
Alibaba’s EMO and Microsoft’s VASA-1 are crazy good. Let’s break down how they work.
It’s no secret that the pace of AI research is exponentially accelerating. One of the biggest trends of the past couple of years has been using transformers to exploit huge-scale datasets. It looks like this trend has finally reached the field of lip-sync models. The EMO release by Alibaba set the precedent for this (I mean look at the 200+ GitHub issues begging for code release). But the bar has been raised even higher with Microsoft’s VASA-1 last month.
They’ve received a lot of hype, but so far no one has discussed what they’re doing. They look like almost identical works on the face of it (pun intended). Both take a single image and animate it using audio. Both use diffusion and both exploit scale to produce phenomenal results. But in actuality, there are a few differences under the hood. This article will take a sneak peek at how these models operate. We also take a look at the ethical considerations of these papers, given their obvious potential for misuse.
The Data
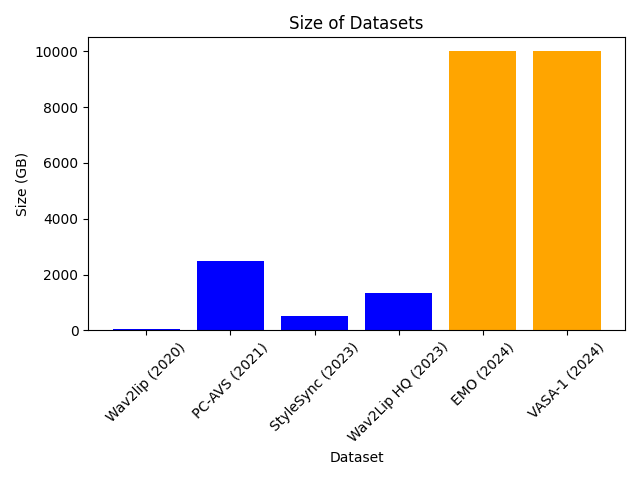
A model can only be as good as the data it is trained on. Or, more succinctly, Garbage In = Garbage Out. Most existing lip sync papers make use of one or two, reasonably small datasets. The two papers we are discussing absolutely blow away the competition in this regard. Let’s break down what they use. Alibaba state in EMO:
We collected approximately 250 hours of talking head videos from the internet and supplemented this with the HDTF [34] and VFHQ [31] datasets to train our models.
Exactly what they mean by the additional 250 hours of collected data is unknown. However, HDTF and VFHQ are publicly available datasets, so we can break these down. HDTF consists of 16 hours of data over 300 subjects of 720–1080p video. VFHQ doesn’t mention the length of the dataset in terms of hours, but it has 15,000 clips and takes up 1.2TB of data. If we assume each clip is, on average, at least 10s long then this would be an additional 40 hours. This means EMO uses at least 300 hours of data. For VASA-1 Microsoft say:
The model is trained on VoxCeleb2 [13] and another high-resolution talk video dataset collected by us, which contains about 3.5K subjects.
Again, the authors are being secretive about a large part of the dataset. VoxCeleb2 is publicly available. Looking at the accompanying paper we can see this consists of 2442 hours of data (that’s not a typo) across 6000 subjects albeit in a lower resolution than the other datasets we mentioned (360–720p). This would be ~2TB. Microsoft uses a dataset of 3.5k additional subjects, which I suspect are far higher quality and allow the model to produce high-quality video. If we assume this is at least 1080p and some of it is 4k, with similar durations to VoxCeleb2 then we can expect another 5–10TB.
For the following, I am making some educated guesses: Alibaba likely uses 300 hours of high-quality video (1080p or higher), while Microsoft uses ~2500 hours of low-quality video, and maybe somewhere between 100–1000 hours of very high-quality video. If we try to estimate the dataset size in terms of storage space we find that EMO and VASA-1 each use ~10TB of face video data to train their model. For some comparisons check out the following chart:
The Models
Both models make use of diffusion and transformers to utilise the massive datasets. However, there are some key differences in how they work.
