

A brief tour of how caching works in attention-based models
I’ve been exploring articles about how Prompt Caching works, and while a few blogs touch on its usefulness and how to implement it, I haven’t found much on the actual mechanics or the intuition behind it.
The question really comes down to this: GPT-like model generation relies on the relationships between every token in a prompt. How could caching just part of a prompt even make sense?
Surprisingly, it does. Let’s dive in!
Prompt caching has recently emerged as a significant advancement in reducing computational overhead, latency, and cost, especially for applications that frequently reuse prompt segments.
To clarify, these are cases where you have a long, static pre-prompt (context) and keep adding new user questions to it. Each time the API model is called, it needs to completely re-process the entire prompt.
Google was the first to introduce Context Caching with the Gemini model, while Anthropic and OpenAI have recently integrated their prompt caching capabilities, claiming great cost and latency reduction for long prompts.
What is Prompt Caching?
Prompt caching is a technique that stores parts of a prompt (such as system messages, documents, or template text) to be efficiently reused. This avoids reprocessing the same prompt structure repeatedly, improving efficiency.
There are multiple ways to implement Prompt Caching, so the techniques can vary by provider, but we’ll try to abstract the concept out of two popular approaches:
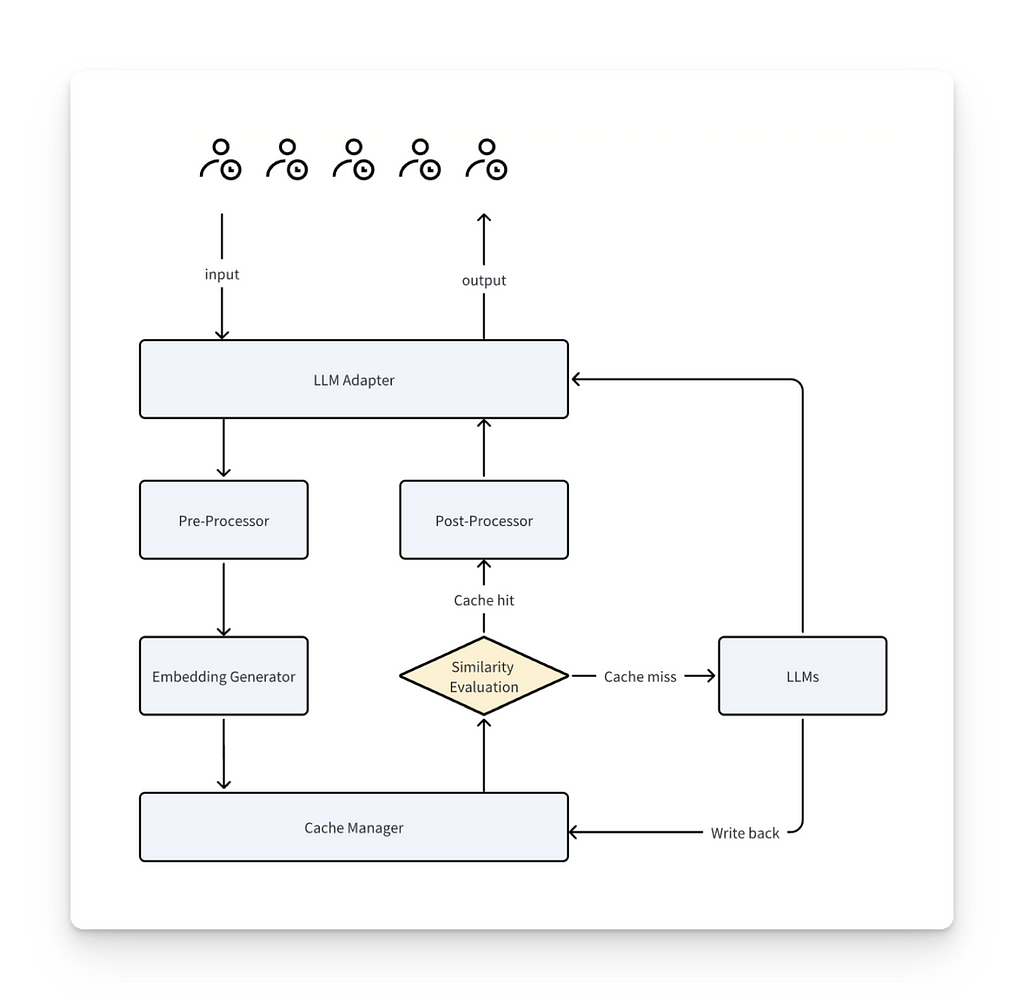
The overall process goes as follows:
- When a prompt comes in, it goes through tokenization, vectorization, and full model inference (typically an attention model for LLMs).
