SQL Server’s Secret Feature — Run Python and Add-Ons Natively In SQL Server
Import Python libraries, manipulate and output SQL tables and more, all without leaving SQL server.
The Problem
Within this project, we confront the challenge of managing 37,000 company names sourced from two distinct origins. The complexity lies in the potential discrepancy between how identical companies are listed across these sources.
The goal
The goal of this article is to teach you to run Python natively within Microsoft SQL server. To use add-ons and external libraries, as well as perform further processing on the resulting tables with SQL.

Initial Algorithm Build
Here is the strategy I will follow when building the algorithms:
- Blocking — Dividing datasets into smaller blocks or groups based on common attributes to reduce computational complexity in comparing records. It narrows down the search space and enhances efficiency in similarity search tasks.
- Pre-processing — Cleaning and standardizing raw data to prepare it for analysis by tasks like lowercase conversion, punctuation removal, and stop word elimination. This step improves data quality and reduces noise.
- Similarity search model application — Applying models to compute similarity or distance between pairs of records based on tokenized representations. This helps identify similar pairs, using metrics like cosine similarity or edit distance, for tasks like record linkage or deduplication.
Blocking
My datasets are highly disproportional — I have 1,361,373 entities in one table and only 37,171 company names in the second table. If I attempt to match on the unprocessed table, the algorithm would take a very long time to do so.
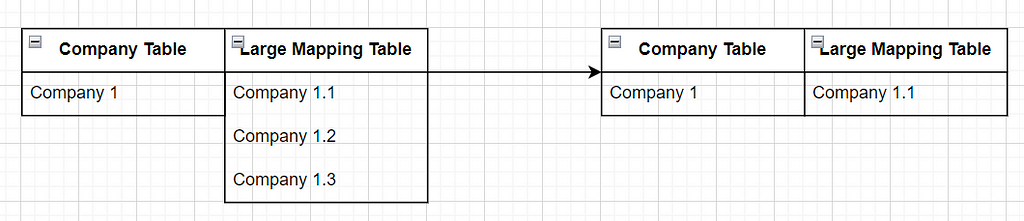
In order to block the tables, we need to see what common characteristics there are between 2 datasets. In my case, the companies are all associated with internal projects. Hence I will do the following:
- Extract the distinct company name and project code from the smaller table.
- Loop through the project codes and try to find them in the larger table.
- Map all of the funds for that project and take it out of the large table.
- Repeat for the next project!
This way, I will be reducing the large dataset with each iteration, while also making sure that the mapping is rapid due to a smaller, filtered dataset on the project level.
Now, I will filter both tables by the project code, like so:
With this approach, our small table only has 406 rows for project ‘ABC’ for us to map, while the big table has 15,973 rows for us to map against. This is a big reduction from the raw table.
Program Structure
This project will consist of both Python and SQL functions on SQL server; here is a quick sketch of how the program will work to have a clearer understanding of each step:
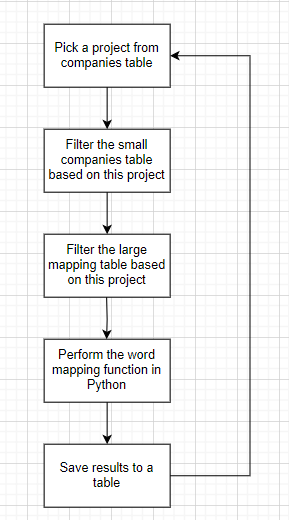
Program execution:
- Printing the project code in a loop is the simplest version of this function:
It quickly becomes apparent that the SQL cursor uses up too many resources. In short, this happens because cursors operate at row level and go through every row to make an operation.
More information on why cursors in SQL are inefficient and it is best to avoid them can be found here: https://stackoverflow.com/questions/4568464/sql-server-temporary-tables-vs-cursors (answer 2)
To increase the performance, I will use temporary tables and remove the cursor. Here is the resulting function:
This now takes about 3 seconds per project to select the project code and the data from the large mapping table, filtered by that project.
For demonstration purposes, I will only focus on 2 projects, however I will return to running the function on all projects when doing so on production.
The final function we will be working with looks like this:
Mapping Table Preparation
The next step is to prepare the data for the Python pre-processing and mapping functions, for this we will need 2 datasets:
- The filtered data by project code from the large mapping table
- The filtered data by project code from the small companies table
Here is what the updated function looks like with the data from 2 tables being selected:
Important: pythonic functions in SQL only take in 1 table input. Make sure to put your data into a single wide table before feeding it into a Python function in SQL.
As a result of this function, we get the projects, the company names and the sources for each project.
Now we are ready for Python!
Python Execution in SQL
Python in SQL Server, through sp_execute_external_script, allows you to run Python code directly within SQL Server.
It enables integration of Python’s capabilities into SQL workflows with data exchange between SQL and Python. In the provided example, a Python script is executed, creating a pandas DataFrame from input data.
The result is returned as a single output.
How cool is that!
