
How to create a production-grade pipeline for object detection
Table of Contents
- Introduction (Or What’s in a Title)
- The Reality of MLOps without the Ops
- Managing Dependencies Effectively
- How to Debug a Production Flow
- Finding the Goldilocks Step Size
- Takeaways
- References
Relevant Links
Introduction (Or What’s In a Title)
Navigating the world of data science job titles can be overwhelming. Here are just some of the examples I’ve seen recently on LinkedIn:
- Data scientist
- Machine learning engineer
- ML Ops engineer
- Data scientist/machine learning engineer
- Machine learning performance engineer
- …
and the list goes on and on. Let’s focus on two key roles: data scientist and machine learning engineer. According to Chip Huyen in her book, Introduction to Machine Learning Interviews [1]:
The goal of data science is to generate business insights, whereas the goal of ML engineering is to turn data into products. This means that data scientists tend to be better statisticians, and ML engineers tend to be better engineers. ML engineers definitely need to know ML algorithms, whereas many data scientists can do their jobs without ever touching ML.
Got it. So data scientists must know statistics, while ML engineers must know ML algorithms. But if the goal of data science is to generate business insights, and in 2024 the most powerful algorithms that generate the best insights tend to come from machine learning (deep learning in particular), then the line between the two becomes blurred. Perhaps this explains the combined Data scientist/machine learning engineer title we saw earlier?
Huyen goes on to say:
As a company’s adoption of ML matures, it might want to have a specialized ML engineering team. However, with an increasing number of prebuilt and pretrained models that can work off-the-shelf, it’s possible that developing ML models will require less ML knowledge, and ML engineering and data science will be even more unified.
This was written in 2020. By 2024, the line between ML engineering and data science has indeed blurred. So, if the ability to implement ML models is not the dividing line, then what is?
The line varies by practitioner of course. Today, the stereotypical data scientist and ML engineer differ as follows:
- Data scientist: Works in Jupyter notebooks, has never heard of Airflow, Kaggle expert, pipeline consists of manual execution of code cells in just the right order, master at hyperparameter tuning, Dockers? Great shoes for the summer! Development-focused.
- Machine learning engineer: Writes Python scripts, has heard of Airflow but doesn’t like it (go Prefect!), Kaggle middleweight, automated pipelines, leaves tuning to the data scientist, Docker aficionado. Production-focused.
In large companies, data scientists develop machine learning models to solve business problems and then hand them off to ML engineers. The engineers productionize and deploy these models, ensuring scalability and robustness. In a nutshell: the fundamental difference today between a data scientist and a machine learning engineer is not about who uses machine learning, but whether you are focused on development or production.
But what if you don’t have a large company, and instead are a startup or a company at small scale with only the budget to higher one or a few people for the data science team? They would love to hire the Data scientist/machine learning engineer who is able to do both! With an eye toward becoming this mythical “full-stack data scientist”, I decided to take an earlier project of mine, Object Detection using RetinaNet and KerasCV, and productionize it (see link above for related article and code). The original project, done using a Jupyter notebook, had a few deficiencies:
- There was no model versioning, data versioning or even code versioning. If a particular run of my Jupyter notebook worked, and a subsequent one did not, there was no methodical way of going back to the working script/model (Ctrl + Z? The save notebook option in Kaggle?)
- Model evaluation was fairly simple, using Matplotlib and some KerasCV plots. There was no storing of evaluations.
- We were compute limited to the free 20 hours of Kaggle GPU. It was not possible to use a larger compute instance, or to train multiple models in parallel.
- The model was never deployed to any endpoint, so it could not yield any predictions outside of the Jupyter notebook (no business value).
To accomplish this task, I decided to try out Metaflow. Metaflow is an open-source ML platform designed to help data scientists train and deploy ML models. Metaflow primarily serves two functions:
- a workflow orchestrator. Metaflow breaks down a workflow into steps. Turning a Python function into a Metaflow step is as simple as adding a @step decorator above the function. Metaflow doesn’t necessarily have all of the bells and whistles that a workflow tool like Airflow can give you, but it is simple, Pythonic, and can be setup to use AWS Step Functions as an external orchestrator. In addition, there is nothing wrong with using proper orchestrators like Airflow or Prefect in conjunction with Metaflow.
