Understanding when reranking makes a difference
In this article I will show you how you can use the Huggingface Transformers and Sentence Transformers libraries to boost you RAG pipelines using reranking models. Concretely we will do the following:
- Establish a baseline with a simple vanilla RAG pipeline.
- Integrate a simple reranking model using the Huggingface Transformers library.
- Evaluate in which cases the reranking model is significantly improving context quality to gain a better understanding on the benefits.
For all of this, I will link to the corresponding code on Github.
What is Reranking?
Before we dive right into our evaluation I want to say few words on what rerankers are. Rerankers are usually applied as follows:
- A simple embedding-based retrieval approach is used to retrieve an initial set of candidates in the retrieval step of a RAG pipeline.
- A Reranker is used to reorder the results to provide a new result order that betters suits the user queries.
But why should the reranker model yield something different than my already quite powerful embedding model, and why do I not leverage the semantic understanding of a reranker in an earlier stage you may ask yourself? This is quite multi-faceted but some key points are that e.g. the bge-reranker we use here is inherently processing queries and documents together in a cross-encoding approach and can thus explicitely model query-document interactions. Another major difference is that the reranking model is trained in a supervised manner on predicting relevance scores that are obtained through human annotation. What that means in practice will also be shown in the evaluation section later-on.
Our Baseline
For our baseline we choose the simplest possible RAG pipeline possible and focus solely on the retrieval part. Concretely, we:
- Choose one large PDF document. I went for my Master’s Thesis, but you can choose what ever you like.
- Extract the text from the PDF and split it into equal chunks of about 10 sentences each.
- Create embedding for our chunks and insert them in a vector database, in this case LanceDB.
For details, about this part, check our the notebook on Github.
After following this, a simple semantic search would be possible in two lines of code, namely:
query_embedding = model.encode([query])[0]
results = table.search(query_embedding).limit(INITIAL_RESULTS).to_pandas()
Here query would be the query provided by the user, e.g., the question “What is shape completion about?”. Limit, in this case, is the number of results to retrieve. In a normal RAG pipeline, the retrieved results would now just be directly be provided as context to the LLM that will synthesize the answer. In many cases, this is also perfectly valid, however for this post we want to explore the benefits of reranking.
Implementing Reranking
With libraries such as Huggingface Transformers, using reranker models is a piece of cake. To use reranking to improve our “RAG pipeline” we extend our approach as follows:
- As previously, simply retrieve an initial number of results through a standard embedding model. However we increase the count of the results from 10 to around 50.
- After retrieving this larger number of initial sources, we apply a reranker model to reorder the sources. This is done by computing relevance scores for each query-source pair.
- For answer generation, we then would normally use the new top x results. (In our case we use the top 10)
In code this is also looking fairly simple and can be implemented in few lines of code:
# Instantiate the reranker
from transformers import AutoModelForSequenceClassification, AutoTokenizer
reranker_tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-v2-m3')
reranker_model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-v2-m3').to("mps")
reranker_model.eval()
# results = ... put code to query your vector database here...
# Note that in our case the results are a dataframe containing the text
# in the "chunk" column.
# Perform a reranking
# Form query-chunk-pairs
pairs = [[query, row['chunk']] for _, row in results.iterrows()]
# Calculate relevance scores
with torch.no_grad():
inputs = reranker_tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512).to("mps")
scores = reranker_model(**inputs, return_dict=True).logits.view(-1,).float()
# Add scores to the results DataFrame
results['rerank_score'] = scores.tolist()
# Sort results by rerank score and add new rank
reranked_results = results.sort_values('rerank_score', ascending=False).reset_index(drop=True)
Again, for seeing the full code for context check Github
As you can see, the main mechanism is simply to provide the model with pairs of query and potentially relevant text. It outputs a relevance score which we then can use to reorder our result list. But is this worth it? In which cases is it worth the extra inference time?
