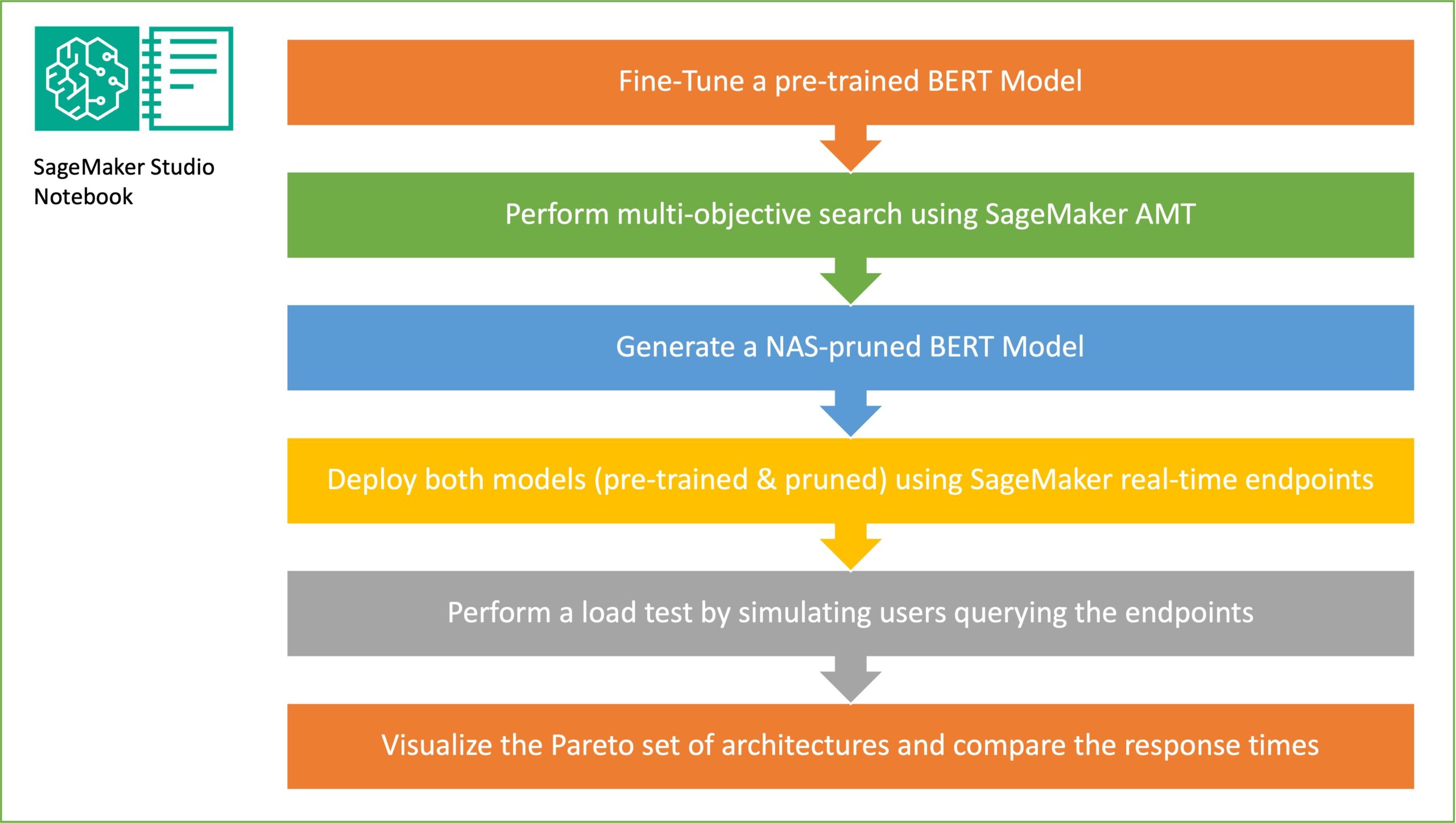

In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. Pre-trained language models (PLMs) are undergoing rapid commercial and enterprise adoption in the areas of productivity tools, customer service, search and recommendations, business process automation, and […]
Originally appeared here:
Reduce inference time for BERT models using neural architecture search and SageMaker Automated Model Tuning