
Orchestrating strategies for optimal workload distribution in microservice applications
Introduction
Large distributed applications handle more than thousands of requests per second. At some point, it becomes evident that handling requests on a single machine is no longer possible. That is why software engineers care about horizontal scaling, where the whole system is consistently organized on multiple servers. In this configuration, every server handles only a portion of all requests, based on its capacity, performance, and several other factors.
Requests between servers can be distributed in different ways. In this article, we will study the most popular strategies. By the way, it is impossible to outline the optimal strategy: each has its own properties and should be chosen according to the system configurations.
Use of load balancers
Load balancers can appear at different application layers. For instance, most web applications consist of frontend, backend and database layers. As a result, several load balancers can be used in different application parts to optimize request routing:
- between users (clients) and frontend servers;
- between frontend and backend servers;
- between backend servers and a database.
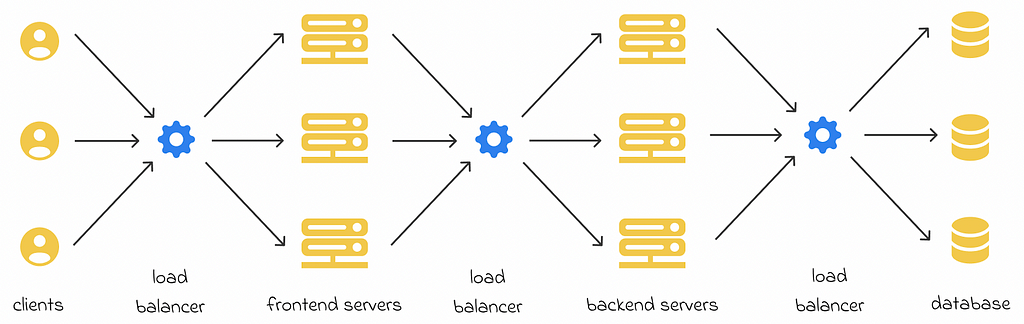
Despite the existence of load balancers on different layers, the same balancing strategies can be applied to all of them.
Health checks
In a system consisting of several servers, any of them can be overloaded at any moment in time, lose network connection, or even go down. To keep track of their active states, regular health checks must be performed by a separate monitoring service. This service periodically sends requests to all the machines and analyzes their answers.
Most of the time, the monitoring system checks the speed of the returned response and the number of active tasks or connections with which a machine is currently dealing. If a machine does not provide an answer within a given time limit, then the monitoring service can launch a trigger or procedure to make sure that the machine returns to its normal functional state as soon as possible.

By analyzing these incoming monitoring statistics, the load balancer can adapt its algorithm to accelerate the average request processing time. This aspect is essentially related to dynamic balancing algorithms (discussed in the section below) that constantly rely on active machine states in the system.
Static vs dynamic algorithms
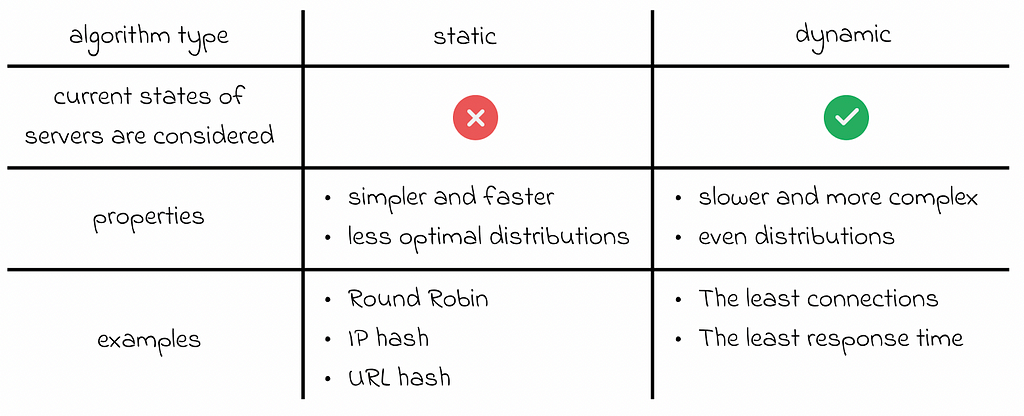
Balancing algorithms can be separated into two groups: static and dynamic:
- Static algorithms are simple balancing strategies that depend only on the static parameters of the system defined beforehand. The most commonly considered parameters are CPU, memory constraints, timeouts, connection limits, etc. Despite being simple, static strategies are not robust for optimally handling situations when machines rapidly change their performance characteristics. Therefore, static algorithms are much more suitable for deterministic scenarios when the system receives equal proportions of requests over time that require relatively the same amount of resources to be processed.
- Dynamic algorithms, on the other hand, rely on the current state of the system. The monitored statistics are taken into account and used to regularly adjust task distributions. By having more variables and information in real-time, dynamic algorithms can use advanced techniques to produce more even distributions of tasks in any given circumstances. However, regular health checks require processing time and can affect the overall performance of the system.
Balancing strategies
In this section, we will discover the most popular balancing mechanisms and their variations.
0. Random
For each new request, the random approach randomly chooses the server that will process it.
Despite its simplicity, the random algorithm works well when the system servers share similar performance parameters and are never overloaded. However, in many large applications the servers are usually loaded with lots of requests. That is why other balancing methods should be considered.
1A. Round robin
Round Robin is arguably the most simple existing balancing technique after the random method. Each request is sent to a server based on its absolute position in the request sequence:
- The request 1 is assigned to server 1;
- The request 2 is assigned to server 2;
- …
- The request k is assigned to server k.

