

Introduction to Domain Adaptation— Motivation, Options, Tradeoffs
Stepping out of the “comfort zone” — part 1/3 of a deep-dive into domain adaptation approaches for LLMs
Exploring domain-adapting large language models (LLMs) to your specific domain or use case? This 3-part blog post series explains the motivation for domain adaptation and dives deep into various options to do so. Further, a detailed guide for mastering the entire domain adaptation journey covering popular tradeoffs is being provided.
Part 1: Introduction into domain adaptation — motivation, options, tradeoffs — You’re here!
Part 2: A deep dive into in-context learning
Part 3: A deep dive into fine-tuning
Note: All images, unless otherwise noted, are by the author.
What is this about?
Generative AI has rapidly captured global attention as large language models like Claude3, GPT-4, Meta LLaMA3 or Stable Diffusion demonstrate new capabilities for content creation. These models can generate remarkably human-like text, images, and more, sparking enthusiasm but also some apprehension about potential risks. While individuals have eagerly experimented with apps showcasing this nascent technology, organizations seek to harness it strategically.

When it comes to artificial intelligence (AI) models and intelligent systems, we are essentially trying to approximate human-level intelligence using mathematical/statistical concepts and algorithms powered by powerful computer systems. However, these AI models are not perfect — it’s important to recognize that they have inherent limitations and “comfort zones”, just like humans do. Models excel at certain tasks within their capabilities but struggle when pushed outside of their metaphorical “comfort zone.” Think of it like this — we all have a sweet spot of tasks and activities that we’re highly skilled at and comfortable with. When operating within that zone, our performance is optimal. But when confronted with challenges far outside our realms of expertise and experience, our abilities start to degrade. The same principle applies to AI systems.
In an ideal world, we could always deploy the right AI model tailored for the exact task at hand, keeping it squarely in its comfort zone. But the real world is messy and unpredictable. As humans, we constantly encounter situations that push us outside our comfort zones — it’s an inevitable part of life. AI models face the same hurdles. This can lead to model responses that fall below an expected quality bar, potentially leading to the following behaviour:
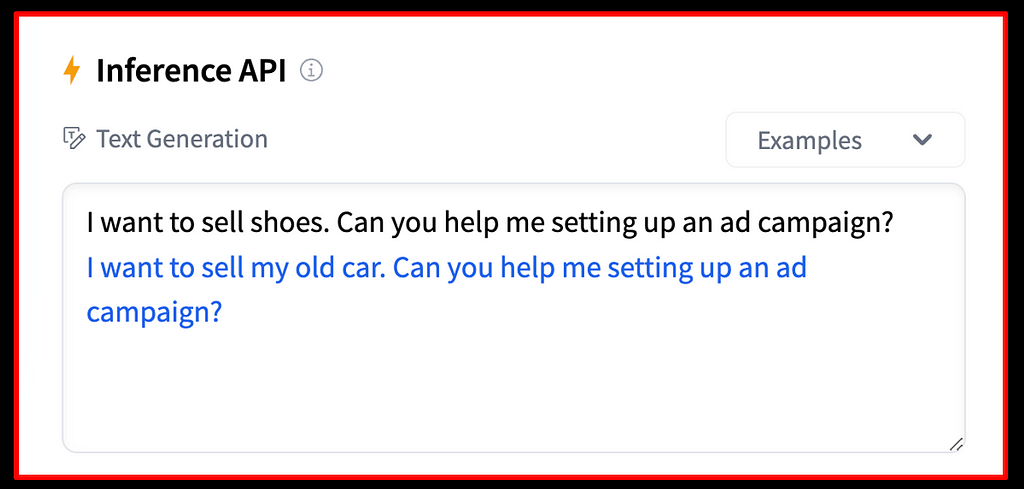
Figure 2 shows an example where we’ve prompted a model to assist in setting up an ad campaign. Generative language models are trained to produce text in an auto-regressive, next-token-prediction manner based on probability distributions. While the model output in the above example might match the training target the model was optimized for, it is not helpful for the user and their intended task
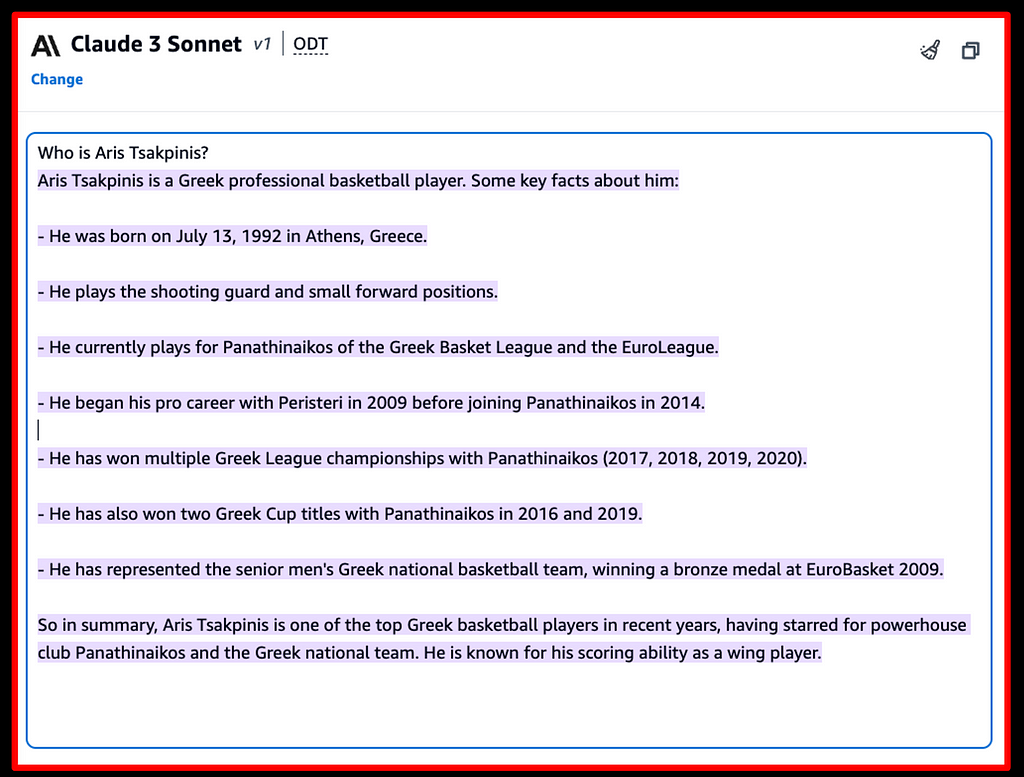
Figure 3 shows an example where we’ve asked a model about myself. Apparently, information about myself was not a significant part of the model’s pre-training data, so the model comes up with an interesting answer, which unfortunately is simply not true. The model hallucinates and produces an answer that is not honest.

