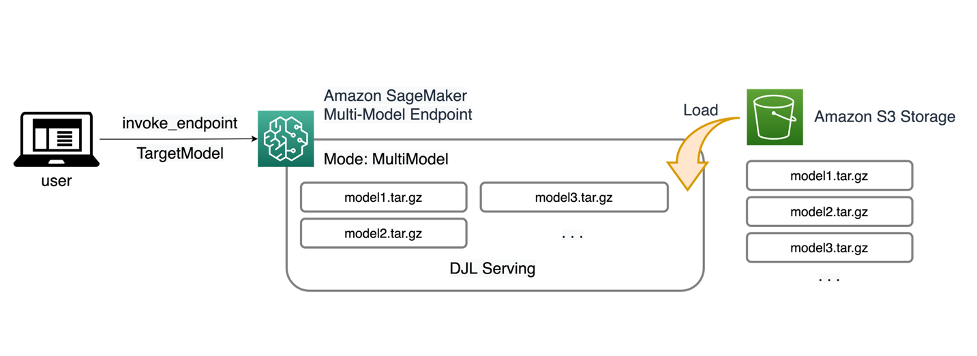

Amazon SageMaker multi-model endpoints (MMEs) are a fully managed capability of SageMaker inference that allows you to deploy thousands of models on a single endpoint. Previously, MMEs pre-determinedly allocated CPU computing power to models statically regardless the model traffic load, using Multi Model Server (MMS) as its model server. In this post, we discuss a […]
Originally appeared here:
Run ML inference on unplanned and spiky traffic using Amazon SageMaker multi-model endpoints