Solving the Classic Betting on the World Series Problem Using Hill Climbing
A simple example of hill climbing — and solving a problem that’s difficult to solve without optimization techniques
Betting on the World Series is an old, interesting, and challenging puzzle. It’s also a nice problem to demonstrate an optimization technique called hill climbing, which I’ll cover in this article.
Hill climbing is a well-established, and relatively straightforward optimization technique. There are many other examples online using it, but I thought this problem allowed for an interesting application of the technique and is worth looking at.
One place the puzzle can be seen in on a page hosted by UC Davis. To save you looking it up, I’ll repeat it here:
[E. Berlekamp] Betting on the World Series. You are a broker; your job is to accommodate your client’s wishes without placing any of your personal capital at risk. Your client wishes to place an even $1,000 bet on the outcome of the World Series, which is a baseball contest decided in favor of whichever of two teams first wins 4 games. That is, the client deposits his $1,000 with you in advance of the series. At the end of the series he must receive from you either $2,000 if his team wins, or nothing if his team loses. No market exists for bets on the entire world series. However, you can place even bets, in any amount, on each game individually. What is your strategy for placing bets on the individual games in order to achieve the cumulative result demanded by your client?
So, it’s necessary to bet on the games one at a time (though also possible to abstain from betting on some games, simply betting $0 on those). After each game, we’ll either gain or lose exactly what we bet on that game. We start with the $1000 provided by our client. Where our team wins the full series, we want to end with $2000; where they lose, we want to end with $0.
If you’ve not seen this problem before and wish to try to solve it manually, now’s your chance before we go into a description of solving this programmatically. It is a nice problem in itself, and can be worthwhile looking at solving it directly before proceeding with a hill-climbing solution.
Approaching the problem
For this problem, I’m going to assume it’s okay to temporarily go negative. That is, if we’re ever, during the world series, below zero dollars, this is okay (we’re a larger brokerage and can ride this out), so long as we can reliably end with either $0 or $2000. We then return to the client the $0 or $2000.
It’s relatively simple to come up with solutions for this that work most of the time, but not necessarily for every scenario. In fact, I’ve seen a few descriptions of this puzzle online that provide some sketches of a solution, but appear to not be completely tested for every possible sequence of wins and losses.
An example of a policy to bet on the (at most) seven games may be to bet: $125, $250, $500, $125, $250, $500, $1000. In this policy, we bet $125 on the first game, $250 on the second game, and so on, up to as many games as are played. If the series lasts five games, for example, we bet: $125, $250, $500, $125, $250. This policy will work, actually, in most cases, though not all.
Consider the following sequence: 1111, where 0 indicates Team 0 wins a single game and 1 indicates Team 1 wins a single game. In this sequence, Team 1 wins all four games, so wins the series. Let’s say, our team is Team 1, so we need to end with $2000.
Looking at the games, bets, and dollars held after each game, we have:
Game Bet Outcome Money Held
---- --- ---- ----------
Start - - 1000
1 125 1 1125
2 250 1 1375
3 500 1 1875
4 125 1 2000
That is, we start with $1000. We bet $125 on the first game. Team 1 wins that game, so we win $125, and now have $1125. We then bet $250 on the second game. Team 1 wins this, so we win $250 and now have $1375. And so on for the next two games, betting $500 and $125 on these. Here, we correctly end with $2000.
Testing the sequence 0000 (where Team 0 wins in four games):
Game Bet Outcome Money Held
---- --- ---- ----------
Start - - 1000
1 125 0 875
2 250 0 625
3 500 0 125
4 125 0 0
Here we correctly (given Team 0 wins the series) end with $0.
Testing the sequence 0101011 (where Team 1 wins in seven games):
Game Bet Outcome Money Held
---- --- ---- ----------
Start - - 1000
1 125 0 875
2 250 1 1125
3 500 0 625
4 125 1 750
5 250 0 500
6 500 1 1000
7 1000 1 2000
Here we again correctly end with $2000.