- an infrastructure abstraction tool. This is where Metaflow really shines. Normally a data scientist would have to manually set up the infrastructure required to send model training jobs from their laptop to AWS. This would potentially require knowledge of infrastructure such as API gateways, virtual private clouds (VPCs), Docker/Kubernetes, subnet masks, and much more. This sounds more like the work of the machine learning engineer! However, by using a Cloud Formation template (infrastructure-as-code file) and the @batch Metaflow decorator, the data scientist is able to ship compute jobs to the cloud in a simple and reliable way.
This article details my journey in productionizing an object detection model using Metaflow, AWS, and Weights & Biases. We’ll explore four key lessons learned during this process:
- The reality of “MLOps without the Ops”
- Effective dependency management
- Debugging strategies for production flows
- Optimizing workflow structure
By sharing these insights I hope to guide you, my fellow data practitioner, in your transition from development to production-focused work, highlighting both the challenges and solutions encountered along the way.
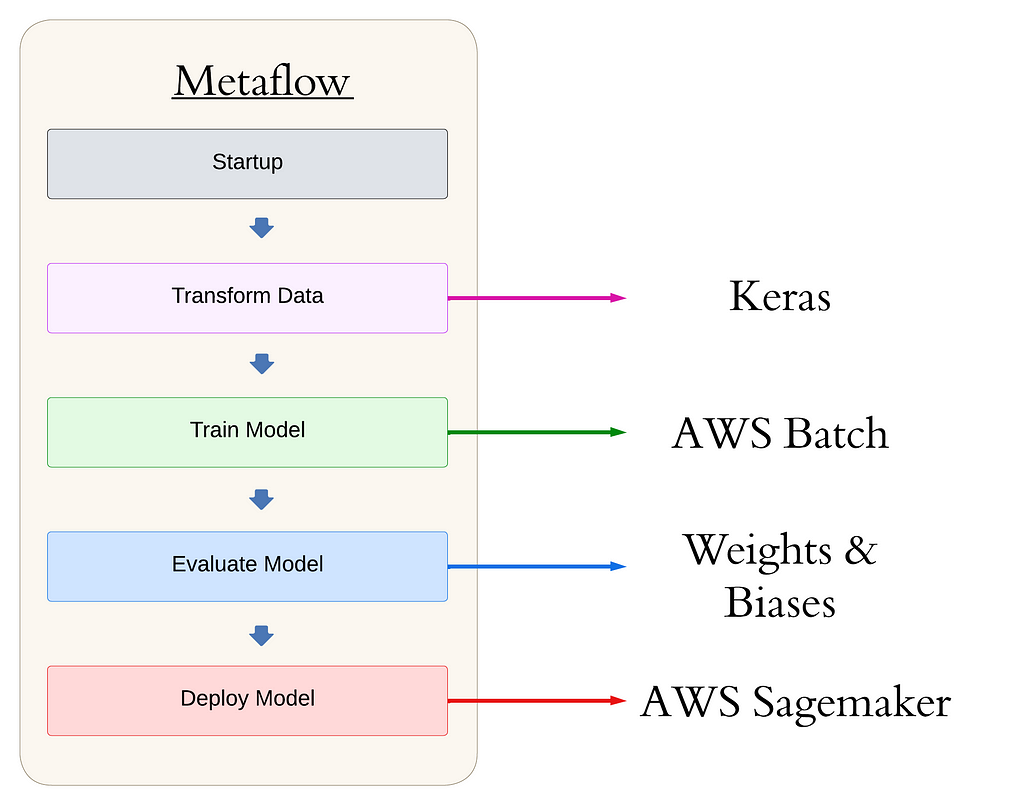
Before we dive into the specifics, let’s take a look at the high-level structure of our Metaflow pipeline. This will give you a bird’s-eye view of the workflow we’ll be discussing throughout the article:
from metaflow import FlowSpec, Parameter, step, current, batch, S3, environment
class main_flow(FlowSpec):
@step
def start(self):
"""
Start-up: check everything works or fail fast!
"""
self.next(self.augment_data_train_model)
@batch(gpu=1, memory=8192, image='docker.io/tensorflow/tensorflow:latest-gpu', queue="job-queue-gpu-metaflow")
@step
def augment_data_train_model(self):
"""
Code to pull data from S3, augment it, and train our model.
"""
self.next(self.evaluate_model)
@step
def evaluate_model(self):
"""
Code to evaluate our detection model, using Weights & Biases.
