A beginner-friendly tutorial on generating your own data for analysis and testing

Imagine you just coded a machine learning model and need to test it on specific scenarios, or you are publishing an academic paper about a custom data science solution but the available datasets have copyright limitations. On the other hand, you might be in the debugging and troubleshooting phase of a machine learning project and need data to identify and resolve issues.
All these situations, and many more, can benefit from using simulated data. Frequently, real-world data is not readily available, expensive, or private. Therefore, creating synthetic data is a useful skill for data science practitioners and professionals.
In this article, I present some methods and techniques for creating simulated data, toy datasets, and “dummy” values from scratch using Python. Some solutions use methods from Python libraries and others are techniques that use built-in Python functions.
All the methods shown in the next sections were useful for me at some point in research tasks, academic papers, model training, or testing. I hope the reader explores the notebook at the end of the article and uses it as a guide or keeps it as a reference for future projects.
Table of contents
1. Using NumPy
2. Using Scikit-learn
3. Using SciPy
4. Using Faker
5. Using Synthetic Data Vault (SDV)
Conclusions and Next Steps
1. Using NumPy
The most famous Python library for dealing with linear algebra and numerical computing is also helpful for data generation.
- Linear data generation
In this example, I’ll show how to create a dataset with noise having a linear relationship with the target values. It can be useful for testing linear regression models.
# importing modules
from matplotlib import pyplot as plt
import numpy as np
def create_data(N, w):
"""
Creates a dataset with noise having a linear relationship with the target values.
N: number of samples
w: target values
"""
# Feature matrix with random data
X = np.random.rand(N, 1) * 10
# target values with noise normally distributed
y = w[0] * X + w[1] + np.random.randn(N, 1)
return X, y
# Visualize the data
X, y = create_data(200, [2, 1])
plt.figure(figsize=(10, 6))
plt.title('Simulated Linear Data')
plt.xlabel('X')
plt.ylabel('y')
plt.scatter(X, y)
plt.show()

- Time series data
In this example, I’ll use NumPy to generate synthetic time series data with a linear trend and a seasonal component. That example is useful for financial modeling and stock market prediction.
def create_time_series(N, w):
"""
Creates a time series data with a linear trend and a seasonal component.
N: number of samples
w: target values
"""
# time values
time = np.arange(0,N)
# linear trend
trend = time * w[0]
# seasonal component
seasonal = np.sin(time * w[1])
# noise
noise = np.random.randn(N)
# target values
y = trend + seasonal + noise
return time, y
# Visualize the data
time, y = create_time_series(100, [0.25, 0.2])
plt.figure(figsize=(10, 6))
plt.title('Simulated Time Series Data')
plt.xlabel('Time')
plt.ylabel('y')
plt.plot(time, y)
plt.show()

- Custom data
Sometimes it’s needed data with particular characteristics. For example, you may need a high-dimensional dataset with only a few informative dimensions for dimensionality reduction tasks. In that case, the example below shows an adequate method to generate such datasets.
# create simulated data for analysis
np.random.seed(42)
# Generate a low-dimensional signal
low_dim_data = np.random.randn(100, 3)
# Create a random projection matrix to project into higher dimensions
projection_matrix = np.random.randn(3, 6)
# Project the low-dimensional data to higher dimensions
high_dim_data = np.dot(low_dim_data, projection_matrix)
# Add some noise to the high-dimensional data
noise = np.random.normal(loc=0, scale=0.5, size=(100, 6))
data_with_noise = high_dim_data + noise
X = data_with_noise
The code snippet above creates a dataset with 100 observations and 6 features based on a lower dimensional array of only 3 dimensions.
2. Using Scikit-learn
In addition to machine learning models, Scikit-learn has data generators useful for building artificial datasets with controlled size and complexity.
- Make classification
The make_classification method can be used to create a random n-class dataset. That method allows the creation of datasets with a chosen number of observations, features, and classes.
It can be useful for testing and debugging classification models such as support vector machines, decision trees, and Naive Bayes.