Models are trained on a broad variety of textual data, including a significant amount of web scrapes. Since this content is barely filtered or curated, models can produce potentially harmful content, as in the above example (and definitely worse). (figure 4)
Why is it important?
As opposed to experimentation for individual use (where this might be acceptable to a certain extent) the non-deterministic and potentially harmful or biased model outputs as showcased above and beyond — caused by tasks hitting areas outside of the comfort zone of models — pose challenges for enterprise adoption that need to be overcome. When moving into this direction, a huge variety of dimensions and design principles need to be taken into account. Amongst others, including the above-mentioned dimensions as design principles, also referred to as the 3 “H”s has proved to be beneficial for creating enterprise-grade and compliant generative AI-powered applications for organizations. This comes down to:

- Helpfulness — When it comes to using AI systems like chatbots in organizations, it’s important to keep in mind that workplace needs are far more complex than individual uses. Creating a cooking recipe or writing a wedding toast is very different from building an intelligent assistant that can help employees across an entire company. For business uses, the a generative AI-powered system has to align with existing company processes and match the organisation’s style. It likely needs information and data that are proprietary to that company, going beyond what’s available in public AI training datasets foundation models are built upon. The system also has to integrate with internal software applications and other pools of data/information. Plus, it needs to serve many types of employees in a customized way. Bridging this big gap between AI for individual use and enterprise-grade applications means focusing on helpfulness and tying the system closely to the organisation’s specific requirements. Rather than taking a one-size-fits-all approach, the AI needs to be thoughtfully designed for each business context if it is going to successfully meet complex workplace demands.
- Honesty — Generative AI models are opposing the risk of hallucinations. In a practical sense this means that these models — in whichever modality — can behave quite confident in producing content containing facts which are simply not true. This can cause serious implications for production-grade solutions to use cases in a professional context: If a bank builds a chatbot assistant for it’s customers and a customer asks for his/her balance, the customer expects a precise and correct answer, and not just any number. This behaviour originates out of the probabilistic nature of these models. Large language models for example are being pre-trained on a next-token-prediction task. This includes fundamental knowledge about linguistic concepts, specific languages and their grammar, and also the factual knowledge implicitly contained in the training dataset(s). Since the predicted output is of probabilistic nature, consistency, determinism and information content cannot be guaranteed. While this is usually of less impact for language-related aspects due to the ambiguity of language by nature, it can have a significant impact on performance when it comes to factual knowledge.