"""
self.next(self.deploy)
@step
def deploy(self):
"""
Code to deploy our detection model to a Sagemaker endpoint
"""
self.next(self.end)
@step
def end(self):
"""
The final step!
"""
print("All done. nn Congratulations! Plants around the world will thank you. n")
return
if __name__ == '__main__':
main_flow()
This structure forms the backbone of our production-grade object detection pipeline. Metaflow is Pythonic, using decorators to denote functions as steps in a pipeline, handle dependency management, and move compute to the cloud. Steps are run sequentially via the self.next() command. For more on Metaflow, see the documentation.
The Reality of MLOps without Ops
One of the promises of Metaflow is that a data scientist should be able to focus on the things they care about; typically model development and feature engineering (think Kaggle), while abstracting away the things that they don’t care about (where compute is run, where data is stored, etc.) There is a phrase for this idea: “MLOps without the Ops”. I took this to mean that I would be able to abstract away the work of an MLOps Engineer, without actually learning or doing much of the ops myself. I thought I could get away without learning about Docker, CloudFormation templating, EC2 instance types, AWS Service Quotas, Sagemaker endpoints, and AWS Batch configurations.
Unfortunately, this was naive. I realized that the CloudFormation template linked on so many Metaflow tutorials provided no way of provisioning GPUs from AWS(!). This is a fundamental part of doing data science in the cloud, so the lack of documentation was surprising. (I am not the first to wonder about the lack of documentation on this.)
Below is a code snippet demonstrating what sending a job to the cloud looks like in Metaflow:
@pip(libraries={'tensorflow': '2.15', 'keras-cv': '0.9.0', 'pycocotools': '2.0.7', 'wandb': '0.17.3'})
@batch(gpu=1, memory=8192, image='docker.io/tensorflow/tensorflow:latest-gpu', queue="job-queue-gpu-metaflow")
@environment(vars={
"S3_BUCKET_ADDRESS": os.getenv('S3_BUCKET_ADDRESS'),
'WANDB_API_KEY': os.getenv('WANDB_API_KEY'),
'WANDB_PROJECT': os.getenv('WANDB_PROJECT'),
'WANDB_ENTITY': os.getenv('WANDB_ENTITY')})
@step
def augment_data_train_model(self):
"""
Code to pull data from S3, augment it, and train our model.
"""
Note the importance of specifying what libraries are required and the necessary environment variables. Because the compute job is run on the cloud, it will not have access to the virtual environment on your local computer or to the environment variables in your .env file. Using Metaflow decorators to solve this issue is elegant and simple.
It is true that you do not have to be an AWS expert to be able to run compute jobs on the cloud, but don’t expect to just install Metaflow, use the stock CloudFormation template, and have success. MLOps without the Ops is too good to be true; perhaps the phrase should be MLOps without the Ops; after learning some Ops.
Managing Dependencies Effectively
One of the most important considerations when trying to turn a dev project into a production project is how to manage dependencies. Dependencies refer to Python packages, such as TensorFlow, PyTorch, Keras, Matplotlib, etc.
Dependency management is comparable to managing ingredients in a recipe to ensure consistency. A recipe might say “Add a tablespoon of salt.” This is somewhat reproducible, but the knowledgable reader may ask “Diamond Crystal or Morton?” Specifying the exact brand of salt used maximizes reproducibility of the recipe.
In a similar way, there are levels to dependency management in machine learning:
- Use a requirements.txt file. This simple option lists all Python packages with pinned versions. This works fairly well, but has limitations: although you may pin these high level dependencies, you may not pin any transitive dependencies (dependencies of dependencies). This makes it very difficult to create reproducible environments and slows down runtime as packages are downloaded and installed. For example:
pinecone==4.0.0
langchain==0.2.7
python-dotenv==1.0.1
pandas==2.2.2
streamlit==1.36.0
iso-639==0.4.5
prefect==2.19.7
langchain-community==0.2.7
langchain-openai==0.1.14
langchain-pinecone==0.1.1
This works fairly well, but has limitations: although you may pin these high level dependencies, you may not pin any transitive dependencies (dependencies of dependencies). This makes it very difficult to create reproducible environments and slows down runtime as packages are downloaded and installed.
- Use a Docker container. This is the gold standard. This encapsulates the entire environment, including the operating system, libraries, dependencies, and configuration files, making it very consistent and reproducible. Unfortunately, working with Docker containers can be somewhat heavy and difficult, especially if the data scientist doesn’t have prior experience with the platform.