X, y = make_classification(n_samples=1000, n_features=5, n_classes=2)
#Visualize the first rows of the synthetic dataset
import pandas as pd
df = pd.DataFrame(X, columns=['feature1', 'feature2', 'feature3', 'feature4', 'feature5'])
df['target'] = y
df.head()
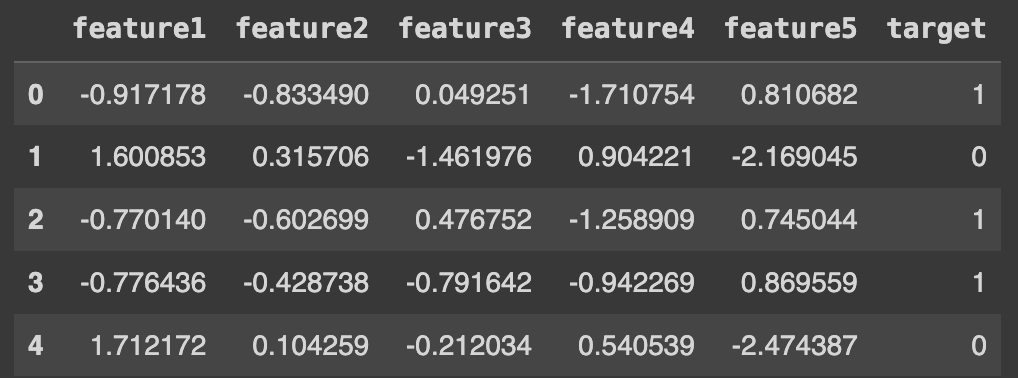
- Make regression
Similarly, the make_regression method is useful for creating datasets for regression analysis. It allows to set the number of observations, the number of features, the bias, and the noise of the resulting dataset.
from sklearn.datasets import make_regression
X,y, coef = make_regression(n_samples=100, # number of observations
n_features=1, # number of features
bias=10, # bias term
noise=50, # noise level
n_targets=1, # number of target values
random_state=0, # random seed
coef=True # return coefficients
)
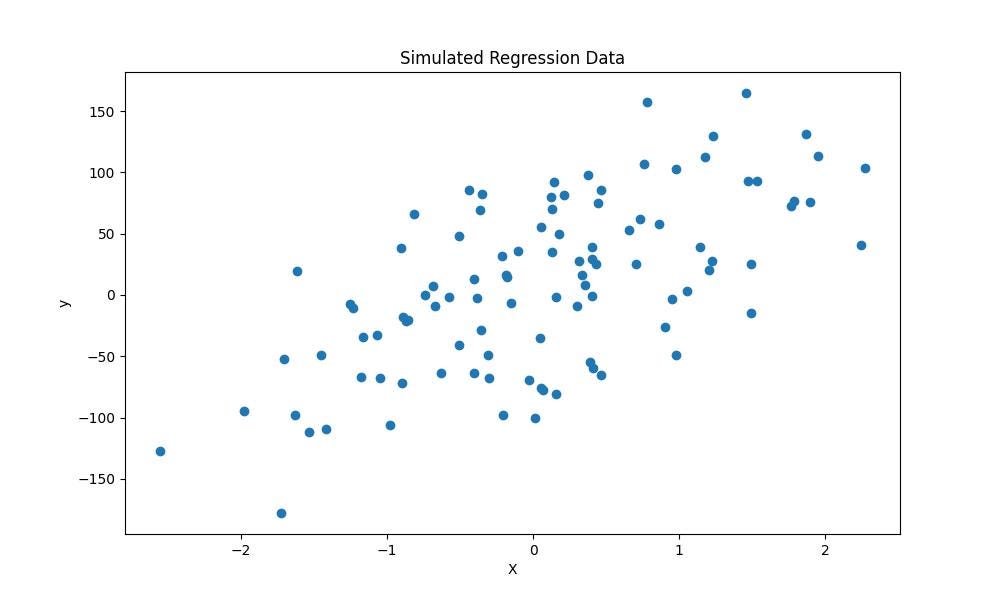
- Make blobs
The make_blobs method allows the creation of artificial “blobs” with data that can be used for clustering tasks. It allows setting the total number of points in the dataset, the number of clusters, and the intra-cluster standard deviation.