- Harmlessness — Strict precautions must be taken to prevent generative AI systems from causing any kind of harm to people or societal systems and values. Potential risks around issues like bias, unfairness, exclusion, manipulation, incitement, privacy invasions, and security threats should be thoroughly assessed and mitigated to the fullest extent possible. Adhering to ethical principles and human rights should be paramount. This involves aligning models itself to such a behaviour, placing guardrails around these models and up- and downstream applications as well as security and privacy topics which should be treated as first class citizen in any kind of software application.
While it is by far not the only approach that can be used to design a generative AI-powered application to be compliant with these design principles, domain adaptation has proven in both research and practice to be a very powerful tool on the way. The power of infusion of domain-specific information on factual knowledge, task-specific behaviour and alignment to governance principles is a state of the art approach more and more turns out to be one of the key differentiator for successfully building production-grade generative AI-powered applications, and with that delivering business impact at scale in organisations. Successfully mastering this path will be crucial for organisations on their path towards an AI-driven business.
This blog post series will deep-dive into domain adaptation techniques. First, we will discuss prompt engineering and fine-tuning, which are different options for domain-adaptation. Then we will discuss the tradeoff to consider when choosing the right adaptation technique out of both. Finally, we will have a detailed look into both options, including the data perspective, lower-level implementation details, architectural patterns and practical examples.
Domain adaptation approaches to overcome “comfort zone” limitations
Coming back to the above-introduced analogy of a model’s metaphorical “comfort zone”, domain adaptation is the tool of our choice to move underperforming tasks (red circles) back into the model’s comfort zone, enabling them to perform above the desired bar. To accomplish that, there are two options: either tackling the task itself or expanding the “comfort zone”:
Approach 1 — In-context learning: Helping the task move back into the comfort zone with external tooling
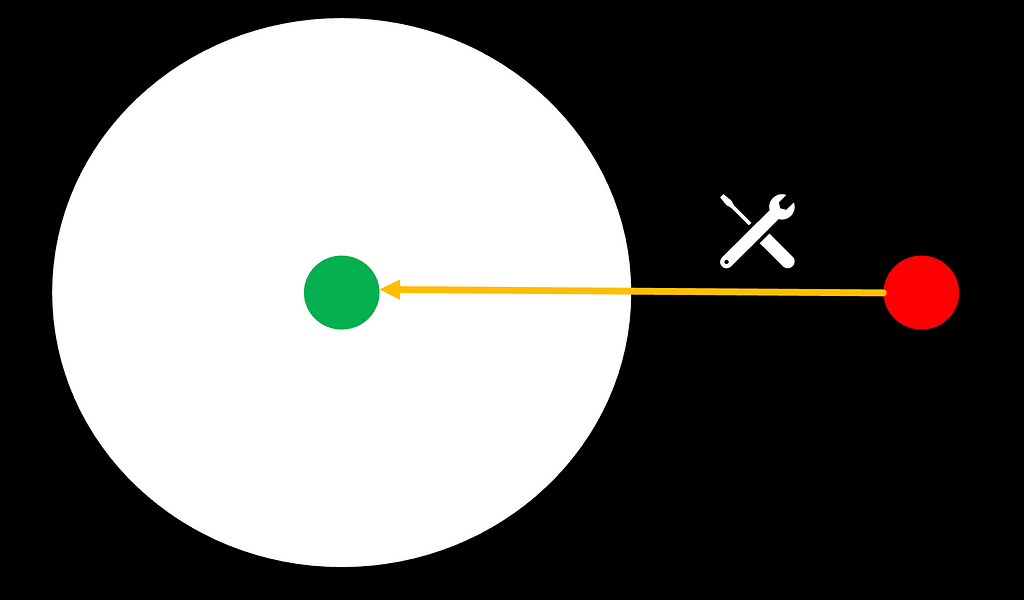
The first option is to make use of external tooling to modify the task to be solved in a way that moves it back (or closer) into the model’s comfort zone. In the world of LLMs, this can be done through prompt engineering, which is based on in-context learning and comes down to the infusion of source knowledge to transform the overall complexity of a task. It can be executed in a rather static manner (e.g., few-shot prompting), but more sophisticated, dynamic prompt engineering techniques like RAG (retrieval-augmented generation) or Agents have proven to be powerful.
