

A side-by-side CNN implementation and comparison
A few months ago, Apple quietly released the first public version of its MLX framework, which fills a space in between PyTorch, NumPy and Jax, but optimized for Apple Silicon. Much like those libraries, MLX is a Python-fronted API whose underlying operations are largely implemented in C++.
Below are some observations of the similarities and differences between MLX and PyTorch. I implemented a bespoke convolutional neural network using PyTorch and its Apple Silicon GPU hardware support, and tested it on a few different datasets. In particular, the MNIST dataset, and the CIFAR-10 and CIFAR-100 datasets.
All the code discussed below can be found here.
Approach
I implemented the model with PyTorch first, since I’m more familiar with the framework. The model has a series of convolutional and pooling layers, followed by a few linear layers with dropout.
# First block: Conv => ReLU => MaxPool
self.conv1 = Conv2d(in_channels=channels, out_channels=20, kernel_size=(5, 5), padding=2)
self.relu1 = ReLU()
self.maxpool1 = MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
# Second block: Conv => ReLU => MaxPool
self.conv2 = Conv2d(in_channels=20, out_channels=50, kernel_size=(5, 5), padding=2)
self.relu2 = ReLU()
self.maxpool2 = MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
# Third block: Conv => ReLU => MaxPool layers
self.conv3 = Conv2d(in_channels=50, out_channels=final_out_channels, kernel_size=(5, 5), padding=2)
self.relu3 = ReLU()
self.maxpool3 = MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
# Fourth block: Linear => Dropout => ReLU layers
self.linear1 = Linear(in_features=fully_connected_input_size, out_features=fully_connected_input_size // 2)
self.dropout1 = Dropout(p=0.3)
self.relu3 = ReLU()
# Fifth block: Linear => Dropout layers
self.linear2 = Linear(in_features=fully_connected_input_size // 2, out_features=fully_connected_input_size // 4)
self.dropout2 = Dropout(p=0.3)
# Sixth block: Linear => Dropout layers
self.linear3 = Linear(in_features=fully_connected_input_size // 4, out_features=classes)
self.dropout3 = Dropout(p=0.3)
self.logSoftmax = LogSoftmax(dim=1)
This architecture is overkill for MNIST dataset classification, but I wanted something with some complexity to compare the two frameworks. I tested this against the CIFAR datasets, which approached around 40% accuracy; not amazing, but I suppose decent for something that isn’t a ResNet.
After finishing this implementation, I wrote a parallel implementation leveraging MLX. I happily discovered that most of the PyTorch implementation could be directly re-used, after importing the necessary MLX modules and replacing the PyTorch ones.
For example, the MLX version of the above code is here; it’s identical aside from a couple of differences in named parameters.
Notes on MLX
MLX has some interesting properties worth calling out.
Array
MLX’s array class takes the place of Tensor; much of the documentation compares it to NumPy’s ndarray, however it is also the datatype used and returned by the various neural network layers available in the framework.
array works mostly as you’d expect, though I did have a bit of trouble converting back and forth between deeply-nested np.ndarrays and mlx.arrays necessitating some list type shuffling to make things work.
Lazy Computation
Operations in MLX are lazily evaluated; meaning that the only computation executed in the lazily-built compute graph is that which generates outputs actually used by the program.
There are two ways to force evaluation of the results of operations (such as inference):
- Calling mlx.eval() on the output
- Referencing the value of a variable for any reason; for example when logging or within conditional statements
This can be a little tricky when trying to manage the performance of the code, since a reference (even an incidental one) to any value triggers an evaluation of that variable as well as all intermediate variables within the graph. For example:
def classify(X, y):
model = MyModel() # Not yet initialized
p = model(X) # Not yet computed
loss = mlx.nn.losses.nll_loss(p, y) # Not yet computed
print(f"loss value: {loss}") # Inits `model`, computes `loss` _and_ `p`
mlx.eval(p) # No-op
# Without the print() above, would return `p` and lazy `loss`
return p, loss
This behavior also makes a little difficult to build one-to-one benchmarks between PyTorch and MLX-based models. Since training loops may not evaluate outputs within the loop itself, its computation needs to be forced in order to track the time of the actual operations.
