Comparing the AWS and GCP fully-managed services for ML workflows
If you’re in that exciting stage of product development where you’re looking to deploy your first AI models to production, then take a moment to enjoy this clean slate. The decisions you’re about to make might influence the future of your company, or at least its technical debt going forward. No pressure 🙂 Or at least that’s what I tell myself, now that I am starting to lay down the technical foundations of our company.
At Storia, we build and deploy a lot of AI models, so efficient model serving is top of mind. We did a deep dive into two of the most prominent services, SageMaker and Vertex AI, and are sharing our takeaways here. We liked SageMaker better for our use case. While we tried to stay impartial for the sake of making the best decision for our company, who knows what sort of biases are creeping in. I spent many years at Google, my cofounder at Amazon. Both are offering us free credits through their startup programs and Amazon welcomed us into their generative AI accelerator last year.
TL;DR: SageMaker wins overall. If you’re starting from scratch and have no affinity for one cloud provider over another (because of free credits, existing lock-in, or strong familiarity with their tooling), just go for SageMaker. However, if GCP already has you enthralled, stay there: Vertex AI is putting up a good enough fight.


What are SageMaker and Vertex AI?
SageMaker and Vertex AI are two competing services from AWS and GCP for training and serving machine learning models. They wrap around cloud primitives (virtual machines, accelerators and storage) to streamline the process of building and deploying ML models. Their goal is to prevent developers from manually and repeatedly setting up operations that are common across most ML workflows.
For instance, building a training pipeline requires a few universal steps: placing the training data in a storage system, bringing up one or more accelerator-enabled virtual machines, ensuring they are not bottlenecked by I/O (i.e. more time is spent propagating gradients than reading training data), checkpointing and evaluating regularly, etc.
SageMaker and Vertex AI enable developers to set up such involved workflows with a mere configuration file or a few bash commands. The result is a self-healing system that accomplishes the task without much monitoring needed. This is why they are often referred to as fully managed services.
SageMaker and Vertex AI for model inference
In this article, we compare SageMaker and Vertex AI from the lens of model inference in particular. Here, their main value proposition is to ensure that (a) the inference server is always up and running, and (b) it autoscales based on incoming traffic. The latter is particularly relevant in today’s era of large models that require powerful accelerators. Since GPUs are scarce and expensive, we cannot afford to have them sit idle, so we need to bring them up and down based on the amount of traffic.
While we focus on inference in this article, it’s worth acknowledging these services encompass many other parts of the workflow. Notably, in addition to support for model training, they both include notebook-centric offerings for data scientists to analyze the training data (see SageMaker Notebooks and Vertex AI Notebooks).
Developer workflow
When using SageMaker or VertexAI for model deployment, developers are expected to perform the following three steps:
- Create a model.
- Configure an endpoint.
- Deploy the model to the endpoint.
These operations can be performed via the web interface, cloud-specific CLIs, or cloud-specific SDKs for various programming languages.
Creating a model
Creating a model boils down to supplying a Docker image for an HTTP server that responds to requests for (1) loading model artifacts in memory, (2) making predictions and (3) health checks. Beyond this contract, SageMaker and Vertex AI are relatively unopinionated about what they serve, treating models as black boxes that need to be kept up and running while responding to prediction requests.
Both SageMaker and Vertex AI offer prebuilt images for various ML frameworks (PyTorch, Tensorflow, Scikit-learn, etc.) and built-in algorithms. For instance, if you simply want to run text-to-image generation with SDXL 1.0, you can grab the image from Amazon’s Marketplace or from Google Cloud’s Model Garden. Alternatively, they also both support custom images that allow developers to write their own serving logic and define their own runtime environment, as long as the container exposes an HTTP server with the three endpoints mentioned above.
Configuring an endpoint
An endpoint configuration associates a model with a set of runtime constraints: machine and accelerator type to run on, minimum and maximum amount of resources to be consumed, and how to handle autoscaling (what metric to monitor and above what threshold to trigger).