Evaluating The Reranker
For evaluating our system we need to define some test queries. In my case I chose to use the following question categories:
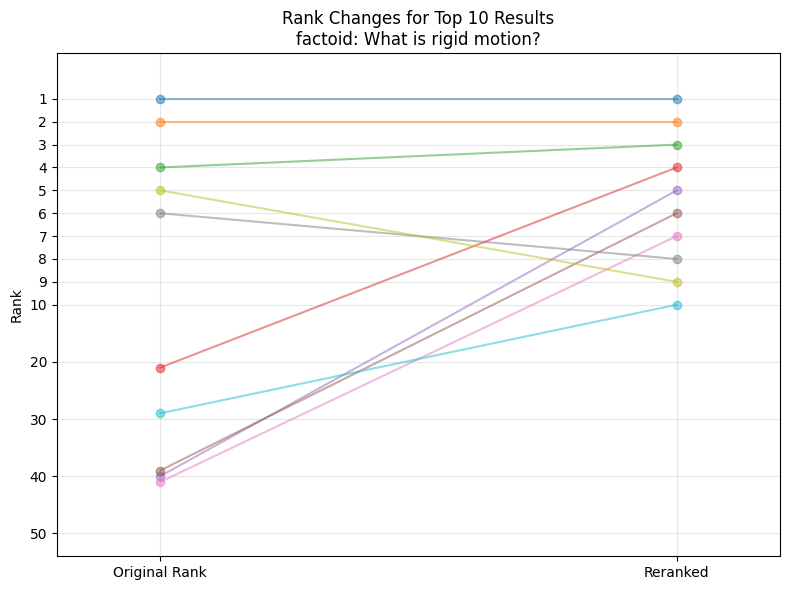
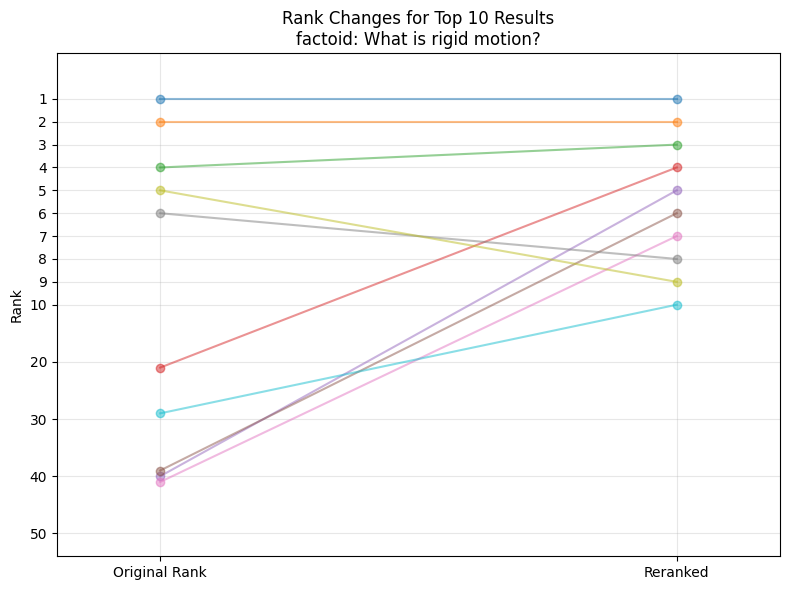
- Factoid Questions such as “What is rigid motion?”
Those should usually have one specific source in the document and are worded such that they could probably even found by text search. - Paraphrased Factoid Questions such as “What is the mechanism in the architecture of some point cloud classification methods that is making them invariant to the order of the points?”
As you can see, those are less specific in mentioning certain terms and require e.g. recognizing the relation of point cloud classification and the PointNet architecture. - Multi Source Questions such as “How does the Co-Fusion approach work, compared to the approach presented in the thesis. What are similarities and differences?”
Those Questions need the retrieval of multiple source that should either be listed or be compared with each other. - Questions for Summaries or Table such as “”What were the networks and parameter sizes used for hand segmentation experiments?”
Those questions target summaries in text and table form, such as a comparison table for model results. They are here to test wether rerankers recognize better that it can be useful to retrieve a summarization part in the document.
As I was quite lazy I only defined 5 questions per category to get a rough impression and evaluated the retrieved context with and without reranking. The criteria I chose for evaluation were for example:
- Did the reranking add important information to the context.
- Did the reranking reduce redundancy to the context.
- Did the reranking give the most relevant result a higher position in the list (better prioritization).
- …
So what about the results?