VASA-1
We can break down VASA-1 into two components. One is an image formation model that takes some latent representation of the facial expression and pose and produces a video frame. The other is a model that generates these latent pose and expression vectors from audio input. The image formation model
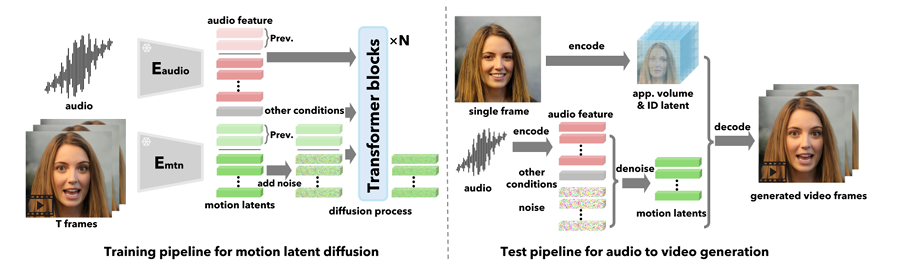
Image Formation Model
VASA-1 relies heavily on a 3D volumetric representation of the face, building upon previous work from Samsung called MegaPortraits. The idea here is to first estimate a 3D representation of a source face, warp it using the predicted source pose, make edits to the expression using knowledge of both the source and target expressions in this canonical space, and then warp it back using a target pose.
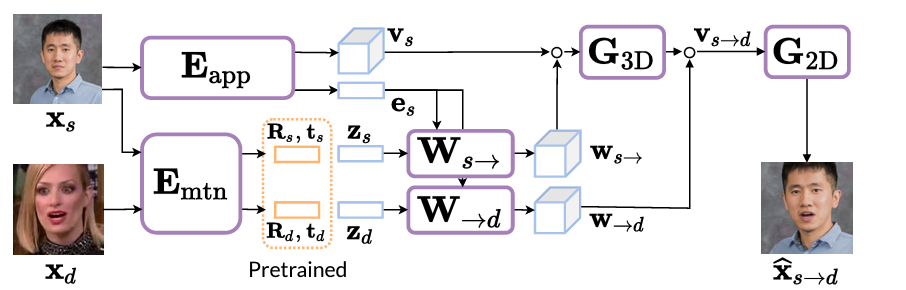
In more detail, this process looks as follows:
- Take the source image (the man in the diagram above) and predict a simple 1D vector which represents this man.
- Also predict a 4D tensor (Width, Height, Depth, RGB) as a volumetric representation of him.
- Predict for both the source and driver (the woman above) their pose and facial expression. Note that only the pose estimation is pre-trained, all the others are trained completely from scratch.
- Create two warping fields using neural networks. One converts the man’s volumetric representation into a canonical space (this just means a front-facing, neutral expression) using our estimate of his identity, pose and facial expression. The other converts his canonical 3D face into a posed 3D face using estimates of the woman’s pose and expression, as well as the man’s identity.
- “Render” the posed man’s face back into 2D.
For details on how exactly they do this, that is how do you project into 3D, how is the warping achieved and how is the 2D image created from the 3D volume, please refer to the MegaPortraits paper.
This highly complex process can be simplified in our minds at this point to just imagine a model that encodes the source in some way and then takes parameters for pose and expression, creating an image based on these.
Audio-to-latent Generation
We now have a way to generate video from a sequence of expressions and pose latent codes. However, unlike MegaPortraits, we don’t want to control our videos using another person’s expressions. Instead, we want control from audio alone. To do this, we need to build a generative model that takes audio as input and outputs latent vectors. This needs to scale up to huge amounts of data, have lip-sync and also produce diverse and plausible head motions. Enter the diffusion transformer. Not familiar with these models? I don’t blame you, there are a lot of advances here to keep up with. I can recommend the following article:
Diffusion Transformer Explained
But in a nutshell, diffusion transformers (DiTs) replace the conventional UNET in image-based diffusion models with a transformer. This switch enables learning on data with any structure, thanks to tokenization, and it is also known to scale extremely well to large datasets. For example, OpenAI’s SORA model is believed to be a diffusion transformer.