Metaflow @pypi/@conda decorators cut a middle road between these two options, being both lightweight and simple for the data scientist to use, while being more robust and reproducible than a requirements.txt file. These decorators essentially do the following:
- Create isolated virtual environments for every step of your flow.
- Pin the Python interpreter versions, which a simple requirements.txt file won’t do.
- Resolves the full dependency graph for every step and locks it for stability and reproducibility. This locked graph is stored as metadata, allowing for easy auditing and consistent environment recreation.
- Ships the locally resolved environment for remote execution, even if the remote environment has a different OS and CPU architecture than the client.
This is much better then simply using a requirements.txt file, while requiring no additional learning on the part of the data scientist.
Let’s go revisit the train step to see an example:
@pypi(libraries={'tensorflow': '2.15', 'keras-cv': '0.9.0', 'pycocotools': '2.0.7', 'wandb': '0.17.3'})
@batch(gpu=1, memory=8192, image='docker.io/tensorflow/tensorflow:latest-gpu', queue="job-queue-gpu-metaflow")
@environment(vars={
"S3_BUCKET_ADDRESS": os.getenv('S3_BUCKET_ADDRESS'),
'WANDB_API_KEY': os.getenv('WANDB_API_KEY'),
'WANDB_PROJECT': os.getenv('WANDB_PROJECT'),
'WANDB_ENTITY': os.getenv('WANDB_ENTITY')})
@step
def augment_data_train_model(self):
"""
Code to pull data from S3, augment it, and train our model.
"""
All we have to do is specify the library and version, and Metaflow will handle the rest.
Unfortunately, there is a catch. My personal laptop is a Mac. However, the compute instances in AWS Batch have a Linux architecture. This means that we must create the isolated virtual environments for Linux machines, not Macs. This requires what is known as cross-compiling. We are only able to cross-compile when working with .whl (binary) packages. We can’t use .tar.gz or other source distributions when attempting to cross-compile. This is a feature of pip not a Metaflow issue. Using the @conda decorator works (conda appears to resolve what pip cannot), but then I have to use the tensorflow-gpu package from conda if I want to use my GPU for compute, which comes with its own host of issues. There are workarounds, but they add too much complication for a tutorial that I want to be straightforward. As a result, I essentially had to go the pip install -r requirements.txt (used a custom Python @pip decorator to do so.) Not great, but hey, it does work.
How to Debug a Production Flow
Initially, using Metaflow felt slow. Each time a step failed, I had to add print statements and re-run the entire flow — a time-consuming and costly process, especially with compute-intensive steps.
Once I discovered that I could store flow variables as artifacts, and then access the values for these artifacts afterwards in a Jupyter notebook, my iteration speed increased dramatically. For example, when working with the output of the model.predict call, I stored variables as artifacts for easy debugging. Here’s how I did it:
image = example["images"]
self.image = tf.expand_dims(image, axis=0) # Shape: (1, 416, 416, 3)
y_pred = model.predict(self.image)
confidence = y_pred['confidence'][0]
self.confidence = [conf for conf in confidence if conf != -1]
self.y_pred = bounding_box.to_ragged(y_pred)
Here, model is my fully-trained object detection model, and image is a sample image. When I was working on this script, I had trouble working with the output of the model.predict call. What type was being output? What was the structure of the output? Was there an issue with the code to pull the example image?
To inspect these variables, I stored them as artifacts using the self._ notation. Any object that can be pickled can be stored as a Metaflow artifact. If you follow my tutorial, these artifacts will be stored in an Amazon S3 buckets for referencing in the future. To check that the example image is correctly being loaded, I can open up a Jupyter notebook in my same repository on my local computer, and access the image via the following code:
import matplotlib.pyplot as plt
latest_run = Flow('main_flow').latest_run
step = latest_run['evaluate_model']
sample_image = step.task.data.image
sample_image = sample_image[0,:, :, :]
one_image_normalized = sample_image / 255
# Display the image using matplotlib
plt.imshow(one_image_normalized)
plt.axis('off') # Hide the axes
plt.show()
Here, we get the latest run of our flow and make sure we are getting our flow’s information by specifying main_flow in the Flow call. The artifacts I stored came from the evaluate_model step, so I specify this step. I get the image data itself by calling .data.image . Finally we can plot the image to check and see if our test image is valid, or if it got messed up somewhere in the pipeline:

Great, this matches the original image downloaded from the PlantDoc dataset (as strange as the colors appear.) To check out the predictions from our object detection model, we can use the following code:
latest_run = Flow('main_flow').latest_run
step = latest_run['evaluate_model']
y_pred = step.task.data.y_pred
print(y_pred)
The output appears to suggest that there were no predicted bounding boxes from this image. This is interesting to note, and can illuminate why a step is behaving oddly or breaking.