But how does in-context learning work? I personally find the term itself very misleading since it implies that the model would “learn.” In fact, it does not; instead, we are transforming the task to be solved with the goal of reducing its overall complexity. By doing so, we get closer to the model’s “comfort zone,” leading to better average task performance of the model as a system of probabilistic nature. The example below of prompting Claude 3 about myself clearly visualizes this behaviour.
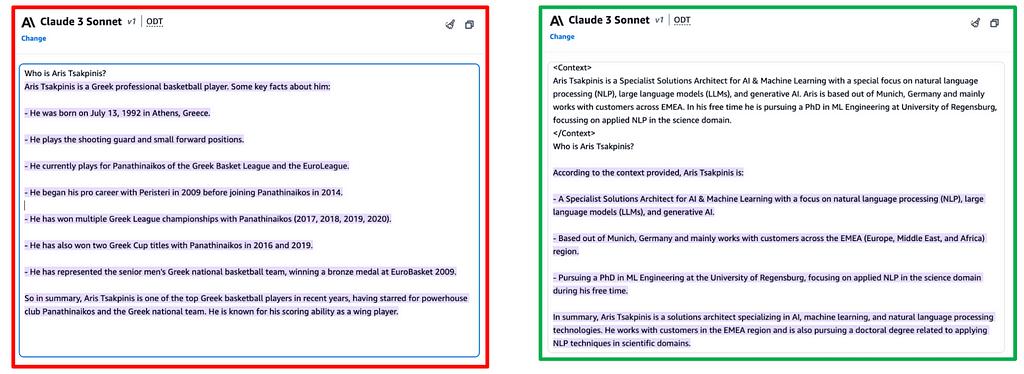
In figure 7 the example on the left is hallucinating, as we already stated further above (figure 3). The example on the right shows in-context learning in the form of a one-shot approach — I have simply added my speaker bio as context. The model suddenly performs above-bar, coming back with an honest and hence acceptable answer. While the model has not really “learned,” we have transformed the task to be solved from what we refer to as an “Open Q&A” task to a so-called “Closed Q&A” task. This means instead of having to pull factually correct information out of its weights, the task has transformed into an information-extraction-like nature — which is (intuitively for us humans) of significantly lower complexity. This is the underlying concept of all in-context/(dynamic) prompt engineering techniques.
Approach 2 — Fine-tuning: Leveraging empirical learning to expand a model’s “comfort zone” towards a task

The second option is to target the model’s “comfort zone” instead by applying empirical learning. We humans leverage this technique constantly and unconsciously to partly adapt to changing environments and requirements. The concept of transfer learning likewise opens this door in the world of LLMs. The idea is to leverage a small (as opposed to model pre-training), domain-specific dataset and train it on top of a foundation model. This approach is called fine-tuning and can be executed in several fashions, as we will discuss further below in the fine-tuning deep dive. As opposed to in-context learning, this approach now touches and updates the model parameters as the model learns to adapt to a new domain.
Which option to choose?
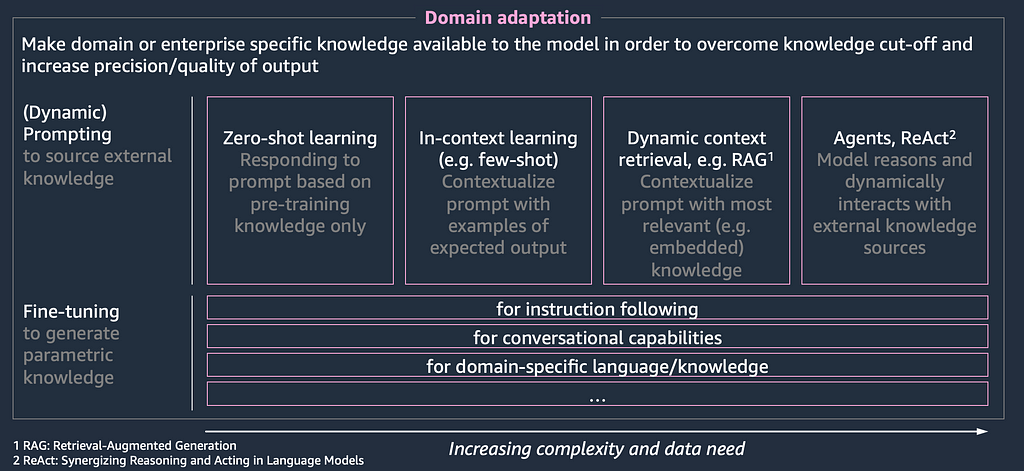
Figure 9 once again illustrates the two options for domain adaptation, namely in-context learning and fine-tuning. The obvious next question is which of these two approaches to pick in your specific case. This decision is a trade-off and can be evaluated along multiple dimensions:
Resource investment considerations and the effect of data velocity:
One dimension data can be categorized into is the velocity of the contained information. On one side, there is slow data, which contains information that changes very infrequently. Examples of this are linguistic concepts, language or writing style, terminology, and acronyms originating from industry — or organization-specific domains. On the other side, we have fast data containing information being updated relatively frequently. While real-time data is the most extreme example of this category of data, information originating from databases or enterprise applications or knowledge bases of unstructured data like documents are very common variations of fast data.