- The system stores the relevant data (tokens and their embeddings) in a cache layer outside the model. The numerical vector representation of tokens is stored in memory.
- On the next call, the system checks if a part of the new prompt is already stored in the cache (e.g., based on embedding similarity).
- Upon a cache hit, the cached portion is retrieved, skipping both tokenization and full model inference.
So… What Exactly is Cached?
In its most basic form, different levels of caching can be applied depending on the approach, ranging from simple to more complex. This can include storing tokens, token embeddings, or even internal states to avoid reprocessing:
- Tokens: The next level involves caching the tokenized representation of the prompt, avoiding the need to re-tokenize repeated inputs.
- Token Encodings: Caching these allows the model to skip re-encoding previously seen inputs and only process the new parts of the prompt.
- Internal States: At the most complex level, caching internal states such as key-value pairs (see below) stores relationships between tokens, so the model only computes new relationships.
Caching Key-Value States
In transformer models, tokens are processed in pairs: Keys and Values.
- Keys help the model decide how much importance or “attention” each token should give to other tokens.
- Values represent the actual content or meaning that the token contributes in context.
For example, in the sentence “Harry Potter is a wizard, and his friend is Ron,” the Key for “Harry” is a vector with relationships with each one of the other words in the sentence:
[“Harry”, “Potter”], [“Harry””, “a”], [“Harry”, “wizard”], etc…
How KV Prompt Caching Works
- Precompute and Cache KV States: The model computes and stores KV pairs for frequently used prompts, allowing it to skip re-computation and retrieve these pairs from the cache for efficiency.
- Merging Cached and New Context: In new prompts, the model retrieves cached KV pairs for previously used sentences while computing new KV pairs for any new sentences.
- Cross-Sentence KV Computation: The model computes new KV pairs that link cached tokens from one sentence to new tokens in another, enabling a holistic understanding of their relationships.
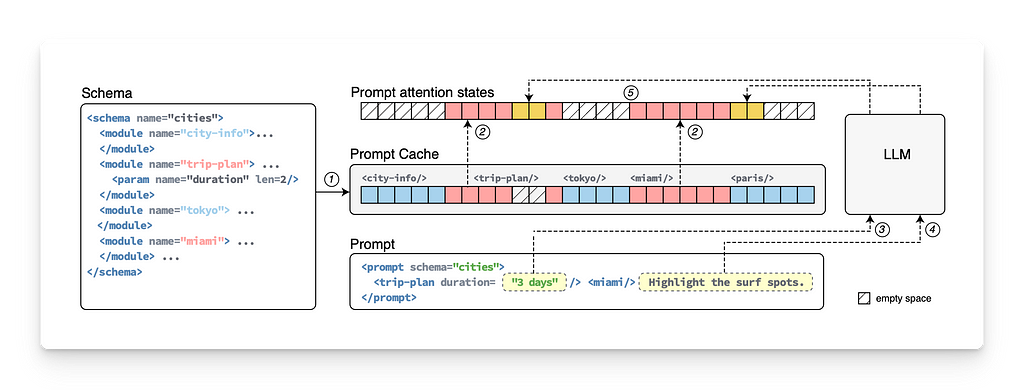
In summary:
All of the relationships between tokens of the cached prompt are already computed. Only new relationships between NEW-OLD or NEW-NEW tokens must be computed.
Is This the End of RAG?
As models’ context sizes increase, prompt caching will make a great difference by avoiding repetitive processing. As a result, some might lean toward just using huge prompts and skipping retrieval processes entirely.
But here’s the catch: as contexts grow, models lose focus. Not because models will do a bad job but because finding answers in a big chunk of data is a subjective task that depends on the use case needs.
Systems capable of storing and managing vast volumes of vectors will remain essential, and RAG goes beyond caching prompts by offering something critical: control.
With RAG, you can filter and retrieve only the most relevant chunks from your data rather than relying on the model to process everything. A modular, separated approach ensures less noise, giving you more transparency and precision than full context feeding.
Finally, larger context models emerging will probably ask for better storage for prompt vectors instead of simple caching. Does that take us back to… vector stores?
At Langflow, we’re building the fastest path from RAG prototyping to production. It’s open-source and features a free cloud service! Check it out at https://github.com/langflow-ai/langflow ✨
Prompt Caching in LLMs: Intuition was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Prompt Caching in LLMs: Intuition
Go Here to Read this Fast! Prompt Caching in LLMs: Intuition