh_term_uri = convert_to_uri(term, base_namespace) #print("Term:", term, "URI:", mesh_term_uri)
for row in results: article_uri = row['article'] if article_uri not in article_data: article_data[article_uri] = { 'title': row['title'], 'abstract': row['abstract'], 'datePublished': row['datePublished'], 'access': row['access'], 'meshTerms': set() } article_data[article_uri]['meshTerms'].add(str(row['meshTerm'])) #print("DEBUG article_data:", article_data)
# Rank articles by the number of matching MeSH terms ranked_articles = sorted( article_data.items(), key=lambda item: len(item[1]['meshTerms']), reverse=True ) return ranked_articles[:10]
As you can see, this function also converts the MeSH terms to URIs so we can filter using the graph. Be careful in the way you convert terms to URIs and ensure it aligns with the other functions.
Here is what it looks like in the app:
Image by Author
As you can see, the two MeSH terms we selected from the previous step are here. If I click “Filter Articles,” it will filter the original 10 articles using our filter criteria in step 2. The articles will be returned with their full abstracts, along with their tagged MeSH terms (see image below).
Image by Author
There are 5 articles returned. Two are tagged with “mouth neoplasms,” one with “gingival neoplasms,” and two with “palatal neoplasms”.
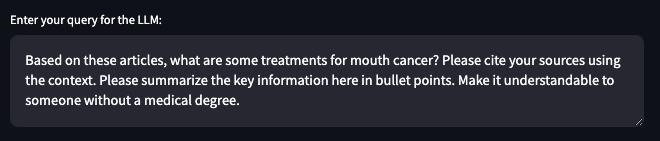
Now that we have a refined list of articles we want to use to generate a response, we can move to the final step. We want to send these articles to an LLM to generate a response but we can also add in additional context to the prompt. I have a default prompt that says, “Summarize the key information here in bullet points. Make it understandable to someone without a medical degree.” For this demo, I am going to adjust the prompt to reflect our original search term:
The results are as follows:
The results look better to me, mostly because I know that the articles we are summarizing are, presumably, about treatments for mouth cancer. The dataset doesn’t contain the actual journal articles, just the abstracts. So these results are just summaries of summaries. There may be some value to this, but if we were building a real app and not just a demo, this is the step where we could incorporate the full text of the articles. Alternatively, this is where the user/researcher would go read these articles themselves, rather than relying exclusively on the LLM for the summaries.
Conclusion
This tutorial demonstrates how combining vector databases and knowledge graphs can significantly enhance RAG applications. By leveraging vector similarity for initial searches and structured knowledge graph metadata for filtering and organization, we can build a system that delivers accurate, explainable, and domain-specific results. The integration of MeSH, a well-established controlled vocabulary, highlights the power of domain expertise in curating metadata, which ensures that the retrieval step aligns with the unique needs of the application while maintaining interoperability with other systems. This approach is not limited to medicine — its principles can be applied across domains wherever structured data and textual information coexist.
This tutorial underscores the importance of leveraging each technology for what it does best. Vector databases excel at similarity-based retrieval, while knowledge graphs shine in providing context, structure, and semantics. Additionally, scaling RAG applications demands a metadata layer to break down data silos and enforce governance policies. Thoughtful design, rooted in domain-specific metadata and robust governance, is the path to building RAG systems that are not only accurate but also scalable.