Deploying a model
Once these configurations are in place, the developer gives the final green light. SageMaker and Vertex AI then provision the necessary machines, run the container, and call the initial model load method exposed by the inference server. Then, throughout the lifetime of the container, they make regular health checks and restart the container when necessary. Based on traffic, they scale up and down in an attempt to minimize resource consumption and maximize throughput.
How do SageMaker and Vertex AI compare?
Verdict: SageMaker wins overall. If you’re starting from scratch and have no affinity for one cloud provider over the other (free credits, existing lock-in, or strong familiarity with their tooling), just go for SageMaker. However, if GCP already has you enthralled, stay there: Vertex AI is putting up a good enough fight.
Many times, the answer to this kind of question is “It depends”. But this is not one of those times. At least in the context of model serving, SageMaker wins by far on most dimensions. Compared to Vertex AI, SageMaker is generally more feature-rich and flexible, without losing sight of its original goal of making ML workflows easy. This, coupled with AWS’s general customer obsession (which translates into faster customer support and more free credits for startups) makes SageMaker a better choice overall.
That being said, Vertex AI can be good enough if your use case is not very sophisticated. If you have a good enough reason to prefer GCP (perhaps you’re already locked in, or have more free credits there), Vertex AI might work for you just fine.
Autoscaling
SageMaker offers more flexibility when configuring autoscaling. In contrast to Vertex AI, it can scale based on QPS instead of resource usage.
In the context of model inference, autoscaling is one of the main value propositions of fully managed services like SageMaker and Vertex AI. When your traffic increases, they provision extra machines. When it decreases, they remove unnecessary instances. This is particularly important in today’s world, where most models run on accelerators that are too expensive to be kept idle. However, adjusting the allocated resources based on traffic is a non-trivial task.
Why is autoscaling difficult?
A big hinderance is that scaling up is not instantaneous. When an extra GPU is needed, the system will provision a new VM, download the Docker image, start the container, and download model artifacts. This can take anywhere between 3 to 8 minutes, depending on the specifics of your deployment. Since it can’t react to fluctuations in traffic quickly enough, the system needs to predict traffic spikes ahead of time by leveraging past information.
How SageMaker wins the autoscaling game
SageMaker offers three types of autoscaling (see documentation): (1) target tracking (tracks a designated metric — like CPU usage — and scales up when a predefined threshold is exceeded), (2) step scaling (supports more complex logic based on multiple tracked metrics) and (3) scheduled scaling (allows you to hard-code specific times when you expect a traffic increase).
The recommended method is target tracking: you pick any metric from Amazon CloudWatch (or even define a custom one!) and the value that should trigger scaling. There are metrics that reflect resource utilization (e.g. CPU / GPU memory or cycles) and also metrics that measure traffic (e.g. InvocationsPerInstance or ApproximateBacklogSizePerInstance).
In contrast, Vertex AI provides a lot less control (see documentation). The only option is target tracking, restricted to two metrics: CPU utilization and GPU duty cycles. Note that there is no metric that directly reflects traffic. This is very inconvenient when your model cannot serve multiple requests concurrently (i.e., neither batching nor multi-threading is possible). Without this ability, your CPU or GPU is operating in one of two modes: either 0% utilization (no requests), or a fixed x% utilization (one or more requests). In this binary reality, CPU or GPU usage does not reflect the true load and is not a good trigger for scaling. Your only option is to scale up whenever utilization is somewhere between 0% and x%, with the added complexity that x is accelerator-dependent: if you switch from an NVIDIA T4 to an A100, you’ll have to manually lower the threshold.
For some extra drama, Vertex AI cannot scale down to zero (see issue); at least one machine must keep running. However, SageMaker allows completely removing all instances for their asynchronous endpoints (more on this in the next section).
Perhaps the only saving grace for GCP is that it allows you to easily track the autoscaling behavior on their web console, whereas AWS provides no information whatsoever on their web portal (and you’ll have to resort to a bash command in a for loop to monitor it).
Synchronous vs asynchronous predictions
SageMaker supports both synchronous calls (which block waiting until the prediction is complete) and asynchronous calls (which immediately return a URL that will hold the output once ready). Vertex AI solely supports the former.