There are a few important things to note about running Python in SQL:
- Strings are defined by double quotes (“), not single quotes (‘). Make sure to check this especially if you are using regex expressions, to avoid spending time on error tracing
- There is only 1 output permitted — so your Python code will result in 1 table on output
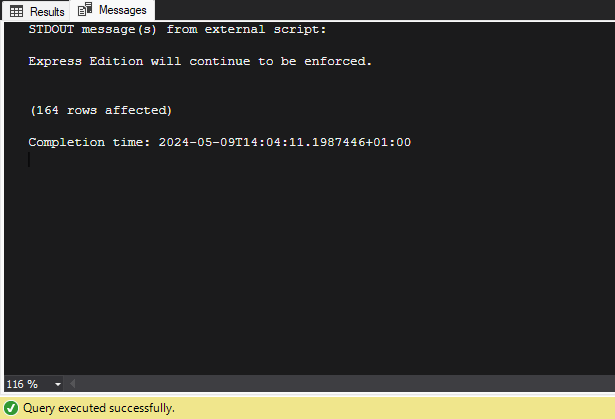
- You can use print statements for debugging and see the results be printed to the ‘Messages’ tab within your SQL server. Like so:
Python Libraries In SQL
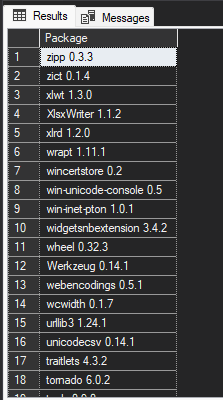
In SQL Server, several libraries come pre-installed and are readily accessible. To view the complete list of these libraries, you can execute the following command:
Here is what the output will look like:
Matching Text With Python
Coming back to our generated table, we can now match the company names from different sources using Python. Our Python procedure will take in the long table and output a table with the mapped entities. It should show the match it thinks is most likely from the large mapping table next to each record from the small company table.
To do this, let’s first add a Python function to our SQL procedure. The first step is to simply feed in the dataset into Python, I will do this with a sample dataset and then with our data, here is the code:
This system allows us to feed in both of our tables into the pythonic function as inputs, it then prints both tables as outputs.
Pre-Processing In Python
In order to match our strings effectively, we must conduct some preprocessing in Python, this includes:
- Remove accents and other language-specific special characters
- Remove the white spaces
- Remove punctuation
The first step will be done with collation in SQL, while the other 2 will be present in the preprocessing step of the Python function.
Here is what our function with preprocessing looks like:
The result of this is 3 columns, one with the name of the company in small, lower cap and no space letters, the second column is the project column and the third column is the source.
Matching Strings In Python
Here we have to be creative as we are pretty limited with the number of libraries which we can use. Therefore, let’s first identify how we would want our output to look.
We want to match the data coming from source 2, to the data in source 1. Therefore, for each value in source 2, we should have a bunch of matching values from source 1 with scores to represent the closeness of the match.
We will use python built-in libraries first, to avoid the need for library imports and hence simplify the job.
The logic:
- Loop through each project
- Make a table with the funds by source, where source 1 is the large table with the mapping data and 2 is the initial company dataset
- Select the data from the small dataset into an array
- Compare each element in the resulting array to each element in the large mapping data frame
- Return the scores for each entity
The code:
And here is the final output:
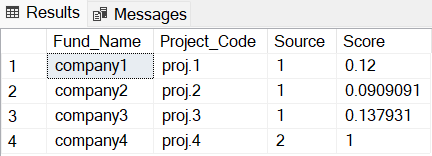
In this table, we have each company name, the project which it belongs to and the source — whether it is from the large mapping table or the small companies table. The score on the right indicates the similarity metric between the company name from source 2 and source 1. It is important to note that company4, which came from source 2, will always have a score of 1–100% match, as it is being matched against itself.
Executing Python scripts within SQL Server via the Machine Learning Services is a powerful feature that allows for in-database analytics and machine learning tasks. This integration enables direct data access without the need for data movement, significantly optimizing performance and security for data-intensive operations.
However, there are limitations to be aware of. The environment supports a single input, which might restrict the complexity of tasks that can be performed directly within the SQL context. Additionally, only a limited set of Python libraries are available, which may require alternative solutions for certain types of data analysis or machine learning tasks not supported by the default libraries. Furthermore, users must navigate the intricacies of SQL Server’s environment, such as complex spacing in T-SQL queries that include Python code, which can be a source of errors and confusion.
Despite these challenges, there are numerous applications where executing Python in SQL Server is advantageous:
1. Data Cleansing and Transformation — Python can be used directly in SQL Server to perform complex data preprocessing tasks, like handling missing data or normalizing values, before further analysis or reporting.
2. Predictive Analytics — Deploying Python machine learning models directly within SQL Server allows for real-time predictions, such as customer churn or sales forecasting, using live database data.
3. Advanced Analytics — Python’s capabilities can be leveraged to perform sophisticated statistical analysis and data mining directly on the database, aiding in decision-making processes without the latency of data transfer.
4. Automated Reporting and Visualization — Python scripts can generate data visualizations and reports directly from SQL Server data, enabling automated updates and dashboards.
5. Operationalizing Machine Learning Models — By integrating Python in SQL Server, models can be updated and managed directly within the database environment, simplifying the operational workflow.
In conclusion, while the execution of Python in SQL Server presents some challenges, it also opens up a wealth of possibilities for enhancing and simplifying data processing, analysis, and predictive modeling directly within the database environment.
PS to see more of my articles, you can follow me on LinkedIn here: https://www.linkedin.com/in/sasha-korovkina-5b992019b/
SQL Server’s Secret Feature — Run Python and Add-Ons Natively In SQL Server. was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
SQL Server’s Secret Feature — Run Python and Add-Ons Natively In SQL Server.