from sklearn.datasets import make_blobs
X,y = make_blobs(n_samples=300, # number of observations
n_features=2, # number of features
centers=3, # number of clusters
cluster_std=0.5, # standard deviation of the clusters
random_state=0)
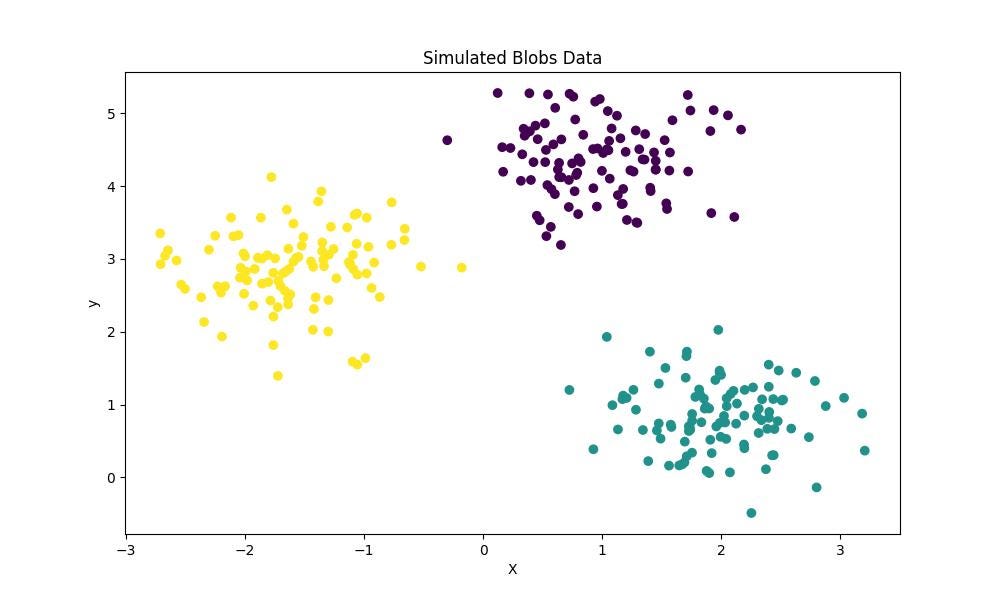
3. Using SciPy
The SciPy (short for Scientific Python) library is, along with NumPy, one of the best ones for handling numerical computing, optimization, statistical analysis, and many other mathematical tasks. The stats model of SciPy can create simulated data from many statistical distributions, such as normal, binomial, and exponential distributions.
from scipy.stats import norm, binom, expon
# Normal Distribution
norm_data = norm.rvs(size=1000)
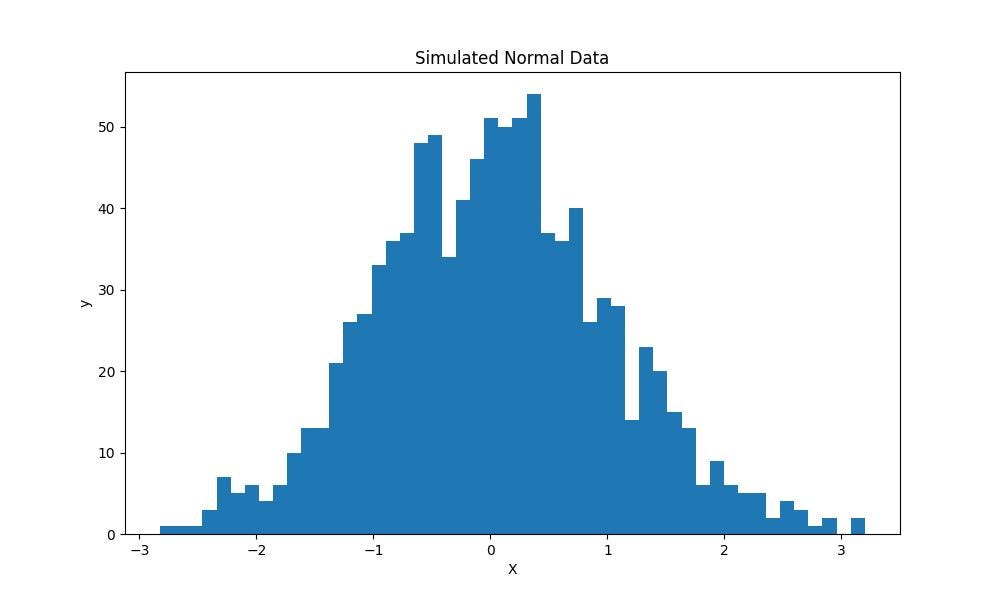
# Binomial distribution
binom_data = binom.rvs(n=50, p=0.8, size=1000)
# Exponential distribution
exp_data = expon.rvs(scale=.2, size=10000)
4. Using Faker
What about non-numerical data? Often we need to train our model on non-numerical or user data such as name, address, and email. A solution for creating realistic data similar to user information is using the Faker Python library.