By default, SageMaker and Vertex AI endpoints are synchronous — the caller is blocked waiting until the prediction is complete. While this is the easiest client/server communication model to wrap your head around, it can be inconvenient when the model has high latency. Both services will simply timeout after 60 seconds: if a single model call takes longer than that, SageMaker / Vertex AI will simply return a timeout response. Note that this includes wait times as well. Say that the client issues two requests simultaneously, and each request takes 45 seconds to resolve. If your model doesn’t support parallelism (e.g. via batching), then the second request will timeout (since it would need 90 seconds to get resolved).
To work around this issue, SageMaker supports asynchronous endpoints — they immediately respond to the client with an S3 URL; the model output will be placed there when completed. It is up to the client to poll the S3 location until available. Since requests are placed in a (best-effort) FIFO queue, the time out is extended to 15 minutes (as opposed to 60 seconds). Unfortunately, Vertex AI does not support asynchronous endpoints; you would have to implement your own queuing and retry logic if you don’t want your requests to simply be dropped after 60 seconds.
Note that both SageMaker and Vertex AI support batch predictions, which are asynchronous. These are not suitable for live traffic, but rather batch jobs (i.e., running offline predictions over an entire dataset).
Multi-model endpoints (MMEs)
SageMaker fully supports multi-model endpoints that share resources among models. Vertex AI’s multi-model endpoints solely share the URL, and don’t translate to any cost savings.
Sometimes you want to deploy more than just one model. Maybe you have an entire pipeline where each step requires a different model, like for language-guided image editing. Or maybe you have a collection of independent models with a power law usage (2–3 of them are used frequently, and the long tail only occasionally). Allocating a dedicated machine to each model can get prohibitively expensive. To this end, SageMaker offers multi-model endpoints, which share the same container and resources among your models. They don’t need to all fit into memory; SageMaker can swap them in and out on demand based on which one is currently requested. The trade-off is the occasional cold start (i.e. if the requested model is not already in memory, your client will have to wait until SageMaker swaps it in). This is tolerable when you have a long tail of rarely used models.
One constraint of SageMaker multi-model endpoints is that they require all models to use the same framework (PyTorch, Tensorflow etc.). However, multi-container endpoints alleviate this restriction.
While Vertex AI officially allows you to deploy multiple models to an endpoint (see documentation), resources are actually associated with the model, not the endpoint. You don’t get the same advantage of sharing resources and reducing costs, but the mere convenience of being able to gradually transition traffic from a model v1 to a model v2 without changing the endpoint URL. Actually sharing resources is only possible for Tensorflow models that use a pre-built container, which is quite restrictive (see documentation).
Quotas and GPU availability
When it comes to quota and accelerator availability, both providers have their own quirks, which are out-shadowed by the same fundamental challenge: GPUs are expensive.
- With GCP, you can get access to (and pay for) a single A100 GPU. However, AWS forces you to rent 8 at a time (which, depending on your needs, might be an overkill). This situation is particular to A100s and doesn’t apply to lower-tier GPUs; you’re free to request a single GPU of any other type on AWS.
- Within GCP, quotas for VMs can be reused for Vertex AI. In other words, you only have to ask for that hot A100 once. However, AWS manages EC2 and SageMaker quotas separately (read more about AWS service quotas), so make sure to request the quota for the right service.
- While we have dedicated customer support from both providers (GCP via their startup program and AWS via their generative AI accelerator), the AWS representatives are generally much more responsive, which also translates to quota requests being resolved quicker.
Limitations
In the previous sections, we discussed what limitations the two services have with respect to each other. There are, however, limitations that are common among the two:
- Payload restrictions. The model response payload has a maximum size for both services: 1.5 MB for public Vertex AI endpoints, 6 MB for synchronous SageMaker endpoints, and 1 GB for asynchronous endpoints (source 1, source 2).
- Timeouts. Prediction requests will be eventually dropped by both services: 60 seconds for Vertex AI and synchronous SageMaker endpoints, 15 minutes for asynchronous SageMaker endpoints (source 1, source 2).