All of this is done from a simple Jupyter notebook that all data scientists are comfortable with. So when should you store variables as artifacts in Metaflow? Here is a heuristic from Ville Tuulos [2]:
RULE OF THUMB Use instance variables, such as self, to store any data and objects that may have value outside the step. Use local variables only for inter- mediary, temporary data. When in doubt, use instance variables because they make debugging easier.
Learn from my lesson if you are using Metaflow: take full advantage of artifacts and Jupyter notebooks to make debugging a breeze in your production-grade project.
One more note on debugging: if a flow fails in a particular step, and you want to re-run the flow from that failed step, use the resume command in Metaflow. This will load in all relevant output from previous steps without wasting time on re-executing them. I didn’t appreciate the simplicity of this until I tried out Prefect, and found out that there was no easy way to do the same.
Finding the Goldilocks Step Size
What is the Goldilocks size of a step? In theory, you can stuff your entire script into one huge pull_and_augment_data_and_train_model_and_evaluate_model_and_deploy step, but this is not advisable. If a part of this flow fails, you can’t easily use the resume function to skip re-running the entire flow.
Conversely, it is also possible to chunk a script into a hundred micro-steps, but this is also not advisable. Storing artifacts and managing steps creates some overhead, and having a hundred steps would dominate the execution time. To find the Goldilocks size of a step, Tuulos tells us:
RULE OF THUMB Structure your workflow in logical steps that are easily explainable and understandable. When in doubt, err on the side of small steps. They tend to be more easily understandable and debuggable than large steps.
Initially, I structured my flow with these steps:
- Augment data
- Train model
- Evaluate model
- Deploy model
After augmenting the data, I had to upload the data to an S3 bucket, and then download the augmented data in the train step for training the model for two reasons:
- the augment step was to take place on my local laptop while the train step was going to be sent to a GPU instance on the cloud.
- Metaflow’s artifacts, normally used for passing data between steps, couldn’t handle TensorFlow Dataset objects as they are not pickle-able. I had to convert them to tfrecords and upload them to S3.
This upload/download process took a long time. So I combined the data augmentation and training steps into one. This reduced the flow’s runtime and complexity. If you’re curious, check out the separate_augement_train branch in my GitHub repo for the version with separated steps.
Takeaways
In this article, I discussed some of the highs and lows I experienced when productionizing my object detection project. A quick summary:
- You will have to learn some ops in order to get to MLOps without the ops. But after learning some of the fundamental setup required, you will be able to ship compute jobs out to AWS using just a Python decorator. The repo attached to this article covers how to provision GPUs in AWS, so study this closely if this is one of your goals.
- Dependency management is a critical step in production. A requirements.txt file is the bare minimum, Docker is the gold standard, while Metaflow has a middle path that is usable for many projects. Just not this one, unfortunately.
- Use artifacts and Jupyter notebooks for easy debugging in Metaflow. Use the resume to avoid re-running time/compute-intensive steps.
- When breaking a script into steps for entry into a Metaflow flow, try to break up the steps into reasonable size steps, erring on the side of small steps. But don’t be afraid to combine steps if the overhead is just too much.
There are still aspects of this project that I would like to improve on. One would be adding data so that we would be able to detect diseases on more varied plant species. Another would be to add a front end to the project and allow users to upload images and get object detections on demand. A library like Streamlit would work well for this. Finally, I would like the performance of the final model to become state-of-the-art. Metaflow has the ability to parallelize training many models simultaneously which would help with this goal. Unfortunately this would require lots of compute and money, but this is required of any state-of-the-art model.
References
[1] C. Huyen, Introduction to Machine Learning Interviews (2021), Self-published
[2] V. Tuulos, Effective Data Science Infrastructure (2022), Manning Publications Co.
Streamlining Object Detection with Metaflow, AWS, and Weights & Biases was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.