The Faker Library can generate convincing data that can be used to test applications and machine learning classifiers. In the example below, I show how to create a fake dataset with name, address, phone number, and email information.
from faker import Faker
def create_fake_data(N):
"""
Creates a dataset with fake data.
N: number of samples
"""
fake = Faker()
names = [fake.name() for _ in range(N)]
addresses = [fake.address() for _ in range(N)]
emails = [fake.email() for _ in range(N)]
phone_numbers = [fake.phone_number() for _ in range(N)]
fake_df = pd.DataFrame({'Name': names, 'Address': addresses, 'Email': emails, 'Phone Number': phone_numbers})
return fake_df
fake_users = create_fake_data(100)
fake_users.head()
5. Using Synthetic Data Vault (SDV)
What if you have a dataset that doesn’t have enough observations or you need more data similar to an existing dataset to supplement the training step of your machine-learning model? The Synthetic Data Vault (SDV) is a Python library that allows the creation of synthetic datasets using statistical models.
In the example below, we’ll use SDV to expand a demo dataset:
from sdv.datasets.demo import download_demo
# Load the 'adult' dataset
adult_data, metadata = download_demo(dataset_name='adult', modality='single_table')
adult_data.head()

from sdv.single_table import GaussianCopulaSynthesizer
# Use GaussianCopulaSynthesizer to train on the data
model = GaussianCopulaSynthesizer(metadata)
model.fit(adult_data)
# Generate Synthetic data
simulated_data = model.sample(100)
simulated_data.head()

Observe how the data is very similar to the original dataset but it’s synthetic data.
Conclusions and Next Steps
The article presented 5 ways of creating simulated and synthetic datasets that can be used for machine-learning projects, statistical modeling, and other tasks involving data. The examples shown are easy to follow, so I recommend exploring the code, reading the documentation available, and developing other data generation methods more suitable to every need.
As said before, data scientists, machine learning professionals, and developers can gain from using synthetic datasets by improving model performance and lowering the costs of production and application testing.
Check the notebook with all the methods explored in the article:
References
[1] DataCamp. “Creating Synthetic Data with Python and Faker.” DataCamp, https://www.datacamp.com/tutorial/creating-synthetic-data-with-python-faker-tutorial. Accessed 4 July 2024.
[2] Scikit-learn. “Generated Datasets.” Scikit-learn, https://scikit-learn.org/stable/datasets/sample_generators.html#sample-generators. Accessed 4 July 2024.
[3] SDV User Guide. “Gaussian Copula User Guide.” SDV, https://sdv.dev/SDV/user_guides/single_table/gaussian_copula.html. Accessed 4 July 2024.
[4] SciPy User Guide. “SciPy Tutorial.” SciPy Documentation, https://docs.scipy.org/doc/scipy/tutorial/index.html. Accessed 4 July 2024.
Step-by-Step Guide to Creating Simulated Data in Python was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Step-by-Step Guide to Creating Simulated Data in Python
Go Here to Read this Fast! Step-by-Step Guide to Creating Simulated Data in Python