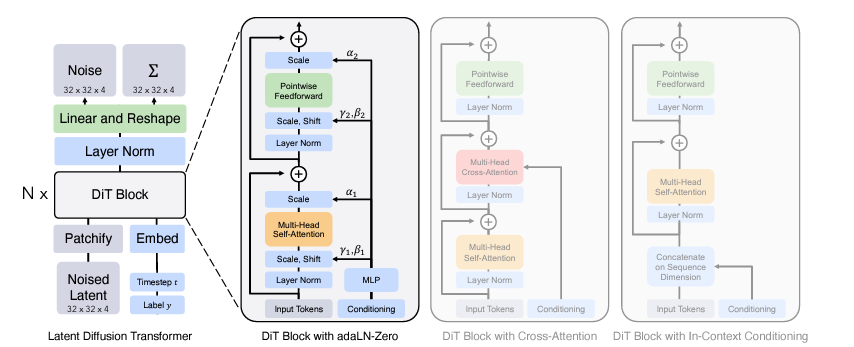
The idea then is to start from random noise in the same shape as the latent vectors and gradually denoise them to produce meaningful vectors. This process can then be conditioned on additional signals. For our purposes, this includes audio, extracted into feature vectors using Wav2Vec2 (see FaceFormer for how exactly this works). Additional signals are also used. We won’t go into too much detail but they include eye gaze direction and emotion. To ensure temporal stability, the previously generated motion latent codes are also used as conditioning.
EMO

EMO takes a slightly different approach with its generation process, though it still relies on diffusion at its core. The model diagram looks a bit crowded, so I think its best to break it into smaller parts.
Using Stable Diffusion
The first thing to notice is that EMO makes heavy use of the pretrained Stable Diffusion 1.5 model. There is a solid trend in vision at large currently towards building on top of this model. In the above diagram, the reference net and the backbone network are both instances of the SD1.5 UNET archietecture and are initialised with these weights. The detail is lacking, but presumably the VAE encoder and decoder are also taken from Stable Diffusion. The VAE components are frozen, meaning that all of the operations performed in the EMO model are done in the latent space of that VAE. The use of the same archieture and same starting weights is useful because it allows activations from intermediate layers to be easily taken from one network and used in another (they will roughly represent the same thing in both network).
Training the First Stage
The goal of the first stage is to get a single image model that can generate a novel image of a person, given a reference frame of that person. This is achieved using a diffusion model. A basic diffusion model could be used to generate random images of people. In stage one, we want to, in some way, condition this generation process on identity. The way the authors do this is by encoding a reference image of a person using the reference net, and introducing the activations in each layer into the backbone network which is doing the diffusion. See the (poorly drawn) diagram below.
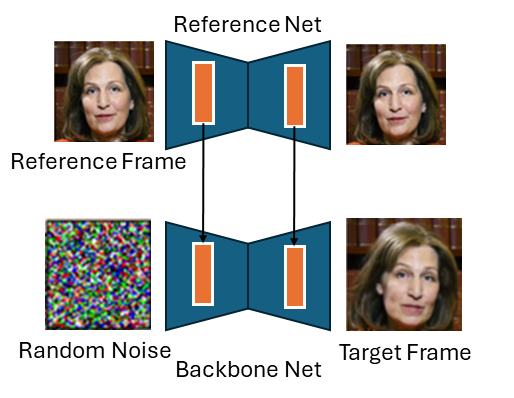
At this stage, we now have a model that can generate random frames of a person, given a single image of that person. We now need to control it in some way.
Training the Second Stage
We want to control the generated frames using two signals, motion and audio. The audio part is the easier to explain, so I’ll cover this first.
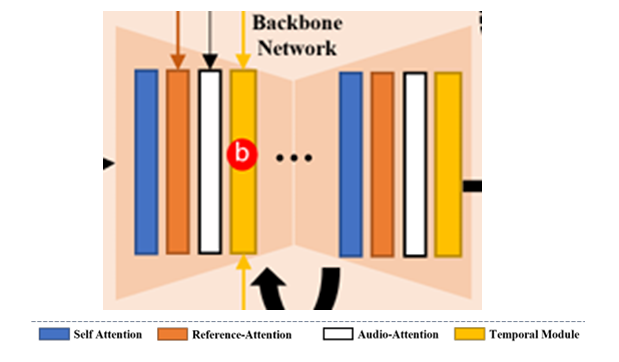
- Audio: As with VASA-1, audio is encoded in the form of wav2vec2 features. These are incorporated into the backbone network using cross attention. This cross attention replaces the text prompt cross attention already present in the Stable Diffusion 1.5 model.