When there are more features than model dimensions
Introduction
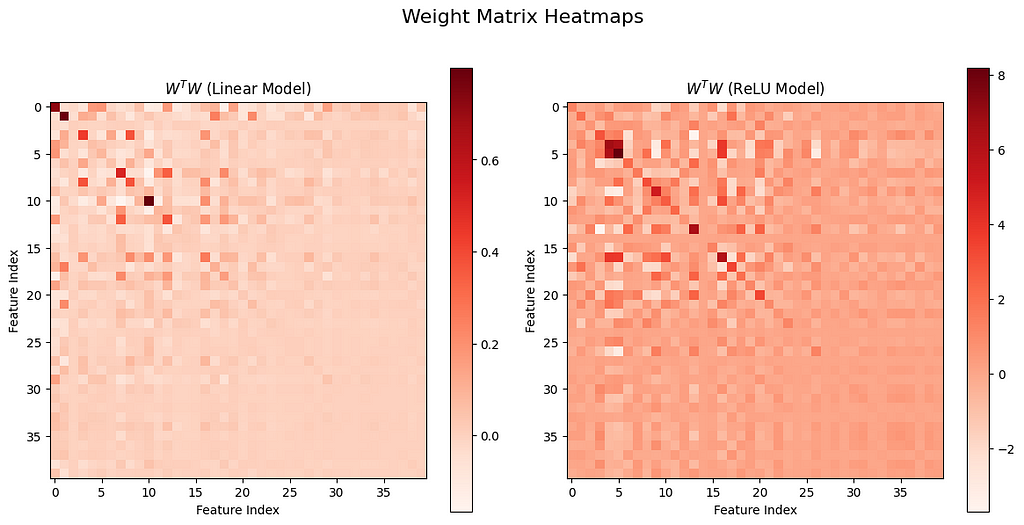
It would be ideal if the world of neural network represented a one-to-one relationship: each neuron activates on one and only one feature. In such a world, interpreting the model would be straightforward: this neuron fires for the dog ear feature, and that neuron fires for the wheel of cars. Unfortunately, that is not the case. In reality, a model with dimension d often needs to represent m features, where d < m. This is when we observe the phenomenon of superposition.
In the context of machine learning, superposition refers to a specific phenomenon that one neuron in a model represents multiple overlapping features rather than a single, distinct one. For example, InceptionV1 contains one neuron that responds to cat faces, fronts of cars, and cat legs [1]. This leads to what we can superposition of different features activation in the same neuron or circuit.
The existence of superposition makes model explainability challenging, especially in deep learning models, where neurons in hidden layers represent complex combinations of patterns rather than being associated with simple, direct features.
In this blog post, we will present a simple toy example of superposition, with detailed implementations by Python in this notebook.
What makes Superposition Occur: Assumptions
We begin this section by discussing the term “feature”.
In tabular data, there is little ambiguity in defining what a feature is. For example, when predicting the quality of wine using a tabular dataset, features can be the percentage of alcohol, the year of production, etc.
However, defining features can become complex when dealing with non-tabular data, such as images or textual data. In these cases, there is no universally agreed-upon definition of a feature. Broadly, a feature can be considered any property of the input that is recognizable to most humans. For instance, one feature in a large language model (LLM) might be whether a word is in French.
Superposition occurs when the number of features is more than the model dimensions. We claim that two necessary conditions must be met if superposition would occur:
Non-linearity: Neural networks typically include non-linear activation functions, such as sigmoid or ReLU, at the end of each hidden layer. These activation functions give the network possibilities to map inputs to outputs in a non-linear way, so that it can capture more complex relationships between features. We can imagine that without non-linearity, the model would behave as a simple linear transformation, where features remain linearly separable, without any possibility of compression of dimensions through superposition.
Feature Sparsity: Feature sparsity means the fact that only a small subset of features is non-zero. For example, in language models, many features are not present at the same time: e.g. one same word cannot be is_French and is_other_languages. If all features were dense, we can imagine an important interference due to overlapping representations, making it very difficult for the model to decode features.
Toy Example: Linearity vs non-linearity with varying sparsity
Synthetic Dataset
Let us consider a toy example of 40 features with linearly decreasing feature importance: the first feature has an importance of 1, the last feature has an importance of 0.1, and the importance of the remaining features is evenly spaced between these two values.
We then generate a synthetic dataset with the following code:
def generate_sythentic_dataset(dim_sample, num_sapmple, sparsity): """Generate synthetic dataset according to sparsity""" dataset=[] for _ in range(num_sapmple): x = np.random.uniform(0, 1, n) mask = np.random.choice([0, 1], size=n, p=[sparsity, 1 - sparsity]) x = x * mask # Apply sparsity dataset.append(x) return np.array(dataset)
This function creates a synthetic dataset with the given number of dimensions, which is, 40 in our case. For each dimension, a random value is generated from a uniform distribution in [0, 1]. The sparsity parameter, varying between 0 and 1, controls the percentage of active features in each sample. For example, when the sparsity is 0.8, it the features in each sample has 80% chance to be zero. The function applies a mask matrix to realize the sparsity setting.