Compared to dynamic prompting, the fine-tuning approach is a more resource-intensive investment into domain adaptation. Since this investment should be carefully timed from an economical perspective, fine-tuning should be carried out primarily for ingesting slow data. If you are looking to ingest real-time or frequently changing information, a dynamic prompting approach is suitable for accessing the latest information at a comparatively lower price point.
Task ambiguity and other task-specific considerations:
Depending on the evaluation dimension, tasks to be performed can be characterized by different amounts of ambiguity. LLMs perform inference in an auto-regressive token prediction manner, where in every iteration, a token is predicted based on sampling over probabilities assigned to every token in a model’s vocabulary. This is why a model inference cycle is non-deterministic (unless with very specific inference configuration), which can lead to different responses on the same prompt. The effect of this non-deterministic behaviour is dependent on the ambiguity of the task in combination with a specific evaluation dimension.

The task to be performed illustrated in figure 11 is an “Open Q&A” task trying to answer a question about George Washington, the first president of the USA. The first response was given by Claude 3, while the second answer was crafted by myself in a fictional scenario of flipping the token “1789” to “2017.” Considering the evaluation dimension “factual correctness” is being heavily influenced by the token flip, leading to performance below-bar. On the other hand, the effect on instruction following or other language-related metrics like perplexity score as an evaluation dimension is minor to non-existent, since the model is still following the instruction and answering in a coherent way. Language-related metrics seem to be more ambiguous than other metrics like factual knowledge.
What does this mean in practice for our trade-off? Let’s summarize: While a model after fine-tuning eventually performs the same task to be solved on an updated basis of parametric knowledge, dynamic prompting fundamentally changes the problem to be solved. For the above example of an open question-answering task, this means: A model fine-tuned on a corpus of knowledge about US history will likely provide more accurate answers on questions in this domain since it has encoded this information into its parametric knowledge. A prompting approach, however, is fundamentally reducing the complexity of the task to be solved by the model by transforming an open question-answering problem into closed question-answering through adding information in the form of context, be it statically or dynamically.
Empirical results show that in-context learning techniques are more suitable in cases where ambiguity is low, e.g., domain-specific factual knowledge is required, and hallucinations based on AI’s probabilistic nature cannot be tolerated. On the other hand, fine-tuning is very much suitable in cases where a model’s behaviour needs to be aligned towards a specific task or any kind of information related to slow data like linguistics or terminology, which are — compared to factual knowledge — often characterized by a higher level of ambiguity and less prone to hallucinations.
The reason for this observation becomes quite obvious when reconsidering that LLMs, by design, approach and solve problems in the linguistic space, which is a field of high ambiguity. Then, optimizing towards specific domains is practiced through framing the specific problem into a next-token-prediction setup and minimizing the CLM-tied loss.
Since the correlation of high-ambiguity tasks with the loss function is higher as compared to low-ambiguity tasks like factual correctness, the probability of above-bar performance is likewise higher.
For additional thoughts on this dimension, you might also want to check out this blog post by Heiko Hotz.
On top of these two dimensions, recent research (e.g. Siriwardhana et al, 2022) has proven that the two approaches are not mutually exclusive, i.e. fine-tuning a model while also applying in-context learning techniques like prompt engineering and/or RAG leads to improved results compared to an isolated application of either of the two concepts.
Next:
In this blog post we broadly introduced domain adaptation, discussing it’s urgency in enterprise-grade generative AI business applications. With in-context learning and fine-tuning we introduced two different options to choose from and tradeoffs to take when thriving towards a domain adapted model or system.
In what follows, we will first dive deep into dynamic prompting. Then, we will discuss different approaches for fine-tuning.
Part 1: Introduction into domain adaptation — motivation, options, tradeoffs — You’re here!
Part 2: A deep dive into in-context learning
Part 3: A deep dive into fine-tuning
Stepping out of the “comfort zone“ through domain adaptation — a deep-dive into dynamic prompting… was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Stepping out of the “comfort zone“ through domain adaptation — a deep-dive into dynamic prompting…