However, with the sequence 1001101, this policy does not work:
Game Bet Outcome Money Held
---- --- ---- ----------
Start - - 1000
1 125 1 1125
2 250 0 875
3 500 0 375
4 125 1 500
5 250 1 750
6 500 0 250
7 1000 1 1250
Here, though Team 1 wins the series (with 4 wins in 7 games), we end with only $1250, not $2000.
Testing a given policy
Since there are many possible sequences of games, this is difficult to test manually (and pretty tedious when you’re testing many possible polices), so we’ll next develop a function to test if a given policy works properly: if it correctly ends with at least $2000 for all possible series where Team 1 wins the series, and at least $0 for all possible series where Team 0 wins the series.
This takes a policy in the form of an array of seven numbers, indicating how much to bet on each of the seven games. In series with only four, five, or six games, the values in the last cells of the policy are simply not used. The above policy can be represented as [125, 250, 500, 125, 250, 500, 1000].
def evaluate_policy(policy, verbose=False):
if verbose: print(policy)
total_violations = 0
for i in range(int(math.pow(2, 7))):
s = str(bin(i))[2:]
s = '0'*(7-len(s)) + s # Pad the string to ensure it covers 7 games
if verbose:
print()
print(s)
money = 1000
number_won = 0
number_lost = 0
winner = None
for j in range(7):
current_bet = policy[j]
# Update the money
if s[j] == '0':
number_lost += 1
money -= current_bet
else:
number_won += 1
money += current_bet
if verbose: print(f"Winner: {s[j]}, bet: {current_bet}, now have: {money}")
# End the series if either team has won 4 games
if number_won == 4:
winner = 1
break
if number_lost == 4:
winner = 0
break
if verbose: print("winner:", winner)
if (winner == 0) and (money < 0):
total_violations += (0 - money)
if (winner == 1) and (money < 2000):
total_violations += (2000 - money)
return total_violations
This starts by creating a string representation of each possible sequence of wins and losses. This creates a set of 2⁷ (128) strings, starting with ‘0000000’, then ‘0000001’, and so on, to ‘1111111’. Some of these are redundant, since some series will end before all seven games are played — once one team has won four games. In production, we’d likely clean this up to reduce execution time, but for simplicity, we simply loop through all 2⁷ combinations. This does have some benefit later, as it treats all 2⁷ (equally likely) combinations equally.
For each of these possible sequences, we apply the policy to determine the bet for each game in the sequence, and keep a running count of the money held. That is, we loop through all 2⁷ possible sequences of wins and losses (quitting once one team has won four games), and for each of these sequences, we loop through the individual games in the sequence, betting on each of the games one at a time.
In the end, if Team 0 won the series, we ideally have $0; and if Team 1 won the series, we ideally have $2000, though there is no penalty (or benefit) if we have more.
If we do not end a sequence of games with the correct amount of money, we determine how many dollars we’re short; that’s the cost of that sequence of games. We sum these shortages up over all possible sequences of games, which gives us an evaluation of how well the policy works overall.
To determine if any given policy works properly or not, we can simply call this method with the given policy (in the form of an array) and check if it returns 0 or not. Anything higher indicates that there’s one or more sequences where the broker ends with too little money.
Hill Climbing
I won’t go into too much detail about hill climbing, as it’s fairly well-understood, and well documented many places, but will describe the basic idea very quickly. Hill climbing is an optimization technique. We typically start by generating a candidate solution to a problem, then modify this in small steps, with each step getting to better and better solutions, until we eventually reach the optimal point (or get stuck in a local optima).
To solve this problem, we can start with any possible policy. For example, we can start with: [-1000, -1000, -1000, -1000, -1000, -1000, -1000]. This particular policy is certain to work poorly — we’d actually bet heavily against Team 1 all seven games. But, this is okay. Hill climbing works by starting anywhere and then progressively moving towards better solutions, so even starting with a poor solution, we’ll ideally eventually reach a strong solution. Though, in some cases, we may not, and it’s sometimes necessary (or at least useful) to re-run hill climbing algorithms from different starting points. In this case, starting with a very poor initial policy works fine.
