How quantum states and PCA components connect

One of the greatest gifts of maths is its weird ability to be as general as our creativity allows. An important consequence of this generalizability is that we can use the same set of tools to create formalisms for vastly different topics. A side effect of when we do this is that some unexpected analogies will appear between these different areas. To illustrate what I’m saying, I will try to convince you, through this article, that the principal values in PCA coordinates and the energies of a quantum system are the same (mathematical) thing.
The linear algebra of PCA
For those unfamiliar with Principal Component Analysis (or PCA), I will formulate it on the bare minimum. The main idea of PCA is, based on your data, to obtain a new set of coordinates such that when our original data is rewritten in this new coordinate system, the axes point in the direction of the highest variance.
Suppose you have a set of n data samples (which I shall refer from now on as individuals), where each individual consists of m features. For instance, if I ask for the weight, height, and salary of 10 different people, n=10 and m=3. In this example, we expect some relation between weight and height, but there is no relation between these variables and salary, at least not in principle. PCA will help us better visualize these relations. For us to understand how and why this happens, I’ll go through each step of the PCA algorithm.
To begin the formalism, each individual will be represented by a vector x, where each component of this vector is a feature. This means that we will have n vectors living in an m-dimensional space. Our dataset can be regarded as a big matrix X, m x n, where we essentially place the individuals side-by-side (a.k.a. each individual is represented as a column vector):
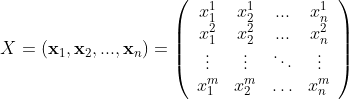
With this in mind, we can properly begin the PCA algorithm.
Centralize the data
Centralizing our data means shifting the data points in a way that it becomes distributed around the origin of our coordinate system. To do this, we calculate the mean for each feature and subtract it from the data points. We can express the mean for each feature as a vector µ:
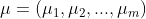
where µ_i is the mean taken for the i-th feature. By centralizing our data we get a new matrix B given by:
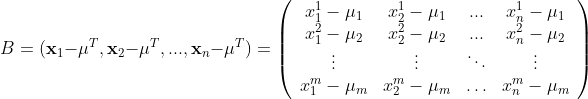
This matrix B represents our data set centered around the origin. Notice that, since I’m defining the mean vector as a row matrix, I have to use its transpose to calculate B (where each individual is represented by a column matrix), but this is just a minor detail.
Compute the covariance matrix
We can compute the covariance matrix, S, by multiplying the matrix B and its transpose B^T as shown below:
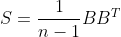
The 1/(n-1) factor in front is just to make the definition equal to the statistical definition. One can easily show that elements S_ij of the above matrix are the covariances of the feature i with the feature j, and its diagonal entry S_ii is the variance of the i-th feature.
Find the eigenvalues and eigenvectors of the covariance matrix
I will list three important facts from linear algebra (that I will not prove here) about the covariance matrix S that we have constructed so far:
- The matrix S is symmetric: the mirrored entries with respect to the diagonal are equal (i.e. S_ij = S_ji);
- The matrix S is orthogonally diagonalizable: there is a set of numbers (λ_1, λ_2, …, λ_m) called eigenvalues, and a set of vectors (v_1, v_2 …, v_m) called eigenvectors, such that, when S is written using the eigenvectors as a basis, it has a diagonal form with diagonal elements being its eigenvalues;
- The matrix S has only real, non-negative eigenvalues.
In PCA formalism, the eigenvectors of the covariance matrix are called the principal components, and the eigenvalues are called the principal values.
At first glance, it seems just a bunch of mathematical operations on a data set. But I will give you a last linear algebra fact and we are done with maths for today:
4. The trace of a matrix (i.e. the sum of its diagonal terms) is independent of the basis in which the matrix is represented.
This means that, if the sum of the diagonal terms in matrix S is the total variance of that data set, then the sum of the eigenvalues of matrix S is also the total variance of the data set. Let’s call this total variance L.
Having this mechanism in mind, we can order the eigenvalues (λ_1, λ_2, …, λ_m) in descending order: λ_1 > λ_2 > … > λ_m in a way that λ_1/L > λ_2/L > … > λ_m/L. We have ordered our eigenvalues using the total variance of our data set as the importance metric. The first principal component, v_1, points towards the direction of the largest variance because its eigenvalue, λ_1, accounts for the largest contribution to the total variance.