test_start = time.perf_counter_ns() # Start time block
accuracy, _ = eval(test_data_loader, model, n)
mx.eval(accuracy) # Force calculation within measurement block
test_end = time.perf_counter_ns() # End time block
There’s a tradeoff between accumulating a large implicit computation graph, and regularly forcing the evaluation of that graph during training. For example, I was able to lazily run through all of this model’s training epochs over the dataset in just a few seconds. However, the eventual evaluation of that (presumably enormous) implicit graph took roughly the same amount of time as eval’ing after each batch. This is probably not always the case.
Compilation
MLX provides the ability to optimize the execution of pure functions through compilation. These can be either a direct call to mlx.compile() or an annotation (@mlx.compile) on a pure function (without side effects).
There are a few gotchas related to state mutation when using compiled functions; these are discussed in the docs.
It seems like this results in a compilation of logic into Metal Shader Language to be run on the GPU (I explored MSL earlier here).
API Compatibility and Code Conventions
As mentioned above, it was pretty easy to convert much of my PyTorch code into MLX-based equivalents. A few differences though:
- Some of the neural network layers discretely expect different configurations of inputs. For example, mlx.nn.Conv2d expects input images in NHWC format (with C representing the channels dimensionality), while torch.nn.Conv2d expects NCHW ; there are a few other examples of this. This required some conditional tensor/array shuffling.
- There is unfortunately no analog to the relative joy that are PyTorch Datasets and DataLoaders being currently provided by MLX; instead I had to craft something resembling them by hand.
- Model implementations, deriving from nn.Module, aren’t expected to override forward() but rather __call__() for inference
- I assume because of the potential for function compilation, as well as the lazy evaluation support mentioned above, the process of training using MLX optimizers is a bit different than with a typical PyTorch model. Working with the latter, one is used to the standard format of something like:
for X, y in dataloader:
p = model(X)
loss = loss_fn(p, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
MLX encourages, and seems to expect, a format resembling the following, taken from the docs and one of the repository examples:
def loss_fn(model, X, y):
return nn.losses.cross_entropy(model(X), y, reduction="mean")
loss_and_grad_fn = nn.value_and_grad(model, loss_fn)
@partial(mx.compile, inputs=model.state, outputs=model.state)
def step(X, y):
loss, grads = loss_and_grad_fn(model, X, y)
optimizer.update(model, grads)
return loss
# batch_iterate is a custom generator function
for X, y in batch_iterate(batch_size, train_images, train_labels):
loss = step(X, y)
Which is fine, but a bit more involved than I was expecting. Otherwise, everything felt very familiar.
Performance
Note that all results below are from my MacBook Air M2.
This CNN has three configurations: PyTorch CPU, PyTorch GPU, and MLX GPU. As a sanity check, over 30 epochs, here’s how the three compare in terms of accuracy and loss:

The results here are all in the same ballpark, though it’s interesting that the MLX-based model appears to converge more quickly than the PyTorch-based ones.
In addition, it seems like the accuracy of the MLX model is consistently slightly below that of the PyTorch-based models. I’m not sure what accounts for that discrepancy.
In terms of runtime performance, I had other interesting results:

When training the model, the PyTorch-based model on the CPU unsurprisingly took the most time, from a minimum of 36 to a maximum of 45 seconds per epoch. The MLX-based model, running on the GPU, had a range of about 21–27 seconds per epoch. PyTorch running on the GPU, via the MPS device , was the clear winner in this regard, with epochs ranging from 10–14 seconds.
Classification over the test dataset of ten thousand images tells a different story.

While it took the CPU-based model around 1700ms to classify all 10k images in batches of 512, the GPU-based models completed this task in 1100ms for MLX and 850ms for PyTorch.
However, when classifying the images individually rather than in batches:

Apple Silicon uses a unified memory model, which means that when setting the data and model GPU device to mps in PyTorch via something like .to(torch.device(“mps”)) , there is no actual movement of data to physical GPU-specific memory. So it seems like the overhead associated with PyTorch’s initialization of Apple Silicon GPUs for code execution is fairly heavy. As seen further above, it works great during parallel batch workloads. But for individual record classification after training, it was far outperformed by whatever MLX is doing under the hood to spin up GPU execution more quickly.