Playing with this puzzle manually before coding it, we may conclude that a policy needs to be a bit more complex than a single array of seven values. That form of policy determines the size of each bet entirely based on which game it is, ignoring the numbers of wins and losses so far. What we need to represent the policy is actually a 2d array, such as:
[[-1000, -1000, -1000, -1000, -1000, -1000, -1000],
[-1000, -1000, -1000, -1000, -1000, -1000, -1000],
[-1000, -1000, -1000, -1000, -1000, -1000, -1000],
[-1000, -1000, -1000, -1000, -1000, -1000, -1000]]
There are other ways to do this, but, as we’ll show below, this method works quite well.
Here, the rows represent the number of wins so far for Team 1: either 0, 1, 2, or 3. The columns, as before, indicate the current game number: either 1, 2, 3, 4, 5, 6, or 7.
Again, with the policy shown, we would bet $1000 against Team 1 every game no matter what, so almost any random policy is bound to be at least slightly better.
This policy has 4×7, or 28, values. Though, some are unnecessary and this could be optimized somewhat. I’ve opted for simplicity over efficiency here, but generally we’d optimize this a bit more in a production environment. In this case, we can remove some impossible cases, like having 0 wins by games 5, 6, or 7 (with no wins for Team 1 by game 5, Team 0 must have 4 wins, thus ending the series). Twelve of the 28 cells are effectively unreachable, with the remaining 16 relevant.
For simplicity, it’s not used in this example, but the fields that are actually relevant are the following, where I’ve placed a -1000:
[[-1000, -1000, -1000, -1000, n/a, n/a, n/a ],
[ n/a, -1000, -1000, -1000, -1000, n/a, n/a ],
[ n/a, n/a, -1000, -1000, -1000, -1000, n/a ],
[ n/a, n/a, n/a, -1000, -1000, -1000, -1000]]
The cells marked ‘n/a’ are not relevant. For example, on the first game, it’s impossible to have already had 1, 2, or 3 wins; only 0 wins is possible at that point. On the other hand, by game 4, it is possible to have 0, 1, 2, or 3 previous wins.
Also playing with this manually before coding anything, it’s possible to see that each bet is likely a multiple of either halves of $1000, quarters of $1000, eights, sixteenths, and so on. Though, this is not necessarily the optimal solution, I’m going to assume that all bets are multiples of $500, $250, $125, $62.50, or $31.25, and that they may be $0.
I will, though, assume that there is never a case to bet against Team 1; while the initial policy starts out with negative bets, the process to generate new candidate policies uses only bets between $0 and $1000, inclusive.
There are, then, 33 possible values for each bet (each multiple of $31.25 from $0 to $1000). Given the full 28 cells, and assuming bets are multiples of 31.25, there are 33²⁸ possible combinations for the policy. So, testing them all is infeasible. Limiting this to the 16 used cells, there are still 33¹⁶ possible combinations. There may be further optimizations possible, but there would, nevertheless, be an extremely large number of combinations to check exhaustively, far more than would be feasible. That is, directly solving this problem may be possible programmatically, but a brute-force approach, using only the assumptions stated here, would be intractable.
So, an optimization technique such as hill climbing can be quite appropriate here. By starting at a random location on the solution landscape (a random policy, in the form of a 4×7 matrix), and constantly (metaphorically) moving uphill (each step we move to a solution that’s better, even if only slightly, than the previous), we eventually reach the highest point, in this case a workable policy for the World Series Betting Problem.
Update to the Evaluation Method
Given that the policies will be represented as 2d matrices and not 1d arrays, the code above to determine the current bet will changed from:
current_bet = policy[j]
to:
current_bet = policy[number_won][j]
That is, we determine the current bet based on both the number of games won so far and the number of the current game. Otherwise, the evaluate_policy() method is as above. The code above to evaluate a policy is actually the bulk of the code.