- Motion: Motion is added using motion frames, to predict the frame at time t, the previous n frames are used to provide context for the motion. The motion frames are encoded in the same way as the reference frame. The intermediate feature activations of the reference net are used to condition the backbone model. The inclusion of these motion referenece activations is done using a specially designed cross-attention layer, taken from AnimateDiff. From these n frames, the next f are predicted using the diffusion model.
In addition to this, two other components are used. One provides a mask, taken as the union of all bounding boxes across the training video. This mask defines what region of the video is allowed to be changed. The other is a small addition of a speed condition is used. The pose velocity is divided into buckets (think slow, medium, fast) and also included. This allows us to specify the speed of the motion at inference time.
Inference
The model is now able to take the following and produces a new set of frames:
- A reference frame
- The previous n frames
- The audio
- The head motion speed
- A bounding box of pixels that can be changed
For the first frame, it is not stated, but I assume the reference frame is repeated and passed as the last n frames. After this point, the model is autoregressive, the outputs are then used as the previous frames for input.
Ethics Discussion
The ethical implications of these works are, of course, very significant. They require only a single image in order to create very realistic synthetic content. This could easily be used to misrepresent people. Given the recent controversy surrounding OpenAI’s use of a voice that sounds suspiciously like Scarlett Johansen without her consent, the issue is particularly relevant at the moment. The two groups take rather different approaches.
EMO
The discussion in the EMO paper is very much lacking. The paper does not include any discussion of the ethical implications or any proposed methods of preventing misuse. The project page says only:
“This project is intended solely for academic research and effect demonstration”
This seems like a very weak attempt. Furthermore, Alibaba include a GitHub repo which (may) make the code publicly available. It’s important to consider the pros and cons of doing this, as we discuss in a previous article. Overall, the EMO authors have not shown too much consideration for ethics.
VASA-1
VASA-1’s authors take a more comprehensive approach to preventing misuse. They include a section in the paper dedicated to this, highlighting the potential uses in deepfake detection as well as the positive benefits.

In addition to this, they also include a rather interesting statement:
Note: all portrait images on this page are virtual, non-existing identities generated by StyleGAN2 or DALL·E-3 (except for Mona Lisa). We are exploring visual affective skill generation for virtual, interactive characters, NOT impersonating any person in the real world. This is only a research demonstration and there’s no product or API release plan.
The approach is actually one Microsoft have started to take in a few papers. They only create synthetic videos using synthetic people and do not release any of their models. Doing so prevents any possible misuse, as no real people are edited. However, it does raise issues around the fact that the power to create such videos in concentrated into the arms of big-tech companies that have the infrastructure to train such models.
Further Analysis
In my opinion this line of work opens up a new set of ethical issues. While it had been previously possible to create fake videos of people, it usually required several minutes of data to train a model. This largely restricted the potential victims to people who create lots of video already. While this allowed for the creation of political misinformation, the limitations helped to stifle some other applications. For one, if someone creates a lot of video, it is possible to tell what their usual content looks like (what do they usually talk about, what their opinions are, etc.) and can learn to spot videos that are uncharacteristic. This becomes more difficult if a single image can be used. What’s more, anyone can become a victim of these models. Even a social media account with a profile picture would be enough data to build a model of a person.
Furthermore, as a different class of “deepfake” there is not much research on how to detect these models. Methods that may have worked to catch video deepfake models would become unreliable.
We need to ensure that the harm caused by these models is limited. Microsoft’s approach of limiting access and only using synthetic people helps for the short term. But long term we need robust regulation of the applications of these models, as well as reliable methods to detect content generated by them.
Conclusion
Both VASA-1 and EMO are incredible papers. They both exploit diffusion models and large-scale datasets to produce extremely high quality video from audio and a single image. A few key points stand out to me:
- It’s not quite a case of scale is all you need. Both models use clever tricks (VASA-1’s use of MegaPortiats and EMO’s reference & backbone nets). However, it does seem to be the case that “scale is something you need”.
- Diffusion is king. Both of these models, as well as most state-of-the-art generation in vision, use diffusion. It seems that VAE’s and GAN’s are almost truly dead.
- The field of lip-sync models is likely to become the domain of the big companies only soon. If trends continue, there is no way academics will be able to build models that keep up with these.
Scale Is All You Need for Lip-Sync? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Scale Is All You Need for Lip-Sync?
Go Here to Read this Fast! Scale Is All You Need for Lip-Sync?