Linear and Relu Models
We would now like to explore how ReLU-based neural models lead to superposition formation and how sparsity values would change their behaviors.
We set our experiment in the following way: we compress the features with 40 dimensions into the 5 dimensional space, then reconstruct the vector by reversing the process. Observing the behavior of these transformations, we expect to see how superposition forms in each case.
To do so, we consider two very similar models:
Linear Model: A simple linear model with only 5 coefficients. Recall that we want to work with 40 features — far more than the model’s dimensions.
ReLU Model: A model almost the same to the linear one, but with an additional ReLU activation function at the end, introducing one level of non-linearity.
Both models are built using PyTorch. For example, we build the ReLU model with the following code:
class ReLUModel(nn.Module): def __init__(self, n, m): super().__init__() self.W = nn.Parameter(torch.randn(m, n) * np.sqrt(1 / n)) self.b = nn.Parameter(torch.zeros(n))
def forward(self, x): h = torch.relu(torch.matmul(x, self.W.T)) # Add ReLU activation: x (batch, n) * W.T (n, m) -> h (batch, m) x_reconstructed = torch.relu(torch.matmul(h, self.W) + self.b) # Reconstruction with ReLU return x_reconstructed
According to the code, the n-dimensional input vector x is projected into a lower-dimensional space by multiplying it with an m×n weight matrix. We then reconstruct the original vector by mapping it back to the original feature space through a ReLU transformation, adjusted by a bias vector. The Linear Model is given by the similar structure, with the only difference being that the reconstruction is done by using only the linear transformation instead of ReLU. We train the model by minimizing the mean squared error between the original feature samples and the reconstructed ones, weighted one the feature importance.
Results Analysis
We trained both models with different sparsity values: 0.1, 0.5, and 0.9, from less sparse to the most sparse. We have observed several important results.
First, whatever the sparsity level, ReLU models “compress” features much better than linear models: While linear models mainly capture features with the highest feature importance, ReLU models could focus on less important features by formation of superposition— where a single model dimension represents multiple features. Let us have a vision of this phenomenon in the following visualizations: for linear models, the biases are smallest for the top five features, (in case you don’t remember: the feature importance is defined as a linearly decreasing function based on feature order). In contrast, the biases for the ReLU model do not show this order and are generally reduced more.
Image by author: reconstructed bias
Another important and interesting result is that: superposition is much more likely to observe when sparsity level is high in the features. To get an impression of this phenomenon, we can visualize the matrix W^T@W, where W is the m×n weight matrix in the models. One might interpret the matrix W^T@W as a quantity of how the input features are projected onto the lower dimensional space:
In particular:
The diagonal of W^T@W represents the “self-similarity” of each feature inside the low dimensional transformed space.
The off-diagonal of the matrix represents how different features correlate to each other.
We now visualize the values of W^T@W below for both the Linear and ReLU models we have constructed before with two different sparsity levels : 0.1 and 0.9. You can see that when the sparsity value is high as 0.9, the off-diagonal elements become much bigger compared to the case when sparsity is 0.1 (You actually don’t see much difference between the two models output). This observation indicates that correlations between different features are more easily to be learned when sparsity is high.
Image by Author: matrix for sparsity 0.1Image by author: matrix for sparsity 0.9
Conclusion
In this blog post, I made a simple experiment to introduce the formation of superposition in neural networks by comparing Linear and ReLU models with fewer dimensions than features to represent. We observed that the non-linearity introduced by the ReLU activation, combined with a certain level of sparsity, can help the model form superposition.
In real-world applications, which are much more complex than my navie example, superposition is an important mechanism for representing complex relationships in neural models, especially in vision models or LLMs.
Some insights on using Google’s latest Vision Language Model
Hutt Lagoon, Australia. Depending on the season, time of day, and cloud coverage, this lake changes from red to pink or purple. Source: Google Maps.
Multimodal models are architectures that simultaneously integrate and process different data types, such as text, images, and audio. Some examples include CLIP and DALL-E from OpenAI, both released in 2021. CLIP understands images and text jointly, allowing it to perform tasks like zero-shot image classification. DALL-E, on the other hand, generates images from textual descriptions, allowing the automation and enhancement of creative processes in gaming, advertising, and literature, among other sectors.