This is PCA in a nutshell. Now… what about quantum mechanics?
The linear algebra of quantum mechanics
Maybe the most important aspect of quantum mechanics for our discussion here is one of its postulates:
The states of a quantum system are represented as vectors (usually called state vectors) that live in a vector space, called the Hilbert space.
As I’m writing this, I noticed that I find this postulate to be very natural because I see this everyday, and I have got used to it. But it’s kinda absurd, so take your time to absorb this. Bear in mind that state is a generic term that we use in physics that means “the configuration of something at a certain time.”
This postulate implies that when we represent our physical system as a vector, all the rules from linear algebra apply here, and there should be no surprise that some connections between PCA (which also relies on linear algebra) and quantum mechanics arise.
Since physics is the science interested in how physical systems change, we should be able to represent changes in the formalism of quantum mechanics. To change a vector, we must apply some kind of operation on it using a mathematical entity called (not surprisingly) operator. A class of operators of particular interest is the class of linear operators; in fact, they are so important that we usually omit the term “linear” because it is implied that when we are talking about operators, these are linear operators. Hence, if you want to impress people at a bar table, just drop this bomb:
In quantum mechanics, it’s all about (state) vectors and (linear) operators.
Measurements in quantum mechanics
If in the context of quantum mechanics, vectors represent physical states, what does operators represent? Well, they represent physical measurements. For instance, if I want to measure the position of a quantum particle, it is modeled in quantum mechanics as applying a position operator on the state vector associated with the particle. Similarly, if I want to measure the energy of a quantum particle, I must apply the energy operator to it. The final catch here to connect quantum mechanics and PCA is to remember that a linear operator, when you choose a basis, can be represented as a matrix.
A very common basis used to represent our quantum systems is the basis made by the eigenvectors of the energy operator. In this basis, the energy operator matrix is diagonal, and its diagonal terms are the energies of the system for different energy (eigen)states. The sum of these energy values corresponds to the trace of your energy operator, and if you stop and think about it, of course this cannot change under a change of basis, as said earlier in this text. If it did change, it would imply that it should be possible to change the energy of a system by writing its components differently, which is absurd. Your measuring apparatus in the lab does not care if you use basis A or B to represent your system: if you measure the energy, you measure the energy and that’s it.
Energies and PCA
With all being said, a nice interpretation of the principal values of a PCA decomposition is that they correspond to the “energy” of your system. When you write down your principal values (and principal components) in descending order, you are giving priority to the “states” that carry the largest “energies” of your system.
This interpretation may be somewhat more insightful than trying to interpret a statistical quantity such as variance. I believe that we have a better intuition about energy since it is a fundamental physical concept.
Conclusion
“All of this is pretty obvious.” This was a provocation made by my dearest friend Rodrigo da Motta, referring to the article you’ve just read.
When I write posts like this, I try to explain things having in mind the reader with minimum context. This exercise led me to the conclusion that, with the right background, pretty much anything can be potentially obvious. Rodrigo and I are physicists who also happen to be data scientists, so this relationship between quantum mechanics and PCA must be pretty obvious to us.
Writing posts like this gives me more reasons to believe that we should expose ourselves to all kinds of knowledge because that’s when interesting connections arise. The same human brain that thinks about and creates the understanding of physics is the one that creates the understanding of biology, and history, and cinema. If the possibilities of language and the connections of our brains are finite, it means that contiously or not, we eventually recycle concepts from one field into another, and this creates underlying shared structures accross the domains of knowledge.
We, as scientists, should take advantage of this.
References
[1] Linear algebra of PCA: https://www.math.union.edu/~jaureguj/PCA.pdf
[2] The postulates of quantum mechanics: https://web.mit.edu/8.05/handouts/jaffe1.pdf
Quantum Mechanics Meets PCA: An (Un)expected Convergence was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Quantum Mechanics Meets PCA: An (Un)expected Convergence
Go Here to Read this Fast! Quantum Mechanics Meets PCA: An (Un)expected Convergence