- Scaling down to 0. This is not supported by Vertex AI and synchronous SageMaker endpoints, but it is possible with SageMaker asynchronous endpoints.
- Attaching a shared file system. Neither SageMaker nor Vertex AI allow mounting an external file storage system (EFS or FSx in AWS and Filestore in GCP). This could be convenient to store and share model artifacts across server replicas or implement tricks like this one for saving space in your Docker image (and reducing launch time). Note that they do support access to regular object storage (S3 and GCS).
Summary
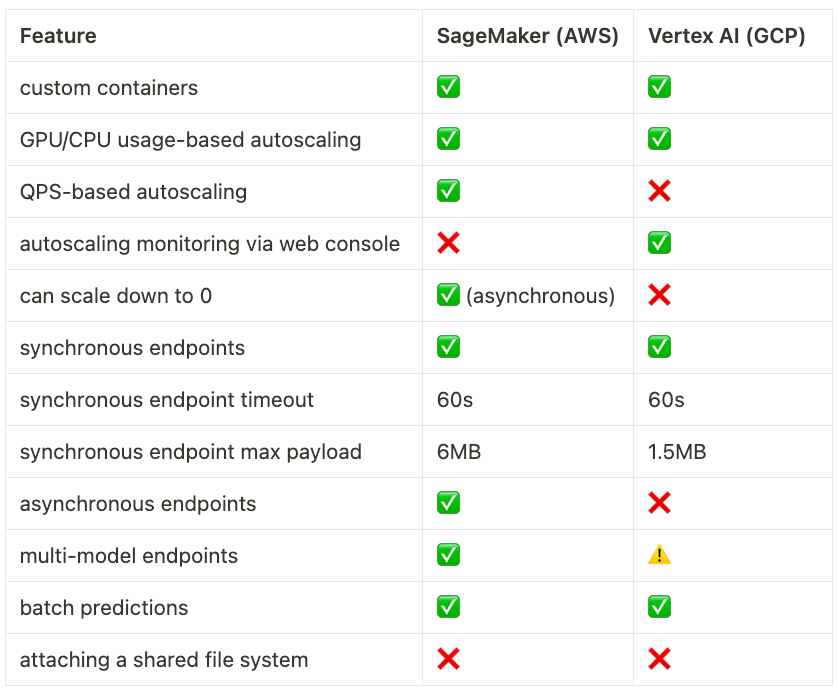
A lot has been said, so here is a neat table that compresses it all:
Alternatives
SageMaker and Vertex are the most popular solutions for model serving and can satisfy most use cases. If you’re not happy with either, then you’ll have to do a little introspection. Do you want more flexibility? Do you want simplicity at the cost of even less flexibility? Or perhaps you just want to reduce cost at the expense of cold starts?
If flexibility is what you’re craving, then there’s probably no way of avoiding Kubernetes — Amazon’s EKS and Google’s GKE are managed Kubernetes services that might be a good start. The additional advantage is that Kubernetes is cloud-agnostic, so you can reuse the same configuration on AWS / GCP / Azure with an infrastructure automation tool like Terraform.
In contrast, if you’re aiming for simplicity, there are services like Replicate, Baseten, Modal or Mystic that are one level of abstraction above SageMaker and Vertex. They come with different trade-offs; for instance, Replicate makes it extremely easy to bring up model endpoints during the experimentation phase, but struggle with significant cold starts.
Contact
If you’re thinking of efficient model serving, we want to hear from you! You can find me on Twitter @juliarturc or LinkedIn.
Further reading
- Official SageMaker documentation
- Official Vertex AI documentation
- Accelerate AI models on GPU using Amazon SageMaker multi-model endpoints with TorchServe, saving up to 75% on inference costs
- Serving Machine Learning models with Google Vertex AI
- Improving launch time of Stable Diffusion on Google Kubernetes Engine (GKE) by 4X
SageMaker vs Vertex AI for Model Inference was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
SageMaker vs Vertex AI for Model Inference
Go Here to Read this Fast! SageMaker vs Vertex AI for Model Inference