Visual language models (VLMs) are a special case of multimodal models. VLMs generate language based on visual inputs. One prominent example is Paligemma, which Google introduced in May 2024. Paligemma can be used for Visual Question Answering, object detection, and image segmentation.
Some blog posts explore the capabilities of Paligemma in object detection, such as this excellent read from Roboflow:
However, by the time I wrote this blog, the existing documentation on preparing data to use Paligemma for object segmentation was vague. That is why I wanted to evaluate whether it is easy to use Paligemma for this task. Here, I share my experience.
Brief introduction of Paligemma
Before going into detail on the use case, let’s briefly revisit the inner workings of Paligemma.
Paligemma combines a SigLIP-So400m vision encoder with a Gemma language model to process images and text (see figure above). In the new version of Paligemma released in December of this year, the vision encoder can preprocess images at three different resolutions: 224px, 448px, or 896px. The vision encoder preprocesses an image and outputs a sequence of image tokens, which are linearly combined with input text tokens. This combination of tokens is further processed by the Gemma language model, which outputs text tokens. The Gemma model has different sizes, from 2B to 27B parameters.
An example of model output is shown in the following figure.
The Paligemma model was trained on various datasets such as WebLi, openImages, WIT, and others (see this Kaggle blog for more details). This means that Paligemma can identify objects without fine-tuning. However, such abilities are limited. That’s why Google recommends fine-tuning Paligemma in domain-specific use cases.
Input format
To fine-tune Paligemma, the input data needs to be in JSONL format. A dataset in JSONL format has each line as a separate JSON object, like a list of individual records. Each JSON object contains the following keys:
Image: The image’s name.
Prefix: This specifies the task you want the model to perform.
Suffix: This provides the ground truth the model learns to make predictions.
Depending on the task, you must change the JSON object’s prefix and suffix accordingly. Here are some examples:
Image captioning:
{"image": "some_filename.png", "prefix": "caption en" (To indicate that the model should generate an English caption for an image), "suffix": "This is an image of a big, white boat traveling in the ocean." }
Question answering:
{"image": "another_filename.jpg", "prefix": "How many people are in the image?", "suffix": "ten" }
Note that for segmentation, apart from the object’s bounding box coordinates, you need to specify 16 extra segmentation tokens representing a mask that fits within the bounding box. According to Google’s Big Vision repository, those tokens are codewords with 128 entries (<seg000>…<seg127>). How do we obtain these values? In my personal experience, it was challenging and frustrating to get them without proper documentation. But I’ll give more details later.
If you are interested in learning more about Paligemma, I recommend these blogs:
As mentioned above, Paligemma was trained on different datasets. Therefore, this model is expected to be good at segmenting “traditional” objects such as cars, people, or animals. But what about segmenting objects in satellite images? This question led me to explore Paligemma’s capabilities for segmenting water in satellite images.
Here’s an example of the water bodies dataset: The RGB image is shown on the left, while the corresponding mask appears on the right.
Some masks in this dataset were incorrect, and others needed further preprocessing. Faulty examples include masks with all values set to water, while only a small portion was present in the original image. Other masks did not correspond to their RGB images. When an image is rotated, some masks make these areas appear as if they have water.
Example of a rotated mask. When reading this image in Python, the area outside the image appears as it would have water. In this case, image rotation is needed to correct this mask. Image made by the author.
Given these data limitations, I selected a sample of 164 images for which the masks did not have any of the problems mentioned above. This set of images is used to fine-tune Paligemma.
Preparing the JSONL dataset
As explained in the previous section, Paligemma needs entries that represent the object’s bounding box coordinates in normalized image-space (<loc0000>…<loc1023>) plus an extra 16 segmentation tokens representing 128 different codewords (<seg000>…<seg127>). Obtaining the bounding box coordinates in the desired format was easy, thanks to Roboflow’s explanation. But how do we obtain the 128 codewords from the masks? There was no clear documentation or examples in the Big Vision repository that I could use for my use case. I naively thought that the process of creating the segmentation tokens was similar to that of making the bounding boxes. However, this led to an incorrect representation of the water masks, which led to wrong prediction results.