Profiling
Taking a quick look at some cProfile output for the MLX-based model, ordered by cumulative execution time:
ncalls tottime percall cumtime percall filename:lineno(function)
426 86.564 0.203 86.564 0.203 {built-in method mlx.core.eval}
1 2.732 2.732 86.271 86.271 /Users/mike/code/cnn/src/python/mlx/cnn.py:48(train)
10051 0.085 0.000 0.625 0.000 /Users/mike/code/cnn/src/python/mlx/model.py:80(__call__)
30153 0.079 0.000 0.126 0.000 /Users/mike/Library/Python/3.9/lib/python/site-packages/mlx/nn/layers/pooling.py:23(_sliding_windows)
30153 0.072 0.000 0.110 0.000 /Users/mike/Library/Python/3.9/lib/python/site-packages/mlx/nn/layers/convolution.py:122(__call__)
1 0.062 0.062 0.062 0.062 {built-in method _posixsubprocess.fork_exec}
40204 0.055 0.000 0.055 0.000 {built-in method relu}
10051 0.054 0.000 0.054 0.000 {built-in method mlx.core.mean}
424 0.050 0.000 0.054 0.000 {built-in method step}
We some time spent here in a few layer functions, with the bulk of time spent in mlx.core.eval(), which makes sense since it’s at this point in the graph that things are actually being computed.
Using asitop to visualize the underlying timeseries powertools data from MacOS:
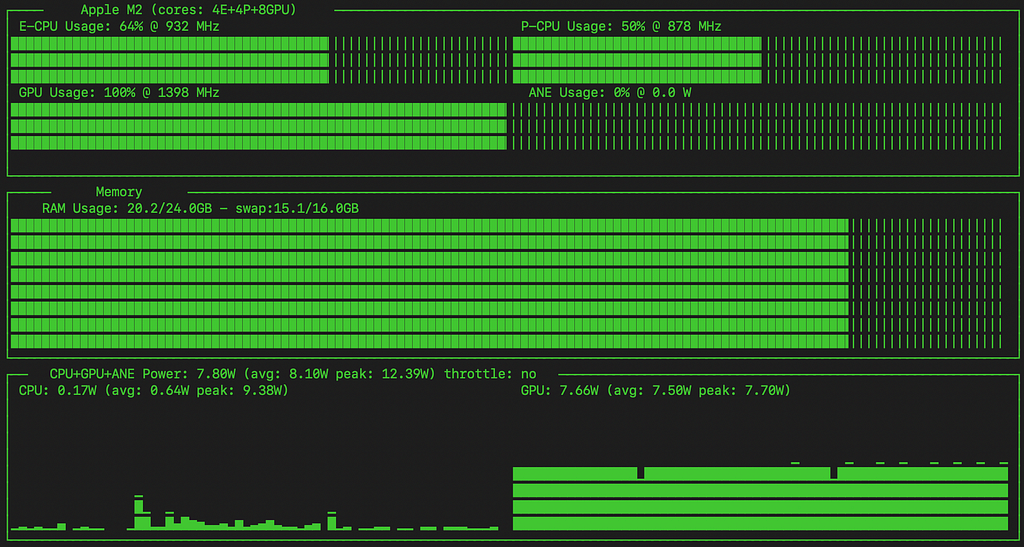
You can see that the GPU is fully saturated during the training of this model, at its maximum clock speed of 1398 MHz.