Code to find a solution
We next show the main code, which starts with a random policy, and then loops (up to 10,000 times), each time modifying and (hopefully) improving this policy. Each iteration of the loop, it generates 10 random variations of the current-best solution, takes the best of these as the new current solution (or keeps the current solution if none are better, and simply keeps looping until we do have a better solution).
import numpy as np
import math
import copy
policy = [[-1000, -1000, -1000, -1000, -1000, -1000, -1000],
[-1000, -1000, -1000, -1000, -1000, -1000, -1000],
[-1000, -1000, -1000, -1000, -1000, -1000, -1000],
[-1000, -1000, -1000, -1000, -1000, -1000, -1000]]
best_policy = copy.deepcopy(policy)
best_policy_score = evaluate_policy(policy)
print("starting score:", best_policy_score)
for i in range(10_000):
if i % 100 == 0: print(i)
# Each iteration, generate 10 candidate solutions similar to the
# current best solution and take the best of these (if any are better
# than the current best).
for j in range(10):
policy_candidate = vary_policy(policy)
policy_score = evaluate_policy(policy_candidate)
if policy_score <= best_policy_score:
best_policy_score = policy_score
best_policy = policy_candidate
policy = copy.deepcopy(best_policy)
print(best_policy_score)
display(policy)
if best_policy_score == 0:
print(f"Breaking after {i} iterations")
break
print()
print("FINAL")
print(best_policy_score)
display(policy)
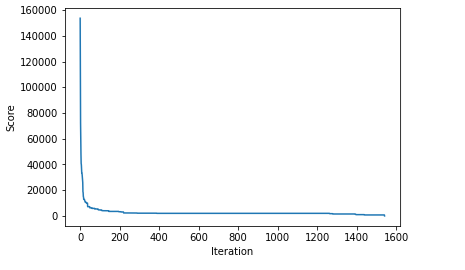
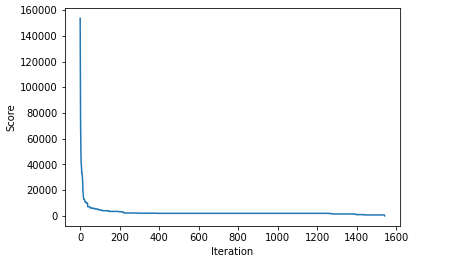
Running this, the main loop executed 1,541 times before finding a solution. Each iteration, it calls vary_policy() (described below) ten times to generate ten variations of the current policy. It then calls evaluate_policy() to evaluate each. This was defined above, and provides a score (in dollars), of how short the broker can come up using this policy in an average set of 128 instances of the world series (we can divide this by 128 to get the expected loss for any single world series). The lower the score, the better.
The initial solution had a score of 153,656.25, so quite poor, as expected. It rapidly improves from there, quickly dropping to around 100,000, then 70,000, then 50,000, and so on. Printing the best policies found to date as the code executes also presents increasingly more sensible policies.
Method to Generate Random Variations
The following code generates a single variation on the current policy:
def vary_policy(policy):
new_policy = copy.deepcopy(policy)
num_change = np.random.randint(1, 10)
for _ in range(num_change):
win_num = np.random.choice(4)
game_num = np.random.choice(7)
new_val = np.random.choice([x*31.25 for x in range(33)])
new_policy[win_num][game_num] = new_val
return new_policy
Here we first select the number of cells in the 4×7 policy to change, between 1 and 10. It’s possible to modify fewer cells, and this can improve performance when the scores are getting close to zero. That is, once we have a strong policy, we likely wish to change it less than we would near the beginning of the process, where the solutions tend to be weak and there is more emphasis on exploring the search space.
However, consistently modifying a small, fixed number of cells does allow getting stuck in local optima (sometimes there is no modification to a policy that modifies exactly, say, 1 or 2 cells that will work better, and it’s necessary to change more cells to see an improvement), and doesn’t always work well. Randomly selecting a number of cells to modify avoids this. Though, setting the maximum number here to ten is just for demonstration, and is not the result of any tuning.
If we were to limit ourselves to the 16 relevant cells of the 4×7 matrix for changes, this code would need only minor changes, simply skipping updates to those cells, and marking them with a special symbol (equivalent to ‘n/a’, such as np.NaN) for clarity when displaying the matrices.
Results
In the end, the algorithm was able to find the following policy. That is, in the first game, we will have no wins, so will bet $312.50. In the second game, we will have either zero or one win, but in either case will be $312.50. In the third game, we will have either zero, one, or two wins, so will bet $250, $375, or $250, and so on, up to, at most, seven games. If we reach game 7, we must have 3 wins, and will bet $1000 on that game.
