

Data science is at its best out in the real world. I intend to share insights from various productionized projects I have been involved in.
During my years working as a Data Scientist, I have met a lot of students interested in becoming one themselves, or newly graduated just starting out. Starting a career in data science, like any field, involves a steep learning curve.
One, very good, question that I keep getting is: I have learned a lot about the theoretical aspects of data science, but what does a real world example look like?
I want to share small pieces of work, from different projects I have been working on throughout my career. Even though some might be a few years old, I will only write about subjects which I still find relevant. I will try to keep the overarching picture clear and concise, so that new aspiring colleagues will get a grasp of what might be coming up. But I also want to stop and look into details, which I hope that more experienced developers might get some insights out of.
Business Case
Let’s now delve into the specific business case that drove this initiative. The team included a project manager, client stakeholders, and myself. The client needed a way to forecast the usage of a specific service. The reason behind this was resource allocation for maintaining the service and dynamic pricing. Experience with behaviour about the service usage was mostly kept within skilled coworkers, and this application was a way to be more resilient towards them retiring together with their knowledge. Also, the onboarding process of new hirings was thought to be easier with this kind of tool at hand.
Data and Analytical Setup
The data had a lot of features, both categorical and numerical. For the use case, there was a need to forecast the usage with a dynamical horizon, i.e. a need to make predictions for different periods of time into the future. There were also many, correlated and uncorrelated, values needed to be forecasted.
These multivariate time series made the attention mostly focused on experimenting with time series based models. But ultimately, Tabnet was adopted, a model that processes data as tabular.
There are several interesting features in the Tabnet architecture. This article will not delve into model details. But for the theoretical background I recommend doing some research. If you don’t find any good resources, I find this article a good overview or this paper for a more in depth exploration.
As a hyper parameter tuning framework, Optuna was used. There are also other frameworks in Python to use, but I have yet to find a reason not to use Optuna. Optuna was used as a Bayesian hyperparameter tuning, saved to disk. Other features utilized are early stopping and warm starting. Early stopping is used for resource saving purposes, not letting non promising looking trials run for too long. Warm starting is the ability to start from previous trials. This I find useful when new data arrives, and not having to start the tuning from scratch.
The initial parameter widths, will be set as recommended in the Tabnet documentation or from the parameter ranges discussed in the Tabnet paper.
To convey for the heteroscedastic nature of the residuals, Tabnet was implemented as a quantile regression model. To do this, or for implementing any model in this fashion, the pinball loss function, with suitable upper and lower quantiles, was used. This loss function has a skewed loss function, punishing errors unequally depending if they are positive or negative.
Walkthrough with Code
The requirements used for these snippets are as follows.
pytorch-tabnet==4.1.0
optuna==3.6.1
pandas==2.1.4
Code for defining the model.
import os
from pytorch_tabnet.tab_model import TabNetRegressor
import pandas as pd
import numpy as np
from utils import CostumPinballLoss
class mediumTabnetModel:
def __init__(self,
model_file_name,
dependent_variables=None,
independent_variables=None,
batch_size=16_000,
n_a=8,
n_steps=3,
n_independent=2,
n_shared=2,
cat_idxs=[],
cat_dims=[],
quantile=None):
self.model_file_name = model_file_name
self.quantile = quantile
self.clf = TabNetRegressor(n_d=n_a,
n_a=n_a,
cat_idxs=cat_idxs,
cat_dims=cat_dims,
n_steps=n_steps,
n_independent=n_independent,
n_shared=n_shared)
self.batch_size = batch_size
self.independent_variables = independent_variables
self.dependent_variables = dependent_variables
self.cat_idxs = cat_idxs # Indexes for categorical values.
self.cat_dims = cat_dims # Dimensions for categorical values.