Now compare to the PyTorch GPU variant:
ncalls tottime percall cumtime percall filename:lineno(function)
15585 41.385 0.003 41.385 0.003 {method 'item' of 'torch._C.TensorBase' objects}
20944 6.473 0.000 6.473 0.000 {built-in method torch.stack}
31416 1.865 0.000 1.865 0.000 {built-in method torch.conv2d}
41888 1.559 0.000 1.559 0.000 {built-in method torch.relu}
31416 1.528 0.000 1.528 0.000 {built-in method torch._C._nn.linear}
31416 1.322 0.000 1.322 0.000 {built-in method torch.max_pool2d}
10472 1.064 0.000 1.064 0.000 {built-in method torch._C._nn.nll_loss_nd}
31416 0.952 0.000 7.537 0.001 /Users/mike/Library/Python/3.9/lib/python/site-packages/torch/utils/data/_utils/collate.py:88(collate)
424 0.855 0.002 0.855 0.002 {method 'run_backward' of 'torch._C._EngineBase' objects}
5 0.804 0.161 19.916 3.983 /Users/mike/code/cnn/src/python/pytorch/cnn.py:176(eval)
Interestingly, the top function appears to be Tensor.item(), which is called in various places in the code to calculate loss and accuracy, and possibly also within some of the layers referenced lower in the stack. Removing the tracking of loss and accuracy during training would probably have a noticeable improvement on overall training performance.
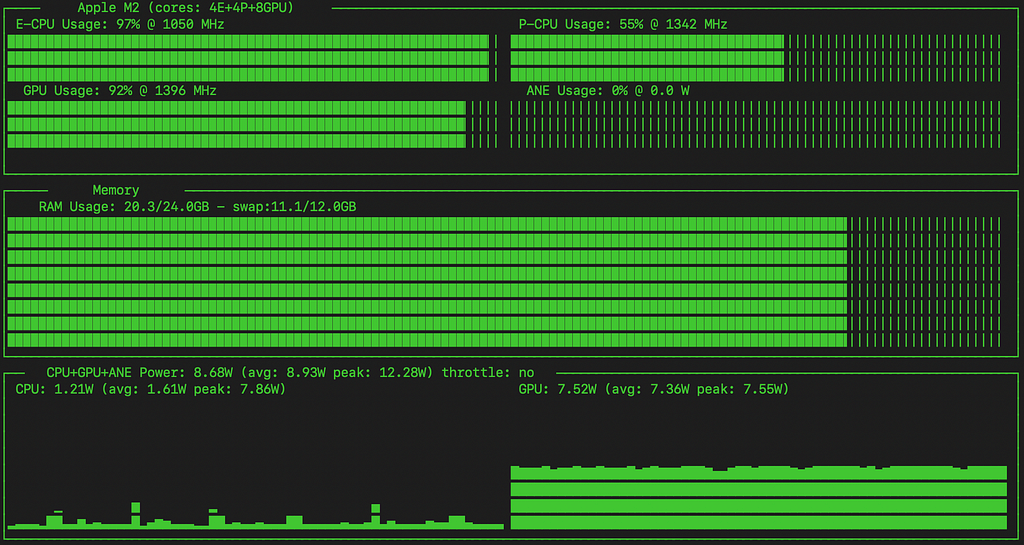
Compared to the MLX model, the PyTorch variant doesn’t seem to have saturated the GPU during training (I didn’t see it breach 95%), and has a higher balance of usage on the CPU’s E cores and P cores.
It’s interesting that the MLX model makes heavier use of the GPU, but trains considerably more slowly.
Neither model (CPU or GPU-based) appears to have engaged the ANE (Apple Neural Engine).
Final Thoughts
MLX was easy to pick up, and that should be the case for anyone with experience using PyTorch and NumPy. Though some of the developer documentation is a bit thin, given the intent to provide tools compatible with those frameworks’ APIs, it’s easy enough to fill in any gaps with the corresponding PyTorch or NumPy docs (for example, SGD [1] [2]).
The overall performance of the MLX model was pretty good; I wasn’t sure whether I was expecting it to consistently outperform PyTorch’s mps device support, or not. While it seemed like training was considerably faster through PyTorch on the GPU, single-item prediction, particularly at scale, was much faster through MLX for this model. Whether that’s an effect of of my MLX configuration, or just the properties of the framework, its hard to say (and if its the former — feel free to leave an issue on GitHub!)
PyTorch and MLX for Apple Silicon was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
PyTorch and MLX for Apple Silicon
Go Here to Read this Fast! PyTorch and MLX for Apple Silicon