When the number of servers reaches its maximum, the Round Robin algorithm starts again from the first server.
1B. Weighted Round Robin
Round Robin has a weighted variation of it, in which a weight usually based on performance capabilities (such as CPU and other system characteristics) is assigned to every server. Then every server receives the proportion of requests corresponding to its weight, in comparison with other servers.
This approach makes sure that requests are distributed evenly according to the unique processing capabilities of each server in the system.

1C. Sticky Round Robin
In the sticky version of Round Robin, the first request of a particular client is sent to a server, according to the normal Round Robin rules. However, if the client makes another request during a certain period of time or the session lifetime, then the request will go to the same server as before.
This ensures that all of the requests coming from any client are processed consistently by the same server. The advantage of this approach is that all information related to requests of the same client is stored on only a single server. Imagine a new request is coming that requires information from previous requests of a particular client. With Sticky Round Robin, the necessary data can be accessed quickly from just one server, which is much faster if the same data was retrieved from multiple servers.

2A. The least connections
The least connections is a dynamic approach where the current request is sent to the server with the fewest active connections or requests it is currently processing.
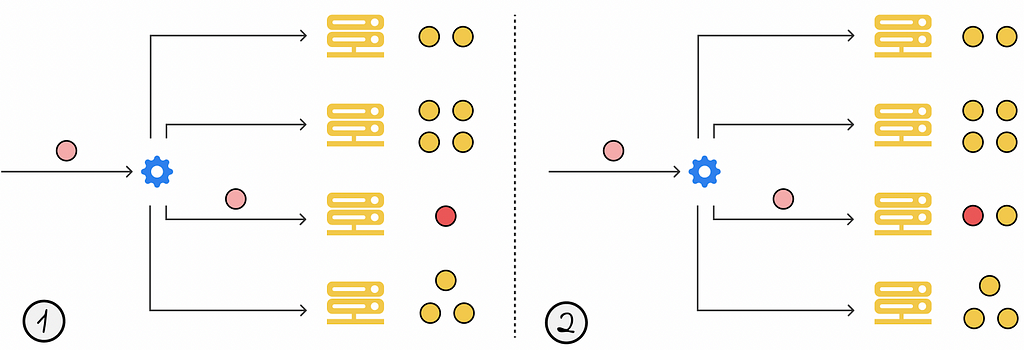
2B. The weighted least connections
The weighted version of the least connections algorithm works in the same way as the original one, except for the fact that each server is associated with a weight. To decide which server should process the current request, the number of active connections of each server is divided by its weight, and the server with the lowest resulting value processes the requests.
3. The least response time
Instead of considering the server with the fewest active connections, this balancing algorithm selects the server whose average response time over a certain period of time in the past was the lowest.
Sometimes this approach is used in combination with the least number of active connections:
- If there is a single server with the fewest connections, then it processes the current request;
- If there are multiple servers with the same lowest number of connections, then the server with the lowest response time among them is chosen to handle the request.

4A. IP hashing
Load balancers sometimes base their decisions on various client properties to ensure that all of its previous requests and data are stored only at one server. This locality aspect allows access the local user data in the system much faster, without needing additional requests to other servers to retrieve the data.
One of the ways to achieve this is by incorporating client IP addresses into a hash function, which associates a given IP address with one of the available servers.
Ideally, the selected hash function has to evenly distribute all of the incoming requests among all servers.

In fact, the locality aspect of IP hashing synergizes well with consistent hashing, which guarantees that the user’s data is resiliently stored in one place at any moment in time, even in cases of server shutdowns.
System Design: Consistent Hashing
4B. URL hashing
URL hashing works similarly to IP hashing, except that requests’ URLs are hashed instead of IP addresses.

This method is useful when we want to store information within a specific category or domain on a single server, independent of which client makes the request. For example, if a system frequently aggregates information about all received payments from users, then it would be efficient to define a set of all possible payment requests and hash them always to a single server.
5. Combination
By leveraging information about all of the previous methods, it becomes possible to combine them to derive new approaches tailored to each system’s unique requirements.
For example, a voting strategy can be implemented where decisions of n independent balancing strategies are aggregated. The most frequently occuring decision is selected as the final answer to determine which server should handle the current request.

It is important not to overcomplicate things, as more complex strategy designs require additional computational resources.
Conclusion
Load balancing is a crucial topic in system design, particularly for high-load applications. In this article, we have explored a variety of static and dynamic balancing algorithms. These algorithms vary in complexity and offer a trade-off between the balancing quality and computational resources required to make optimal decisions.
Ultimately, no single balancing algorithm can be universally best for all scenarios. The appropriate choice depends on multiple factors such as system configuration settings, requirements, and characteristics of incoming requests.
Resources
All images unless otherwise noted are by the author.
System Design: Load Balancer was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
System Design: Load Balancer