[[312.5, 312.5, 250.0, 125.0, 718.75, 31.25, 281.25],
[375.0, 312.5, 375.0, 375.0, 250.0, 312.5, 343.75],
[437.5, 156.25, 250.0, 375.0, 500.0, 500.0, 781.25],
[750.0, 718.75, 343.75, 125.0, 250.0, 500.0, 1000.0]]
I’ve also created a plot of how the scores for the best policy found so far drops (that is, improves — smaller is better) over the 1,541 iterations:
This is a bit hard to see since the score is initially quite large, so we plot this again, skipping first 15 steps:
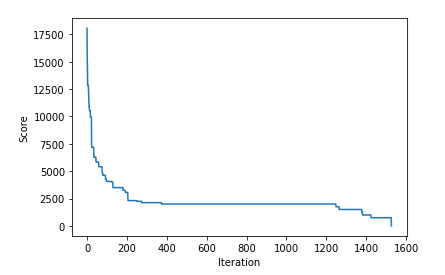
We can see the score initially continuing to drop quickly, even after the first 15 steps, then going into a long period of little improvement until it eventually finds a small modification to the current policy that improves it, followed by more drops until we eventually reach a perfect score of 0 (being $0 short for any possible sequence of wins & losses).
Similar types of problems
The problem we worked on here is an example of what is known as a constraints satisfaction problem, where we simply wish to find a solution that covers all the given constraints (in this case, we take the constraints as hard constraints — it’s necessary to end correctly with either $0 or $2000 for any possible valid sequence of games).
Given two or more full solutions to the problem, there is no sense of one being better than the other; any that works is good, and we can stop once we have a workable policy. The N Queens problem and Sudoku, are two other examples of problems of this type.
Other types of problems may have a sense of optimality. For example, with the Travelling Salesperson Problem, any solution that visits every city exactly once is a valid solution, but each solution has a different score, and some are strictly better than others. In that type of problem, it’s never clear when we’ve reached the best possible solution, and we usually simply try for a fixed number of iterations (or amount of time), or until we’ve reached a solution with at least some minimal level of quality. Hill climbing can also be used with these types of problems.
It’s also possible to formulate a problem where it’s necessary to find, not just one, but all workable solutions. In the case of the Betting on World Series problem, it was simple to find a single workable solution, but finding all solutions would be much harder, requiring an exhaustive search (though optimized to quickly remove cases that are equivalent, or to quit evaluation early where policies have a clear outcome).
Similarly, we could re-formulate Betting on World Series problem to simply require a good, but not perfect, solution. For example, we could accept solutions where the broker comes out even most of the time, and only slightly behind in other cases. In that case, hill climbing can still be used, but something like a random search or grid search are also possible — taking the best policy found after a fixed number of trials, may work sufficiently in that case.
In problems harder than the Betting on World Series problem, simple hill climbing as we’ve used here may not be sufficient. It may be necessary, for example, to maintain a memory of previous policies, or to include a process called simulated annealing (where we take, on occasion, a sub-optimal next step — a step that may actually have lower quality than the current solution — in order to help break away from local optima).
For more complex problems, it may be better to use Bayesian Optimization, Evolutionary Algorithms, Particle Swarm Intelligence, or other more advanced methods. I’ll hopefully cover these in future articles, but this was a relatively simple problem, and straight-forward hill climbing worked quite well (though as indicated, can easily be optimized to work better).
Conclusions
This article provided a simple example of hill climbing. The problem was relatively straight-forward, so hopefully easy enough to go through for anyone not previously familiar with hill climbing, or as a nice example even where you are familiar with the technique.
What’s interesting, I think, is that despite this problem being solvable otherwise, optimization techniques such as used here are likely the simplest and most effective means to approach this. While tricky to solve otherwise, this problem was quite simple to solve using hill climbing.
All images by author
Solving the classic Betting on the World Series problem using hill climbing was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Solving the classic Betting on the World Series problem using hill climbing