self.ram_data = None
def fit(self, training_dir, train_date_split):
if self.ram_data is None:
data_path = os.path.join(training_dir, self.training_data_file)
df = pd.read_parquet(data_path)
df_train = df[df['dates'] < train_date_split]
df_val = df[df['dates'] >= train_date_split]
x_train = df_train[self.independent_variables].values.astype(np.int16)
y_train = df_train[self.dependent_variables].values.astype(np.int32)
x_valid = df_val[self.independent_variables].values.astype(np.int16)
y_valid = df_val[self.dependent_variables].values.astype(np.int32)
self.ram_data = {'x_train': x_train,
'y_train': y_train,
'x_val': x_valid,
'y_val': y_valid}
self.clf.fit(self.ram_data['x_train'],
self.ram_data['y_train'],
eval_set=[(self.ram_data['x_val'],
self.ram_data['y_val'])],
batch_size=self.batch_size,
drop_last=True,
loss_fn=CostumPinballLoss(quantile=self.quantile),
eval_metric=[CostumPinballLoss(quantile=self.quantile)],
patience=3)
feat_score = dict(zip(self.independent_variables, self.clf.feature_importances_))
feat_score = dict(sorted(feat_score.items(), key=lambda item: item[1]))
self.feature_importances_dict = feat_score
# Dict of feature importance and importance score, ordered.
As a data manipulation framework, Pandas was used. I would also recommend using Polars, as a more efficient framework.
The Tabnet implementation comes with a pre-built local and global feature importance attribute to the fitted model. The inner workings on this can be studied in the article posted previous, but as the business use case goes this serves two purposes:
- Sanity check — client can validate the model.
- Business insights — the model can provide new insights about the business to the client.
together with the subject matter experts. In the end application, the interpretability was included to be displayed to the user. Due to data anonymization, there will not be a deep dive into interpretability in this article, but rather save it for a case where the true features going into the model can be discussed and displayed.
Code for the fitting and searching steps.
import optuna
import numpy as np
def define_model(trial):
n_shared = trial.suggest_int('n_shared', 1, 7)
logging.info(f'n_shared: {n_shared}')
n_independent = trial.suggest_int('n_independent', 1, 16)
logging.info(f'n_independent: {n_independent}')
n_steps = trial.suggest_int('n_steps', 2, 8)
logging.info(f'n_steps: {n_steps}')
n_a = trial.suggest_int('n_a', 4, 32)
logging.info(f'n_a: {n_a}')
batch_size = trial.suggest_int('batch_size', 256, 18000)
logging.info(f'batch_size: {batch_size}')
clf = mediumTabnetModel(model_file_name=model_file_name,
dependent_variables=y_ls,
independent_variables=x_ls,
n_a=n_a,
cat_idxs=cat_idxs,
cat_dims=cat_dims,
n_steps=n_steps,
n_independent=n_independent,
n_shared=n_shared,
batch_size=batch_size,
training_data_file=training_data_file)
return clf
def objective(trial):
clf = define_model(trial)
clf.fit(os.path.join(args.training_data_directory, args.dataset),
df[int(len(df) * split_test)])
y_pred = clf.predict(predict_data)
y_true = np.array(predict_data[y_ls].values).astype(np.int32)
metric_value = call_metrics(y_true, y_pred)
return metric_value
study = optuna.create_study(direction='minimize',
storage='sqlite:///db.sqlite3',
study_name=model_name,
load_if_exists=True)
study.optimize(objective,
n_trials=50)
The data are being split into a training, validation and testing set. The usage for the different datasets are:
- Train. This is the dataset the model learns from. Consists in this project of 80%.
- Validation. Is the dataset Optuna calculates its metrics from, and hence the metric optimized for. 10% of the data for this project.
- Test. This is the dataset used to determine the true model performance. If this metric is not good enough, it might be worth going back to investigating other models. This dataset is also used to decide when it is time to stop the hyper parameter tuning. It is also on the basis of this dataset the KPI’s are derived and visualisations shared with the stakeholders.