By the time I wrote this blog (beginning of December), Google announced the second version of Paligemma. Following this event, Roboflow published a nice overview of preparing data to fine-tune Paligemma2 for different applications, including image segmentation. I use part of their code to finally obtain the correct segmentation codewords. What was my mistake? Well, first of all, the masks need to be resized to a tensor of shape [None, 64, 64, 1] and then use a pre-trained variational auto-encoder (VAE) to convert annotation masks into text labels. Although the usage of a VAE model was briefly mentioned in the Big Vision repository, there is no explanation or examples on how to use it.
The workflow I use to prepare the data to fine-tune Paligemma is shown below:
Steps to convert one original mask from the filtered water bodies dataset to a JSON object. This process is repeated over the 164 images of the train set and the 21 images of the test dataset to build the JSONL dataset.
As observed, the number of steps needed to prepare the data for Paligemma is large, so I don’t share code snippets here. However, if you want to explore the code, you can visit this GitHub repository. The script convert.py has all the steps mentioned in the workflow shown above. I also added the selected images so you can play with this script immediately.
When preprocessing the segmentation codewords back to segmentation masks, we note how these masks cover the water bodies in the images:
Resulting masks when decoding the segmentation codewords in the train set. Image made by the author using this Notebook.
How is Paligemma at segmenting water in satellite images?
Before fine-tuning Paligemma, I tried its segmentation capabilities on the models uploaded to Hugging Face. This platform has a demo where you can upload images and interact with different Paligemma models.
Default Paligemma model at segmenting water in satellite images.
The current version of Paligemma is generally good at segmenting water in satellite images, but it’s not perfect. Let’s see if we can improve these results!
There are two ways to fine-tune Paligemma, either through Hugging Face’s Transformer library or by using Big Vision and JAX. I went for this last option. Big Vision provides a Colab notebook, which I modified for my use case. You can open it by going to my GitHub repository:
I used a batch size of 8 and a learning rate of 0.003. I ran the training loop twice, which translates to 158 training steps. The total running time using a T4 GPU machine was 24 minutes.
The results were not as expected. Paligemma did not produce predictions in some images, and in others, the resulting masks were far from the ground truth. I also obtained segmentation codewords with more than 16 tokens in two images.
Results of the fine-tuning where there were predictions. Image made by the author.
It’s worth mentioning that I use the first Paligemma version. Perhaps the results are improved when using Paligemma2 or by tweaking the batch size or learning rate further. In any case, these experiments are out of the scope of this blog.
The demo results show that the default Paligemma model is better at segmenting water than my finetuned model. In my opinion, UNET is a better architecture if the aim is to build a model specialized in segmenting objects. For more information on how to train such a model, you can read my previous blog post:
I want to mention some other challenges I encountered when fine-tuning Paligemma using Big Vision and JAX.
Setting up different model configurations is difficult because there’s still little documentation on those parameters.
The first version of Paligemma has been trained to handle images of different aspect ratios resized to 224×224. Make sure to resize your input images with this size only. This will prevent raising exceptions.
When fine-tuning with Big Vision and JAX, You might have JAX GPU-related problems. Ways to overcome this issue are:
a. Reducing the samples in your training and validation datasets.
b. Increasing the batch size from 8 to 16 or higher.
The fine-tuned model has a size of ~ 5GB. Make sure to have enough space in your Drive to store it.
Takeaway messages
Discovering a new AI model is exciting, especially in this age of multimodal algorithms transforming our society. However, working with state-of-the-art models can sometimes be challenging due to the lack of available documentation. Therefore, the launch of a new AI model should be accompanied by comprehensive documentation to ensure its smooth and widespread adoption, especially among professionals who are still inexperienced in this area.
Despite the difficulties I encountered fine-tuning Paligemma, the current pre-trained models are powerful at doing zero-shot object detection and image segmentation, which can be used for many applications, including assisted ML labeling.
Are you using Paligemma in your Computer Vision projects? Share your experience fine-tuning this model in the comments!
I hope you enjoyed this post. Once more, thanks for reading!
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.