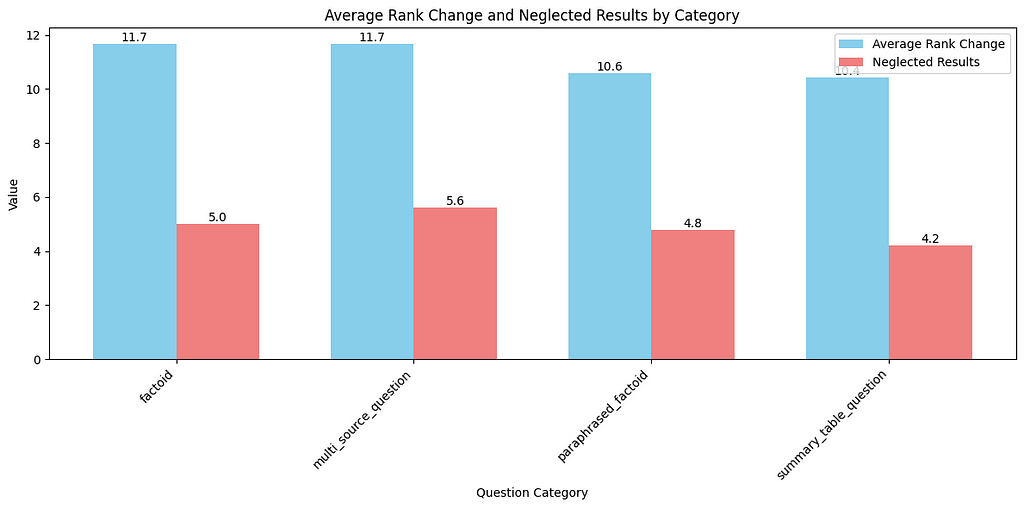
Even in the overview, we can see, that there is a significant difference between the categories of questions, specifically there seems to be a lot of reranking going on for the multi_source_question category. When we look closer on the distributions of the metrics this is additionally confirmed.
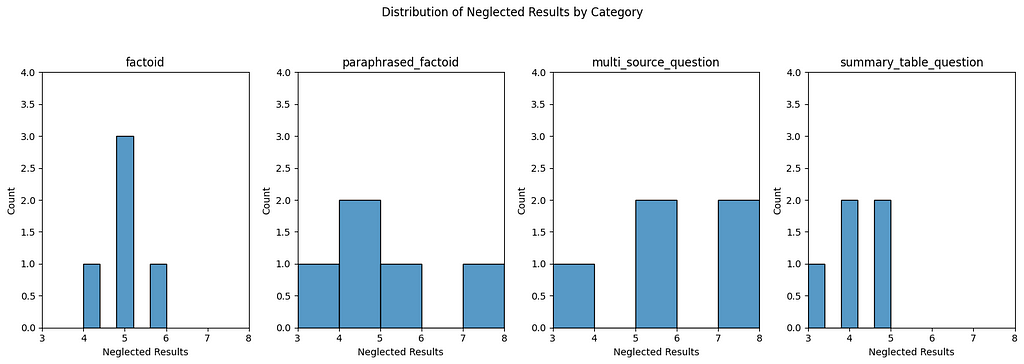
Specifically for 3 of our 5 questions in this category nearly all results in the final top 10 end up there through the reranking step. Now it is about finding out why that is the case. We therefore look at the two queries that are most significantly (positively) influenced by the reranking.
Question1: “How does the Co-Fusion approach work, compare to the approach presented in the thesis. What are similarities and differences?”
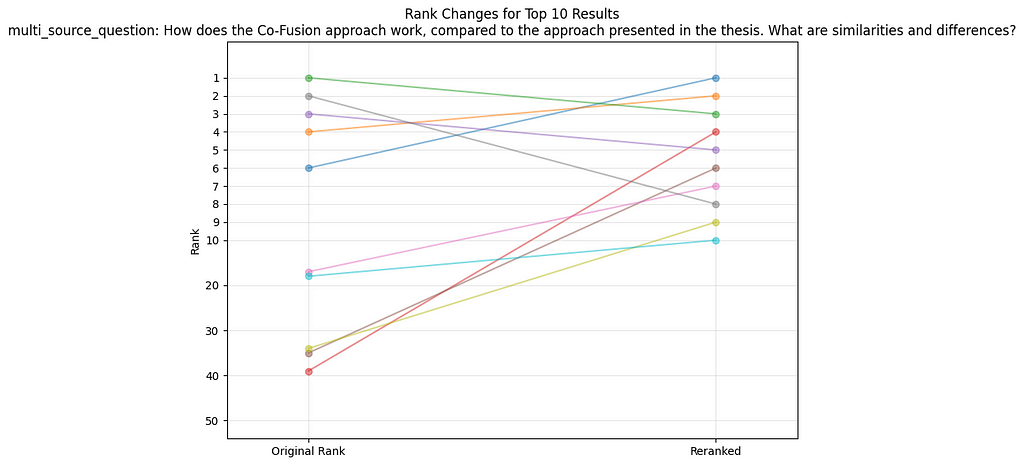
The first impression here is that the reranker for this query definitely had two major effects. It prioritized the chunk from position 6 as the top result. Also, it pulled several really low-ranking results into the top 10. When inspecting these chunks further we see the following:
- The reranker managed to bring up a chunk that is highly related and describes SLAM approaches as opposed to the approach in the thesis.