One final note is that to mimic the behavior of when the model is deployed, as much as possible, the datasets is being split on time. This means that the data from the first 80% of the period goes into the training part, the next 10% goes into validation and the most recent 10% into testing.

For the example presented here, the trials are saved to disk. A more common approach is to save it to a cloud storage for better accessibility and easier maintenance. Optuna also comes with a UI for visualization, which can be spin up running the following command in the terminal.
pip install optuna-dashboard
cd /path/to/directory_with-db.sqlite3/
optuna-dashboard sqlite:///db.sqlite3
A manual task for sanity checking the parameter tuning, is to see how close to the sampling limits, the optimal parameters are. If they are reasonably far away from the bounds set, there is no need to look further into broadening the search space.
An in-depth look into what is displayed from the tuning can be found here.
And here is a visualisation of some of the results.
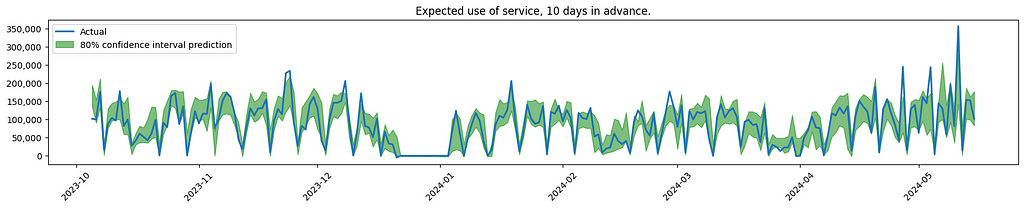
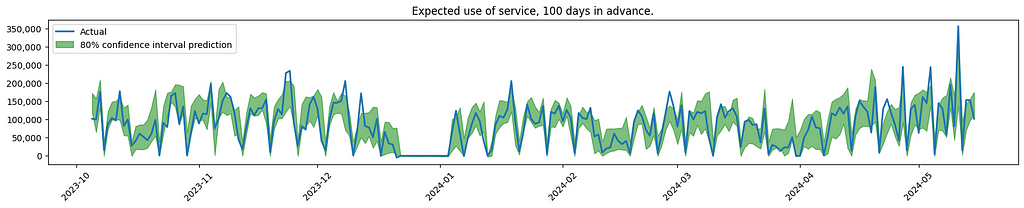
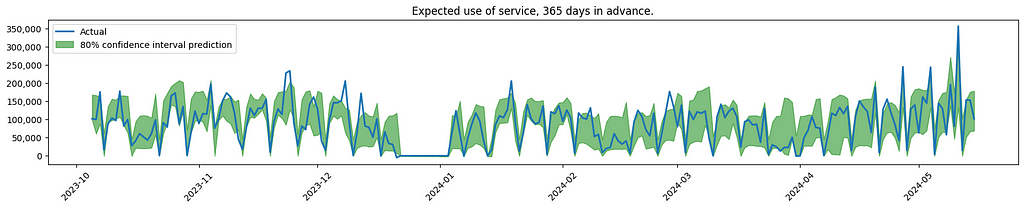
Conclusions and client remarks.
The graph indicates increased uncertainty when forecasting service usage further into the future. This is to be expected, also confirmed by the client.
As noticed, the model is having difficulties finding the spikes that are out of the ordinary. In the real use case, the effort was focused on looking into more sources of data, to see if the model could better predict these outliers.
In the final product there was also introduced a novelty score for the data point predicted, using the library Deepchecks. This came out of discussions with the client, trying to detect data drift and also for user insights into the data. In another article, there will be a deep dive on how this could be developed.
Thank you for reading!
I hope you found this article useful and/or inspiring. If you have any comments or question, please reach out! You can also connect with me on LinkedIn.
Real world Use Cases: Forecasting Service Utilization Using Tabnet and Optuna was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Real world Use Cases: Forecasting Service Utilization Using Tabnet and Optuna