- The reranker also managed to include a chunk that mentions Co-Fusion as one example for a SLAM approach that can deal with dynamic objects and includes discussion about the limitations.
In general, the main pattern that emerges here is, that the reranker is able to capture nuances in the tone of the speech. Concretely formulations such as “SLAM approaches are closely related to the method presented in the thesis, however” paired with potential sparse mentions of Co-Fusion will be ranked way higher than by using a standard embedding model. That probably is because an Embedding model does most likely not capture that Co-Fusion is a SLAM approach and the predominant pattern in the text is general Information about SLAM. So, the reranker can give us two things here:
- Focusing on details in the respective chunk rather than going for the average semantic content.
- Focusing more on the user intent to compare some method with the thesis’ approach.
Question 2: “Provide a summary of the fulfilment of the objectives set out in the introduction based on the results of each experiment”
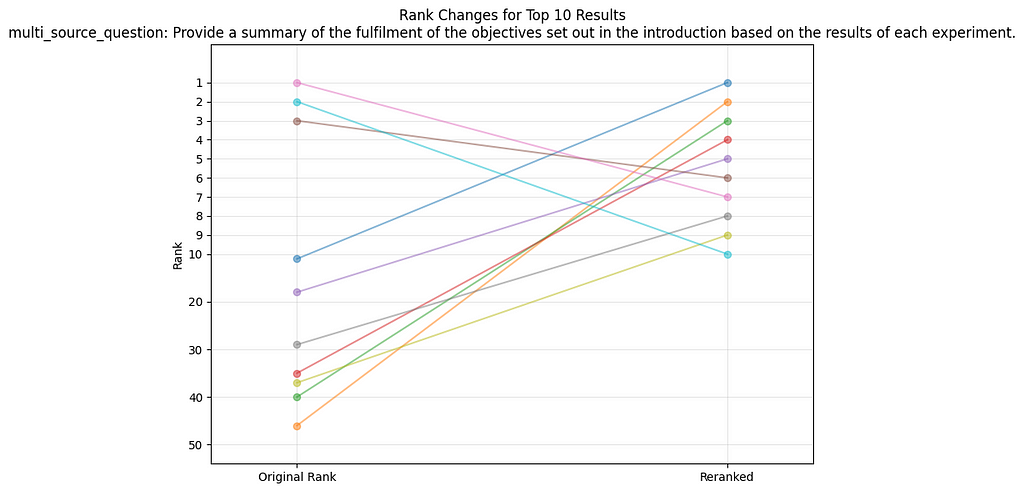
Also, here we realize that a lot of low-ranking sources are pulled into the top 10 sources through the reranking step. So let’s investigate why this is the case once more:
- The reranker again managed to capture nuanced intent of the question and reranks e.g. a chunk that contains the formulation “it was thus suscpected… ” as highly relevant, which it truly is because what follows is then describing wether the assumptions were valid and if the approach could make use of that.
- The reranker gives as a lot of cryptically formulated experimental results that include also a bunch of tabular overviews on results of the ML-trainings, potentially understanding the summarizing character of these sections.
Conclusion
Implementing reranking is not a hard task with packages such as Huggingface Transformers providing easy to use interfaces to integrate them into your RAG pipeline and the major RAG frameworks like llama-index and langchain supporting them out of the box. Also, there are API-based rerankers such as the one from Cohere you could use in your application.
From our evaluation we also see, that rerankers are most useful for things such as:
- Capturing nuanced semantics hidden in a chunk with either different or cryptic content. E.g., a single mention of a method that is only once related to a concept within the chunk (SLAM and Co-Fusion)
- Capturing user intent, e.g. comparing some approach to the thesis approach. The reranker can then focus on formulations that imply that there is a comparison going on instead of the other semantics.
I’m sure there are a lot more cases, but for this data and our test questions these were the dominant patterns and I feel they outline clearly what a supervisedly trained reranker can add over using only an an embedding model.
Reranking Using Huggingface Transformers for Optimizing Retrieval in RAG Pipelines was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Reranking Using Huggingface Transformers for Optimizing Retrieval in RAG Pipelines